
Prediction of Energy Consumption in a Coal-Fired Boiler Based on MIV-ISAO-LSSVM

Abstract
:1. Introduction
2. Improved Snow Ablation Optimizer
2.1. Snow Ablation Optimizer
- (1)
- The exploitation phase
- (2)
- The exploration phase
2.2. Algorithm Improvement Strategy
- (1)
- Tent map
- (2)
- Adaptive t-distribution
- (3)
- Opposites learning mechanism
- (4)
- Quick search strategy
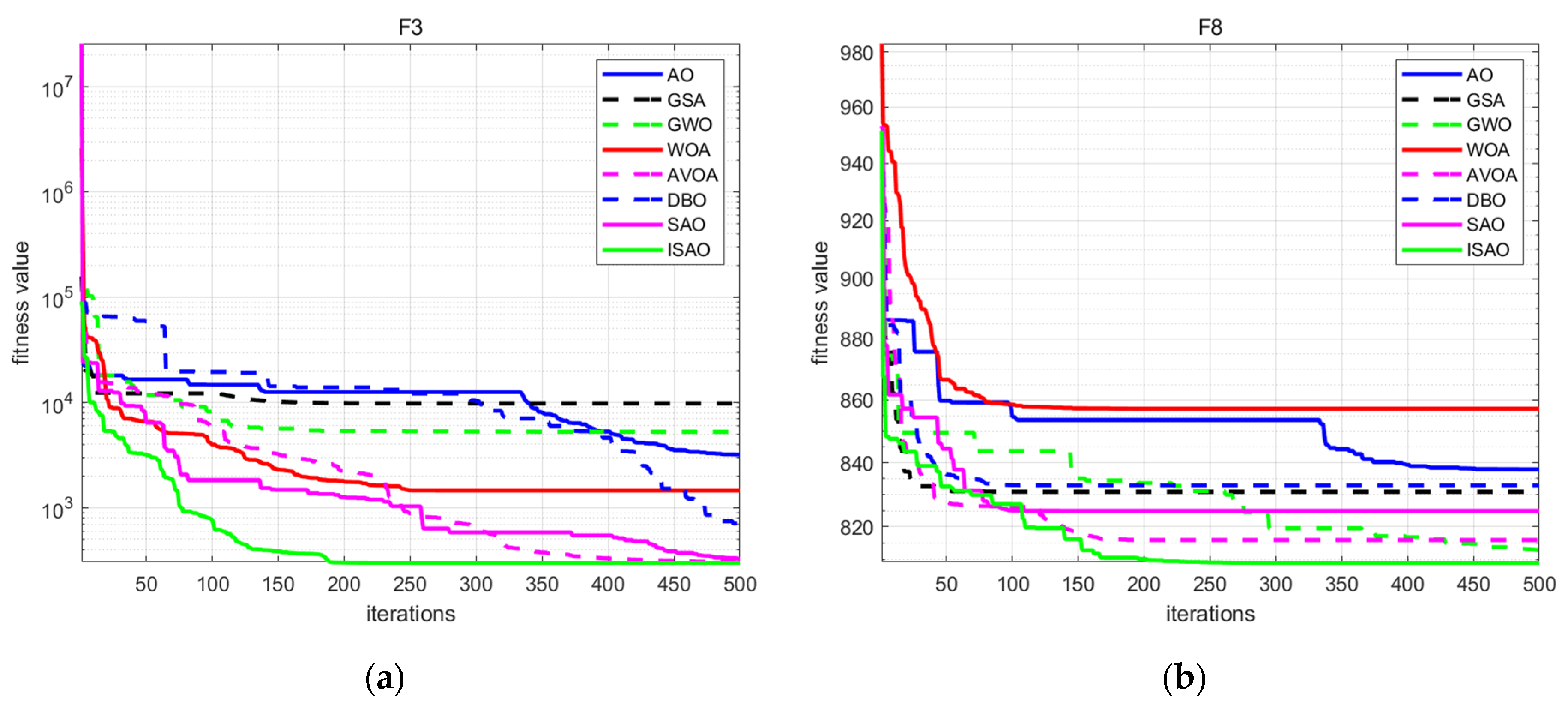
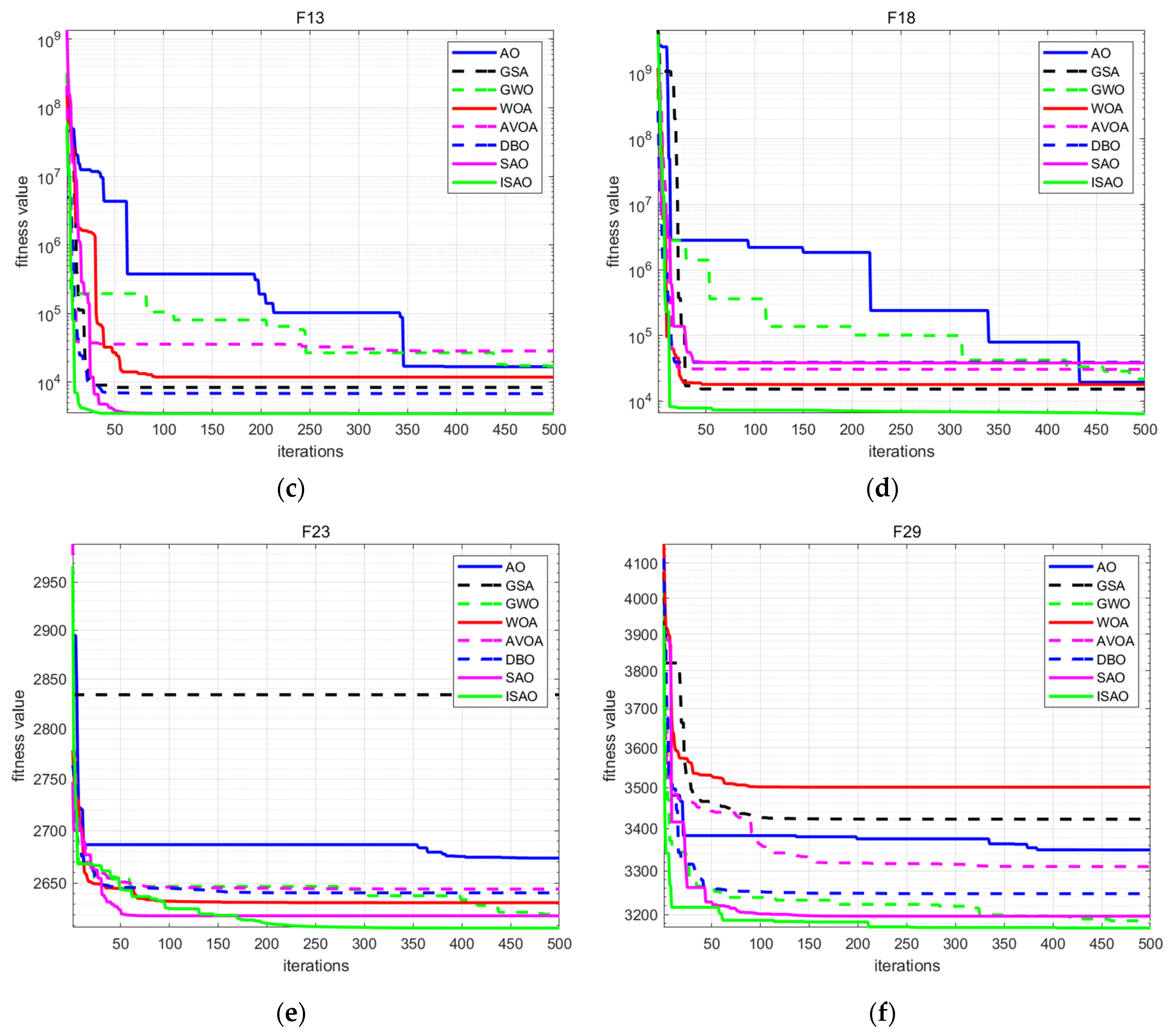
2.3. ISAO Optimization Ability Test
3. Boiler Energy Consumption Prediction Model
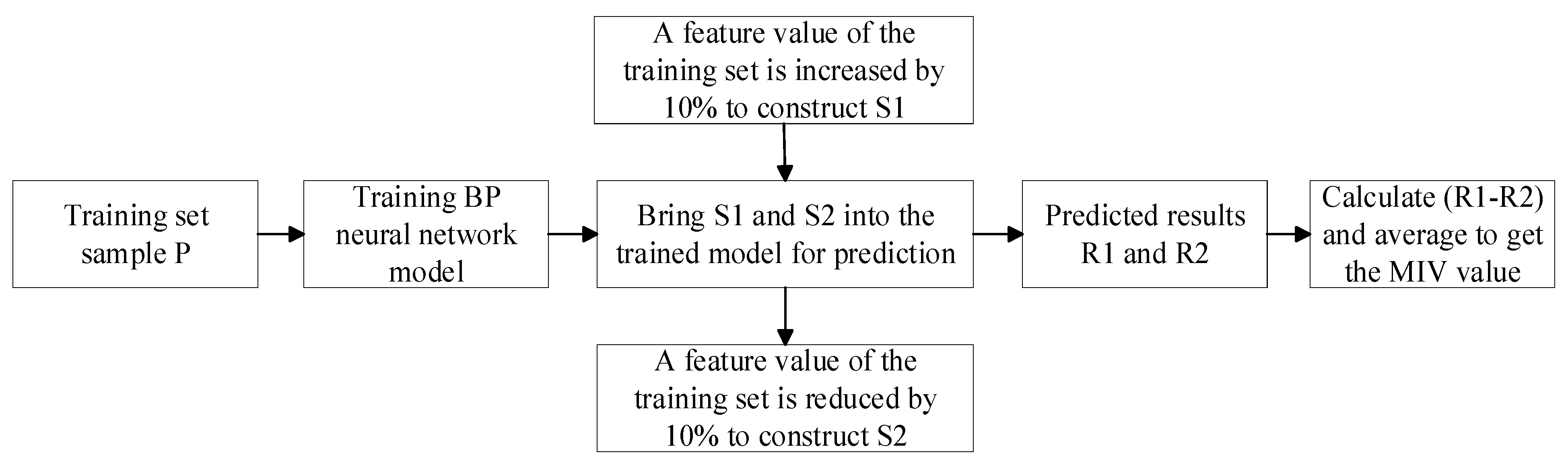
