1. Introduction
It has frequently been argued that measured student performance in educational large-scale assessment (LSA; [
1,
2,
3]) studies is affected by test-taking strategies. In a recent paper that was published in the highly ranked
Science journal, researchers Steffi Pohl, Esther Ulitzsch and Matthias von Davier [
4] argue that “current reporting practices, however, they confound differences in test-taking behavior (such as working speed and item nonresponse) with differences in competencies (ability). Furthermore, they do so in a different way for different examinees, threatening the fairness of country comparisons” [
4]. Hence, the reported student performance (or, equivalently, student ability) is regarded by the authors as a conflated composite of a “true” ability and test-taking strategies. Importantly, Pohl et al. [
4] question the validity of country comparisons that are currently reported in LSA studies and argue for an approach that separates test-taking behavior (i.e., item response propensity and working speed) from a purified ability measure. The core idea of the Pohl et al. [
4] approach is on how to model missing item responses in educational large-scale assessment studies. In this article, we systematically investigate the consequences of different treatments of missing item responses in the programme for international student assessment (PISA) study conducted in 2018. Note that we do not focus on exploring or modeling test-taking strategies in this article.
While the treatment of missing data in statistical analyses in social sciences is now widely used [
5,
6,
7,
8], in recent literature, there are recommendations for treating missing item responses in item response theory (IRT; [
9]) models in LSA studies [
10,
11]. Typically, the treatment of item responses can be distinguished between calibration (computation of item parameters) and scaling (computation of ability distributions).
It is essential to distinguish the type of missing item responses. Missing item responses at the end of the test are referred to as not reached items, while missing items within the test are denoted as omitted items [
12]. Since the PISA 2015 study, not reached items are no longer scored as wrong and the proportion of not reached items is used as a predictor in the latent background model [
13]. Items that are not administered to students in test booklets in a multiple-matrix design [
13,
14,
15] lead to missingness completely at random (except in multi-stage adaptive testing; see [
16]). This kind of missingness is not the topic of this article and typically does not cause issues in estimating population and item parameters.
Several psychometricians have repeatedly argued that missing item responses should never be scored as wrong because such a treatment would produce biased item parameter estimates and unfair country rankings [
4,
10,
11,
17,
18]. In contrast, model-based treatments of missing item responses that rely on latent ignorability [
4,
10,
11,
19] are advocated. Missing item responses can be ignored in this approach when including response indicators and a latent response propensity [
20,
21]. Importantly, the missingness process is summarized by the latent response variable. As an alternative, multiple imputation at the level of items can be employed to handle missing item responses properly [
22,
23]. However, scoring missing item responses as wrong could be defended for validity reasons [
24,
25,
26]. Moreover, it has been occasionally argued that simulation studies cannot provide information on the proper treatment of missing item responses in a concrete empirical application because the truth is unknown that would have generated the data [
25,
27]. Nevertheless, simulation studies could be tremendously helpful in understanding and comparing competitive statistical modeling approaches.
Our findings might only be generalizable to other low-stakes assessment studies like PISA [
28,
29,
30]. However, the underlying mechanisms for missing item responses can strongly differ from high-stakes assessment studies [
31].
Although several proposals of using alternative scaling models for abilities in LSA studies like PISA have been made, previous work either did not report country means in the metric of interest [
10] such that consequences cannot be interpreted, or constituted only a toy analysis consisting only a few countries [
4] that did enable a generalization to operational practice. Therefore, this article compares different scaling models that rely on different treatments of missing item responses. We use the PISA 2018 mathematics dataset as a showcase. We particularly contrast the scoring of missing item responses as wrong with model-based approaches that rely on latent ignorability [
4,
10,
11] and a more flexible Mislevy-Wu model [
32,
33] containing the former two models as submodels. In the framework of the Mislevy-Wu model, it is tested whether the scoring of missing item responses as wrong or treating them as latent ignorable are preferred in terms of model fit. Moreover, it is studied whether the probability of responding to an item depends on the item response itself (i.e., nonignorable missingness, [
7]). In the most general model, the missingness process is assumed to be item format-specific. Finally, we investigate the variability across means from different models for a country.
The rest of the article is structured as follows. In
Section 2, an overview of different statistical modeling approaches for handling missing item responses is presented.
Section 3 contains an illustrative simulation study that demonstrates the distinguishing features of the different modeling approaches. In
Section 4, the sample of persons and items and the analysis strategy for the PISA 2018 mathematics case study are described. In
Section 5, the results of PISA 2018 mathematics are presented. Finally, the paper closes with a discussion in
Section 6.
