

Hyperparameter Search for Machine Learning Algorithms for Optimizing the Computational Complexity

Abstract
:1. Introduction
- (a)
- To use different ML-based datasets to test the multiple optimization approaches.
- (b)
- To design hybrid Hyperparameter models for testing the computational time, accuracy and cost of proposed model.
2. Related Work
3. Proposed Methodology
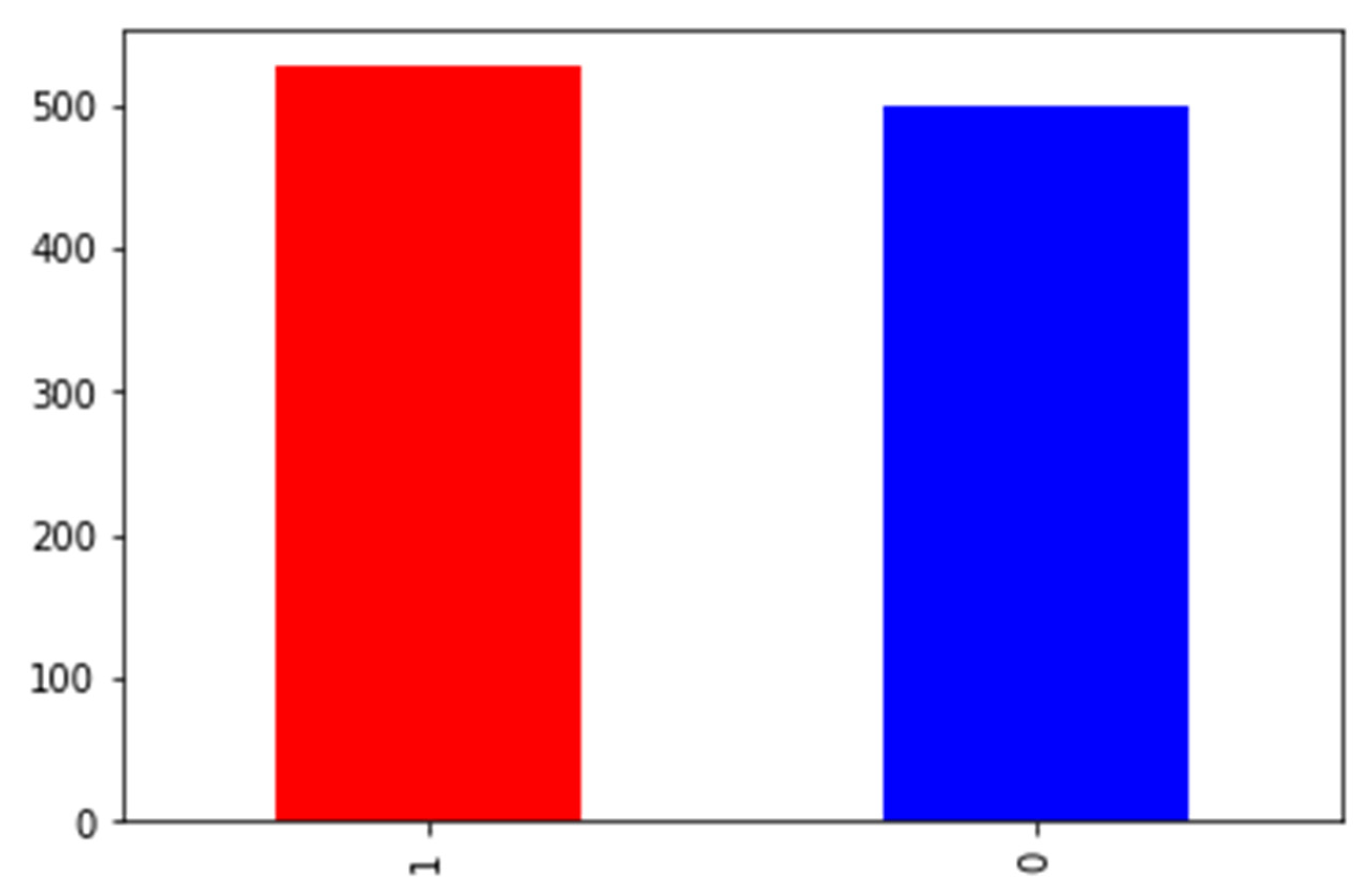
3.1. Data Preprocessing
3.2. Feature Engineering
3.3. Feature Scoring
3.4. Ant-Bee Colony Optimization (ACO)
| Algorithm 1. The ACO-SVM pseudocode. |
| Begin Initialize While stopping criteria not satisfied Position each ant in starting node Repeat For each ant Choose next node by applying state rule End for Until every ant has built a solution Apply offline pheromone update Support Vector Machine Train Model Test Model Fitness Accuracy End while End |
3.5. Genetic Algorithm
| Algorithm 2. The GA-SVM pseudocode. |
| Begin Create initial population While iteration number < max number of iterations For Each Chromosome Evaluate Fitness Support Vector Machine Train Model Test Model Fitness Accuracy End For Parent Select Crossover Mutation Elitism End While End |
3.6. Whale Optimization
| Algorithm 3. The WOA-SVM pseudocode. |
| Begin Create Bubble Net Update a, A, C and L Calculate the distance between each whale If (A < 1) Update the position for current whale Else if A > 1 For each whale Select the new best position Evaluate Fitness Support Vector Machine Train Model Test Model Fitness Accuracy End for End if End |
3.7. Particle Swarm Optimization
| Algorithm 4. The PSO-SVM pseudocode. |
| Begin Initialize While stopping criteria not satisfied Position each ant in starting node Repeat For each ant Choose next node by applying state rule End for Until every swarm has built a solution Apply offline pheromone update Support Vector Machine Train Model Test Model Fitness Accuracy End while End |
4. Results and Discussion
4.1. Parameters
4.2. Performance of ACO-SVM
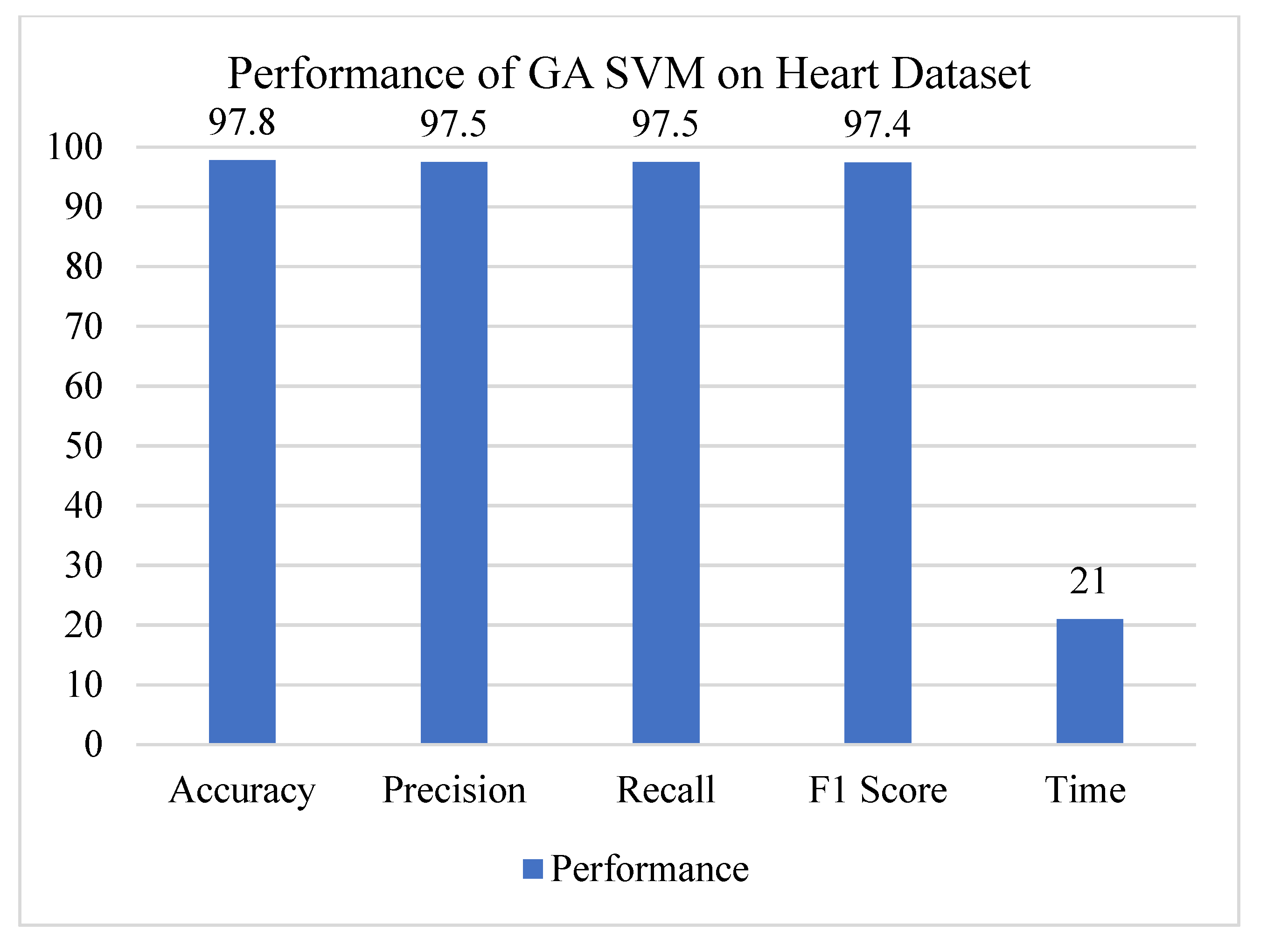
4.3. Performance of GA-SVM
4.4. Performance of WOA-SVM
4.5. Performance of PSO-SVM
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mantovani, R.G.; Rossi, A.L.D.; Vanschoren, J.; Bischl, B.; De Carvalho, A.C.P.L.F. Effectiveness of Random Search in SVM hyperparameter tuning. In Proceedings of the 2015 International Joint Conference on Neural Networks, Killarney, Ireland, 12–17 July 2015. [Google Scholar] [CrossRef]
- Dery, L.; Mengistu, R.; Awe, O. Neural Combinatorial Optimization for Solving Jigsaw Puzzles: A Step Towards Unsupervised Pre-Training. 2017. Available online: http://cs231n.stanford.edu/reports/2017/pdfs/110.pdf (accessed on 15 November 2022).
