

Detecting Plant-Wide Oscillation Propagation Effects of Disturbances and Faults in a Chemical Process Plant Using Network Topology of Variance Decompositions

Abstract
:1. Introduction
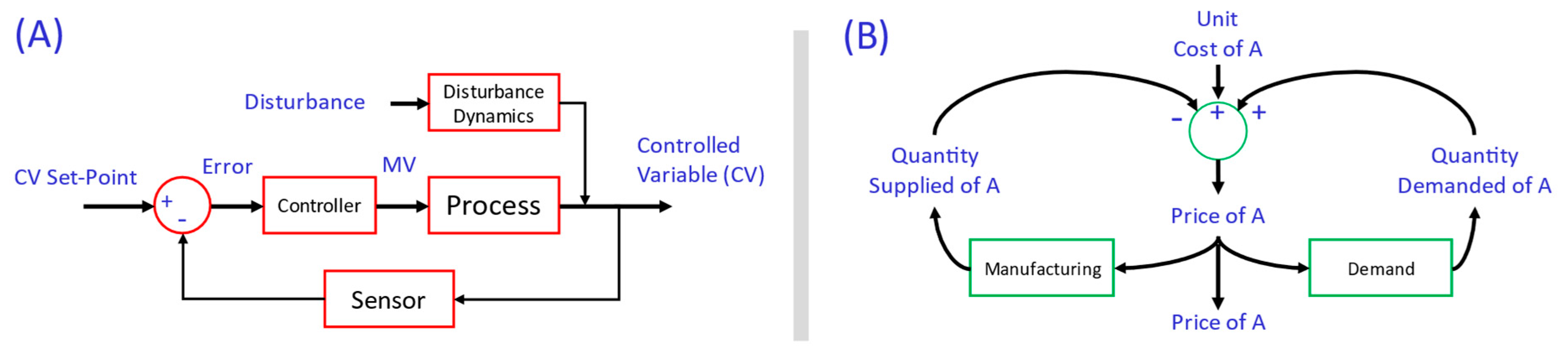
1.1. Problem Setup
1.2. Challenge of Oscillation Propagation and Root-Cause Analysis
1.3. Objectives of the Work
- To explain how the dynamics of a chemical process such as the TEP can be modeled to compute measures of multivariate connectedness,
- To show how the measures of variable connectedness are represented as network graphs for visual analysis of system volatility,
- To perform the computations and network rendering of connectedness using two connectedness dimensions: time connectedness and frequency connectedness
- To discuss how the findings on the use of network topology of variance decompositions for volatility spillover analysis in a chemical process may complement and perhaps advance chemical process design and control.
2. Methodology
2.1. Theory: A Solution—Multivariate Time-Series Variance Decompositions and Their Connectedness
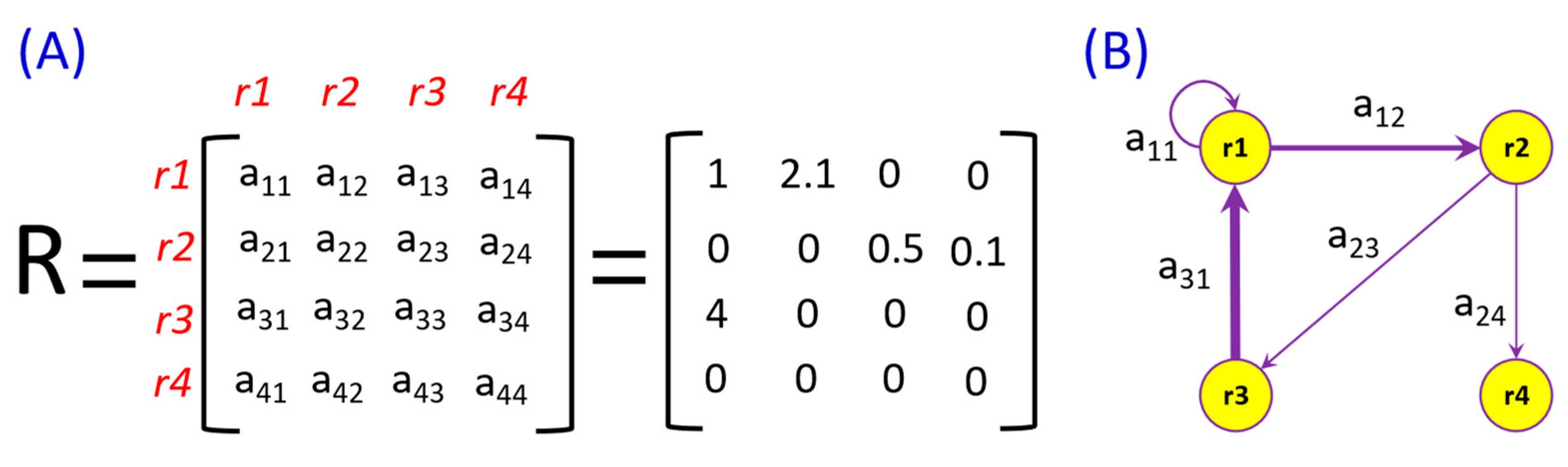
2.1.1. Variance Decomposition—Estimating Multivariate Connectedness
2.1.2. Network Topology—Graphs of Connectedness
2.2. Computations: On TEP Benchmark Dataset Using the R-Package “ConnectednessApproach”
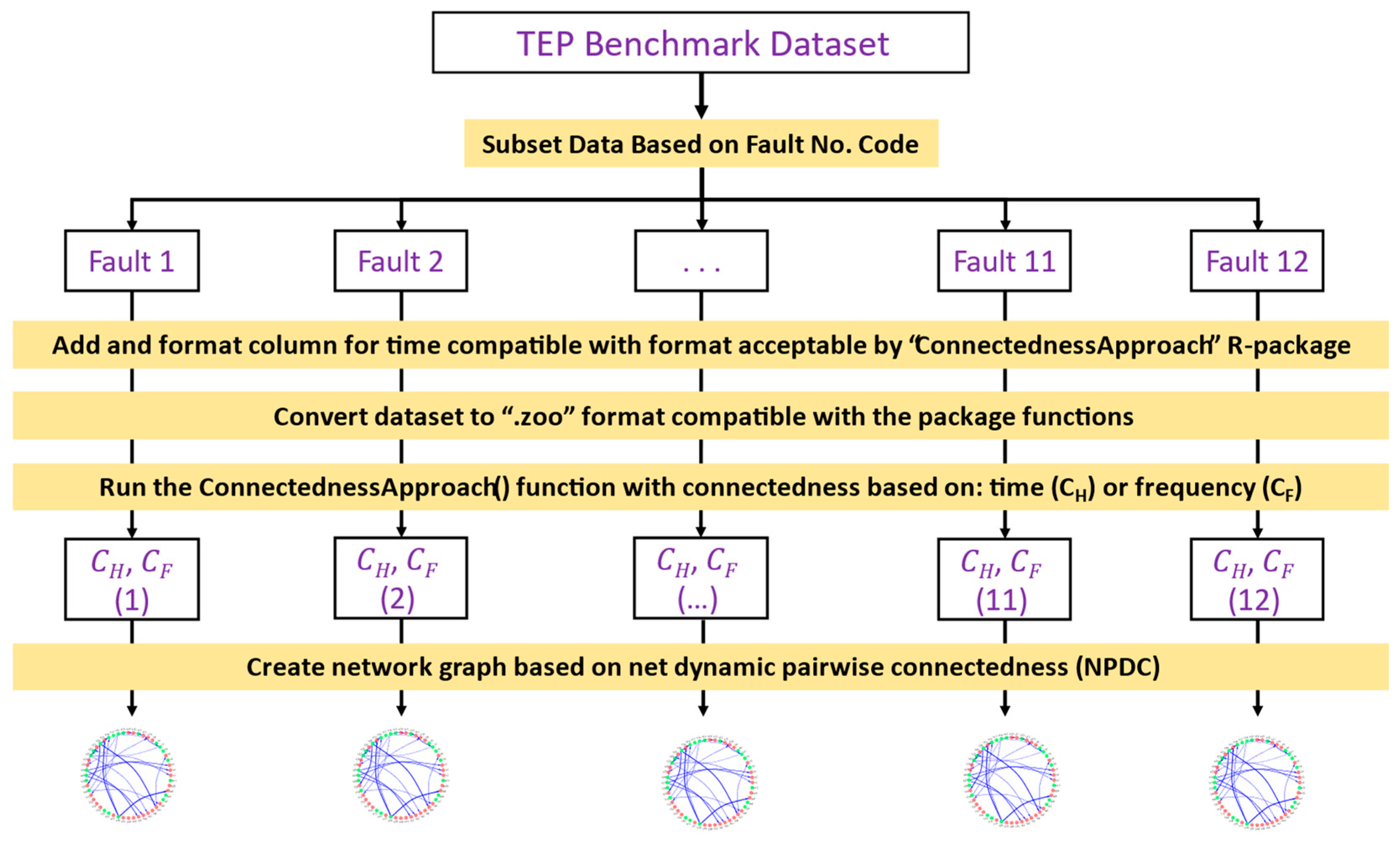
2.2.1. Data Analytics Workflow
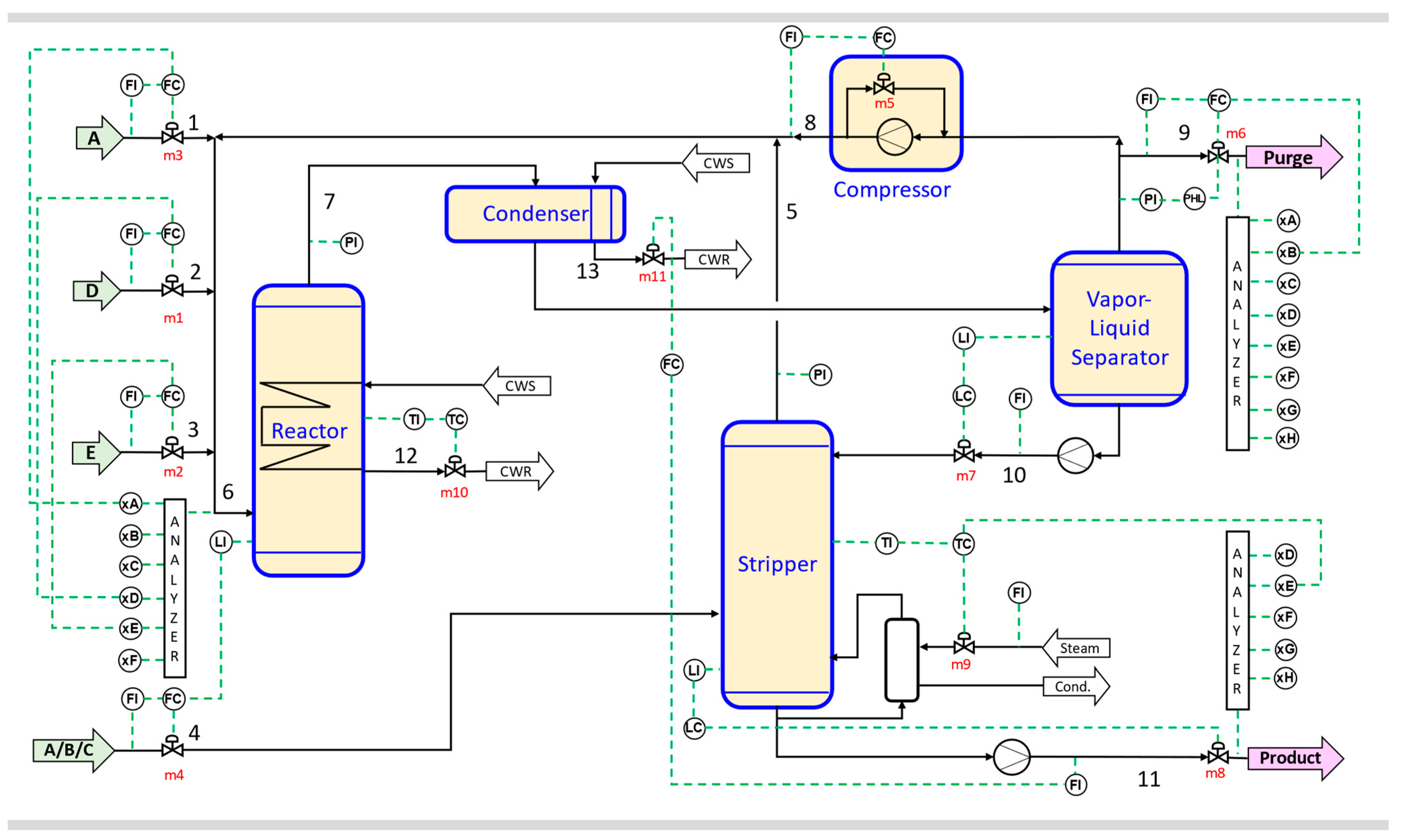
2.2.2. Benchmark Dataset: Tennessee-Eastman Chemical Process (TEP)
2.2.3. Type of Connectedness
- Time Connectedness
- 2.
- Frequency Connectedness
2.2.4. Process Variables Connectedness Reporting Using Volatility Spillover Index
3. Results and Discussion
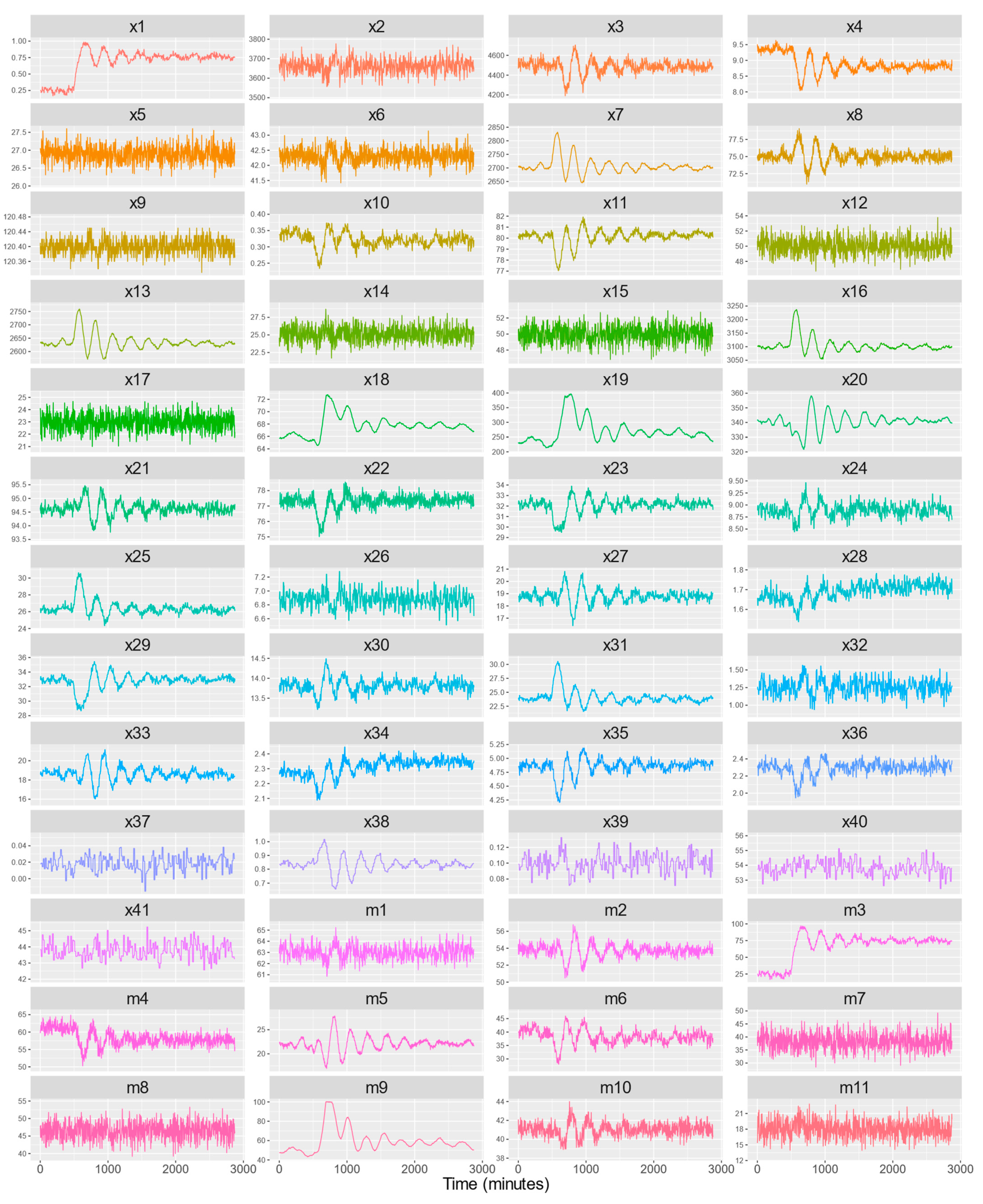
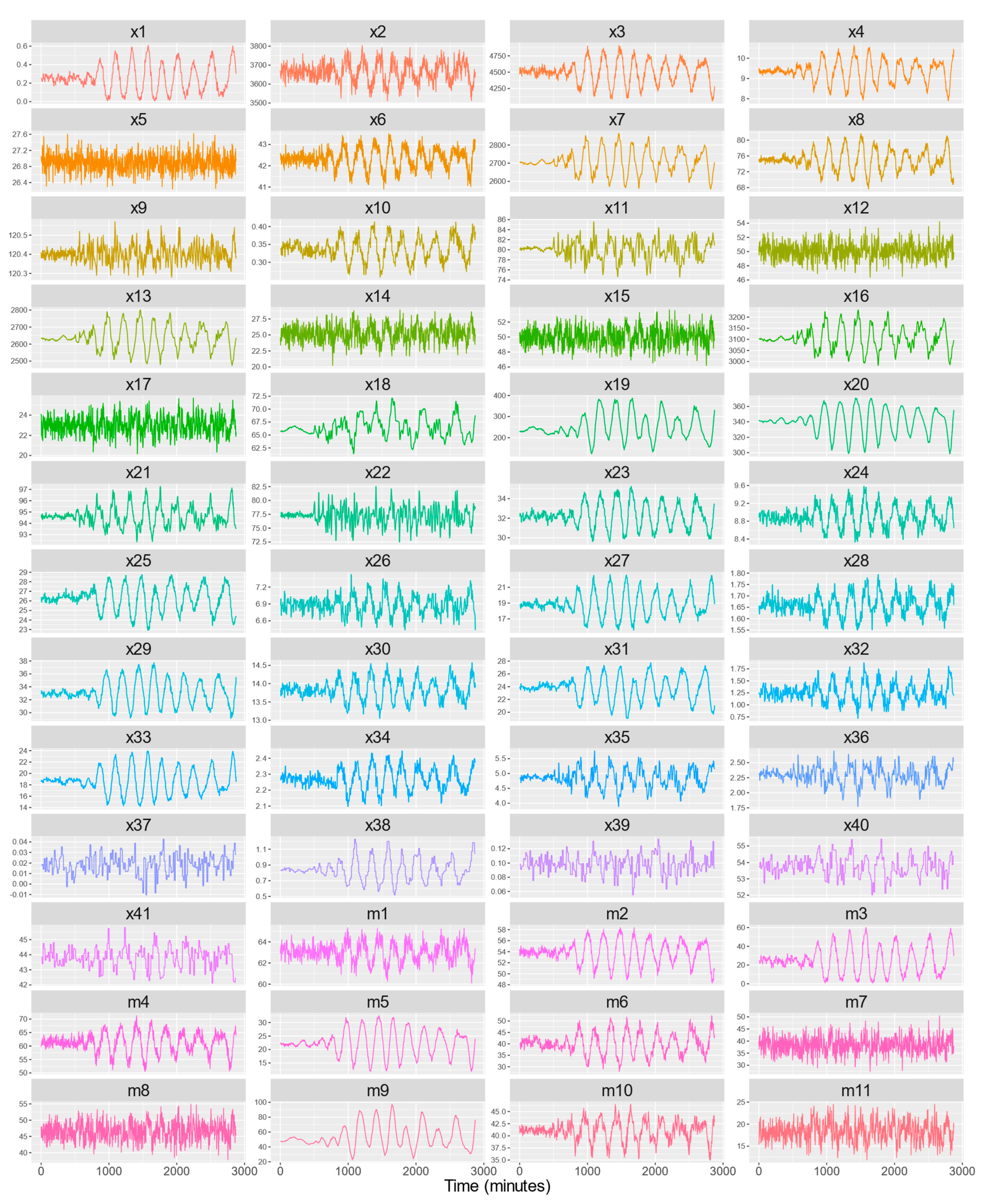
3.1. VAR Model Residuals Analysis
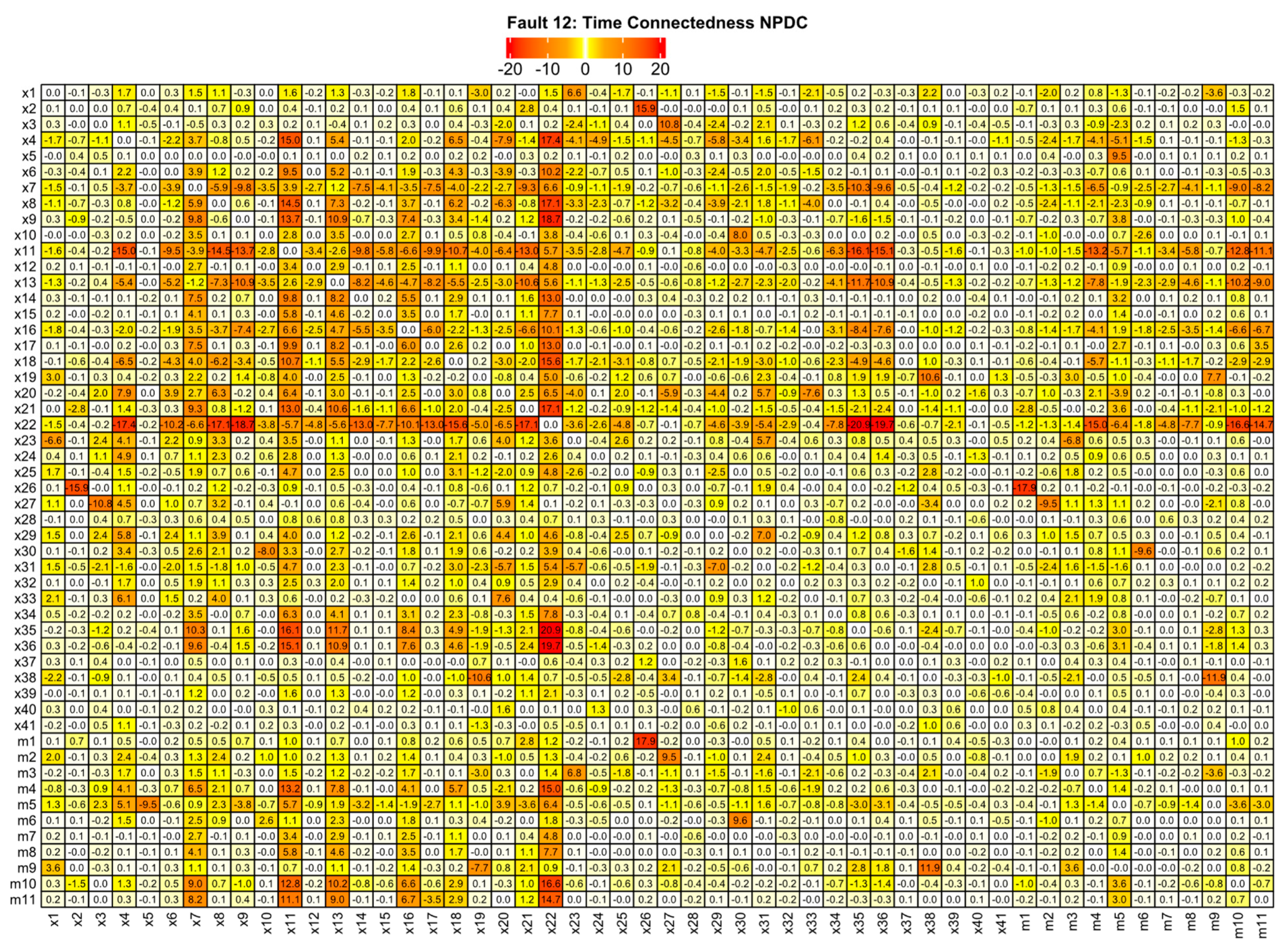
3.2. Oscillation Propagation Effects from TEP Faults Based on Time Connectedness
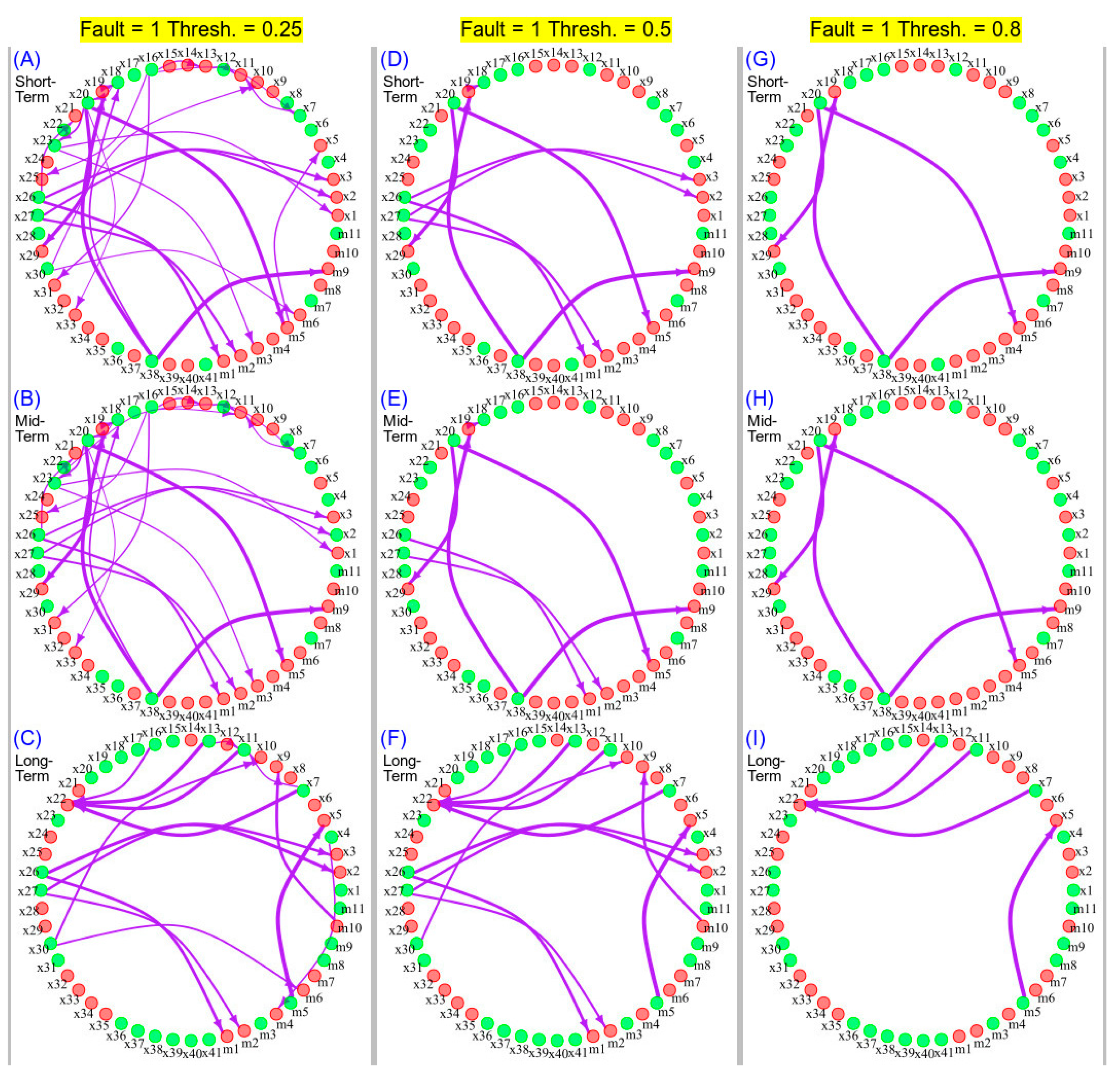
3.3. Network Topology at Varying Connectedness Thresholds
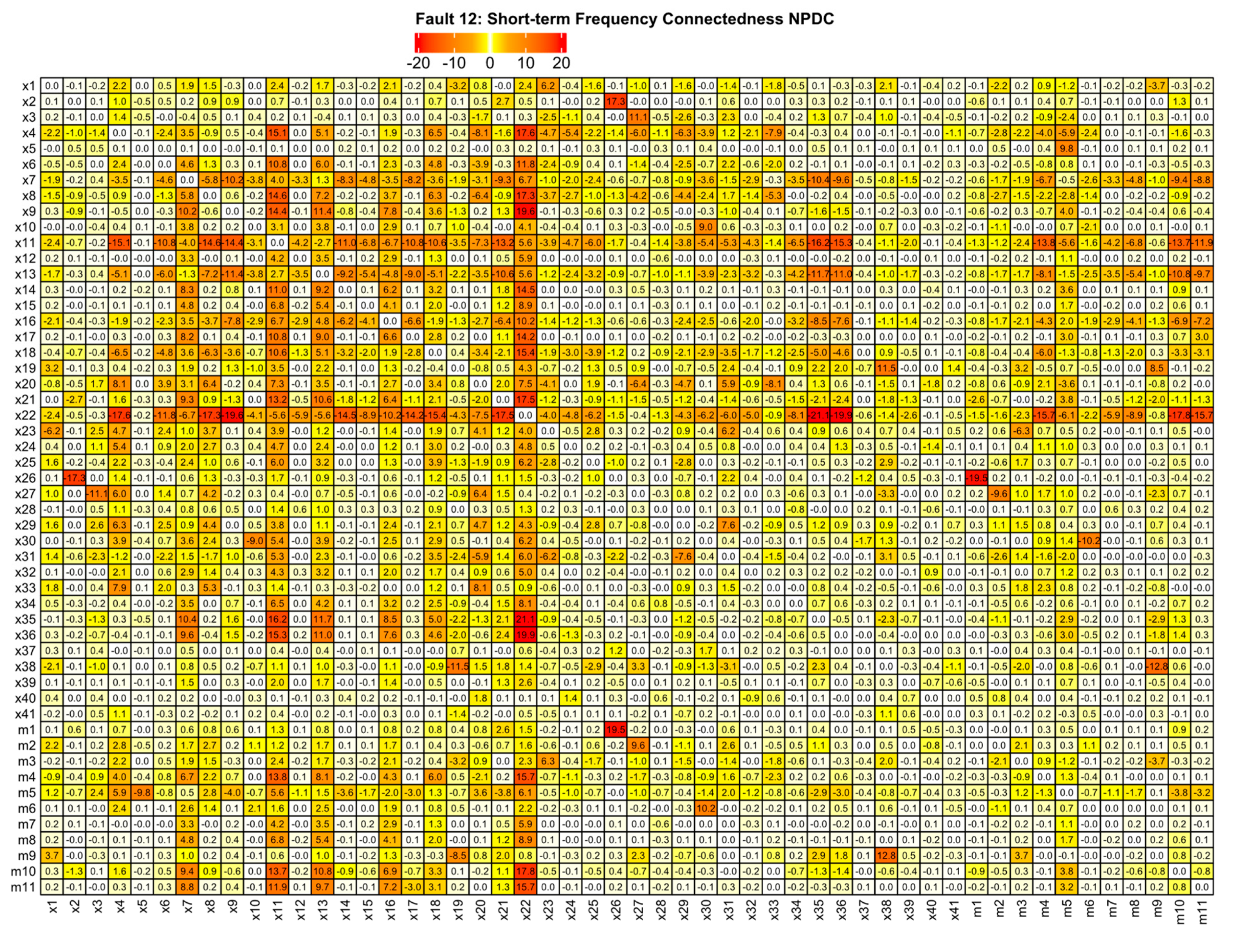
3.4. Connectedness Based on Frequency
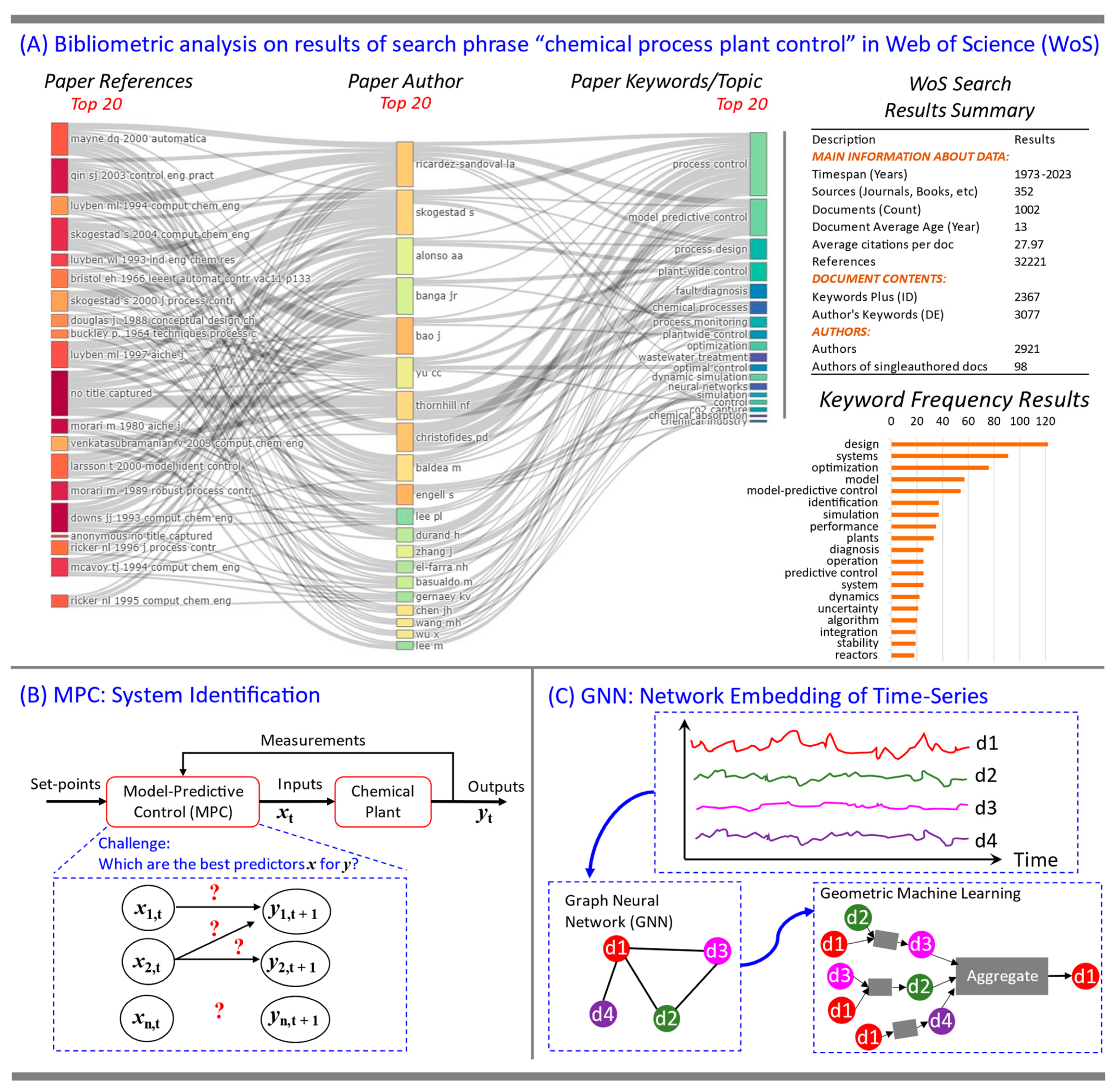
3.5. Significance of the Current Work

3.5.1. Model-Predictive Control (MPC)—System Identification
3.5.2. Graph Neural Network—Network Embedding of Time-Series
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A



References
- Duan, P.; Chen, T.; Shah, S.L.; Yang, F. Methods for root cause diagnosis of plant-wide oscillations. AIChE J. 2014, 60, 2019–2034. [Google Scholar] [CrossRef]
- Wang, Y.; Hu, X.; Zhou, S.; Ji, G. Oscillation Source Detection for Large-Scale Chemical Process with Interpretative Structural Model. In Information Technology and Intelligent Transportation Systems, Proceedings of the 2015 International Conference on Information Technology and Intelligent Transportation Systems ITITS 2015, Xi’an, China, 12–13 December 2015; Springer: Cham, Switzerland, 2017; pp. 441–451. [Google Scholar]
