
A Trust Region Reduced Basis Pascoletti-Serafini Algorithm for Multi-Objective PDE-Constrained Parameter Optimization


Abstract
:1. Introduction
2. Multi-Objective Optimization
- (a)
- The functions are called cost or objective functions. Analogously, the vector-valued function is named the (multi-objective) cost or (multi-objective) objective function.
- (b)
- The Hilbert space is named the admissible space, the set is called the admissible set and a vector is called admissible.
- (c)
- The space is named the objective space and the image set is called the objective set. A vector is called objective point.
- (a)
- An admissible vector and its corresponding objective point are called (locally) weakly Pareto optimal if there is no (in a neighborhood of ) with . The setsare said to be the weak Pareto set and the locally weak Pareto set, respectively. The setsare the weak Pareto front and the locally weak Pareto front, respectively.
- (b)
- An admissible vector and its corresponding objective point are called (locally) Pareto optimal if there is no (in a neighborhood of ) with . The setsare called the Pareto set and the local Pareto set, respectively. The setsare called the Pareto front and the local Pareto front, respectively.
2.1. The PS Method
- (a)
- We define the ideal objective point by for all .
- (b)
- For an arbitrary vector define the shifted ideal point. Let be given by for all . Then the set is defined by .
- (c)
- We define .
- (d)
- For any we set .
2.2. Hierarchical PS Method
- (a)
- and for every we denote by the canonical projection to .
- (b)
- the set denotes the (local) (weak) Pareto set and the set denotes the (local) (weak) Pareto front of the subproblem (MOPI).
- (c)
- the (local) (weak) nadir objective point for the subproblem (MOPI) is defined by
- (a)
- Coverage: Every part of the Pareto set and front has to be represented in the sets and , respectively. This can be measured by
- (b)
- Uniformity:The points on the Pareto set and front should be distributed (almost) equidistantly; cf. [16] (Remark 1.7.69-(b)).
- (c)
- Cardinality:The number of points contained in the numerical approximation should be reasonable. In the case of Algorithm 1 is not possible to estimate a-priori the number of elements computed by the method. It is possible to show a bound which can be computed when the nadir objective point is known (cf. [16], Remark 1.7.69-(c)).
| Algorithm 1: Solving (MOP) numerically by the hierarchical PS method |
|
3. The Non-Convex Parametric PDE-Constrained MOP
- (a)
- For all it holdswith a constant , which does not depend on u.
- (b)
- For all with in and , it holds
- (c)
- The mapping is well-defined.
The RB Method for MPPOP
4. The TR-RB Method
| Algorithm 2: TR-RB algorithm |
|
4.1. The TR-RB Algorithm Applied to the PS Method
- (1)
- Use one common RB space for all the subproblems and reference points, i.e., use a single space (which is, of course, updated in the process) for solving the MOP. This strategy acquires efficiency in terms of reconstructing the full-order parameter space during the iterations. Therefore, thanks to the possibility of skipping an enrichment (which is the costly part in Algorithm 2), we expect more and more speed-up, together with accuracy, as the algorithm proceeds.
- (2)
- Use multiple (local) RB spaces. This idea is already exploited by [16,37,38]. In this case, we do not use the previously obtained RB space for the next minimization problem. We generate instead k initial spaces , resulting from the minimization (Note that this procedure does not require extra computational cost, since we need to solve these problems for the hierarchical PS method anyway) of the objectives . Then at the beginning of every PS problem, we can decide to use the space for which and , with being a predefined maximal number of basis functions. If several spaces satisfy these conditions then we select the one for which the value is the smallest. If instead there is no space fulfilling these conditions, we initialize a new space by using the full-order quantities and for .
4.2. How to Reduce the Number of Basis Functions
| Algorithm 3: Summary of T2 |
|
5. Numerical Experiments
5.1. Parameter Choices for the TR-RB Algorithm
- The initial TR radius is chosen as , the tolerance for increasing the TR radius is set to and the factor for shrinking the TR radius to . For the minimal TR radius we use .