- Li, Y.; Zhang, Y.; Cai, Y. A new hyperparameter optimization method for power load forecast based on recurrent neural networks. Algorithms 2021, 14, 163. [Google Scholar] [CrossRef]
- Kanimozhi, V.; Jacob, T.P. Artificial intelligence based network intrusion detection with hyperparameter optimization tuning on the realistic cyber dataset CSE-CIC-IDS2018 using cloud computing. In Proceedings of the 2019 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 4–6 April 2019; pp. 33–36. [Google Scholar] [CrossRef]
- Veloso, B.; Gama, J. Self Hyperparameter Tuning for Stream Classification Algorithms. In Proceedings of the Second International Workshop, IoT Streams 2020, and First International Workshop, ITEM 2020, Co-located with ECML/PKDD 2020, Ghent, Belgium, 14–18 September 2020; Communications in Computer and Information Science. Volume 1325, pp. 3–13. [Google Scholar] [CrossRef]
- Bergstra, J.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for hyperparameter optimization. In Proceedings of the 25th Annual Conference on Neural Information Processing Systems (NIPS 2011), Granada, Spain, 12–15 December 2011; Advances in Neural Information Processing Systems 24. pp. 1–9. [Google Scholar]
- Bergstra, J.; Bengio, Y. Random search for hyperparameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Yang, L.; Shami, A. On hyperparameter optimization of machine learning algorithms: Theory and practice. Neurocomputing 2020, 415, 295–316. [Google Scholar] [CrossRef]
- Hossain, R.; Timmer, D. Machine Learning Model Optimization with Hyperparameter Tuning Approach. Glob. J. Comput. Sci. Technol. D Neural Artif. Intell. 2021, 21, 7–13. [Google Scholar]
- Wang, L.; Feng, M.; Zhou, B.; Xiang, B.; Mahadevan, S. Efficient hyperparameter optimization for NLP applications. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 2112–2117. [Google Scholar] [CrossRef]
- Escorcia-Gutierrez, J.; Mansour, R.F.; Beleño, K.; Jiménez-Cabas, J.; Pérez, M.; Madera, N.; Velasquez, K. Automated Deep Learning Empowered Breast Cancer Diagnosis Using Biomedical Mammogram Images. Comput. Mater. Contin. 2022, 71, 4221–4235. [Google Scholar] [CrossRef]
- Zahedi, L.; Mohammadi, F.G.; Amini, M.H.; Amini, M.H. OptABC: An Optimal Hyperparameter Tuning Approach for Machine Learning Algorithms. In Proceedings of the 2021 20th IEEE International Conference on Machine Learning and Applications (ICMLA), Pasadena, CA, USA, 13–16 December 2021; pp. 1138–1145. [Google Scholar] [CrossRef]
- Elgeldawi, E.; Sayed, A.; Galal, A.R.; Zaki, A.M. Hyperparameter tuning for machine learning algorithms used for arabic sentiment analysis. Informatics 2021, 8, 79. [Google Scholar] [CrossRef]
- Probst, P.; Boulesteix, A.L.; Bischl, B. Tunability: Importance of hyperparameters of machine learning algorithms. J. Mach. Learn. Res. 2019, 20, 1–32. [Google Scholar]
