1. Introduction
In many control applications, preview knowledge is available for improving tracking quality and disturbance rejection. Model predictive control (MPC) is a popular method for incorporating both preview knowledge and constraints, because, in principle [
1], the information is incorporated in a systematic fashion. However, a standard preview MPC design is often monolithic in nature, where the constraint, preview, and feedback information are coupled in the associated optimisation (e.g., [
2,
3,
4,
5]). In contrast, large-scale industrial plants are often live systems with an operating feedback controller. Re-designing the controller within the MPC framework may be costly and impractical. Thus, it is more attractive to practitioners if the advanced control features, such as preview information and constraint handling, can be retrofitted into their existing feedback controller (e.g., [
6]).
One of the popular approaches is the reference governor. The reference governor is an add-on scheme that ensures the satisfaction of the state and control constraints by modifying the set-point to a well-designed closed-loop system [
7]. For example, the work by Gilbert and Ong [
8], Borrelli et al. [
9] proposed a reference governor design that satisfies constraints by adjusting the set-point based on the maximal output admissible set. However, such a design is simple and efficient, but only employing the set-point as the degree-of-freedom could result in a loss of optimality, where the degrees-of-freedom are limited to the reference signal only [
10]. Much research in recent years has focused on the development of the reference governor within the predictive control framework. For example, the work by Aghaei et al. [
11] showed an MPC-based reference governor design, where a couple of exogenous signals, computed by solving an on-line optimisation, were added onto the reference and control variables of the original closed-loop system for ensuring constraint satisfaction. Work by Klauco [
12] developed another MPC-based reference governor design for which a set of future references is optimised based on the prediction of the closed-loop system behaviour.
Nonetheless, a large number of these MPC-based reference governor studies employed the set-point as the only optimisation variable, which could thus lead to a loss in performance and optimality. In addition, in some studies, the reference signal is assumed to be constant or the existing control design was based on a state-feedback controller. For some applications, an output-feedback controller is often employed, which is synthesised using frequency domain techniques for satisfying some robustness and performance specifications given in the frequency domain. As a consequence, this begs the question: is there a systematic way to incorporate the merits of MPC, such as the capability for handling constraint and preview knowledge, into an existing feedback controller? A simplistic proposal might involve a standard MPC formulated around the underlying closed-loop dynamics. However: (i) the MPC computes the decision variables depending on the predictions and current state of the closed-loop dynamics. Therefore, the constraint handling features of the MPC depend upon the predictions of the closed-loop dynamics. Thus, optimising such predictions will introduce an additional feedback loop to the original closed-loop, in turn impacting on the carefully designed properties of the existing controller [
13,
14]; (ii) coupling the feedback and feed-forward design in the standard MPC results in an ’optimal’ feed-forward compensator with respect to the instantaneous cost function rather than the overall closed-loop behaviour. Consequently, the performance of such a compensator is often poor, as reported in many studies [
4,
15,
16]. In the context of designing a modular MPC upon a given feedback controller, if the preview compensator is not carefully designed in a sense that it only handles the transient of the existing closed-loop, the preview action is then mistakenly corrected by the pre-determined feedback control law, resulting in a deterioration in the performance.
We addressed the former problem in our earlier work [
14] by presenting a preview modular MPC layer that is based on a known feedback controller. In short, the pre-determined feedback control law focuses on the frequency domain closed-loop properties, such as sensitivity, whilst the feed-forward input from the modular MPC is purely based on advance knowledge. Without corrections that are linked to the measurements from the plant, the MPC module thus does not, unnecessarily, interact with the feedback loop. In this work, we propose the preview compensator design procedure for the modular MPC formulation. Specifically, we derive the key conditions that ensure the preview gain is systematic and optimal in a sense that the preview compensator from the modular MPC formulation only handles the transient of the closed-loop and, once the steady-state is reached, the preview perturbation input remains at zero. Moreover, we derive results demonstrating that the modular MPC can be implemented upon any given linear feedback controller and the use of an observer on the modular MPC has no effect upon the proposed conditions.