3.1. Mean Impact Value
3.2. Least-Squares Support Vector Machine
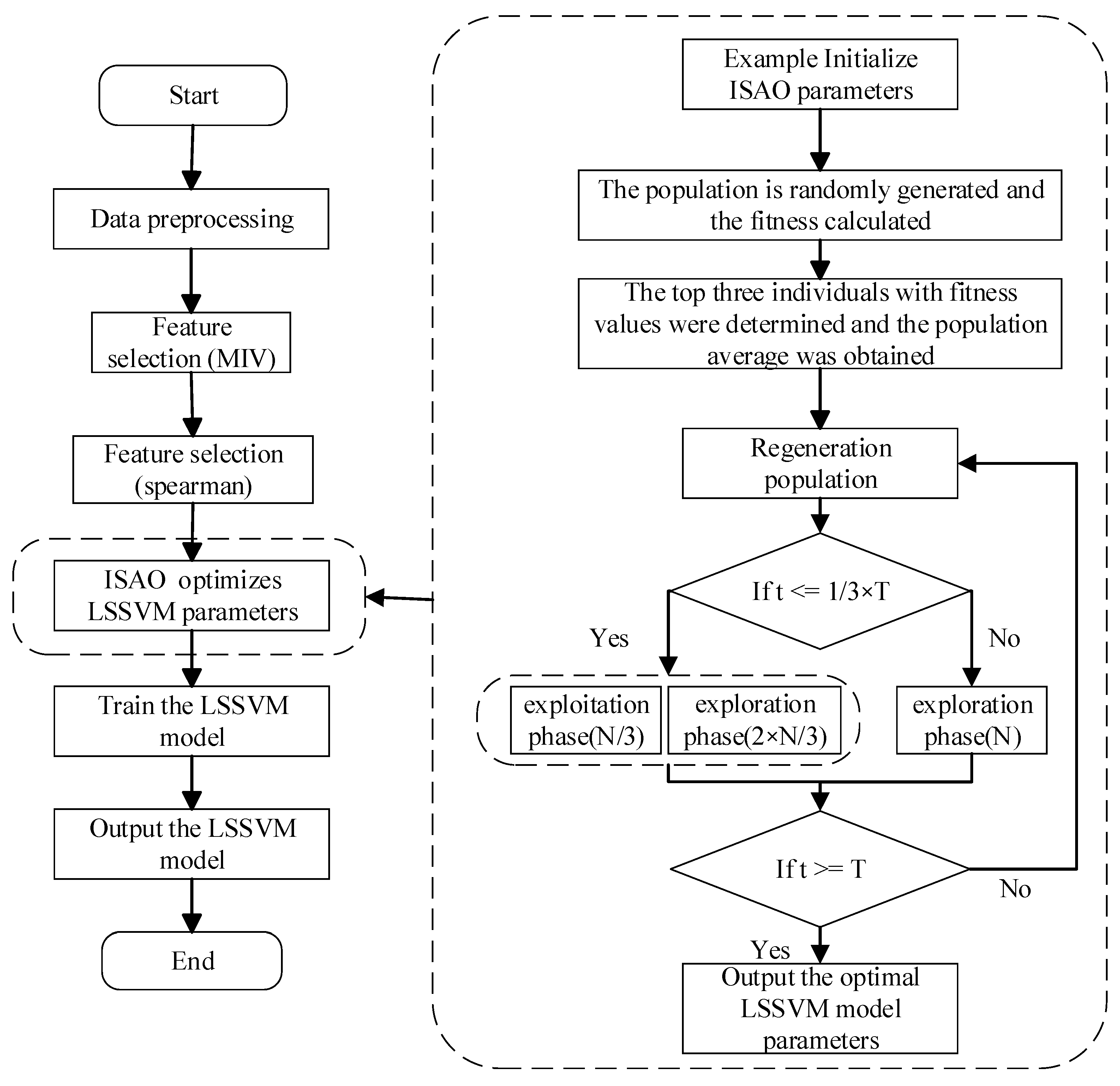
3.3. MIV-ISAO-LSSVM
- (1)
- Clean the dataset and select features;
- (2)
- Specify the number of algorithm populations, set the maximum number of iterations, and generate initial populations using the tent map;
- (3)
- Compare the fitness values of all individuals in the population, determine the three individuals with the smallest fitness values, and calculate the average of all individuals in the population ;
- (4)
