1. Introduction
Gearboxes are crucial devices in industrial processes, as they play an important role in power transmission. Then, fault detection and diagnosis in such devices are attracting growing interest in researches, with focus on fault severity assessment. In particular, when a fault is starting, the first stages of the failure mode are not easy to detect, in most cases, and the incipient fault is not advised until reaching severe stages that can cause damages to other devices, decrease the performance of the process, and produce economical losses [
1,
2].
Vibration signal is one of the most informative signals commonly used to determine the health condition of rotating machines [
3]. Once a vibration signal is available, data-driven approaches can offer signal processing techniques to tackle the problem of fault detection and diagnosis by identifying certain signal characteristics in time, frequency or time-frequency domains, as proposed in [
4] for gearboxes.
Particularly, gearboxes exhibit nonlinear and chaotic behavior [
5], and these characteristics are enhanced in the presence of faults [
6,
7,
8]. Then, the identification of informative characteristics in the vibration signal produced by faulty conditions is not easy to accomplish in gearboxes by using standard signal processing, and usually requires expert knowledge. Additionally, previous studies have visually shown that the vibration signal behavior is non-monotonic to the fault severity increment in helical gearboxes [
9,
10]; that is, the signal amplitude does not increase with the fault. Under this scenario, Machine Learning (ML) approaches can address properly the task of fault detection and diagnosis. Moreover, signal processing permits different characterization of the vibration signal useful for the application of ML-based approaches providing high-performance solutions, commonly being the supervised fault classification.