This paper first presents the basic definitions of the model and known output-feedback controller and also the formulation of the modular MPC in
Section 2. In
Section 3.1, the conditions that guarantee the additional MPC design does not influence the nominal stability and robustness of the closed-loop dynamics are revisited. The novelty of this paper starts in
Section 3.2, where we derive a set of conditions that proves the preview compensator within the modular MPC formulation is well-designed and systematic in a sense that the preview compensator only handles the transient of the closed-loop based on the future reference signals. In the rest of
Section 3, we also derive results that show that the modular MPC is feasible to implement upon any existing linear controller and the proposed conditions hold, regardless of the observer design for the modular MPC. In
Section 4, numerical examples are presented and followed by conclusions in
Section 5.
Notation
Let and denote the real and complex fields, respectively, and let denote a complex variable. The space denotes the space of proper real-rational transfer function matrices and denotes a sample variable of a discrete-time signal. Let denote the transpose of a vector and is the transpose of a matrix . The notation denotes the future prediction sequence , where denotes the one-step ahead predictions at step k. Let denote the eigenvalues of the matrix V.
3. Analysis of the MPC Design upon an Existing Controller
We revisit in
Section 3.1 the conditions that ensure the nominal stability and robustness properties of the original closed-loop are retained. The key novelty of this paper begins from
Section 3.2, where we derive the key conditions that ensure the preview compensator is systematic and well-designed in a sense that the preview control action only handles the transient of the existing closed-loop dynamics. Moreover, in the rest of
Section 3, other theoretical aspects of the modular MPC formulation, such as the practicality and tuning, are discussed.
3.1. Interactions between the Modular MPC and Existing Controller
As discussed in Algorithm 1, the perturbation
is added into the embedded control law (
5b); hence, the control input now becomes, as follows:
The perturbation
seems to solely handle the constraints and preview knowledge; however, this might not be true, as illustrated in the following lemma.
Lemma 2 ([
14]).
The modular MPC introduces an additional feedback loop to the existing closed-loop system when constraints are inactive. Proof. Following an unconstrained optimisation problem (
16a) in Algorithm 1, the perturbation to the control law is:
Substituting (
18) into (
17) yields:
Clearly, as the optimum
depends upon the state
, the underlying state feedback gain
K is implicitly changed to
. □
Lemma 2 indicates that the perturbation from the modular MPC could potentially change the nominal stability and robustness properties of the underlying controller, even when constraints are not active.
In order to retain the nominal closed-loop dynamics, it is required that the perturbation becomes independent of the feedback measurement , in other words, the term in the cost function of Algorithm 1 needs to be zero.
Theorem 1 ([
14]).
The unconstrained input perturbation sequence from the additional MPC layer (Algorithm 1) has no impact on the original unconstrained closed-loop dynamics if and only if . For , the cost function (16a) needs to embed some knowledge of the nominal output-feedback control law (2), such that the weights satisfy the following conditions: Theorem 1 demonstrates that the extra control layer that satisfies the conditions (20) will not impact on the underlying robust output-feedback control law, unless constraints are predicted to be active. Consequently, in normal operation, the properties of the original closed-loop dynamics are retained and the additional control layer solely handles the upcoming/preview information.
The reader may wonder whether an alternative form of the cost function, where only the measures of
and
are considered, and the term that is linked to
is neglected, could circumvent the need of the conditions (20). Indeed, the perturbation
c from (
16a) would then become independent of
. However, the preview gain
would then become sub-optimal, which is demonstrated in the following section.
3.2. Preview Compensator in the Modular MPC Formulation
In
Section 2 and
Section 3.1, we revisit the modular MPC design and important conditions. In
Section 3.2, based upon the earlier results, we present the preview compensator design within the modular MPC formulation, which is the key novelty of this paper.
By inspection of the offset-free control law (
17), the perturbation input for handling the preview knowledge
only requires to respond to the transient of the closed-loop systems, whilst the steady-state is ensured by the embedded control law
. For the perturbation input only handling the transient, the preview control gain
needs to possess certain matrix structures. However, first, before the structure of the preview gain is defined, the concept of the tail or consistency in predictions is revisited [
19,
23]. The tail or consistency in predictions is known as the solutions of the input predictions, that are optimised at the previous sample, are extended into the candidates of the optimisation at the current sample. For example, when considering the perturbation input predictions
at step
k and
at step
, defined as follows:
If the predictions are consistent, then the perturbation input prediction
at step
should possess the following form:
From (
22), it is shown that the prediction at step
is consistent with its corresponding prediction at step
k, for example
.