- For the Armijo backtracking strategy, we use the constants and .
- The tolerance of the first-order condition is set to , where is the tolerance for the first-order condition of the current augmented Lagrangian subproblem. Moreover, we choose as the tolerance of the first-order condition of the TR-subproblem and as the constant in (15).
- For checking the necessity of updating the RB space, we choose , , and .
- The tolerance chosen in T1 (cf. Section 4.2) for the Fourier coefficient is . Similarly, we choose the same tolerance for T3 in order to break the removal algorithm before deleting important basis functions, i.e., we subtract it on the right-hand side of (25a)–(25f).
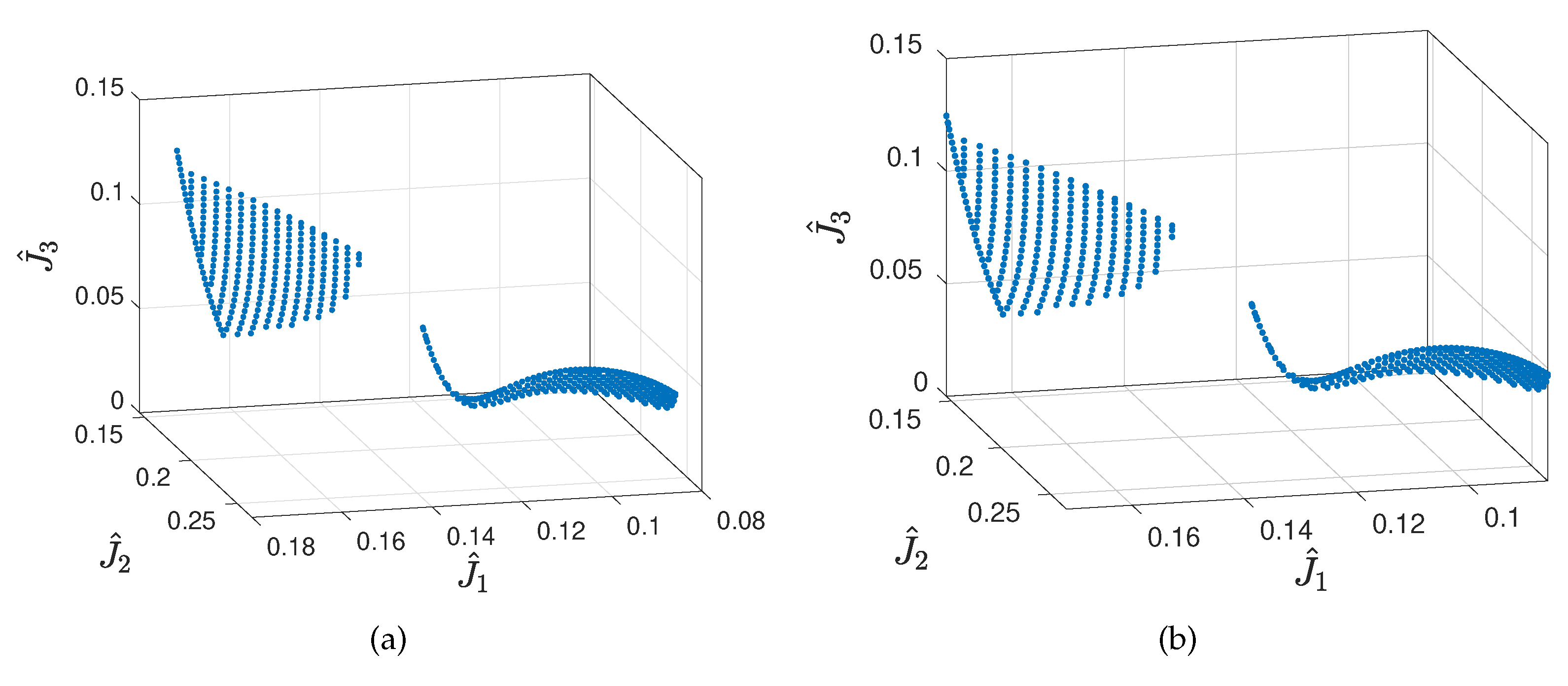
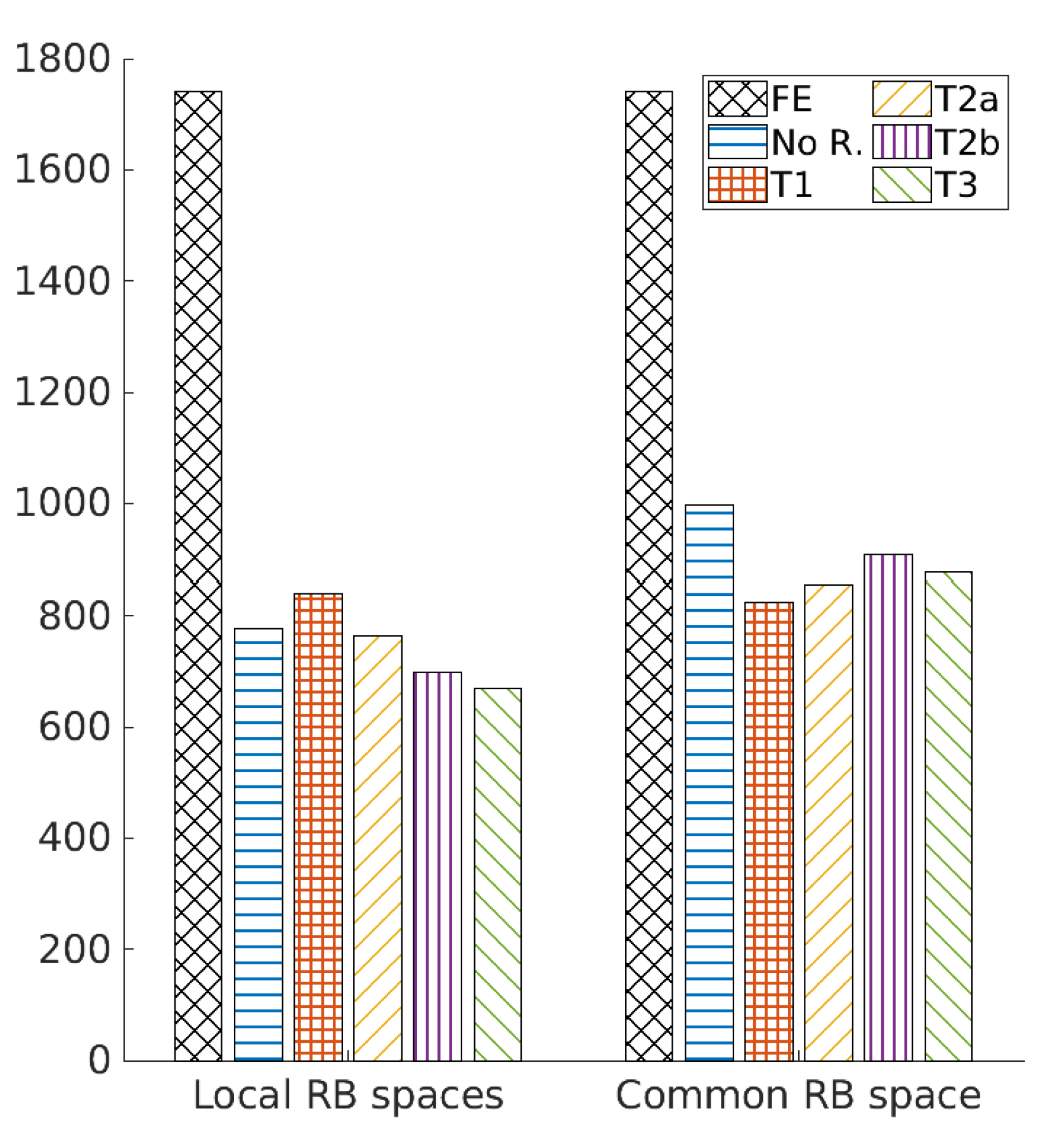
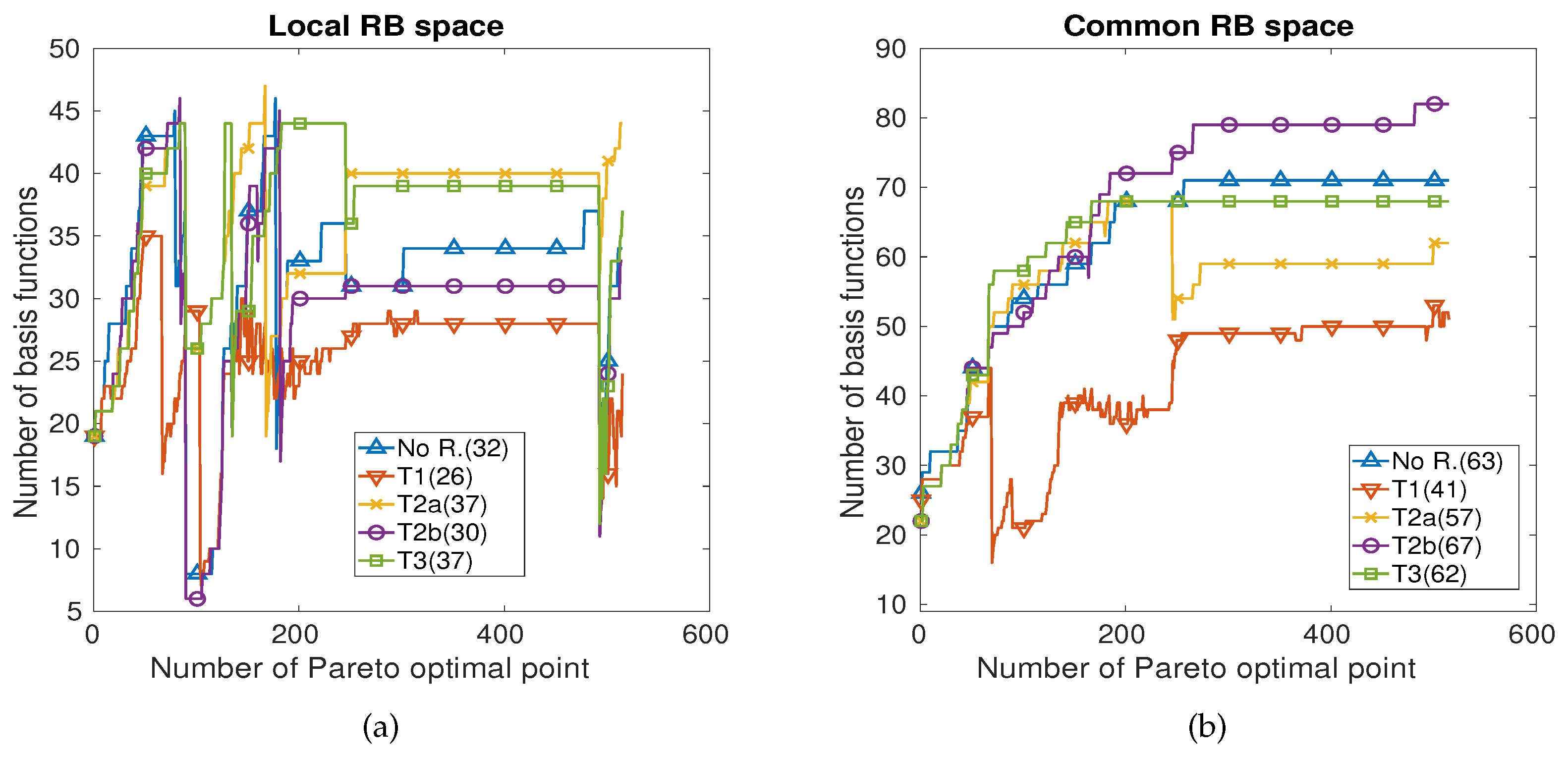
5.2. Numerical Ressults
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| AGC | Approximated generalized Cauchy |
| CG | Conjugate gradient |
| FE | Finite element |
| MOP | Multiobjective optization problem |
