
Deep-Sequence–Aware Candidate Generation for e-Learning System

Abstract
:1. Introduction
Deep Learning-Based Recommendations
2. Related Work
Heterogeneous Candidate Generation
3. Proposed Methodology
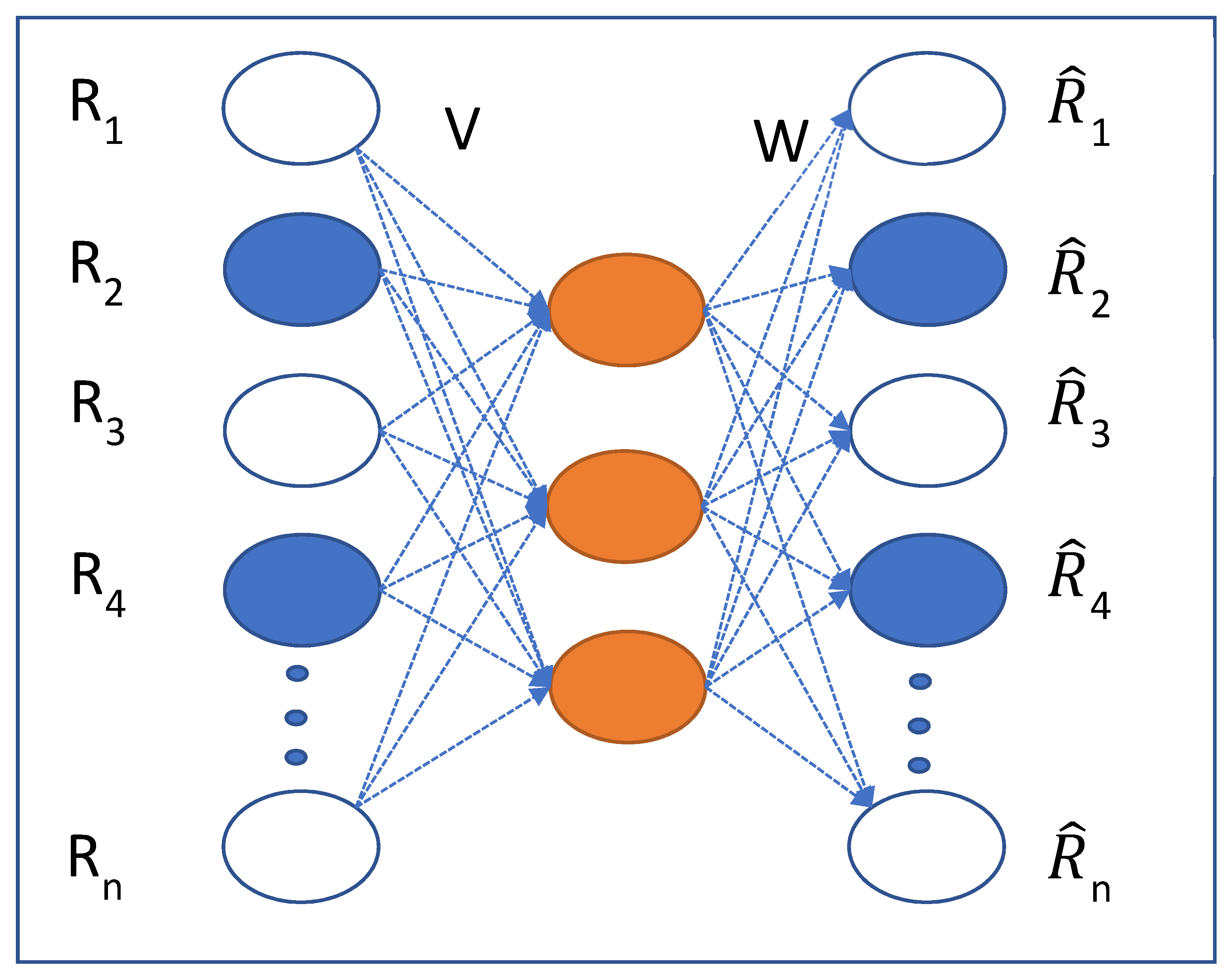
3.1. Sequence-Aware Embedding
3.2. Content Data
3.3. Deep Network
3.4. Network Optimization
- Select an initial array ofand learning rate
- Repeat until an approximate minimum is calculated:
- Randomly shuffle examples in the training set:
- ○
- For i = 1,2,…, n, do:
- ∎
4. Experimental Results
4.1. Experimental Setup
4.1.1. Datasets
Ubob.com Dataset
MovieLens 20M Dataset
4.1.2. Implementation Environment
4.2. Performance of the Proposed Model
4.2.1. Training
4.2.2. Prediction Accuracy
- YouTube model: Proposed by Covington et al. [10], this method uses continuous and categorical features to recommend items by ignoring the sequence data of user history.