Remark 2. Consistency in predictions are of key importance. The planned preview control actions do not change over time once the steady-state is known in the reference signal. Thus, the preview control action (or the preview gain) only handles the transient of the closed-loop.
To fulfil the requirement of consistency in predictions, consider the general form of the preview gain
, as follows:
where the elements
need to satisfy the following lemmas.
Lemma 3. When consistency in the prediction holds in (22) (e.g., ), if . Proof. Considering the perturbation prediction
at step
k:
and
at step
, defined as follows:
It is clear that, for example, the perturbation input (
in (
25)) at step
does not consist of the past reference value (
) from step
k, that is because the preview action at step
shouldn’t act on the past reference values from step
k. Thus, in order for the
prediction of the perturbation input (
) at step
k also not consisting of the past reference value
, (i.e.
consistency in predictions), the element
needs to be zero and, by induction,
. □
Next, when considering a preview reference signal at steady-state, a well-designed preview control action and its predictions should be zero or no impact on the original closed-loop in nominal case, as the perturbation input only handles the transient of the closed-loop.
Lemma 4. For a constant steady-state reference signal, if .
Proof. Let a constant reference signal be denoted as
. Substituting the constant reference signal into (
24) reveals that for
and
to hold only if
and
. By induction,
. □
Lemma 5. When considering a time-varying reference containing the non-zero steady-state, consistency in the predictions (22) holds if in (23) possesses the following form: Proof. Assuming
in (
26) is true, considering the reference signals containing the steady-state
and
, where
denotes the steady-state, and the perturbation input
is defined as follows:
and the prediction at step
,
is as follows:
From (
27) and (
28), it is clear that
and by induction, consistency in predictions (
22) can be proven. □
To summarise, for the perturbation input
from the modular MPC only handling the transient of the closed-loop and remaining zero whilst the steady-state is reached, the preview control gain
is needed to be of the following form:
where
. The systematic and well-designed
structure (
29) ensures the perturbation
in the embedded control law (
17) possesses the property of consistency in predictions. The question is now how to obtain the
structure (
29) from the modular MPC optimisation (8). Thus, the key result of this work is as follows.
Theorem 2. The preview control gain in (18) is of the form (29) if and only if the following conditions are satisfied: Proof. From (
18), it is shown that the preview gain is defined as
. In the first part of this proof, we prove
is an block diagonal matrix and then, in the second part,
is of the form similar to (
29). The proof is based on inspection of the Lyapunov equation
, expressed as follows:
First, in proving
being an identity matrix multiplied by a constant, begin from the middle equality of (
31):
Suppose the conditions (30) are true, then
must be true based on Theorem 1. Subsequently, the equality (
32) becomes:
Notice that the vector
possesses a special property:
In addition, the matrix
also possesses a special property. When considering the term
in (
33), define the general form of
, as follows:
The term
in (
33) now becomes:
Thus, based on the results from (
34) and (
36), the first row of (
33) becomes:
and the second row of (
33), by inspection of (
34) and (
36), is as follows:
Repeat the step (
38) to other rows of (
33), by induction, the term
can be proven to be a block diagonal matrix, as follows:
and, furthermore, the inverse of a block diagonal matrix
is also a block diagonal matrix.
Next, let us prove
is of the form (
29). When considering the middle-right equality in (
31):
Suppose the conditions (30) are true, then
from Theorem 1. Subsequently, the equality (
40) becomes:
where
are simplified, as follows (
):
and the term
possesses some special properties, as follows:
Based on (
42) and (
43), the first row of (
41) becomes:
Next, we need to prove
is true if
possesses the property of the optimal
in (
26) (Lemma 4), assuming
is a constant vector/reference. That is equivalent to prove
.
In finding the condition
, considering the top-right equality of the Lyapunov equation (
31):
Suppose that the conditions (30) holds, then we can substitute
into (
45):
When considering (
46) multiplied with a constant reference
, and given that
, thus, (
46) becomes:
Thus, extracting the term
in (
47) yields:
Consequently, substituting the result from (
48) into (
44),
must hold, which implies
or
.
