
Object Detection Algorithm for Surface Defects Based on a Novel YOLOv3 Model


Abstract
:1. Introduction
2. Object-Detection Algorithm Based on YOLOv3
3. Object-Detection Algorithm Based on Novel YOLOv3 Model
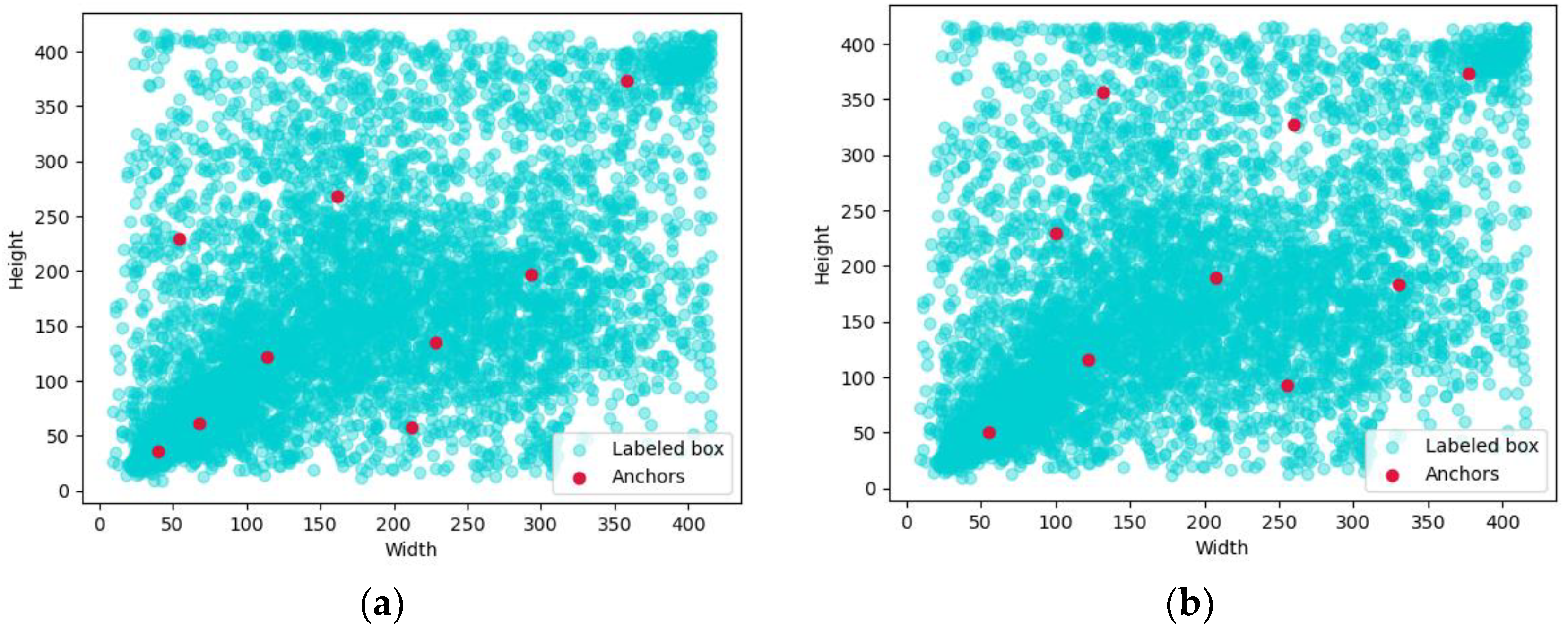
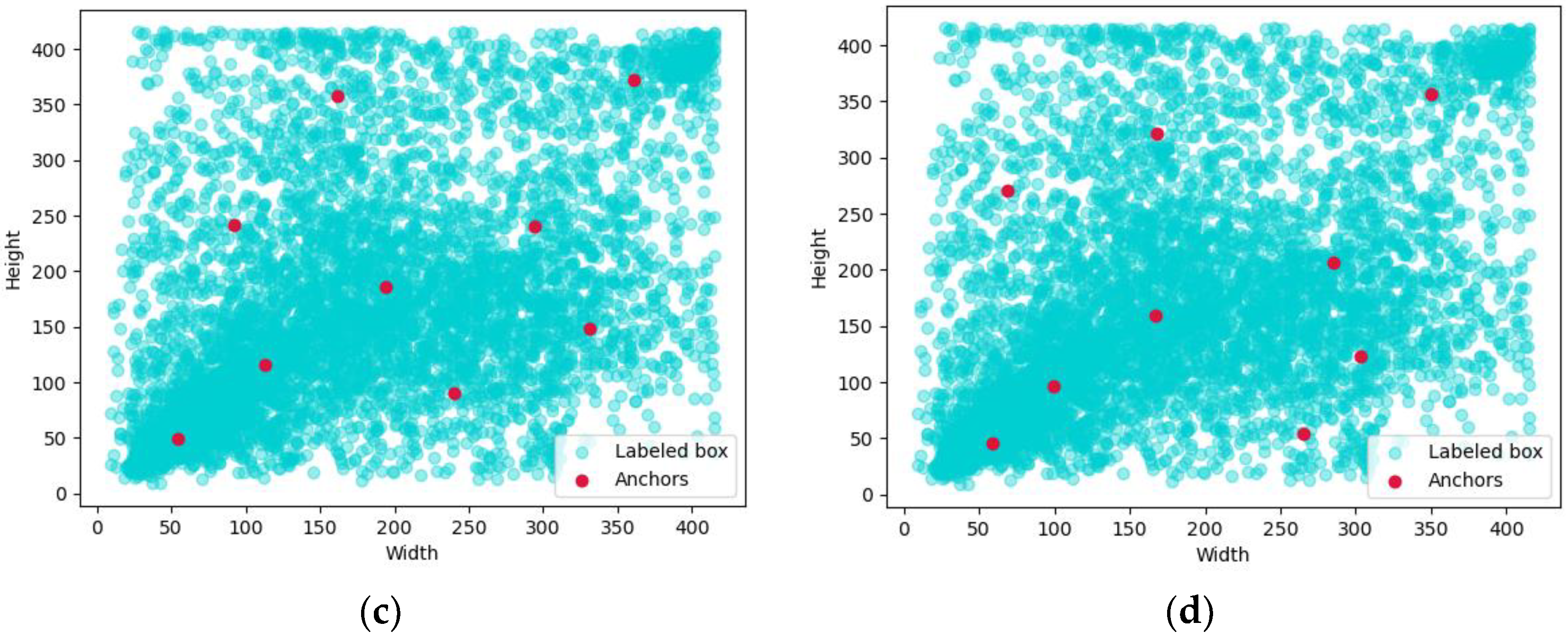
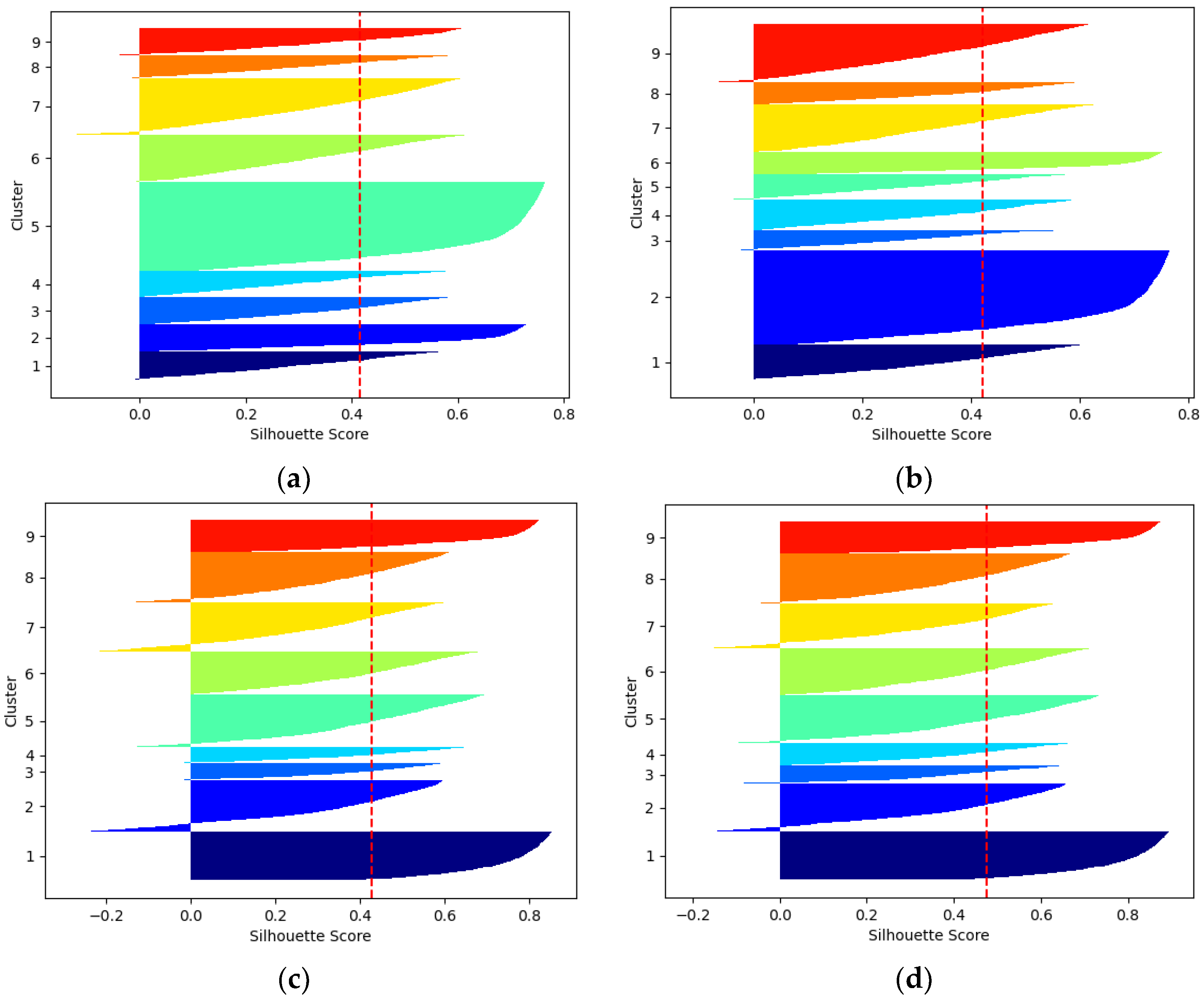
3.1. Optimization of K-Means++ Algorithm Clustering Prior Box
3.2. Fused Attention Mechanism
3.2.1. Channel Attention Module
3.2.2. Spatial Attention Module
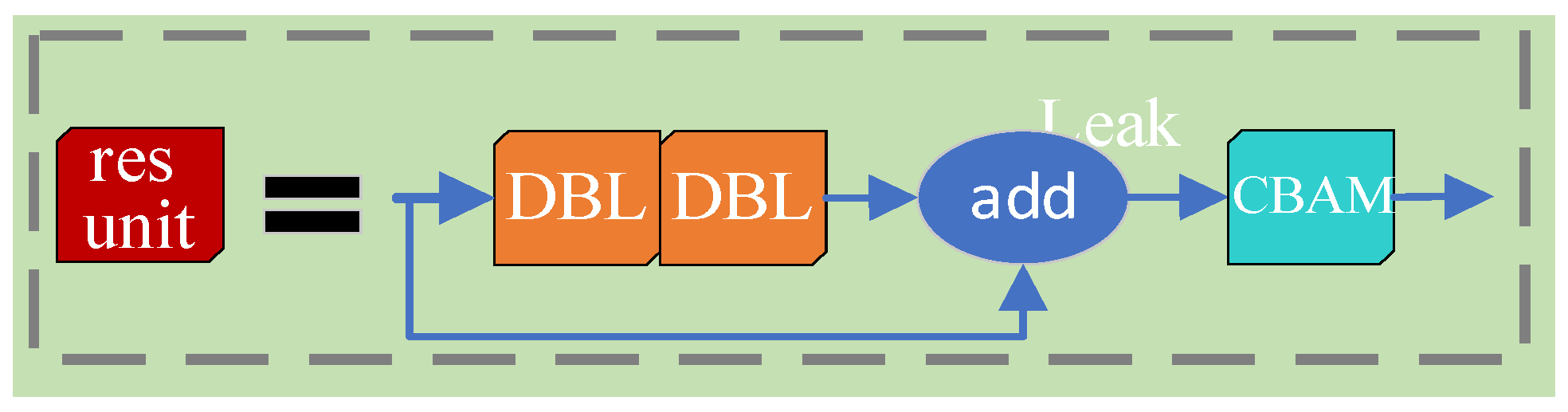
3.3. Improving the Network Structure
3.4. Optimizing the Loss Function
4. Experimental Results and Analysis
4.1. Experimental Environment and Model Parameters
4.2. Analysis of Experimental Result
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Luo, Q.; Fang, X.; Liu, L.; Yang, C.; Sun, Y. Automated Visual Defect Detection for Flat Steel Surface: A Survey. IEEE Trans. Instrum. Meas. 2020, 69, 626–644. [Google Scholar] [CrossRef] [Green Version]
- Czimmermann, T.; Ciuti, G.; Milazzo, M.; Chiurazzi, M.; Roccella, S.; Oddo, C.M.; Dario, P. Visual-based defect detection and classification approaches for industrial applications—A survey. Sensors 2020, 20, 1459. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, H.; Jing, H.; Chen, T.; Zhang, Y.; Pu, W. Partial Application of Defect Detection in Industry. Int. Core J. Eng. 2021, 7, 144–147. [Google Scholar]
