
An Integrated Method of Bayesian Optimization and D-Optimal Design for Chemical Experiment Optimization

Abstract
:1. Introduction
2. Preliminaries
2.1. Bayesian Optimization
| Algorithm 1. The pseudocode of BO. |
| Input: Dataset |
| for to do Fit Gaussian process model and acquisition function on Solve Evaluate Take end for |
| Output: |
2.2. Local Penalization
| Algorithm 2. The pseudocode of BBOLP. |
| Input: Dataset , Batch size |
| for to do Fit Gaussian process model and acquisition function on Take and for to do Maximization step: Penalization step: end for Take Parallel evaluate in Take end for |
| Output: |
2.3. D-Optimal Design
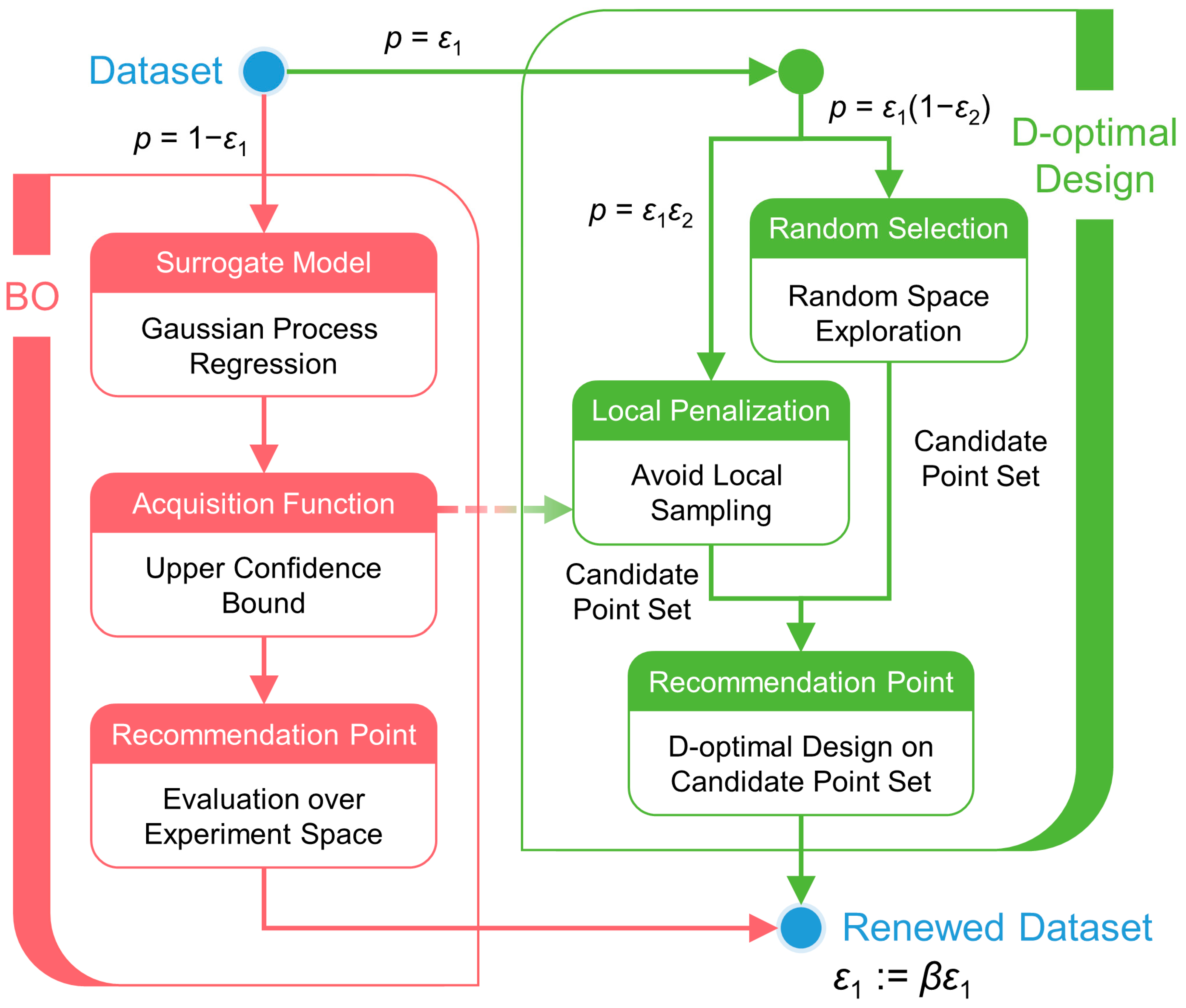
3. Methodology
| Algorithm 3. The pseudocode of BODO. |
| Input: Dataset , , , , Candidate point set size |
| for to do Fit Gaussian process model and acquisition function on Take if then Solve else if then random select samples from else for to do Maximization step: Penalization step: end for end if for do end for end if evaluate Take end for |
| Output: |
4. Results and Discussion
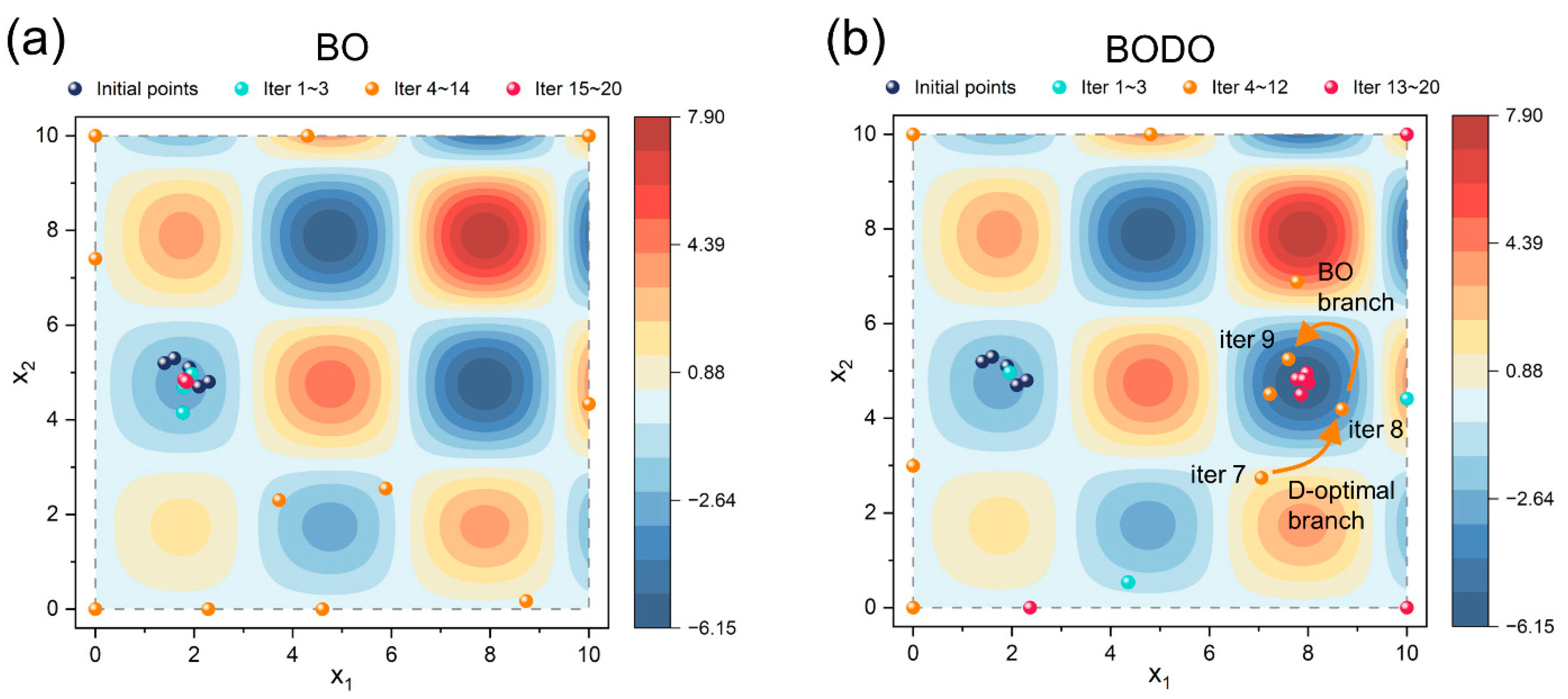
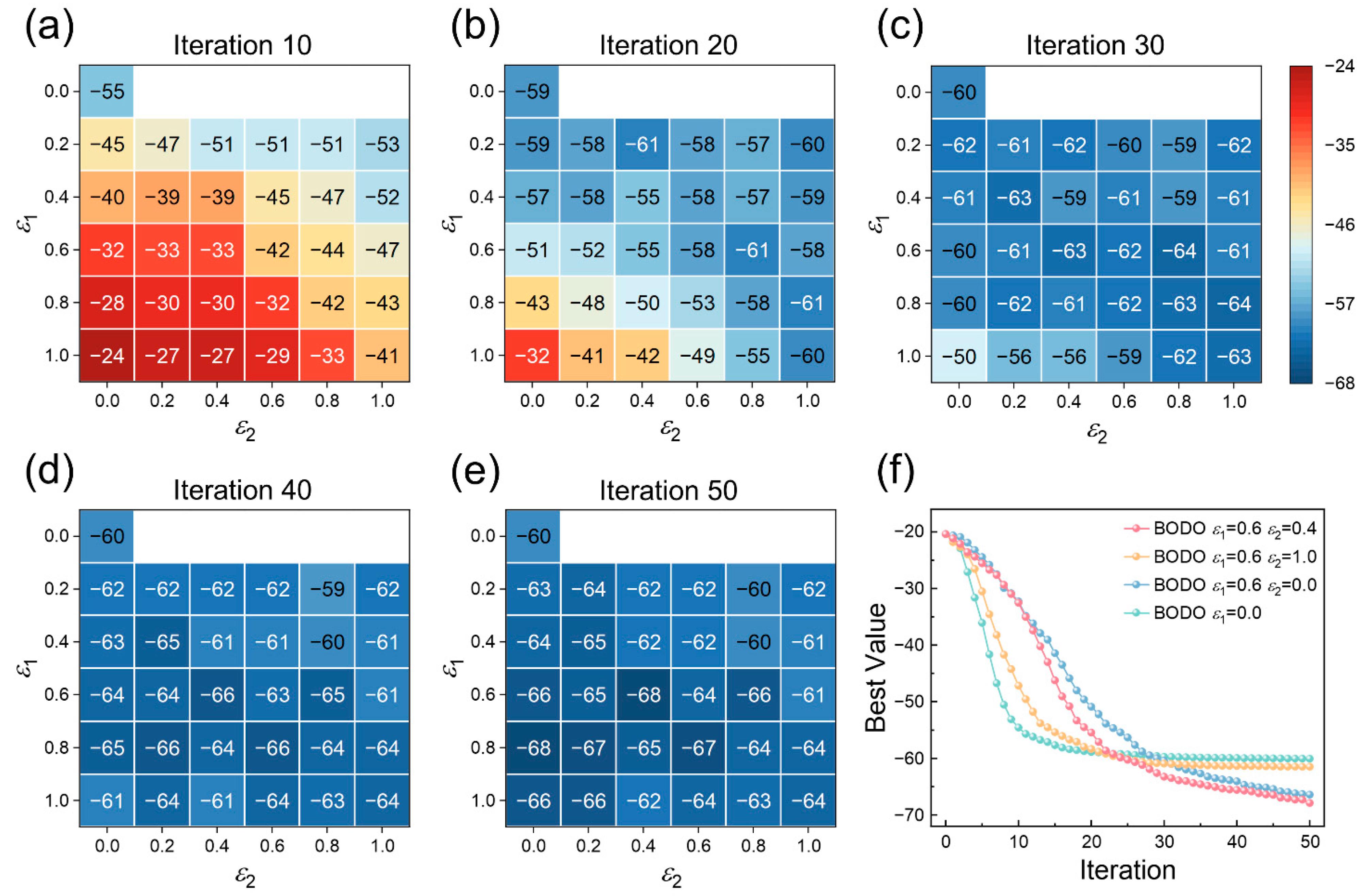
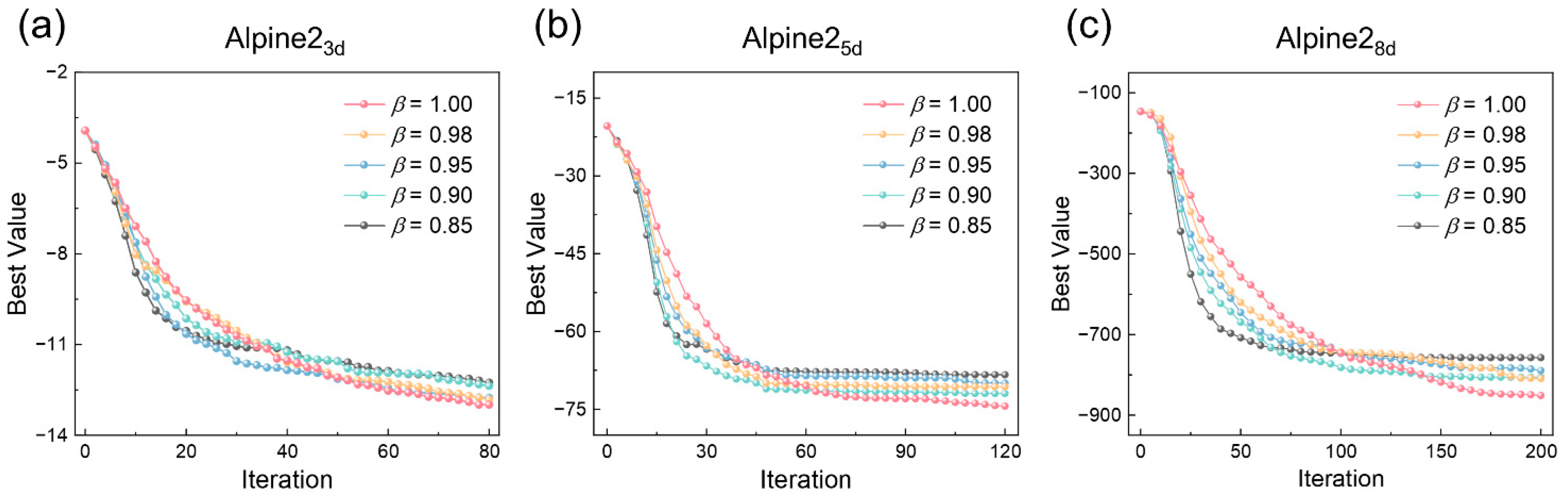
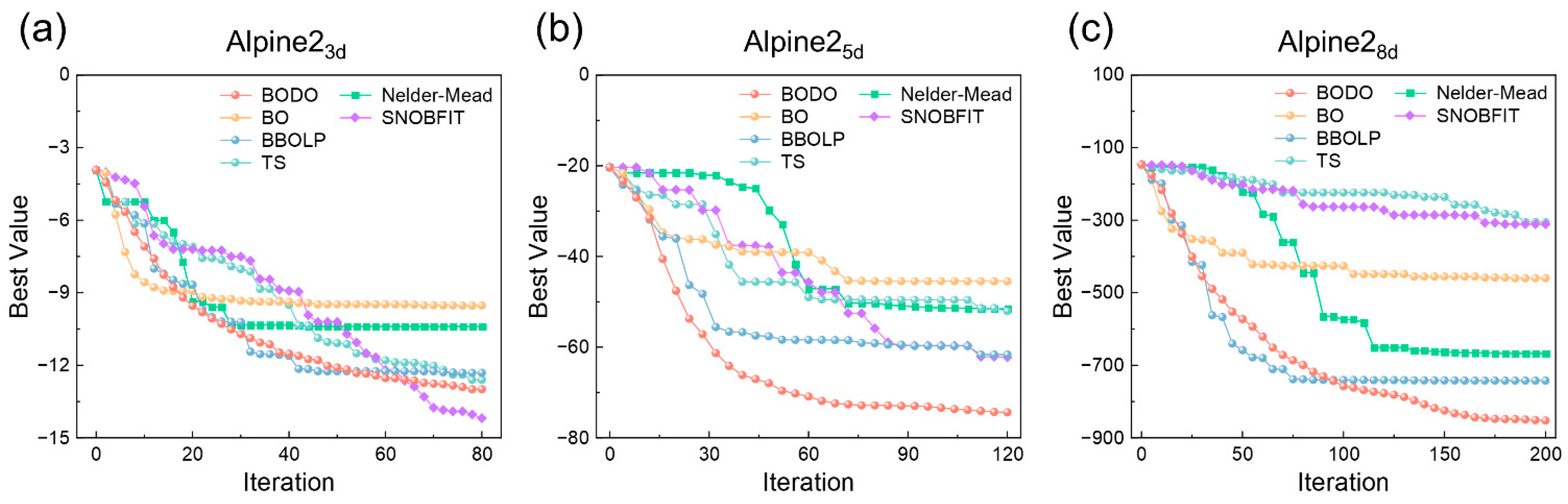
4.1. Benchmark alpine2 Function
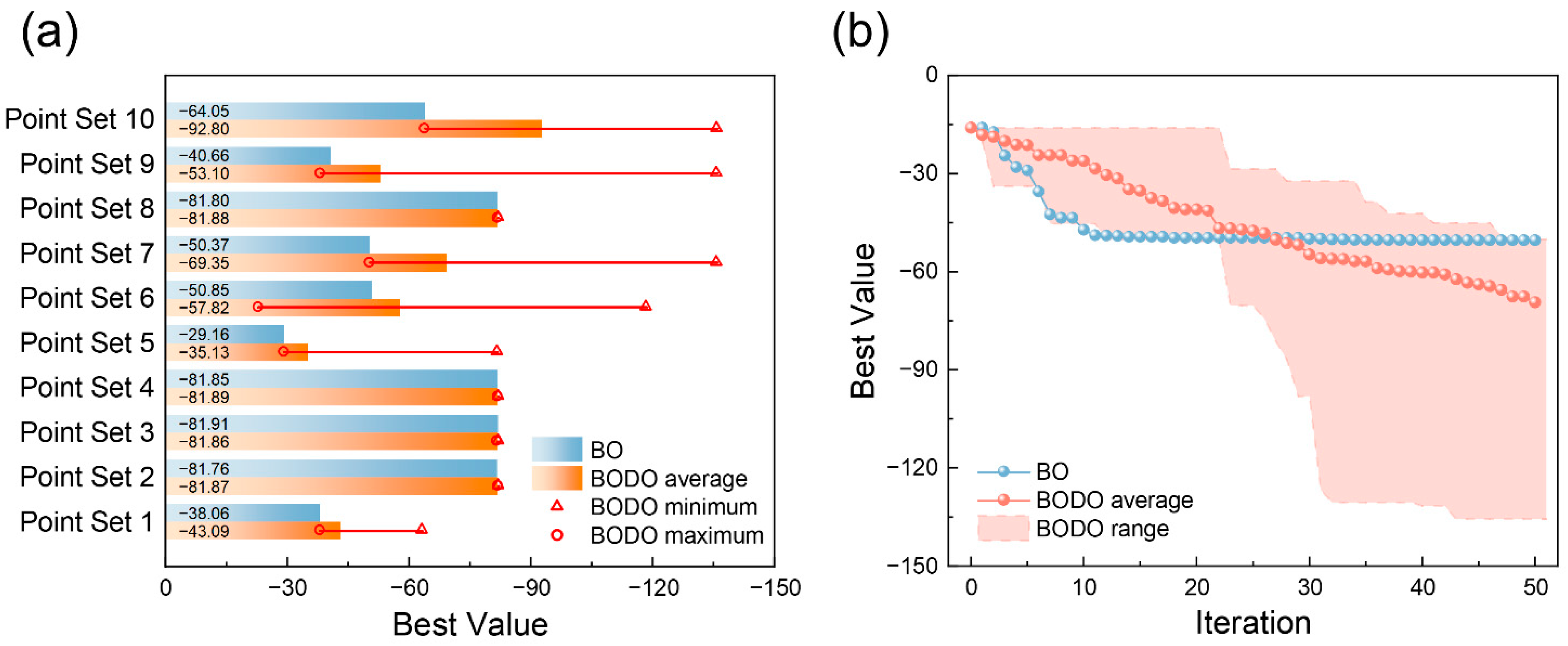
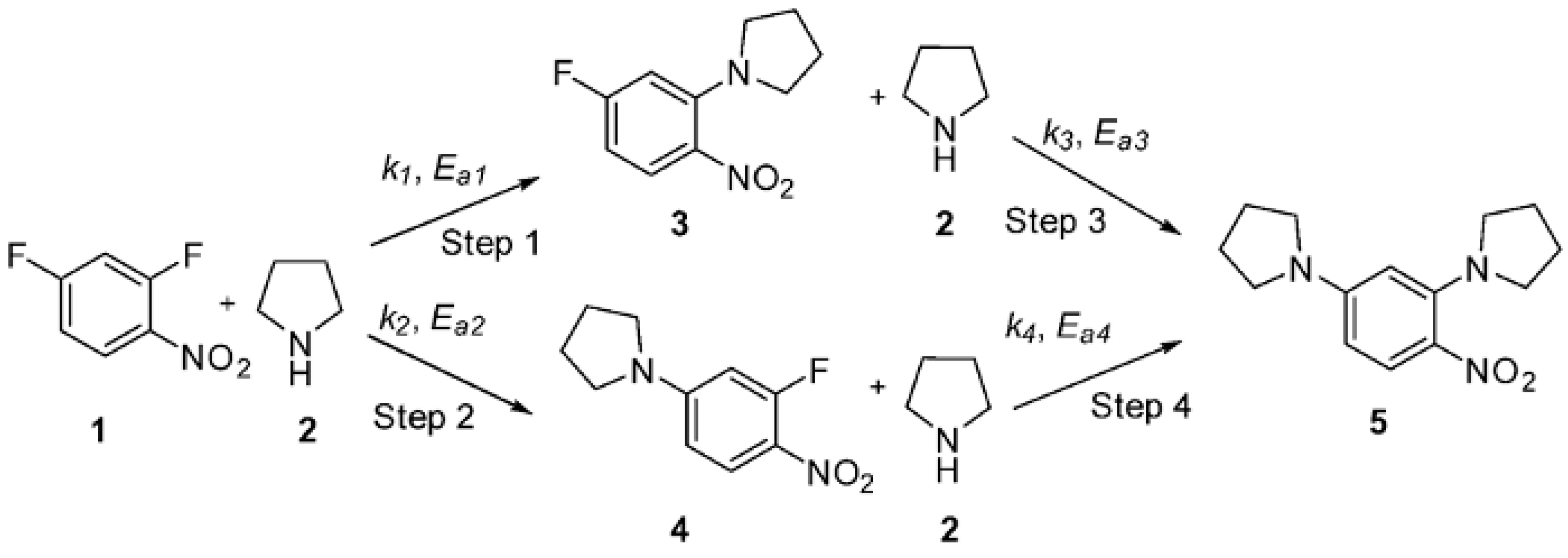
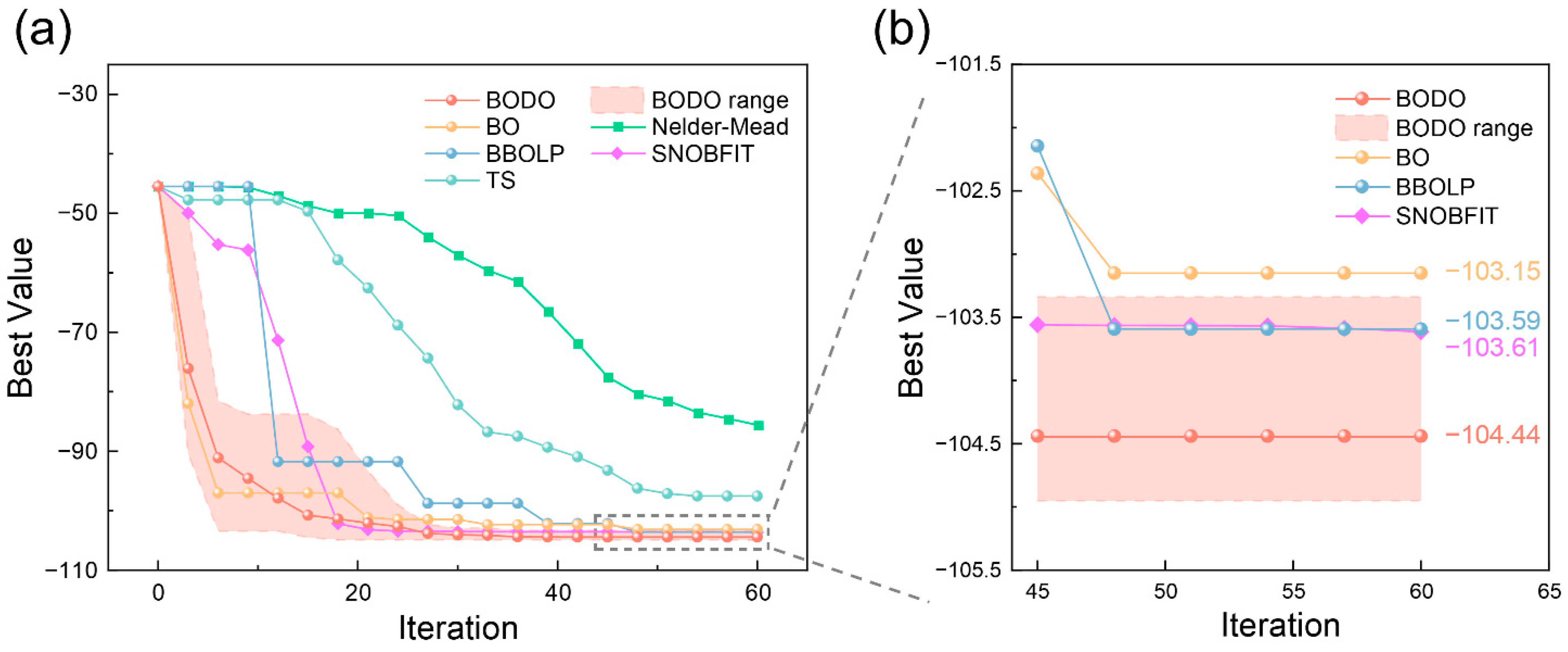
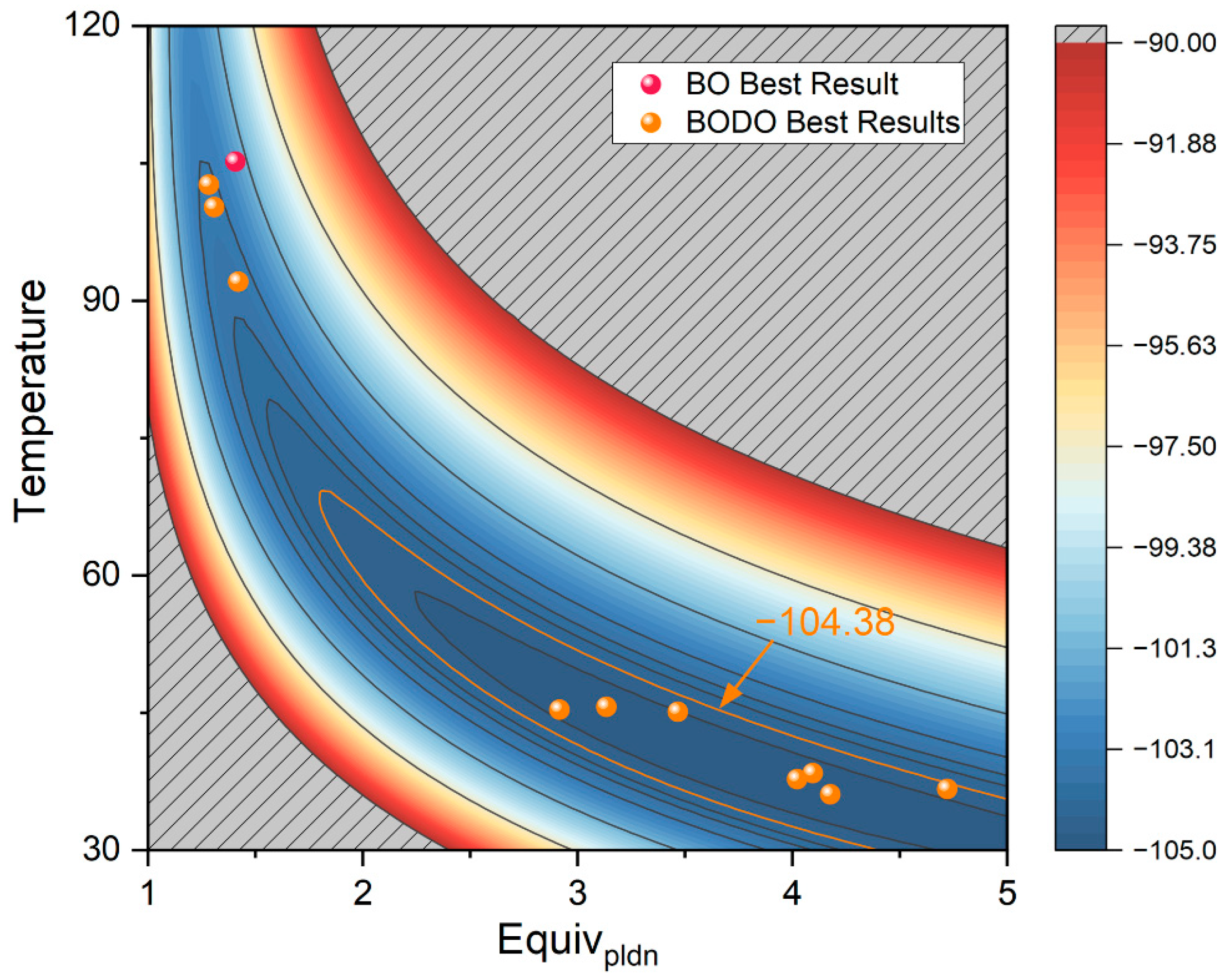
4.2. Benchmark Chemical Process: Summit SnAr
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bourne, R.A.; Hii, K.K.; Reizman, B.J. Introduction to Synthesis 4.0: Towards an internet of chemistry. React. Chem. Eng. 2019, 4, 1504–1505. [Google Scholar] [CrossRef]
