1. Introduction
Nowadays, energy crises and environmental issues are frontier problems that arouse great concern. Reducing the emissions of CO
2 is one of the crucial challenges for sustainable development in the future. Carbon Capture and Storage (CCS) is by far a mature theory to study the reduction of CO
2 emissions. The ionic liquids (ILs) have some properties of low volatility, high solubility and high selectivity, which make them increasingly interesting in capturing CO
2. These advantages make the ILs considered as a relatively novel type of solvents [
1,
2,
3,
4].
The value about the solubility of CO
2 in ILs is important information. It can not only help us to study the interaction between CO
2 and ILs, but also provides important guidance for ILs design that meets industrial needs [
5,
6]. At present, the main methods for obtaining solubility of CO
2 in ILs include experimental measurement and modeling. Due to the difficulties, e.g., the non-ideal behavior of the research system, the complexity of ionic liquid system, the limited measurement conditions, the time-consuming and high costs on the measurement of ILs, it is impossible to obtain the solubility by the experimental measurement method for practical applications [
7,
8]. The modeling methods mainly consist of mechanism modeling and data-driven modeling.
The thermodynamic models have the advantages of clear engineering background, strong interpretability and good extrapolation ability. For these reasons, researchers have tried to present thermodynamic models to predict solubility of CO2 in ILs. It commonly includes state equation, activity coefficient group contribution models, and quantum stoichiometry models.
Jaubert [
9] and Lei [
10] established the prediction model to determine solubility of CO
2 in ILs by Peng Robinson (PR) state equation. Soave [
11] developed a model based on the Soave Redlich Kwong (SRK) state equation to predict the behavior of equilibrium constants of CO
2. Peters [
12] utilized the group contribution method to prognosticate the phase behavior of binary systems of ILs and CO
2. The UNIQUAC model has been used by Coutinho [
13] to calculate the activity coefficient and been applied with the PR state equation and Wong–Sandler mixing rule to correlate the experimental data of CO
2 solubility in ILs. Cornelius [
14] evaluated solubility of CO
2 in ILs by using a model combined with quantum chemical calculation and a thermodynamics method.
Although the mechanism modeling methods can predict the solubility of CO
2 in ILs theoretically and accurately, they need to be supported by the mechanism knowledge of the real situations. The physical meaning of the system parameters of such mechanism modeling methods is relatively uncertain, and the calculation is complicated. The above two reasons lead to low prediction accuracy and poor model robustness [
15].
Due to the high interpolation and strong learning ability of the data-driven modeling methods without any assumptions between inputs and outputs, they have been widely used to predict the solubility of various gases in different solvents [
16,
17].
Mohammad [
16] used decision tree learning in modelling to predict the solubility of CO
2 in ILs, and the outputs of the model were in excellent agreement with the corresponding experimental values. Eslamimanesh [
17] utilized the artificial neural network (ANN) algorithm to predict the solubility of CO
2 in 24 commonly used ILs, which were successfully applied for the prediction. Farmani [
18] compared the ability of the ANN model and the EOS model to predict solid solubility in supercritical CO
2, and the results indicated the ANN model was able to more consistent with the experimental data. Lashkarbolooki [
19] developed the ANN to predict phase equilibrium behavior in binary systems that contain CO
2, and the prediction accuracy of the model was high. Afshin [
20] introduced the CMIS method to fuse all kinds of sub-models, and the obtained prediction results of CO
2 solubility in various ILs was in good agreement with the experimental values.
At present, most of the data-driven models which were established to predict the solubility of CO2 in ILs are single models. However, these models are prone to the local optimization and cannot describe the global characteristics of the problem. Therefore, the prediction performance of these models is limited.
In order to overcome the shortcomings of mechanism modeling and data-driven modeling in predicting the solubility of CO2 in ILs, a multi-model fusion modeling method combing the Back Propagation (BP), Support Vector Machine (SVM) and Extreme Learning Machine (ELM) sub-models is proposed. After applying proposed models to predict the solubility of CO2 in ILs the effectiveness of multi-model fusion models will be verified.
