


A Shift Schedule to Optimize Pure Electric Vehicles Based on RL Using Q-Learning and Opt LHD

Abstract
:1. Introduction
2. Modeling of the Pure Electric Vehicle
2.1. Driver Model
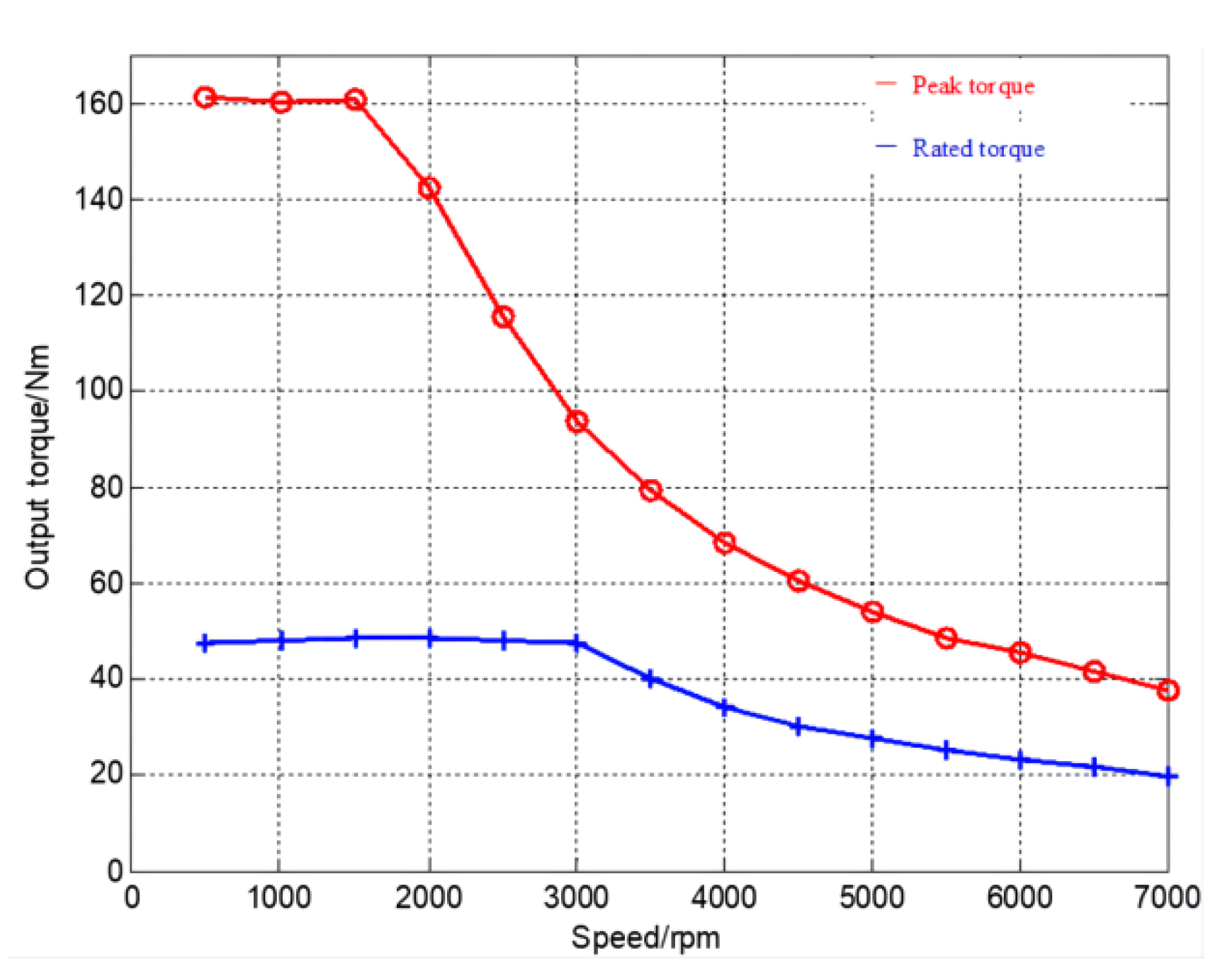
2.2. Motor Model
2.3. Battery Model
2.4. Power Train Model
