1. Introduction
Biodiesel, a renewable energy source, is gaining prominence as the world seeks sustainable alternatives to fossil fuels. Its production, derived from natural sources such as vegetable oils, animal fats, and recycled greases, has grown significantly in recent years [
1]. This increase is primarily driven by global commitments against climate change and the push towards greener energy sources. The production process of biodiesel involves transesterification, where fats and oils are converted into fatty acid methyl esters. An often-overlooked by-product of biodiesel production is glycerin. For every ten pounds of biodiesel produced, approximately one pound of glycerin is generated [
2]. Despite being a by-product, glycerin holds immense value in various industries. However, the glycerin produced typically contains impurities and contaminants, necessitating purification to meet quality standards. This purification process, which removes unwanted substances such as water and fatty acids, faces challenges due to a limited operating domain and a narrow control range. These constraints hinder its ability to effectively and efficiently remove the wide array of impurities found in glycerin by-products from biodiesel production, posing a significant challenge in consistently producing high-quality glycerin [
3].
Accurately predicting process efficiency is crucial, especially under operating conditions that extend beyond the standard monitoring range. This complexity raises challenges in determining controller actions to compensate for process disturbances while ensuring the desired product quality is maintained [
4]. A prime example is observed in glycerin purification. Critical factors such as the composition of the feed stream, the water-to-glycerin ratio, the performance of the evaporation unit, and adjustments to manipulated variables in the distillation column must be meticulously managed. These adjustments are necessary not only to maintain the quality of refined glycerin but also to ensure that the controller actions are effective within the unit operation constraints.
Expert engineers frequently modify these conditions, relying on their specialized knowledge and on-site experimental data [
5]. However, the limited scope of most operating variables can often hamper the efficiency of glycerin purification. The complexity of the process increases due to the multitude of variables influencing operating conditions, which can lead to process instability [
6]. Consequently, this challenge has led researchers to turn their focus toward utilizing artificial intelligence (AI) and data-driven techniques [
7]. These methods offer the ability to analyze large datasets, identify patterns, and make predictions or real-time decisions using the information provided [
8]. Even if the prediction skill of the AI-based method is high, the result can be deviated by multiple characteristics of process operation [
9].
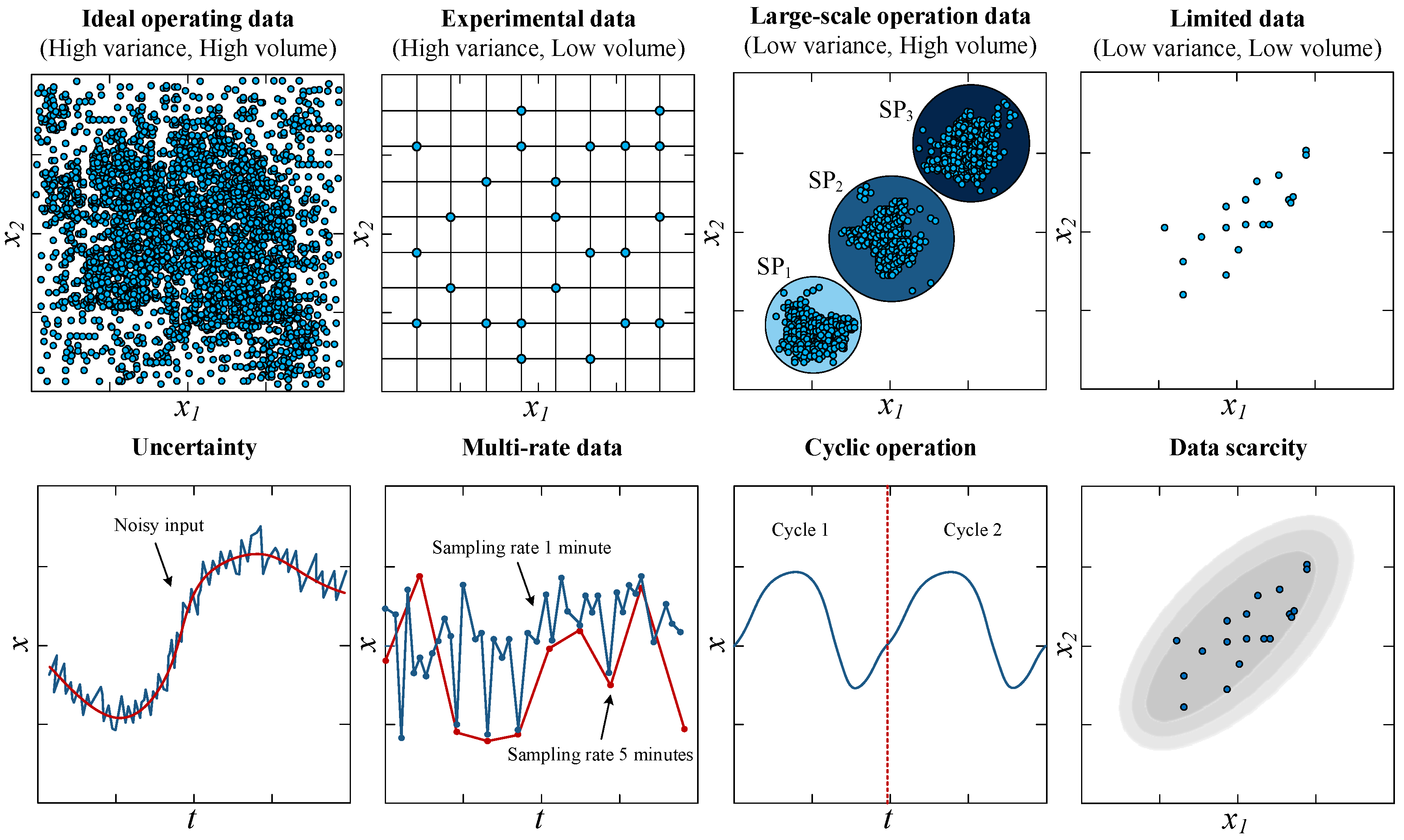
In chemical process optimization, data can be categorized by two criteria: variance/volume tradeoff and challenges from the data characteristics, as illustrated in
Figure 1. In the case of the variance/volume tradeoff, the ‘Large-scale operation data’ exemplify a limited operating domain, with datapoints predominantly clustered around the setpoint, indicating a narrow focus on operational conditions under normal circumstances with high volume and low variance. Conversely, the ‘Limited data’ represent a limited amount of data, with sparse datapoints reflecting rare yet significant operational states that are critical to process stability and quality. The dearth of data in both cases—the limited operating domain and the limited number of available datapoints—not only poses substantial challenges for process monitoring and control, especially when it comes to adapting to and managing deviations that fall outside the usual operational parameters, but also makes the prediction model unreliable outside the experienced domain. On the other hand, when considering challenges from data characteristics, four commonly found problems are uncertainty, multi-rate information, cyclic operation, and limited data [
10].