- Neogi, N.; Mohanta, D.K.; Dutta, P.K. Defect detection of steel surfaces with global adaptive percentile thresholding of gradient image. J. Inst. Eng. (India) Ser. B 2017, 98, 557–565. [Google Scholar] [CrossRef]
- Haoran, G.; Wei, S.; Awei, Z. Novel defect recognition method based on adaptive global threshold for highlight metal surface. Chin. J. Sci. Instrum. 2017, 38, 2797–2804. [Google Scholar]
- Wang, Z.; Zhang, C.; Li, W.; Qian, J.; Tang, D.; Cai, B.; Chang, Y. Cathodic Copper Plate Surface Defect Detection based on Bird Swarm Algorithm with Chaotic Theory. J. Image Graph. 2020, 25, 697–707. [Google Scholar]
- Cao, G.; Ruan, S.; Peng, Y.; Huang, S.; Kwok, N. Large-Complex-Surface Defect Detection by Hybrid Gradient Threshold Segmentation and Image Registration. IEEE Access 2018, 6, 36235–36246. [Google Scholar] [CrossRef]
- Shi, T.; Kong, J.; Wang, X.; Liu, Z.; Zheng, G. Improved Sobel Algorithm for Defect Detection of Rail Surfaces with Enhanced Efficiency and Accuracy. J. Cent. South Univ. 2016, 23, 2867–2875. [Google Scholar] [CrossRef]
- Zhou, S.Y. Research on Detecting Method for Image of Surface Defect of Steel Sheet Based on Visual Saliency and Sparse Representation. Ph.D. Thesis, Huazhong University of Science and Technology, Wuhan, China, 2017. [Google Scholar]
- Huang, Q.; Zhang, H.; Zeng, X.; Huang, W. Automatic Visual Defect Detection Using Texture Prior and Low-Rank Representation. IEEE Access 2018, 6, 37965–37976. [Google Scholar] [CrossRef]
