1. Introduction
In many relevant situations, life insurers face the necessity to determine the distribution of the value of their portfolio of policies at a certain future date. This happens, for example, when regulators need to maintain solvency capital requirements in order to continue to conduct business, as stated in the Solvency II directive or in the Swiss Solvency Test. In particular, Article
of the European directive requires that the Solvency Capital Requirement “shall correspond to the Value-at-Risk of the basic own funds of an insurance or reinsurance undertaking subject to a confidence level of
over a one-year period” (see
European Parliament and European Council 2009). As a consequence, insurers are obliged to assess the value of assets and liabilities at a future date, the so-called risk horizon, in order to derive their full loss distributions. To achieve this, the relevant risk factors must be projected at the risk horizon and then, conditional on the realized values, a market consistent valuation of the insurer’s assets and liabilities is required. This has led insurance and reinsurance companies to face a computationally intensive problem. Indeed, due to the complex structure of the insurer’s liabilities, in general, closed form formulas are not available and a straightforward approach, common among insurers, is to obtain an estimate through nested Monte Carlo simulations. Unfortunately, this approach is extremely time consuming and becomes readily unmanageable from a computational point of view. In this regard, one possible alternative method proposed in the literature to reduce the computational effort and to preserve the accuracy of the desired estimates is the Least-Squares Monte Carlo (LSMC) method, firstly introduced by
Carrière (
1996);
Tilley (
1993), and
Longstaff and Schwartz (
2001) in the context of American-type Option Pricing. Application of the LSMC method for valuing solvency capital requirements in the insurance business was proposed in
Cathcart and Morrison (
2009) and
Bauer et al. (
2010). Moreover,
Floryszczak et al. (
2016) and
Krah et al. (
2018) illustrate a practical implementation of the LSMC in this particular context. The above-mentioned papers, proposed in the actuarial literature, share the common feature of evaluating capital requirements for a single policy.
In the case of an entire portfolio of policies, the nested simulation approach is even more difficult to implement due to the huge computational effort needed. For instance, assuming 10,000 outer trajectories simulated from the current time to the risk horizon for each one of the v risk factors, and then 2500 inner paths for each outer, with a monthly discretization for 20 years, and considering an insurance portfolio composed of 10,000 contracts, the total number of cash-flow projections needed would be 10,000 ×v× 2500 × 12 × 20 × 10,000 = v× 6 ×, which is very hard to manage.
In order to keep the computational complexity of the evaluation problem at a reasonable level, we propose a metamodeling approach. Metamodeling, introduced in system engineering (see
Barton 2015), can be defined as “the practice of using a model to describe another model as an instance” (see
Allemang and Hendler 2011). This approach has also been widely used in the actuarial literature to estimate the price and Greeks of large portfolios of life insurance policies. For instance,
Gan (
2013) developed a metamodel based on data clustering and machine learning to price large portfolios of variable annuities, while
Gan and Lin (
2015) tackled a similar problem by developing a functional data approach. In addition,
Gan (
2015) compares the data clustering approach and Latin hypercube sampling to select representative variable annuities. Finally,
Gan and Valdez (
2018) proposes a metamodel to estimate partial Greeks of variable annuities with dependence.
In the present paper, the metamodel we propose to approximate the future value distribution of a life insurance portfolio is constructed in different steps:
Select a subset of representative policies by means of conditional Latin hypercube sampling;
Project the risk factors from the evaluation date to the risk horizon by means of outer simulations;
Compute a rough estimate of each representative policy by means of a very limited (say two) number of inner simulations;
Create a regression model to approximate the distribution of the value of representative policies;
Use the regression model to estimate the future value distribution of the entire portfolio.
We propose two different approaches to develop the regression model in steps 4 and 5. The first approach relies upon the well-established Ordinary Least Squares (OLS) method for approximating the conditional distribution of each representative policy at the risk horizon, and then a second OLS regression is applied to estimate the future value distribution of the entire portfolio. Roughly speaking, we may say that the LSMC method is applied to estimate the distribution of the value of each representative policy at the risk horizon, and then this information is extended to the entire portfolio by means of a simple OLS regression. We call this approach the LSMC method.
The second approach exploits the class of generalized beta of the second kind (GB2) distributions to model the conditional distribution of each representative policy value at the risk horizon and also to estimate the future value distribution of the entire portfolio. We underline that the GB2 regression model has been used in
Gan and Valdez (
2018) for modeling the fair current market values of guarantees embedded in a large variable annuity portfolio starting from a set of representative policies. Extensive numerical experiments have been conducted in order to assess the performance of the proposed models. The remainder of the paper is structured as follows.