Researchers have proposed multiple innovative techniques to resolve these challenges. Regarding uncertainty, Panjapornpon et al. introduced a deep learning model constructed using a compensation architecture for energy optimization that addresses measurement uncertainties [
11]. Similarly, Wiebe, Cecilo, and Misener integrated data-driven stochastic degradation models with optimization strategies, using robust techniques to manage uncertainties in equipment degradation. Lastly, Moghadasi et al. proposed a gradient-boosting machine with the density-based spatial clustering of applications with noise to optimize steam consumption in the gas sweetening process [
12]. These contributions show that the advancement of the data-driven method can be significantly useful in resolving the challenges facing industrial processes. However, a common thread among these techniques is their reliance on large datasets. The integration of data cleaning methods and network architecture modification can remove the contribution made by process disturbances, but it requires a lot of training information, as well as careful tuning of the network parameters, to ensure that the resulting model accurately reflects the underlying system dynamics without being overly influenced by noise or irrelevant data [
13]. This approach typically involves iterative refinement of both the data preprocessing steps and the network architecture to strike a balance between the model complexity and generalization ability [
14].
When encountering complex scenarios such as in the chemical industry, the framework of the AI-based model may change according to the challenges that the research focuses on [
15]. Han et al. proposed a feed-forward neural network (FNN) with data envelopment analysis (DEA) for the optimization of ethylene production [
16]. The integration of DEA with a deep learning model can help in optimization, but based on its architecture, the network might not effectively capture all nonlinear relationships. This can be resolved using the recurrent neural network, such as long short-term memory (LSTM) [
17]. The network has a recurrent interval state that helps in handling the long-term dependency found in the data [
18]. The performance of the LSTM network can be enhanced by integrating with an attention mechanism (AM). AM-LSTM is particularly useful in tasks where the sequence is long and not equally important along the sequence, by allowing the network to weigh diverse parts of the input differently [
19]. However, despite these advancements, AM-LSTM networks still face challenges in terms of adaptability and scalability, particularly when dealing with limited data scenarios, both in terms of quantity and domain-specific data. To resolve this issue, Han et al. proposed a hybrid approach using Monte Carlo (MC) simulation to expand the working domain of the LSTM network [