| MPPOP | Multiobjective parametric PDE-constrained optimization problem |
| PDE | Partial Differential Equation |
| PS | Pascoletti-Serafini |
| RB | Reduced basis |
| s.t. | subject to |
| TR | Trust-region |
References
- Ehrgott, M. Multicriteria Optimization, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Miettinen, K. Nonlinear Multiobjective Optimization; Kluwer Academic Publishers: Cambridge, MA, USA, 1999. [Google Scholar]
- Zadeh, L. Optimality and non-scalar-valued performance criteria. IEEE Trans. Autom. Control 1963, 8, 59–60. [Google Scholar] [CrossRef]
- Eichfelder, G. Adaptive Scalarization Methods in Multiobjective Optimization; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Pascoletti, A.; Serafini, P. Scalarizing vector optimization problems. J. Optim. Theory Appl. 1984, 42, 499–524. [Google Scholar] [CrossRef]
- Hinze, M.; Pinnau, R.; Ulbrich, M.; Ulbrich, S. Optimization with PDE Constraints; Springer Science + Business Media B.V.: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Schilders, W.H.; Van der Vorst, H.A.; Rommes, J. Model Order Reduction; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Hesthaven, J.S.; Rozza, G.; Stamm, B. Certified Reduced Basis Methods for Parametrized Partial Differential Equations; SpringerBriefs in Mathematics: Heidelberg, Germany, 2016. [Google Scholar]
- Patera, A.T.; Rozza, G. Reduced Basis Approximation and a Posteriori Error Estimation for Parametrized Partial Differential Equations; MIT Pappalardo Graduate Monographs in Mechanical Engineering: Cambridge, MA, USA, 2007. [Google Scholar]
- Banholzer, S.; Gebken, B.; Reichle, L.; Volkwein, S. ROM-based inexact subdivision methods for PDE-constrained multiobjective optimization. Math. Comput. Appl. 2021, 26, 32. [Google Scholar] [CrossRef]
- Iapichino, L.; Ulbrich, S.; Volkwein, S. Multiobjective PDE-constrained optimization using the reduced-basis method. Adv. Comput. Math. 2017, 43, 945–972. [Google Scholar] [CrossRef]