2. Statistical Models for Handling Missing Item Responses
In this section, different statistical approaches for handling missing item responses are discussed. These different approaches are utilized in the illustrative simulation study (see
Section 3) and the empirical case study involving PISA 2018 mathematics data (see
Section 4).
For simplicity, we only consider the case of dichotomous items. The case of polytomous items only requires more notation for the description of models but does not change the general reasoning elaborated for dichotomous items. Let
denote the dichotomous item responses and the
response indicators for person
p and item
i. The response indicator
takes the value one if
is observed and zero if
is missing. Consistent with the operational practice since PISA 2015, the two-parameter logistic (2PL) model [
34] is used for scaling item responses [
13,
16]. The item response function is given as
where
denotes the logistic distribution function. The item parameters
and
are item discriminations and difficulties, respectively. It holds that
. Local independence of item responses is posed; that is, item responses
are conditionally independent from each other given the ability variable
. The latent ability
follows a standard normal distribution. If all item parameters are estimated, the mean of the ability distribution is fixed to zero and the standard deviation is fixed to one. The one-parameter logistic (1PL, [
35]) model is obtained if all item discriminations are set equal to each other.
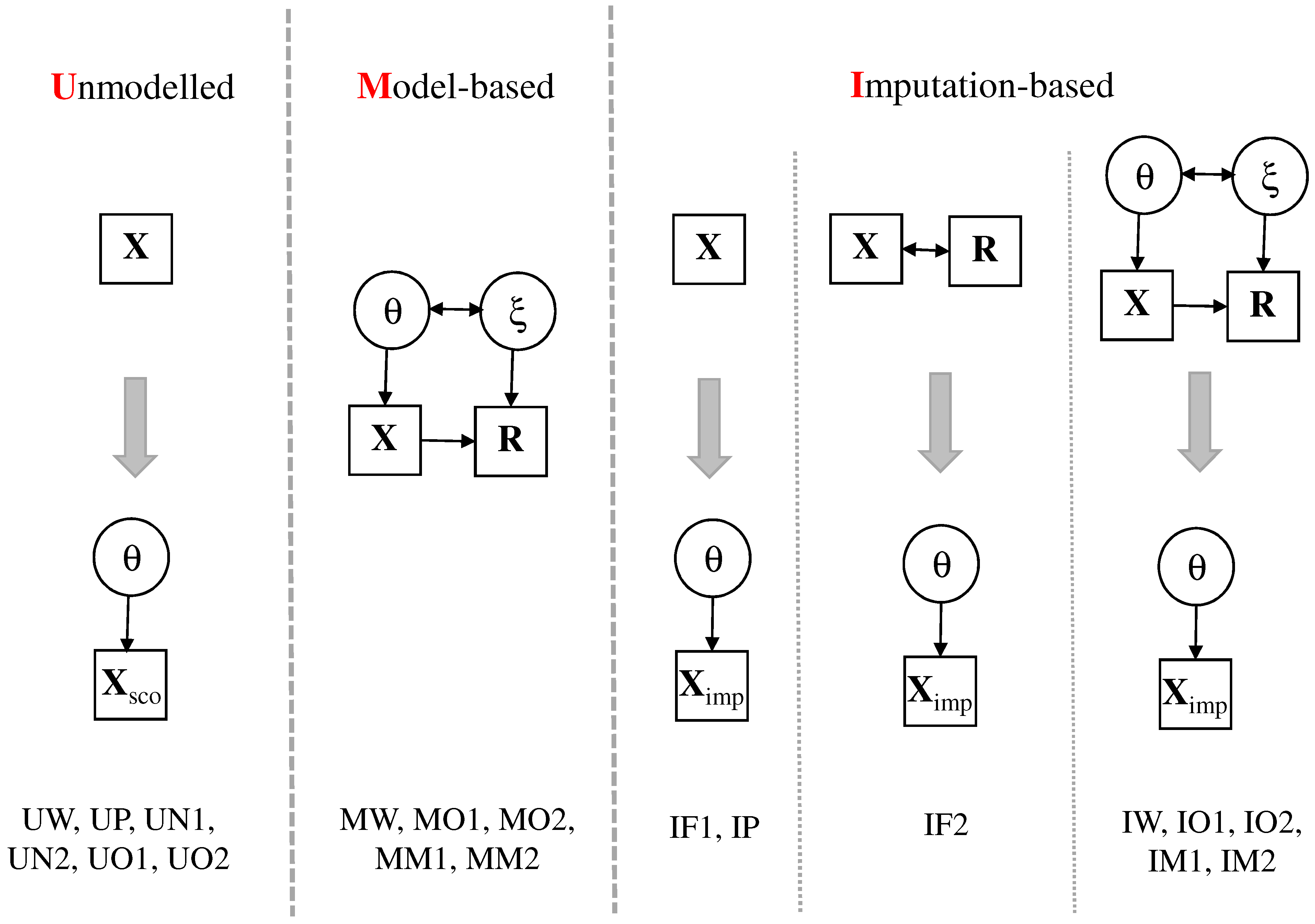
In
Figure 1, the main distinctive features of the different missing data treatments are shown. Three primary strategies can be distinguished [
36,
37]. These strategies differ in how to include information from the response indicator variables.