20]. By simulating a wide range of possible scenarios, the MC-LSTM model can effectively deal with limited data situations. Since it provided an improvement, it is important to note that MC simulation is inherently probabilistic, relying solely on random sampling techniques. The integration of digital twin technology offers a more holistic and accurate simulation [
21]. Digital twins create dynamic virtual representations of physical systems, allowing for more detailed and realistic scenario modeling while perfectly eliminating limited data problems [
22]. Based on the aforementioned literature, an overview of research on AI applications in production capacity analysis is presented in
Table 1 where several research gaps can be identified:
Adaptability to limited and sparse data: Existing models, including advanced neural networks, often require large datasets for training. This necessity poses a challenge in scenarios where data are sparse or limited, as is common in chemical process optimization.
Improvement beyond Monte Carlo simulations: While the MC-LSTM model represents an advancement in dealing with limited data scenarios, the reliance on probabilistic, random sampling techniques indicates a gap. Exploring alternatives or enhancements to Monte Carlo simulations that offer deterministic modeling approaches could provide more reliable and accurate predictions.
Integration of digital twin technology: The introduction of digital twin technology for more accurate scenario modeling is a promising direction. However, the seamless integration of this technology with AI-based models, particularly in optimizing the chemical process and production capacity, remains a gap.
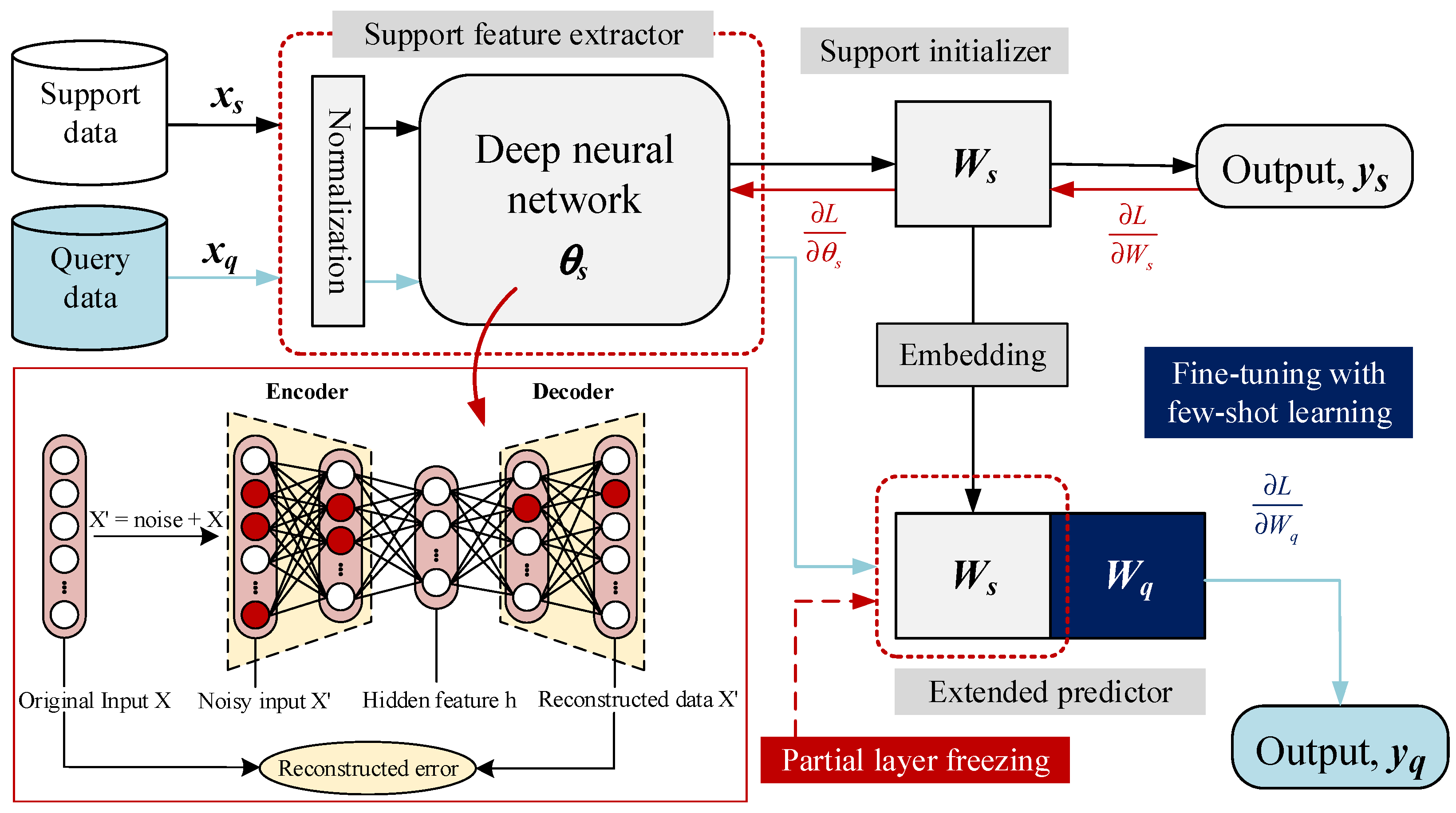
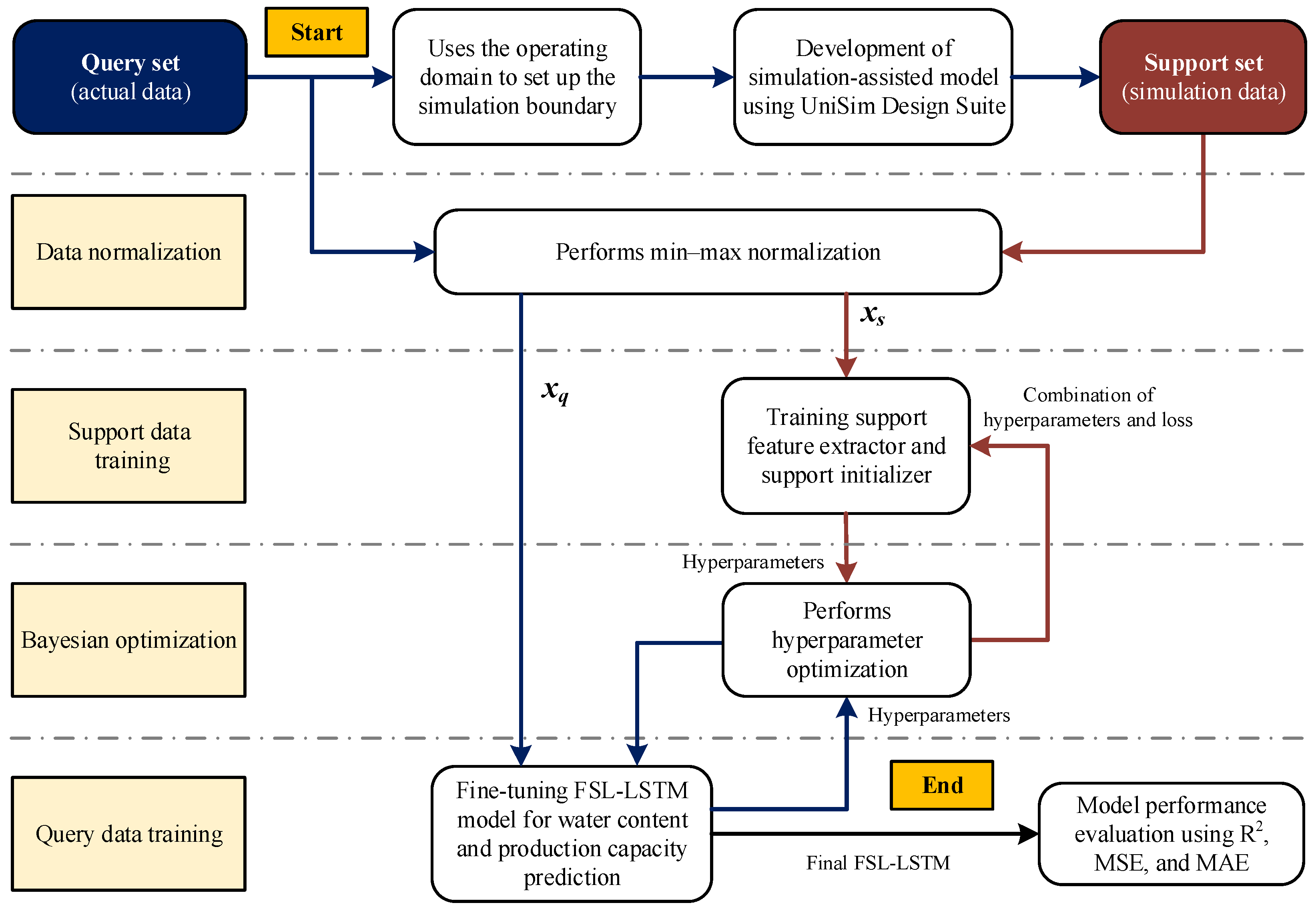
Therefore, this study proposes a model development framework using LSTM with simulation-assisted few-short learning (FSL-LSTM) for predicting and optimizing the glycerin product purity of the glycerin purification process and water removal of the evaporating unit under feed uncertainty and limited data. The model is trained to create a support feature extractor and weight initializer using a simulated support set, which is then used to fine-tune the prediction model in the limited data domain using a query set obtained from the large-scale glycerin purification unit. The main contribution of the proposed procedure is summarized as follows:
Develop a glycerin purification process simulation model to determine optimal operating conditions and generate data for the support set.
Formulate a robust predictive model based on deep learning constructed using LSTM structure fine-tuning based on few-shot learning techniques for tracking the refined glycerin production capacity and water content of refined glycerin under multiple operating conditions.
Reveal the relationship between the input variables and the target variables of the prediction model to enhance the production capacity and water content using the proposed model.
The remainder of this work is divided into the following sections:
Section 2 explains the concept of modeling procedures in developing FLS-LSTM, which includes few-shot learning, LSTM architecture, and Bayesian optimization.
