
Fast and Versatile Chromatography Process Design and Operation Optimization with the Aid of Artificial Intelligence


Abstract
:1. Introduction
2. Material and Methods
2.1. Modeling
2.2. Dataset Generation
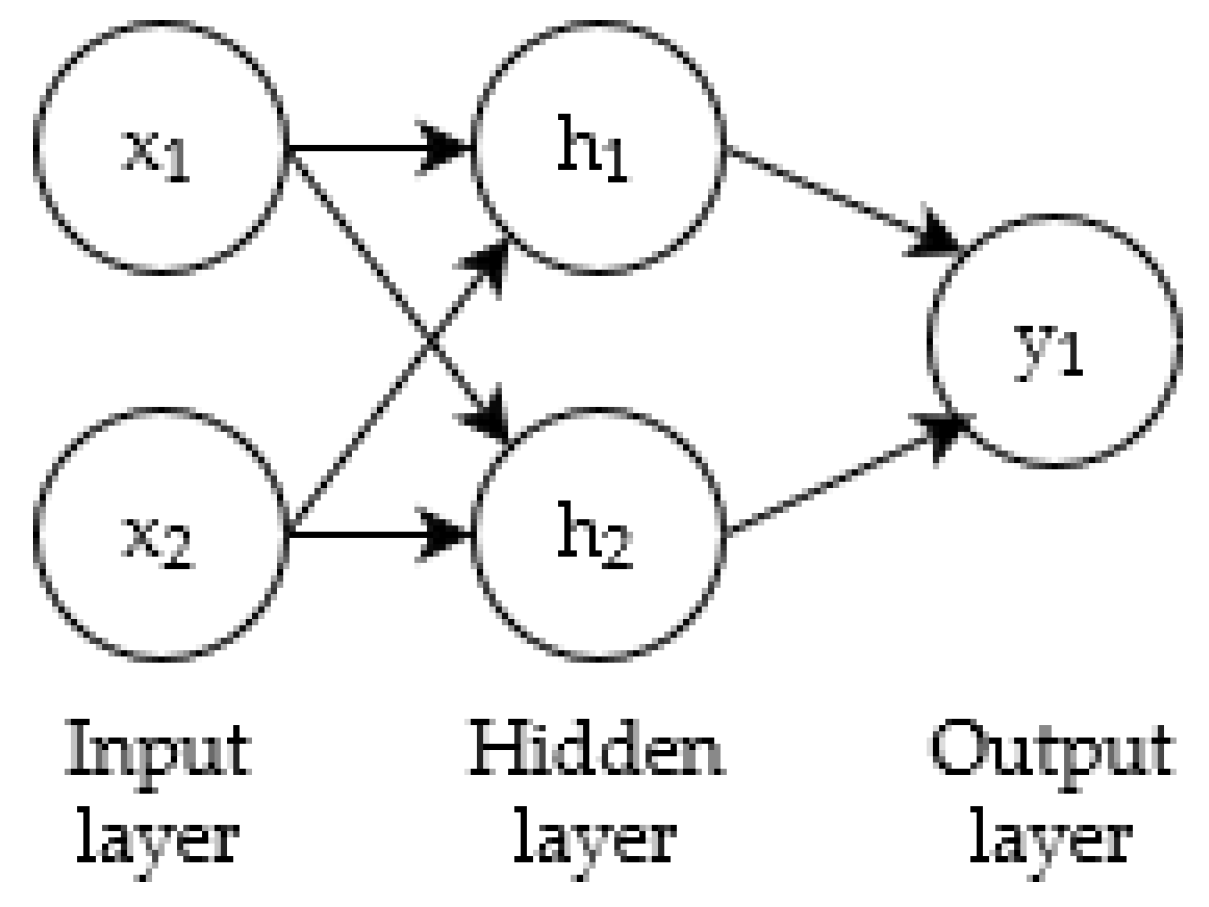
2.3. Artificial Neural Network
3. Results and Discussion
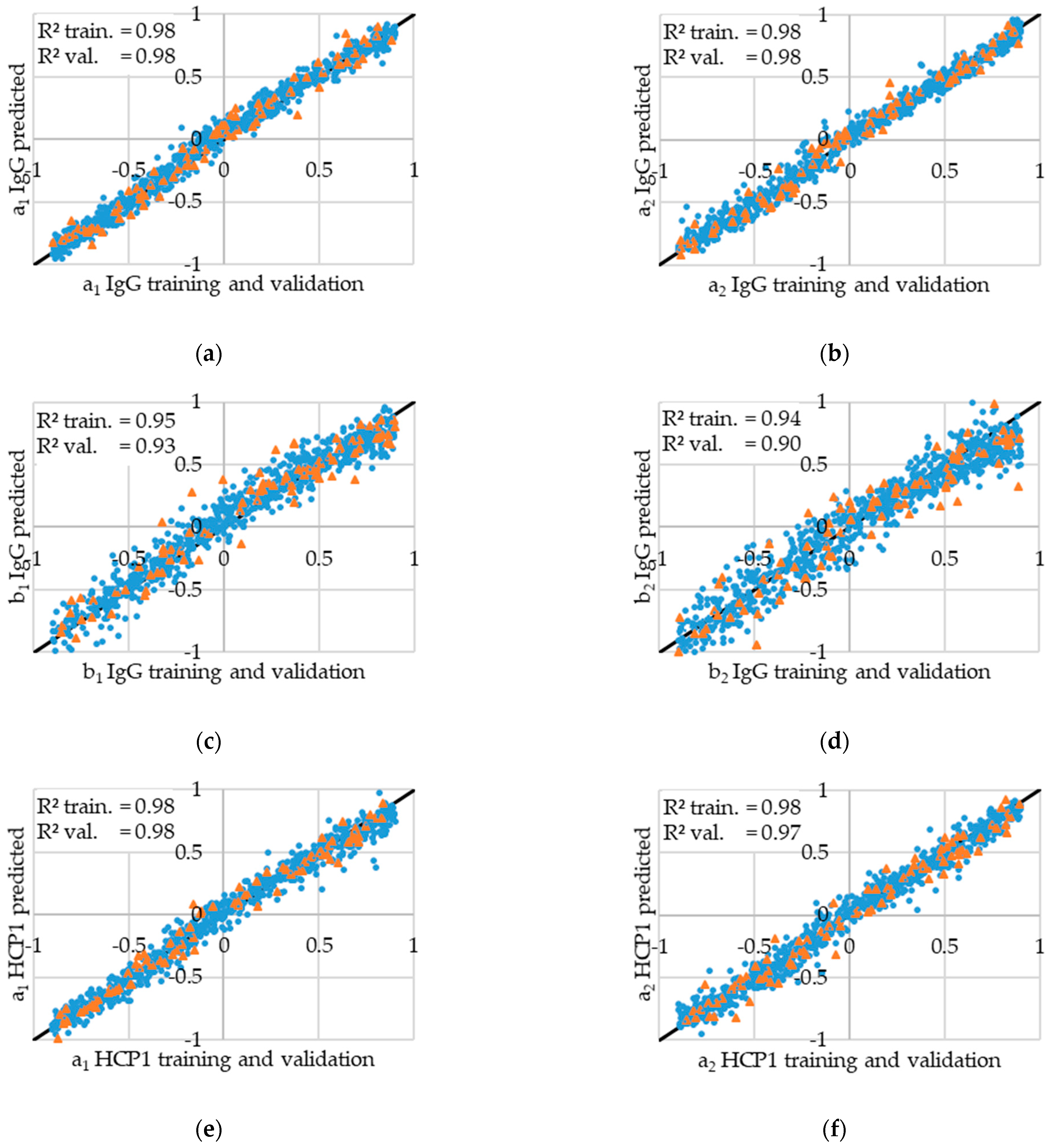
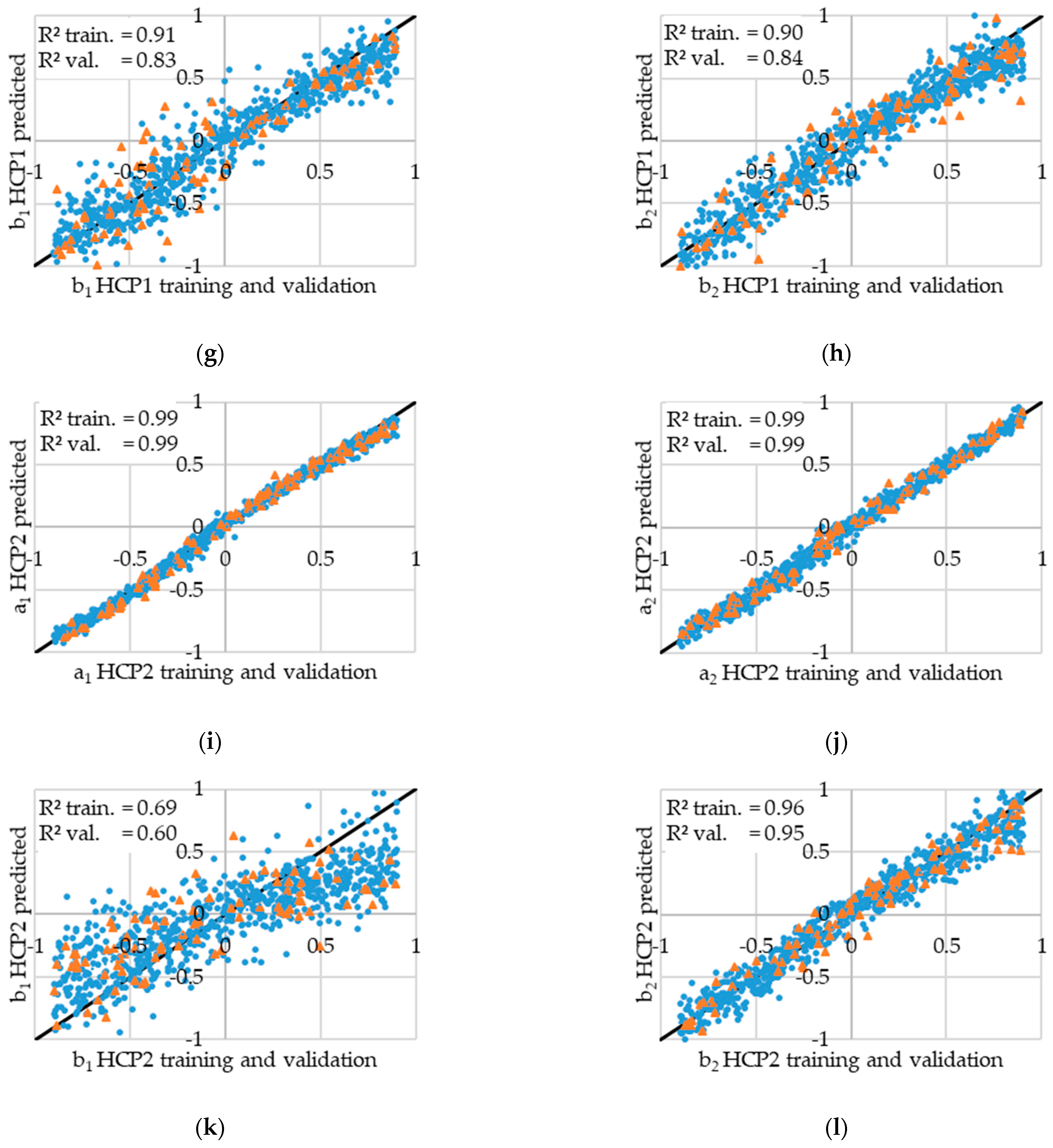
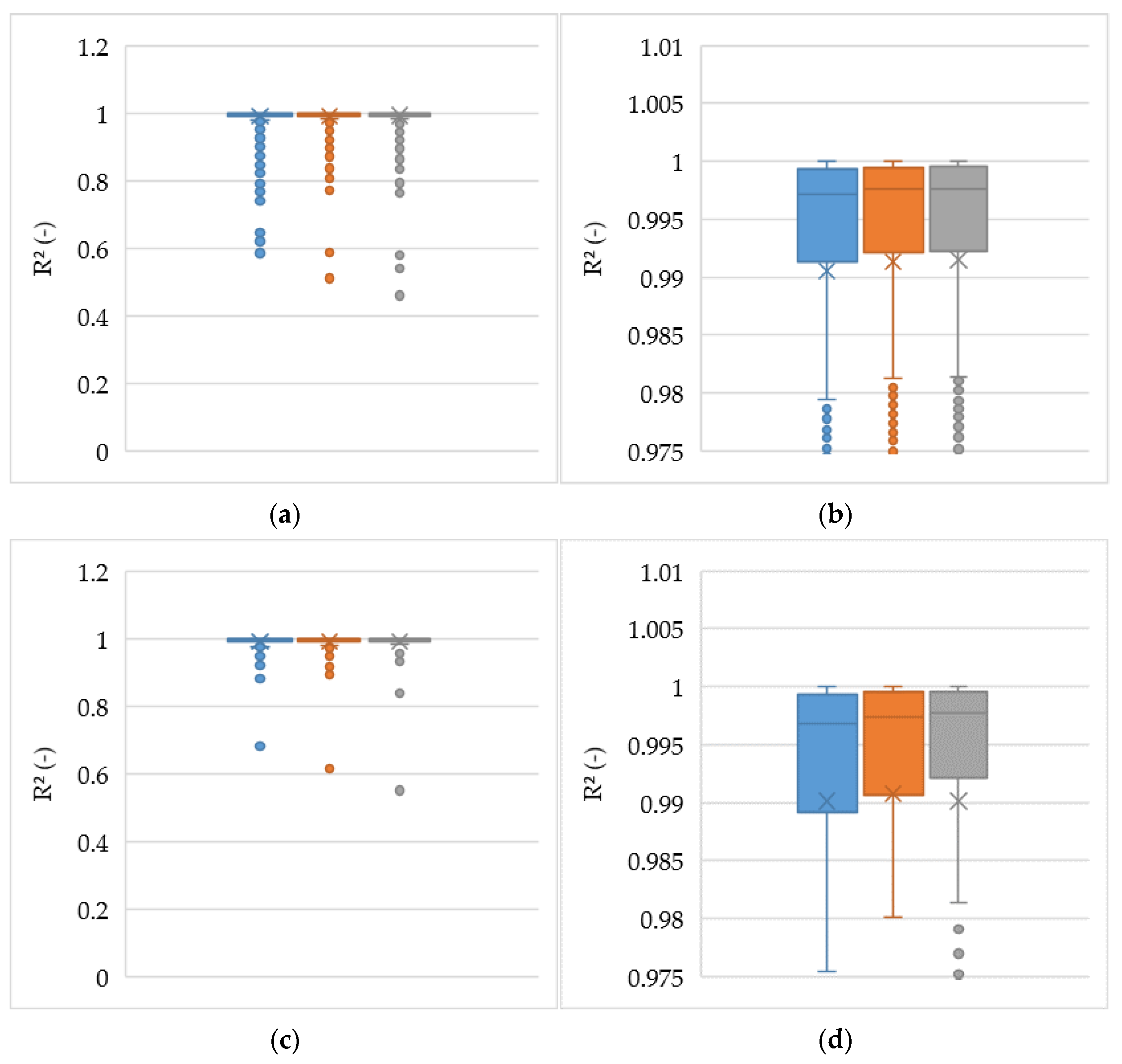
3.1. ANN Prediction Results