- Schu, M. Adaptive Trust-Region POD Methods and Their Application in Finance. Ph.D. Thesis, University of Trier, Trier, Germany, 2012. Available online: https://ubt.opus.hbz-nrw.de/opus45-ubtr/frontdoor/deliver/index/docId/574/file/PhD_Thesis_Schu.pdf (accessed on 28 April 2022).
- Arian, E.; Fahl, M.; Sachs, W.S. Trust-Region Proper Orthogonal Decomposition for Flow Controls; Techincal Report No. 2000–2025; Institute for Computer Applications in Science and Engineering, NASA Langley Research Center: Hampton, VA, USA, 2000. [Google Scholar]
- Qian, E.; Grepl, M.; Veroy, K.; Willcox, K. A certified trust region reduced basis approach to PDE-constrained optimization. SIAM J. Sci. Comput. 2017, 39, S434–S460. [Google Scholar] [CrossRef]
- Yue, Y.; Meerbergen, K. Accelerating optimization of parametric linear systems by model order reduction. SIAM J. Optimiz. 2013, 23, 1344–1370. [Google Scholar] [CrossRef]
- Banholzer, S. ROM-Based Multiobjective Optimization with PDE Constraints. Ph.D. Thesis, University of Konstanz, Konstanz, Germany, 2021. Available online: http://nbn-resolving.de/urn:nbn:de:bsz:352-2-1g98y1ic7inp29 (accessed on 28 April 2022).
