
Synthetic Dataset Generation of Driver Telematics


Abstract
:1. Background
1.1. Literature
1.2. Motivation
2. Related Work
2.1. Extended SMOTE
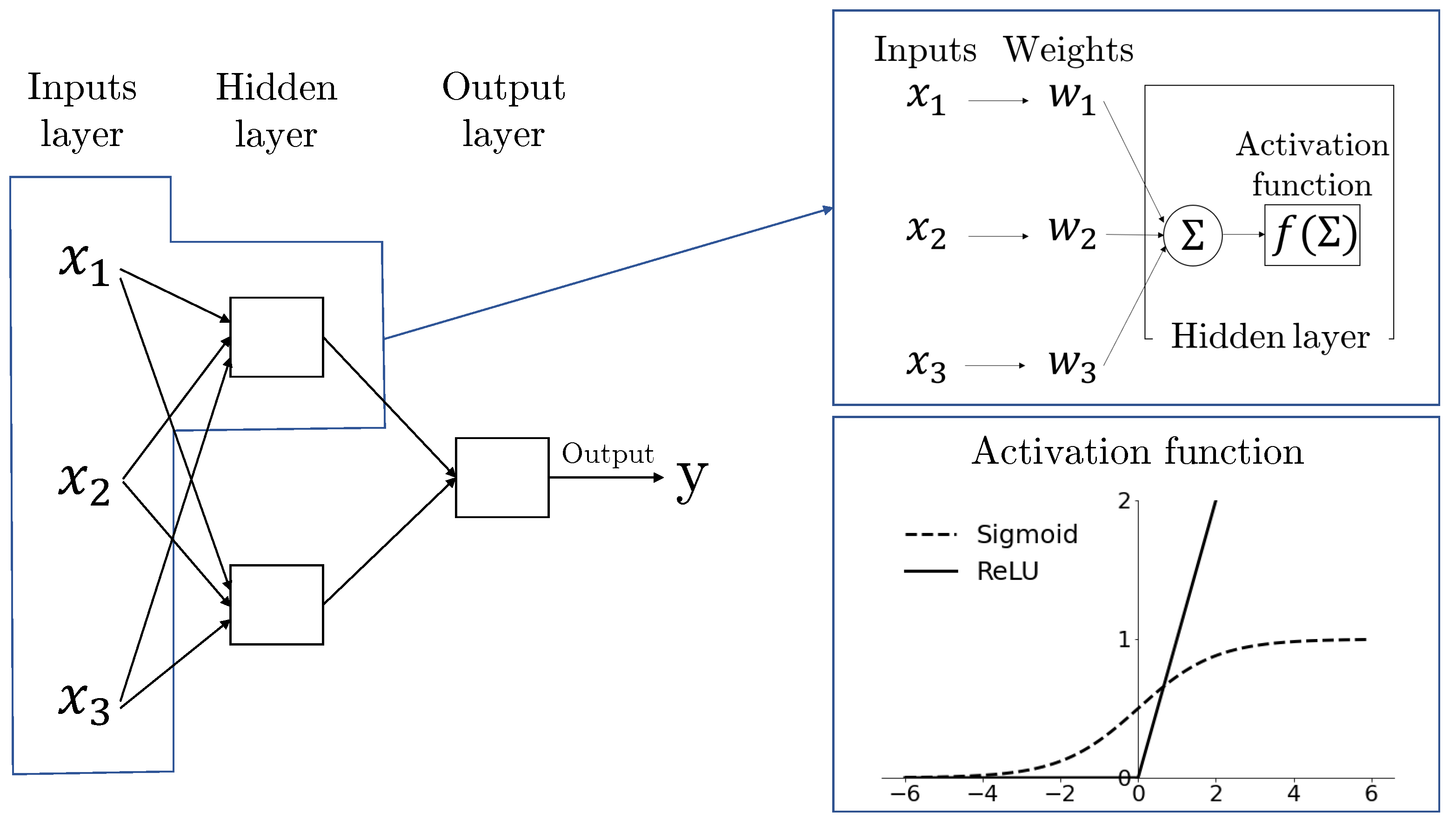
2.2. Feedforward Neural Network
3. The Synthetic Output: File Description
- Duration is the period that policyholder is insured in days, with values in [22, 366].
- Insured.age is the age of insured driver in integral years, with values in [16, 103].
- Car.age is the age of vehicle, with values in [−2, 20]. Negative values are rare but are possible as buying a newer model can be up to two years in advance.
- Years.noclaims is the number of years without any claims, with values in [0, 79] and always less than Insured.age.
- Territory refers to the territorial location code of vehicle, which has 55 labels in {11, 12, 13, …, 91}.
- Annual.pct.driven is the number of day a policyholder uses vehicle divided by 365, with values in [0, 1].
- Pct.drive.mon, ⋯, Pct.drive.sun are compositional variables meaning that the sum of seven (days of the week) variables is 100%.
- Pct.drive.wkday and Pct.drive.wkend are clearly compositional variables too.
- NB_Claim refers to the number of claims, with values in {0, 1, 2, 3}; 95.72% observations with zero claim, 4.06% with exactly one claim, and merely 0.20% with two claim and 0.01% with three claim. Real NB_Claim has the following proportions; zero claim: 95.60%, one claim: 4.19%, two claim: 0.20%, three claim: 0.007%.
- AMT_Claim is the aggregated amount of claims, with values in [0, 138766.5]. Table 3 shows summary statistics of synthetic and real data.
4. The Data Generating Process
4.1. The Detailed Simulation Procedures
4.1.1. Synthetic Portfolio Generation
- integer features are rounded up;
- for categorical features, only Car.use are multi-class. Car.use is converted by one-hot coding before applying extended SMOTE so that every categorical feature variable has the value 0 or 1. After the generation, they are rounded up; and,
- for compositional features, Pct.drive.sun and Pct.drive.wkend are not involved in the generation process, but are calculated by ‘1 − the rest of related features.’