As for
, considering the equality in (
41), based on the results from (
42) and (
43), the second row of (
41) becomes:
Thus,
,
and
. Repeating the step (
49), by induction, it reveals that
possesses a similar structure as the preview gain
in (
29). Consequently, based on the earlier result
in (
39), the structure of
is in an equivalent form of (
29) if the conditions (30) hold. □
Remark 3. The conditions (30) are equivalent to the conditions (20). Satisfying these conditions is crucial, which can simultaneously ensure that the modular MPC (i) retains the nominal stability and robustness properties of the original closed-loop; and, (ii) provides an optimal preview control action that solely handles the transient closed-loop dynamics.
3.3. Feasibility of Satisfying the Conditions (20) and (30)
Based upon the conditions (20) and (30), the readers may wonder whether there exist the weights
for any given feedback controllers
K. Indeed, finding a feasible set of
for a stable controller
K to be optimal with respect to the cost function (
7) is not always guaranteed. Nonetheless, if cross-product terms are allowed in the cost function (
7), then one is guaranteed to find some feasible set of
for any linear feedback controller
K. The feedback controller
K is optimal with respect to the cost function, which is summarised in the following Theorem 3.
Theorem 3. If the cross-term N is included in the cost function (7), a set of weights exists, such that any given linear controller K is optimal with the following cost function:and its corresponding conditions in Theorem 1 and 2 are modified, as follows: Proof. The proof is based on some earlier work on the inverse linear quadratic regulator problem [
24]. When considering a control law
, every closed-loop system with such a control law is optimal with respect to some cost functions:
where
is any positive-definite matrix. The cost function (
52) has shown that with the cross terms, one can always recover the weights for a linear control law
. □
Thus, based upon the conditions (51) and given that the stabilising controller
K in (
5b) is pre-determined, the weights
that satisfy (51) can be computed by solving a linear matrix inequality (LMI) problem [
25]. For example, consider the convex optimisation problem, as follows [
26,
27]:
By selecting an arbitrary
and solving the optimisation problem (53), the inequalities (
53b) and equalities (
53c), (
53d) enforce the weights
to satisfy the proposed conditions (51), for any chosen
.
3.4. Tuning of the Modular MPC
The preview horizon
can be chosen as large as possible. The number of state in the autonomous prediction model (9) increases accordingly and so does the computational cost. As for the control horizon
, a longer control horizon results in a larger maximal controlled admissible set
(
15), which implicitly reduces the chance of infeasibility in optimisation (16). Additionally, more computational power is required for a large
.
Remark 4. The condition (51) only requires satisfaction of the weights within the cost function (50) and is independent of the choice of preview and control horizons . 3.5. The Impact of Observer Design for the Modular MPC on the Proposed Conditions (20) and (30)
So far, it is implicitly assumed that the full-state measurements are available to the modular MPC. In most applications, the full-state measurements are not typically accessible to the controller. Given that the modular MPC is formulated based on the state-space design approach that relies upon the full-state measurements, thus, an observer design is necessary for such applications that without the full-state measurements. Thus, it raises a question as to whether the modular MPC would affect the existing closed-loop if an observer is incorporated or, namely, whether the proposed conditions (20) and (30) hold if the observer is used with the modular MPC. When considering the closed-loop system model (5), the observer is constructed, as follows:
where
denotes the observer gain and the closed-loop control law (
54b) is a function of the estimate
of the state
. Given that the degree-of-freedom of the modular MPC is the perturbation input
, which is added upon the existing controller
. Thus, in order to ensure the modular MPC with an observer does not impact the existing closed-loop in nominal situation, the perturbation input
is proved to be independent of the estimated state
, similar to the argument in Theorem 1, in the following Theorem.
Theorem 4. For a modular MPC incorporating an observer (54), the properties of Theorem 1 and 2 of the modular MPC hold, regardless of the observer design or the choice of the observer gain L (as long as L is a stable observer gain).
Proof. When considering the closed-loop system model (5) and the observer system (54), the augmented closed-loop system is defined, as follows:
Replacing the closed-loop model matrices (5) with the augmented model (55), one can repeat the steps in
Section 2 and
Section 3.1 and derive the same conditions as in Theorems 1 and 2. Thus, the conditions on the weights (20) and (30) are independent of the choice of the observer gain
L. □
The results from Theorem 4 show that the perturbation input
in (
54b) is independent of the estimated state
in nominal operation if the conditions (20) are satisfied. However, the accuracy of the predictions of the closed-loop dynamics depends upon the quality of the state estimation. The inaccurate predictions could potentially cause the modular MPC falsely expecting constraint violations, then, the perturbation input
could become more active than necessary. In such cases, the modular MPC would affect the sensitivities and robustness properties of the existing closed-loop. Nonetheless, tuning the observer to achieve accurate state estimation is process dependent; thus, the readers can refer to [
28] for more details on the observer tuning under the MPC framework.