- Perform population iteration. The exploitation stage follows Formulas (2) and (6), while the exploration stage follows Formulas (3) and (8). The fitness values of both old and new individuals are compared, and only those with lower fitness values are kept;
- (5)
- During the later stage of the algorithm, Formula (7) is used to generate opposing individuals, and their fitness values are also compared.
- (6)
- Upon completion of the final iteration, the optimal individual’s ‘’ and ‘’ values are extracted and used to train the LSSVM, resulting in an LSSVM prediction model that has been optimized by the ISAO algorithm.
4. Example Analysis
4.1. Data Preprocessing
4.1.1. Data Source
4.1.2. Calculating the Energy Consumption of the Boiler System
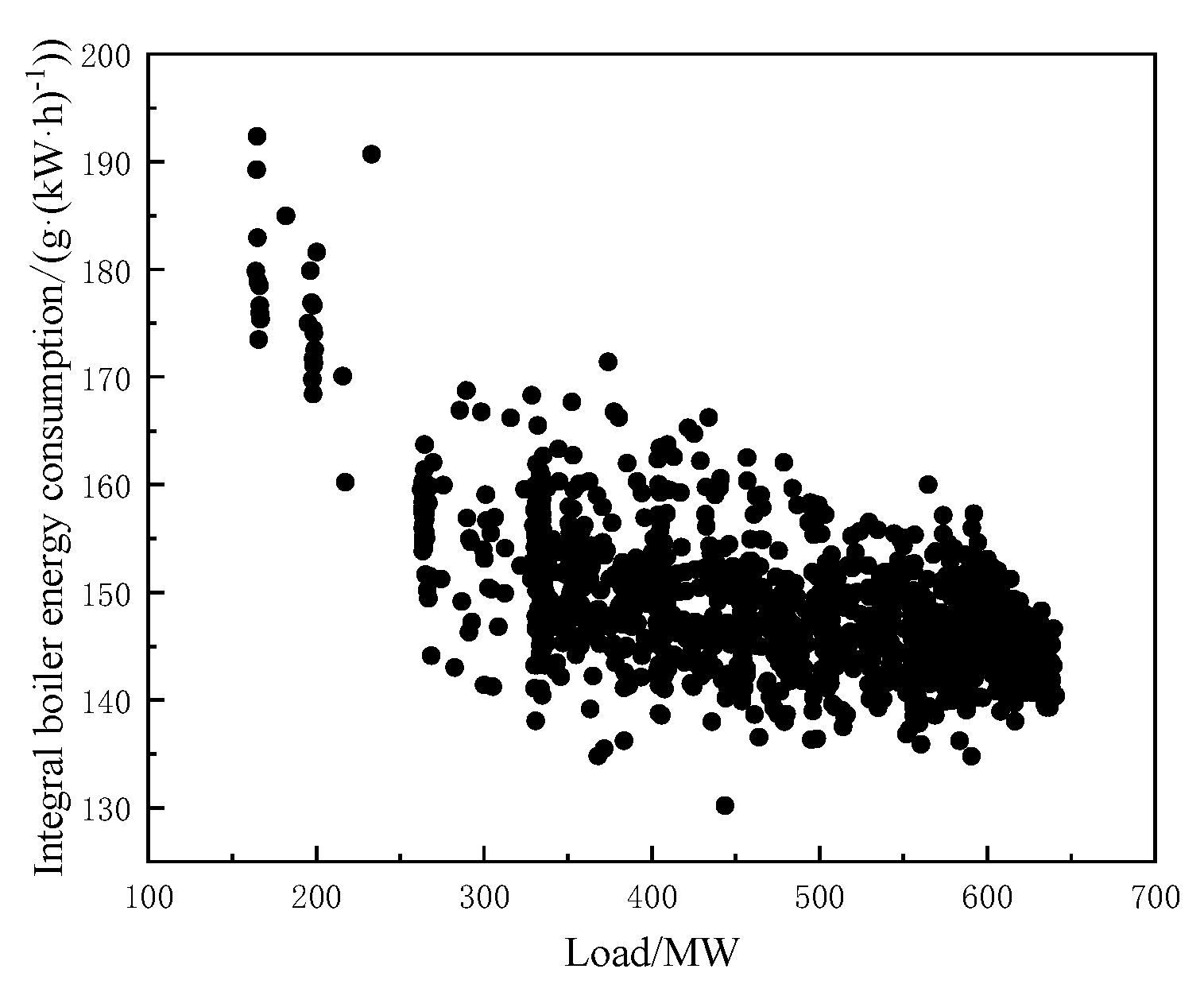
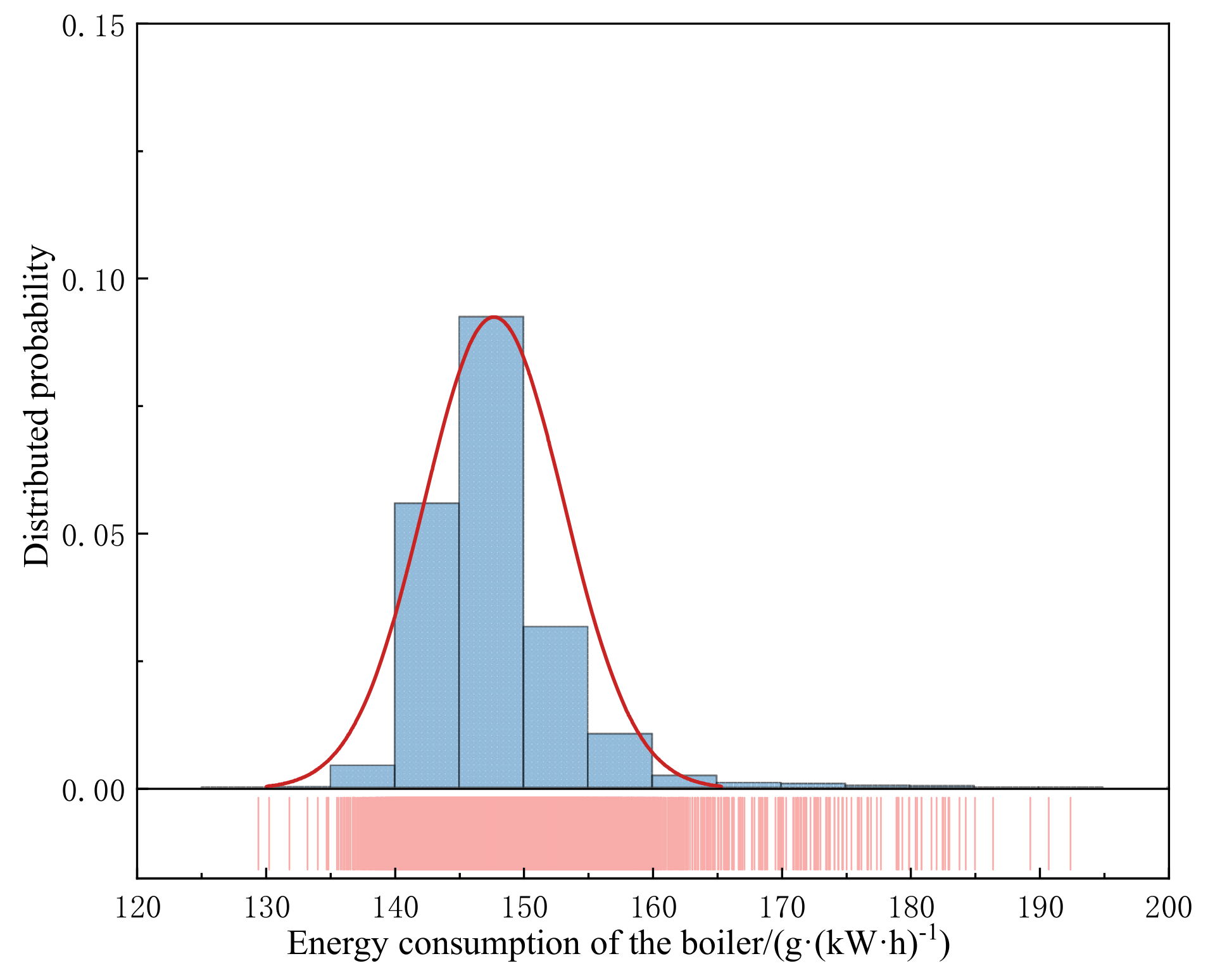
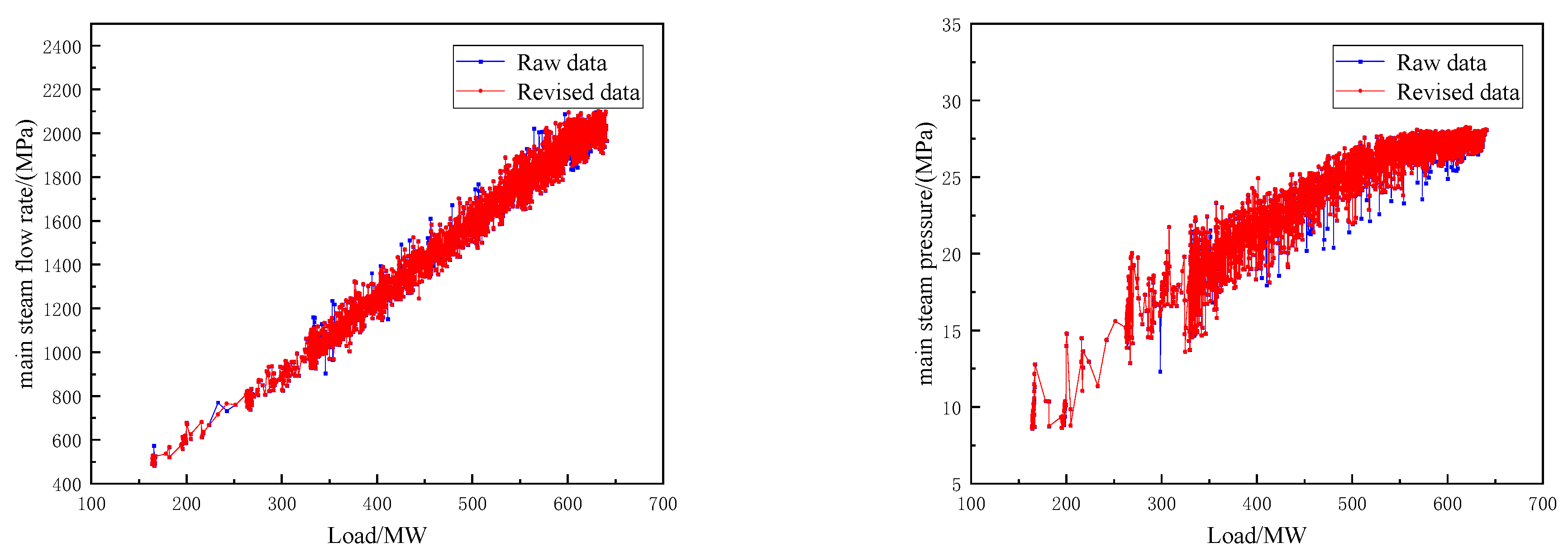
4.1.3. Removing Outliers
4.2. Feature Selection
4.2.1. Data Standardization
4.2.2. Feature Selection Result
4.3. Model Prediction Results
5. Conclusions
- (1)
- Using the single consumption analysis method, we calculated and analyzed the energy consumption distribution of the boiler system in the target unit based on field measurement data under variable load conditions. The results indicate that when the load of the target unit is reduced to less than 30%, the energy consumption of the boiler system increases by approximately 20.7% compared to its consumption under 95% load operation.
- (2)
- Compared to other optimization algorithms, the strategy proposed in this study improves the convergence speed of the ISAO algorithm. Although the performances of LSSVM prediction models obtained by different optimization algorithms are similar, the ISAO algorithm can efficiently and accurately obtain the hyperparameters of LSSVM for boiler system energy consumption.