4.1.2. The Simulation of Number of Claims
- Sub-simulation 1: . Corresponding instance index is. The data is given as the following:
- Sub-simulation 2: . Corresponding instance index is. The data is given as the following:
- Sub-simulation 3: . Corresponding instance index is. The data is given as the following:
4.1.3. The Simulation of Aggregated Amount of Claims
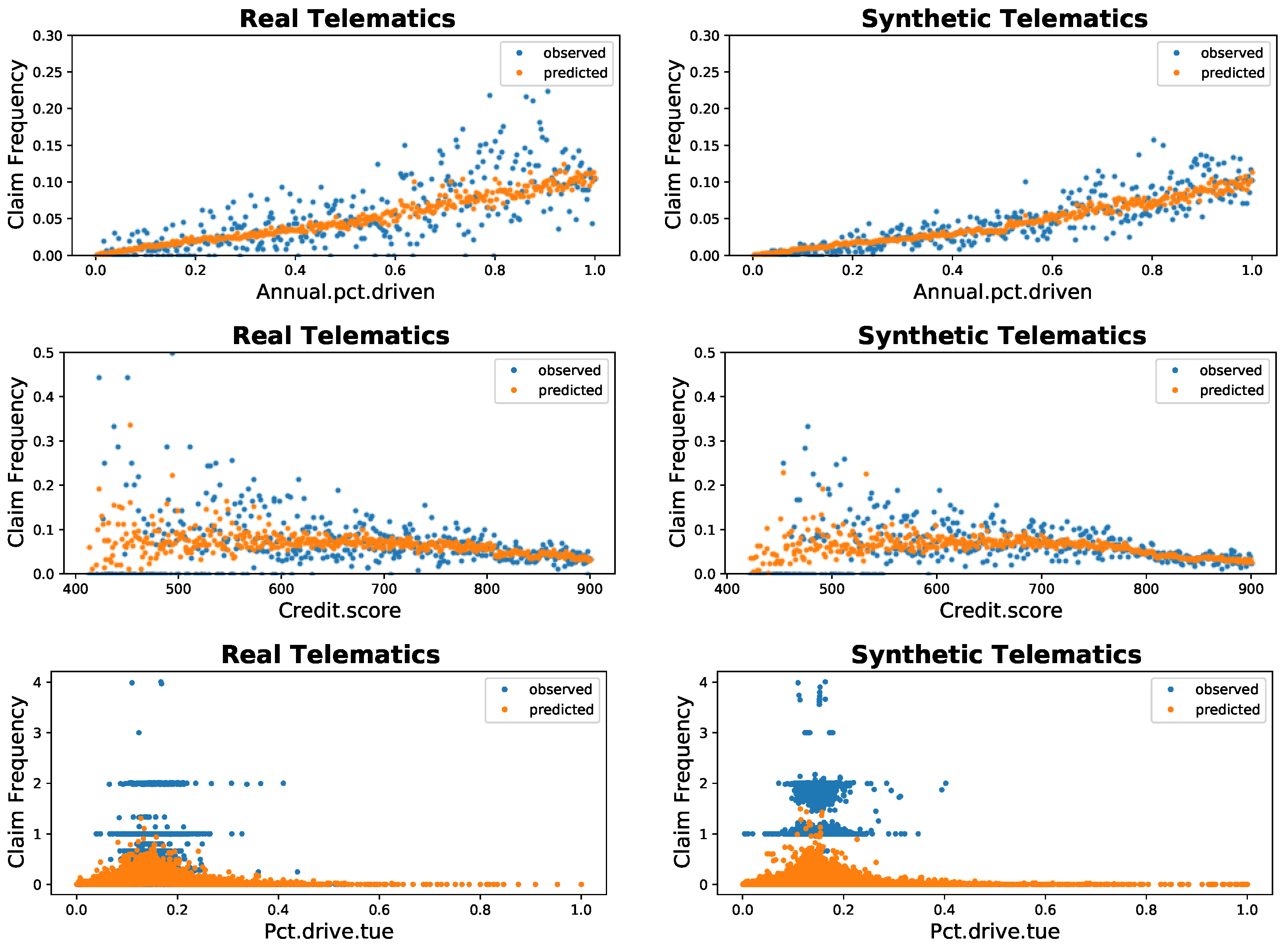
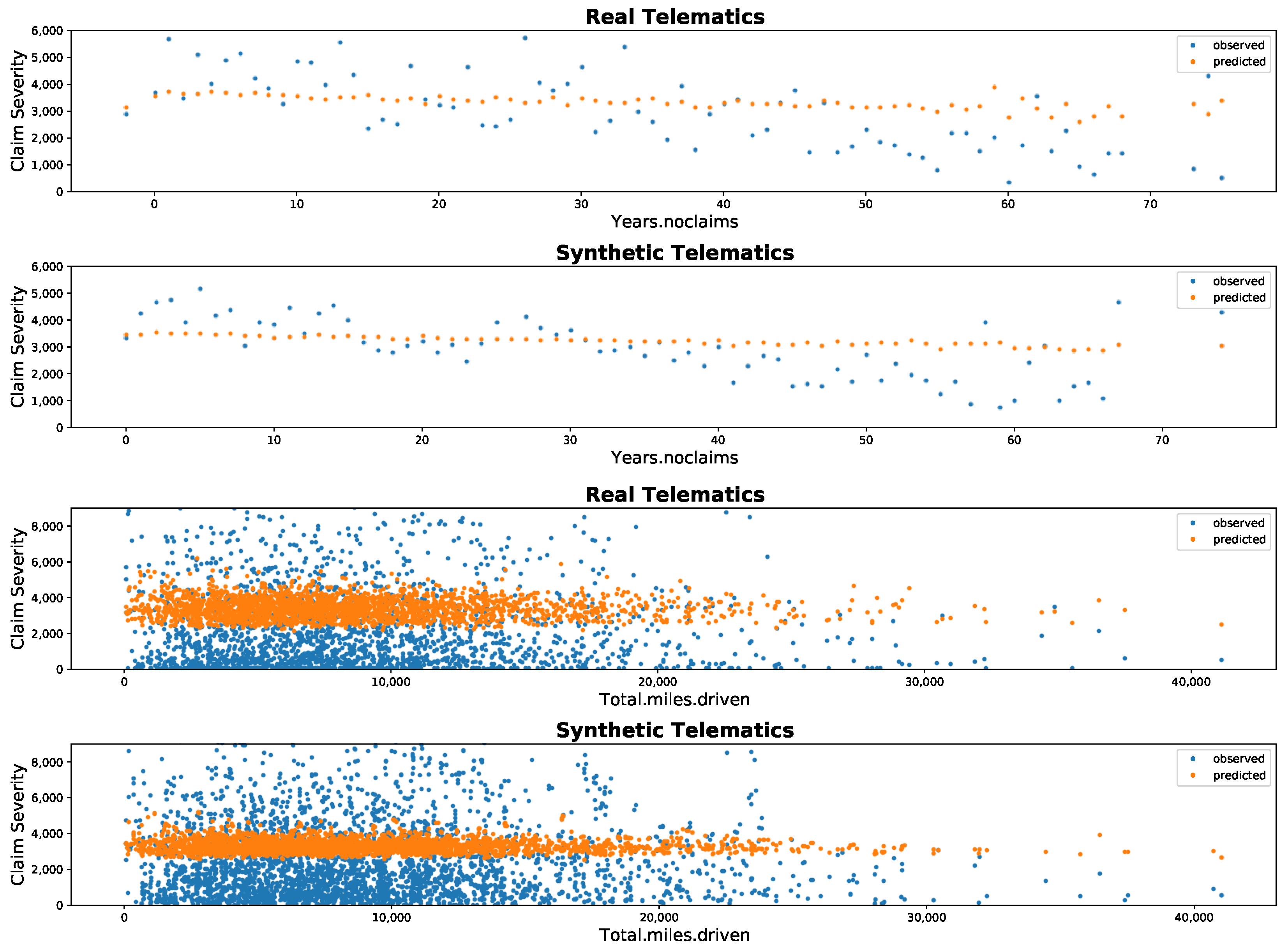
4.2. Comparison: Poisson and Gamma Regression
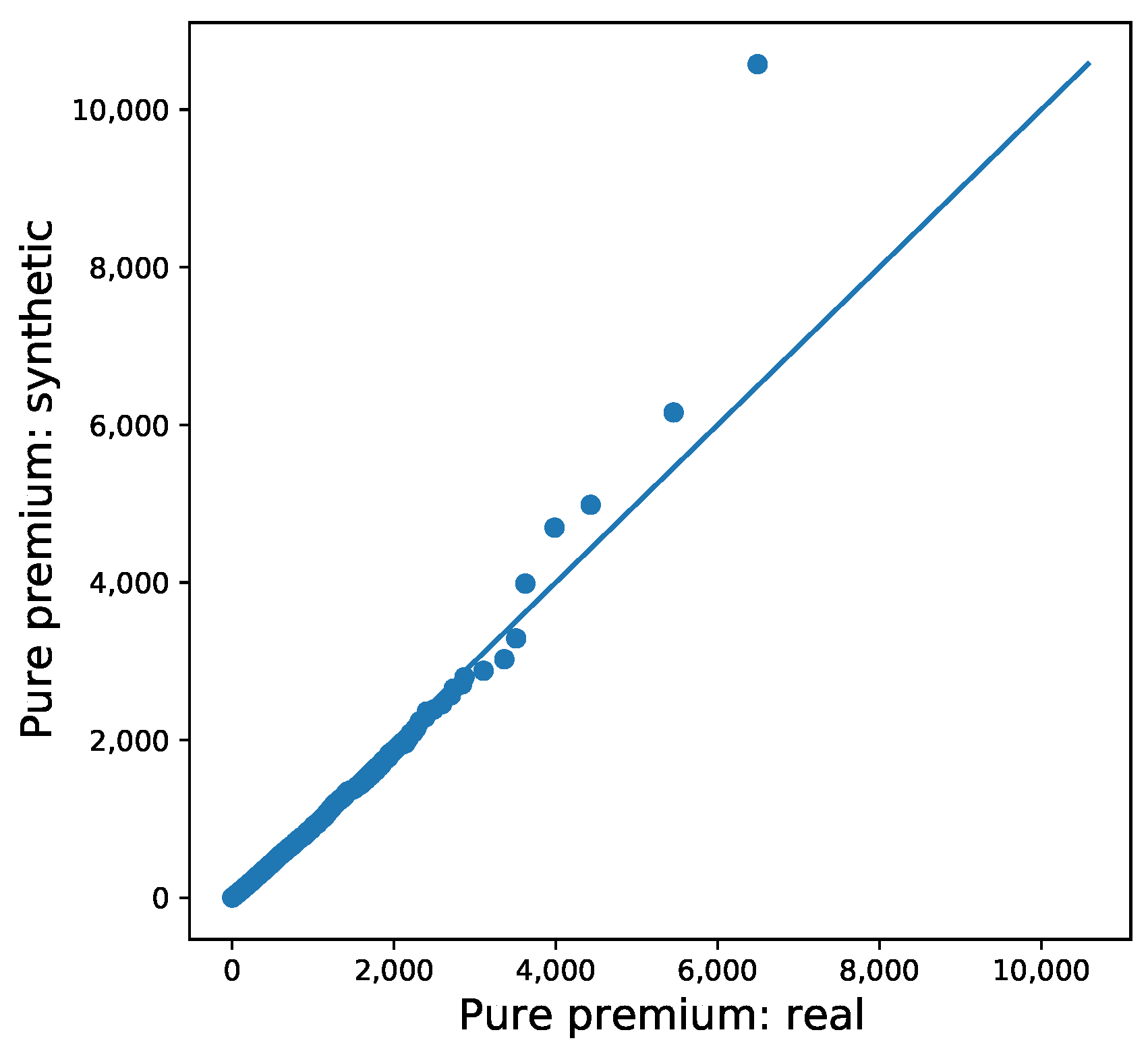
5. Concluding Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
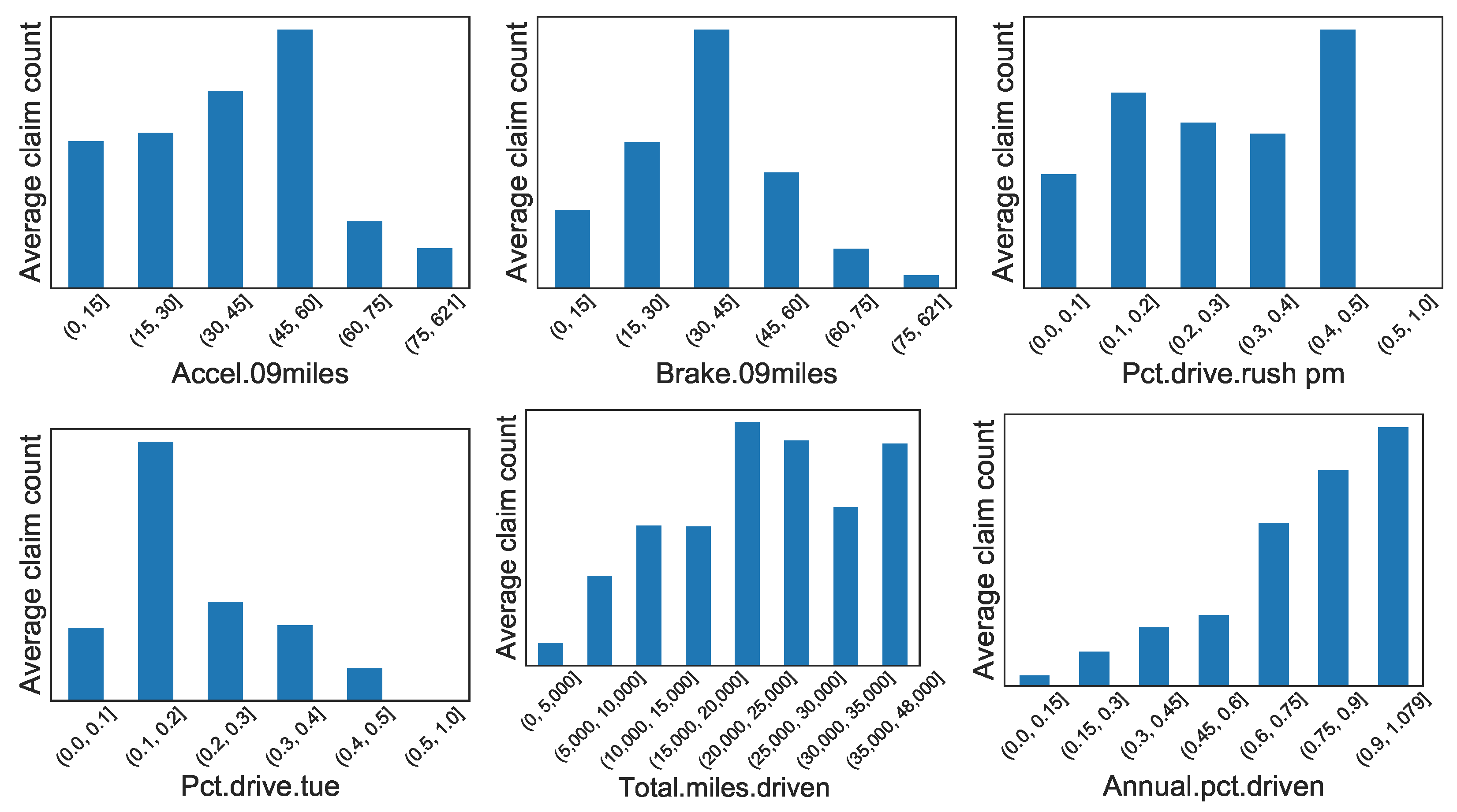
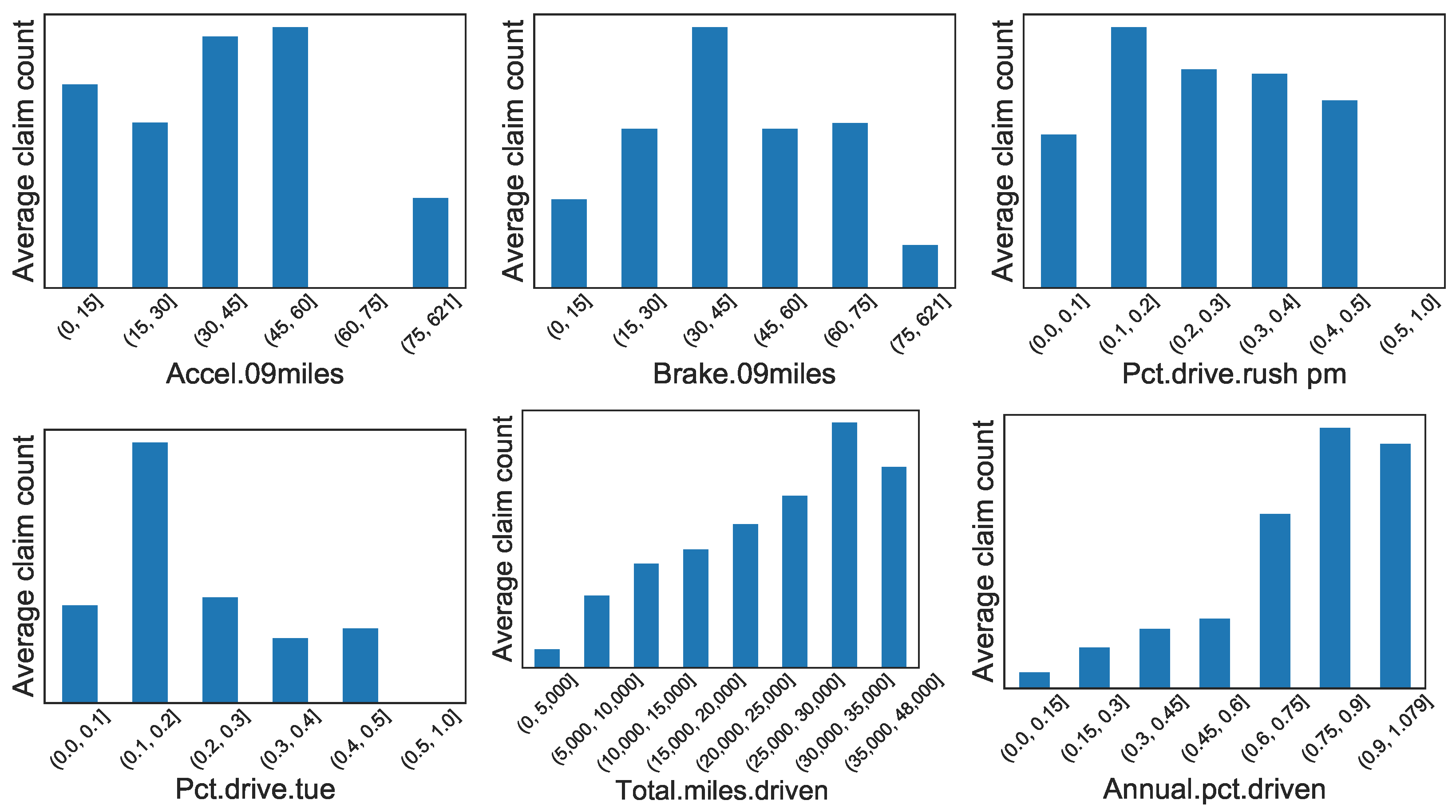
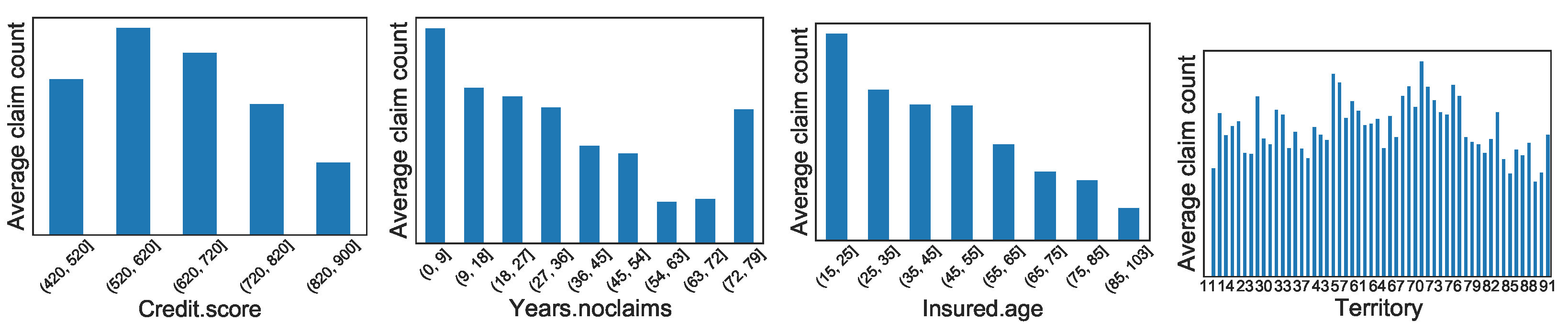
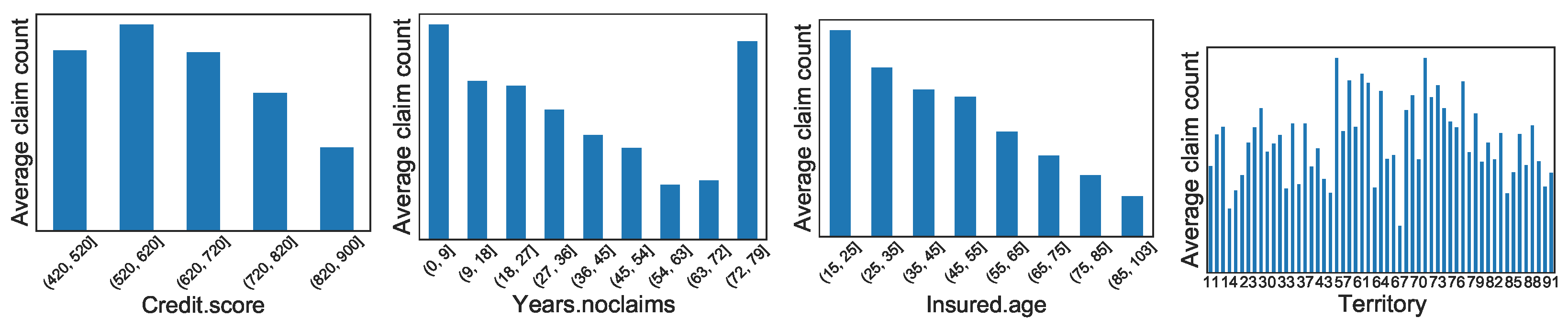
Appendix A. Graphical Display of Distributions of Selected Variables between Synthetic and Real Datasets




References
- Arik, Sercan O., Markus Kliegl, Rewon Child, Joel Hestness, Andrew Gibiansky, Chris Fougner, Ryan Prenger, and Adam Coates. 2017. Convolutional recurrent neural networks for small-footprint keyword spotting. arXiv arXiv:1703.05390. [Google Scholar]
- Ayuso, Mercedes, Montserrat Guillen, and Jens P. Nielsen. 2019. Improving automobile insurance ratemaking using telematics: Incorporating mileage and driver behaviour data. Transportation 46: 735–52. [Google Scholar] [CrossRef] [Green Version]
- Ayuso, Mercedes, Montserrat Guillén, and Ana María Pérez-Marín. 2014. Time and distance to first accident and driving patterns of young drivers with pay-as-you-drive insurance. Accident Analysis and Prevention 73: 125–31. [Google Scholar] [CrossRef] [PubMed]
- Ayuso, Mercedes, Montserrat Guillen, and Ana María Pérez-Marín. 2016. Telematics and gender discrimination: Some usage-based evidence on whether men’s risk of accidents differs from women’s. Risks 4: 10. [Google Scholar] [CrossRef] [Green Version]
- Baecke, Philippe, and Lorenzo Bocca. 2017. The value of vehicle telematics data in insurance risk selection processes. Decision Support Systems 98: 69–79. [Google Scholar] [CrossRef]
- Bansal, Trapit, David Belanger, and Andrew McCallum. 2016. Ask the GRU: Multi-task learning for deep text recommendations. arXiv arXiv:1609.02116v2. [Google Scholar]
- Bergstra, James, and Yoshua Bengio. 2012. Random search for hyper-parameter optimization. Journal of Machine Learning Research 13: 281–305. [Google Scholar]