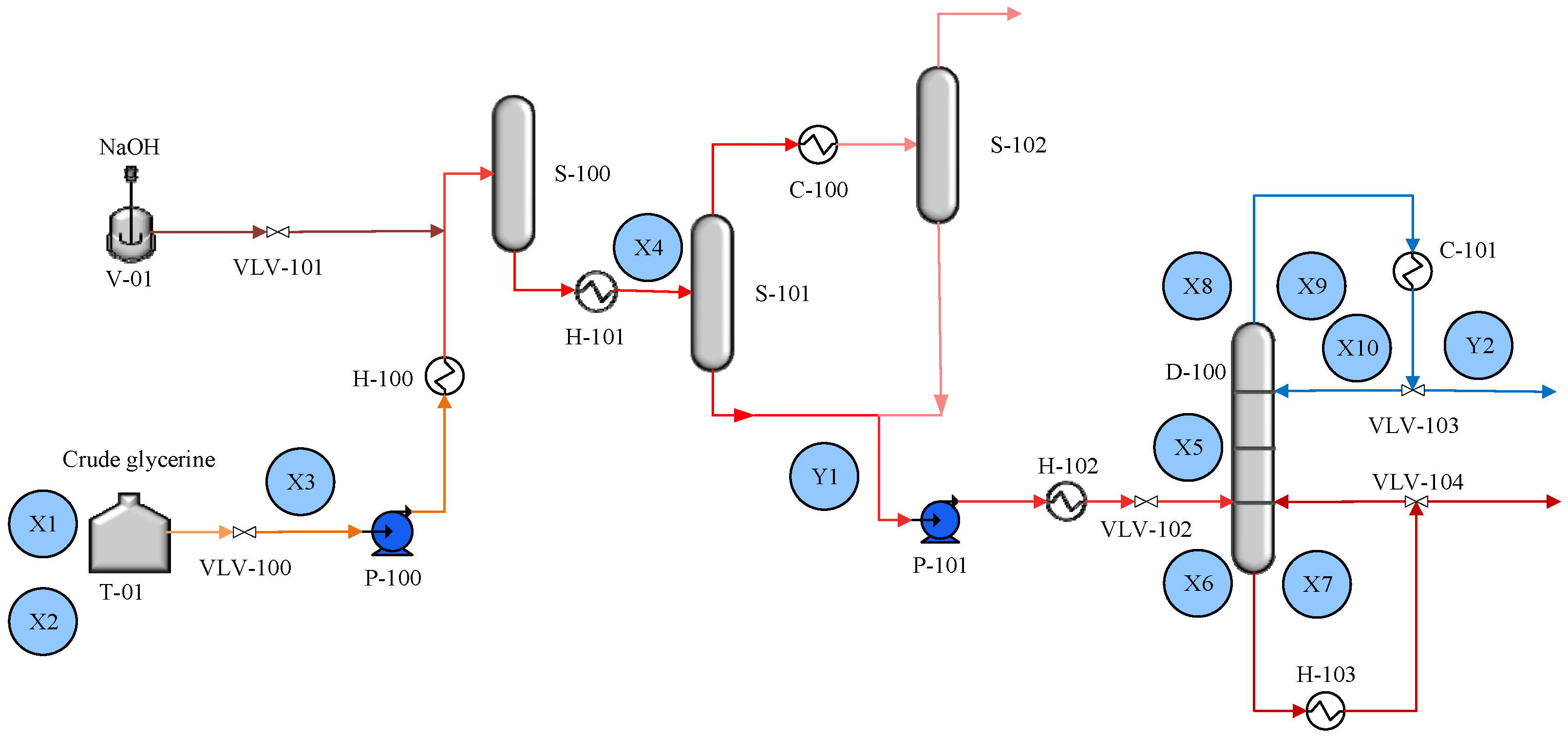
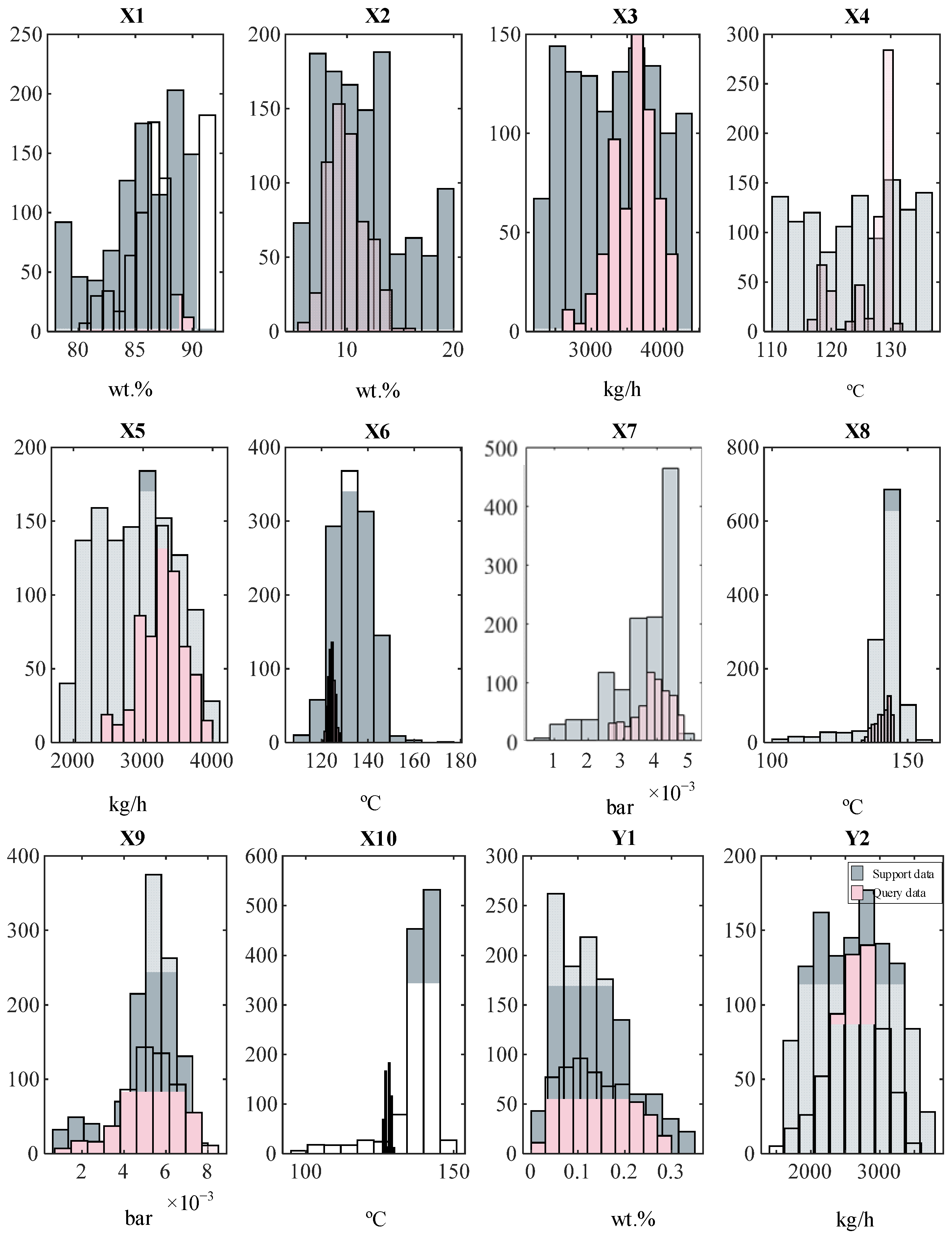
Section 3 presents the case study utilized in this study, incorporating a system description and comparative analysis of support and query data.