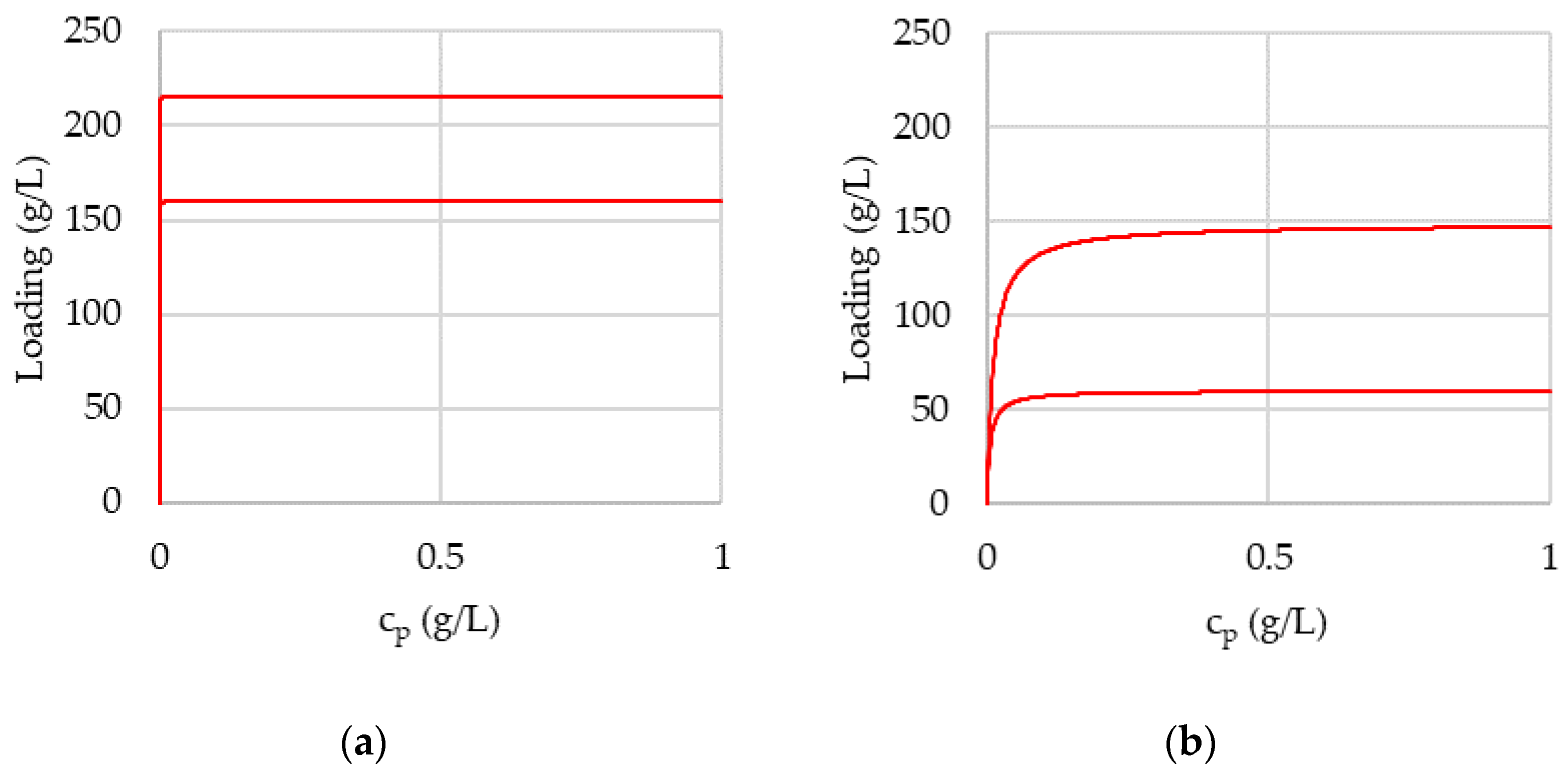
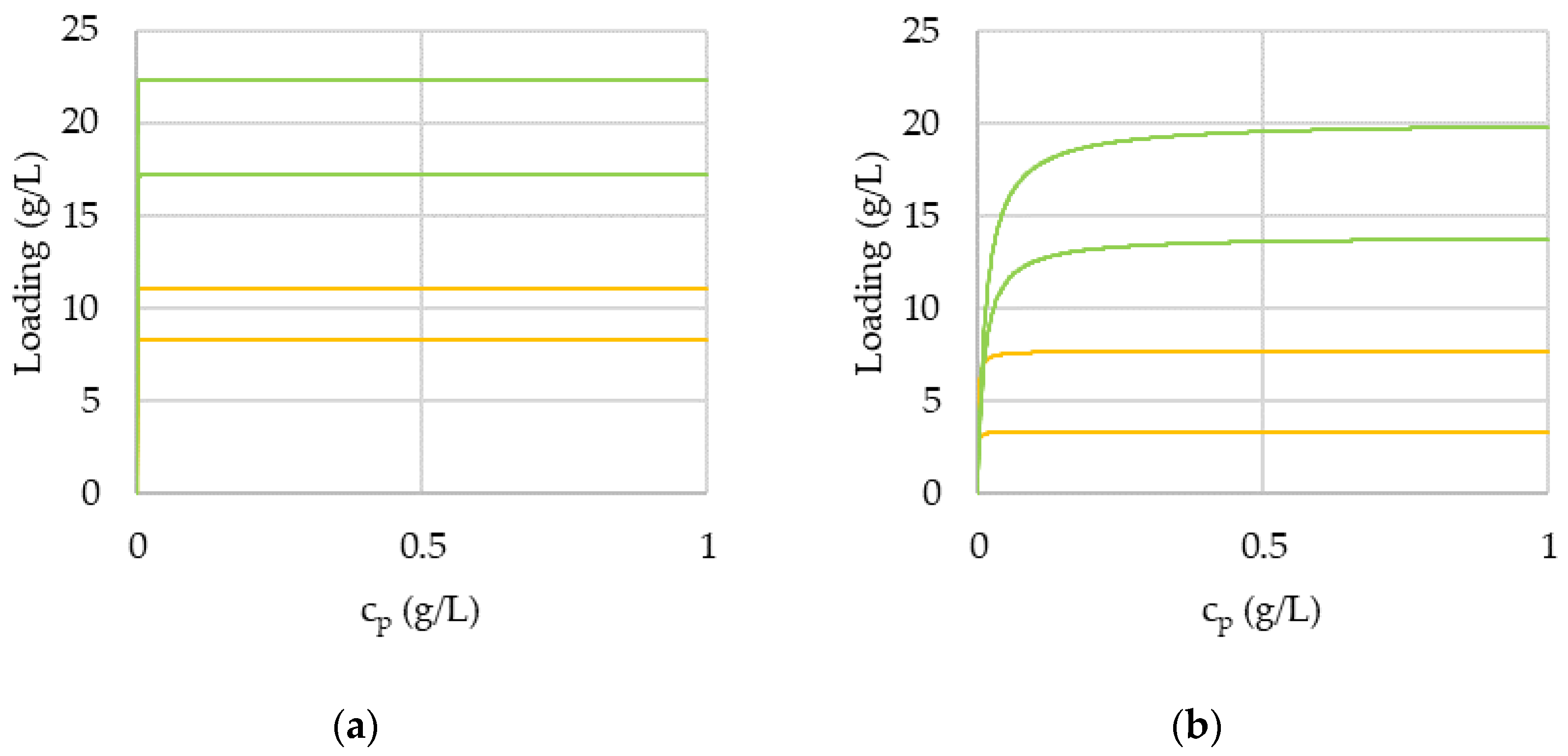
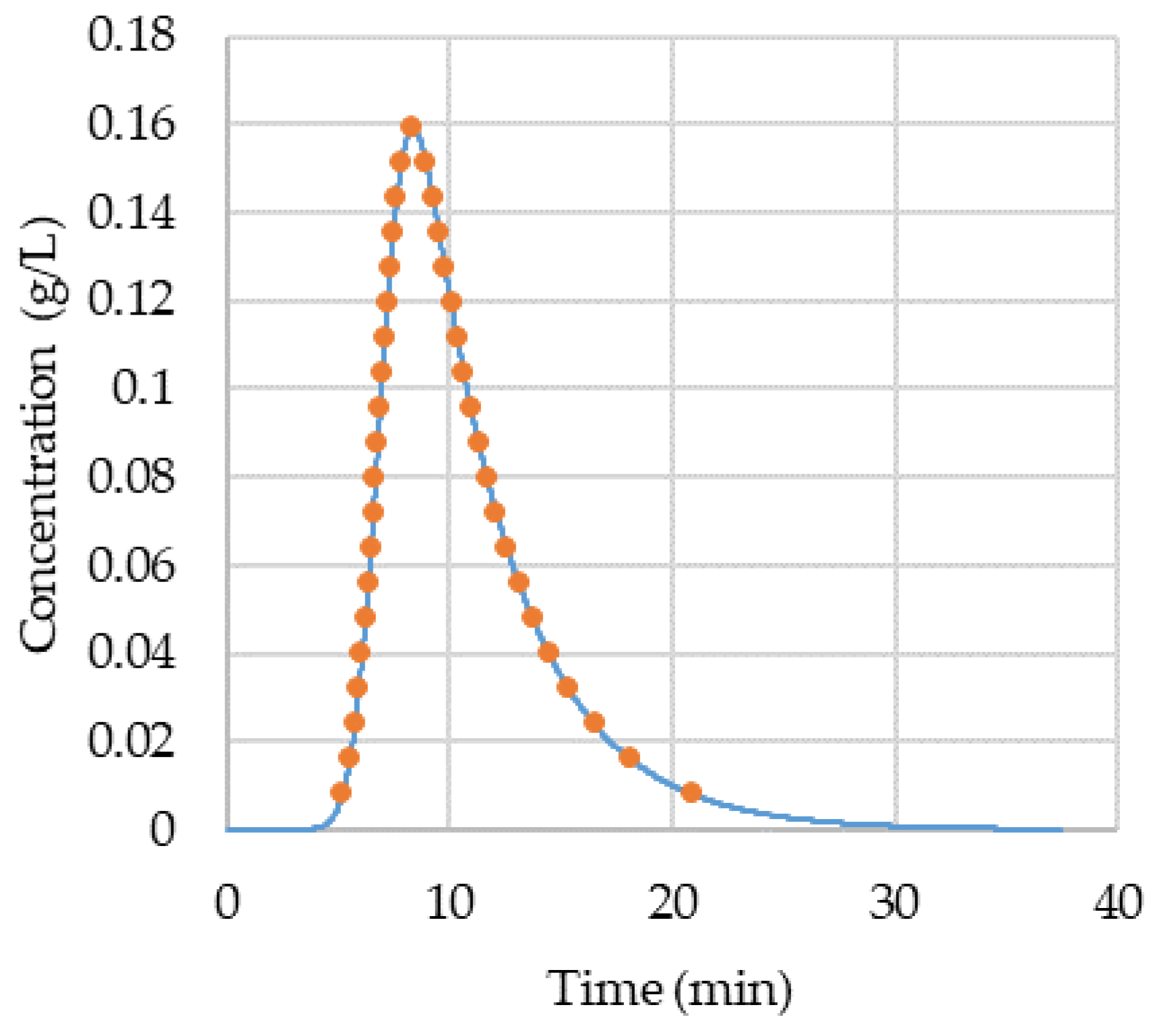
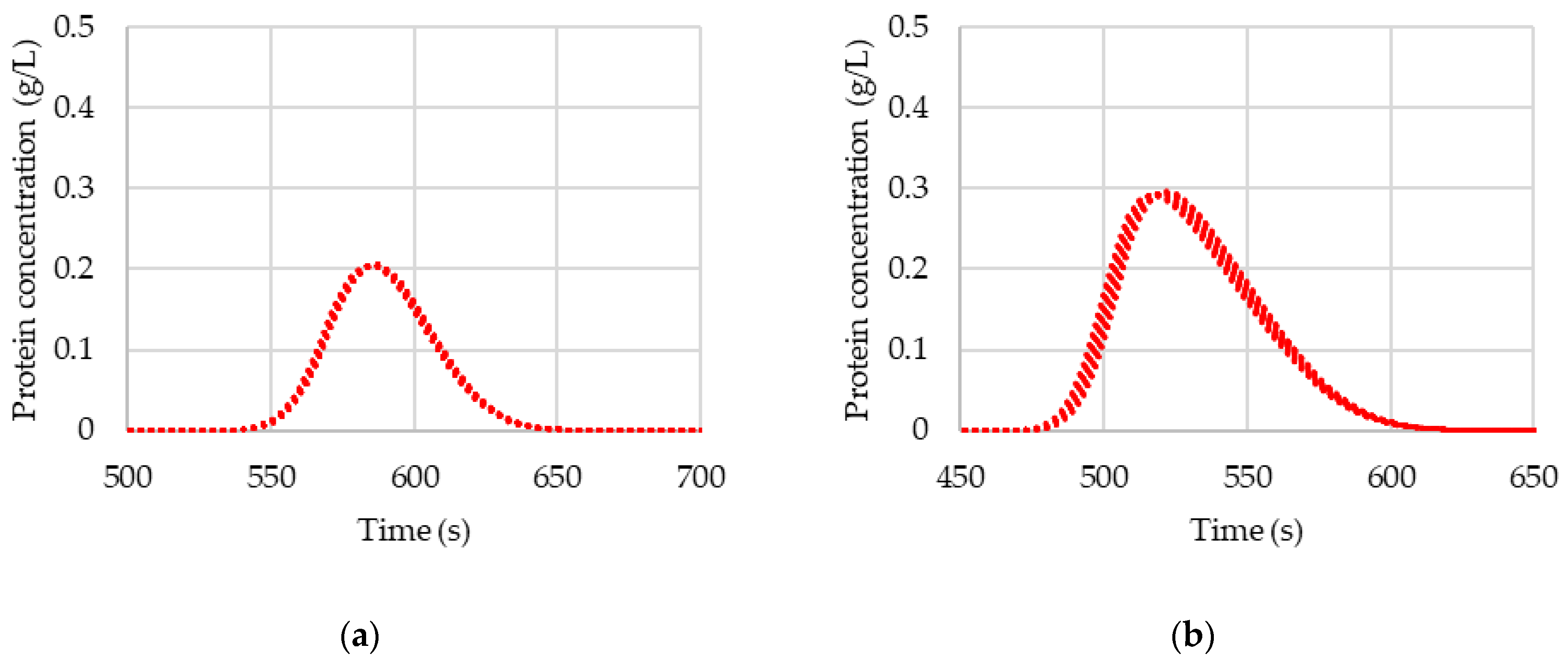
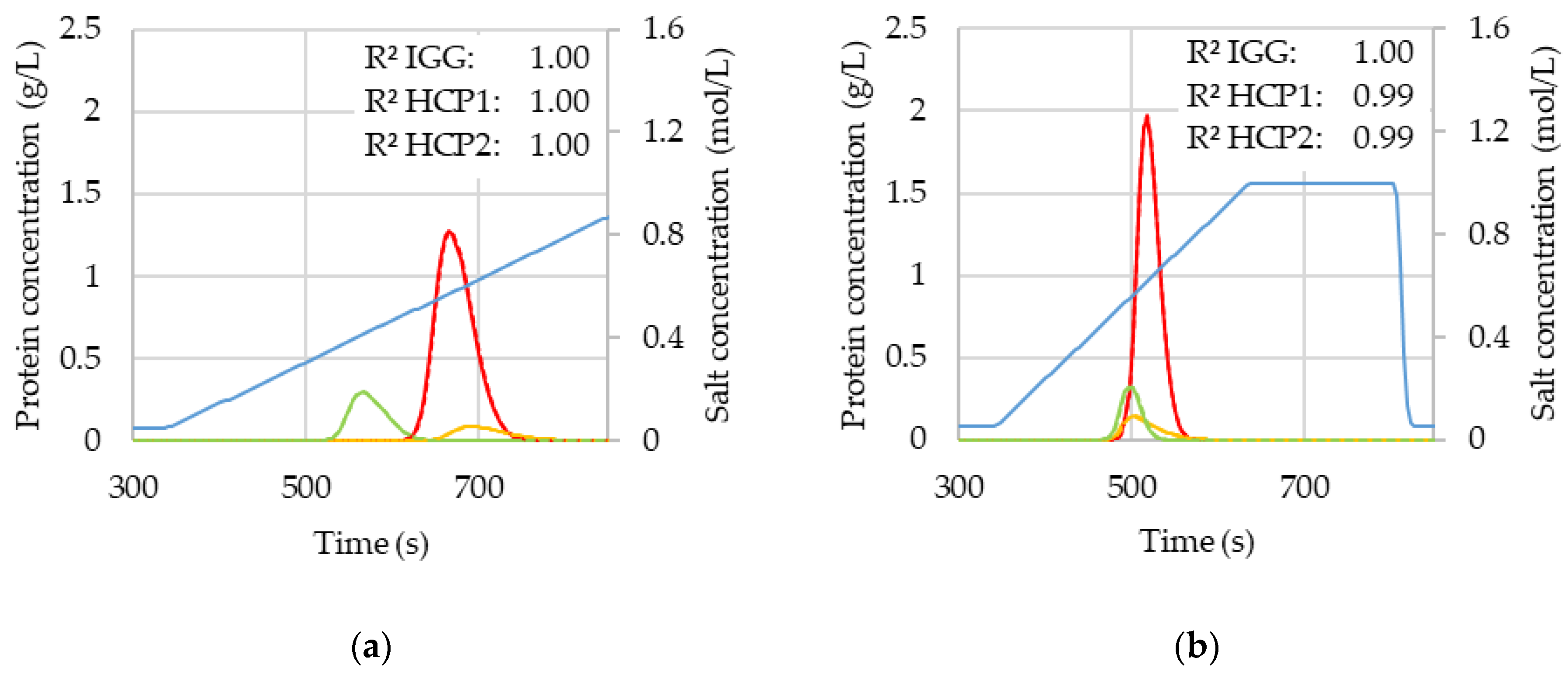
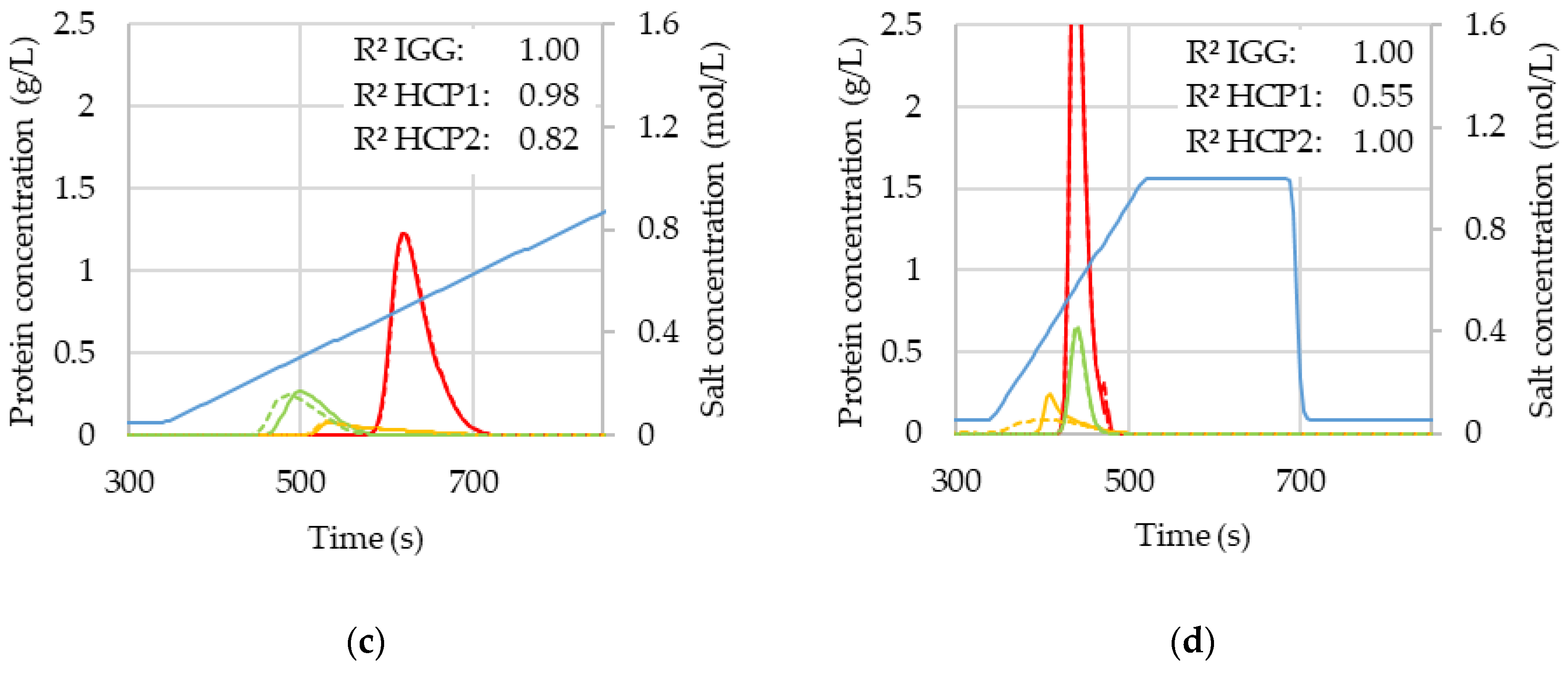
3.2. Comparison of Chromatogramms with Original and Predicted Values
3.3. Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Guiochon, G. Preparative liquid chromatography. J. Chromatogr. A 2002, 965, 129–161. [Google Scholar] [CrossRef]