- Andonie, R. Hyperparameter optimization in learning systems. J. Membr. Comput. 2019, 1, 279–291. [Google Scholar] [CrossRef]
- Novello, P.; Poëtte, G.; Lugato, D.; Congedo, P. Goal-oriented sensitivity analysis of hyperparameters in deep. J. Sci. Comput. 2023, 94, 45. [Google Scholar] [CrossRef]
- Maclaurin, D.; Duvenaud, D.; Adams, R.P. Gradient-based Hyperparameter Optimization through Reversible Learning. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 37. [Google Scholar]
- Klein, A.; Falkner, S.; Bartels, S.; Hennig, P.; Hutter, F. Fast Bayesian optimization of machine learning hyperparameters on large datasets. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics AISTATS 2017, Fort Lauderdale, FL, USA, 20–22 April 2017; Volume 54. [Google Scholar]
- Morales-Hernández, A.; Van Nieuwenhuyse, I.; Rojas Gonzalez, S. A survey on multi-objective hyperparameter optimization algorithms for machine learning. Artif. Intell. Rev. 2022. [Google Scholar] [CrossRef]
- Pannakkong, W.; Thiwa-Anont, K.; Singthong, K.; Parthanadee, P.; Buddhakulsomsiri, J. Hyperparameter Tuning of Machine Learning Algorithms Using Response Surface Methodology: A Case Study of ANN, SVM, and DBN. Math. Probl. Eng. 2022, 2022, 8513719. [Google Scholar] [CrossRef]
- Wu, Q.; Wang, C.; Huang, S. Frugal Optimization for Cost-related Hyperparameters. In Proceedings of the 35th AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 12A, pp. 10347–10354. [Google Scholar]
- ALGorain, F.T.; Clark, J.A. Bayesian Hyperparameter optimisation for Malware Detection. Electronics 2022, 11, 1640. [Google Scholar] [CrossRef]
- Liang, Q.; Gongora, A.E.; Ren, Z.; Tiihonen, A.; Liu, Z.; Sun, S.; Deneault, J.R.; Bash, D.; Mekki-Berrada, F.; Khan, S.A.; et al. Benchmarking the performance of Bayesian optimization across multiple experimental materials science domains. Npj Comput. Mater. 2021, 7, 188. [Google Scholar] [CrossRef]
- Hazan, E.; Klivans, A.; Yuan, Y. Hyperparameter optimization: A spectral approach. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018; Workshop Track Proceedings. pp. 1–18. [Google Scholar]
- Van Rijn, J.N.; Hutter, F. Hyperparameter importance across datasets. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 2367–2376. [Google Scholar] [CrossRef]
- Luo, G. A review of automatic selection methods for machine learning algorithms and hyperparameter values. Netw. Model. Anal. Health Inform. Bioinforma. 2016, 5, 18. [Google Scholar] [CrossRef]
- Blume, S.; Benedens, T.; Schramm, D. Hyperparameter Optimization Techniques for Designing Software Sensors Based on Artificial Neural Networks. Sensors 2021, 21, 8435. [Google Scholar] [CrossRef] [PubMed]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | Formula |
|---|---|
| Cost | |
| Accuracy |