- Rieth, C.A.; Amsel, B.D.; Tran, R.; Cook, M.B. Issues and Advances in Anomaly Detection Evaluation for Joint Human-Automated Systems. In Advances in Human Factors in Robots and Unmanned Systems, Proceedings of the AHFE 2017 International Conference on Human Factors in Robots and Unmanned Systems, Los Angeles, CA, USA, 17–21 July 2017; Springer International Publishing: Cham, Switzerland, 2018; Volume 8, pp. 52–63. [Google Scholar]
- Downs, J.J.; Vogel, E.F. A plant-wide industrial process control problem. Comput. Chem. Eng. 1993, 17, 245–255. [Google Scholar] [CrossRef]
- Cao, J.; Zhang, L.; Zheng, J.; Xia, C. An Integrated Approach to Oscillation Propagation Identification and Source Locating in Process Multi-loop Systems. Chin. J. Chem. Eng. 2011, 19, 999–1008. [Google Scholar] [CrossRef]
- Bounoua, W.; Aftab, M.F.; Omlin, C.W.P. Controller Performance Monitoring: A Survey of Problems and a Review of Approaches from a Data-Driven Perspective with a Focus on Oscillations Detection and Diagnosis. Ind. Eng. Chem. Res. 2022, 61, 17735–17765. [Google Scholar] [CrossRef]
- Granger, C.W.J. Investigating Causal Relations by Econometric Models and Cross-spectral Methods. Econometrica 1969, 37, 424–438. [Google Scholar] [CrossRef]
- Stokes, P.A.; Purdon, P.L. A study of problems encountered in Granger causality analysis from a neuroscience perspective. Proc. Natl. Acad. Sci. USA 2017, 114, E7063–E7072. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shojaie, A.; Fox, E.B. Granger Causality: A Review and Recent Advances. arXiv 2021. [Google Scholar] [CrossRef]
- Diebold, F.X.; Yılmaz, K. On the network topology of variance decompositions: Measuring the connectedness of financial firms. J. Econom. 2014, 182, 119–134. [Google Scholar] [CrossRef] [Green Version]
- Jiang, W.; Gao, R.; Lu, C. The Analysis of Causality and Risk Spillover between Crude Oil and China’s Agricultural Futures. Int. J. Environ. Res. Public Health 2022, 19, 10593. [Google Scholar] [CrossRef]
- Diebold, F.X.; Yilmaz, K. Financial and Macroeconomic Connectedness: A Network Approach to Measurement and Monitoring; Oxford University Press: Oxford, UK, 2015. [Google Scholar] [CrossRef]
- Baruník, J.; Křehlík, T. Measuring the Frequency Dynamics of Financial Connectedness and Systemic Risk. J. Financ. Econom. 2018, 16, 271–296. [Google Scholar] [CrossRef]
- Marlin, T.E. Process Control: Designing Processes and Control Systems for Dynamic Performance, 2nd ed.; McGraw-Hill Company: New York, NY, USA, 2000. [Google Scholar]
- Joffe, M. Equilibrium, Instability, Growth and Feedback in Economics. In Feedback Economics: Economic Modeling with System Dynamics; Cavana, R.Y., Dangerfield, B.C., Pavlov, O.V., Radzicki, M.J., Wheat, I.D., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 43–68. [Google Scholar] [CrossRef]
- Rieth, C.A.; Amsel, B.D.; Tran, R.; Cook, M.B. Additional Tennessee Eastman Process Simulation Data for Anomaly Detection Evaluation; Harvard Dataverse: Cambridge, MA, USA, 2017. [Google Scholar] [CrossRef]