- Altenhöner, U.; Meurer, M.; Strube, J.; Schmidt-Traub, H. Parameter estimation for the simulation of liquid chromatography. J. Chromatogr. A 1997, 769, 59–69. [Google Scholar] [CrossRef]
- Eisele, P.; Killpack, R. Propene. Ullmann’s Encyclopedia of Industrial Chemistry; Wiley: Chichester, UK, 2010; p. 101. ISBN 3527306730. [Google Scholar]
- Zobel-Roos, S.; Schmidt, A.; Mestmäcker, F.; Mouellef, M.; Huter, M.; Uhlenbrock, L.; Kornecki, M.; Lohmann, L.; Ditz, R.; Strube, J. Accelerating Biologics Manufacturing by Modeling or: Is Approval under the QbD and PAT Approaches Demanded by Authorities Acceptable Without a Digital-Twin? Processes 2019, 7, 94. [Google Scholar] [CrossRef] [Green Version]
- Helgers, H.; Schmidt, A.; Lohmann, L.J.; Vetter, F.L.; Juckers, A.; Jensch, C.; Mouellef, M.; Zobel-Roos, S.; Strube, J. Towards Autonomous Operation by Advanced Process Control—Process Analytical Technology for Continuous Biologics Antibody Manufacturing. Processes 2021, 9, 172. [Google Scholar] [CrossRef]
- European Medicines Agency. EU Guidelines for Good Manufacturing Practice for Medicinal Products for Human and Veterinary Use—Annex 15: Qualification and Validation. Available online: https://www.ema.europa.eu/en/human-regulatory/research-development/scientific-guidelines/quality/quality-quality-design-qbd (accessed on 5 October 2021).
- International Council for Harmonisation of Technical Requirements for Pharmaceuticals for Human Use. ICH-Endorsed Guide for ICH Q8/Q9/Q10 Implementation, 6 December. Available online: https://database.ich.org/sites/default/files/Q8_Q9_Q10_Q%26As_R4_Points_to_Consider_0.pdf (accessed on 22 October 2021).
- Guidance for Industry PAT—A Framework for Innovative Pharmaceutical Development; Manufacturing, and Quality Assurance, U.S. Department of Health and Human Services: Washington, DC, USA, 2004.