First, response indicators are unmodelled (using model labels starting with “U”), and missing entries in item responses are scored using some a priorily defined rule resulting in item responses without missing entries. For example, missing item responses can be scored as wrong or can be omitted in the estimation of the scaling model. In a second step, the 2PL scaling model is applied to the dataset containing scored item responses .
Second, model-based approaches (using model labels starting with “M”) pose a joint IRT model for item responses
and response indicators
[
19]. The 2PL scaling model for the one-dimensional ability variable
is part of this model. In addition, a further latent variable
(i.e., the so-called response propensity) is included that describes the correlational structure underlying the response indicators
. In most approaches discussed in the literature, there is no path from
to
. After controlling for ability
and response propensity
, there is no modeled effect of the item response on the response indicator. In this paper, we allow for this additional relation by using the Mislevy-Wu model and empirically demonstrate that missingness on items depends on the item response itself.
Third, imputation-based approaches (using model labels starting with “I”) first generate multiply imputed datasets and fit the 2PL scaling model to the imputed datasets in a second step [
37,
38]. Different imputation models can be employed. One can either use only the item responses
or use the item responses
and the response indicators
in the imputation model. As an alternative, imputations can be generated based on an IRT model that contains item responses
and missing indicators
. These imputation models can coincide with IRT models that are employed as model-based approaches in our overview. After fitting the IRT models for
, the output contains a posterior distribution
for each subject
p. For each imputed dataset, one first simulates latent variables
and
from the posterior distribution [
39]. For items with missing item responses (i.e.,
), one can simulate scores for
according to the conditional distribution
(
). It holds that
The 2PL scaling model is applied to the imputed datasets
in a second step. In the analyses of this paper, we always created 5 imputed datasets to reduce the simulation error associated with the imputation. We stack the 5 multiply imputed datasets into one long dataset and applied the 2PL scaling model for the stacked dataset (see [
40,
41,
42]). The stacking approach does not result in biased item parameter estimates [
41], but resampling procedures are required for obtaining correct standard errors [
40]. This article mainly focuses on differences between results from different models and does not investigate the accuracy of standard error computation methods based on resampling procedures.
In the next subsections, we describe the different models for treating missing item responses. These models differ with regards to the missingness mechanism assumptions of missing item responses. Some of the model abbreviations in
Figure 1 are already mentioned in this section. Models that only appear in the case study PISA 2018 mathematics are described in
Section 4.1.
2.1. Scoring Missing Item Responses as Wrong
In a reference model, we scored all missing item responses (omitted and not reached items) as wrong (model UW). The literature frequently argues that missing item responses should never be scored as wrong [
4,
10,
17,
43]. However, we think that the arguments against the scoring as wrong are flawed because these studies simulate missing item responses based on response probabilities that do not depend on the item itself. We think that these data-generating models are not plausible in applications (but see also [
44] for a more complex missing model; [
25,
26]). On the other hand, one can simulate missing item responses such that missing item responses can only occur for incorrectly solved items (i.e., for items with
). In this situation, all missing data treatments that do not score missing item responses as wrong will provide biased estimates [
27].
2.2. Scoring Missing Item Responses as Partially Correct
Missing responses for MC items can be scored as partially correct (also known as fractional correct item responses; see [
45]). The main idea is that a student could guess the MC item if he or she does not know the answer. If an item
i has
alternatives, a random guess of an item option would provide a correct response with probability
. In IRT estimation, one can weigh probabilities
with
and
with
[
45]. This weighing implements a scoring of a missing MC item as partially correct (model UP). The maximum likelihood estimation is replaced by a pseudo-likelihood estimation that allows non-integer item responses [
45]. More formally, the log-likelihood function
l for estimating item parameters
and
can be written as
where
f denotes the density of the standard normal distribution, and
N denotes the sample size. The entries
in the vector of scored item responses
can generally take values between 0 and 1. The EM algorithm typically used in estimating IRT models [
46,
47] only needs to be slightly modified for handling fractionally correct item responses. In the M-step for computing expected counts, one must utilize the fractional item responses instead of using only zero or one values. The estimation can be carried out in the R [
48] package sirt [
49] (i.e., using the function
rasch.mml2()).