- Diebold, F.X.; Yilmaz, K. Measuring Financial Asset Return and Volatility Spillovers, with Application to Global Equity Markets. Econ. J. 2009, 119, 158–171. [Google Scholar] [CrossRef] [Green Version]
- CRAN. The Comprehensive R Archive Network (CRAN); CRAN: Vienna, Austria, 2023. [Google Scholar]
- RStudioTeam. RStudio: Integrated Development for R. RStudio; PBC: Boston, MA, USA, 2020. [Google Scholar]
- Fortela, D.L.B.; Mikolajczyk, A.P. Tennessee-Eastman Chemical Process (TEP) Connectedness; GitHub: San Francisco, CA, USA, 2023. [Google Scholar]
- Gabauer, D.; Gabauer, M.D. R-Package: ConnectednessApproach, R package Version 1.0.1; The Comprehensive R Archive Network (CRAN): Vienna, Austria, 2022. [Google Scholar]
- Kang, S.H.; Lee, J.W. The network connectedness of volatility spillovers across global futures markets. Phys. A: Stat. Mech. Its Appl. 2019, 526, 120756. [Google Scholar] [CrossRef]
- Csardi, G.; Nepusz, T. The igraph software package for complex network research. InterJournal 2006, 1695, 1–9. [Google Scholar]
- Naeem, M.A.; Peng, Z.; Suleman, M.T.; Nepal, R.; Shahzad, S.J.H. Time and frequency connectedness among oil shocks, electricity and clean energy markets. Energy Econ. 2020, 91, 104914. [Google Scholar] [CrossRef]
- Chatziantoniou, I.; Gabauer, D.; Gupta, R. Integration and Risk Transmission in the Market for Crude Oil: A Time-Varying Parameter Frequency Connectedness Approach; University of Pretoria, Department of Economics: Pretoria, South Africa, 2021. [Google Scholar]
- Wu, W.; Song, C.; Liu, J.; Zhao, J. Data-knowledge-driven distributed monitoring for large-scale processes based on digraph. J. Process Control. 2022, 109, 60–73. [Google Scholar] [CrossRef]
- Jiang, Q.; Yan, X.; Huang, B. Review and Perspectives of Data-Driven Distributed Monitoring for Industrial Plant-Wide Processes. Ind. Eng. Chem. Res. 2019, 58, 12899–12912. [Google Scholar] [CrossRef]
- Yang, F.; Duan, P.; Shah, S.L.; Chen, T. Capturing Causality from Process Data. In Capturing Connectivity and Causality in Complex Industrial Processes; Yang, F., Duan, P., Shah, S.L., Chen, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 41–65. [Google Scholar] [CrossRef]
- Aria, M.; Cuccurullo, C. Bibliometrix: An R-tool for comprehensive science mapping analysis. J. Informetr. 2017, 11, 959–975. [Google Scholar] [CrossRef]
- Ricardez-Sandoval, L.A.; Budman, H.M.; Douglas, P.L. Simultaneous design and control of chemical processes with application to the Tennessee Eastman process. J. Process Control 2009, 19, 1377–1391. [Google Scholar] [CrossRef]
- Skogestad, S. Control structure design for complete chemical plants. Comput. Chem. Eng. 2004, 28, 219–234. [Google Scholar] [CrossRef]
- Antelo, L.T.; Banga, J.R.; Alonso, A.A. Hierarchical design of decentralized control structures for the Tennessee Eastman Process. Comput. Chem. Eng. 2008, 32, 1995–2015. [Google Scholar] [CrossRef]