- Jones, D.; Snider, C.; Nassehi, A.; Yon, J.; Hicks, B. Characterising the Digital Twin: A systematic literature review. CIRP J. Manuf. Sci. Technol. 2020, 29, 36–52. [Google Scholar] [CrossRef]
- Schmidt, A.; Helgers, H.; Vetter, F.; Juckers, A.; Strube, J. Digital Twin of mRNA-Based SARS-COVID-19 Vaccine Manufacturing towards Autonomous Operation for Improvements in Speed, Scale, Robustness, Flexibility and Real-Time Release Testing. Processes 2021, 9, 748. [Google Scholar] [CrossRef]
- Gerogiorgis, D.I.; Castro-Rodriguez, D. A Digital Twin for Process Optimisation in Pharmaceutical Manufacturing. In Proceedings of the 31st European Symposium on Computer Aided Process Engineering, Istanbul, Turkey, 6–9 June 2021; pp. 253–258. [Google Scholar] [CrossRef]
- Wang, G.; Briskot, T.; Hahn, T.; Baumann, P.; Hubbuch, J. Estimation of adsorption isotherm and mass transfer parameters in protein chromatography using artificial neural networks. J. Chromatogr. A 2017, 1487, 211–217. [Google Scholar] [CrossRef]
- Gao, W.; Engell, S. Neural Network-Based Identification of Nonlinear Adsorption Isotherms. IFAC Proc. Vol. 2004, 37, 721–726. [Google Scholar] [CrossRef]
- Hejtmánek, V.; Schneider, P. Axial dispersion under liquid-chromatography conditions. Chem. Eng. Sci. 1993, 48, 1163–1168. [Google Scholar] [CrossRef]
- Guiochon, G. Fundamentals of Preparative and Nonlinear Chromatography, 2nd ed.; Elsevier: Amsterdam, The Netherland, 2006; ISBN 978-0123705372. [Google Scholar]
- Seidel-Morgenstern, A.; Guiochon, G. Modelling of the competitive isotherms and the chromatographic separation of two enantiomers. Chem. Eng. Sci. 1993, 48, 2787–2797. [Google Scholar] [CrossRef]
- Carta, G.; Rodrigues, A.E. Diffusion and convection in chromatographic processes using permeable supports with a bidisperse pore structure. Chem. Eng. Sci. 1993, 48, 3927–3935. [Google Scholar] [CrossRef]
- Wilson, E.J.; Geankoplis, C.J. Liquid Mass Transfer at Very Low Reynolds Numbers in Packed Beds. Ind. Eng. Chem. Fundam. 1966, 5, 9–14. [Google Scholar] [CrossRef]
- Dose, E.V.; Jacobson, S.; Guiochon, G. Determination of isotherms from chromatographic peak shapes. Anal. Chem. 1991, 63, 833–839. [Google Scholar] [CrossRef]
- von Lieres, E.; Schnittert, S.; Püttmann, A.; Leweke, S. Chromatography Analysis and Design Toolkit (CADET). Chem. Ing. Tech. 2014, 86, 1626. [Google Scholar] [CrossRef]
- Golubović, J.; Protić, A.; Zečević, M.; Otašević, B.; Mikić, M. Artificial neural networks modeling in ultra performance liquid chromatography method optimization of mycophenolate mofetil and its degradation products. J. Chemom. 2014, 28, 567–574. [Google Scholar] [CrossRef]
- Malenović, A.; Jančić-Stojanović, B.; Kostić, N.; Ivanović, D.; Medenica, M. Optimization of Artificial Neural Networks for Modeling of Atorvastatin and Its Impurities Retention in Micellar Liquid Chromatography. Chromatographia 2011, 73, 993–998. [Google Scholar] [CrossRef]
- E Madden, J.; Avdalovic, N.; Haddad, P.; Havel, J. Prediction of retention times for anions in linear gradient elution ion chromatography with hydroxide eluents using artificial neural networks. J. Chromatogr. A 2001, 910, 173–179. [Google Scholar] [CrossRef]
- Asprion, N.; Böttcher, R.; Pack, R.; Stavrou, M.-E.; Höller, J.; Schwientek, J.; Bortz, M. Gray-Box Modeling for the Optimization of Chemical Processes. Chem. Ing. Tech. 2018, 91, 305–313. [Google Scholar] [CrossRef]
- Anderson, R.; Biong, A.; Gómez-Gualdrón, D.A. Adsorption Isotherm Predictions for Multiple Molecules in MOFs Using the Same Deep Learning Model. J. Chem. Theory Comput. 2020, 16, 1271–1283. [Google Scholar] [CrossRef]
- Mahmoodi, F.; Darvishi, P.; Vaferi, B. Prediction of coefficients of the Langmuir adsorption isotherm using various artificial intelligence (AI) techniques. J. Iran. Chem. Soc. 2018, 15, 2747–2757. [Google Scholar] [CrossRef]
- Zobel-Roos, S.; Mouellef, M.; Ditz, R.; Strube, J. Distinct and Quantitative Validation Method for Predictive Process Modelling in Preparative Chromatography of Synthetic and Bio-Based Feed Mixtures Following a Quality-by-Design (QbD) Approach. Processes 2019, 7, 580. [Google Scholar] [CrossRef] [Green Version]
- Zobel-Roos, S. Entwicklung, Modellierung und Validierung von Integrierten Kontinuierlichen Gegenstrom-Chromatographie-Prozessen. Ph.D. Thesis, Technische Universität Clausthal, Clausthal-Zellerfeld, Germany, 2018. [Google Scholar]
- Mollerup, J. A Review of the Thermodynamics of Protein Association to Ligands, Protein Adsorption, and Adsorption Isotherms. Chem. Eng. Technol. 2008, 31, 864–874. [Google Scholar] [CrossRef]
- Brooks, C.A.; Cramer, S.M. Steric mass-action ion exchange: Displacement profiles and induced salt gradients. AIChE J. 1992, 38, 1969–1978. [Google Scholar] [CrossRef]
- Carta, G.; Jungbauer, A. Protein Chromatography; Wiley: Chichester, UK, 2010; ISBN 9783527318193. [Google Scholar]
- Langmuir, I. The adsorption of gases on plane surfaces of glass, mica and platinum. J. Am. Chem. Soc. 1918, 40, 1361–1403. [Google Scholar] [CrossRef] [Green Version]
- Leśko, M.; Åsberg, D.; Enmark, M.; Samuelsson, J.; Fornstedt, T.; Kaczmarski, K. Choice of Model for Estimation of Adsorption Isotherm Parameters in Gradient Elution Preparative Liquid Chromatography. Chromatographia 2015, 78, 1293–1297. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Seidel-Morgenstern, A. Experimental determination of single solute and competitive adsorption isotherms. J. Chromatogr. A 2004, 1037, 255–272. [Google Scholar] [CrossRef]
- Vetter, F.; Zobel-Roos, S.; Strube, J. PAT for Continuous Chromatography Integrated into Continuous Manufacturing of Biologics towards Autonomous Operation. Processes 2021, 9, 472. [Google Scholar] [CrossRef]
- Kornecki, M.; Schmidt, A.; Lohmann, L.; Huter, M.; Mestmäcker, F.; Klepzig, L.; Mouellef, M.; Zobel-Roos, S.; Strube, J. Accelerating Biomanufacturing by Modeling of Continuous Bioprocessing—Piloting Case Study of Monoclonal Antibody Manufacturing. Processes 2019, 7, 495. [Google Scholar] [CrossRef] [Green Version]
- Sixt, M.; Uhlenbrock, L.; Strube, J. Toward a Distinct and Quantitative Validation Method for Predictive Process Modelling—On the Example of Solid-Liquid Extraction Processes of Complex Plant Extracts. Processes 2018, 6, 66. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Engell, S.; Hanisch, F. Neural network-based identification and mpc control of smb chromatography. IFAC Proc. Vol. 2002, 35, 31–36. [Google Scholar] [CrossRef] [Green Version]
- Fausett, L.V. Fundamentals of Neural Networks: Architectures, Algorithms, and Applications; Prentice Hall: Englewood Cliffs, NJ, USA, 1994; ISBN 0-13-334186-0. [Google Scholar]
- Hagge, T.; Stinis, P.; Yeung, E.; Tartakovsky, A.M. Solving Differential Equations with Unknown Constitutive Relations as Recurrent Neural Networks. 2017. Available online: https://arxiv.org/pdf/1710.02242 (accessed on 22 October 2021).