- Bergstra, James S., Rémi Bardenet, Yoshua Bengio, Balázs Kégl, James S. Bergstra, Rémi Bardenet, Yoshua Bengio, and Balázs Kégl. 2011. Algorithms for hyper-parameter optimization. In Advances in Neural Information Processing Systems. New York: Curan Associates Inc., pp. 2546–54. [Google Scholar]
- Boucher, Jean-Philippe, Steven Côté, and Montserrat Guillen. 2017. Exposure as duration and distance in telematics motor insurance using generalized additive models. Risks 5: 54. [Google Scholar] [CrossRef] [Green Version]
- Butler, Patrick. 1993. Cost-based pricing of individual automobile risk transfer: Car-mile exposure unit analysis. Journal of Actuarial Practice 1: 51–67. [Google Scholar]
- Chawla, Nitesh V., Kevin W. Bowyer, Lawrence O. Hall, and W. Philip Kegelmeyer. 2002. SMOTE: Synthetic Minority Over-sampling Technique. Journal of Artificial Intelligence Research 16: 321–57. [Google Scholar] [CrossRef]
- Dalkilic, Turkan Erbay, Fatih Tank, and Kamile Sanli Kula. 2009. Neural networks approach for determining total claim amounts in insurance. Insurance: Mathematics and Economics 45: 236–41. [Google Scholar] [CrossRef]
- Denuit, Michel, Xavier Maréchal, Sandra Piterbois, and Jean-François Walhin. 2007. Actuarial Modelling of Claim Counts: Risk Classification, Credibility and Bonus-Malus Systems. West Sussex: John Wiley & Sons. [Google Scholar]
- Duchi, John, Elad Hazan, and Yoram Singer. 2011. Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research 12: 2121–59. [Google Scholar]
- Fernández, Alberto, Salvador Garcia, Francisco Herrera, and Nitesh V. Chawla. 2018. SMOTE for learning from imbalanced data: Progress and challenges, marking the 15-year anniversary. Journal of Artificial Intelligence Research 61: 863–905. [Google Scholar] [CrossRef]
- Franceschi, Luca, Michele Donini, Paolo Frasconi, and Massimiliano Pontil. 2017. Forward and reverse gradient-based hyperparameter optimization. Paper presented at 34th International Conference on Machine Learning, Sydney, Australia, August 6–11; pp. 1165–73. [Google Scholar]
- Gabrielli, Andrea, and Mario V. Wüthrich. 2018. An individual claims history simulation machine. Risks 6: 29. [Google Scholar] [CrossRef] [Green Version]
- Gan, Guojun, and Emiliano A. Valdez. 2007. Valuation of large variable annuity portfolios: Monte Carlo simulation and synthetic datasets. Dependence Modeling 5: 354–74. [Google Scholar] [CrossRef]
- Gan, Guojun, and Emiliano A. Valdez. 2018. Nested stochastic valuation of large variable annuity portfolios: Monte Carlo simulation and synthetic datasets. Data 3: 1–21. [Google Scholar]