2.5. Vehicle Dynamics Model
3. Design of Shift Schedules
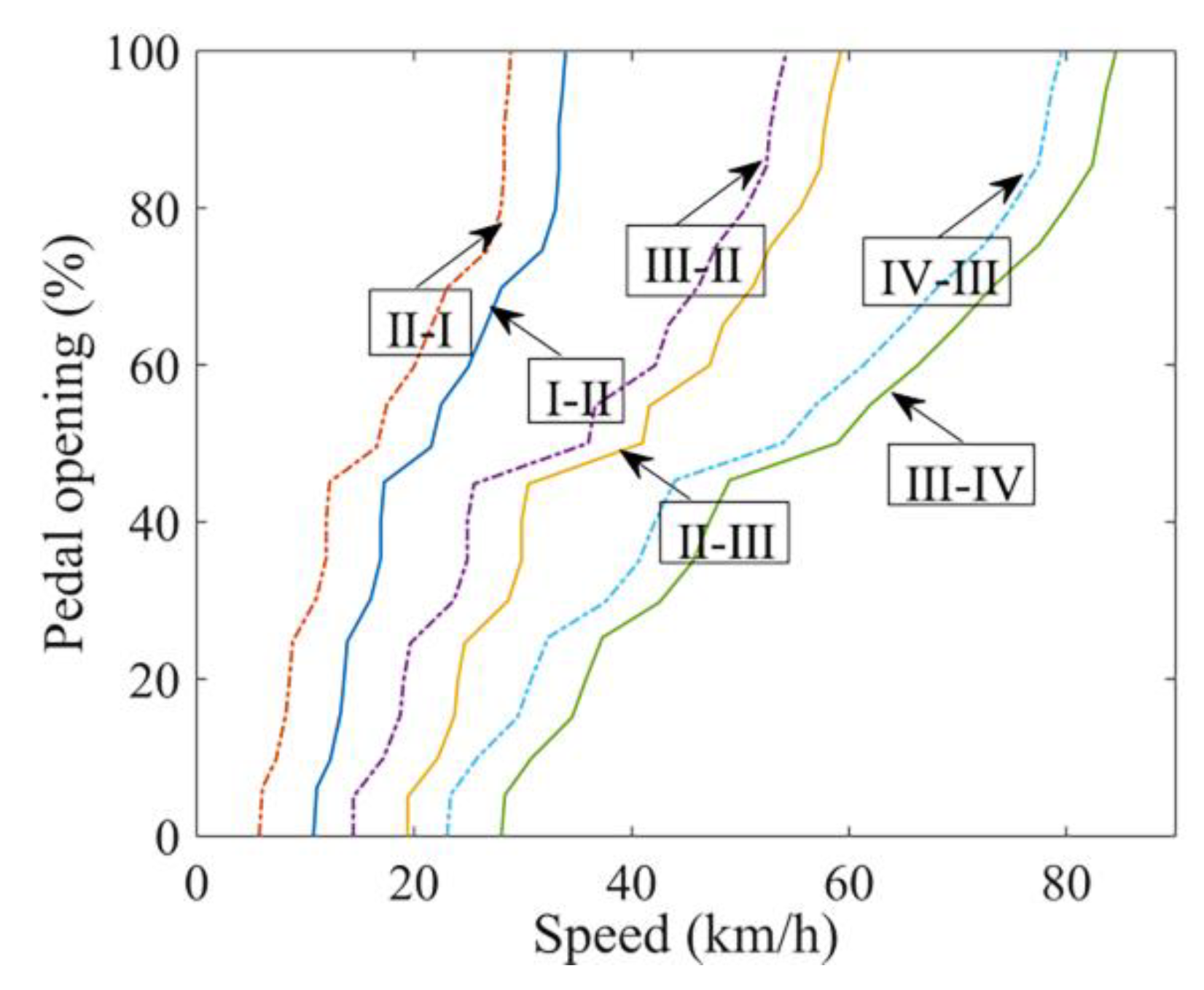
3.1. Design of EC Shift Schedule
3.2. Design of the Shift Schedule Based on RL
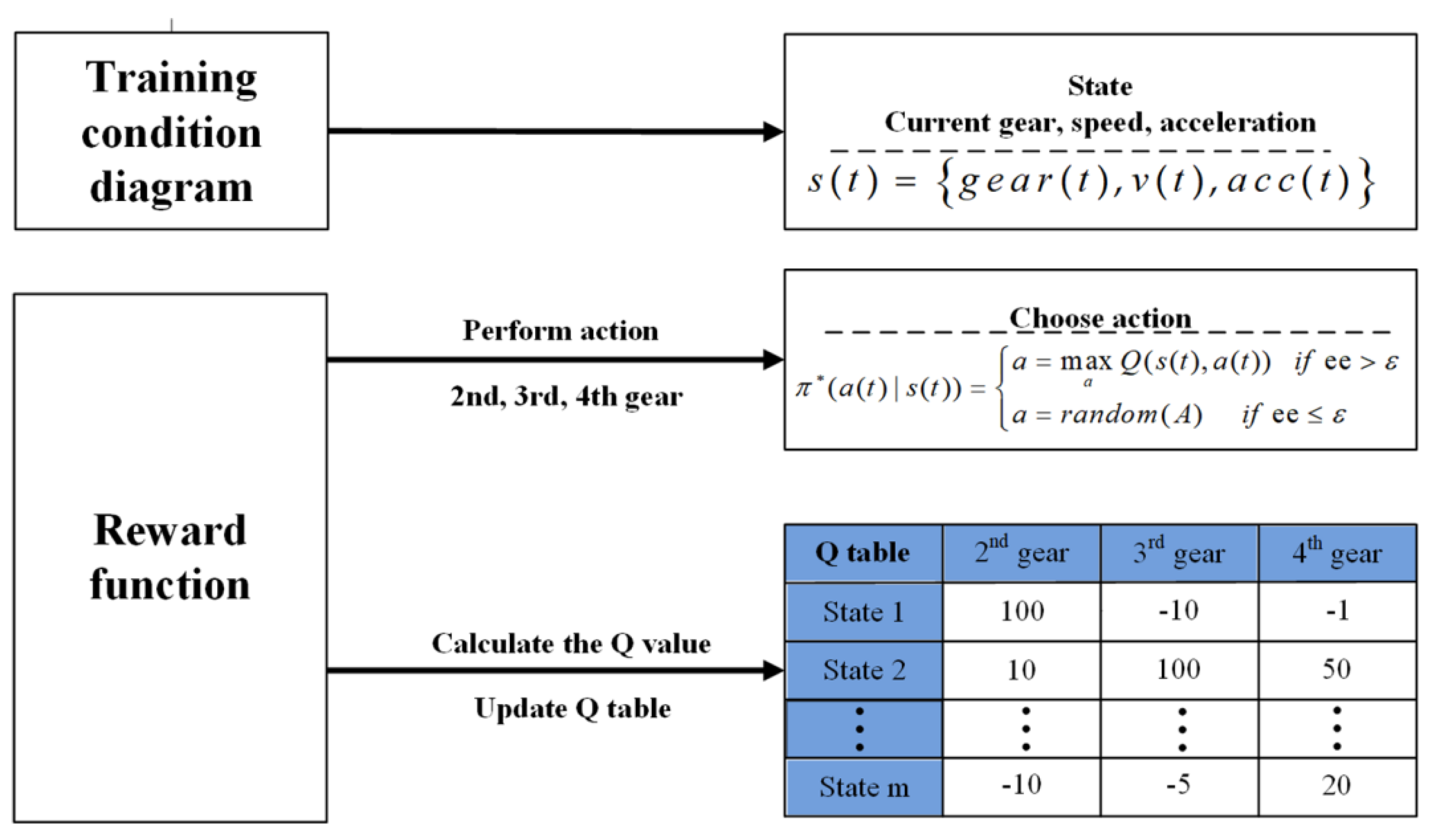
3.2.1. Establishment of States and Actions of RL Algorithms
3.2.2. RL State Space Reduction
