1. Introduction
Industry 4.0, also called the “smart factory” [
1], focuses on the integration of advanced technologies such as the Internet of Things, big data and artificial intelligence with enterprise resource planning, manufacturing execution management and process control management. Thus, a smart factory has the capabilities of autonomous perception, analysis, reasoning, decision-making and control. The flexible job shop scheduling problem (FJSP) is an extension of the traditional job shop scheduling problem (JSP). The FJSP provides possibilities and guarantees low variation in diversified and differentiated manufacturing, which is widely used in the semiconductor manufacturing process, the automobile assembly process, mechanical manufacturing systems, etc. [
2]. As the core of manufacturing execution management and process control management, the real-time optimization and control of FJSP provides increased flexibility in the management of a smart factory, aiming to improve factory productivity and the efficient utilization of resources in real time [
3].
The FJSP breaks through the uniqueness restriction of production resources. Each operation can be assigned on one or more available machines and the processing time is different for different machines [
4]. The FJSP reduces the machine constraints and expands the size of the feasible solution search space, so it is a strong NP-hard problem that is more complex than the JSP [
5,
6]. So far, a large number of studies on the FJSP have assumed that the scheduling takes place in a static production environment, where the shop floor information is known in advance, and the deterministic scheduling scheme cannot be changed during the entire working process. However, an actual manufacturing shop has dynamic and uncertain characteristics, such as random job arrival, machine breakdowns, order cancellations, urgent order insertions, variations in delivery dates or processing times, etc. The scheduling scheme should be adjusted continuously according to the changes in the production environment [
7,
8], and the dynamic FJSP (DFJSP) can respond to the unexpected events of the flexible job shop in real time. Therefore, the research into the FJSP cannot meet the actual production demand and more and more scholars are now paying attention to the DFJSP.
At present, the methods of solving the DFJSP are mainly heuristic [
9] and metaheuristic algorithms. Tao et al. [
10] proposed an improved dual-chain quantum genetic algorithm, based on the non-dominated ranking method, to solve the multi-objective DFJSP. Nouiri et al. [
11] used particle swarm optimization to solve the dynamic flexible job shop scheduling problem under machine breakdowns, to reduce energy consumption. Wu et al. [
12] solved the DFJSP with multiple perturbations by the non-dominated sorting genetic algorithm (NSGA) III to minimize the maximum completion time and energy consumption. The heuristic algorithm is simple and efficient, but it often falls into the local optimum and the solution quality is poor due to greed and short-sightedness. The metaheuristic algorithm improves the solution quality through parallel searching and iterative searching, but it is time-consuming. Moreover, there is a strong correlation between algorithm structures and scheduling problems, which leads to the redesign of the algorithm once the production resources, constraints or production objectives change. Therefore, a method of solving the DFJSP urgently needs to be studied on the basis of new methods and new theories that integrate the advantages of the heuristic algorithm’s solution time and the metaheuristic algorithm’s solution quality.
With the advance of artificial intelligence, reinforcement learning (RL) to solve the production scheduling problem originated in 1995 [
13]. In 2018, some scholars applied deep reinforcement learning (DRL) to the scheduling field and then it was widely used, which attracted the attention and competitive research of scholars in China and abroad. The basic components of reinforcement learning are the environment, agents, the behavior policy, the reward and the value function, where the learning process is usually described by a Markov decision process (MDP) [
14]. For large-scale problems, it is necessary to parameterize it through a policy network and to balance exploration and exploitation, which ensures that the scheduling agent converges to the optimal or near-optimal solution in a reasonable time, thus improving the adaptability and self-learning of production scheduling in intelligent manufacturing.
Wang et al. [
15] applied Q-learning to study a dynamic single-machine scheduling problem (SMSP) with random arrival time and processing time. Fonseca et al. [
16] solved the flow job shop scheduling problem (FSP) to minimize the completion time of all jobs via the RL approach. Shahrabi et al. [
17] solved the dynamic job shop scheduling problem with random job arrival and machine breakdowns by a variable neighborhood search that dynamically adjusted the parameters by RL to minimize the average flow time. Wang et al. [
18] solved the job shop scheduling problem by a weighted Q-learning algorithm based on clustering and dynamic searching to minimize penalties for earliness and tardiness. Wang et al. [
7] applied a dual Q-learning to solve an assembly job shop scheduling problem with uncertain assembly times to minimize the total weighted earliness penalty and completion time cost. The top level Q-learning is focused on the dispatching policy and the bottom level Q-learning focuses on global targets. Bouazza et al. [
1] utilized the Q-learning algorithm to solve a partially flexible job shop scheduling problem with new job insertions. One Q matrix was used to choose a machine selection rule and the other was focused on a particular dispatching rule. Luo et al. [
19] established double deep Q-networks (DDQN) with seven state features and six composite dispatching rules to solve the DFJSP, with the objective of minimizing total tardiness. Luo et al. [
20] proposed a two-hierarchy deep reinforcement learning model for solving the FJSP to minimize the total tardiness and average machine utilization rate. The higher-level DDQN determines the optimization goal and the lower-level chooses a proper dispatching rule.
Table 1 summarizes the differences between the aforementioned work and our work.