- Gao, Guangyuan, Shengwang Meng, and Mario V. Wüthrich. 2019. Claim frequency modeling using telematics car driving data. Scandinavian Actuarial Journal 2: 143–62. [Google Scholar] [CrossRef]
- Goodfellow, Ian, Yoshua Bengio, and Aaron Courville. 2016. Deep Learning. Cambridge, MA: MIT Press. [Google Scholar]
- Guillen, Montserrat, Jens P. Nielsen, Ana María Pérez-Marín, and Valandis Elpidorou. 2020. Can automobile insurance telematics predict the risk of near-miss events? North American Actuarial Journal 24: 141–52. [Google Scholar] [CrossRef] [Green Version]
- Guillen, Montserrat, Jens P. Nielsen, Mercedes Ayuso, and Ana M. Pérez-Marín. 2019. The use of telematics devices to improve automobile insurance rates. Risk Analysis 39: 662–72. [Google Scholar] [CrossRef]
- Hornik, Kurt, Maxwell Stinchcombe, and Halbert White. 1989. Multilayer feedforward networks are universal approximators. Neural Networks 2: 359–66. [Google Scholar] [CrossRef]
- Husnjak, Siniša, Dragan Peraković, Ivan Forenbacher, and Marijan Mumdziev. 2015. Telmatics system in usage based motor insurance. Procedia Engineering 100: 816–25. [Google Scholar] [CrossRef] [Green Version]
- Ibiwoye, Ade, Olawale O. E. Ajibola, and Ashim B. Sogunro. 2012. Artificial neural network model for predicting insurance insolvency. International Journal of Management and Business Research 2: 59–68. [Google Scholar]
- Karapiperis, Dimitris, Birny Birnbaum, Aaron Bradenburg, Sandra Catagna, Allen Greenberg, Robin Harbage, and Anne Obersteadt. 2015. Usage-Based Insurance and Vehicle Telematics: Insurance Market and Regulatory Implications. Technical Report. Kansas City: National Association of Insurance Commissioners and The Center for Insurance Policy and Research. [Google Scholar]
- Kiermayer, Mark, and Christian Weiß. 2020. Grouping of contracts in insurance using neural networks. Scandinavian Actuarial Journal, 1–28. [Google Scholar] [CrossRef]
- Kingma, Diederik P., and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv arXiv:1412.6980. [Google Scholar]
- Li, Jing, Ji-Hang Cheng, Jing-Yuan Shi, and Fei Huang. 2012. Brief introduction of back propagation (BP) neural network algorithm and its improvement. Advances in Intelligent and Soft Computing 169: 553–58. [Google Scholar]
- Maclaurin, Dougal, David Duvenaud, and Ryan Adams. 2015. Gradient-based hyperparameter optimization through reversible learning. Paper presented at 32nd International Conference on Machine Learning, Lille, France, July 6–11; Volume 37, pp. 2113–22. [Google Scholar]