ML-based classifiers using the k-nearest neighbor method (KNN) [
11,
12,
13,
14], artificial neural networks (ANN) [
15,
16,
17,
18] and support vector machines (SVM) [
19,
20,
21,
22,
23], are frequently developed to propose fault classification models. Random Forest (RF) and Decision Trees (DT) are also reported as fault classifiers for gearboxes because of their powerful performance in cases where only a few samples are available and high dimensional feature spaces [
24,
25,
26,
27,
28].
The performance of a conventional ML-based fault classification model is highly dependent on the input feature quality, avoiding the well-known curse of dimensionality, and the selection of the best classification model. Particularly, feature selection is a stage that must be carefully accomplished after features extraction is performed on the vibration signal. Statistical condition indicators (SCI) serve as features extracted from the vibration signal in the time domain, some of them being closely related to the vibration analysis such as the root-mean-square, standard deviation, kurtosis, skewness, among others [
29]. Other features are related to the biomedical field to analyze surface electromyography signals [
30,
31]. The availability of a large set of features makes both feature selection or the mining for new features a process that is not easily generalized.
Although the recent applications of Deep Learning (DL) models to fuse the stages of feature extraction and selection are being widely reported [
9,
32,
33,
34,
35,
36,
37,
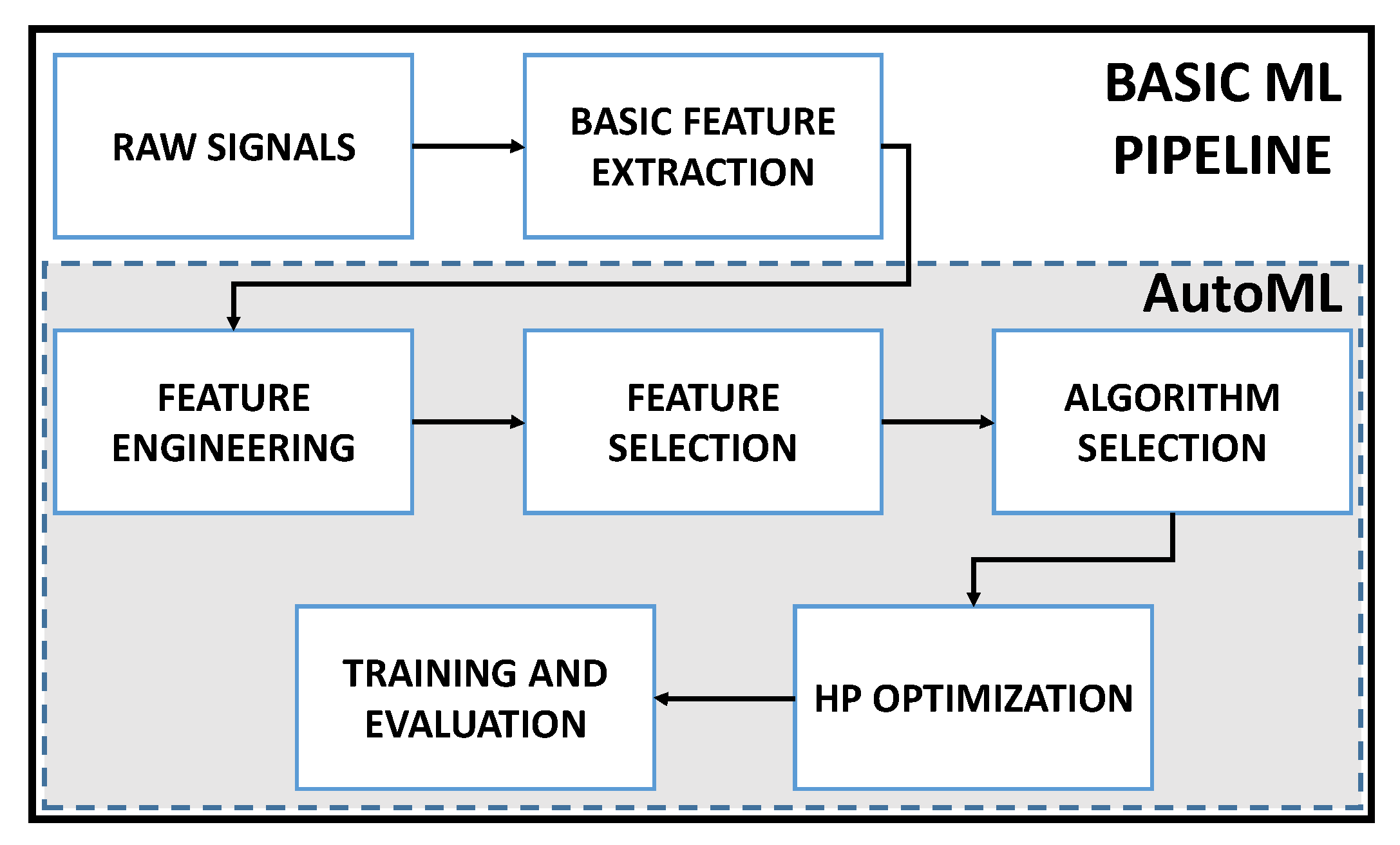
38], the selection of fault-related features like SCI extracted from the raw vibration signal is still a field of interest, mainly due to the easy understanding of such SCI. Moreover, the necessity of developing the whole ML pipeline, including not only feature engineering and selection but also classification model selection, hyperparameter optimization and validation, is currently a challenge in ML system development, called Automated Machine Learning (AutoML) [