3.2.3. Return Function of the Shift Schedule Based on RL
3.2.4. Establishment of the Shift Schedule Based on RL
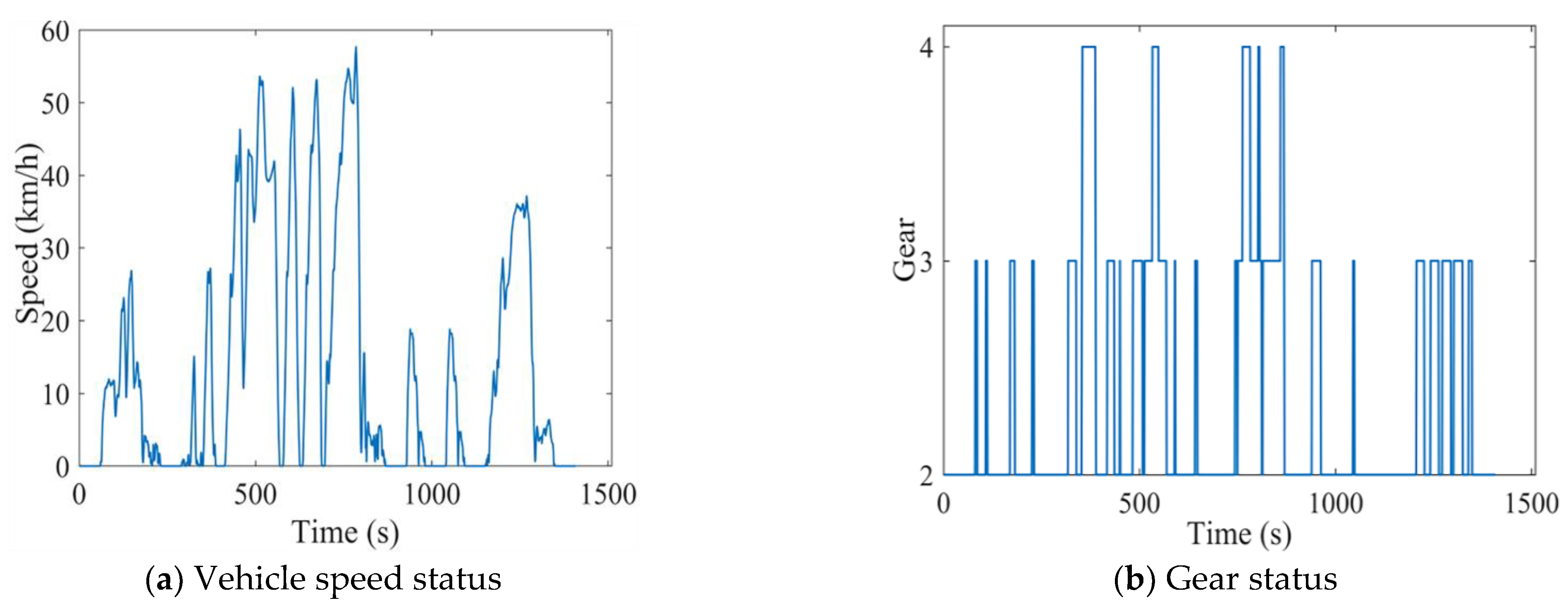
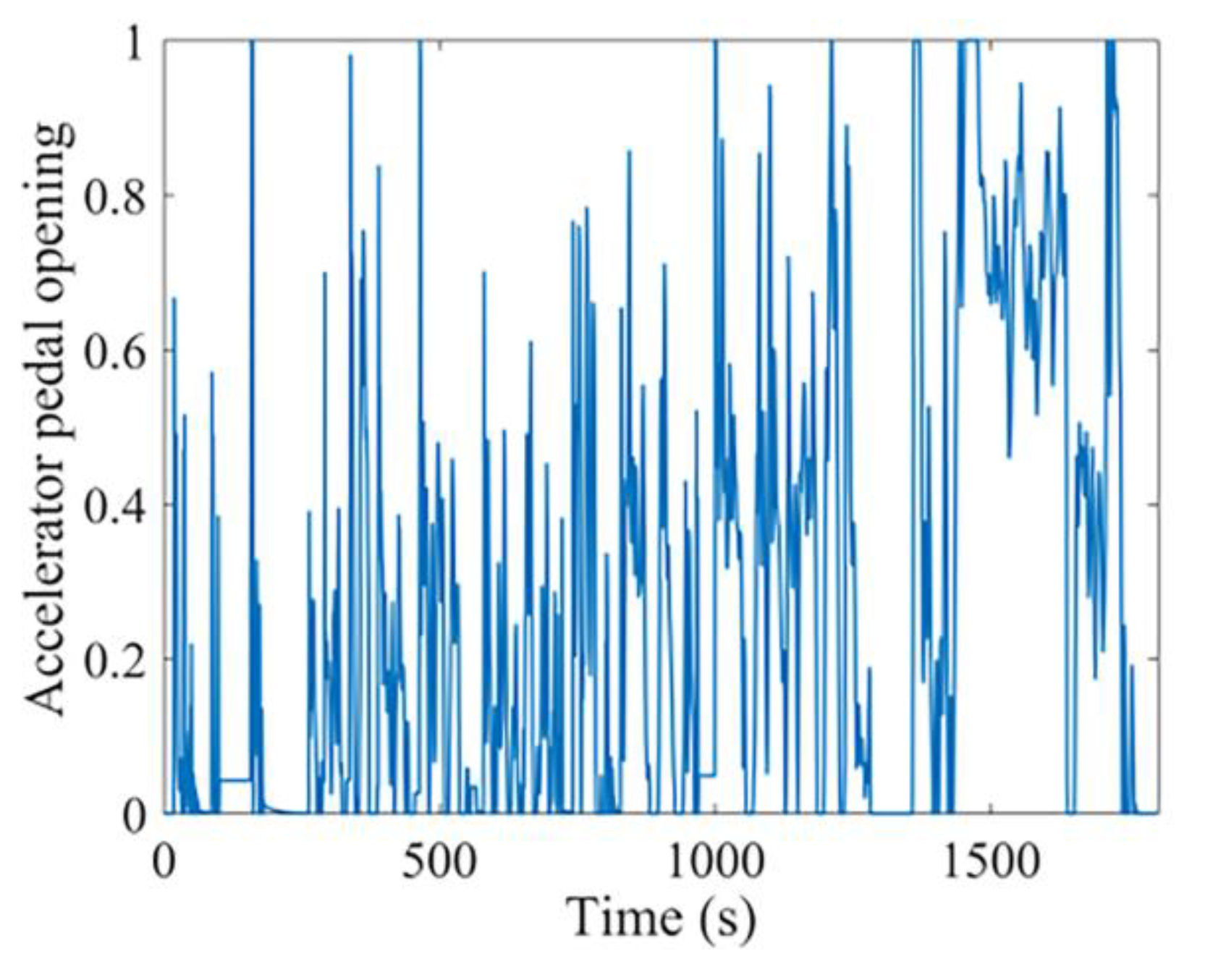
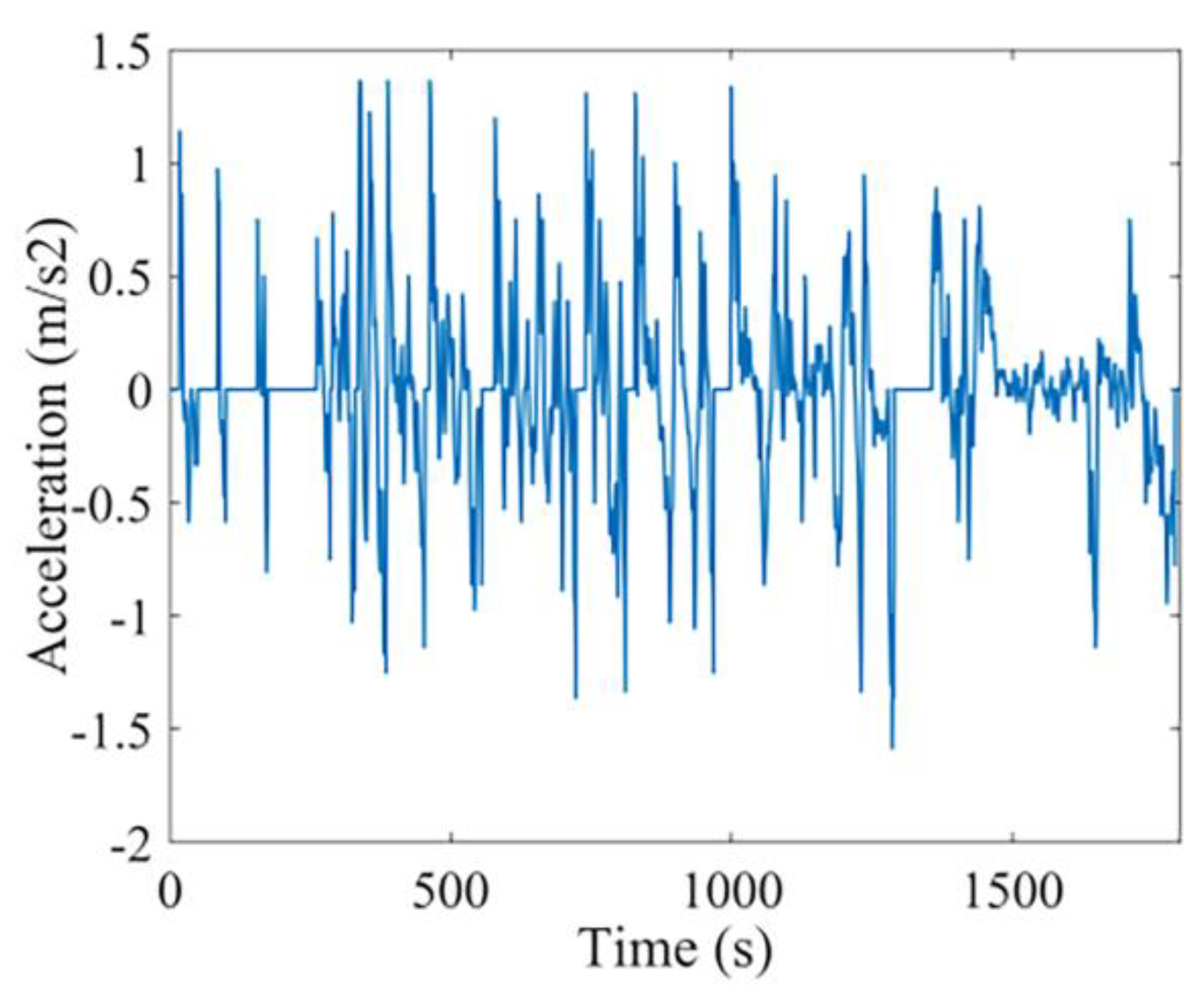
3.2.5. Model Simulation Verification
4. Hardware-in-the-Loop Experiment