- AutoRec: The model [20] attempts to exploit user preference data for items to provide personalized recommendations based on the autoencoder concept.
- Deep interest network: Developed by Zhou et al. [23], deep networks map the historical behaviors of users into low-dimensional embedding vectors to learn nonlinear relations among features to predict the click-through rate.
- DDPG (Tag-aware) model: Designed by Zhiruo Zhao et al. [24], the model is a tag-aware recommender system based on deep reinforcement learning without complex function design, taking advantage of tags to make up for the interpretability problems existing in the recommender system.
4.2.3. Dealing with the User Cold-Start Issue
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Kutlimuratov, A.; Abdusalomov, A.; Whangbo, T.K. Evolving Hierarchical and Tag Information Via the Deeply Enhanced Weighted Non-Negative Matrix Factorization of Rating Predictions. Symmetry 2020, 12, 1930. [Google Scholar] [CrossRef]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix factorization techniques for recommender systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Fang, Y.; Si, L. Matrix co-factorization for recommendation with rich side information and implicit feedback. In Proceedings of the 2nd International Workshop on Information Heterogeneity and Fusion in Recommender Systems, Chicago, IL, USA, 23–27 October 2011; pp. 65–69. [Google Scholar]
- Ricci, F.; Rokach, L.; Shapira, B.; Kantor, P.B. Recommender Systems Handbook; Springer: Berlin, Germany, 2011; ISBN 978-0-387-85819-7. [Google Scholar]
- Bobadilla, J.; Ortega, F.; Hernando, A.; Gutiérrez, A. Recommender systems survey. Knowl. Based Syst. 2013, 46, 109–132. [Google Scholar] [CrossRef]
- Wang, J.; de Vries, A.P.; Reinders, M.J.T. Unifying User-based and Item-based Collaborative Filtering Approaches by Similarity Fusion. In Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Seattle, WA, USA, 6–11 August 2006; pp. 501–508. [Google Scholar]
- Su, X.; Khoshgoftaar, T.M. A survey of collaborative filtering techniques. Adv. Artif. Intell. 2009, 2009, 1–19. [Google Scholar] [CrossRef]
- Zheng, L.; Lu, C.-T.; He, L.; Xie, S.; He, H.; Li, C.; Noroozi, V.; Dong, B.; Yu, P.S. MARS: Memory Attention-Aware Recommender System. In Proceedings of the 2019 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Washington, DC, USA, 5–8 October 2019; pp. 11–20. [Google Scholar]
- Ruining, H.; Julian, J. VBPR: Visual bayesian personalized ranking from implicit feedback. In Proceedings of the AAAI-16 Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Covington, P.; Adams, J.; Sargin, E. Deep neural networks for youtube recommendations. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 191–198. [Google Scholar]
- Deshpande, M.; Karypis, G. Item-based top-N recommendation algorithms. ACM Trans. Inf. Syst. 2004, 22, 143–177. [Google Scholar] [CrossRef]
- Schein, A.I.; Popescul, A.; Ungar, L.H.; Pennock, D.M. Methods and metrics for cold-start recommendations. In Proceedings of the 25th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, New York, NY, USA, 11–15 August 2002; pp. 253–260. [Google Scholar]
- Lam, X.N.; Vu, T.; Le, T.D.; Duong, A.D. Addressing cold-start problem in recommendation systems. In Proceedings of the 2nd International Conference on Ubiquitous Information Management and Communication; Suwon, Korea, 31 January–1 February 2008, ACM: New York, NY, USA, 2008; pp. 208–211. [Google Scholar]
- Agrawal, R.; Srikant, R. Mining sequential patterns. In Proceedings of the 11th International Conference on Data Engineering (ICDE), Taipei, Taiwan, 6–10 March 1995; pp. 3–14. [Google Scholar]