- Antelo, L.T.; Exler, O.; Banga, J.R.; Alonso, A.A. Optimal tuning of thermodynamic-based decentralized PI control loops: Application to the Tennessee Eastman Process. AIChE J. 2008, 54, 2904–2924. [Google Scholar] [CrossRef] [Green Version]
- Tippett, M.J.; Bao, J. Distributed model predictive control based on dissipativity. AIChE J. 2012, 59, 787–804. [Google Scholar] [CrossRef]
- Lin, S.-W.; Yu, C.-C. Design and control for recycle plants with heat-integrated separators. Chem. Eng. Sci. 2004, 59, 53–70. [Google Scholar] [CrossRef]
- Thornhill, N. Finding the source of nonlinearity in a process with plant-wide oscillation. IEEE Trans. Control. Syst. Technol. 2005, 13, 434–443. [Google Scholar] [CrossRef] [Green Version]
- Durand, H.; Christofides, P.D. Economic Model Predictive Control: Handling Valve Actuator Dynamics and Process Equipment Considerations. Found. Trends® Syst. Control. 2018, 5, 293–350. [Google Scholar] [CrossRef]
- Baldea, M.; El-Farra, N.H.; Ydstie, B.E. Dynamics and control of chemical process networks: Integrating physics, communication and computation. Comput. Chem. Eng. 2012, 51, 42–54. [Google Scholar] [CrossRef]
- Engell, S. Feedback control for optimal process operation. J. Process. Control. 2007, 17, 203–219. [Google Scholar] [CrossRef]
- Nott, H.; Lee, P. An optimal control approach for scheduling mixed batch/continuous process plants with variable cycle time. Comput. Chem. Eng. 1999, 23, 907–917. [Google Scholar] [CrossRef]
- Durand, H. A Nonlinear Systems Framework for Cyberattack Prevention for Chemical Process Control Systems. Mathematics 2018, 6, 169. [Google Scholar] [CrossRef] [Green Version]
- Li, C.; Zhang, J.; Wang, G. Batch-to-batch optimal control of batch processes based on recursively updated nonlinear partial least squares models. Chem. Eng. Commun. 2006, 194, 261–279. [Google Scholar] [CrossRef]
- El-Farra, N.H.; Gani, A.; Christofides, P.D. Fault-tolerant control of process systems using communication networks. AIChE J. 2005, 51, 1665–1682. [Google Scholar] [CrossRef]
- Zumoffen, D.; Basualdo, M. From Large Chemical Plant Data to Fault Diagnosis Integrated to Decentralized Fault-Tolerant Control: Pulp Mill Process Application. Ind. Eng. Chem. Res. 2008, 47, 1201–1220. [Google Scholar] [CrossRef]
- Ingildsen, P.; Rosen, C.; Gernaey, K.; Nielsen, M.; Guildal, T.; Jacobsen, B. Modelling and control strategy testing of biological and chemical phosphorus removal at Avedøre WWTP. Water Sci. Technol. 2006, 53, 105–113. [Google Scholar] [CrossRef] [PubMed]
- Chan, L.L.T.; Chen, J. Probabilistic uncertainty based simultaneous process design and control with iterative expected improvement model. Comput. Chem. Eng. 2017, 106, 609–620. [Google Scholar] [CrossRef]
- Biliyok, C.; Lawal, A.; Wang, M.; Seibert, F. Dynamic modelling, validation and analysis of post-combustion chemical absorption CO2 capture plant. Int. J. Greenh. Gas Control. 2012, 9, 428–445. [Google Scholar] [CrossRef]