From the above literature review, the research has mainly focused on single machine scheduling, flow job shop scheduling and job shop scheduling. Research on DRL for solving the DFJSP has not been explored deeply. Moreover, the DFJSP, with random job arrival and penalties for earliness and tardiness criteria, has not been solved by DRL. In addition, the DRL methods are not compared with traditional metaheuristics in most of the literature. It is unclear whether DRL approaches outperform traditional metaheuristics in terms of solution quality and generalization. For instance, in the work of Luo et al. [
19], the proposed DRL demonstrated superiority only when compared with heuristic rules as well as the Q-learning agent.
In most of the RL-based methods mentioned above, Q-learning is mostly used, which requires the problem to have discrete and finite state space. To maintain a lookup Q table and reduce computational complexity, model accuracy is often sacrificed when dealing with continuous-state problems. For instance, in the work of Shahrabi et al. [
17], the number of machines/jobs/operations chosen as state features is unlimited and extremely large. There is no efficient theoretical guidance on how to determine the proper number of states, so the drawback of compulsive state discretization is obvious. In the work of Luo et al. [
19,
20], the DDQN-based scheduling agent is designed, whereas there are strong correlations between hand-crafted features, which may mislead the neural networks and increases many invalid computations. Without loss of generality, ε-greedy or annealed linearly ε-greedy are used for most of the literature above. With the rapid growth of the scheduling solution space, the fixed ε and fixed linear annealing rates are not conducive to searching for the optimal or near-optimal solution.
For the reasons mentioned above, a DRL method is proposed to solve the DFJSP with random job arrival, to minimize penalties for earliness and tardiness in this study, so as to realize the real-time optimization and decision-making of the DFJSP. The experimental results indicate that the proposed DRL outperforms other reinforcement learning algorithms, heuristics and metaheuristics in terms of solution quality and generalization. The three contributions of this research are as follows.
- (1)
To the best of our knowledge, this is the first attempt to solve the DFJSP with random job arrival, to minimize the total penalties for earliness and tardiness using DRL. The work can thus fill a research gap regarding solving the DFJSP by DRL.
- (2)
A DDQN algorithm model of flexible dynamic scheduling is proposed and state features, actions and rewards for the scheduling agent have been designed.
- (3)
A soft ε-greedy behavior policy is proposed, which reasonably balances exploration and exploitation according to the solution space of strong NP-hard problems, thus improving the learning speed of the scheduling agent.
The remainder of this study is organized as follows: The mathematical model of DFJSP with random job arrival is established in
Section 2.
Section 3 presents the background of DDQN and gives the implementation details.
Section 4 provides the results of numerical experiments.
Section 5 discusses the findings and the implications and gives future research directions. Finally, conclusions are drawn in
Section 6.
2. Problem Formulation
2.1. Problem Description
We describe the dynamic flexible job shop scheduling problem with random job arrival using symbols defined as follows: There are n successively arriving jobs J = {}, which should be processed on m machines M = {}. Each job Ji consists of a predetermined sequence of operations. Oij is the jth operation of job Ji, which can be processed on a compatible machine set. The processing time of Oij on machine Mk is denoted tijk. The arrival time of job Ji is Ai and the due date is . In this study, the assumptions and constraints were as follows:
- (1)
Each machine can process only one operation at a time.
- (2)
The order of precedence of operations belonging to the same job must be followed and there are no precedence constraints among the operations of different jobs.
- (3)
The operation must be processed without interruption.
- (4)
Jobs are independent and no priorities are assigned to any job.
- (5)
The setup time of the equipment, the transportation time between operations and the breakdown time of the machine are negligible.
- (6)
An unlimited buffer between machines is assumed.
2.2. Mathematical Model
In order to meet the needs of the just-in-time production mode, the basic requirement of the scheduling problem to minimize penalties for earliness and tardiness [
21] is as follows: From the perspective of the economic benefit of an enterprise, the processing of products should meet the requirements of delivery time, with neither delays nor a principle of “the sooner the better”. A mathematical model of the DFJSP was established to minimize penalties for earliness and tardiness with random job arrival. The notation used in this model is as follows:
i,r: Index of jobs, ;
j,t: Index of operations belonging to job Ji and Jt;
k: Index of machines, ;
hi: The number of operations of Ji;
tijk: The processing time of operation Oij on machine Mk;
sij: The starting time of Oij;
mij: The available machine set for operation Oij;
fi: The delivery relaxation factor of Ji;
: Unit (per day) earliness cost of Ji;
: Unit (per day) tardiness cost of Ji;
Ai: The arrival time of Ji;
Di: The due date of Ji;
: The completion time of Ji;
Z: A large enough positive number.
In an actual production environment, the swift completion of products results in more inventory pressure and financial costs, whereas delays in completing the job result in financial damage [
22]. Therefore, here, the objective was to obtain a schedule that has the least penalties for earliness and tardiness (PET) in the DFJSP with new job insertions. The objective function is given by Equation (1) and some constraints are given in Equations (2)–(8).