3.6. Discussions on Stability and Feasibility when Constraints Are Active
It should be emphasised that, when constraints are active, the robustness of the feedback closed-loop dynamics cannot be retained as the perturbation input
would then necessarily impact upon the closed-loop as constraint handling is linked to predictions and predictions are based on the current state. Techniques to give absolute robust guarantees during constraint handling, such as LMIs and tube methods [
29,
30], are known to be cautious as well as computationally challenging and, thus, are not pursued here.
Nevertheless, the nominal stability of the proposed modular MPC during constraint handling can be established based upon the use of infinite horizons and invariant sets, but only assuming the optimisation (8) is feasible at every sample
k. The proof is standard in the literature [
19], so it is not expanded here. Assume that at the first sample there exists a perturbation input sequence
that ensures the trajectories of the closed-loop system always satisfy the constraints (13) then, thereafter, recursive feasibility of this assumption alongside optimisation (8) gives an implicit proof the perturbation input
tends to zero and, thus, the control law defaults to the underlying robust stable feedback.
However, in the presence of model uncertainties, unmodelled disturbances or ambitious constraint requirements alongside large target changes, there might not exist a perturbation input sequence
that satisfies the constraint set (
15); this is so-called infeasibility of optimisation (8). In addition, the steady-state
could become unreachable due to active constraints. The focus of this paper is on a simple MPC formulation on an output-feedback controller, thus, for tackling the infeasibility in MPC, the readers are referred to some studies, for example, the use of constraint-softening strategies [
31,
32] and steady-state target calculators [
33,
34].