2. Methods
2.1. Single Modeling Method
2.1.1. Back Propagation Neural Networks
Back Propagation Neural Networks (BPNN) is a supervised learning method that simulates the perception of the world by biological neurons. The training process consists of forward propagation of signals and back propagation of errors. The input signal begins to diffuse from the input layer to the hidden layer and is output by the output layer after a series of processing [
21]. If the result of forward propagation yields the expected output, the learning process will be terminated. Otherwise, the weights and biases between different neurons will be adjusted layer by layer according to the gradient descent method till the expected minimum of the target function is reached. The BP neural network has high nonlinear mapping ability and flexible network structure. It has been widely applied in many fields of chemistry, chemical industry and economy that have a degree of difficulty and are complex to solve.
The approximation and generalization ability of the BP neural network model strongly depends on the samples [
22,
23]. The convergence velocity of the algorithm of the model is slow, and is easily trapped to a local optimum. In the process of establishing the BP neural network model, the undertraining and overtraining of model will affect the prediction effectiveness. Therefore, it is important to reasonably select the number of the hidden layers and neurons in each hidden layer [
24].
2.1.2. Support Vector Machine
Support Vector Machine (SVM) is a supervised learning method that is developed from statistical learning theory and is similar to neural network [
25]. The basic idea of this design is based on Vapnik Chervonenkis (VC) dimension theory and structural risk minimization principle. Under the finite sample information, the complexity and learning ability of the model are adjusted by constructing the loss function, and then the model with better prediction performance is established.
In the process of developing a support vector machine model, different kernel functions and non-linear mapping can map the input patterns into different higher dimensional linear feature space [
26,
27]. In order to obtain better performance of SVM models, it is necessary to select the kernel function type and optimize the relevant parameters of the kernel function reasonably. The commonly used kernel functions are polynomial kernel function, radial basis kernel function and sigmoid kernel function.
The expression of the polynomial kernel function is as follows:
Parameter
q represents the order of the polynomial.
The expression of the radial basis kernel function is as follows:
Parameter
σ represents the core width.
The expression of the sigmoid kernel function is as follows:
Parameter
v represents a scalar and
c displacement parameters.
The SVM model has advantages in solving non-linear, local minima and high dimensional pattern recognition and regression prediction problems. Although it shows certain robustness on sample sets and has little impact on the model when adding or removing samples, it is difficult to be applied to large training sets and has limitations on multi-classification problems.
2.1.3. Extreme Learning Machine
Extreme Learning Machine (ELM) is a new network learning algorithm based on an improved traditional neural network [
28]. The weights between input layer and hidden layer are generated randomly or artificially and the output weights are determined analytically during the learning process. It is a single hidden layer feed forward artificial neural network model without any adjustment. ELM can achieve better balance in terms of model learning speed, predictive stability, generalization and so on [
29,
30,
31].
When developing the ELM, reduction of computations and improvement of stability and accuracy of the model can be achieved, by changing the type of activation functions and the number of neurons in the hidden layer and optimizing the input weight and the bias of the hidden layer [
32]. Compared with the traditional algorithm, the ELM method is easy to use and theoretically achieve a globally optimum solution with much faster learning speed and good generalization capability. However, relevant parameters are given randomly, which may invalidate some hidden layer nodes and resulting in poor prediction of the model.
2.2. Linear Fusion Method
The part of the information of the predicted objects is usually included in the different types of sub-models. These information contributions are different to the fusion model, and there is some uniqueness. The basic idea of the multi-model fusion prediction method is to synthetically utilize the information provided by each sub-model. A multi-model fusion prediction model is established by the appropriate fusion method. It is expected that the more comprehensive prediction information will be contained in this model.
The commonly used sub-model fusion method is the linear fusion method. The reliability of weight coefficient is very important in improving the prediction accuracy and stability of the model. In this paper, two methods for calculating the weight coefficient are presented. The first method is to minimize the squared error. The optimization objective of this method is to minimize the sum of squares of errors between predicted and actual values. The weight coefficients of the fusion model are obtained by optimization. The second method is the information entropy method. The weight coefficient of the fusion model is determined by evaluating the prediction effects of each sub-model in the method.