Equation (2) makes sure that a job can only be processed after its arrival time. Equation (3) indicates that the order of precedence between the operations of each job must be followed. Equation (4) ensures that a machine can only process one job at a time. Equation (5) ensures that a job can only be processed by one machine at the same time.
3. Proposed DRL
3.1. DQN and DDQN
Deep Q-networks (DQN) combine reinforcement learning with non-linear value functions for the first time, in which the neural network is trained through reinforcement learning to have the ability to master difficult control and decision-making policies [
23]. However, there is an incompatible gap between reinforcement learning and deep learning. For example, most deep learning methods assume that the data samples are independent of each other, with no sequence correlation and a fixed underlying distribution, while in reinforcement learning, sequences of highly correlated states are typically encountered and the data distribution is unstable under the influence of selective actions. Inspired by the experience replay of the hippocampus [
24] in a biological neural network, the state transition tuple
generated at each time-step in reinforcement learning is stored in a replay memory and the tuple data are randomly sampled to adjust the parameter
of the neural network (the iterative updating formula is shown in Equation (9)) by minibatch updates. Therefore, the goal of maximizing the Q-value function of RL is realized and the loss function of deep learning is minimized at the same time. The DQN is a milestone in creating a general artificial intelligence to complete a varied range of challenging tasks with a single algorithm.
where
is the learning rate used by the stochastic gradient descent algorithm. The target
must be designed in unsupervised learning, for which the iterative formula of each time-step is shown in Equation (10), while the sample target
is known in supervised learning;
is the discount factor in the Q-learning algorithm.
It can be seen from Equation (10) that selecting an action and evaluating an action use the same values in the DQN. There is a neural network where the current parameter is , the state is the input and the number of values at the output layer is , so the set expression is {, where is the number of actions}. If the value of is the largest, then action is chosen via an behavior policy, while the evaluation uses the value . This results in a large number of overoptimistic value estimates.
The overoptimistic value estimates themselves are not necessarily a problem, but they have a negative impact on the quality of the learned policy in some cases. If the value of each action is overestimated evenly, the action selection will not be affected and the agent learning will not be affected. On the contrary, if the overestimation of is uneven, the action with the overestimated value will be preferred during action selection. The action affects the environmental state distribution in RL, so the overestimation of affects the state data’s distribution. If the agent learns less from those states, the learning quality of the agent will be greatly reduced and overoptimism is not conducive to the stability of learning.
In order to reduce overestimations, Hasselt et al. designed the DDQN [
25] from the idea of double Q-learning [
26,
27]. The online network and the target network are designed to decouple the selection from the evaluation. The
value from the online network provides the basis on which the behavior policy can select an action and the target network
value is used for evaluating the action. The iterative formula of
is shown in Equation (11). The update of the target network
remains a periodic copy of the online network
.
3.2. Model Architecture
The general process of reinforcement learning to solve the production scheduling problem is as follows: Firstly, the scheduling problem type, constraint conditions and dynamic attributes are defined according to the manufacturing environment, which generates the production scheduling instance. Secondly, the instance is expressed as a MDP according to the production state, scheduling action and reward. Lastly, the agent then continuously interacts with the MDP to obtain production data samples and the reinforcement learning algorithm is trained to learn the strategy.
The model of the proposed DRL is shown in
Figure 1, including the flexible job shop production environment, the agent and the reinforcement learning process. The architecture of the online network and the target network in the agent is the same. Deep neural networks are trained in the DDQN, which consists of five fully connected layers with one input layer, one output layer and three hidden layers. The number of nodes in the input and output layers is equal to the number of state features (four) and the number of actions is also four. Each hidden layer consists of 30 nodes. The activation function is Relu. The learning process is as follows.
- (1)
The agent obtains the current state of the flexible job shop environment st;
- (2)
The agent determines the scheduling rule at according to the value of the online network and the behavior policy to select an operation Oij and select a feasible machine Mk;
- (3)
The flexible production shop performs at: Oij is processed on Mk and the production environment state is transferred to st+1;
- (4)
The agent obtains the instant reward rt from the production environment and the experience tuple (st, at, rt, st+1) is stored in the experience replay D;
- (5)
Randomization of the samples is performed in D and the target and the loss function are calculated according to the target network and the online network to update the parameters of the online network.
3.3. State Features
In the field of reinforcement learning applications, the design quality of the environmental state features plays a key role and influences the performance of an RL algorithm. In a production scheduling method based on RL, the characteristics of the scheduling attributes are defined as the production state characteristics, such as the number of jobs, the number of operations, the number of machines, the remaining working hours, the number of remaining operations, the load of machine tools, the total processing time and other factors [
1,
17]. These characteristic attributes have an infinite range of values and the decomposition and partition of the state space can easily be subjective and lack the guidance of objective data [
28]. In a flexible manufacturing environment, production information is complex and constantly changing and excessive quantitative eigenvalues are prone to overfitting [
29]. In order to ensure that different actions are selected adaptively according to the state of the production environment, most reinforcement learning algorithms solve the production scheduling problem by establishing the relationship between the production features’ attributes and the production objectives. For these reasons, this study designed four production state features with values of [0, 1], which are defined below:
- (1)
Average utilization rate
The average utilization rate of the machines
is calculated by Equation (12).
is the completion time of the last operation on machine
Mk at rescheduling point
t and
is the current number of completed operations of job
Ji at the current time
t.