- Wu, X.; Shen, J.; Li, Y.; Wang, M.; Lawal, A.; Lee, K.Y. Nonlinear dynamic analysis and control design of a solvent-based post-combustion CO2 capture process. Comput. Chem. Eng. 2018, 115, 397–406. [Google Scholar] [CrossRef]
- Husnil, Y.A.; Lee, M. Control structure synthesis for operational optimization of mixed refrigerant processes for liquefied natural gas plant. AIChE J. 2014, 60, 2428–2441. [Google Scholar] [CrossRef]
- Mayne, D.Q. Model predictive control: Recent developments and future promise. Automatica 2014, 50, 2967–2986. [Google Scholar] [CrossRef]
- Qin, S.; Badgwell, T.A. A survey of industrial model predictive control technology. Control. Eng. Pract. 2002, 11, 733–764. [Google Scholar] [CrossRef]
- Luyben, M.; Floudas, C. Analyzing the interaction of design and control—1. A multiobjective framework and application to binary distillation synthesis. Comput. Chem. Eng. 1994, 18, 933–969. [Google Scholar] [CrossRef]
- Bristol, E. On a new measure of interaction for multivariable process control. IEEE Trans. Autom. Control 1966, 11, 133–134. [Google Scholar] [CrossRef]
- Skogestad, S. Plantwide control: The search for the self-optimizing control structure. J. Process. Control. 2000, 10, 487–507. [Google Scholar] [CrossRef]
- Douglas, J.M. Conceptual Design of Chemical Processes; McGraw-Hill: New York, NY, USA, 1988; p. 601. [Google Scholar]
- Buckley, P.S. Techniques of Process Control; Wiley: Hoboken, NJ, USA, 1965. [Google Scholar]
- Luyben, M.L.; Tyréus, B.D. An industrial design/control study for the vinyl acetate monomer process. Comput. Chem. Eng. 1998, 22, 867–877. [Google Scholar] [CrossRef]
- Morari, M.; Stephanopoulos, G. Studies in the synthesis of control structures for chemical processes: Part II: Structural aspects and the synthesis of alternative feasible control schemes. AIChE J. 1980, 26, 232–246. [Google Scholar] [CrossRef]
- Venkatasubramanian, V.; Rengaswamy, R.; Yin, K.; Kavuri, S.N. A review of process fault detection and diagnosis: Part I: Quantitative model-based methods. Comput. Chem. Eng. 2003, 27, 293–311. [Google Scholar] [CrossRef]
- Truls, L.; Skogestad, S. Plantwide control—A review and a new design procedure. Model. Identif. Control 2000, 21, 209–240. [Google Scholar]
- Morari, M.; Zafiriou, E. Robust Process Control; Prentice-Hall, Inc.: Englewood Cliffs, NJ, USA, 1989; p. 488. [Google Scholar]
- Ricker, N.L. Decentralized control of the Tennessee Eastman Challenge Process. J. Process. Control. 1996, 6, 205–221. [Google Scholar] [CrossRef]
- McAvoy, T.; Ye, N. Base control for the Tennessee Eastman problem. Comput. Chem. Eng. 1994, 18, 383–413. [Google Scholar] [CrossRef]
- Ricker, N.; Lee, J. Nonlinear model predictive control of the Tennessee Eastman challenge process. Comput. Chem. Eng. 1995, 19, 961–981. [Google Scholar] [CrossRef]