Section 4 shows the performance of the proposed model in predicting glycerin production and water content, the accuracy–iteration tradeoff, and the production optimization results. Finally, conclusions are drawn in
Section 5.
4. Result and Discussion
4.1. Water Content and Production Capacity Prediction Result
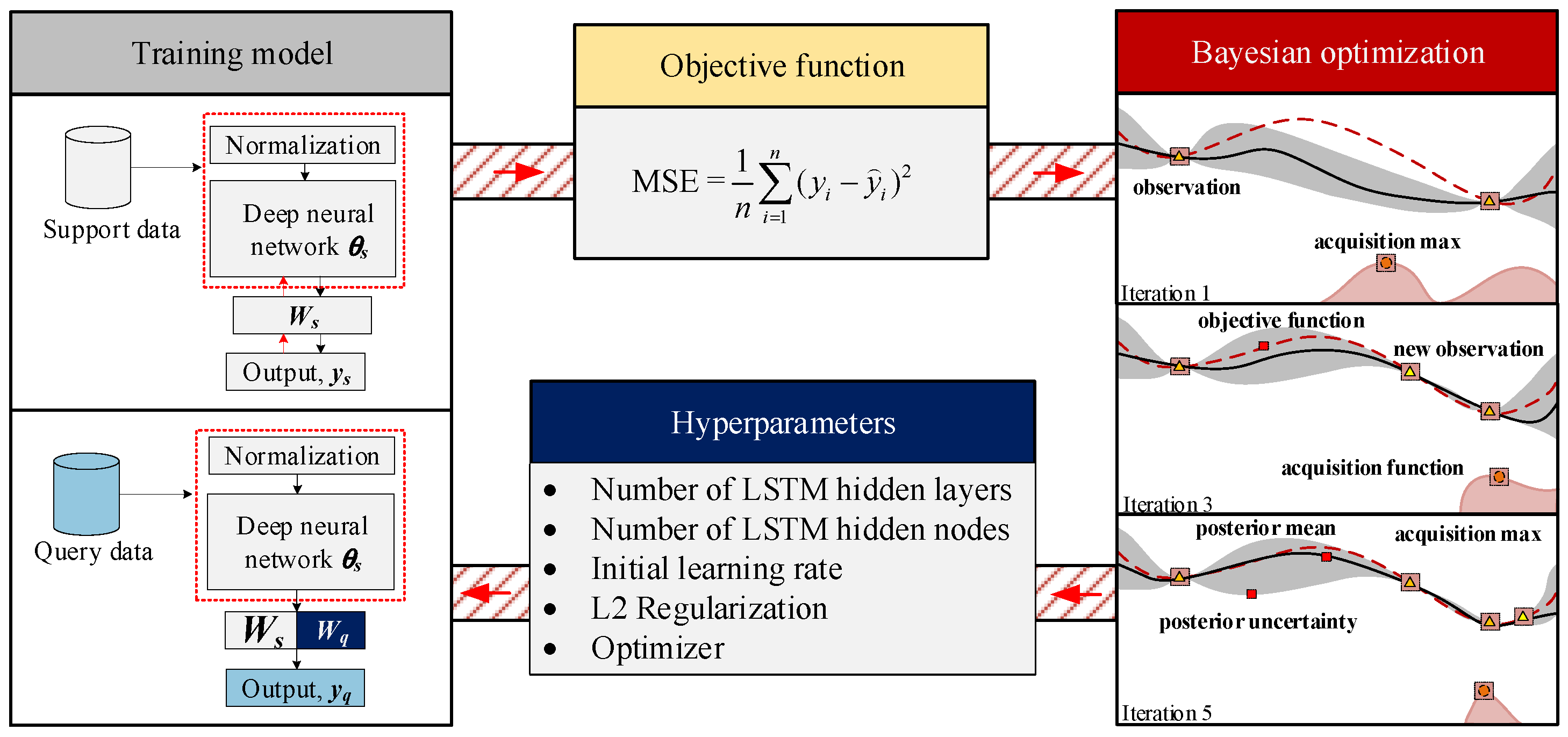
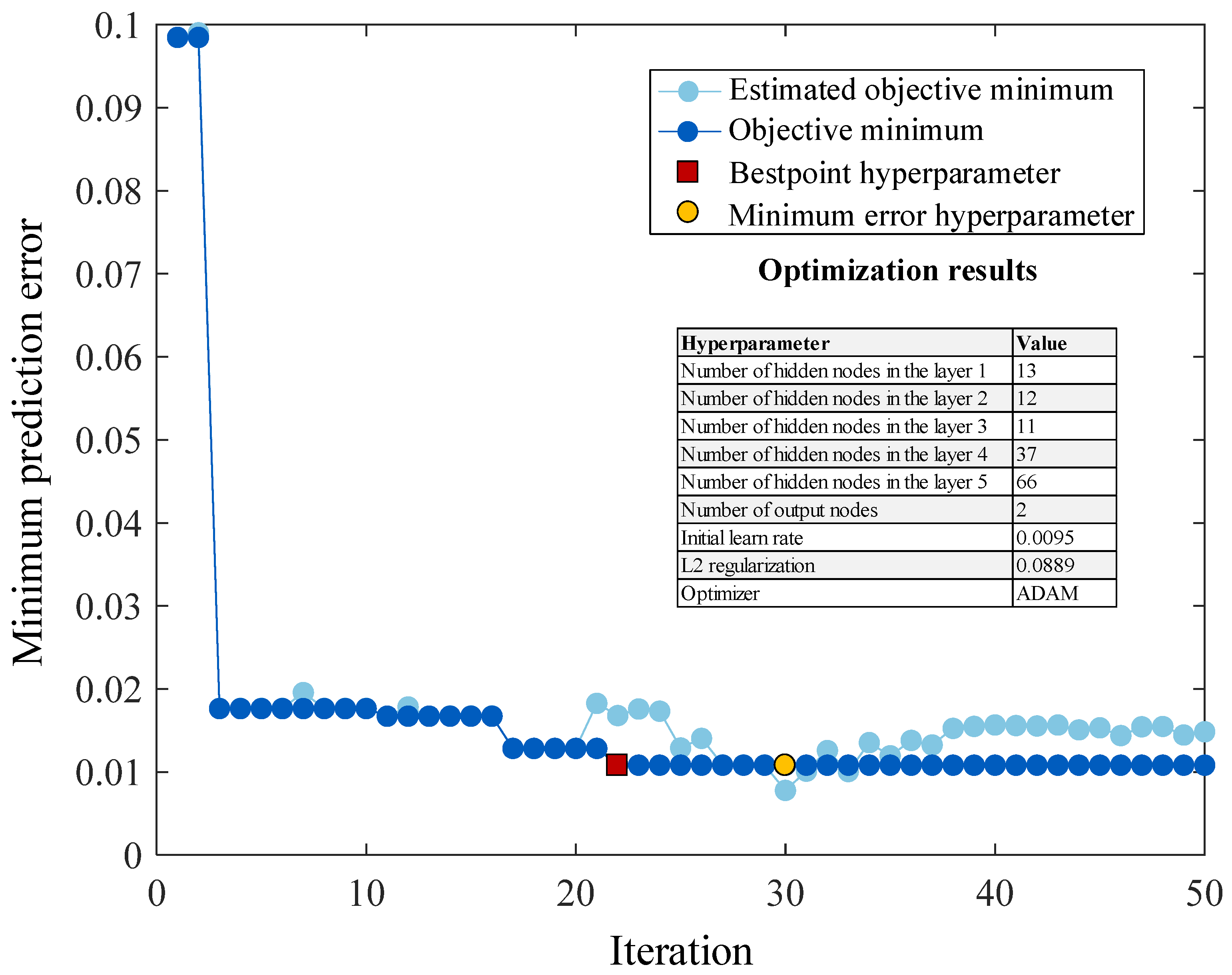
The hyperparameter optimization applied to the FSL-LSTM using nine selected hyperparameters is shown in
Figure 9. These optimized hyperparameters, chosen for observation, include the number of hidden layers, the number of hidden nodes, the initial learning rate, the L2 regularization, and the optimizer. As the number of iterations increases, the prediction error steadily decreases. This ongoing reduction indicates that the optimization process is effectively identifying better hyperparameter combinations. Notably, the FSL-LSTM model, after hyperparameter optimization, exhibits a significant decrease in the minimum prediction error. This error drops from 0.1 to 0.02 as early as iteration 2 and remains stable until reaching its lowest point, 0.0149, at iteration 22. This minimum error value lies close to the estimated objective minimum line, further validating the effectiveness of the optimization approach. The best set of hyperparameters is located at 22 iterations. One essential point is that the optimal value for the learning rate is 0.0095. Furthermore, the remarkably low learning rate of 0.0095 highlights the importance of carefully adjusting the model’s pre-trained knowledge during fine-tuning. This minimal step size helps safeguard the valuable information encoded in the initial model, allowing it to serve as a strong foundation for learning task-specific details without causing a catastrophic forgetting of its general capabilities. This reflects that the pre-trained knowledge gained from the support data significantly helps the model during the training phase.
The comparative results of water content prediction focusing on the testing performance of the model are presented in
Table 6: the performance accuracy of the testing model of water content. The FSL-LSTM model demonstrates a notable R
2 value of 0.995, thereby evidencing its superior predictive accuracy compared to other traditional models: 0.793 for FNN, 0.204 for RNN, 0.149 for NARX, and 0.801 for LSTM. The result demonstrates that the FSL-LSTM provided a 24.2% improvement in R
2 values in the case of the LSTM with custom few-shot learning. When comparing the performance of advanced LSTM models, the AM-LSTM and MC-LSTM also show substantial predictive accuracy, with R
2 values of 0.918 and 0.849, respectively. The FSL-LSTM, however, surpasses the AM-LSTM with an R
2 value improvement of 8.3%, underscoring the significant impact of the few-shot learning approach in refining predictive performance. The FSL-LSTM model, which employs a digital twin to generate data, shows a 17.2% improvement in R
2 value over the MC-LSTM. This suggests that the synthetic data generated from the digital twin, when combined with real-world fine-tuning, result in a model that is not only robust but also highly precise in its predictions.