4. Illustrative Examples
In this section, we present numerical examples to demonstrate how easily the modular MPC algorithm can be implemented upon an existing controller. The plant considered in this work, as adopted from [
35], is the double integrator with a slow process zero, defined as follows:
and the robust controller is given in [
35], as follows:
Subsequently, when considering a reasonable sampling time
, the discrete time closed-loop model is characterised by the matrices:
Based on the closed-loop model (58), the weights
for the MPC cost function (
50) can be computed by performing the optimisation (53). Let the preview knowledge be available up to
samples and the control horizon is chosen as
for demonstration purposes.
4.1. Example 1: Handling Preview Information
The control task is to track a step reference signal that happens at 2 s.
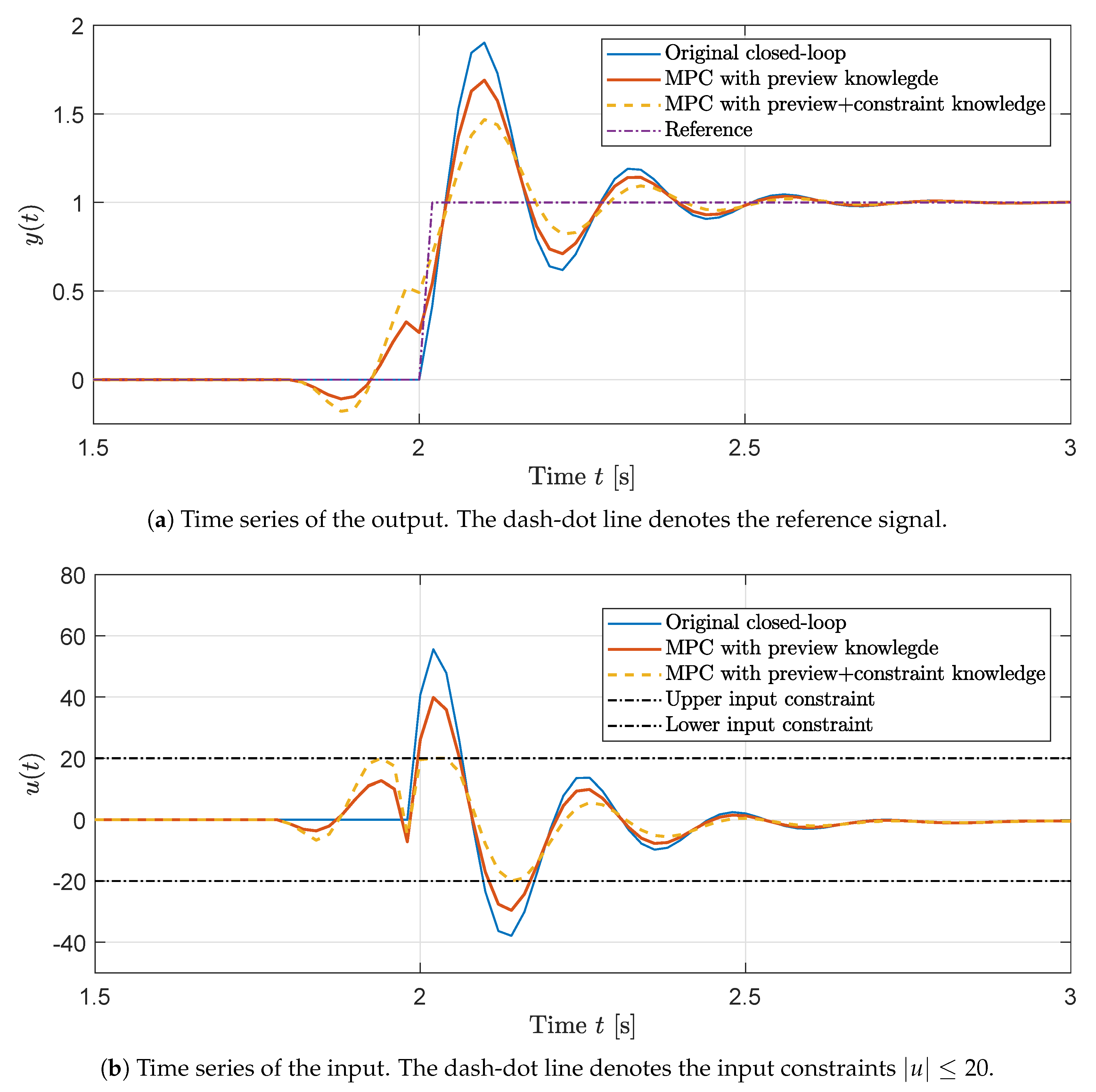
Figure 2a shows that with the preview knowledge, the proposed modular MPC (the thick solid red line) clearly achieved better tracking with less overshoot than the system with only the original controller (the thin solid blue line). The input effort was also lower when the MPC module anticipated the changes in the preview measurement, as shown in
Figure 2b. Furthermore, the perturbation input from the modular MPC is illustrated in
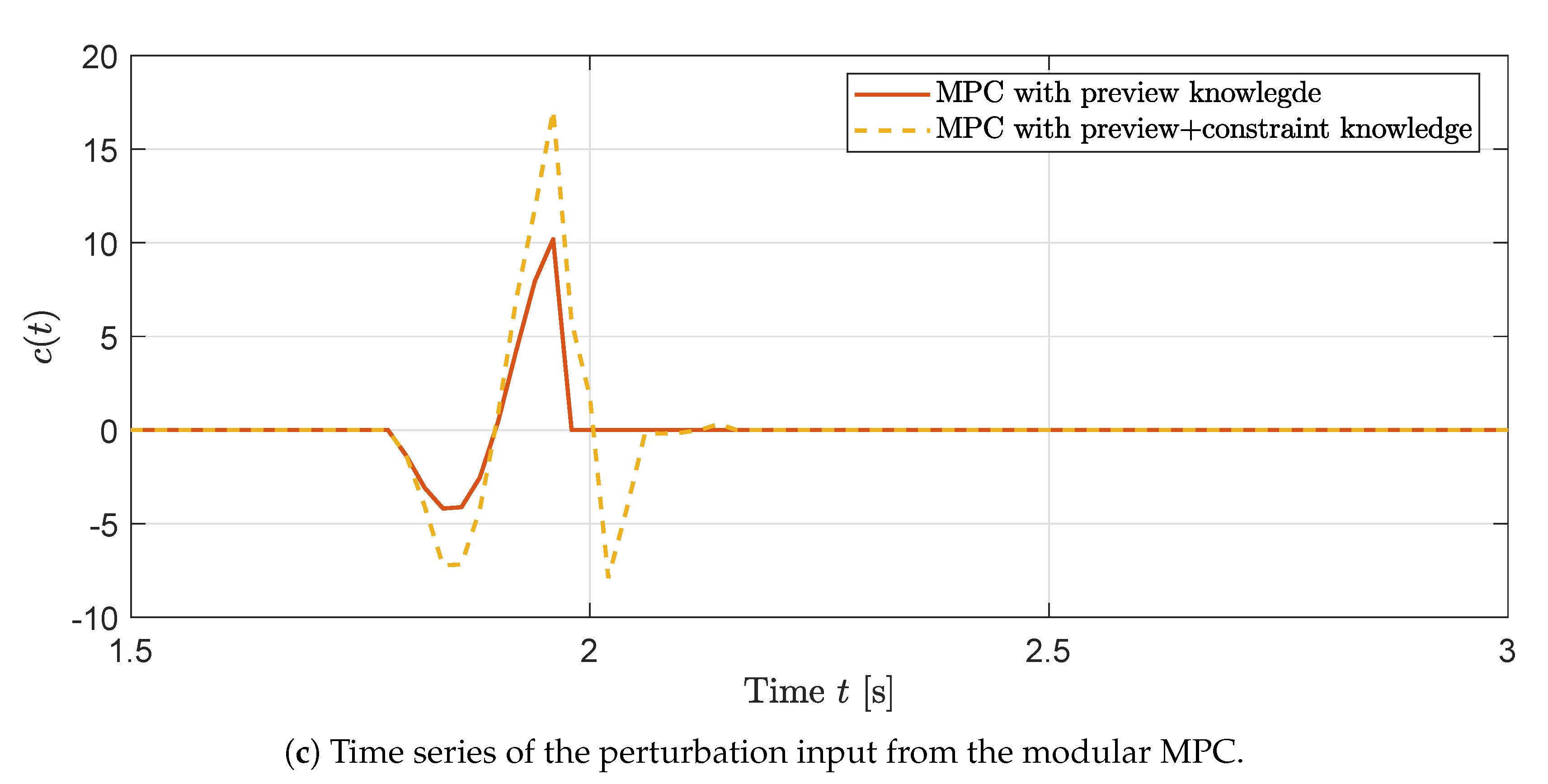
Figure 2c. It is clearly shown that the modular MPC is only active between 1.8 s and 2.2 s, where, with the preview horizon
(that is 0.2 s), the MPC module noticed a sudden step changes from the preview reference signal and provided additional perturbation input to the closed-loop system for improving the overshoot.
4.2. Example 2: Handling Preview and Constraint Information
This example shows how the constraint handling feature is incorporated into the existing controller. The control task is equivalent to the previous example that a step reference is tracked, but, in this example, a constraint is imposed on the input as