- Bahakim, S.S.; Ricardez-Sandoval, L.A. Simultaneous design and MPC-based control for dynamic systems under uncertainty: A stochastic approach. Comput. Chem. Eng. 2014, 63, 66–81. [Google Scholar] [CrossRef]
- Gutierrez, G.; Ricardez-Sandoval, L.A.; Budman, H.; Prada, C. An MPC-based control structure selection approach for simultaneous process and control design. Comput. Chem. Eng. 2014, 70, 11–21. [Google Scholar] [CrossRef]
- He, Z.R.; Sahraei, M.H.; Ricardez-Sandoval, L.A. Flexible operation and simultaneous scheduling and control of a CO2 capture plant using model predictive control. Int. J. Greenh. Gas Control 2016, 48, 300–311. [Google Scholar] [CrossRef]
- Francisco, M.; Skogestad, S.; Vega, P. Model predictive control for the self-optimized operation in wastewater treatment plants: Analysis of dynamic issues. Comput. Chem. Eng. 2015, 82, 259–272. [Google Scholar] [CrossRef] [Green Version]
- Albalawi, F.; Durand, H.; Christofides, P.D. Process operational safety via model predictive control: Recent results and future research directions. Comput. Chem. Eng. 2018, 114, 171–190. [Google Scholar] [CrossRef]
- Wang, S.; Simkoff, J.M.; Baldea, M.; Chiang, L.H.; Castillo, I.; Bindlish, R.; Stanley, D.B. Autocovariance-based plant-model mismatch estimation for linear model predictive control. Syst. Control Lett. 2017, 104, 5–14. [Google Scholar] [CrossRef] [Green Version]
- Forbes, M.G.; Patwardhan, R.S.; Hamadah, H.; Gopaluni, R.B. Model Predictive Control in Industry: Challenges and Opportunities. IFAC-Pap. 2015, 48, 531–538. [Google Scholar] [CrossRef]
- Ortiz Torres, G.; Rumbo Morales, J.Y.; Ramos Martinez, M.; Valdez-Martínez, J.S.; Calixto-Rodriguez, M.; Sarmiento-Bustos, E.; Torres Cantero, C.A.; Buenabad-Arias, H.M. Active Fault-Tolerant Control Applied to a Pressure Swing Adsorption Process for the Production of Bio-Hydrogen. Mathematics 2023, 11, 1129. [Google Scholar] [CrossRef]
- Kaiser, E.; Kutz, J.N.; Brunton, S.L. Sparse identification of nonlinear dynamics for model predictive control in the low-data limit. Proc. R. Soc. A Math. Phys. Eng. Sci. 2018, 474, 20180335. [Google Scholar] [CrossRef] [Green Version]
- Lomov, I.; Lyubimov, M.; Makarov, I.; Zhukov, L.E. Fault detection in Tennessee Eastman process with temporal deep learning models. J. Ind. Inf. Integr. 2021, 23, 100216. [Google Scholar] [CrossRef]
- Fabian Hartung, B.J.F.; Michels, T.; Wagner, D.; Liznerski, P.; Reithermann, S.; Fellenz, S.; Jirasek, F.; Rudolph, M.; Neider, D.; Leitte, H.; et al. Deep Anomaly Detection on Tennessee Eastman Process Data. arXiv 2023. [Google Scholar] [CrossRef]
- Tjøstheim, D.; Jullum, M.; Løland, A. Some recent trends in embeddings of time series and dynamic networks. arXiv 2022. [Google Scholar] [CrossRef]
- Peña, D.; Yohai, V.J. Generalized Dynamic Principal Components. J. Am. Stat. Assoc. 2016, 111, 1121–1131. [Google Scholar] [CrossRef]
- Hyvärinen, A.; Oja, E. Independent component analysis: Algorithms and applications. Neural Netw. 2000, 13, 411–430. [Google Scholar] [CrossRef] [Green Version]