- Wang, J.; Li, Q.; Gan, J.; Yu, H.; Yang, X. Surface Defect Detection via Entity Sparsity Pursuit With Intrinsic Priors. IEEE Trans. Ind. Inform. 2020, 16, 141–150. [Google Scholar] [CrossRef]
- Perez, H.; Tah, J.H.; Mosavi, A. Deep learning for detecting building defects using convolutional neural networks. Sensors 2019, 19, 3556. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhou, H.; Zhuang, Z.; Liu, Y.; Liu, Y.; Zhang, X. Defect classification of green plums based on deep learning. Sensors 2020, 20, 6993. [Google Scholar] [CrossRef] [PubMed]
- Jiao, L.; Zhang, F.; Liu, F.; Yang, S.; Li, L.; Feng, Z.; Qu, R. A survey of deep learning-based object detection. IEEE Access 2019, 7, 128837–128868. [Google Scholar] [CrossRef]
- Felzenszwalb, P.; McAllester, D.; Ramanan, D. A discriminatively trained, multiscale, deformable part model. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 1–8 June 2008. [Google Scholar]
- Girshick, R.; Iandola, F.; Darrell, T.; Malik, J. Deformable part models are convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 437–446. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Seferbekov, S.; Iglovikov, V.; Buslaev, A.; Shvets, A. Feature pyramid network for multi-class land segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 272–275. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Xu, Y.; Zhang, K.; Wang, L. Metal Surface Defect Detection Using Modified YOLO. Algorithms 2021, 14, 257. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Qianhui, Y.; Changlun, Z.; Qiang, H.; Hengyou, W. Research Progress of Loss Function in Object Detection. Comput. Sci. Appl. 2021, 11, 2836–2844. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number/Loss | L2 Loss | IoU Loss | GIoU Loss |
|---|---|---|---|
| a | 19.69 | 0.16 | 0.07 |
| b | 19.69 | 0.18 | 0.18 |
| c | 19.69 | 0.29 | 0.29 |
| Category | Model/Version |
|---|---|
| CPU | Intel Xeon CPU E5-2678 v3 @ 2.50 GHz |
| GPU | NVIDIA GeForce RTX 2080 Ti 11 G |
| RAM | Samsung RECC DDR4 16 G |
| SSD | Samsung SSD 860EVO 512 G |
| Operating system | Ubuntu 18.04 |
| CUDA version | CUDA10.0 |
| cuDNN | cuDNN 7.6 |
| Programming language | Python 3.7 |
| Hyperparameter Name | Parameter Value |
|---|---|
| Learning rate | 0.0001 |
| Batch size | 16 |
| Weight decay coefficient | 0.0005 |
| The number of iterations | 100,000 |
| Number of Figure | Feature Graph | Receptive Field | Prior Box | ||
|---|---|---|---|---|---|
| a | Big | ||||
| Middle | |||||
| Small | |||||
| b | Big | ||||
| Middle | |||||
| Small | |||||
| c | Big | ||||
| Middle | |||||
| Small | |||||
| d | Big | ||||
| Middle | |||||
| Small | |||||
| Number of Figure | Clustering Method | Measurement Method | Number of Clustering Centers | Value of Average Contour Coefficient |