- Mateos, C.; Nieves-Remacha, M.J.; Rincón, J.A. Automated platforms for reaction self-optimization in flow. React. Chem. Eng. 2019, 4, 1536–1544. [Google Scholar] [CrossRef]
- Zhang, S.; Liang, X.; Huang, X.; Wang, K.; Qiu, T. Precise and fast microdroplet size distribution measurement using deep learning. Chem. Eng. Sci. 2021, 247, 116926. [Google Scholar] [CrossRef]
- Clayton, A.D.; Manson, J.A.; Taylor, C.; Chamberlain, T.W.; Taylor, B.A.; Clemens, G.; Bourne, R.A. Algorithms for the self-optimisation of chemical reactions. React. Chem. Eng. 2019, 4, 1545–1554. [Google Scholar] [CrossRef]
- Burger, B.; Maffettone, P.M.; Gusev, V.V.; Aitchison, C.M.; Bai, Y.; Wang, X.; Li, X.; Alston, B.M.; Li, B.; Clowes, R.; et al. A mobile robotic chemist. Nature 2020, 583, 237–241. [Google Scholar] [CrossRef]
- Hughes, G.; Mills, H.; De Roure, D.; Frey, J.G.; Moreau, L.; Schraefel, M.C.; Smith, G.; Zaluska, E. The semantic smart laboratory: A system for supporting the chemical eScientist. Org. Biomol. Chem. 2004, 2, 3284–3293. [Google Scholar] [CrossRef] [Green Version]
- Zendehboudi, S.; Ahmadi, M.A.; Mohammadzadeh, O.; Bahadori, A.; Chatzis, I. Thermodynamic Investigation of Asphaltene Precipitation during Primary Oil Production: Laboratory and Smart Technique. Ind. Eng. Chem. Res. 2013, 52, 6009–6031. [Google Scholar] [CrossRef]
- Li, J.; Lu, Y.; Xu, Y.; Liu, C.; Tu, Y.; Ye, S.; Liu, H.; Xie, Y.; Qian, H.; Zhu, X. AIR-Chem: Authentic Intelligent Robotics for Chemistry. J. Phys. Chem. A 2018, 122, 9142–9148. [Google Scholar] [CrossRef]
- Zhang, S.; Qin, K.; Huang, X.; Wei, Y.; Wang, T.; Wang, K.; Qiu, T. Insight into Microdispersion Flows with a Novel Video Deep Learning Method. Adv. Intell. Syst. 2022, 4, 2200098. [Google Scholar] [CrossRef]