- (2)
Estimated earliness and tardiness rate
is the average completion time of the last operations on all machines at rescheduling point t and is the estimated remaining processing time of Ji. If + > Di, Ji is estimated to be delayed. If + < Di, Ji is estimated to be completed in advance. The number of estimated early and tardy jobs is equal to the number of estimated early jobs NJearly plus the number of estimated tardy jobs NJtard. The estimated earliness and tardiness rate is equal to the number of estimated early and tardy jobs divided by the number of all jobs. The method of calculating this is given in Algorithm 1.
| Algorithm 1 Procedure of calculating the estimated earliness and tardiness rate |
| Input: CTk(t), OPi(t), Di |
| Output: |
| 1: ← |
| 2: NJtard ← 0 |
| 3: NJearly ← 0 |
| 4: for i = 1: n do |
| 5: if OPi(t) < hi then |
| 6: ← 0 |
| 7: for j = OPi(t) + 1: hi do |
| 8: |
| 9: ← + ti,j |
| 10: if + > Di then |
| 11: NJtard ← NJtard + 1 |
| 12: break |
| 13: end if |
| 14: end for |
| 15: if + < Di then |
| 16: NJearly ← NJearly + 1 |
| 17: end if |
| 18: end if |
| 19: end for |
| 18: ← (NJtard + NJearly)/n |
| 19: Return |
- (3)
Actual earliness and tardiness rate ETa(t)
ETi(t) is the completion time of the completed operations of Ji at rescheduling point t and thus ETi(t)[OPi(t)] represents the completion time of the last completed operation of Ji. If ETi(t)[OPi(t)] > Di, Ji is delayed; if ETi(t)[OPi(t)] + < Di, Ji is completed in advance. The actual number of early and tardy jobs is equal to the actual number of early jobs NJa_early plus the actual number of tardy jobs NJa_tard. The actual earliness and tardiness rate is equal to the number of actual early and tardy jobs divided by the number of all jobs. The method of calculating this is given in Algorithm 2.
| Algorithm 2 Procedure of calculating the actual earliness and tardiness rate ETa(t) |
| Input: OPi(t), Di, ETi(t) |
| Output: ETa(t) |
| 1: NJa_tard ← 0 |
| 2: NJa_early ← 0 |
| 3: for i = 1: n do |
| 4: if OPi(t) < hi then |
| 5: ← 0 |
| 6: if ETi(t)[OPi(t)]> Di then |
| 7: NJa_tard ← NJa_tard + 1 |
| 8: continue |
| 9: else |
| 10: for j = OPi(t) + 1: hi do |
| 11: |
| 12: ← + ti,j |
| 13: if ETi(t)[OPi(t)] + > Di then |
| 14: NJa_tard ← NJa_tard + 1 |
| 15: break |
| 16: end if |
| 17: end for |
| 18: if ETi(t)[OPi(t)] + < Di then |
| 19: NJa_early ← NJa_early+ 1 |
| 20: end if |
| 21: end if |
| 22: end if |
| 23: end for |
| 24: ETa(t) ← (NJa_tard+ NJa_early)/n |
| 25: Return ETa(t) |
- (4)
Actual earliness and tardiness penalty
P [i] is the actual earliness and tardiness penalty of Ji, and its value is equal to the unit time penalty coefficient of Ji multiplied by the actual earliness/tardiness of Ji. The actual earliness and tardiness penalty Pa(t) is normalized by [0,1). Its normalization equation is , where and is a constant related to n, Z[n,n*10]. If there are no early and tardy jobs at the rescheduling point t, is equal to 0 and the value of is also 0; otherwise, a large number of jobs are early or tardy, for which the is greater and is closer to 1. The specific calculation method is shown in Algorithm 3.
| Algorithm 3 Procedure of calculating the actual earliness and tardiness penalty cost Pa(t) |
| Input: OPi(t), Di, ETi(t) |
| Output: Pa(t) |
| 1: P’ ← 1 |
| 2: P ← 0 |
| 3: for i = 1: n do |
| 4: if OPi(t) < hi then |
| 5: ← 0 |
| 6: for j = OPi(t) + 1: hi do |
| 7: |
| 8: ← + ti,j |
| 9: end for |
| 10: if ETi(t)[OPi(t)] > Di then |
| 11: |
| 12: |
| 13: end if |
| 14: if ETi(t)[OPi(t)] + < Di then |
| 15: |
| 16: |
| 17: end if |
| 18: end if |
| 18: end for |
| 19: |
| 20: Return Pa(t) |
3.4. Action Set
The FJSP problem includes two subproblems: operation sequencing and machine selection. Therefore, the four scheduling rules were designed to complete two tasks: first selecting an operation and then selecting a machine from the set of feasible machines. UCjob(t) is the set of unfinished jobs at rescheduling point t and Mij represents the set of suitable machines for Oij. The four comprehensive dispatching rules are as follows.