- Banholzer, S.; Keil, T.; Mechelli, L.; Ohlberger, M.; Schindler, F.; Volkwein, S. An adaptive projected Newton non-conforming dual approach for trust-region reduced basis approximation of PDE-constrained parameter optimization. arXiv 2020, arXiv:2012.11653. [Google Scholar]
- Keil, T.; Mechelli, L.; Ohlberger, M.; Schindler, F.; Volkwein, S. A non-conforming dual approach for adaptive trust-region reduced basis approximation of PDE-constrained optimization. ESAIM M2AN 2021, 55, 1239–1269. [Google Scholar] [CrossRef]
- Yano, M.; Huang, T.; Zahr, M.J. A globally convergent method to accelerate topology optimization using on-the-fly model reduction. Comput. Methods Appl. Mech. Eng. 2021, 375, 113635. [Google Scholar] [CrossRef]
- Zahr, M.J.; Carlberg, K.T.; Kouri, D.P. An efficient, globally convergent method for optimization under uncertainty using adaptive model reduction and sparse grids. SIAM/ASA J. Uncertain. Quantif. 2019, 7, 877–912. [Google Scholar] [CrossRef]
- Kouri, D.P.; Heinkenschloss, M.; Ridzal, D.; van Bloemen Waanders, B.G. A trust-region algorithm with adaptive stochastic collocation for PDE optimization under uncertainty. SIAM J. Sci. Comput. 2013, 35, A1847–A1879. [Google Scholar] [CrossRef] [Green Version]
- Kouri, D.P.; Heinkenschloss, M.; Ridzal, D.; van Bloemen Waanders, B.G. Inexact objective function evaluations in a trust-region algorithm for PDE-constrained optimization under uncertainty. SIAM J. Sci. Comput. 2014, 36, A3011–A3029. [Google Scholar] [CrossRef]
- Grüne, L.; Pannek, J. Nonlinear Model Predictive Control: Theory and Algorithms, 2nd ed.; Springer: London, UK, 2016. [Google Scholar]
- Borwein, J.M. On the existence of Pareto efficient points. Math. Oper. Res. 1983, 8, 64–73. [Google Scholar] [CrossRef]
- Hartley, R. On cone-efficiency, cone-convexity and cone-compactness. SIAM J. Appl. Math. 1978, 34, 211–222. [Google Scholar] [CrossRef]
- Sawaragi, Y.; Nakayama, H.; Tanino, T. Theory of Multiobjective Optimization; Elsevier: Amsterdam, The Netherlands, 1985. [Google Scholar]
- Wierzbicki, A.P. The Use of Reference Objectives in Multiobjective Optimization. In Multiple Criteria Decision Making Theory and Application; Springer: Berlin/Heidelberg, Germany, 1980; pp. 468–486. [Google Scholar]
- Mueller-Gritschneder, D.; Graeb, H.; Schlichtmann, U. A successive approach to compute the bounded Pareto front of practical multiobjective optimization problems. SIAM J. Optim. 2009, 20, 915–934. [Google Scholar] [CrossRef]
- De Motta, R.S.; Afonso, S.M.B.; Lyra, P.R.M. A modified NBI and NC method for the solution of N-multiobjective optimization problems. Struct. Multidiscip. Optim. 2012, 46, 239–259. [Google Scholar] [CrossRef]
- Khaledian, K.; Soleimani-damaneh, M. A new approach to approximate the bounded Pareto front. Math. Method Oper. Res. 2015, 82, 211–228. [Google Scholar] [CrossRef]
- Lowe, T.J.; Thisse, J.-F.; Ward, J.E.; Wendell, R.E. On efficient solutions to multiple objective mathematical programs. Manag. Sci. 1984, 30, 1346–1349. [Google Scholar] [CrossRef]
- Sayın, S. Measuring the quality of discrete representations of efficient sets in multiple objective mathematical programming. Math. Program. 2000, 87, 543–560. [Google Scholar] [CrossRef]
- Mechelli, L. POD-Based State-Constrained Economic Model Predictive Control of Convection-Diffusion Phenomena. Ph.D. Thesis, University of Konstanz, Konstanz, Germany, 2019. Available online: http://nbn-resolving.de/urn:nbn:de:bsz:352-2-2zoi8n9sxknm1 (accessed on 28 April 2022).