2.2.1. Minimum Squared Error
The assumption is that there is a true value set {
yi} (
i = 1,2,…,
n), where
n is the total number of samples. To use the number of
m of sub-models to predict, propose the
yj,i (
j = 1,2,…,
m,
i = 1,2,…,
n) is the prediction value of the
i sample in the
j model, and the
ys,i is the prediction value of the
i sample in linear fusion model.
where parameter
ωj indicates the weighting factor of the
j sub-model in the linear fusion model and satisfies the following constraints:
where
es,i represents the absolute prediction error of the linear fusion model of the
i sample:
where
J denotes the sum of squared errors of the linear fusion model:
where
ω = (
ω1,
ω2, …,
ωm)
T indicts the weight column vector of the linear fusion model;
E = (
Ej,k)
m×m denotes the prediction error information matrix of the linear fusion model, when
j ≠
k,
Ej,k represents prediction error covariance between the
j and
k models, and when
j =
k,
Ej,k represents sum of squared errors of the
j model.
Minimizing the sum of squared prediction errors of the linear fusion model is the objective function. Then, the model calculating the weight can be transformed into a nonlinear programming model:
where
Rm×1 represents column vectors whose elements is all one.
By solving Equation (8), the formula for calculating the weight in the linear fusion model is obtained as follows:
The optimal value of the corresponding objective function is:
2.2.2. Information Entropy
The entropy in thermodynamics is a measure of the degree of disorder of the system. The information entropy in information theory is a measure to describe the degree of order of the system. Therefore, the absolute values of the entropy and information entropy are equal but the values are opposite to each other [
33]. A system may have different states, and the assumption is that the
Pi (
i = 1, 2, …,
n) is the probability of the occurrence of the
i state, then the information entropy in the system is:
From the viewpoint of information entropy, it is based upon the variations of the prediction error of each sub-model and takes into account the differences and error factors among sub-models. The information entropy method can be used to compute the weight coefficient of the linear fusion model. The smaller the variation of information, the larger the weight coefficient of the sub-model in the linear fusion model.
The relative prediction error of the
i sample in the
j sub-model is
Rej,i:
The ratio of
Rej,i to the total relative prediction error of
n sample is as follows:
The information entropy value of relative prediction error of the
j sub-model is:
The coefficient of variation of the relative prediction error of the
j sub-model is:
The weighting coefficient calculation formula of the
j sub-model is:
2.3. Implementation Steps
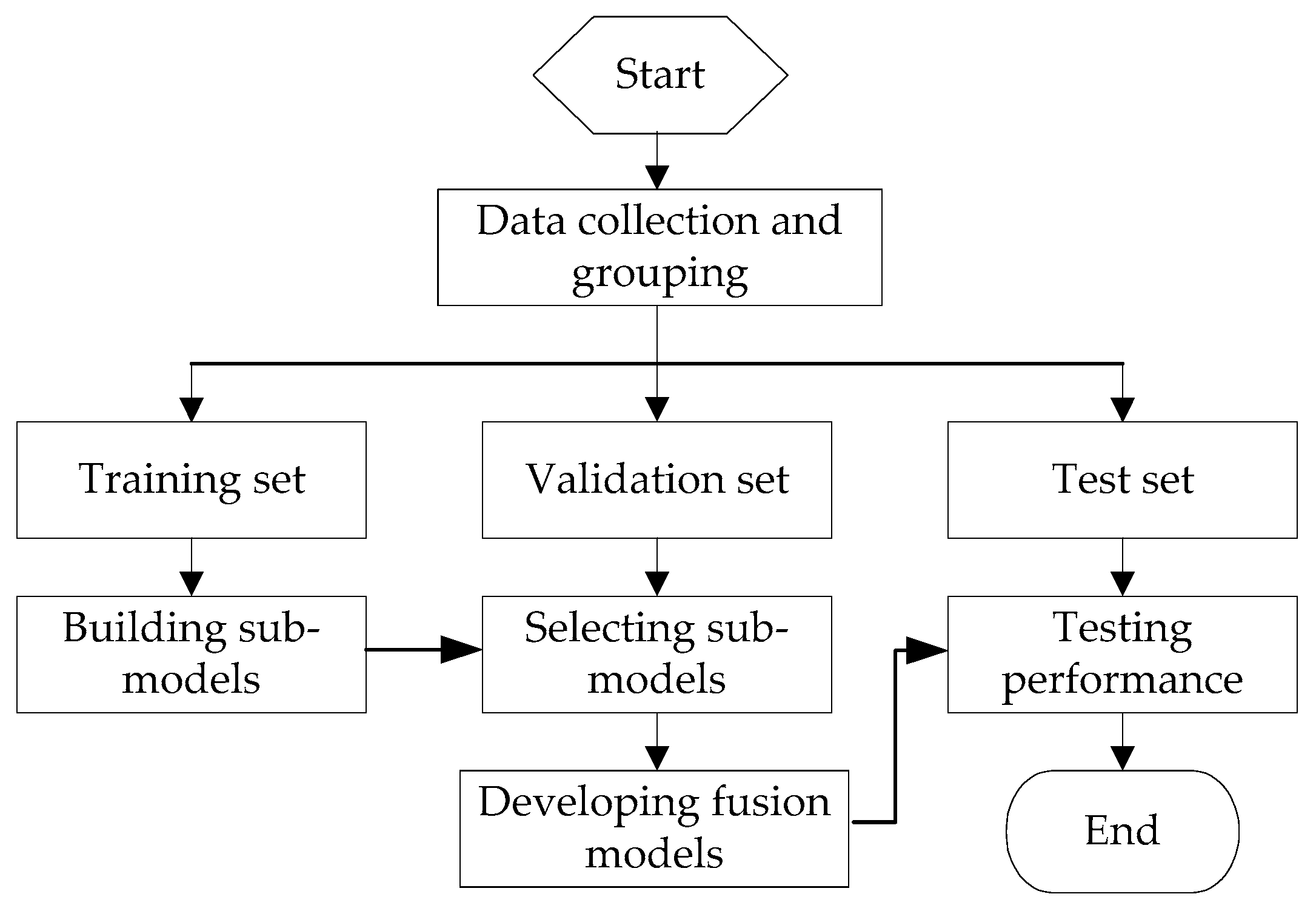
The preferred BP neural network, support vector machine and extreme learning machine sub-models are used to establish the prediction model by linear fusion method. This process is divided into three steps including data collection and grouping, sub-model training and evaluation, fusion model developing and testing. The implementation process is shown in
Figure 1.
The implementation steps are as follows:
(1) Data collection and grouping
According to the modeling requirements, the dataset for modeling is collected. The whole dataset is divided into a training set (X1), validation set (X2) and test set (X3) in the appropriate proportion. The training set (X1) is selected in a way that covers all the ranges of the experimental data and operating conditions.
(2) Sub-model training and evaluation
The implementation process of sub-model training and evaluation is shown in
Figure 2. Different types of sub-models are developed through training sets (
X1). The BP sub-models (BP-ANN
1, BP-ANN
2, …, BP-ANN
m) are established by changing the number of hidden layer nodes. The different types of kernel functions are chosen to develop SVM sub-models (SVM
1, SVM
2, …, SVM
n). Based on different hidden layer neurons and iterative functions, the ELM sub-models (ELM
1, ELM
2, …, ELM
k) are built. The model parameters are optimized by genetic algorithm (GA) to obtain the best results for each model.
The prediction performances of each sub-model are evaluated by using the validation set (X2). According to the performance indicators of the validation set, the optimal sub-models are selected from the same kind of sub-models. Then, three optimal sub-models are obtained, which are BP-ANNOpt, SVMOpt, ELMOpt.
(3) Fusion models developing and testing
The implementation process of the fusion model development and testing is shown in
Figure 3. The parameters
w1,
w2 and
w3 represent the combination weight of three optimal sub-models, respectively. The weight of the three sub-models is calculated by the method of minimum square error (Equation (9)) or the information entropy method (Equation (16)) separately. Then, the two linear fusion models are established. Finally, the prediction performance of the built linear fusion models are tested using the test set (
X3).