The effectiveness of the proposed model is further revealed by MAE values of 0.017, thereby surpassing the MAE values of FNN, RNN, NARX, LSTM, AM-LSTM, and MC-LSTM, which have MAE values of 0.038, 0.099, 0.105, 0.043, 0.0051, and 0.037, respectively. In comparison to traditional LSTM, incorporating few-shot learning fine-tuning with a simulation-assisted model reduced errors by 60% up to 83% when compared to other models in the study. Additionally, in the case of MSE values, the FSL-LSTM model records a minimal MSE value of 0.001, markedly lower than those recorded by FNN (0.009), RNN (0.067), NARX (0.075), LSTM (0.009), AM-LSTM (0.004), and MC-LSTM (0.004) with an error reduction of up to 98%.
Table 7 shows the comparative analysis for the glycerin production prediction using a testing dataset of glycerin production predictions. The FSL-LSTM model attains an R
2 value of 0.895, outstripping FNN (0.541), RNN (0.309), NARX (0.397), LSTM (0.498), AM-LSTM (0.562), and MC-LSTM (0.572), which is a 79.7% improvement in R
2 values compared to the traditional LSTM. Additionally, the R
2 performance improvement for the glycerine production prediction is higher than the improvement in water content.
In evaluating the MAE loss variable within this context, the FSL-LSTM model records an MAE of 0.050, a value that is demonstrably lower than those recorded by FNN (0.054), RNN (0.056), NARX (0.055), LSTM (0.057), AM-LSTM (0.138), and MC-LSTM (0.052). Despite the marginal disparities among the training models, the FSL-LSTM model exhibits a significantly reduced MAE value, exhibiting a 12.2% error reduction. Conclusively, the MSE evaluation of the model for production capacity further corroborates the superiority of the FSL-LSTM model. With an MSE value of 0.006, it presents a notable error reduction of 50% compared to the LSTM model.
Figure 10a shows the predicted glycerin production capacity values from three different training models: the LSTM model, the FNN model, and the FSL-LSTM model, compared with the actual values (represented by a black line). Among these, the FSL-LSTM model (indicated by a red line) most accurately simulates changes in production capacity, closely aligning with the actual values. In contrast, the predictions from the LSTM model (shown in dark red) and the FNN model (depicted in orange) are less accurate, as evidenced by the divergence of their respective lines from the actual values, where the FSL-LSTM can track the abrupt process transition in changing production capacity.
Figure 10b focuses on the prediction performance of water content using FSL-LSTM. Here, the FSL-LSTM model is again notable for its accuracy, with its predictions (red line) closely mirroring the actual values. The LSTM model, while capable of capturing some characteristics of the actual data, falls short of the performance demonstrated by the FSL-LSTM model. Even in the water content prediction, where the noise in the process is relatively larger than the glycerin production prediction, the FSL-LSTM can accurately predict the water content under this scenario.
4.2. Domain-Specific Testing Result Using Unseen Data
Table 8 provides an overview of the robustness of the FSL-LSTM model when assessing its performance on data that extends beyond the training domain. The ‘simulated’ category denotes scenarios that have never been operated before in real operational data. In this case, the model exhibits an outstanding predictive accuracy for water content, with an R
2 of 0.992 and a minimal MSE of 0.0004. For glycerin production under the same conditions, the predictive strength of the proposed model is further underscored by an even higher R
2 of 0.994 and a low MSE value of 0.0003.