39,
40].
According to the case study and the related dataset, for example, fault classification of gearboxes under different failure mode severity or multi-fault scenarios, where different failure modes are combined, the ML-based approach requires the development of a new pipeline for each scenario, that is, feature engineering and model adjustment. In most cases, this process requires exhaustive training plans, including greedy searching on feature and parameter spaces which demands computational efforts and optimization algorithms to obtain a proper classification model as mentioned previously. This is why, the development of ML pipelines automatically is nowadays highly required in practical problems associated to high dimensional feature spaces and complex model requirements. The evaluation of the different computational tools providing this support is well received by the ML-based engineering applications community in helping to choose the proper model.
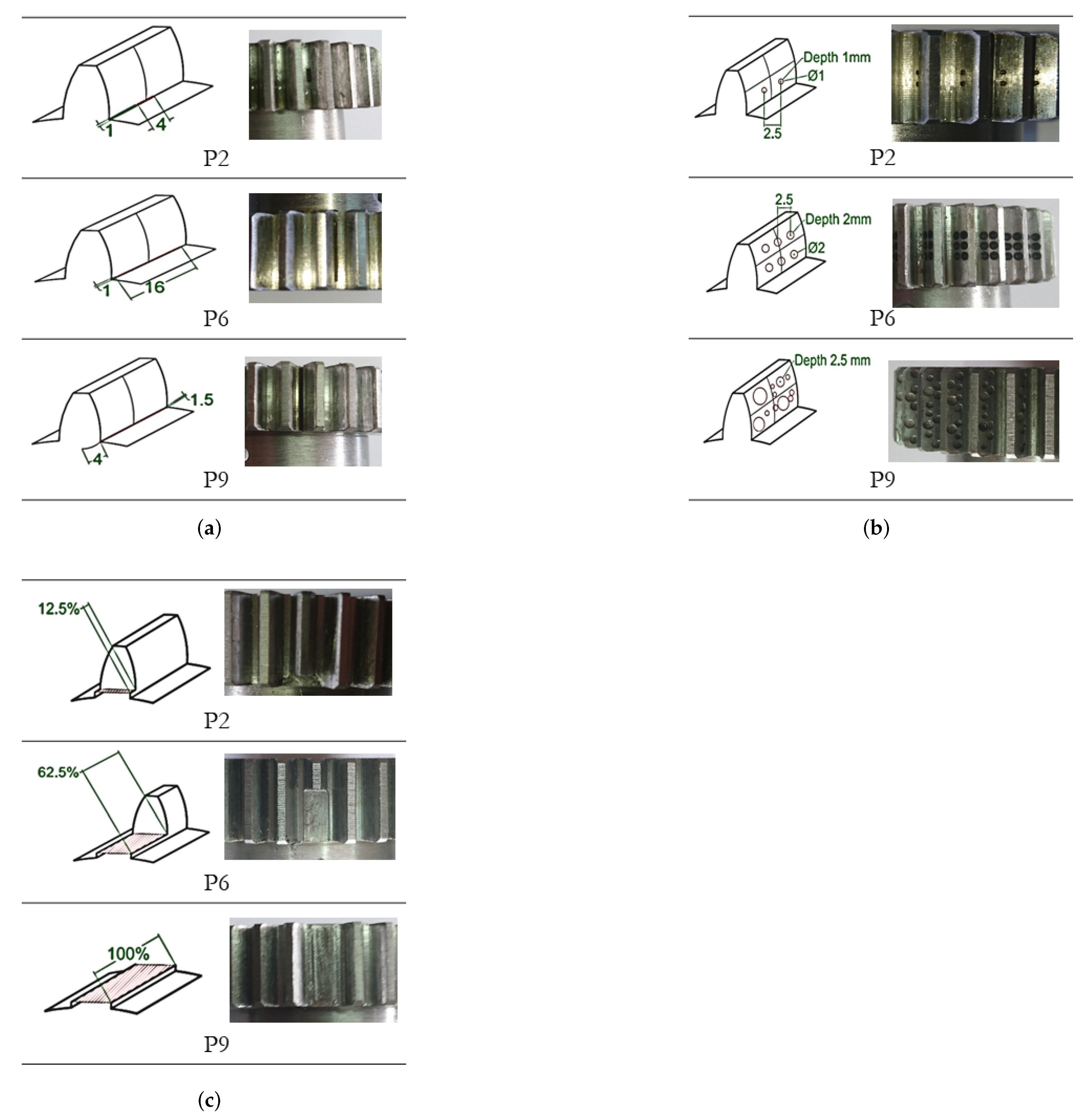
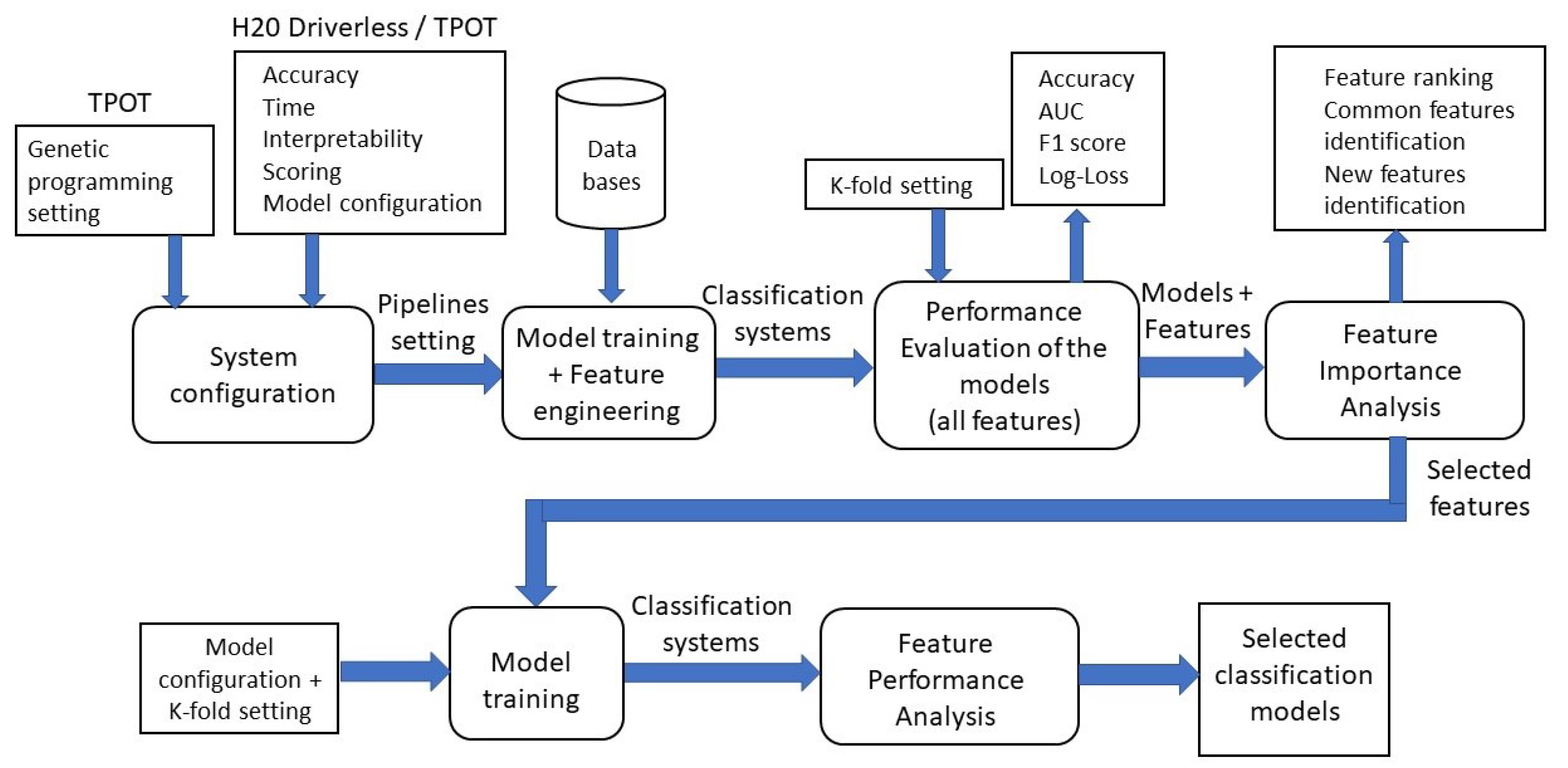
To face the automated development of ML pipelines systematically, this paper presents the application of two AutoML systems for fault severity classification, with evaluation and comparison from an empirical perspective. Particularly, the paper is focused on the feature selection stage, including feature engineering over SCI extracted from vibration signals related to the fault severity of three failure modes in gears, which are pitting, crack and broken tooth. In the following, SCI are named statistical features or features. The application of AutoML in the field of Prognosis and Health Management (PHM) is a more difficult challenge as the industrial equipment, particularly rotating machines, usually work under complex and time varying conditions of load and speed. Then, new contributions in this field are required.