- Evans, L.C. Partial Differential Equations; American Mathematical Society: Providence, RI, USA, 2010. [Google Scholar]
- Haasdonk, B. Reduced basis methods for parametrized PDEs—A tutorial introduction for stationary and instationary problems. In Model Order Reduction and Approximation: Theory and Algorithms; Benner, P., Ohlberger, M., Cohen, A., Willcox, K., Eds.; SIAM: Philadelphia, PA, USA, 2017; pp. 65–136. [Google Scholar]
- Rozza, G.; Huynh, D.B.P.; Patera, A.T. Reduced basis approximation and a posteriori error estimation for affinely parametrized elliptic coercive partial differential equations. Arch. Comput. Method E 2008, 15, 229–275. [Google Scholar] [CrossRef] [Green Version]
- Beermann, D.; Dellnitz, M.; Peitz, S.; Volkwein, S. Set-oriented multi- objective optimal control of PDEs using proper orthogonal decomposition. In Reduced-Order Modeling (ROM) for Simulation and Optimization; Keiper, W., Milde, A., Volkwein, S., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 47–72. [Google Scholar]
- Haasdonk, B.; Dihlmann, M.; Ohlberger, M. A training set and multiple bases generation approach for parameterized model reduction based on adaptive grids in parameter space. Math. Comput. Model. Dyn. 2011, 17, 423–442. [Google Scholar] [CrossRef]
- Keil, T. Adaptive Reduced Basis Methods for Multiscale Problems and Large-Scale PDE-Constrained Optimization. Ph.D. Thesis, WWU Münster, Münster, Germany, 2022. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Method | # Total PDE Solves | # FE Solves |
|---|---|---|
| FE | 433378 | 433378 |
| Common RB Space No R. | 493254 | 20743 |
| Common RB Space T1 | 493282 | 20786 |
| Common RB Space T2a | 497032 | 20838 |
| Common RB Space T2b | 497032 | 20752 |
| Common RB Space T3 | 493985 | 20792 |
| Local RB Space No R. | 497072 | 20773 |
| Local RB Space T1 | 497589 | 20893 |
| Local RB Space T2a | 507064 | 21226 |
| Local RB Space T2b | 507064 | 20857 |
| Local RB Space T3 | 502911 | 21023 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Banholzer, S.; Mechelli, L.; Volkwein, S. A Trust Region Reduced Basis Pascoletti-Serafini Algorithm for Multi-Objective PDE-Constrained Parameter Optimization. Math. Comput. Appl. 2022, 27, 39. https://doi.org/10.3390/mca27030039
Banholzer S, Mechelli L, Volkwein S. A Trust Region Reduced Basis Pascoletti-Serafini Algorithm for Multi-Objective PDE-Constrained Parameter Optimization. Mathematical and Computational Applications. 2022; 27(3):39. https://doi.org/10.3390/mca27030039
Chicago/Turabian StyleBanholzer, Stefan, Luca Mechelli, and Stefan Volkwein. 2022. "A Trust Region Reduced Basis Pascoletti-Serafini Algorithm for Multi-Objective PDE-Constrained Parameter Optimization" Mathematical and Computational Applications 27, no. 3: 39. https://doi.org/10.3390/mca27030039