It should be mentioned pseudo-likelihood estimation of IRT models that allow non-integer item responses is not widely implemented in IRT software. However, the partially correct scoring can be alternatively implemented by employing a multiple imputation approach of item responses. For every missing item response of item i, a correct item response is imputed with probability . No imputation algorithm is required because only random guessing is assumed. This means that the guessing probability of is constant for persons and items.
Missing item responses for CR items are scored as wrong in the partially correct scoring approach because students in this situation cannot simply guess unknown answers.
2.3. Treating Missing Item Responses as Ignorable
As an alternative to scoring missing item responses as wrong, missing item responses can be ignored in likelihood estimation. In model UO1, all missing item responses are ignored in the scaling model. The student ability
is extracted based on the observed item responses only. The log-likelihood function
l for this model can be written as
It can be seen from Equation (
4) that only observations with observed item responses (i.e.,
) contribute to the likelihood function.
The method UO1 is valid if missing item responses can be regarded as ignorable [
18]. If
is a partitioning of the vector of complete item responses into the observed and the missing part, the assumption that item responses are missing at random [
7] is given as
This means that the probability of omitting items only depends on observed items and not the unobserved item responses. By integrating out missing item responses
, the joint distribution
and using the MAR assumption (
5) can be written as
Hence, Equation (
6) shows that likelihood inference for MAR data can entirely rely on the probability distribution
of observed item responses. The notion of (manifest) ignorability means that model parameters of the distributions
and
are distinctive. This means that these distributions can be modeled independently.
It should be emphasized that the MAR assumption (
5) does not involve the latent ability
. The probability of missingness must be inferred by (summaries of) observed item responses only. This kind of missingness process might be violated in practice. In the following subsection, a weakened version of ignorability is discussed.
2.4. Treating Missing Item Responses as Latent Ignorable
Latent ignorability [
19,
50,
51,
52,
53,
54,
55,
56,
57,
58,
59,
60] is one of the weakest nonignorable missingness mechanisms. Latent ignorability weakens the assumption of ignorability for MAR data. In this case, the existence of a latent variable
is assumed. The dimension of
is typically much lower than the dimension of
. Latent ignorability is defined as (see [
19])
That is, the probability of missing item responses depends on observed item responses and the latent variable
, but not the unknown missing item responses
itself. By integrating out
, we obtain
The specification (
7) is also known as a shared-parameter model [
61,
62]. In most applications, conditional independence of item responses
and response indicators
conditional on
is assumed [
19]. In this case, Equation (
8) simplifies to
In the rest of this paper, it is assumed that the latent variable
consists of a latent ability
and a latent response propensity
. The latent response propensity
is a unidimensional latent variable that represents the dimensional structure of the response indicators
. The probability of responding to an item is given by (model MO2; [
10,
20,
44,
63,
64,
65,
66])
Note that the probability of responding to item
i only depends on
and is independent of
and
. The 2PL model is assumed for item responses
(see Equation (
1)):
The model defined by Equations (
10) and (
11) is also referred to as the Holman–Glas model [
20,
37]. In this article, a bivariate normal distribution for
is assumed, where
is fixed to one, and
, as well as
, are estimated (see [
67,
68] for more complex distributions).
The model UO1 (see
Section 2.3) that presupposes ignorability (instead of latent ignorability) can be tested as a nested model within model MO2 by setting
. This model is referred to as model MO1.
Note that the joint measurement model for item responses
and response indicators
can be written as
Hence, the model defined in Equation (
12) can be interpreted as an IRT model for a variable
that has three categories: Category 0 (observed incorrect):
,
, Category 1 (observed correct):
,
, and Category 2 (missing item response):
,
(see [
43,
69,
70]).
2.4.1. Generating Imputations from IRT Models Assuming
Latent Ignorability
The IRT models MO1 and MO2 are also used for generating multiply imputed datasets. Conditional on
, missing item responses are imputed according to the response probability from the 2PL model (see Equation (
11)). The stacked imputed dataset is scaled with the unidimensional 2PL model. If models MO1 or MO2 were be the true data-generating models, the results from multiple imputation (i.e., IO1 and IO2) would coincide with model-based treatments (i.e., MO1 and MO2). However, results can differ in the case of misspecified models [
71,
72].