- Bi, K.; Zhang, S.; Zhang, C.; Li, H.; Huang, X.; Liu, H.; Qiu, T. Knowledge expression, numerical modeling and optimization application of ethylene thermal cracking: From the perspective of intelligent manufacturing. Chin. J. Chem. Eng. 2021, 38, 1–17. [Google Scholar] [CrossRef]
- Hough, B.R.; Beck, D.A.; Schwartz, D.T.; Pfaendtner, J. Application of machine learning to pyrolysis reaction networks: Reducing model solution time to enable process optimization. Comput. Chem. Eng. 2017, 104, 56–63. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Zhang, S.; Qiu, T. Two-Level Decoupled Ethylene Cracking Optimization of Batch Operation and Cyclic Scheduling. Ind. Eng. Chem. Res. 2022, 61, 16539–16551. [Google Scholar] [CrossRef]
- Shields, B.J.; Stevens, J.; Li, J.; Parasram, M.; Damani, F.; Alvarado, J.I.M.; Janey, J.M.; Adams, R.P.; Doyle, A.G. Bayesian reaction optimization as a tool for chemical synthesis. Nature 2021, 590, 89–96. [Google Scholar] [CrossRef]
- MacLeod, B.P.; Parlane, F.G.L.; Morrissey, T.D.; Häse, F.; Roch, L.M.; Dettelbach, K.E.; Moreira, R.; Yunker, L.P.E.; Rooney, M.B.; Deeth, J.R.; et al. Self-driving laboratory for accelerated discovery of thin-film materials. Sci. Adv. 2020, 6, eaaz8867. [Google Scholar] [CrossRef] [PubMed]
- Gromski, P.S.; Henson, A.B.; Granda, J.M.; Cronin, L. How to explore chemical space using algorithms and automation. Nat. Rev. Chem. 2019, 3, 119–128. [Google Scholar] [CrossRef]
- Häse, F.; Roch, L.M.; Aspuru-Guzik, A. Next-Generation Experimentation with Self-Driving Laboratories. Trends Chem. 2019, 1, 282–291. [Google Scholar] [CrossRef]