The goal is the comparison of the informative capability between the original statistical features, through the performance evaluation of the ML classifiers proposed by the AutoML systems. The experimental framework uses the software tools H2O Driverless AI which is equipped with evolutionary algorithms to perform feature engineering and selection, and TPOT, which also uses an evolutionary search to build tree-based ML pipelines. Both tools are relatively simple and straightforward to use, offering basic and intuitive configurations for generating different types of pipelines using state-of-the-art techniques and implementations.
Results of the evaluation and comparison between H2O DAI and TPOT show that both platforms select common features regardless of the selected model. For some failure modes, TPOT reduces the feature space but increase it in others. Moreover, accuracy when using the whole feature space, without feature selection, remains very close for the pipelines created by both platforms. Regarding H2O DAI, the informative capability of ten time-domain vibration signal-related statistical features is highlighted, which are enough to obtain proper classification performance.
Moreover, not only are the best features identified for each failure mode, but a common set of features reports proper performance to classify all the failure modes. This is an important contribution in the field of fault severity classification in gearboxes, for which the search for a common set of features for several failure modes in the same machine are still under research.
The rest of the paper is organized as follows.
Section 2 presents the background about the AutoML as an emerging area in ML, and the description of the failure modes in gearboxes under study in this paper.
Section 3 discusses the previous works regarding the feature analysis for fault severity assessment in gearboxes by using vibration signals mainly, and recent applications of AutoML on this domain.
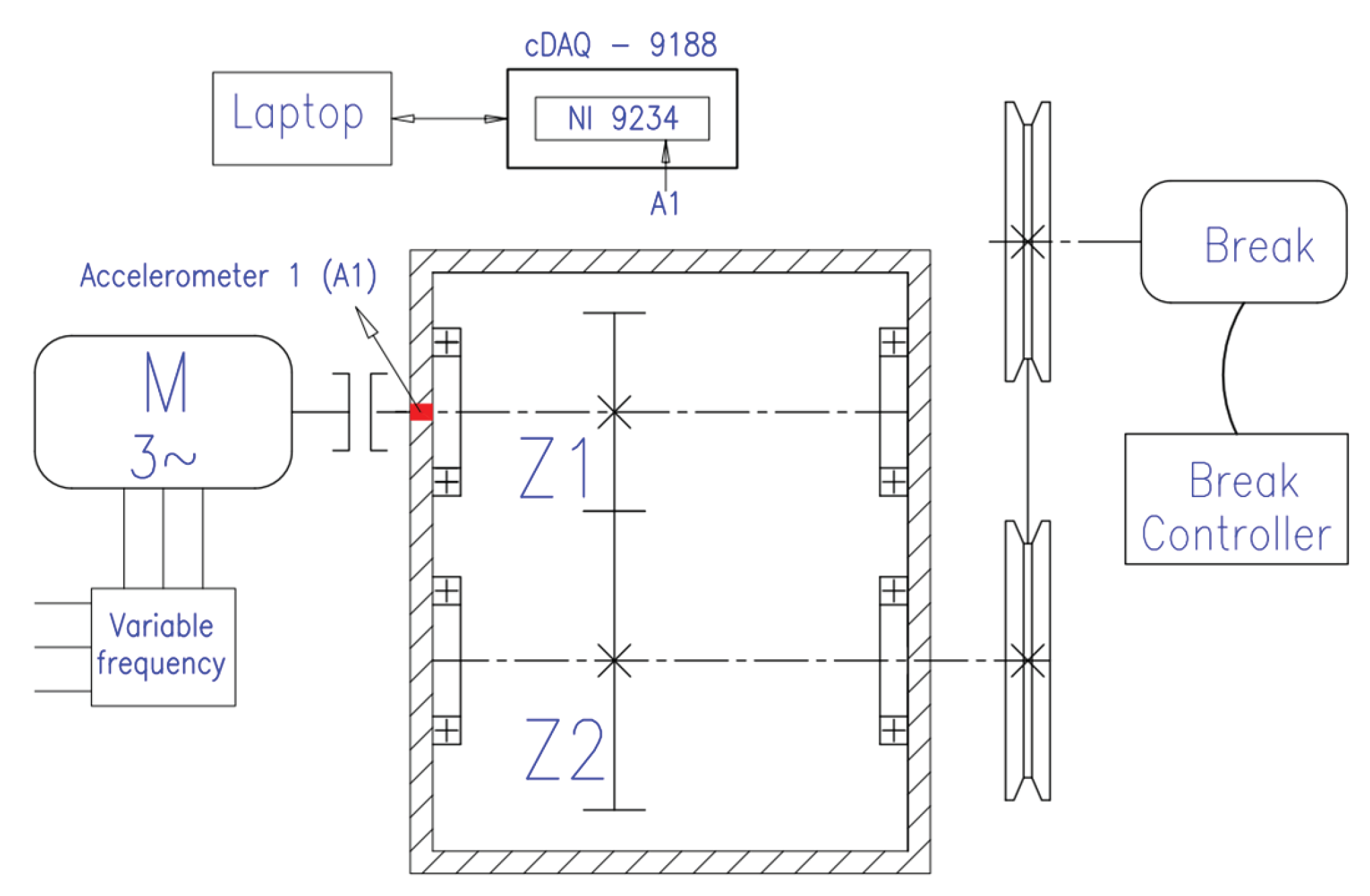
Section 4 describes the test bed of the different cases study, the collection of the data set for each case and the corpus generations.