- McCulloch, Warren S., and Walter Pitts. 1943. A logical calculus of the ideas immanent in nervous activity. The Bulletin of Mathematical Biophysics 5: 115–33. [Google Scholar] [CrossRef]
- Murugan, Pushparaja. 2017. Hyperparameters optimization in deep convolutional neural network/bayesian approach with gaussian process prior. arXiv arXiv:1712.07233. [Google Scholar]
- Osafune, Tatsuaki, Toshimitsu Takahashi, Noboru Kiyama, Tsuneo Sobue, Hirozumi Yamaguchi, and Teruo Higashino. 2017. Analysis of accident risks from driving behaviors. International Journal of Intelligent Transportation Systems Research 15: 192–202. [Google Scholar] [CrossRef]
- Peng, Yifan, Anthony Rios, Ramakanth Kavuluru, and Zhiyong Lu. 2018. Chemical-protein relation extraction with ensembles of svm, cnn, and rnn models. arXiv arXiv:1802.01255. [Google Scholar]
- Pesantez-Narvaez, Jessica, Montserrat Guillen, and Manuela Alcañiz. 2019. Predicting motor insurance claims using telematics data—XGBoost versus logistic regression. Risks 7: 70. [Google Scholar] [CrossRef] [Green Version]
- Pérez-Marín, Ana M., Montserrat Guillen, Manuela Alcañiz, and Lluís Bermúdez. 2019. Quantile regression with telematics information to assess the risk of driving above the posted speed limit. Risks 7: 80. [Google Scholar] [CrossRef] [Green Version]
- Ruder, Sebastian. 2016. An overview of gradient descent optimization algorithms. arXiv arXiv:1609.04747. [Google Scholar]
- Snoek, Jasper, Hugo Larochelle, and Ryan P. Adams. 2012. Practical Bayesian optimization of machine learning algorithms. In Advances in Neural Information Processing Systems. New York: Curan Associates Inc., pp. 2951–59. [Google Scholar]
- So, Banghee, Jean-Philippe Boucher, and Emiliano A. Valdez. 2020. Cost-sensitive multi-class adaboost for understanding driving behavior with telematics. arXiv arXiv:2007.03100. [Google Scholar] [CrossRef]
- Thiede, Luca Anthony, and Ulrich Parlitz. 2019. Gradient based hyperparameter optimization in echo state networks. Neural Networks 115: 23–29. [Google Scholar] [CrossRef]
- Verbelen, Roel, Katrien Antonio, and Gerda Claeskens. 2018. Unravelling the predictive power of telematics data in car insurance pricing. Journal of the Royal Statistical Society: Series C Applied Statistics 67: 1275–304. [Google Scholar] [CrossRef] [Green Version]