- Ludl, P.O.; Heese, R.; Höller, J.; Asprion, N.; Bortz, M. Using machine learning models to explore the solution space of large nonlinear systems underlying flowsheet simulations with constraints. Front. Chem. Sci. Eng. 2021, 16, 183–197. [Google Scholar] [CrossRef]
- Ma, Y.; Gao, Z.; Shi, P.; Chen, M.; Wu, S.; Yang, C.; Wang, J.; Cheng, J.; Gong, J. Machine learning-based solubility prediction and methodology evaluation of active pharmaceutical ingredients in industrial crystallization. Front. Chem. Sci. Eng. 2021, 16, 523–535. [Google Scholar] [CrossRef]
- Zhou, Y.; Li, G.; Dong, J.; Xing, X.-H.; Dai, J.; Zhang, C. MiYA, an efficient machine-learning workflow in conjunction with the YeastFab assembly strategy for combinatorial optimization of heterologous metabolic pathways in Saccharomyces cerevisiae. Metab. Eng. 2018, 47, 294–302. [Google Scholar] [CrossRef]
- Burre, J.; Kabatnik, C.; Al-Khatib, M.; Bongartz, D.; Jupke, A.; Mitsos, A. Global flowsheet optimization for reductive dimethoxymethane production using data-driven thermodynamic models. Comput. Chem. Eng. 2022, 162. [Google Scholar] [CrossRef]
- Khamparia, A.; Pandey, B.; Pandey, D.K.; Gupta, D.; Khanna, A.; de Albuquerque, V.H.C. Comparison of RSM, ANN and Fuzzy Logic for extraction of Oleonolic Acid from Ocimum sanctum. Comput. Ind. 2020, 117, 103200. [Google Scholar] [CrossRef]
- Aslan, V.; Eryilmaz, T. Polynomial regression method for optimization of biodiesel production from black mustard (Brassica nigra L.) seed oil using methanol, ethanol, NaOH, and KOH. Energy 2020, 209, 118386. [Google Scholar] [CrossRef]