When the ‘actual’ operational data, which are not fundamental simulation knowledge from the digital twin and lie outside the training domain, are considered, the performance of FSL-LSTM is slightly decreased in the water content prediction task. The impact is more pronounced in the case of glycerin production prediction, where the R2 value decreases to 0.790. This reduction is not extreme when considering the high benchmark set by the model in normal testing scenarios, where an R2 of 0.895 was achieved. The decrease in R2 can be attributed to the model grappling with unique operational scenarios presented by the actual data that extend beyond its trained and simulated experience. Despite this, it is important to note that the performance of the FSL-LSTM model, even with these limitations, remains higher than other methods evaluated under normal testing conditions. This suggests that while the reduction in performance is discernible, it is relatively slight, and the model maintains a degree of predictive resilience that surpasses conventional approaches.
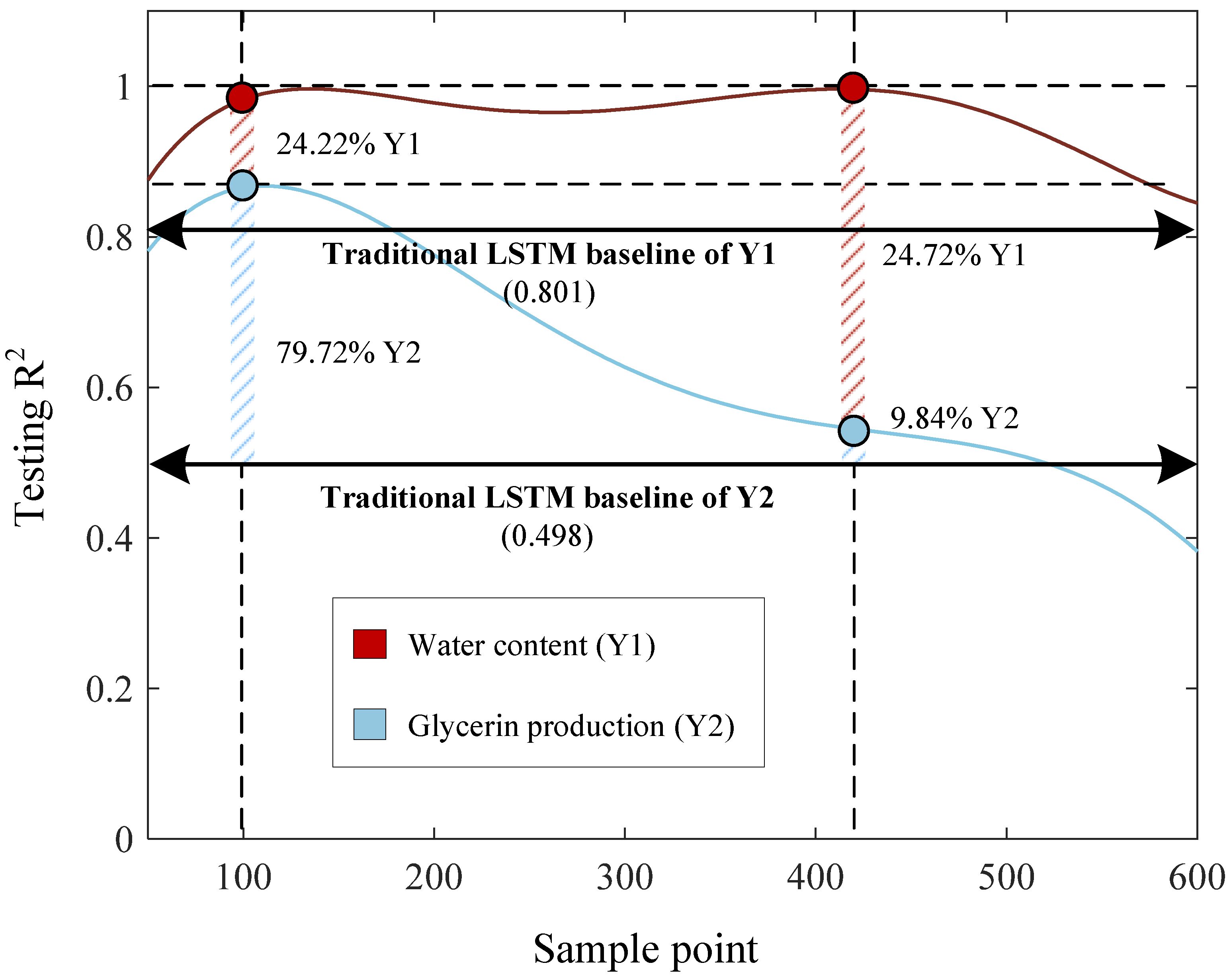
4.3. Accuracy–Iteration Tradeoff in Few-Shot Learning LSTM
Figure 11 shows the result of decreasing and increasing the number of iterations in few-shot learning techniques. The model selection of FSL-LSTM is determined by the tradeoff between accuracy improvement among two outputs. The best number of iterations is obtained at two locations on this plot, 100 (maximum testing R
2 of glycerin production is located) and 440 iterations (maximum testing R
2 of water content is located). At 100 iterations, the testing R
2 values of Y1 and Y2 are 0.995 and 0.895, respectively, while the traditional LSTM performances without fine-tuning using few-shot learning are 0.801 for Y1 and 0.498 for Y2. The decision on accuracy–iteration in few-shot learning is determined by the percentage of relative improvement (RI), which is calculated using Equation (20).
Denoted by the is the testing R2 value of Y1 or Y2 from the few-shot learning, and is the testing R2 value of Y1 or Y2 from the traditional LSTM baseline. Calculating the RI value is an essential step in assessing the performance gains achieved by the FSL-LSTM model over the traditional LSTM baseline, which provides a quantifiable measure of improvement in predictive accuracy.
At maximum testing R2 of glycerin production, this point provided a 24.22% improvement in water content prediction and a 79.72% improvement in glycerin production over the LSTM baseline. Furthermore, at 440 iterations, the R2 value of testing data for Y1 is 0.999, while for Y2 it is 0.547. At this point, the few-shot learning significantly improved the performance in water content prediction by up to 24.72%. However, the large improvement in Y2 results in an overfitting problem in Y1, where the testing performance drops substantially with only a 9.84% improvement. Thus, the justification of iteration count should be made with a primary focus on glycerin production prediction performance, and in this context, 100 iterations (one datapoint per iteration) prove to be the optimal selection for few-shot learning with FSL-LSTM.