Section 2 provides the evaluation framework and
Section 3 introduces the metamodeling approach.
Section 4 illustrates some numerical results, and finally, in
Section 5, conclusions are drawn.
2. The Evaluation Framework
We consider a life insurance portfolio with
M contracts underwritten by different policyholders (males and females) of different ages at the inception date
. We take into account different types of life insurance policies which differ from each other in terms of maturity, policyholders’ ages, and sex. In particular, we consider unit-linked products, term life insurance and immediate life annuities. We assume that the unit-linked product pays, upon reaching maturity, and assuming the survival of the insured, the maximum value between the minimum guaranteed benefit and the value of a specific reference asset. The immediate life annuity is assumed to pay
of the level of a given reference asset continuously whilst the insured is alive; finally, the term insurance contract pays the total value of the asset upon the death of the policyholder before maturity. Regarding all the possible policy configurations, see
Table 1.
Since our task is to approximate the portfolio value distribution at the risk horizon starting from a set of representative policies, we use the Conditional Latin Hypercube Sampling (CLHS) method (see
Minasny and McBratney 2006). Indeed, this approach has already been applied to select subsets of representative policies providing reliable results, e.g., see
Gan and Valdez (
2018). Therefore, in order to select a set of
s representative contracts, we apply the CLHS method to the design matrix
, which contains all the features characterizing each specific policy, i.e., types, maturity, sex and age of the policyholder. Note that the categorical variables are treated as dummy variables.
In order to project the cash-flows generated by the contracts over time, we need to simulate the possible evolution of the risk factors. In this regard, we consider a computational framework where mortality, interest rate and the reference asset are taken into account. Despite insurance companies being exposed to systematic and non-systematic mortality risks, in our setting we consider only the first component for computational purposes due to the big dimension of the portfolio that will be considered.
Let
be a filtered probability space large enough to support a process
X in
, representing the evolution of financial variables, and a process
Y in
, representing the evolution of mortality. The filtration
represents the flow of information available as time passes by; this includes knowledge of the evolution of all state variables up to each time
t and of whether the policyholder has died by then. Specifically, we define
as the
-algebra generated by
, where
and where
is the joint state variables process in
. Thus, we have
, with
and with
being the smallest filtration with respect to which
is a stopping time and interpreted as the remaining lifetime of an insured. For more detail of modeling mortality under the intensity-based framework, see
Biffis (
2005).
Under the physical probability measure,
, we assume that the financial risk factors (reference asset value
S, and interest rate
r) dynamics are described by the following stochastic differential equations
where
is the risk premium,
is a positive constant,
is a standard Wiener process, and
is the risk-free interest rate, which is assumed to follow the dynamics
Here, is a standard Wiener process, and the coefficients are positive constants representing the speed of mean reversion, the long-term interest rate, and the interest rate volatility, respectively. Further, we assume that the two Wiener processes, and , are correlated with the correlation coefficient .
In the absence of arbitrage opportunities, an equivalent martingale measure
exists, under which all financial security prices are martingales after deflation by the money market account. We refer the readers to
Biffis (
2005) for more detail. Under the risk-neutral probability measure,
, the dynamics in Equations (
1) and (
2) can be re-written as
and
where
is the market price of risk. Note that
and
are two correlated standard Wiener processes with the coefficient of correlation
under
.
Concerning mortality, following
Fung et al. (
2014), we assume that the force of mortality,
, under the physical probability measure
for an individual aged
x at time
, evolves accordingly to the following one-factor, non-mean-reverting and time-homogeneous affine process:
where
represent the volatility of the mortality intensity and
is a standard Wiener process which is assumed to be independent with respect to
and
. As pointed out by
Fung et al. (
2014), the important advantages of the mortality model defined in Equation (
3) are its tractability since analytical expressions are available to evaluate survival probabilities, and also its simplicity since the model dynamics can be easily simulated. Furthermore, this model guarantees that, under specific conditions, the force of mortality is strictly positive (i.e., if
).
The dynamics in Equation (
3) under
can be defined as
where
is a standard Wiener process under the risk-neutral measure and
is the market price of the systematic mortality risk.
Note that the parameters in the stochastic mortality model are estimated by calibrating the implied survival curve to the one obtained from the Italian population data of year 2016 (assumed to be
) collected from the Human Mortality Database (see
Fung et al. 2014). The calibration procedure was conducted for all policyholder ages and genders reported in
Table 1.