- Viaene, Stijn, Guido Dedene, and Richard A. Derrig. 2005. Auto claim fraud detection using Bayesian learning neural networks. Expert Systems with Applications 29: 653–66. [Google Scholar] [CrossRef]
- Wüthrich, Mario V. 2019. Bias regularization in neural network models for general insurance pricing. European Actuarial Journal 10: 179–202. [Google Scholar] [CrossRef]
- Yan, Chun, Meixuan Li, Wei Liu, and Man Qi. 2020. Improved adaptive genetic algorithm for the vehicle insurance fraud identification model based on a bp neural network. Theoretical Computer Science 817: 12–23. [Google Scholar] [CrossRef]
- Zhang, Jingzhao, SaiPraneeth Karimireddy, Andreas Veit, Seungyeon Kim, SashankJ Reddi, Sanjiv Kumar, and Suvrit Sra. 2019. Why Adam beats SGD for attention models. arXiv arXiv:1912.03194. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Source | Reference | Sample | Period | Analytical Techniques | Research Synthesis |
|---|---|---|---|---|---|
| Belgium | Verbelen et al. (2018) | 10,406 drivers (33,259 obs.) | 2010–2014 | Poisson GAM, Negative binomial GAM | Shows that the presence of telematics variables are better important predictors of driving habits |
| Canada | So et al. (2020) | 71,875 obs. | 2013–2016 | Adaboost, SAMME.C2 | Demonstrates telematics information improves the accuracy of claims frequency prediction with a new boosting algorithm |
| China | Gao et al. (2019) | 1478 drivers | 2014.01–2017.06 | Poisson GAM | Shows the relevance of telematics covariates extracted from speed-acceleration heatmaps in a claim frequency model |
| Europe | Baecke and Bocca (2017) | 6984 drivers (<age 30) | 2011–2015 | Logistic regression, Random forests, Neural networks | Illustrates the importance of telematics variables for pricing UBI products and shows that as few as three months of data may already be enough to obtain efficient risk estimates |
| Greece | Guillen et al. (2020) | 157 drivers (1225 obs.) | 2016– 2017 | Negative binomial reg. | Demonstrates how the information drawn from telematics can help predict near-miss events |
| Japan | Osafune et al. (2017) | 809 drivers | 2013.12–2015.02 | Support Vector Machines | Investigates accident risk indices that statistically separate safe and risky drivers |
| Spain | Ayuso et al. (2014) | 15,940 drivers (<age 30) | 2009–2011 | Weibull regression | Compares driving behaviors of novice and experienced young drivers with PAYD policies |
| Ayuso et al. (2016) | 8198 drivers (<age 30) | 2009–2011 | Weibull regression | Determines the use of gender becomes irrelevant in the presence of sufficient telematics information | |