- Stuke, A.; Todorović, M.; Rupp, M.; Kunkel, C.; Ghosh, K.; Himanen, L.; Rinke, P. Chemical diversity in molecular orbital energy predictions with kernel ridge regression. J. Chem. Phys. 2019, 150, 204121. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Antti, H.; Ebbels, T.M.; Keun, H.C.; Bollard, M.E.; Beckonert, O.; Lindon, J.C.; Nicholson, J.K.; Holmes, E. Statistical experimental design and partial least squares regression analysis of biofluid metabonomic NMR and clinical chemistry data for screening of adverse drug effects. Chemom. Intell. Lab. Syst. 2004, 73, 139–149. [Google Scholar] [CrossRef]
- Olson, M.; Wyner, A.J.; Berk, R. Modern neural networks generalize on small data sets. In Proceedings of the 32nd International Conference on Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 3 December 2018; pp. 3623–3632. [Google Scholar]
- Zhang, S.; Liu, H.-X.; Gao, D.-T.; Wang, W. Surveying the methods of improving ANN generalization capability. In Proceedings of the 2003 International Conference on Machine Learning and Cybernetics, Xi’an, China, 5 November 2003; pp. 1259–1263. [Google Scholar] [CrossRef]
- Shahriari, B.; Swersky, K.; Wang, Z.; Adams, R.P.; de Freitas, N. Taking the Human Out of the Loop: A Review of Bayesian Optimization. Proc. IEEE 2015, 104, 148–175. [Google Scholar] [CrossRef] [Green Version]
- Cao, L.; Russo, D.; Felton, K.; Salley, D.; Sharma, A.; Keenan, G.; Mauer, W.; Gao, H.; Cronin, L.; Lapkin, A.A. Optimization of Formulations Using Robotic Experiments Driven by Machine Learning DoE. Cell Rep. Phys. Sci. 2021, 2, 100295. [Google Scholar] [CrossRef]
- Fantke, P.; Cinquemani, C.; Yaseneva, P.; De Mello, J.; Schwabe, H.; Ebeling, B.; Lapkin, A.A. Transition to sustainable chemistry through digitalization. Chem 2021, 7, 2866–2882. [Google Scholar] [CrossRef]
- Felton, K.C.; Rittig, J.G.; Lapkin, A.A. Summit: Benchmarking Machine Learning Methods for Reaction Optimisation. Chem 2021, 1, 116–122. [Google Scholar] [CrossRef]