- Mobasher, B.; Dai, H.; Luo, T.; Nakagawa, M. Using sequential and non-sequential patterns in predictive Web usage mining tasks. In Proceedings of the 2002 IEEE International Conference on Data Mining, Maebashi City, Japan, 9–12 December 2002; pp. 669–672. [Google Scholar] [CrossRef]
- Yu, H.; Riedl, M.O. A sequential recommendation approach for interactive personalized story generation. In Proceedings of the 11th International Conference on Autonomous Agents and Multiagent Systems, Valencia, Spain, 4–8 June 2012. [Google Scholar]
- Zhao, G.; Lee, M.L.; Hsu, W.; Chen, W. Increasing temporal diversity with purchase intervals. In Proceedings of the 35th international ACM SIGIR conference on Research and development in information retrieval, Portland, OR, USA, 12–16 August 2012. [Google Scholar]
- Qiao, Z.; Zhang, P.; Cao, Y.; Zhou, C.; Guo, L.; Fang, B. Combining Heterogenous Social and Geographical Information for Event Recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014; pp. 165–174. [Google Scholar] [CrossRef]
- Bao, Y.; Fang, H.; Zhang, J. TopicMF: Simultaneously Exploiting Ratings and Reviews for Recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014. [Google Scholar]
- Sedhain, S.; Menon, A.K.; Sanner, S.; Xie, L. AutoRec: Autoencoders Meet Collaborative Filtering. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 111–112. [Google Scholar]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Janvin, C. A Neural Probabilistic Language Model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L. BPR: Bayesian Personalized Ranking from Implicit Feedback. arXiv 2012, arXiv:1205.2618. [Google Scholar]
- Zhou, G.; Zhu, X.; Song, C.; Fan, Y.; Zhu, H.; Ma, X.; Yan, Y.; Jin, J.; Li, H.; Gai, K. Deep Interest Network for Click-Through Rate Prediction. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1059–1068. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Z.; Chen, X.; Xu, Z.; Cao, L. Tag-Aware Recommender System Based on Deep Reinforcement Learning. Math. Probl. Eng. 2021, 2021, 5564234. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classification | Details |
|---|---|
| OS | Windows 10 |
| Programming Language | Python (Keras-Anaconda), TensorFlow |
| CPU | Intel(R) core (TM) Core i7-7700 |
| RAM | 16.00 GB |
| Course Name | Similarity |
|---|---|
| Real Estate Broker_Civil Act and Special Civil Act) | 0.737 |
| Real Estate Broker_Real Estate Disclosure Act | 0.697 |
| Real Estate speciality | 0.549 |
| Real Estate Agent_Real Estate Act | 0.533 |
| Model | Ubob.Com Dataset | MovieLens 20M | ||
|---|---|---|---|---|
| Precision 1 | Precision 5 | Precision 10 | MAE | |
| YouTube model | 0.593 | 0.461 | 0.294 | 0.6471 |
| Proposed deep-sequence–aware model | 0.599 | 0.482 | 0.358 | 0.6328 |
| AutoRec | 0.309 | 0.213 | 0.175 | 0.6854 |
| Deep interest network | 0.32 | 0.254 | 0.197 | 0.7086 |
| DDPG (Tag-aware) | - | - | - | 0.7143 |
| Model | Ubob.Com Dataset | MovieLens 20M | |
|---|---|---|---|
| MAE of 25 Cold-Start Users | MAE of 50 Cold-Start Users | MAE of 50 Cold-Start Users | |
| YouTube model | 0.651 | 0.721 | 0.6987 |
| Proposed deep-sequence–aware model | 0.637 | 0.685 | 0.6901 |
| AutoRec | 0.753 | 0.802 | 0.7458 |
| Deep interest network | 0.749 | 0.787 | 0.7136 |
| DDPG (Tag-aware) | - | - | 0.7044 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ilyosov, A.; Kutlimuratov, A.; Whangbo, T.-K. Deep-Sequence–Aware Candidate Generation for e-Learning System. Processes 2021, 9, 1454. https://doi.org/10.3390/pr9081454
Ilyosov A, Kutlimuratov A, Whangbo T-K. Deep-Sequence–Aware Candidate Generation for e-Learning System. Processes. 2021; 9(8):1454. https://doi.org/10.3390/pr9081454
Chicago/Turabian StyleIlyosov, Aziz, Alpamis Kutlimuratov, and Taeg-Keun Whangbo. 2021. "Deep-Sequence–Aware Candidate Generation for e-Learning System" Processes 9, no. 8: 1454. https://doi.org/10.3390/pr9081454