4.4. Production Optimization Results
After the FSL-LSTM is finally tested for its ability to track water content and glycerin production, an operating condition adjustment is performed on the model to find the optimal condition for the glycerine purification process based on the prediction sensitivity. For example,
Figure 12a shows the operational adjustment result for optimizing water content without changing glycerine production capacity. It can be seen that if X1 and X3 are increased by 0.46 and 0.7 while X9 is reduced by 0.07, the water content of the final glycerin product can be reduced by 0.35. The system manipulation of the feed composition and operational pressure enhances the separation efficiency, minimizing the need for excessive heat and mitigating the thermal stress on the distillation equipment. Operating the column under conditions that avoid extremes in temperature and pressure variations fosters process stability, lowering the risk of overpressure incidents.
In
Figure 12b, there are optimization results for production maximization while the final water content remains constant. This can be performed by reducing X1, X3, X6, X9, and X10 by 0.83, 0.69, 0.4, 0.23, and 0.09, respectively, and increasing X5 by 3. The production of glycerin will be improved by 0.34. The significant gap in X5 indicates a potential underutilization of the existing distillation unit due to unused capacity within the column internals. Overall, these results illustrate the effectiveness of the FSL-LSTM model in guiding targeted operational adjustments for the glycerin purification process under limited operating data and working domains. Lowering the bottom temperature of the column implies that the energy supplied to vaporize the feed is minimized, which can both reduce the thermal degradation of heat-sensitive components such as glycerin and decrease the energy consumption of the separation process.
In aiming to optimize both glycerin production and water content, an increase in the distillation column feed rate and adjustments in temperature at strategic points of the process highlight the ability to enhance both productivity and product purity, as shown in
Figure 12c. However, adjusting X1 and X3 has counteracting effects on Y1 and Y2. Increasing X1 and X3 actually leads to a reduction in Y1, as a richer glycerin feed and increased feed mass flow effectively decrease the remaining water content in the final product. Conversely, reducing X1 and X3 can lead to an increase in Y2, facilitating a more manageable load on the distillation system. Considering these counteracting effects, other operational variables become a strategic approach. According to
Figure 12c, increasing X5 (by 1.1), X6 (by 0.4), and X9 (by 0.329) while reducing X10 (by 0.194) offers a path to optimize the distillation conditions for both separation efficiency (by 0.64) and production capacity (by 0.35). By boosting X5, the throughput of the distillation column is increased, directly contributing to a higher production capacity, while the precise increase in X6 and X9 enhances the vaporization dynamics and condensation dynamics, improving the separation of glycerine from water. Simultaneously, the reduction in X10 aims to optimize energy efficiency and further refine the separation process by carefully managing the thermal conditions. The adjustment ensures that the process not only meets its production goal but also improves product purity, illustrating a sophisticated balance between process efficiency, energy consumption, and product quality in the face of complex operational tradeoffs.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
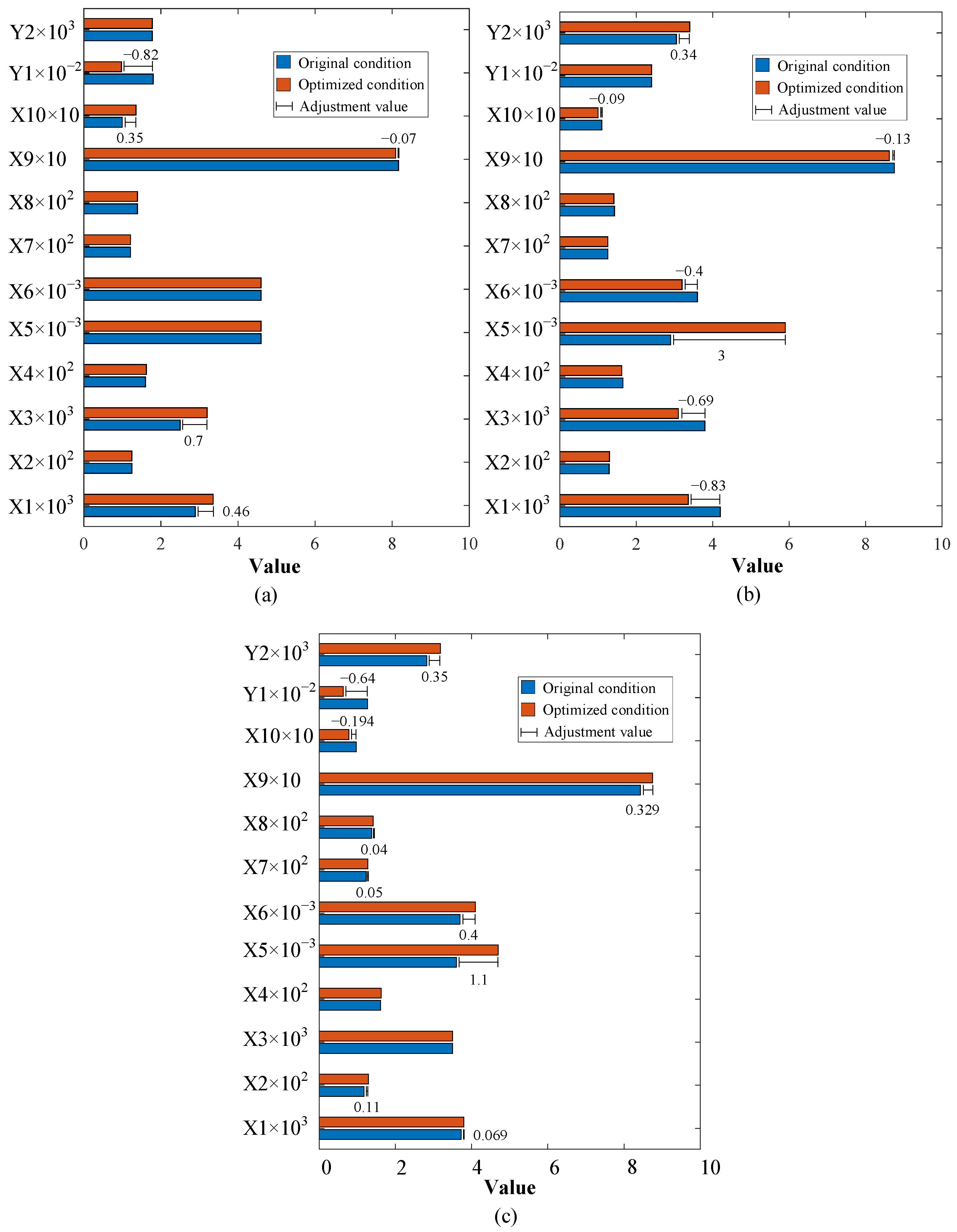{kind=link}