- (1)
Dispatching Rule 1: Firstly, according to Equation (13), the job
Ji with the minimum redundancy time is selected from the uncompleted job set
UCjob(t) and the operation
Oi(OPi(t)+1) is selected. The machine is then allocated for
Oi(OPi(t)+1) and the minimum completion time is the allocation principle. Selection of the machine considers not only the available time of the machine but also the completion time of the prior
Oi OPi(t) and the processing time of
Oi(OPi(t)+1). When
Ji arrives dynamically at rescheduling time
t, if a feasible machine is idle, its available time is the rescheduling time
t; otherwise, its available time is the time when it completes the processing operation. Therefore, the machine is selected according to Equation (14).
- (2)
Dispatching Rule 2: Firstly, 2according to Equation (15), the job
Ji with the largest estimated remaining processing time is selected from the uncompleted jobs and its operation
Oi(OPi(t)+1) is selected. A suitable machine for
Oi(OPi(t)+1) then is selected according to Equation (14).
- (3)
Dispatching Rule 3: Firstly, according to Equation (16), the job
Ji with the largest penalty coefficient is selected from the uncompleted jobs and its operation
Oi(OPi(t)+1) is selected. The suitable machine with the smallest load for
Oi(OPi(t)+1) is selected according to Equation (17).
- (4)
Dispatching Rule 4: Firstly, according to Equation (18), the job
Ji with the smallest estimated remaining processing time is selected from the uncompleted jobs and its process
Oi(OPi(t)+1) is selected. A suitable machine for
Oi(OPi(t)+1) is then selected according to Equation (14).
3.5. Rewards
In this study, the goal of production scheduling was to minimize penalties for earliness and tardiness, while the goal of the DDQN algorithm was to maximize the cumulative reward. Therefore, the reward function keeps the increasing direction of the cumulative reward consistent with the decreasing direction of the optimization goal. In order to improve the learning efficiency of agents, this study designed a heuristic immediate reward function, which is calculated by Equation (19).
If < , this indicates that the scheduling optimization objective is decreasing, and if the immediate reward is according to Equation (19), this indicates that the cumulative reward is increasing. Moreover, the more the optimization objective is reduced, the greater the immediate reward in the iteration. If = , the scheduling optimization objective changes to 0 and the immediate reward is also 0. If > , the optimization goal is increasing and if the immediate reward is , the cumulative reward is decreasing. There is a negative correlation between the optimization goal and the cumulative reward. Therefore, through the definition of the immediate reward function, not only is the minimization objective of the scheduling problem transformed into the maximization objective of the cumulative reward, but also the selected action of each decision point t is accurately evaluated, which improves the learning ability of the agent regarding a complex control strategy.
3.6. Action Selection Strategy
In deep reinforcement learning, exploration means that every action has the same probability of being randomly selected and exploitation involves selecting the action with the largest value. Due to the limited learning time, exploration and exploitation are contradictory. In order to maximize the cumulative reward, a compromise must be made between exploration and exploitation.
The ε-greedy policy, with
being annealed linearly, is one of the most commonly used behavior policies. For example,
with an initial value of 1, anneals linearly by 0.001 at each step and is fixed at 0.1. Thereafter, the probability of exploration is 0.1 and that of exploitation is 0.9 at each step. However, a fixed linear annealing rate is not reasonable for all flexible scheduling problems. In order to improve the learning speed of the agent, there is less exploration for scheduling problems with a small solution space, while exploration should be strengthened for scheduling problems with a large solution space. Therefore, in this study a soft ε-greedy behavior policy, which is calculated by Equation (20), was designed to adapt to flexible scheduling problems with different scales, and the linear annealing rate is
. The larger the total operation number
and the larger the solution space of the scheduling problem, the smaller the value of
, which means that the linear decline of the exploration rate
is slower, thus enhancing exploration and weakening exploitation.
3.7. Procedure of DDQN
By defining three key elements (state, action and reward), the DFJSP problem is transformed into an RL problem. According to the algorithm model architecture described in
Section 3.2, the four production environment state characteristics in
Section 3.3, the four action scheduling rules in
Section 3.4, the immediate reward in
Section 3.5 and the behavior policy in
Section 3.6, the scheduling agent is trained to realize adaptive scheduling. Algorithm 4 is the training method of the scheduling agent, where
L is the training time,
t is the rescheduling time when an operation is completed or a new job arrives and
T is the sum of all the current operations.
| Algorithm 4 The DDQN-based training method |
| 1: Initialize replay memory to capacity |
| 2: Initialize online network action-value with random weights |
| 3: Initialize target network action-value with weights |
| 4: for episode = 1: do |
| 5: Initialize production state |
| 6: for t = 1: do |
| 7: With probability , select a random action |
| 8: Otherwise, select action = |
| 9: Execute action , calculate the immediate reward by Equation (19) and observe the next state |
| 10: Set production state |
| 11: Store transition in |
| 12: Sample a random minibatch of transitions from D |
| 13: Set target |
| 14: Calculate the loss function and perform a stochastic gradient descent step with respect to the parameters of online network Q |
| 15: Every steps, reset |
| 16: end for |
| 17: end for |
4. Numerical Experiments
In this section, a correlation analysis between the state features and the process of training the scheduling agent are provided, followed by a sensitivity study on the control parameter µ of the soft ε-greedy action selection policy. To confirm reasonable exploration of the soft ε-greedy strategy, the learning rate between the flexible ε-greedy strategy and the fixed linearly decreasing ε-greedy strategy was compared. To show the superiority and generality of the DDQN, we compared it with DQN; SARSA; a well-known heuristic algorithm, first in first out (FIFO); a traditional metaheuristic algorithm, genetic algorithm (GA); and a random action strategy (RA) with different production configurations. The training and test results, and the video of solving the DFJSP using the trained DDQN are uploaded as
Supplementary Materials.