| Parameter | Description | Possible Values |
|---|---|---|
| C | The regularisation parameter. For a given value of C, the regularisation strength decreases. No negatives allowed. A penalty equal to l2 is imposed. | float, default = 1.0 |
| Degree | Polynomial degree of the kernel function. Totally disregarded by every other kernel out there. | int, default = 3 |
| Kernel | Defines the type of kernel to be used in the algorithm. | ‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’} or callable, default = ’rbf’ |
| Gamma | The ‘rbf,’ ‘poly,’ and ‘sigmoid’ kernel coefficients. | {‘scale’, ‘auto’} or float, default = ’scale’ |
| Coef0 | The kernel function has an independent term. Only in the contexts of poly and sigmoid does it have any bearing. | float, default = 0.0 |
| Shrinking | Whether or not to employ the “shrinking heuristic” | bool, default = True |
| Probability | Allowing for the calculation of probabilities. A performance hit is noticed when calling fit if this is turned on. The function utilizes 5-fold cross-validation internally, which can take some time, and prediction may not agree with prediction. | bool, default = False |
| Tolerance | Acceptable cutoff point for ending. | float, default = 1 × 10−3 |
| Cache Size | Indicate the amount of space required to dedicate to the kernel cache (in MB). | float, default = 200 |
| Class Weight | For SVC, use class weight[i]*C as the value for the class I parameter C. If no other weight is specified, each class is assumed to have a weight of 1. By dividing n samples by (n classes * np.bincount(y)), the “balanced” setting automatically adjusts weights so that they are inversely proportionate to class frequencies in the input data. | dict or ‘balanced’, default = None |
| Verbose | Set the output to be very detailed. Be aware that enabling this parameter may cause problems in a multithreaded environment because it relies on a per-process runtime setting in libsvm. | bool, default = False |
| Max Iterations | A fixed upper bound on the number of iterations the solver can do, or -1 if there is none. | int, default = −1 |
| Decision function shape | Whether to return a decision function of shape (n samples, n classes) similar to that of all other classifiers, or to instead return libsvm’s original one-vs-one (‘ovo’) decision function. To train models, one-on-one (‘ovo’) is always used internally, and an ovr matrix is constructed exclusively from the ovo matrix. However, this parameter is lost in binary classification. | {‘ovo’, ‘ovr’}, default = ’ovr’ |
| Random state | Controls pseudo random number generation for probability estimation data shuffling. Ignored when probability is False. Pass an int for reproducible output across function calls. | bool, default = False |