Finally, it is worth noting that, due to the flexibility of the methodology that will be proposed, different and/or more complex dynamics to describe the evolution of the risk factors may be assumed with respect to the ones assumed above.
3. Problem and Methodology
Under the framework defined in
Section 2, we need to evaluate the streams of payments embedded in each policy inside the insurance portfolio. Before discussing the methodology, let us recall some results provided by
Biffis (
2005) related to the time-
fair values of the most common payoffs embedded in typical life insurance products, i.e., survival and death benefits.
Proposition 1. (Survival benefit.) Let C be a bounded -adapted process. Then, the time-τ fair value of the time-T survival benefit of amount with is given by:In particular, if C is -adapted, the following holds: Proposition 2. (Death benefit.) Let C be a bounded predictable process. Then, the time-t fair value of the death benefit of amount payable in case the insured dies before time with is given by In particular, if C is -predictable, the following holds We refer the readers to
Biffis (
2005) for the corresponding proofs and further details. Therefore, as we can see from Propositions 1 and 2, evaluating life insurance policies at future times implies solving conditional expectations for which often analytical formulas do not exist. Due to this, simulation-based approaches are extensively used (see
Boyer and Stentoft 2013), among which we mention the nested simulations method where a high number of inner simulations branch out from another huge set of outer scenarios. However, the simulations within simulations approach is computationally challenging, especially when several policies are considered, as in our case. Therefore, in the following, we are going to discuss two methodologies to evaluate the streams of payments embedded in each policy inside the insurance portfolio. For this purpose, we project the relevant risk factors affecting the policy (i.e.,
and
) under the physical probability measure from time
up to the risk horizon
, and then for each outer scenario another set of inner trajectories is simulated under the risk-neutral measure.
In order to avoid the huge computational cost of a pure nested model, as in the LSMC approach, we simulate
n possible outer trajectories of the risk factors and then for each of them we further simulate
inner paths. Following this approach, let
be an
matrix, where the row vector
contains the
kth outer scenario of the
v risk factors affecting the value of the
ith representative policy. For each vector
and for time
, we simulate
trajectories under the risk-neutral probability measure. To simplify the notation, we focus on the
ith representative policy, and we denote
the vector containing the time-
t values of the risk factors along the
jth inner trajectory corresponding to the
kth outer scenario. Moreover, we label
a
matrix where the element
represents the value of the
ith policy corresponding to the
kth outer scenario obtained by averaging across the few inner simulations. Formally,
where
s represent the discounted cash-flows at time
t of the
ith policy with maturity
.
In this way, we obtain a first (rough) estimate of each representative policy value distribution at the future time . The next step is to obtain a more accurate estimate of the distribution of the time- value of each representative policy and then to infer the distribution of the time- value of the entire portfolio. We achieve this by applying two different approaches, an OLS as in the least-squares Monte Carlo method and a GB2 model.
3.1. The LSMC Method
The least-squares Monte Carlo method applied to the problem of computing the distribution of the insurer’s liabilities at a certain future date is based on the idea that the bias deriving from the few inner simulations can be reduced by approximating the involved conditional expectations with a linear combination of basis functions depending on some covariates, whose coefficients are estimated through an ordinary least-squares procedure (see
Bauer et al. 2010 for further details).
A straightforward application of the LSMC approach would be to apply the method on each policy inside the insurance portfolio. However, this kind of strategy would be quite computationally expensive due to the big dimensions of an insurance portfolio. Due to this, we propose applying the LSMC method first on just a set of representative policies and then through an OLS regression extend it to the entire portfolio.
Hence, according to the LSMC method, we assume that the conditional
ith representative policy value,
, can be expressed as a linear combination of basis functions depending on the covariate matrix
as follows:
where
is the
jth basis function in the regression,
L is the number of basis functions, and
s represent the coefficients estimated through
In this way, we obtain an matrix where each row vector contains the values of each representative policy corresponding to the kth outer scenario.
Now, in order to approximate the distribution of the value of the entire portfolio, we construct an OLS regression model for each outer scenario. In this regard, we denote with an matrix, where the row vector contains the w covariates (gender, product type, age, and maturity) characterizing the ith contract in the portfolio plus an intercept term (M is the total number of contracts inside the insurance portfolio). Moreover, let be the matrix describing the structure of the representative insurance portfolio. Hence, contains the w covariates characterizing the ith representative contract plus an intercept term.
Therefore, we regress each row vector
(
) on the covariate matrix
, and once the coefficients are estimated, we extend them to the remaining policies by exploiting the matrix
. In this way, we obtain the value of the
ith contract corresponding to the
kth outer scenario, which is denoted by
. Formally,
where
Finally, the entire portfolio value distribution is obtained by adding up all the policy values in Equation (
6) corresponding to each outer scenario.