2.4.2. Including Summaries of Response Indicators in the
Latent Background Model
The IRT model for response indicators
in Equation (
10) is a 1PL model. Hence, the sum score
is a sufficient statistic for the response propensity
[
73]. Then, the joint distribution can be written as
Instead of estimating a joint distribution
, a conditional distribution
can be specified in a latent background model (LBM; [
74,
75]). That is, one uses the proportion of missing item responses
as a predictor for
[
11,
12] and employs a conditional normal distribution
. This manifest variable
can be regarded as a proxy variable for the latent variable
. The resulting model is referred to as model UO2.
2.5. Mislevy-Wu Model for Nonignorable Item Responses
Latent ignorability characterizes only a weak deviation from an ignorable missing data process. It might be more plausible that the probability
of responding to an item depends on the observed or unobserved item response
itself [
76,
77,
78,
79,
80]. The so-called Mislevy-Wu model [
32,
33,
81,
82] extends the model MO2 (see Equation (
10)) that assumes latent ignorability to
In this model, the probability of responding to an item depends on the latent response propensity
and the item response
itself (see [
24,
25,
49,
81,
83,
84]). The parameter
governs the missingness proportion for
in the subgroup of persons with
, while the sum
represents the missingness proportion for persons with
. The unique feature of the Mislevy-Wu model is that the missingness proportion is allowed to depend on the item response. If a very small negative value for the missingness parameter
is chosen (e.g.,
), the response probability
in Equation (
14) is close to one, meaning that persons with
always provide item response (i.e., they have a missing proportion of zero). By applying the Bayes theorem, it follows in this case that persons with a missing item response must possess an incorrectly solved item; that is, it holds
. It should be emphasized that the Mislevy-Wu model is a special case of models discussed in [
85].
Model MM1 is defined by assuming a common
parameter for all items. In model MM2, two
parameters are estimated for item formats CR and MC in the PISA 2018 mathematics case study (see
Section 5 for results).
Note that the Mislevy-Wu model for item responses
and response indicators
can be also formulated as a joint measurement model for a polytomous item with three categories 0 (observed incorrect), 1 (observed correct), and 2 (missing; see also Equation (
12)):
The most salient property of the models MM1 and MM2 is that the model treating missing item responses as wrong (model UW) can be tested by setting
in Equation (
14) (see [
33]). This model is referred to as model MW and the corresponding scaling model based on multiply imputed datasets from MW as model IW. Moreover, the model MO2 assuming latent ignorability is obtained by setting
for all items
i (see Equation (
10)). It has been shown that parameter estimation in the Mislevy-Wu model and model selection among models MW, MO2, and MM1 based on information criteria have satisfactory performance [
33].
For both models, multiply imputed datasets were also created based on conditional distributions . The scaling models based on stacked imputed datasets are referred to as IM1 and IM2.
2.6. Imputation Models Based on Fully Conditional Specification
The imputation models discussed in previous subsections are based on unidimensional or two-dimensional IRT models (see [
36,
86,
87,
88,
89] for more imputation approaches relying on strong assumptions). Posing such a strict dimensionality assumption might result in invalid imputations because almost all IRT models in educational large-scale assessment studies are likely to be misspecified [
26]. Hence, alternative imputation models for missing item responses were considered that relied on fully conditional specification (FCS; [
41]) implemented in the R package mice [
90].
The FCS imputation algorithm operates as follows (see [
41,
91,
92,
93]). Let
denote the vector of variables that can have missing values. FCS cycles through all variables in
(see [
37,
94,
95,
96]). For variable
, all remaining variables in
except
are used as predictors for
(denotes as
) in the imputation model. More formally, a linear regression model
is specified. For dichotomous variables
, (
16) might be replaced by a logistic regression model. Our experiences correspond with those from the literature that using a linear regression with predictive mean matching (PMM; [
41,
97,
98,
99]) provides more stable estimates of the conditional imputation models. PMM guarantees that imputed values only take values that are present in the observed data (i.e., values of 0 or 1 for dichotomous item responses).