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; The MIT Press: Cambridge, MA, USA, 2016; ISBN 978-0-262-03561-3. [Google Scholar]
- Kruse, R.; Borgelt, C.; Braune, C.; Klawonn, F.; Moewes, C.; Steinbrecher, M. Computational Intelligence; Springer Fachmedien Wiesbaden: Wiesbaden, Germany, 2015; ISBN 978-3-658-10903-5. [Google Scholar]
- Stanley, K.O.; Miikkulainen, R. Evolving Neural Networks through Augmenting Topologies. Evol. Comput. 2002, 10, 99–127. [Google Scholar] [CrossRef] [PubMed]
- Klambauer, G.; Unterthiner, T.; Mayr, A.; Hochreiter, S. Self-Normalizing Neural Networks. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the importance of initialization and momentum in deep learning. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; Dasgupta, S., McAllester, D., Eds.; PMLR: Atlanta, GA, USA, 2013; pp. 1139–1147. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. Tensorflow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. 2015. Available online: https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/45166.pdf (accessed on 22 October 2021).
- Chollet, F. Keras. 2015. Available online: https://keras.io (accessed on 22 October 2021).
- Zobel-Roos, S.; Mouellef, M.; Siemers, C.; Strube, J. Process Analytical Approach towards Quality Controlled Process Automation for the Downstream of Protein Mixtures by Inline Concentration Measurements Based on Ultraviolet/Visible Light (UV/VIS) Spectral Analysis. Antibodies 2017, 6, 24. [Google Scholar] [CrossRef] [PubMed] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| IgG | a1 | a2 | b1 | b2 | Concentration |
|---|---|---|---|---|---|
| Upper boundary | 0.96 (+20%) | −2.7 (+10%) | −0.192 (+20%) | 0.225 (+13%) | 3 g/L (+50%) |
| Base Value | 0.8 | −3 | −0.24 | 0.2 | 2 g/L |
| Lower Boundary | 0.64 (−20%) | −3.3 (−10%) | −0.288 (−10%) | 0.175 (−8.75%) | 1.5 g/L (−25%) |
| HCP1 | a1 | a2 | b1 | b2 | Concentration |
|---|---|---|---|---|---|
| Upper boundary | 1.92 (+20%) | −2.7 (+10%) | −0.006 (+20%) | 0.0113 (+13%) | 0.35 g/L (+180%) |
| Base Value | 1.6 | −3 | −0.0075 | 0.01 | 0.125 g/L |
| Lower Boundary | 1.28 (−20%) | −3.3 (−10%) | −0.009 (−20%) | 0.00875 (−8.75%) | 0.1 g/L (−20%) |
| HCP2 | a1 | a2 | b1 | b2 | Concentration |
|---|---|---|---|---|---|
| Upper boundary | 0.36 (+20%) | −2.7 (+10%) | −0.004 (+20%) | 0.0225 (+13%) | 0.7 g/L (+86.6%) |
| Base Value | 0.3 | −3 | −0.005 | 0.02 | 0.375 g/L |
| Lower Boundary | 0.24 (−20%) | −3.3 (−10%) | −0.006 (−20%) | 0.0175 (−8.75%) | 0.35 g/L (−6.6%) |
| Set | Q1 (25%) | Median (50%) | Q3 (75%) | Lower Whisker | Upper Whisker |
|---|---|---|---|---|---|
| Training 10 CV R2 | 0.991 | 0.997 | 0.999 | 0.979 | 1 |
| Training 5 CV R2 | 0.992 | 0.998 | 0.999 | 0.981 | 1 |
| Training 3 CV R2 | 0.992 | 0.998 | 1 | 0.981 | 1 |
| Validation 10 CV R2 | 0.989 | 0.997 | 0.999 | 0.975 | 1 |
| Validation 5 CV R2 | 0.99 | 0.997 | 0.999 | 0.980 | 1 |
| Validation 3 CV R2 | 0.992 | 0.998 | 0.999 | 0.981 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mouellef, M.; Vetter, F.L.; Zobel-Roos, S.; Strube, J. Fast and Versatile Chromatography Process Design and Operation Optimization with the Aid of Artificial Intelligence. Processes 2021, 9, 2121. https://doi.org/10.3390/pr9122121
Mouellef M, Vetter FL, Zobel-Roos S, Strube J. Fast and Versatile Chromatography Process Design and Operation Optimization with the Aid of Artificial Intelligence. Processes. 2021; 9(12):2121. https://doi.org/10.3390/pr9122121
Chicago/Turabian StyleMouellef, Mourad, Florian Lukas Vetter, Steffen Zobel-Roos, and Jochen Strube. 2021. "Fast and Versatile Chromatography Process Design and Operation Optimization with the Aid of Artificial Intelligence" Processes 9, no. 12: 2121. https://doi.org/10.3390/pr9122121