- Hinton, G.E.; Salakhutdinov, R. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kohonen, T. Self-organized formation of topologically correct feature maps. Biol. Cybern. 1982, 43, 59–69. [Google Scholar] [CrossRef]
- Xia, F.; Sun, K.; Yu, S.; Aziz, A.; Wan, L.; Pan, S.; Liu, H. Graph Learning: A Survey. IEEE Trans. Artif. Intell. 2021, 2, 109–127. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Current Symbol | Variable Definition | Original Symbol [4] | Units |
|---|---|---|---|
| x1 | A feed (stream 1) | XMEAS (1) | kscmh |
| x2 | D feed (stream 2) | XMEAS (2) | kg/h |
| x3 | E feed (stream 3) | XMEAS (3) | kg/h |
| x4 | A and C feed (stream 4) | XMEAS (4) | kscmh |
| x5 | Recycle flow (stream 8) | XMEAS (5) | kscmh |
| x6 | Reactor feed rate (stream 6) | XMEAS (6) | kscmh |
| x7 | Reactor pressure | XMEAS (7) | kPa gauge |
| x8 | Reactor level | XMEAS (8) | % |
| x9 | Reactor temperature | XMEAS (9) | °C |
| x10 | Purge rate (stream 9) | XMEAS (10) | kscmh |
| x11 | Product separator temperature | XMEAS (11) | °C |
| x12 | Product separator level | XMEAS (12) | % |
| x13 | Product separator pressure | XMEAS (13) | kPa gauge |
| x14 | Product separator underflow (stream 10) | XMEAS (14) | m3/h |
| x15 | Stripper level | XMEAS (15) | % |
| x16 | Stripper pressure | XMEAS (16) | kPa gauge |
| x17 | Stripper underflow (stream 11) | XMEAS (17) | m3/h |
| x18 | Stripper temperature | XMEAS (18) | °C |
| x19 | Stripper steam flow | XMEAS (19) | kg/h |
| x20 | Compressor work | XMEAS (20) | kW |
| x21 | Reactor cooling water outlet temperature | XMEAS (21) | °C |
| x22 | Separator cooling water outlet temperature | XMEAS (22) | °C |
| x23 | A mole % reactor feed (stream 6) | XMEAS (23) | mol% |
| x24 | B mole % reactor feed (stream 6) | XMEAS (24) | mol% |
| x25 | C mole % reactor feed (stream 6) | XMEAS (25) | mol% |
| x26 | D mole % reactor feed (stream 6) | XMEAS (26) | mol% |
| x27 | E mole % reactor feed (stream 6) | XMEAS (27) | mol% |
| x28 | F mole % reactor feed (stream 6) | XMEAS (28) | mol% |
| x29 | A mole % purge gas (stream 9) | XMEAS (29) | mol% |
| x30 | B mole % purge gas (stream 9) | XMEAS (30) | mol% |
| x31 | C mole % purge gas (stream 9) | XMEAS (31) | mol% |
| x32 | D mole % purge gas (stream 9) | XMEAS (32) | mol% |
| x33 | E mole % purge gas (stream 9) | XMEAS (33) | mol% |
| x34 | F mole % purge gas (stream 9) | XMEAS (34) | mol% |
| x45 | G mole % purge gas (stream 9) | XMEAS (35) | mol% |
| x36 | H mole % purge gas (stream 9) | XMEAS (36) | mol% |
| x37 | D mole % product (stream 11) | XMEAS (37) | mol% |
| x38 | E mole % product (stream 11) | XMEAS (38) | mol% |
| x39 | F mole % product (stream 11) | XMEAS (39) | mol% |
| x40 | G mole % product (stream 11) | XMEAS (40) | mol% |
| x41 | H mole % product (stream 11) | XMEAS (41) | mol% |
| m1 | D feed flow valve opening (stream 2) | XMV (1) | % open |
| m2 | E feed flow valve opening (stream 3) | XMV (2) | % open |