3.2. The GB2 Model
A GB2 model appears to provide a flexible family of distributions as it nests a range of standard distributions as special or limiting cases, such as the log-normal, the generalized-gamma, the Burr type iII, the Burr type xII and many other (see
McDonald 1984). Moreover, it has been used in several actuarial applications (e.g., see
Gan and Valdez 2018) to model the fair market value of a portfolio made up of life insurance policies. A GB2 random variable can be constructed from a transformed ratio of two gamma random variables. The density function of a GB2 random variable,
Y, is given by
where
are shape parameters,
is the scale parameter,
is the Beta function, and its expectation equals:
which exists if
.
In order to approximate the value of the portfolio, at first we approximate the time- value of each representative policy, and then we use this information to approximate the distribution of the value of the entire insurance portfolio at the risk horizon. To achieve this, we construct two different GB2 regression models which exploit the generated information at the risk horizon , and then the features characterizing uniquely each policy, respectively.
Specifically, since the policy values
obtained from Equation (
4) are not accurate due to the few inner trajectories on which they are based on, we aim at reducing the bias by estimating the involved conditional expectation through a GB2 regression model. In this regard, we assume that the
ith policy value at time
conditioned on a specific outer scenario is a GB2 random variable with parameters
. In particular, we make the
parameter depend on some independent covariates (i.e., the value at time
of the risk factors which affect the policy of interest). Note that several approaches to incorporate covariates in the GB2 regression model exist as well as different re-parametrization (see
Beirlant et al. 2004;
Frees and Valdez 2008). However, as noticed by
Sun et al. (
2008) and
Frees et al. (
2016), incorporating them into the scale parameter,
b, facilitates the interpretability of the model; indeed, as can be seen in Equation (
8), the expectation will change proportionally with respect to
b, allowing one to interpret the regression coefficients as proportional changes.
Hence, , where are the corresponding coefficients attached to each risk-factor. Note that the matrix now includes an intercept term.
We can use the maximum likelihood method to estimate the parameters. Since we incorporate covariates through the scale parameter, we can write the log-likelihood function of the model as
where
…
s,
n is the number of the generated outer scenarios and
denotes the value of the
ith policy corresponding to the
kth outer scenario.
Once we estimate the parameters for the GB2 model, we use the expectation for predicting the value of the policy at time
. Since we incorporate covariates through the scale parameter, we can estimate it as
where
is the vector containing the
kth outer scenario of the risk factors affecting the
ith representative policy.
Once we obtain an estimate of the distribution of each representative policy at time , we extend this information to the remaining policies. As already carried out for the OLS model, we are going to exploit both the matrices and on which we now construct a new GB2 regression model.
Therefore, let
be the
matrix whose elements
denote the value of the
ith representative policy corresponding to the
kth outer scenario obtained through Equation (
10).
Now, we construct a GB2 regression model in order to infer, starting from the set of representative policies, the distribution of the entire portfolio. Hence, recalling the pdf defined in Equation (
7), we define the following log-likelihood function as:
where
s is the number of the representative policies and
is the row vector containing the information of the
ith representative contract.
Once again, after we estimate the parameters through the maximum likelihood approach, we can then derive the distribution at the risk horizon for all the policies inside the insurance portfolio as
where
is the value of the
ith contract corresponding to the
kth outer scenario.
Finally, the entire portfolio value distribution is again obtained by adding up all the policy values corresponding to each outer scenario.
Note that the log-likelihood functions in Equations (
9) and (
11) may have multiple local maxima and since an analytic solution does not exist, we need to rely on a numerical procedure to estimate the involved parameters. We adopt the same multistage optimization algorithm described in
Gan and Valdez (
2018).
4. Numerical Results
In this section, we present some numerical results obtained by exploiting the previously defined models. In particular, we consider a life insurance portfolio with M = 10,000 contracts, and we focus on approximating its value distribution at the future time
year. These policies can be of three different types: a unit-linked pure endowment contract with a minimum maturity guarantee
payable upon the survival of the policyholder at the maturity date
T, term life insurance policy which pays the value of a reference asset in case of death before maturity
T, and an immediate life annuity contract with continuous survival benefits equal to the
of a reference asset value up to the entire life of the insured person. We consider different policyholders, both males and females, with different ages
x at time
, which is also assumed to be the inception time of each policy. These characteristics are reported in
Table 1. We assume that the insurance benefits depend upon a reference asset with the initial value
.