4.1. Introduction to Hardware-in-the-Loop Platforms
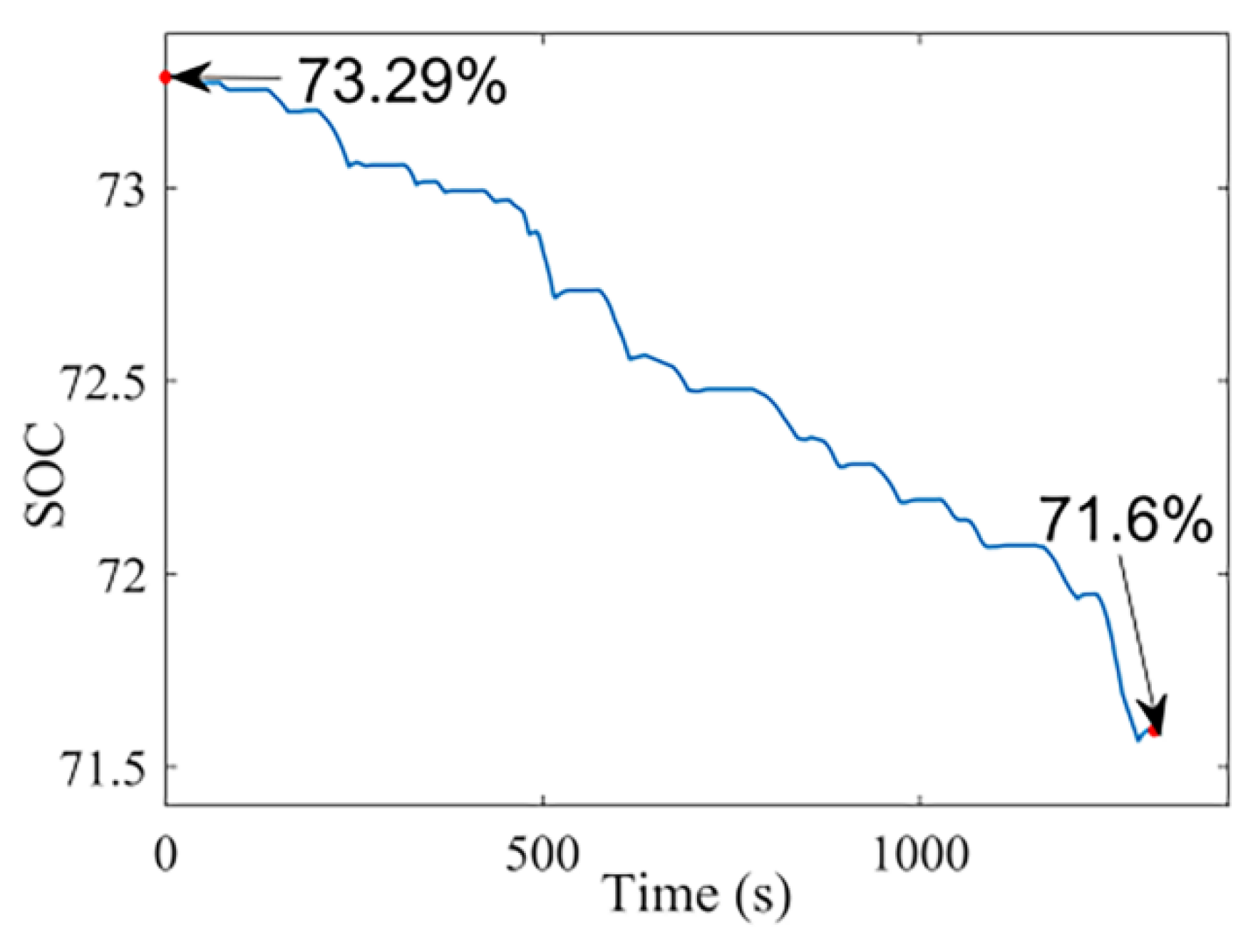
4.2. Hardware-in-the-loop Experiments and Analysis
Dynamic Shift Experiment






5. Conclusions
- (1)
- The proposed shift schedule can continuously self-learn according to the reward and punishment mechanism designed by the reward function and match the best gear according to the principle of economy. It solves the problem of high energy consumption caused by poor adaptability of traditional shift schedules.
- (2)
- The Opt LHD was introduced to reduce the state space of the Q table of the shift schedule, and solved the problem that the shift schedule could not be embedded in the TCU due to the “dimension disaster”. Using Opt LHD sampling can reduce the number of trials, ease the computational burden of the computer, and effectively reduce the computing power demand.