The problem instances were generated by simulating a dynamic production environment of a flexible job shop. A new job arrival or an operation completion is defined as the system event that triggers rescheduling. It is assumed that several jobs exist on the flexible shop floor at the very beginning. The arrival of subsequent new jobs follows a Poisson distribution, whereas the arrival interval obeys a negative exponential distribution with an average rate
. For
Ji, the delivery relaxation factor
fi, the operation number
hi, the process time
tij of the jth operation
Oij, and
wie and
wit are satisfied with a uniform distribution [
29]. The parameter settings are shown in
Table 2.
The algorithm proposed in this study and the flexible workshop production environments were coded with Python 3.8.3. The training and test experiments were performed on a PC with an Intel(R) Core(TM) i7-6700 CPU and a 3.40 GHz CPU and 16 GB RAM.
4.1. Training Details
The values of all the hyperparameters were selected by performing an informal search on the instances that were generated for the DFJSP, with random job arrival using different parameter settings of
,
nadd and
m. In line with the literature [
24], a systematic grid search was not performed owing to the high computational cost, although it is conceivable that even better results could be obtained by systematically tuning the hyperparameter values. The list of hyperparameters and their values are shown in
Table 3.
4.1.1. Correlations between States
In order to collect a set of states completely and fully, multiple problem instances were generated according to different production configurations. In order to avoid sequences of highly correlated states, a set of states was collected from different instances by running a random policy before the training started [
23], so as to objectively evaluate the correlation between the state features. The correlation coefficient
between the state features is calculated according to the following equation:
(
). The experimental results are shown in
Table 4 below.
ETe is moderately correlated with
ETa,
is less correlated with
ETe and
is less correlated with
ETa as well, while the other state characteristics have extremely low correlations.
4.1.2. Training and Stability
The DDQN was trained for a simulated flexible job shop with 10 machines and 20 dynamic new job arrivals, and the average value of exponential distribution between two successive job arrivals (
Eave) was 30. The earliness and tardiness penalties of the first 4000 epochs calculated by the proposed DDQN algorithm are shown in
Figure 2. It can be seen from the curve that the target value drops smoothly and that the volatility decreases gradually with an increase in the training steps. The learning curve remains relatively stable after the 2500th epoch. This shows that the scheduling agent learns the appropriate dispatching rules according to the changes in the production states and this self-learning ability improves the adaptability for solving the DFJSP.
4.2. Comparison between the Soft ε-greedy and ε-greedy Behavior Policies
4.2.1. Sensitivity of the Control Parameter µ
The control parameter µ in Equation (20) affects the performance of the algorithm proposed in this article. The larger the
, the slower the linear decline in
, which enhances exploration. On the contrary, the smaller the
, the faster the linear decline in
, which weakens exploration. To determine the appropriate value of µ, it was increased from 0.4 to 2.4 in steps of 0.2. At each parameter level, the trained deep reinforcement learning model was independently tested 30 times on an instance with 10 machines, 20 new job arrivals and E
ave set to 30.
Figure 3 shows the box plots of the earliness and tardiness penalties for 30 trials with different values of µ, with the mean values marked by green triangles. It can be observed in the figure that µ = 1.8 achieved the lowest degree in terms of both the distribution range and the mean value of earliness and tardiness penalties. Therefore, the recommended value for µ is 1.8.