In
Table A1 and
Table A2 given in
Appendix A, we report the values of the involved parameters in Equations (
1)–(
3). In particular, concerning mortality, we have calibrated the survival curve implied by Equation (
3) on the Italian males and females mortality data in the year 2016 obtained from the Human Mortality Database for each age
, and we assumed a longevity risk premium
.
We conduct this numerical experiment by varying both the number of outer simulations,
n, and the number of representative policies,
s. In particular, we adopt a monthly Euler’s discretization setting in order to project
outer trajectories of each risk factor under the
-measure, and then for each outer scenario we further simulate
inner trajectories under the risk-neutral probability measure. With this simulation set, we are able to obtain a first rough estimate of
on which we construct the LSMC and GB2 models discussed in
Section 3.1 and
Section 3.2, respectively. Note that, concerning the LSMC method, we exploit as basis functions Hermite polynomials of orders 1 and 2, which are denoted, respectively, as LSMC_1 and LSMC_2 hereafter.
To determine the number of representative contracts
s, we start from the informal rule proposed by
Loeppky et al. (
2009), which provide reasons and evidence supporting that the sample size should be about 10 times the input dimension. In our case, the dimension of covariates in the design matrix
is 5 (including the binary dummy variables converted from the categorical variables), and so we choose
as the initial number of representative contracts. However, we investigate the models’ performances by setting
and
.
Finally, the results are compared with a solid benchmark obtained through a nested simulations approach based on 10,000 × 2500 simulations. This allows us to conclude on the reliability of the proposed methodologies and to compare them in terms of computational demand.