In situations with many items,
is a high-dimensional vector of covariates in the imputation model (
16). To provide a stable and efficient estimation of the imputation model, a dimension reduction method for the vector of covariates can be applied to enable a feasible estimation. For example, principal component analysis [
100] or sufficient dimension reduction [
101] can be applied in each imputation model for reducing the dimensionality of
. In this paper, partial least squares (PLS) regression [
102] is used for transforming the vector of covariates to a low-dimensional vector of PLS factors that successively maximize the covariance with the criterion variable (i.e., maximize the covariance
with factor loading vectors
for uncorrelated factors
with
; see [
103]). In the simulation study and the empirical case study, we use 10 PLS factors to avoid the curse of dimensionality due to estimating too many parameters in the regression models [
103,
104].
In the imputation model IF1, only item responses
are included. This specification will provide approximately unbiased estimates if the MAR assumption (i.e., manifest ignorability) holds. In model IF2, response indicators
are additionally included [
105]. This approach is close to the assumption of latent ignorability in which summaries of the response indicators are also required for predicting the missingness of an item response. Hence, it can be expected that the model IF2 outperforms IF1 and provides similar results to the model MO2 relying on latent ignorability. In contrast to the Mislevy-Wu model, for imputing item response
in model IF2, the predictors
and
are used. Hence, the probability of responding to an item is not allowed to depend on the item itself. This assumption might be less plausible than assuming the response model in Equation (
14).
Like for all imputation-based approaches in this paper, 5 multiply imputed datasets were created, and the 2PL scaling model is applied to the stacked dataset involving all imputed datasets.
3. Illustrative Simulation Study
In order to better understand the relations between different models for the treatment of missing item responses, we performed a small illustrative simulation study to provide insights into the behavior of the most important models under a variety of data-generating models.
3.1. Method
We restrict ourselves to the analysis of only one group. This does not imply interpretational issues because the main motivation of this study is to provide a better insight into the behavior of the models and not to mimic the PISA application involving 45 countries. We only employed a fixed number of items in a linear fixed test design. Hence, we did not utilize a multi-matrix design with random allocation of students to test booklets as implemented in PISA. In our experience, we have not (yet) seen any simulation study whose results with a multi-matrix test design substantially differ from a linear fixed test design. We chose a sample size of , which corresponds to a typical sample size at the item level in the PISA application.
Item responses were generated based on the Mislevy-Wu model (see Equation (
10)). Item responses were simulated according to the 2PL model. We fixed the correlation of the latent ability
and the latent response propensity
to 0.5. We assumed item difficulties that were equidistantly chosen on the interval
(i.e.,
, −1.789, −1.579, …, 1.789, 2.000), and we used item discriminations of 1 when simulating data. The ability variable
was assumed to be standard normally distributed. For the response mechanism in the Mislevy-Wu model in Equation (
10), we varied a common missingness parameter
in five factor levels −10, −3,
, −1, and 0. The case
effectively corresponds to the situation in which missing item responses can only be produced by incorrect item responses. This simulation condition refers to the situation in which missing item responses must be scored as wrong for obtaining unbiased statistical inference. The situation
corresponds to the situation of latent ignorability. The cases
correspond to situations in which both the scoring as wrong and latent ignorability missing data treatment are not consistent with the data-generating model, and biased estimation can be expected. For the model for response indicators, we used a common
parameter across items in the simulation. As our motivation was to vary the average proportion of missing item responses (i.e., the factor levels were
,
,
, and
), the common
parameter is a function of the
parameter. Prior to the main illustrative simulation, we numerically determined the
parameter to obtain the desired missing data proportion rate (see
Table A1 in
Appendix A for the specific values used).
Seven analysis models were utilized in this simulation study. First, we evaluated the performance of the 2PL model for complete data (model CD). Second, we estimated the Mislevy-Wu model assuming a common missingness parameter
(model MM1;
Section 2.5). Third, we applied the method of scoring of missing items as wrong in model UW. Fourth, in contrast to UW, missing item responses were ignored in the estimation in model UO (
Section 2.3). Fifth, we estimated the model with response propensity
relying on latent ignorability (model MO2,
Section 2.4). Furthermore, two imputation-based approaches were used that rely on the fully conditional specification approach implemented in the R package mice [
90]. For both approaches, five multiply imputed datasets were utilized, and the 2PL models were estimated by using a stacked dataset containing all five imputed datasets. Sixth, the model IF1 uses item responses in the imputation approach that employs PMM. Seventh, the model IF2 uses item responses and response indicators in the imputation model. To avoid multicollinearity issues, PLS imputation with 10 PLS factors was applied for models IF1 and IF2.