4.2.2. Comparison of Learning Rates
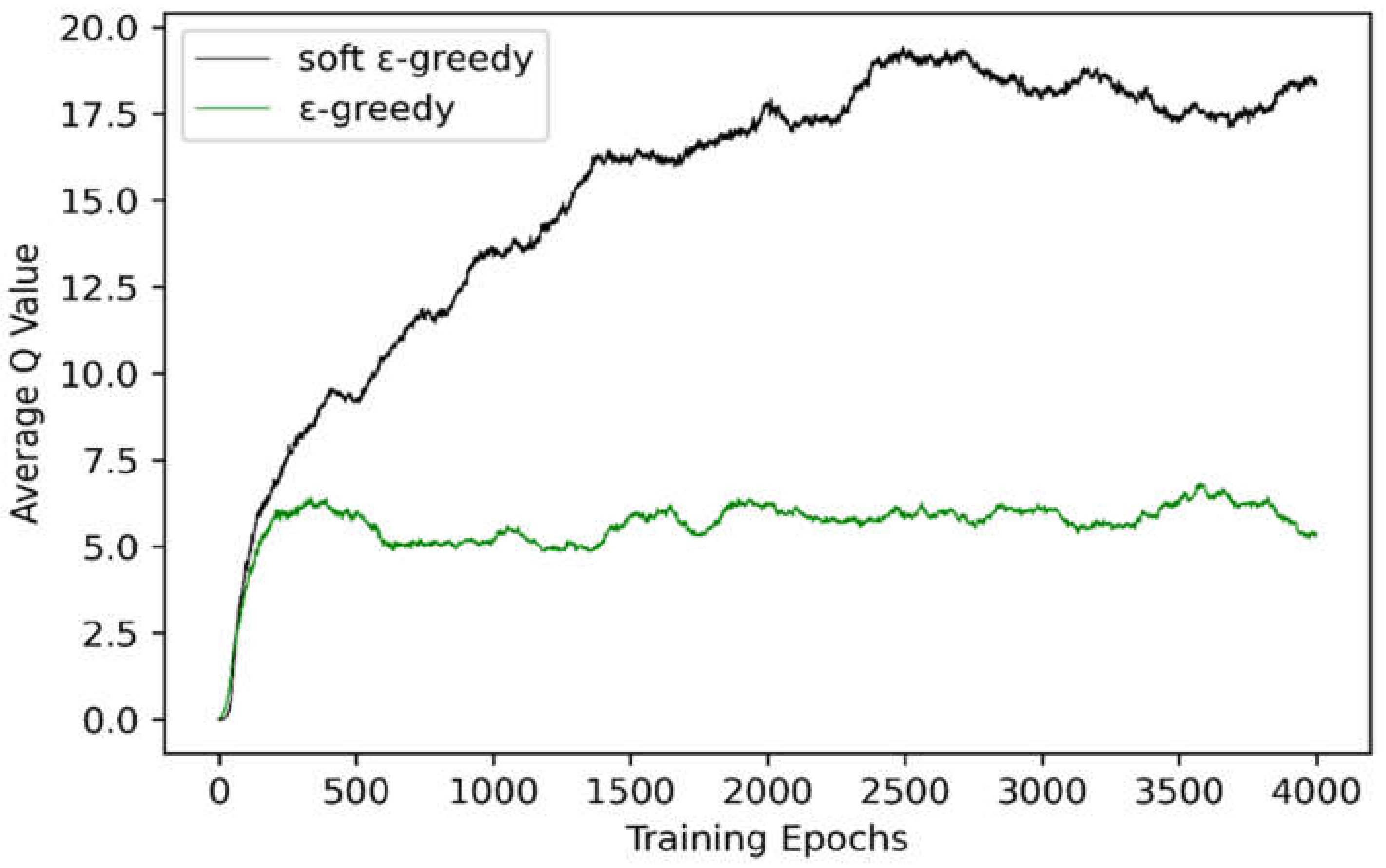
To demonstrate that the soft
-greedy behavior policy can reasonably balance exploration and exploitation depending on the problem size, the DDQN was trained for an instance with 10 machines, 50 new job arrivals and
Eave set to 50. For the soft
-greedy and
-greedy behavior policy,
anneals linearly from 1 to 0.1. The linear annealing rate of
is
for the soft
-greedy policy, whereas the value is 0.001 for the
-greedy policy. During training, the parameter µ was set to 1.8; the values of the other hyperparameters are listed in
Table 3. Through a method from the DQN literature [
23], a fixed set of states was collected by running a random policy before the training started and the average of the maximum predicted
for these states was tracked. In
Figure 4, the average predicted
of the soft
-greedy behavior policy is significantly higher than that of the
-greedy policy, indicating that the linearly decreasing rate of
was adjusted according to the problem size, thus achieving a better compromise between exploration and exploitation and maximizing the cumulative reward.
4.3. Comparison of DDQN with Other Methods
To verify the effectiveness and generalization of the proposed DDQN, the DFJSP was classified according to different parameter settings for
Eave,
m and
nadd. To simulate a real production environment, the number of operations, delivery factors and penalty coefficients were distributed randomly for each job, so 30 independent instances were generated for each type of DFJSP. The DDQN was compared with two other RL algorithms, DQN and SARSA; one of the most commonly used heuristics algorithms, FIFO; and a famous metaheuristic algorithm, GA. Moreover, the random action selection policy RA was designed to prove the learning ability of the agent. In each instance, the DDQN and the other algorithms were repeated independently 20 times. The mean values of the total earliness and tardiness penalty obtained by each method are shown in
Table 5 and the best results are highlighted in bold font.
In this study, the only difference between the DQN and the DDQN was the target yi. Moreover, during training, decreased linearly from 1 to 0.1 in the DQN, while decreased from 1 to 0.01 in the DDQN. During testing, was fixed at 0.001.
In SARSA, in order to discretize the production state space reasonably, the neural network with a self-organizing mapping layer (SOM) from [
19] was used to divide the state features into nine discrete states. The SARSA agent had the same action set of dispatching rules used in this study at each discrete state. A
table was maintained that contained 9 × 6
-values for the state–action pairs and the SARSA agent was trained to learn the policies linearly.