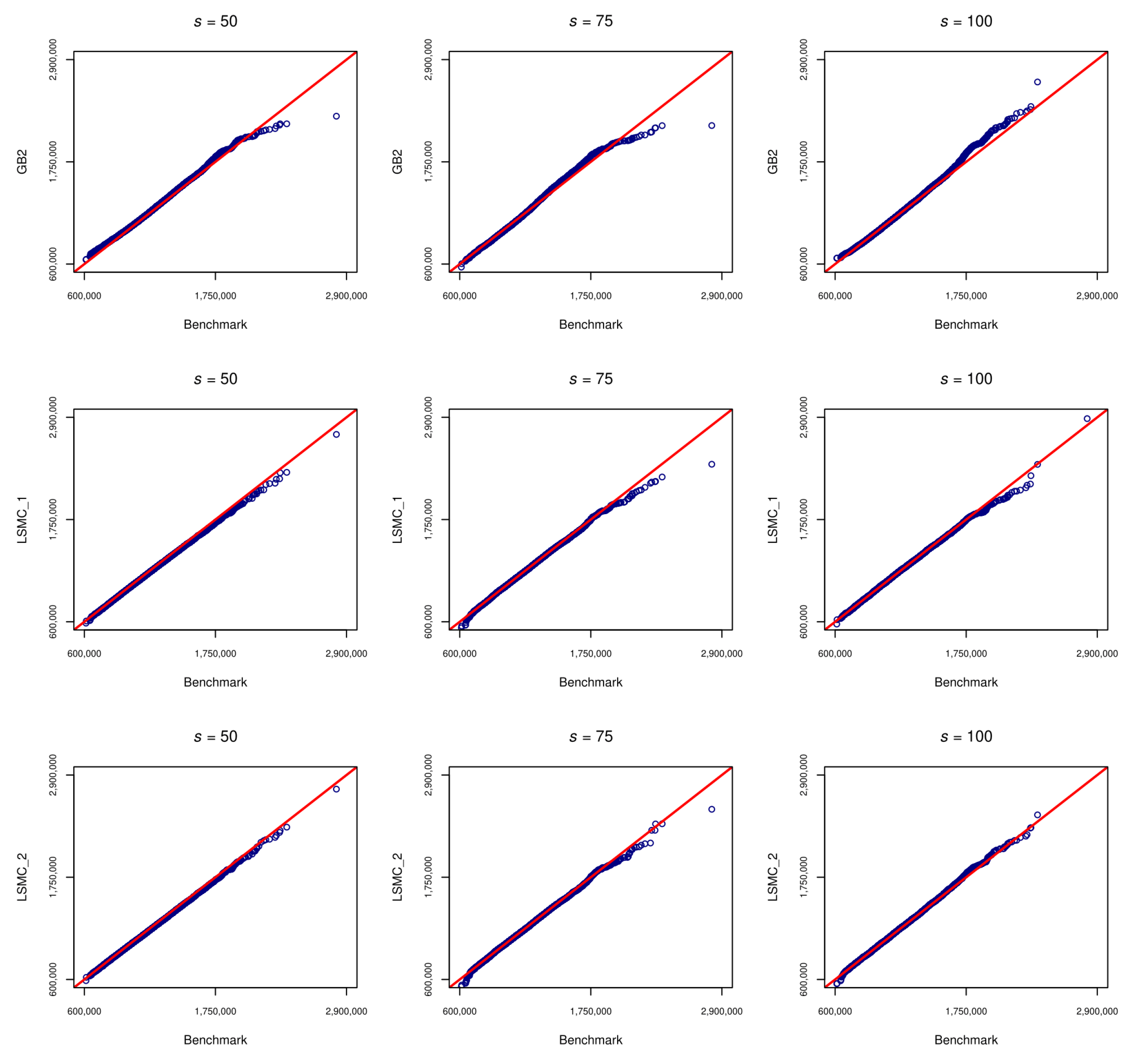
Figure 1 shows the Quantile-Quantile (Q-Q) plots of the portfolio value at time
obtained by the nested simulations algorithm (assumed to be the theoretical one) and those predicted by the GB2 regression model and the LSMC models based on
n = 10,000 outer simulations and by varying the number of representative contracts
. In this regard, we can see from
Figure 1 that the proposed methodologies provide a good approximation except for the right tail of the distribution. In particular, concerning the GB2 regression model, we can see that the higher the number of representative contracts, the better the approximation.
For a comprehensive analysis, we perform multiple runs of each proposed method; in particular, the following analysis is based on 50 runs.
In
Table 2,
Table 3 and
Table 4, we report the Mean Absolute Percentage Error (MAPE) relative to different quantities obtained by performing 50 runs of the proposed methodologies with a fixed number of outer scenarios (
n = 10,000) and by varying the number of representative contracts
.
If we compare
Table 2,
Table 3 and
Table 4, it is evident that increasing the number of representative contracts
s leads to a better approximation of the mean and of the other considered measures of position. Moreover, it seems that the GB2 model, at least for a low number of representative contracts, is not able to adequately model the right tail of the distribution.
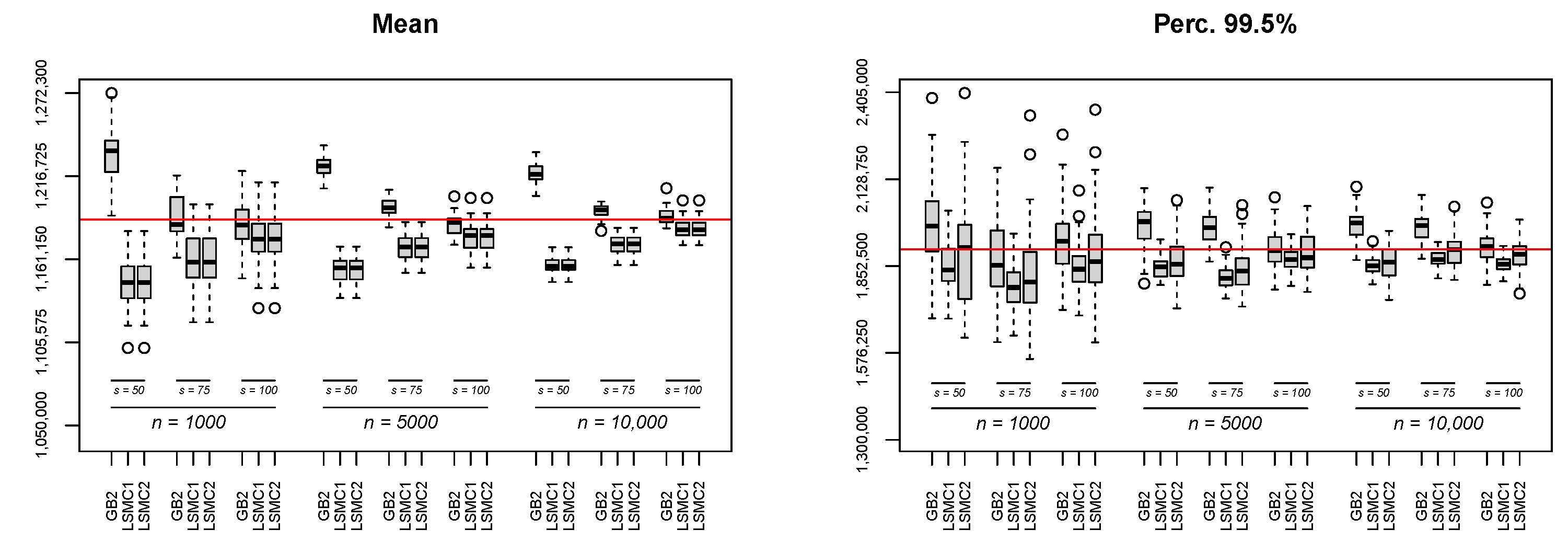
In
Table 5, we report the Mean Percentage Error (MPE) and MAPE relative to the mean estimates obtained by running the GB2 and LSMC methods 50 times with different numbers of outer simulations,
n, and representative contracts,
s.