Section 5 details the experimental framework and results by using the AutoML software
H2O Driverless AI.
Section 6 is devoted to the discussion, and finally
Section 7 summarizes and concludes the paper.
3. Previous Work
Fault severity assessment in gears by using ML has been widely reported. This section is devoted to approaches using feature extraction by calculating statistical features, and focused on the problem of feature selection, and also recent approaches using artificial features extracted from DL models.
In [
12], the identification of five different gear crack levels is performed by using features obtained from Wavelet Packet Decomposition (WPD). The first set of features is composed by 620 statistical features calculated from the wavelet coefficients at different levels, which are then reduced to seven significant principal components. KNN is used as a classifier and compared to other statistical models such as linear discriminant analysis, quadratic discriminant analysis, classification and regression trees, and naive Bayes classifier. Another approach to crack fault level identification is discussed in [
13] by considering 25 features extracted from the time and frequency domains. A two-stage feature selection and weighting technique via Euclidean distance evaluation is proposed to select sensitive features and to weigh the selected features according to their sensitivity to each fault level. The Weighted K-Nearest Neighbor (WKNN) classifier is adopted to identify three gear crack levels under different loads and motor speeds.
Four different crack levels are detected in [
61] by using statistical features and decision trees (DT). Similar work using DT and ARMA feature extraction from the vibration signals is presented in [
62]. Ordinal rough approximation operators based on fuzzy covering and feature selection algorithms for ordinal classification are proposed in [
63] for gear crack level identification. Finally, a DL approach using a Long Short-Term Memory (LSTM) based recurrent neural network is discussed in [
64], to detect tooth crack growth at different stages, where the vibration signal is the input to the LSTM network. The LSTM prediction error is used as a measure of fault severity.
The detection of localized pitting damages in a worm gearbox by a vibration visualization method and ANNs is presented in [
18]. Twelve statistical features are calculated from vibration signals in time and frequency domains for multi-class recognition, where each class is related to a severity level. In [
29], a pitting severity assessment is tackled with supervised learning using an SVM-based ranking model that learns the ordinal information contained in the dataset. Thirty-four statistical features were calculated from vibration signals in the time and frequency domain, among others specifically designed for gearbox damage diagnosis. Three levels of damage were estimated. The approach in [
65] uses Stacked Auto Encoders (SAE) for unsupervised feature extraction, feature reduction based on QR decomposition is then applied on the feature matrix provided by the SAE to obtain low dimensional data feeding an unsupervised K-means clustering.
Fault severity in broken tooth is also tackled by different approaches. The approach in [
9] introduces Stacked Convolutional Autoencoders (SCAE) together with a Deep Convolutional Neural Network (DCNN) as a method for unsupervised hierarchical feature extraction for fault severity assessment in a helical gearbox. In that proposal, statistical features are not extracted, but the artificial ones are provided by the DCNN after training with initialization parameters given by an SCAE. These features feed a multilayer perceptron for classification. Another approach is provided in [
38], where artificial features are provided by a CNN. The spectrogram of the vibration signal is used as the input to the CNN, the output of the last convolutional layer is connected to one softmax layer and finally, these outputs feed an SVM-based decision layer. An approach based on fuzzy transition is developed in [
10] to predict the broken tooth severity in helical gearboxes. This is accomplished by two steps: a set of statistical features extracted from the vibrations signal are uses as input for a static fuzzy model to compute the weights of fuzzy transitions (WFT), and then a dynamic equation using WFT predicts the next degradation state of the rotating device. All the previous works focus on the same dataset related to ten severity damages of broken tooth in helical gearboxes.
Research on AutoML arises as a way to face the challenge of automating the Combined Algorithm Selection and Hyper-parameter tuning, called CASH by [
66], and recent applications can be found. The review in [
67] tackles the use of AutoML for developing smart devices to obtain auto generated embedded code ready to test and execute. An Automated Hyperparameter Search-Based Deep Learning Model for Highway Traffic Prediction is performed by AutoML in [
68]. In the field of process monitoring, ref. [
69] uses AutoML to optimize the parameters of a soft-sensor for monitoring the lysine fermentation process. The authors in [
70] propose in the future research that the AutoML approach could be used for parameter optimization of a Variational Auto Encoder for nonlinear process monitoring.
However, ML-based fault diagnosis has just started to be analyzed under this approach with only a few works in the field of fault diagnosis for rotating machines. In [
71] an approach using the Google DeepMind Team method called Neural Architecture Search (NAS) with reinforcement learning is proposed, as an AutoML tool for the automated search of a multiscale cascade CNN applied to the fault diagnosis of the gearbox data set of the PHM 2009 Data Challenge. In particular, two problems were addressed: fault detection and fault severity classification. Inspired by the NAS method, in [
72] a neural network architecture automatic search method based on reinforcement learning is applied to rolling bearing fault diagnosis for two cases studies: the Case Western Reserve University (CWRU) bearing dataset and the locomotive bearing data set. Inspired by AutoML approaches, a self-optimizing module is proposed in [
73] to dynamically adjust the knowledge base selection and parameter setting for training an Extreme Learning Machine based on physical knowledge. The self-optimizing module was applied on the CWRU bearing dataset.