| Parameter | Description | Possible Values |
|---|---|---|
| C | The regularisation parameter. For a given value of C, the regularisation strength decreases. No negatives allowed. A penalty equal to l2 is being imposed. | default = 1.0 |
| Degree | Polynomial degree of the kernel function. Totally disregarded by every other kernel out there. | 5 |
| Kernel | Defines the type of kernel to be used in the algorithm. | rbf |
| Parameter | Description | Possible Values |
|---|---|---|
| C | Regularisation parameter. For a given value of C, the regularisation strength decreases. No negatives allowed. A penalty equal to l2 is being imposed. | default = 2.0 |
| Degree | Polynomial degree of the kernel function. Totally disregarded by every other kernel out there. | 4 |
| Kernel | Defines the type of kernel to be used in the algorithm. | linear |
| Parameter | Description | Possible Values |
|---|---|---|
| C | The regularisation parameter. For a given value of C, the regularisation strength decreases. No negatives allowed. A penalty equal to l2 is being imposed. | default = 2.0 |
| Kernel | Defines the type of kernel to be used in the algorithm. | polynomial |
| Parameter | Description | Possible Values |
|---|---|---|
| C | The regularisation parameter. For a given value of C, the regularisation strength decreases. No negatives allowed. A penalty equal to l2 is being imposed. | default = 2.0 |
| Kernel | Defines the type of kernel to be used in the algorithm. | polynomial |
| Class Weight | For SVC, use class weight[i]*C as the value for the class I parameter C. If no other weight is specified, each class is assumed to have a weight of 1. By dividing n samples by (n classes * np.bincount(y)), the “balanced” setting automatically adjusts weights so that they are inversely proportionate to class frequencies in the input data. | True |
| Verbose | Set the output to be very detailed. Be aware that enabling this parameter may cause problems in a multithreaded environment because it relies on a per-process runtime setting in libsvm. | False |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, Y.A.; Awwad, E.M.; Al-Razgan, M.; Maarouf, A. Hyperparameter Search for Machine Learning Algorithms for Optimizing the Computational Complexity. Processes 2023, 11, 349. https://doi.org/10.3390/pr11020349
Ali YA, Awwad EM, Al-Razgan M, Maarouf A. Hyperparameter Search for Machine Learning Algorithms for Optimizing the Computational Complexity. Processes. 2023; 11(2):349. https://doi.org/10.3390/pr11020349
Chicago/Turabian StyleAli, Yasser A., Emad Mahrous Awwad, Muna Al-Razgan, and Ali Maarouf. 2023. "Hyperparameter Search for Machine Learning Algorithms for Optimizing the Computational Complexity" Processes 11, no. 2: 349. https://doi.org/10.3390/pr11020349