Looking at
Table 5, we can see that for a fixed number of outer scenarios and for each applied method, the accuracy of the mean estimates increases with the number of representative contracts
s. Moreover, it is evident that in most of the considered configurations, the GB2 model outperforms the LSMC methods. Furthermore, if we look at the last column of
Table 5 (
), for instance, we can see that the higher the number of outer scenarios, the better the approximation. Finally, we can see that increasing the number of basis functions up to degree two in the LSMC method does not improve the accuracy of the mean estimates. This is probably due to the few outer simulated trajectories (at most 10,000 paths), which is not sufficient to appreciate the improvement which is usually expected. In the left-hand side of
Figure A1 given in
Appendix B, we report the corresponding box-plots from which it is possible to see that, in each of the considered configurations, the LSMC method systematically underestimates the quantity of interest.
Concerning the estimate of the
th percentile of the distribution, which would be of interest for valuing solvency capital requirements,
Table 6 reports the MPE and MAPE relative to 50 estimates obtained by varying both the number of simulations and the number of representative contracts.
From
Table 6, we can detect a similar behaviour as the one previously discussed. Specifically, we can see that, concerning the GB2 model, an increase in the number of representative contracts (for fixed
n) leads to an improvement of the resulting estimates. On the contrary, for the LSMC method, there is no clear pattern. Indeed, as we can see, increasing the number of representative contracts (for a fixed
n) does not lead to a clear improvement in the results. Moreover, increasing the number of basis functions as well as the number of outer simulations does not increase the accuracy of the estimates (see also the right side of
Figure A1 in
Appendix B). As in the case of the mean estimate, this could be due to the small number of outer simulations, and so we may conclude that passing from 1000 to 10,000 trajectories is still not sufficient to exploit more basis functions. Once again, if we look at the case of
n = 10,000 and
, the GB2 model outperforms the LSMC approach.
Now, let us examine the speed of the proposed algorithms with respect to the benchmark.
Table 7 shows the runtime of GB2 and LSMC expressed as a percentage of the time required by the nested simulation method based on 10,000 outers and 2500 inners. Note that we conducted all experiments using
R on a computer equipped with an Intel
® Core(TM) i7-1065G7 CPU 1.50 GHz processor with 12 GB of RAM and Windows 10 Home operating system.
As we can see from
Table 7, by applying the proposed methodologies, we have drastically reduced the computational time required instead by a nested simulations approach. Moreover, as expected, the LSMC method presented in
Section 3.1 outperforms the GB2 model in terms of time in each of the proposed configurations. However, this is due to the existence of a closed form formula for the estimation of the involved parameters. Indeed, as stated in
Section 3.2, the estimation procedure for the GB2 model is based on a multistage optimization algorithm due to the complexity of the likelihood functions, which may have multiple local maxima. Regardless, if compared with the simulations within simulations method, the GB2 model proved to be an accurate and efficient alternative.