6. Discussion
The previous section shows the proper performance of the original time-domain condition indicators for fault severity classification with the model obtained by the AutoML systems. The results are compared to alternative ones obtained by the authors when the best set of features and classification model is obtained by manually adjusting the classification parameters and taking the individual ranking provided by the feature ranking algorithm [
80,
81].
In [
80], the same dataset of the pitting damage was analyzed for vibration signals and a subset of 24 time-domain condition indicators. Feature selection was conducted by using Chi-square-based ranking and a KNN classifier. Results show that 6 features can provide over 95% of accuracy and 12 features offer over 96%.
The method proposed in [
81] was adopted to perform feature selection by using relief-based feature ranking and tested on a RF classifier, with the same dataset used in this work. Results are show in
Table 6 and
Figure 10.
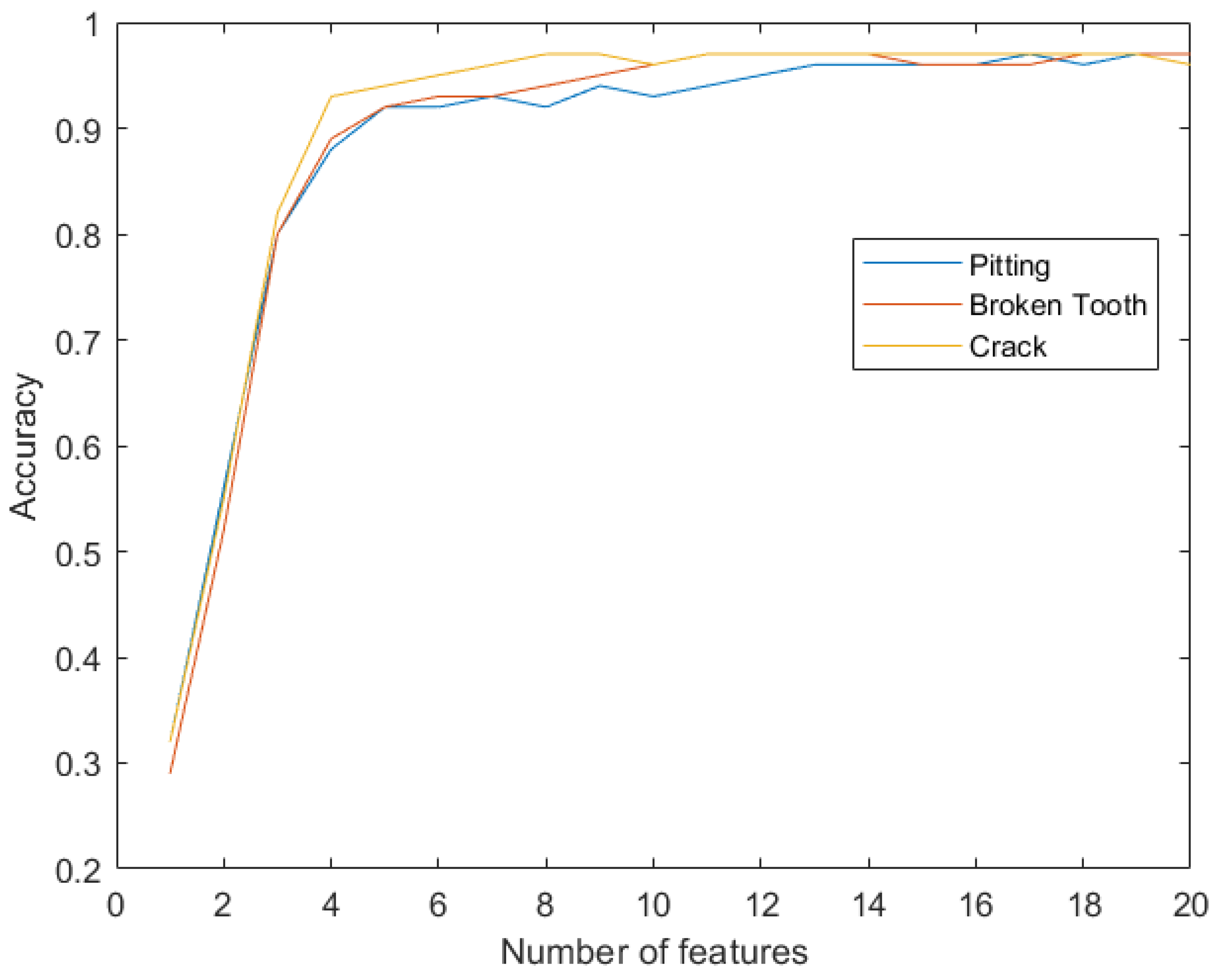
Results in
Table 6 show that, for all the three failures modes, the accuracy remains above 97% with more than 13 features. By comparing to
Figure 8, this trend is similar, and the accuracy is around 96% for pitting, 98% for crack, and 95% for Broken Tooth, when test examples are used. By comparing to
Figure 9, when common features are used, the average accuracy over 98% is attained for pitting, 96% for crack and 97% for Broken tooth, by using over 13 features and test examples.
These results are similar for feature selection and classification using AutoML. The aggregate value of using AutoML is that the search is guided by an optimization problem, simplifying the underlying design process of the ML pipeline. However, at least on the tested problems, the overall performance of the resulting pipeline is not substantially different from those achieved by the standard pipeline design approach. On the other hand, given the simplified approach to ML development, this work was able to show that the same set of features can be used to solve three different fault diagnosis problems in gearboxes, which was previously unknown and not reported by other works in our knowledge.