|---|---|---|---|---|
| a | K-means | Euclidean distance | 9 | 0.41 |
| b | K-means++ | Euclidean distance | 9 | 0.42 |
| c | K-means | IoU | 9 | 0.43 |
| d | K-means++ | IoU | 9 | 0.48 |
| Algorithm Name | Pit (AP%) | Patches (AP/%) | Scratches (AP/%) | Crazing (AP/%) | Concave (AP/%) | mAP (%) |
|---|---|---|---|---|---|---|
| YOLOv3 | 76.94 | 65.46 | 54.74 | 30.32 | 21.97 | 49.89 |
| YOLOv3-CBAM | 80.36 | 67.39 | 56.16 | 31.23 | 23.41 | 51.71 |
| YOLOv3-Loss | 85.21 | 71.46 | 72.36 | 43.45 | 42.53 | 63.00 |
| YOLOv3-4L | 84.69 | 75.23 | 73.63 | 51.16 | 40.19 | 64.98 |
| YOLOv3-ALL | 94.85 | 82.58 | 78.11 | 68.54 | 51.15 | 75.05 |
| Algorithm Type | Test Pictures (piece) | Total Time Taken (ms) | Average Detection Time (ms) |
|---|---|---|---|
| YOLOv3 | 300 | 9713 | 32 |
| YOLOv3-ALL | 300 | 11628 | 39 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lv, N.; Xiao, J.; Qiao, Y. Object Detection Algorithm for Surface Defects Based on a Novel YOLOv3 Model. Processes 2022, 10, 701. https://doi.org/10.3390/pr10040701
Lv N, Xiao J, Qiao Y. Object Detection Algorithm for Surface Defects Based on a Novel YOLOv3 Model. Processes. 2022; 10(4):701. https://doi.org/10.3390/pr10040701
Chicago/Turabian StyleLv, Ning, Jian Xiao, and Yujing Qiao. 2022. "Object Detection Algorithm for Surface Defects Based on a Novel YOLOv3 Model" Processes 10, no. 4: 701. https://doi.org/10.3390/pr10040701