.
Figure 2a,b show the output and input of the original closed-loop system and the modular MPC algorithm with preview and constraint information. In
Figure 2a, it is clearly demonstrated that the modular MPC with
constraint and preview knowledge (the dashed line) drove the output into the more opposite direction at the beginning (around 1.85 s), as comparing to the MPC layer with only the preview measurement (the thick solid red line).
Figure 2b shows how the modular MPC with constraint and preview knowledge (the dashed line) anticipated constraint violation and reacted more aggressively in advance, in comparison to the MPC algorithm with only the preview knowledge (the thick solid red line). In addition, in
Figure 2c, it reveals that, when the constraint violation was not expected and the preview signal reached a steady-state, the perturbation input from the modular MPC always remained at zero.
4.3. Optimality and Consistency in Predictions
Section 4.1 and
Section 4.2 showed that the preview action from the modular MPC solely handled the transient of the closed-loop dynamics in the unconstrained case. To demonstrate that the preview action is optimal, consistency in predictions is examined, as suggested by Remark 2.
Figure 3 shows the predicted sequences and closed-loop trajectory of the perturbation input at different time instant. At each time instant, the modular MPC predicted the perturbation input sequence (grey solid line) and the first sample of the sequence (star) was then implemented into the system. By inspecting
Figure 3, the predictions are consistent with the actual closed-loop input trajectory (dash line). In other words, the tail of the predictions at the previous time sample is included in the predictions at the later time. Thus, the preview control action is optimal with respect to the overall closed-loop behaviour.



{kind=link}
{kind=link}
{kind=link}
{kind=link}