7. Summary and Conclusions
This paper presents the application of two AutoML systems, H2O DAI and TPOT, for obtaining fault severity ML pipelines for spur gears under three different failures modes at different severity levels. The case study in this work is for fault severity assessment in gearboxes, treated as classification problems for three failure modes: pitting, crack and broken tooth. Fault severity assessment in gearboxes is not a trivial problem, as the gearboxes are mechanical systems with high non-linear and chaotic behaviors that usually work under changes in load and speed.
The use of AutoML to solve fault detection in gearboxes has not been previously reported in the literature, making this work the first to show the power of this approach to generate optimized ML models for this problem. Both AutoML systems are easy to use and provide both optimization modules and feature engineering modules (H2O explicitly, while TPOT mainly does this implicitly), which simplifies the design process of specialized ML pipelines.
The results and main conclusions in this paper are summarized in two ways. Regarding the general results of using AutoML in this domain:
The setting of H2O DAI in the process of feature engineering is more explicit for the user. This is particularly useful when testing the creation of new features;
Results of the evaluation and comparison between H2O DAI and TPOT show that both platforms select common features, regardless of the selected model by each platform. The size of the feature space used by each system varies, and neither of them is consistently more or less efficient in this regard;
Classification accuracy when using all the features, without feature selection, remains very close for both systems, over 96%;
The accuracy achieved by AutoML can be increased relative to a hand-tuned classification model, particularly by adjusting the feature selection technique.
Regarding the feature analysis of the generated AutoML pipelines, we can state the following:
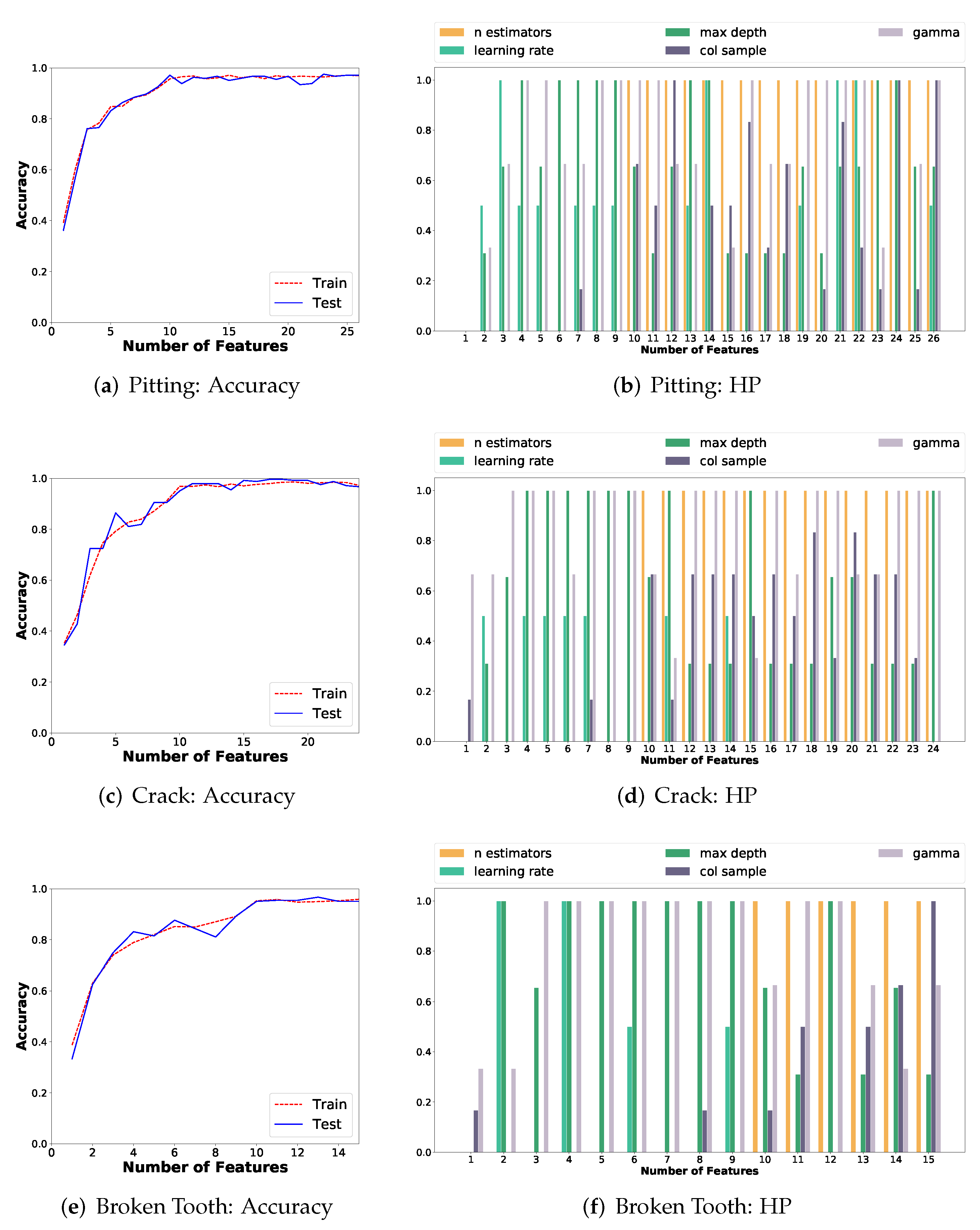
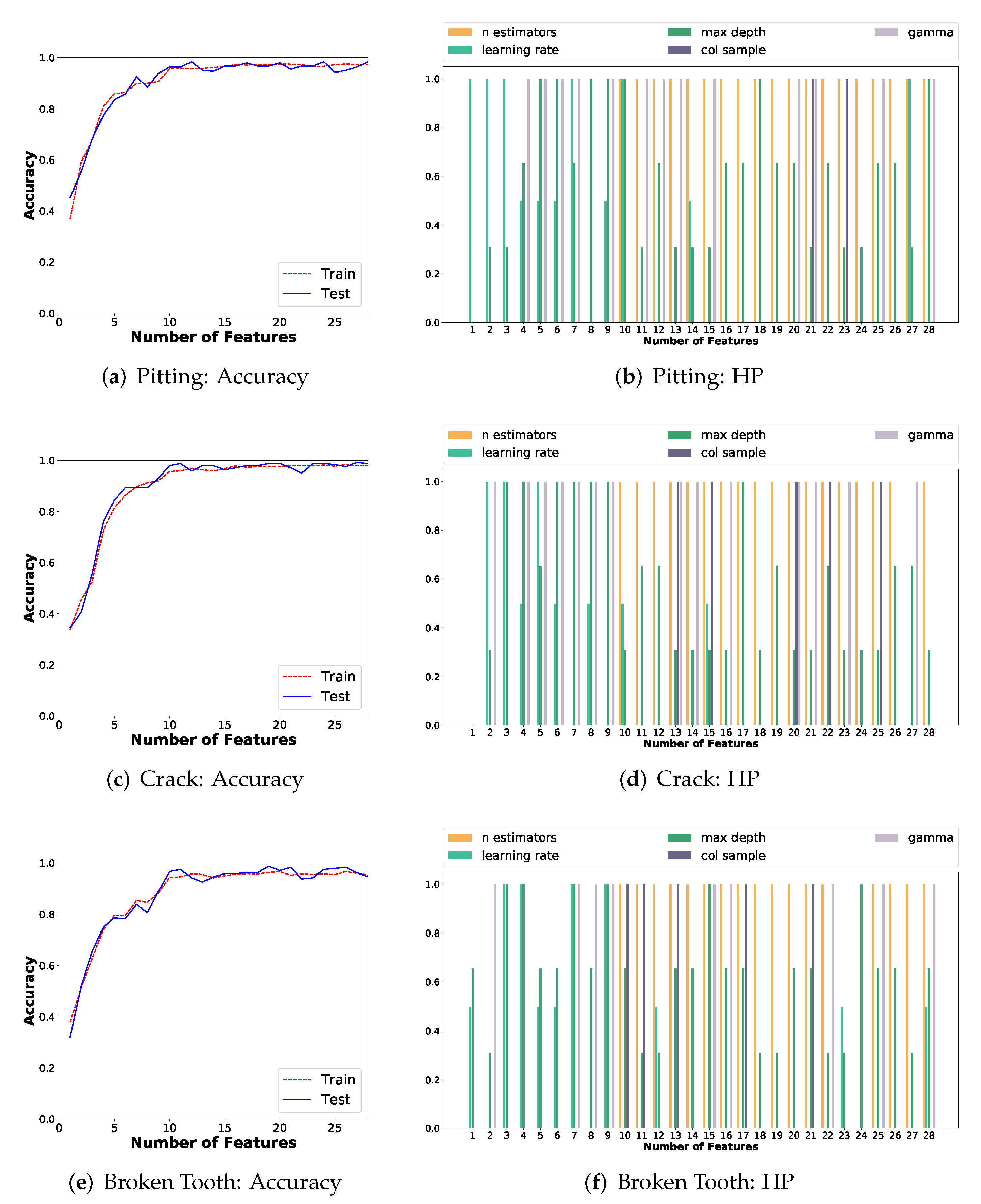
Time-domain statistical features are highly informative. This is verified by the fact that the feature engineering methods provided by the AutoML platforms do not substantially increase the classification accuracy of the ML pipelines. This particularity was identified because of the use of AutoML, and this discovery reduces the requirements of computing other complex features beyond the informative ones;
Classification accuracy over 90% is obtained with 10 features, and over 95% with more than 13 features, for each failure mode, when problem-specific features are selected based on the relative feature importance. The use of AutoML permitted to set the proper number of features, and this directly improves the generalization capability of the ML model for fault diagnosis;
Common features for all three failures modes can be selected based on average values of feature importance across all problems. These common features are highly informative as they achieve a classification accuracy over 96%. Moreover, the common set of features are ranked as highly informative for all problems by both AutoML systems. The analysis and use of the same set of features for all three failure modes has not been previously reported in the literature;
The accuracy of the classifiers obtained by AutoML are highly competitive with the state-of-the-art in this domain, reaching 96% of accuracy and even 99% in some failure modes. For comparison, accuracy by manual design of ML pipelines has been reported of up to 97% on the same datasets. This result verifies the power of the pipelines created from AutoML.
Future works can be focused on testing other AutoML platforms, like Neural Architecture Search (NAS) developed by Google DeepMind Team, to evaluate neural network architectures or a Bayesian approach, such as Auto-Sklearn [
82], for the case study presented in this work.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}