- Nguyen, V.; Rana, S.; Gupta, S.K.; Li, C.; Venkatesh, S. Budgeted Batch Bayesian Optimization. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016; pp. 1107–1112. [Google Scholar] [CrossRef]
- Sun, S.; Tiihonen, A.; Oviedo, F.; Liu, Z.; Thapa, J.; Zhao, Y.; Hartono, N.T.P.; Goyal, A.; Heumueller, T.; Batali, C.; et al. A data fusion approach to optimize compositional stability of halide perovskites. Matter 2021, 4, 1305–1322. [Google Scholar] [CrossRef]
- Xue, D.; Balachandran, P.V.; Yuan, R.; Hu, T.; Qian, X.; Dougherty, E.R.; Lookman, T. Accelerated search for BaTiO 3 -based piezoelectrics with vertical morphotropic phase boundary using Bayesian learning. Proc. Natl. Acad. Sci. USA 2016, 113, 13301–13306. [Google Scholar] [CrossRef] [Green Version]
- Jorayev, P.; Russo, D.; Tibbetts, J.D.; Schweidtmann, A.M.; Deutsch, P.; Bull, S.D.; Lapkin, A.A. Multi-objective Bayesian optimisation of a two-step synthesis of p-cymene from crude sulphate turpentine. Chem. Eng. Sci. 2021, 247, 116938. [Google Scholar] [CrossRef]
- Pukelsheim, F. Optimal Design of Experiments, Classics in Applied Mathematics; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2006. [Google Scholar] [CrossRef] [Green Version]
- Močkus, J. On bayesian methods for seeking the extremum. In Optimization Techniques IFIP Technical Conference; Marchuk, G.I., Ed.; Springer: Berlin/Heidelberg, Germany, 1975; pp. 400–404. [Google Scholar] [CrossRef] [Green Version]
- Fisher, R.A. Design of Experiments. Br. Med. J. 1936, 1, 554. [Google Scholar] [CrossRef]
- Baumgartner, L.M.; Coley, C.W.; Reizman, B.J.; Gao, K.W.; Jensen, K.F. Optimum catalyst selection over continuous and discrete process variables with a single droplet microfluidic reaction platform. React. Chem. Eng. 2018, 3, 301–311. [Google Scholar] [CrossRef] [Green Version]