The 2PL analysis models provided item difficulties and item discriminations and fixed the ability distribution to the standard normal distribution. To enable a comparison of the estimated mean and the standard deviation with the mean and the standard deviation of the data-generating model, estimated item parameters were linked to the true item parameters used in the data-generating model. As a result, a mean and a standard deviation as a result of the linking procedure is compared to the true mean (i.e., M = 0) and the true standard deviation (SD = 1). In this simulation, we applied Haberman linking [
106,
107] that is equivalent to log-mean-mean linking for two groups [
108]. Note that we use Haberman linking for multiple groups (i.e., multiple countries) in the case study in
Section 4.
A total number of 500 replications was carried out for each cell of the design. We evaluated bias and root mean square error (RMSE) for the estimated mean and standard deviation. We also assessed Monte Carlo standard errors for bias, and RMSE are calculated based on the jackknife procedure [
109,
110]. Twenty jackknife zones were defined for the computing of the Monte Carlo standard errors.
In this illustrative simulation study, the statistical software R [
48] along with the packages mice [
90] and sirt [
49] are used.
3.2. Results
In
Table 1, the bias for the mean and the standard deviation for different missing data treatments as a function of the missing proportion and the missingness parameter
is shown. In the case of complete data (CD), no biases exist. Except for the situation of a large proportion of missing item responses of
and an extreme
parameter of
(bias = 0.054), the Mislevy-Model (model MM1)—that is consistent with the data-generating model—performed very well in terms of bias for the mean and the standard deviation. If missing data were only caused by wrong items (i.e.,
), models that rely on ignorability (UO, IF1) or latent ignorability (MO2, IF2) produced large biases (e.g., for the mean in the condition of 10% missing data UO 0.159, MO2 0.149, IF1 0.160, IF2 0.152). As was to be expected in this case, scoring missing item responses as wrong provided unbiased results. In contrast, if the data-generating model relied on latent ignorability (i.e.,
), scoring missing item responses as wrong provided biased estimates (e.g., for the mean for 10% missing data, the bias was −0.139). Note that in this condition, MO2 and IF2 provided unbiased estimates, while the models that did not take response indicators into account provided biased estimates (e.g., for the mean for 10% missing data: UO 0.037, IF1 0.038).
For values of the missingness parameter between and 0, both missing data treatments as wrong and latent ignorable provided biased estimates for the mean. The biases were much more pronounced for higher missing data proportions. Moreover, the standard estimation is substantially underestimated when relying on a model for latent ignorability if the latent ignorability was not used for simulating item responses. Interestingly, the imputation model IF2 that uses both item responses and response indicators showed similar behavior to the model MO2 that involves the latent response propensity , while the imputation model IF1 only using item responses performed similarly to UO. The standard deviation was underestimated in many conditions for the models assuming latent ignorability if the Mislevy-Wu model holds.
The Monte Carlo standard errors for the bias of the mean (M = 0.0023, SD = 0.0005, Max = 0.0044) were similar to those of the standard deviation (M = 0.0022, SD = 0.0005, Max = 0.0038). The uncertainty in the bias estimates is negligible to the variation across different missing data treatments. Hence, the conclusions obtained from this simulation study can be considered trustworthy.
In
Table A2 in
Appendix A, the RMSE for the mean and the standard deviation for the different missing data treatments are shown as a function of the missing data proportion and the missingness parameter
. In situations where the models UW or MO2 provided unbiased estimates, the Mislevy-Wu model MM1 has slightly larger variable estimates. However, only in these particular situations, the RMSE of the simpler restrictive models was smaller than those of MM1. In general situations, the increase in variability was outperformed by a lower bias of model MM1. The Monte Carlo standard error for the RMSE of the mean was on average 0.0023 (SD = 0.0006, Max = 0.0044). The corresponding Monte Carlo error for the RMSE of the standard deviation turned out to be quite similar (M = 0.0023, SD = 0.0007, Max = 0.0042).
3.3. Summary
In this illustrative simulative study, we showed that one could not generally conclude that missing items must never be scored wrong. Moreover, models that treat missing item responses as latent ignorable do not guarantee a smaller bias compared to the scoring as wrong. In general, the scoring as wrong can provide negatively biased mean estimates, while the treatment as latent ignorable will typically provide positively biased estimates.
As with any simulation study, the data-generating truth must be known in advance which is not the case in any empirical application. The Mislevy-Wu model is a general model for treating nonignorable missing item responses. It certainly has the potential to provide less biased estimates than alternatives recently discussed in the literature.