- (3)
- A MIV-ISAO-LSSVM model was developed to predict the energy consumption of ultra-supercritical coal-fired boilers under various load conditions. The MIV algorithm reduces the number of dataset features from 166 to 26. This greatly simplifies the model and identifies the main factors that affect the energy consumption of the boiler system. The hyperparameters of the LSSVM model are obtained through the ISAO optimization algorithm. The model demonstrated superior accuracy, reliability, and applicability compared to other models.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Correction Statement
References
- Siksnelyte-Butkiene, I.; Zavadskas, E.K.; Streimikiene, D. Multi-criteria decision-making (MCDM) for the assessment of renewable energy technologies in a household: A review. Energies 2020, 13, 1164. [Google Scholar] [CrossRef]
- Ordu, M.; Der, O. Polymeric materials selection for flexible pulsating heat pipe manufacturing using a comparative hybrid MCDM approach. Polymers 2023, 15, 2933. [Google Scholar] [CrossRef] [PubMed]
- Yang, H.; Zhuo, D.Y.; Cao, J.; Dong, Y.S.; Si, F.Q. Dynamic soft sensing modeling of NOx concentration at outlet of SCR flue gas denitration system based on DJMI-GRU. Therm. Power Gener. 2021, 50, 51–58. [Google Scholar] [CrossRef]
- Yang, K.X.; Feng, Y.L.; Liu, M.; Yang, J. Multi-parameter Optimization and Operation Strategy of Fluegas Waste Heat and Water Co-recovery System for Coal-fired Power Plants. Proc. CSEE 2021, 41, 4566–4576. [Google Scholar] [CrossRef]
- Sun, H.B.; Yang, J.G.; Jin, H.W.; Tu, H.; Zhou, X.; Zhao, H. NOx Prediction Model for Coal-fired Boiler Based on Bayesian Optimization-Random Forest Regression. J. Chin. Soc. Power Eng. 2023, 43, 910–916. [Google Scholar] [CrossRef]
- Dai, B.; Wang, F.; Chang, Y. Multi-objective economic load dispatch method based on data mining technology for large coal-fired power plants. Control Eng. Pract. 2022, 121, 105018. [Google Scholar] [CrossRef]
- Blackburn, L.D.; Tuttle, J.F.; Andersson, K.; Fry, A.; Powell, K.M. Development of novel dynamic machine learning-based optimization of a coal-fired power plant. Comput. Chem. Eng. 2022, 163, 107848. [Google Scholar] [CrossRef]
- Wang, Z.; Yao, G.; Xue, W.; Cao, S.; Xu, S.; Peng, X. A Data-Driven Approach for the Ultra-Supercritical Boiler Combustion Optimization Considering Ambient Temperature Variation: A Case Study in China. Processes 2023, 11, 2889. [Google Scholar] [CrossRef]
- Fu, Z.G.; Liu, B.H.; Wang, P.K.; Gao, X.W. Big Data Mining Technology Application in Energy Consumption Analysis of Coal-fired Power Plant Units. Proc. CSEE 2018, 38, 3578–3587. [Google Scholar] [CrossRef]
- Cai, Y. Theoretical Research on Data Mining Based on Energy Saving and Consumption Diagnosis for Thermal Power Units. Master’s Thesis, Zhejiang University, Hangzhou, China, 2018. [Google Scholar]
- Xiao, H.; Xue, Y.L.; Liu, P.; Li, Z. Optimum Exergy Efficiency Analysis of Coal-fired Power Plants Based on Operation Data. Proc. CSEE 2019, 39, 164–170. [Google Scholar] [CrossRef]
- Sun, Y.P.; Wang, L.F.; Zhang, Z.W.; Yang, Q. Genetic optimization model of power supply coal consumption for thermal power unit based on random forest. Inf. Commun. Technol. Policy 2021, 47, 76–82. [Google Scholar] [CrossRef]
- Wan, A.P.; Yang, J.; Miao, X. Boiler Load Forecasting of CHP Plant Based on Attention Mechanism and Deep Neural Network. J. Shanghai Jiao Tong Univ. 2023, 57, 316–325. [Google Scholar] [CrossRef]
- Wang, Y.O.; Chen, Y.F.; Mou, K.Y.; Ren, S.J. Study on index system construction of energy consumption and economic diagnosis of thermal power unit. J. Eng. Therm. Energy Power 2022, 37, 175–185. [Google Scholar] [CrossRef]
- Wang, W.; Wei, Y.; Teng, X. Short-Term Wind Power Forecasting Based On VMD-SSA-LSSVM. Acta Energiae Solaris Sin. 2023, 44, 204–211. [Google Scholar] [CrossRef]
- Lan, M.W.; Li, Y.; Zhao, G.Q. Study on boiler combustion modeling based on MAPSO optimizing LSSVM model parameters. J. Cent. South Univ. Sci. Technol. 2022, 53, 1506–1515. [Google Scholar] [CrossRef]
- Deng, L.; Liu, S. Snow ablation optimizer: A novel metaheuristic technique for numerical optimization and engineering design. Expert Syst. Appl. 2023, 225, 120069. [Google Scholar] [CrossRef]
- Li, C.; Luo, G.; Qin, K.; Li, C. An image encryption scheme based on chaotic tent map. Nonlinear Dyn. 2017, 87, 127–133. [Google Scholar] [CrossRef]
- Zhuo, X.H.; Feng, Y.C.; Chen, L.; Luo, W.G.; Liu, S.Y. Transformer fault diagnosis based on SVM optimized by the improved bald eagle search algorithm. Power Syst. Prot. Control 2023, 51, 118–126. [Google Scholar] [CrossRef]
- Bai, X.; Bai, Y.G. Support vector machine and feature selection simultaneous optimization based on improved Harris hawk algorithm. Comput. Eng. Des. 2023, 44, 1537–1546. [Google Scholar] [CrossRef]