- (3)
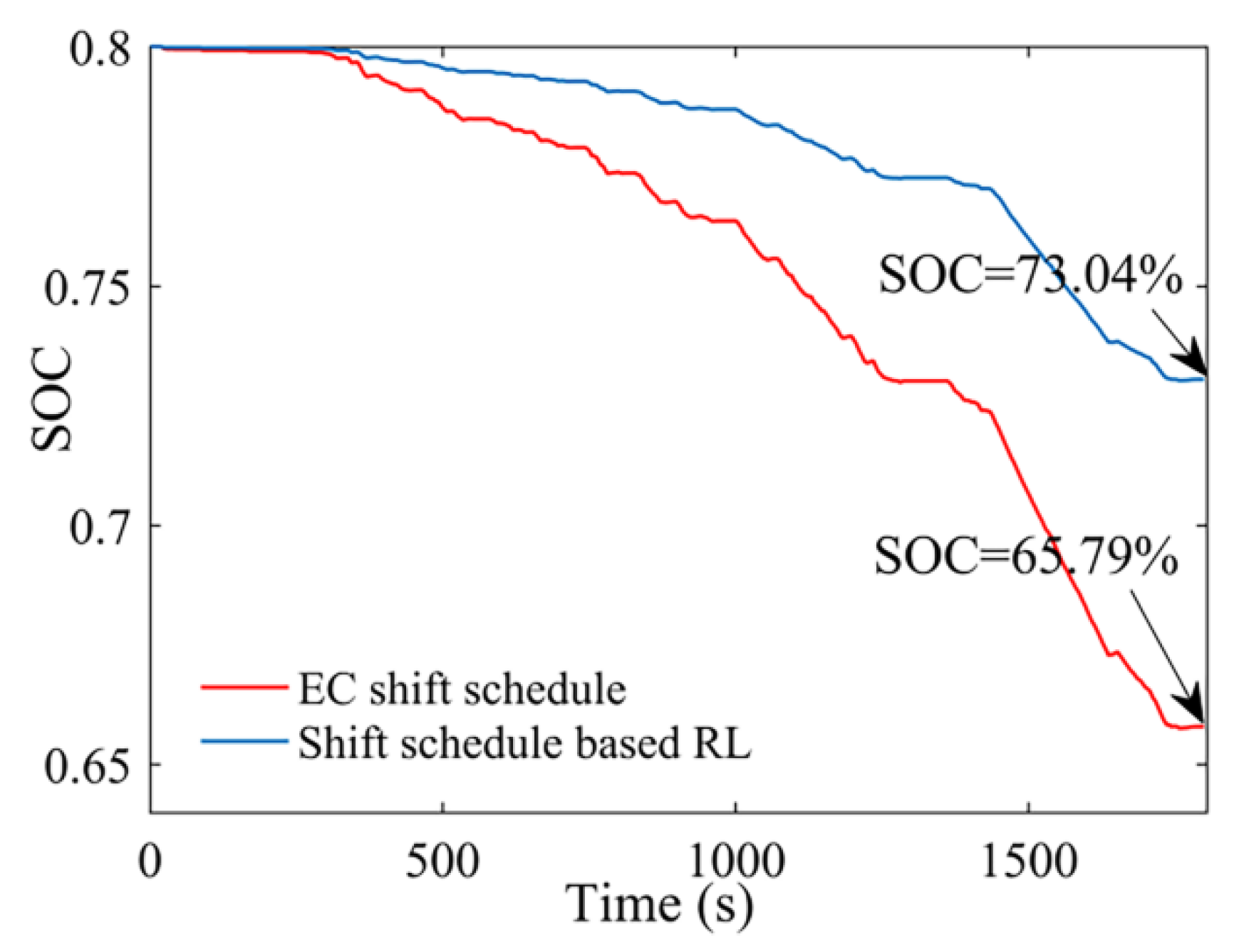
- Compared with the EC shift schedule, energy consumption is reduced by about 3.18% by using the shift schedule based on RL. The feasibility and application potential of the shift schedule based on RL have been proven.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ruan, J.; Walker, P.; Zhang, N. A comparative study energy consumption and costs of battery electric vehicle transmissions. Appl. Energy 2016, 165, 119–134. [Google Scholar] [CrossRef] [Green Version]
- Han, K.; Wang, Y.; Filev, D.; Dai, E.; Kolmanovsky, I.; Girard, A. Optimized design of multi-speed transmissions for battery electric vehicles. In Proceedings of the 2019 American Control Conference (ACC), Philadelphia, PA, USA, 10–12 July 2019; pp. 816–821. [Google Scholar]
- Nguyen, C.T.; Walker, P.D.; Zhang, N. Optimization and coordinated control of gear shift and mode transition for a dual-motor electric vehicle. Mech. Syst. Signal Process. 2021, 158, 107731. [Google Scholar] [CrossRef]
- Han, K.; Li, N.; Kolmanovsky, I.; Girard, A.; Wang, Y.; Filev, D.; Dai, E. Hierarchical optimization of speed and gearshift control for battery electric vehicles using preview information. In Proceedings of the 2020 American Control Conference (ACC), Denver, CO, USA, 1–3 July; 2020; pp. 4913–4919. [Google Scholar]
- Sujan, V.A. System and Methods of Adjusting a Transmission Shift Schedule. U.S. Patent 9,989,147, 5 June 2018. [Google Scholar]
- Yuanguang, J.; Haonan, L.; Jiankun, P.; Zhanjiang, L. Research of the AMT Multi Parameter Fusion Shift Rule of Pure Electric Bus. Mech. Transm. 2019, 43, 21–26. [Google Scholar] [CrossRef]
- Huang, W.; Huang, J.; Yin, C. Optimal design and control of a two-speed planetary gear automatic transmission for electric vehicle. Appl. Sci. 2020, 10, 6612. [Google Scholar] [CrossRef]
- Sun, G.B.; Chiu, Y.J.; Lu, G.W.; Xiong, M. The Study of Dynamic Programming with Fuzzy Logic Energy Design and Simulation of Gear Shift for Electric Vehicles. J. Netw. Intell. 2019, 4, 88–99. [Google Scholar]
- Lin, C.; Zhao, M.; Pan, H.; Yi, J. Blending gear shift strategy design and comparison study for a battery electric city bus with AMT. Energy 2019, 185, 1–14. [Google Scholar] [CrossRef]
- Hang, Q.; Hongwen, H.; Mo, H. Electric Vehicle Shift Strategy Based on Model Predictive Control. J. Chongqing Univ. Technol. 2021, 35, 90–95. [Google Scholar]
- Li, H.; He, H.; Peng, J.; Li, Z. Five-parameter shift strategy of automatic mechanical transmission for electric bus. DEStech Trans. Env. Energ. Earth Sci. 2019. [CrossRef]
- Li, G.; Görges, D. Ecological adaptive cruise control for vehicles with step-gear transmission based on RL. IEEE Trans. Intell. Transp. Syst. 2019, 21, 4895–4905. [Google Scholar] [CrossRef]