4. Conclusions
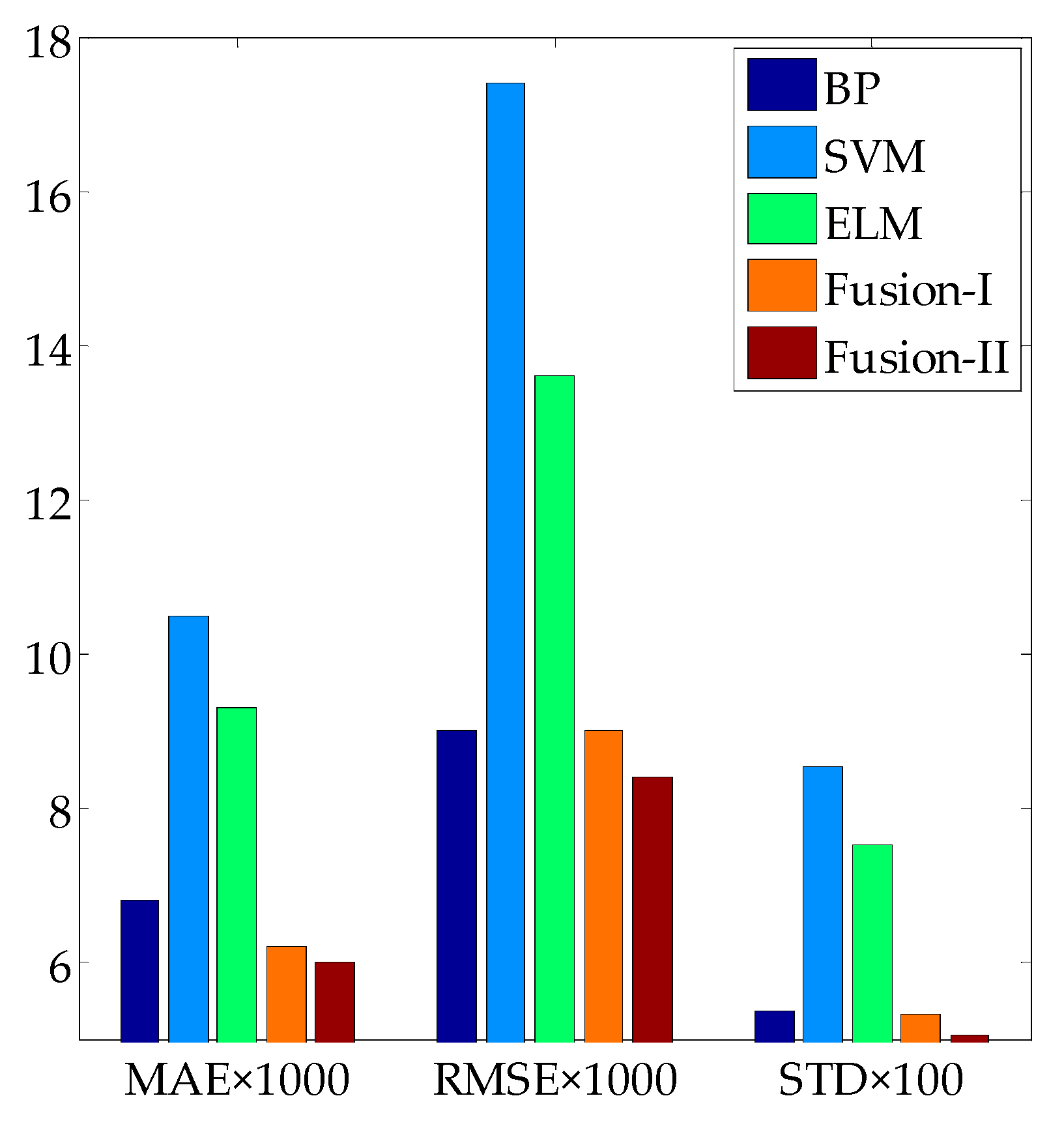
In this paper, a fusion modeling method was proposed for predicting the solubility of CO2 in ILs. Firstly, 544 sets of samples from nine ILs were collected from the literature, and divided into a training set, validation set and test set according to a certain proportion. The sub-models of the BP neural network, SVM and ELM were established by using the training set. Among them, three sub-models with the optimal evaluation performance were selected by using the validation set. Then, the linear fusion models were established by using the minimum square error method and the information entropy method, respectively. Finally, the test set was used to test the prediction performance of the linear fusion models and optimal sub-models. The results show that the prediction effect of the linear fusion model is better than other single sub-models. Furthermore, the prediction effect of the linear fusion model based on the information entropy method is better than based on the minimum square error method.
Although the prediction model established by the fusion modeling method has a good prediction effect of nine imidazole ionic liquids in the paper, it may not be suitable for the prediction of the solubility of other ILs in CO2. Nonetheless, the fusion modeling method solves the shortcomings of being time-consuming, high cost of experimental measurement and the complexity and generalization of mechanism model. It provides an effective method for predicting the solubility of CO2 in the ILs, and also can be considered as a new method for prediction of different thermodynamic properties.