| Boucher et al. (2017) | 71,489 obs. | 2011 | Poisson GAM | Offers the benefits of using generalized additive models (GAM) to gain additional insights as to how premiums can be more dynamically assessed with telematics information | |
| Guillen et al. (2019) | 25,014 drivers (<age 40) | 2011 | Zero-inflated Poisson | Investigates how telematics information helps explain part of the occurrence of zero accidents not typically accounted by traditional risk factors | |
| Ayuso et al. (2019) | 25,014 drivers (<age 40) | 2011 | Poisson regression | Incorporates information drawn from telematics metrics into classical frequency model for tariff determination | |
| Pérez-Marín et al. (2019) | 9614 drivers (<age 35) | 2010 | Quantile regression | Demonstrates that the use of quantile regression allows for better identification of factors associated with risky drivers | |
| Pesantez-Narvaez et al. (2019) | 2767 drivers (<age 30) | 2011 | XGBoost | Examines and compares the performance of XGBoost algorithm against the traditional logistic regression |
| Type | Variable | Description |
|---|---|---|
| Traditional | Duration | Duration of the insurance coverage of a given policy, in days |
| Insured.age | Age of insured driver, in years | |
| Insured.sex | Sex of insured driver (Male/Female) | |
| Car.age | Age of vehicle, in years | |
| Marital | Marital status (Single/Married) | |
| Car.use | Use of vehicle: Private, Commute, Farmer, Commercial | |
| Credit.score | Credit score of insured driver | |
| Region | Type of region where driver lives: rural, urban | |
| Annual.miles.drive | Annual miles expected to be driven declared by driver | |
| Years.noclaims | Number of years without any claims | |
| Territory | Territorial location of vehicle | |
| Telematics | Annual.pct.driven | Annualized percentage of time on the road |
| Total.miles.driven | Total distance driven in miles | |
| Pct.drive.xxx | Percent of driving day xxx of the week: mon/tue/…/sun | |
| Pct.drive.xhrs | Percent vehicle driven within x hrs: 2hrs/3hrs/4hrs | |
| Pct.drive.xxx | Percent vehicle driven during xxx: wkday/wkend | |
| Pct.drive.rushxx | Percent of driving during xx rush hours: am/pm | |
| Avgdays.week | Mean number of days used per week | |
| Accel.xxmiles | Number of sudden acceleration 6/8/9/…/14 mph/s per 1000 miles | |
| Brake.xxmiles | Number of sudden brakes 6/8/9/…/14 mph/s per 1000 miles | |
| Left.turn.intensityxx | Number of left turn per 1000 miles with intensity 08/09/10/11/12 | |