In GA [
30], the chromosomes of the FJSP were encoded in the form of operation sequence (OS) and machine assignment (MS). In order to improve the response speed of production events, every individual of the initial population was randomly generated. The selection operation adopted a combination of the roulette wheel and the elite retention strategy. In the crossover operation, a uniform crossover was applied for MS and a precedence preserving order-based crossover (POX) was used for OS. The MS of the mutation operator adopted a multi-round single point exchange mutation and the OS part adopted a neighborhood search mutation. The hyperparameter settings were the population size
N = 100, the number of iterations
I = 200, the crossover probability
pc = 0.8 and the mutation probability
pm = 0.01.
FIFO choses the next operation of the earliest arriving job from among the unfinished jobs and the selected operation was assigned to the machine with the smallest sum of available time and processing time among the suitable machines. The RA was used to randomly select a dispatching rule at each rescheduling point.
In order to show the solution quality of the DDQN designed in this study, the average earliness and tardiness penalties of all the algorithms compared for all test instances were calculated according to
Table 5, as shown in
Figure 5. As can be seen in
Figure 5, the DDQN outperformed the competing methods. The performance in terms of solution quality was normalized with respect to the average penalty of RA (that is, 100%). Note that the normalized performance of other algorithms, expressed as a percentage, was calculated as 100% * (algorithm penalty—RA penalty)/RA penalty. The normalized performance of the other algorithms was 33.80% (DDQN), 25.75% (DQN), 16.60% (SARSA), 1.68% (GA) and −13.32% (FIFO). It can also be seen that reinforcement learning (DDQN, DQN and SARSA) outperformed the competing methods (GA, RA and FIFO) in almost all instances, whereas deep reinforcement learning (DDQN and DQN) obtained a better solution quality than standard reinforcement learning with linear function approximation (SARSA).
To verify the generalization ability of DRL, the winning rate was defined, which was calculated as the number of instances in which the method achieved the best result divided by the number of all instances.
Figure 6 presents the winning rate of all the algorithms calculated according to
Table 4. Of the 36 test instances, the DDQN had the best results in 28 kinds of instances and the winning rate was 72.22%. The DQN has the smallest penalty for five scheduling problems and the winning rate was 13.89%. Both SARSA and GA had the minimum target value for two instances and the winning rate was 5.56%. The target value of FIFO was the smallest for one scheduling problem, with a winning rate of 2.78%. The winning rate of the random action strategy was 0%. The DDQN proposed in this study had the highest winning rate and performed at a level that was superior to the compared algorithms in general. Compared with RA, the DDQN obtained a lower total penalty in all test instances, demonstrating its ability to master difficult control policies for solving the DFJSP, to determine the proper dispatching rule at each rescheduling point.
It can be seen that on the whole, the DDQN clearly outperformed the other five methods in terms of solution quality and generalization. It is competent for solving the DFJSP with random job arrival to minimize penalties for earliness and tardiness. Reinforcement learning solves the scheduling problem as a Markov decision-making process and determines the ongoing action according to the production state to optimize the scheduling objectives.
5. Discussion
In this study, the DDQN was developed for the dynamic flexible job shop scheduling problem with random job arrival, aiming at optimizing the penalties for earliness and tardiness. In contrast to previous work [
15,
16,
17,
18,
19,
20], our approach provides DRL for the DFJSP in handling ongoing and weak correlation production states. Moreover, the soft ε-greedy strategy is designed to balance exploration and exploitation according to the problem scale, which improves the self-learning speed of the scheduling agent.
Because of the weak correlation between state features, the suitable number of dispatching actions and the DDQN architecture, the scheduling agent can achieve stable learning and convergence through training. Therefore, the training curve shows that the average penalties for earliness and tardiness drops smoothly with increasing training epochs. The proposed DRL allows the scheduling agent to learn the action–value function efficiently, to learn the optimal scheduling rules from the different production states. These comparison experiments show the DDQN-based scheduling agent outperforms the five compared methods in terms of solution quality and generalization.
The real-time optimization and decision-making of the DFJSP makes rapid and scientific response to customer orders and production emergencies and realizes intelligent matching between dispersed resources such as manpower, materials and machines. It improves the on-time delivery rate and reduces inventory and costs of enterprises. The proposed DRL provides reliable and robust scheduling schemes and meets customized production requirements according to dynamic changes in the production process. Cost, inventory, procurement, sales and transportation plans are automatically generated, which drives various management modules of enterprises around production. Therefore, the factory has the capabilities of self-learning and self-adaptation to realize intelligent decision-making.
For future work, more dynamic events like rush order insertions, stochastic processing time and machine breakdowns are worthy of investigation. Other objectives, such as machine utilization rate, energy consumption and makespan, will be considered to validate the generality of the proposed DDQN over different objectives. Meanwhile, there is not a single dispatching rule that performs well for all production environments [
20], so the number of actions should be increased for a more general agent. However, a general state value that is shared across many similar actions is learned in many control tasks with large action spaces [
31] and, consequently, introducing the dueling architecture [
31] can be useful to improve the performance of the DDQN. In addition, since the DDQN is based on experience replay, which limits the methods to off-policy learning algorithms, we will apply state-of-the-art on-policy RL algorithms, such as an asynchronous advantage actor-critic algorithm (A3C) [
32,
33] and proximal policy optimization for solving the DFJSP.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}