- Abualigah, L.; Yousri, D.; Abd Elaziz, M.; Ewees, A.A.; Al-Qaness, M.A.; Gandomi, A.H. Aquila optimizer: A novel meta-heuristic optimization algorithm. Comput. Ind. Eng. 2021, 157, 107250. [Google Scholar] [CrossRef]
- Rashedi, E.; Nezamabadi-pour, H.; Saryazdi, S. GSA: A Gravitational Search Algorithm. Inf. Sci. 2009, 179, 2232–2248. [Google Scholar] [CrossRef]
- Hatta, N.M.; Zain, A.M.; Sallehuddin, R.; Shayfull, Z.; Yusoff, Y. Recent studies on optimisation method of Grey Wolf Optimiser (GWO): A review (2014–2017). Artif. Intell. Rev. 2019, 52, 2651–2683. [Google Scholar] [CrossRef]
- Chen, X.; Cheng, L.; Liu, C.; Liu, Q.; Liu, J.; Mao, Y.; Murphy, J. A WOA-based optimization approach for task scheduling in cloud computing systems. IEEE Syst. J. 2020, 14, 3117–3128. [Google Scholar] [CrossRef]
- Abdollahzadeh, B.; Gharehchopogh, F.S.; Mirjalili, S. African vultures optimization algorithm: A new nature-inspired metaheuristic algorithm for global optimization problems. Comput. Ind. Eng. 2021, 158, 107408. [Google Scholar] [CrossRef]
- Wu, C.; Fu, J.; Huang, X.; Xu, X.; Meng, J. Lithium-Ion Battery Health State Prediction Based on VMD and DBO-SVR. Energies 2023, 16, 3993. [Google Scholar] [CrossRef]
- Liu, D.; Liu, F.; Xu, Y.P. Short-term PV output forecast based on MIV-PSO-BPNN. Acta Energiae Solaris Sin. 2022, 43, 94. [Google Scholar] [CrossRef]
- Sun, J.J. Prediction of Pier Scour Depth Based on GA-MIV-BP Neural Network. Master’s Thesis, Nanchang University, Nanchang, China, 2022. [Google Scholar]
- Chen, Y.; Li, M. Evaluation of influencing factors on tea production based on random forest regression and mean impact value. Agric. Econ. Zemědělská Ekon. 2019, 65, 340–347. [Google Scholar] [CrossRef]
- Suykens, J.A.; Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Shi, M.; Tan, P.; Qin, L.; Huang, Z. Research on Valve Life Prediction Based on PCA-PSO-LSSVM. Processes 2023, 11, 1396. [Google Scholar] [CrossRef]
- Xie, L.R.; Wang, B.; Bao, H.Y.; Liang, W.; Maimaitireyimu, A. Super-Short-Term Wind Power Forecasting Based On EEMD-WOA-LSSVM. Acta Energiae Solaris Sin. 2021, 43, 94. [Google Scholar] [CrossRef]
- Borchani, H.; Varando, G.; Bielza, C.; Larranaga, P. A survey on multi-output regression. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2015, 5, 216–233. [Google Scholar] [CrossRef]
- He, D.B.; Sun, S.X.; Liang, X.; Xie, L.; Zhang, K. Multi-target feature selection algorithm based on adaptive graph learning. Control. Decis. 2023, 1–9. [Google Scholar] [CrossRef]
- Song, Z.P. Consumption Rate Analysis: Theory and Practice. Proc. CSEE 1992, 1992, 17–23. [Google Scholar] [CrossRef]
- Wang, J.; Duan, L.; Yang, J.; Yang, M.; Jing, Y.; Tian, L. Energy-Saving Optimization Study on 700 °C Double Reheat Advanced Ultra-Supercritical Coal-Fired Power Generation System. J. Therm. Sci. 2023, 32, 30–43. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Test Function | Dimension | Search Range | Optimal Solution |
|---|---|---|---|
| Shifted and Rotated Zakharov Function | 10 | [−100, 100] | 300 |
| Shifted and Rotated Non-Continuous Rastrigin’s Function | 10 | [−100, 100] | 800 |
| Hybrid Function 3 | 3 | [−100, 100] | 1300 |
| Hybrid Function 6 | 5 | [−100, 100] | 1800 |
| Composition Function 3 | 4 | [−100, 100] | 2300 |
| Composition Function 9 | 3 | [−100, 100] | 2900 |
| Test Function | Optimizers | Optimal Fitness | Optimizers | Optimal Fitness |
|---|---|---|---|---|
| F3 | ISAO | 300.000 | DBO | 710.895 |
| SAO | 326.937 | GSA | 9790.301 | |
| AO | 3199.818 | GWO | 5257.905 | |
| AVOA | 309.023 | WOA | 1465.277 | |
| F8 | ISAO | 807.057 | DBO | 832.833 |
| SAO | 815.919 | GSA | 830.844 | |
| AO | 837.849 | GWO | 812.931 | |
| AVOA | 815.919 | WOA | 857.138 | |
| F13 | ISAO | 3452.194 | DBO | 6783.287 |
| SAO | 3492.485 | GSA | 8377.862 | |
| AO | 16,804.696 | GWO | 17,089.842 | |
| AVOA | 28,475.712 | WOA | 11,839.759 | |
| F18 | ISAO | 6365.220 | DBO | 38,942.046 |
| SAO | 38,069.597 | GSA | 15,188.760 | |
| AO | 19,341.321 | GWO | 21,467.438 | |
| AVOA | 30,375.804 | WOA | 17,808.072 | |
| F23 | ISAO | 2607.639 | DBO | 2640.688 |
| SAO | 2619.127 | GSA | 2833.831 | |
| AO | 2673.621 | GWO | 2620.237 | |
| AVOA | 2644.219 | WOA | 2631.444 | |
| F29 | ISAO | 3169.441 | DBO | 3247.289 |
| SAO | 3196.178 | GSA | 3422.736 | |
| AO | 3349.266 | GWO | 3183.158 | |
| AVOA | 3310.118 | WOA | 3501.046 |
| Time | Load (MW) | Main Steam Pressure (MPa) | Main Steam Temperature (°C) | Main Steam Flow Rate (t·h−1) | … | Steam Temperature before Reheater Desuperheater (°C) | Steam Temperature at the Inlet of Final Reheater (°C) |
|---|---|---|---|---|---|---|---|
| 01/07/2022 00:00:00 | 606.41 | 27.81 | 584.20 | 1757.49 | … | 481.47 | 469.63 |