| Right.turn.intensityxx | Number of right turn per 1000 miles with intensity 08/09/10/11/12 | |
| Response | NB_Claim | Number of claims during observation |
| AMT_Claim | Aggregated amount of claims during observation |
| Synthetic | NB_Claim | Mean | Std Dev | Min | Q1 | Median | Q3 | Max |
|---|---|---|---|---|---|---|---|---|
| AMT_Claim | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 4062 | 6767 | 0 | 670 | 2191 | 4776 | 138,767 | |
| 2 | 8960 | 9554 | 0 | 2350 | 7034 | 11,225 | 56,780 | |
| 3 | 5437 | 2314 | 2896 | 3620 | 5372 | 5698 | 9743 | |
| Real | NB_Claim | Mean | Std Dev | Min | Q1 | Median | Q3 | Max |
| AMT_Claim | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 4646 | 8387 | 0 | 659 | 2238 | 5140 | 145,153 | |
| 2 | 8643 | 10,920 | 0 | 1739 | 5184 | 11,082 | 62,259 | |
| 3 | 5682 | 2079 | 3253 | 4540 | 5416 | 5773 | 9521 |
| Category | Continuous/Integer | Percentage | Compositional |
|---|---|---|---|
| Marital | Duration | Annual.pct.driven | Pct.drive.mon |
| Insured.sex | Insured.age | Pct.drive.xhrs | Pct.drive.tue |
| Car.use | Car.age | Pct.drive.rushxx | . |
| Region | Credit.score | . | |
| Territory | Annual.miles.drive | Pct.drive.sun | |
| NB_Claim | Years.noclaims | Pct.drive.wkday | |
| Total.miles.driven | Pct.drive.wkend | ||
| Avgdays.week | |||
| Accel.xxmiles | |||
| Brake.xxmiles | |||
| Left.turn.intensityxx | |||
| Right.turn.intensityxx | |||
| AMT_Claim |
| Architecture | N.Hidden L. | N.Nodes_First Hidden L. | N.Nodes_Rest Hidden L. | Activation | BatchSize | Learning R. |
|---|---|---|---|---|---|---|
| sub-sim1 | 3 | 353 | 68 | ReLU | 85 | 0.000667 |
| sub-sim2 | 3 | 473 | 67 | ReLU | 18 | 0.001019 |
| sub-sim3 | 2 | 60 | 60 | ReLU | 16 | 0.001922 |
| Architecture | N.Hidden L. | N.Nodes_First Hidden L. | N.Nodes_Rest Hidden L. | Activation | BatchSize | Learning R. |
|---|---|---|---|---|---|---|
| 6 | 344 | 67 | ReLU | 3 | 0.000526 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
So, B.; Boucher, J.-P.; Valdez, E.A. Synthetic Dataset Generation of Driver Telematics. Risks 2021, 9, 58. https://doi.org/10.3390/risks9040058
So B, Boucher J-P, Valdez EA. Synthetic Dataset Generation of Driver Telematics. Risks. 2021; 9(4):58. https://doi.org/10.3390/risks9040058
Chicago/Turabian StyleSo, Banghee, Jean-Philippe Boucher, and Emiliano A. Valdez. 2021. "Synthetic Dataset Generation of Driver Telematics" Risks 9, no. 4: 58. https://doi.org/10.3390/risks9040058