{kind=link}
{kind=link}
{kind=link}
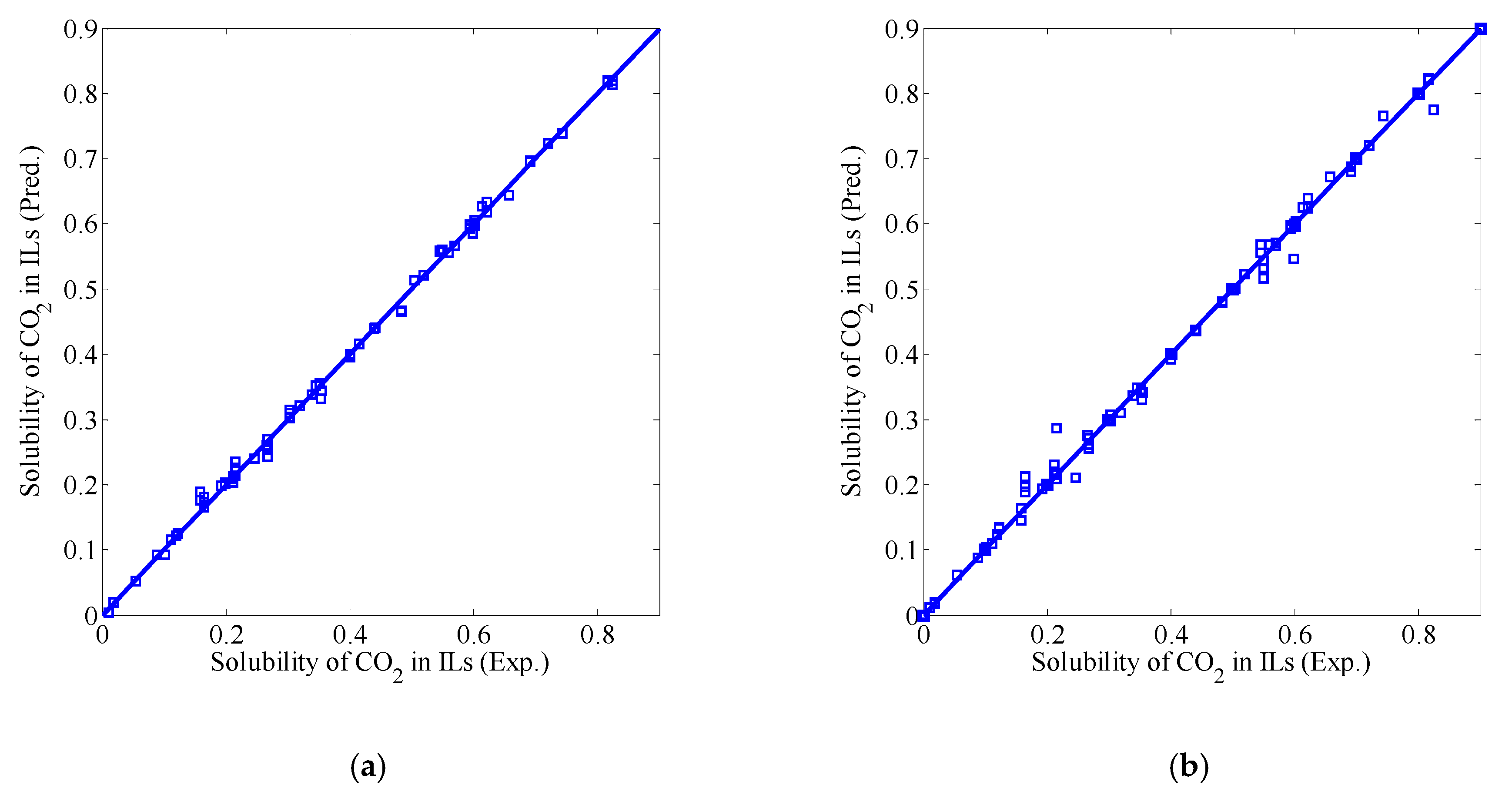{kind=link}
{kind=link}
{kind=link}
{kind=link}