- Cox, D.; Reid, N. The Theory of the Design of Experiments; Chapman and Hall/CRC: Boca Raton, FL, USA, 2000. [Google Scholar] [CrossRef]
- de Aguiar, P.; Bourguignon, B.; Khots, M.; Massart, D.; Phan-Than-Luu, R. D-optimal designs. Chemom. Intell. Lab. Syst. 1995, 30, 199–210. [Google Scholar] [CrossRef]
- Kuram, E.; Ozcelik, B.; Bayramoglu, M.; Demirbas, E.; Simsek, B.T. Optimization of cutting fluids and cutting parameters during end milling by using D-optimal design of experiments. J. Clean. Prod. 2013, 42, 159–166. [Google Scholar] [CrossRef]
- Gonzalez, J.; Dai, Z.; Hennig, P.; Lawrence, N. Batch Bayesian Optimization via Local Penalization. In Proceedings of the 19th International Conference on Artificial Intelligence and Statistics, Cadiz, Spain, 9–11 May 2016; pp. 648–657. [Google Scholar]
- Frazier, P.I. Bayesian optimization, in: Recent Advances in Optimization and Modeling of Contemporary Problems. Informs 2018, 11, 255–278. [Google Scholar]
- Schulz, E.; Speekenbrink, M.; Krause, A. A tutorial on Gaussian process regression: Modelling, exploring, and exploiting functions. J. Math. Psychol. 2018, 85, 1–16. [Google Scholar] [CrossRef]
- Bradford, E.; Schweidtmann, A.M.; Lapkin, A. Efficient multiobjective optimization employing Gaussian processes, spectral sampling and a genetic algorithm. J. Glob. Optim. 2018, 71, 407–438. [Google Scholar] [CrossRef] [Green Version]
- Cortés-Borda, D.; Kutonova, K.V.; Jamet, C.; Trusova, M.E.; Zammattio, F.; Truchet, C.; Rodriguez-Zubiri, M.; Felpin, F.-X. Optimizing the Heck–Matsuda Reaction in Flow with a Constraint-Adapted Direct Search Algorithm. Org. Process. Res. Dev. 2016, 20, 1979–1987. [Google Scholar] [CrossRef] [Green Version]