| m3 | A feed flow valve opening (stream 1) | XMV (3) | % open |
| m4 | A and C feed flow valve opening (stream 4) | XMV (4) | % open |
| m5 | Compressor recycle valve opening | XMV (5) | % open |
| m6 | Purge valve opening (stream 9) | XMV (6) | % open |
| m7 | Separator pot liquid flow valve opening (stream 10) | XMV (7) | % open |
| m8 | Stripper liquid product flow valve opening (stream 11) | XMV (8) | % open |
| m9 | Stripper steam valve opening | XMV (9) | % open |
| m10 | Reactor cooling water flow valve opening | XMV (10) | % open |
| m11 | Condenser cooling water flow valve opening | XMV (11) | % open |
| Fault No. | Fault Description | Type |
|---|---|---|
| 1 | A/C feed ratio, B composition constant (stream 4) | Step Change |
| 2 | B composition, A/C ratio constant (stream 4) | Step Change |
| 3 | D feed temperature (stream 2) | Step Change |
| 4 | Reactor cooling water inlet temperature | Step Change |
| 5 | Condenser cooling water inlet temperature | Step Change |
| 6 | A feed loss (stream 1) | Step Change |
| 7 | C heater pressure loss—reduced availability (stream 4) | Step Change |
| 8 | A, B, C feed composition (stream 4) | Random Variation |
| 9 | D feed temperature (stream 2) | Random Variation |
| 10 | C feed temperature (stream 4) | Random Variation |
| 11 | Reactor cooling water inlet temperature | Random Variation |
| 12 | Condenser cooling water inlet temperature | Random Variation |
| Fault No. | Mean of Standardized Residuals | Degrees of Freedom | t-Statistic | p-Value Two-Sided t-test | ||
|---|---|---|---|---|---|---|
| 1 | 28.66 | 2703 | 1.8129 | 0.06995 | ||
| 2 | 30.92 | 2703 | 1.9395 | 0.05254 | ||
| 3 | 30.84 | 2703 | 1.9615 | 0.05000 | ||
| 4 | 28.45 | 2703 | 1.8305 | 0.06728 | ||
| 5 | 28.59 | 2703 | 1.7647 | 0.07773 | ||
| 6 | 10.20 | 2703 | 1.8913 | 0.05870 | ||
| 7 | 31.66 | 2703 | 1.9764 | 0.04821 | ||
| 8 | 25.75 | 2703 | 1.5543 | 0.12020 | ||
| 9 | 30.76 | 2703 | 1.9507 | 0.05120 | ||
| 10 | 31.19 | 2703 | 1.9776 | 0.04808 | ||
| 11 | 30.86 | 2703 | 1.9541 | 0.05079 | ||
| 12 | 31.48 | 2703 | 1.7588 | 0.07872 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fortela, D.L.B.; Mikolajczyk, A.P. Detecting Plant-Wide Oscillation Propagation Effects of Disturbances and Faults in a Chemical Process Plant Using Network Topology of Variance Decompositions. Processes 2023, 11, 1747. https://doi.org/10.3390/pr11061747
Fortela DLB, Mikolajczyk AP. Detecting Plant-Wide Oscillation Propagation Effects of Disturbances and Faults in a Chemical Process Plant Using Network Topology of Variance Decompositions. Processes. 2023; 11(6):1747. https://doi.org/10.3390/pr11061747
Chicago/Turabian StyleFortela, Dhan Lord B., and Ashley P. Mikolajczyk. 2023. "Detecting Plant-Wide Oscillation Propagation Effects of Disturbances and Faults in a Chemical Process Plant Using Network Topology of Variance Decompositions" Processes 11, no. 6: 1747. https://doi.org/10.3390/pr11061747