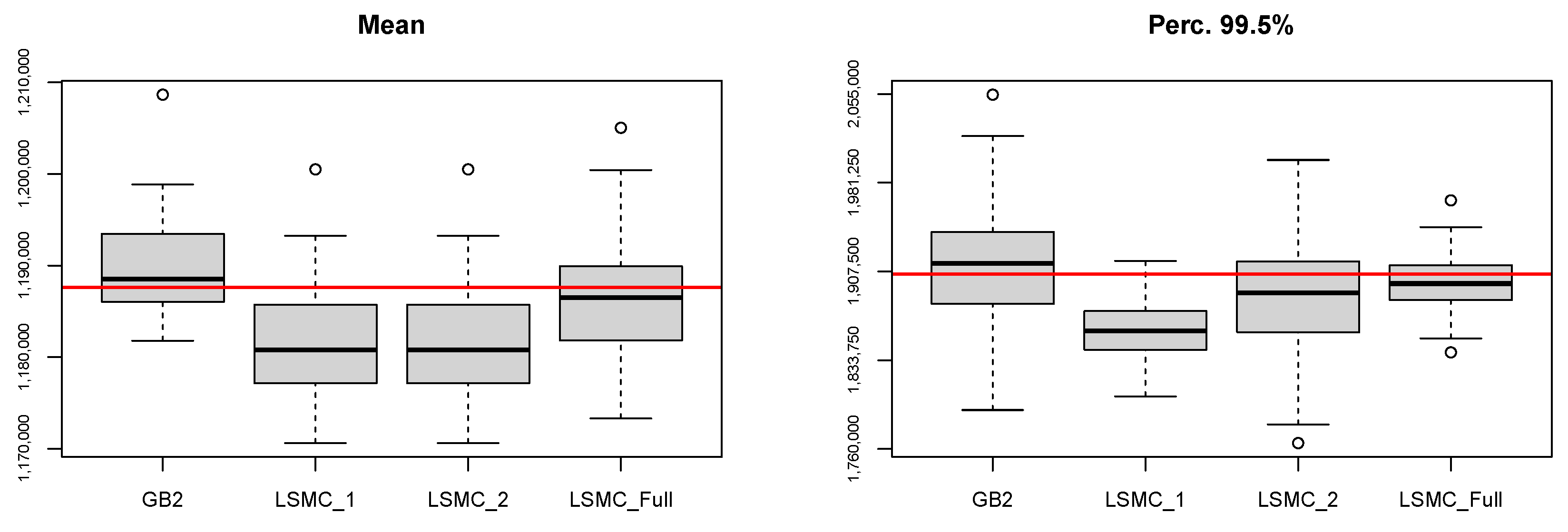
Full LSMC
To provide an exhaustive analysis, we consider a straightforward application of the LSMC method. Hence, we apply the LSMC method on each contract composing the insurance portfolio without considering any set of representative policies. The results are then compared with those already shown in the previous section both in terms of accuracy and computational demand. Just as an example, we construct the LSMC model by exploiting as set of basis functions Hermite polynomials with order 1 based on 10,000 × 2 simulations (LSMC_Full).
Table 8 reports the MPE and MAPE relative to the 5th-percentile, the mean, and the 99.5th percentile estimates obtained by performing 50 runs of the proposed methods. Further, we report the results relative to the GB2 model (GB2) and LSMC method with Hermite polynomials of order 1 (LSMC_1) and order 2 (LSMC_2) based on 10,000 × 2 simulations and
representative policies.
As is shown in
Table 8, the errors relative to the LSMC_Full approach are lower than those of the other proposed methods since the estimates are based on the entire insurance portfolio, i.e., this approach does not suffer of any uncertainty related to the missingness of policies in its estimation procedure.
Figure A1 given in
Appendix B reports the box-plots on which the quantities in
Table 8 are based on.
Finally, we compare these methods in terms of time. In
Table 9, we report the computational time required by the algorithms. We can see that the naive application of the LSMC approach is more computationally expensive with respect to the GB2 and LSMC models based on a set of representative policies.
5. Conclusions
In this paper, we addressed the problem of approximating the value of a life insurance portfolio at a future time by proposing two different methodologies able to avoid the time-consuming nested simulations approach. The first approach can be thought of as extension of the well-known LSMC method, while the second is based on the GB2 distribution, which is widely used to approximate the fair value of portfolios of life insurance policies. To validate the proposal, we have considered a solid benchmark obtained by nested simulations, and we compared the two proposed methodologies both in terms of accuracy and efficiency. The analysis has been carried out by considering an ever increasing number of simulations and representative policies, from which it turned out that, generally, both the methodologies are able to provide increasingly accurate results. Moreover, the LSMC method proved to be faster in computational terms but also less accurate than the GB2 model. Furthermore, the proposed methodologies have been compared with a straightforward application of the LSMC method (i.e., without considering any subset of representative policies), which turned out to be more accurate but computationally more expensive.
Extensive numerical results have shown that the proposed methods represent viable alternatives to the full nested Monte Carlo model. Therefore, the proposed metamodeling approach may help insurance and reinsurance undertakings to reduce the computational budget needed, for instance, in the context of evaluating solvency capital requirements. In this regard, it can be used to evaluate the future cash-flows (inflows and outflows) generated by the entire portfolio by considering at first only a subset of policies, and then extend to the remaining ones. Indeed, this represents the main issue for deriving the full loss distribution on which the Value-at-Risk measure should be obtained, as prescribed by the European Solvency II directive.




{kind=link}
{kind=link}
{kind=link}