- Wenguang, L.; Shanshan, B.; Chang, X. Shifting Strategy for Two-Speed AMT of Electric Vehicle. J. Chongqing Univ. Technol. 2021, 35, 41–49. [Google Scholar]
- Liu, Z.; Li, Z.; Zhang, J.; Su, L.; Ge, H. Accurate and efficient estimation of lithium-ion battery state of charge with alternate adaptive extended Kalman filter and ampere-hour counting methods. Energies 2019, 12, 757. [Google Scholar] [CrossRef] [Green Version]
- Zhu, B.; Zhang, N.; Walker, P.; Zhou, X.; Zhan, W.; Wei, Y.; Ke, N. Gear shift schedule design for multi-speed pure electric vehicles. Proc. Inst. Mech. Eng. Part D J. Automob. Eng. 2015, 229, 70–82. [Google Scholar] [CrossRef]
- Samadi, E.; Badri, A.; Ebrahimpour, R. Decentralized multi-agent based energy management of microgrid using RL. Int. J. Electr. Power Energy Syst. 2020, 122, 106211. [Google Scholar] [CrossRef]
- Yi, J.; Li, X.; Xiao, M.; Xu, J.; Zhang, L. Construction of nested maximin designs based on successive local enumeration and modified novel global harmony search algorithm. Eng. Optim. 2017, 49, 161–180. [Google Scholar] [CrossRef]
- Chen, J.; Su, Y. Fuel Consumption and Nox Emissions from Vehicle Over the Wltc and Cltc_C. Available online: https://ssrn.com/abstract=4046059 (accessed on 17 October 2022).
- Powell, B.K.; Bailey, K.E.; Cikanek, S.R. Dynamic modeling and control of hybrid electric vehicle powertrain systems. IEEE Control. Syst. Mag. 1998, 18, 17–33. [Google Scholar]
- Lewis, F.L.; Vrabie, D. RL and adaptive dynamic programming for feedback control. IEEE Circuits Syst. Mag. 2009, 9, 32–50. [Google Scholar] [CrossRef]
- Sun, Y.; Ru, Y.; He, X.; Dong, C. Research on Testing System and Test Method for Charging Facilities of Electric Vehicles. In Proceedings of the 2018 5th IEEE International Conference on Cloud Computing and Intelligence Systems (CCIS), Nanjing, China, 23–25 November 2018; pp. 1048–1052. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Working Condition | Time | Distance | vmax | amax |
|---|---|---|---|---|
| WVUCITY | 1408 s | 5.29 km | 57.65 km/h | 1.14 m/s2 |
| WVUSUB | 1665 s | 24.81 km | 72.10 km/h | 1.30 m/s2 |
| HWFET | 766 s | 16.41 km | 96.40 km/h | 1.43 m/s2 |
| UDDS | 1370 s | 11.99 km | 91.25 km/h | 1.48 m/s2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, X.; Zhao, L.; Zhang, K.; Guo, H. A Shift Schedule to Optimize Pure Electric Vehicles Based on RL Using Q-Learning and Opt LHD. Processes 2022, 10, 2132. https://doi.org/10.3390/pr10102132
Yu X, Zhao L, Zhang K, Guo H. A Shift Schedule to Optimize Pure Electric Vehicles Based on RL Using Q-Learning and Opt LHD. Processes. 2022; 10(10):2132. https://doi.org/10.3390/pr10102132
Chicago/Turabian StyleYu, Xin, Ling Zhao, Kun Zhang, and Hongqiang Guo. 2022. "A Shift Schedule to Optimize Pure Electric Vehicles Based on RL Using Q-Learning and Opt LHD" Processes 10, no. 10: 2132. https://doi.org/10.3390/pr10102132