- Huyer, W.; Neumaier, A. SNOBFIT—Stable Noisy Optimization by Branch and Fit. ACM Trans. Math. Softw. 2008, 35, 1–25. [Google Scholar] [CrossRef]
- Hone, C.A.; Holmes, N.; Akien, G.R.; Bourne, R.A.; Muller, F.L. Rapid multistep kinetic model generation from transient flow data. React. Chem. Eng. 2016, 2, 103–108. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Step | k (10−2·mol−1·s−1) | Ea (kJ·mol−1) |
|---|---|---|
| 1 | 57.9 ± 0.7 | 33.3 ± 0.3 |
| 2 | 2.70 ± 0.06 | 35.3 ± 0.5 |
| 3 | 0.865 ± 0.004 | 38.9 ± 1.5 |
| 4 | 1.63 ± 0.11 | 44.8 ± 1.8 |
| Name | Type | Description | Domain Range |
|---|---|---|---|
| input | residence time | [0.5, 2] | |
| input | equivalents of pyrrolidine | [1, 5] | |
| input | concentration of 2,4-dinitrofluorobenenze | [0.1, 0.5] | |
| input | reactor temperature | [30, 120] | |
| objective | space time yield (kg/m3/h) | ||
| objective | weight ratio of product 4 and 5 over 3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, X.; Zhang, S.; Li, H.; Qiu, T. An Integrated Method of Bayesian Optimization and D-Optimal Design for Chemical Experiment Optimization. Processes 2023, 11, 87. https://doi.org/10.3390/pr11010087
Huang X, Zhang S, Li H, Qiu T. An Integrated Method of Bayesian Optimization and D-Optimal Design for Chemical Experiment Optimization. Processes. 2023; 11(1):87. https://doi.org/10.3390/pr11010087
Chicago/Turabian StyleHuang, Xinye, Shuyuan Zhang, Haoran Li, and Tong Qiu. 2023. "An Integrated Method of Bayesian Optimization and D-Optimal Design for Chemical Experiment Optimization" Processes 11, no. 1: 87. https://doi.org/10.3390/pr11010087