6. Discussion
In this paper, competing approaches for handling missing item responses in educational large-scale assessment studies like PISA are investigated. We compared the Mislevy-Wu model that allows the probability of item missingness depending on the item itself with the more frequently discussed approaches of scoring items as wrong or models assuming latent ignorability. In an illustrative simulation study, we demonstrated that neither of the two latter approaches provides unbiased parameter estimates if the more general Mislevy-Wu model holds (see also [
44]). In realistic data constellations in which the Mislevy-Wu model holds, it is likely that the method of scoring missing item responses as wrong results in underestimated (country) means, while models relying on latent ignorability provide overestimated means. Based on these findings, we are convinced that the often-taken view in psychometric literature that strongly advocates latent ignorability and denies the scoring as wrong [
4,
11,
12,
18] is unjustified (see also [
24,
25,
27]).
In our reanalysis of the PISA 2018 mathematics data, different scaling models with different treatments of missing item responses were specified. It has been shown that differences in country means and country standard deviations across models can be substantial. The present study sheds some light on the ongoing debate about properly handling missing item responses in educational large-scale assessment studies. Ignoring missing item responses and treating them as wrong can be seen as opposing strategies. Other scaling models can be interpreted to provide results somewhere between these two extreme poles of handling missingness. We argued that the Mislevy-Wu model contains the strategy of scoring as wrong and the latent ignorable model as submodels. Hence, these missing data treatments can be tested. In our analysis, it turned out that the Mislevy-Wu model fitted the PISA data best. More importantly, the treatment of missing item responses as wrong provided a better model fit than ignoring them or modeling them by the latent ignorable model that has been strongly advocated in the past [
10,
11]. It also turned out that the missingness mechanism strongly differed between CR and MC items.
We believe that the call for controlling for test-taking behavior in the reporting in large-scale assessment studies such as response propensity [
4] using models that also include response times [
157,
158] poses a threat to validity [
159,
160,
161,
162,
163,
164] because results can be simply manipulated by instructing students to omit items they do not know [
26]. Notably, missing item responses are mostly omissions for CR items. Response times might be useful for detecting rapid guessing or noneffortful responses [
81,
165,
166,
167,
168,
169,
170,
171]. However, it seems likely that students who do not know the solution to CR items do not respond to these items. In this case, the latent ignorability assumption is unlikely to hold, and scaling models that rely on it (see [
4,
12]) will result in biased and unfair country comparisons. We are skeptical that the decision of whether a missing item response is scored as wrong should be based on a particular response time threshold [
166,
172,
173]. Students can also be simply instructed to quickly skip items that they are not probably able to solve.
In our PISA analysis, we restricted the analysis to 45 countries that received booklets of average item difficulty. Recently, a number of low-performing countries also participated in recent PISA cycles that receive booklets of lower difficulty [
174,
175,
176]. We did not include these low-performing countries for the following reasons. First, the proportion of correctly solved items for low-performing countries is lower. This implies that it is more difficult for these countries to disentangle the parameters of the model for response indicators and item parameters. Second, the meaning of missingness on item responses across countries differs if different booklets are administered in countries. Hence, it is difficult to compare outcomes of different scaling models for the missing data treatment if there is no prerequisite of the same administered test design. To some extent, the issue also appears in the recently implemented multi-stage testing (MST; [
177,
178]) design in PISA that also results in different proportions of test booklets of different average difficulty across countries. We think that there is no defensible strategy of properly treating missing item responses from MST designs that enables a fair and valid comparison of countries [
26].
In this article, we only investigated the impact of missing item responses on country means and country standard deviations. In LSA studies, missing data is also a prevalent issue for student covariates (e.g., sociodemographic status; see [
104,
179,
180,
181,
182,
183,
184]). As covariates also enter the plausible value imputation of latent abilities through the latent background model [
75,
129] or relationships of abilities and covariates are often of interest in reporting, missing data on covariates is also a crucial issue that needs to be adequately addressed [
104].
It could be argued that there is not a unique, scientifically sound, or widely publicly accepted scaling model in PISA (see [
185]). The uncertainty in choosing a psychometric model can be reflected by explicitly acknowledging the variability of country means and standard deviations obtained by different model assumptions. This additional source of variance associated with model uncertainty [
186,
187,
188,
189,
190,
191] can be added to the standard error due to the sampling of students and linking error due to the selection of items [
192]. The assessment of specification uncertainty has been discussed in sensitivity analysis [
193] and has recently become popular as multiverse analysis [
194,
195] or specification curve analysis [
196,
197]. As educational LSA studies are policy-relevant [
198,
199], we think that model uncertainty should be included in statistical inference [
200,
201].




{kind=link}
{kind=link}