| 01/07/2022 00:05:00 | 607.06 | 27.84 | 584.28 | 1759.91 | … | 481.43 | 470.82 |
| 01/07/2022 00:10:00 | 604.98 | 27.76 | 583.70 | 1749.93 | … | 480.62 | 473.70 |
| 01/07/2022 00:15:00 | 605.52 | 27.77 | 583.87 | 1752.29 | … | 480.87 | 473.65 |
| 01/07/2022 00:20:00 | 604.50 | 27.74 | 583.38 | 1748.92 | … | 480.40 | 472.55 |
| … | … | … | … | … | … | … | … |
| 01/08/2022 0:00:00 | 605.87 | 26.57 | 580.73 | 2001.80 | … | 479.83 | 476.47 |
| Time | Economizer /(g·(kW·h)−1) | Water Wall /(g·(kW·h)−1) | Low Temperature Superheater /(g·(kW·h)−1) | Platen Superheater /(g·(kW·h)−1) | … | Integral Boiler System /(g·(kW·h)−1) |
|---|---|---|---|---|---|---|
| 01/07/2022 00:00:00 | 7.367 | 60.757 | 19.311 | 8.059 | … | 152.218 |
| 01/07/2022 00:05:00 | 7.420 | 60.980 | 19.211 | 7.949 | … | 152.463 |
| 01/07/2022 00:10:00 | 7.500 | 61.840 | 19.136 | 7.791 | … | 152.946 |
| 01/07/2022 00:15:00 | 7.487 | 61.817 | 19.274 | 7.615 | … | 152.883 |
| 01/07/2022 00:20:00 | 7.499 | 61.782 | 19.293 | 7.478 | … | 152.732 |
| … | … | … | … | … | … | … |
| 01/08/2022 00:00:00 | 7.164 | 60.084 | 19.708 | 9.086 | 149.170 |
| Features | Absolute Value of MIV | Sum of Current Feature’s MIV | Percentage |
|---|---|---|---|
| main steam flow rate | 1.4531 | 1.4531 | 0.1209 |
| steam pressure at the outlet of final reheater | 0.8112 | 2.2643 | 0.1884 |
| feed water flow rate | 0.7240 | 2.9883 | 0.2487 |
| main steam pressure | 0.5148 | 3.5031 | 0.2916 |
| feed water temperature | 0.4650 | 3.9681 | 0.3303 |
| … | … | … | … |
| flame intensity of furnace D | 0.0002 | 12.0154 | 1.0000 |
| Number | Feature | Number | Feature | Number | Feature |
|---|---|---|---|---|---|
| 1 | main steam flow rate | 10 | steam temperature at the outlet of platen superheater | 19 | flue gas temperature at the outlet of air preheater |
| 2 | main steam pressure | 11 | oil supply master pipe flow rate | 20 | integrated temperature of cold end of air preheater |
| 3 | steam temperature at the outlet of low temperature superheater | 12 | water pressure at the inlet of low temperature economizer | 21 | coal–water ratio |
| 4 | steam temperature at the outlet of separator | 13 | the outlet air temperature at the outlet of secondary air heater | 22 | separator wall temperature |
| 5 | steam temperature at the inlet of final superheater | 14 | steam temperature at the outlet of final reheater | 23 | SO2 concentration at the inlet of chimney |
| 6 | total boiler air volume | 15 | steam temperature at the inlet of final reheater | 24 | wind pressure at the outlet of mill |
| 7 | steam temperature at the outlet of final superheater | 16 | temperature of primary air at the outlet of air preheater | 25 | flue gas temperature at the outlet of low temperature superheater |
| 8 | intermediate superheating | 17 | the temperature of the steam before the reheater desuperheater | 26 | flue gas temperature at the inlet of low temperature superheater |
| 9 | water temperature at the outlet of condenser | 18 | steam temperature at the inlet of low temperature reheater |
| Evaluation Index | ISAO-LSSVM | LSSVM | BP | ELM | PSO-LSSVM | SSA-LSSVM | WOA-LSSVM | |
|---|---|---|---|---|---|---|---|---|
| aRRMSE | 0.2747 | 0.2807 | 0.3355 | 0.4605 | 0.2747 | 0.2747 | 0.2747 | |
| MAE | integral boiler | 1.0690 | 1.0811 | 1.3469 | 1.6693 | 1.0689 | 1.0689 | 1.0689 |
| economizer | 0.1435 | 0.1516 | 0.2177 | 0.2231 | 0.1435 | 0.1435 | 0.1435 | |
| water wall | 0.6044 | 0.6105 | 0.8596 | 1.1897 | 0.6044 | 0.6044 | 0.6044 | |
| low temperature superheater | 0.2072 | 0.2029 | 0.2578 | 0.5851 | 0.2072 | 0.2072 | 0.2072 | |
| platen superheater | 0.1319 | 0.1335 | 0.1413 | 0.2895 | 0.1319 | 0.1319 | 0.1319 | |
| final superheater | 0.0778 | 0.0821 | 0.0988 | 0.1604 | 0.0778 | 0.0778 | 0.0778 | |
| low temperature reheater | 0.1169 | 0.1203 | 0.1433 | 0.2060 | 0.1169 | 0.1169 | 0.1169 | |
| final reheater | 0.0747 | 0.0752 | 0.1418 | 0.1475 | 0.0747 | 0.0747 | 0.0747 | |
| air preheater | 0.1772 | 0.1737 | 0.2108 | 0.2892 | 0.1772 | 0.1772 | 0.1772 | |
| The number of iterations where the optimal value is found | 6 | / | / | / | 20 | 14 | 19 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Ma, X.; Cheng, Z.; Zhou, X. Prediction of Energy Consumption in a Coal-Fired Boiler Based on MIV-ISAO-LSSVM. Processes 2024, 12, 422. https://doi.org/10.3390/pr12020422
Zhang J, Ma X, Cheng Z, Zhou X. Prediction of Energy Consumption in a Coal-Fired Boiler Based on MIV-ISAO-LSSVM. Processes. 2024; 12(2):422. https://doi.org/10.3390/pr12020422
Chicago/Turabian StyleZhang, Jiawang, Xiaojing Ma, Zening Cheng, and Xingchao Zhou. 2024. "Prediction of Energy Consumption in a Coal-Fired Boiler Based on MIV-ISAO-LSSVM" Processes 12, no. 2: 422. https://doi.org/10.3390/pr12020422