Machine Learning in P&C Insurance: A Review for Pricing and Reserving


Abstract
:1. Introduction
1.1. Research Methodology
- Query research databases (Google Scholar, ProQuest, SSRN, arXiv, ResearchGate) for a combination of machine learning keywords (machine learning, data science, decision tree (DT), classification and regression trees (CART), neural network (NN) convolutional neural networks (CNN), recurrent neural networks (RNN), random forest (RF), gradient boosting (GBM/GBT/XGBoost), generalized additive model (GAM, GAMLSS), support vector machine (SVM, SVR, SVC), principal component analysis (PCA), autoencoders (AE), computer science) AND the subjects of interest in our review (actuarial science, general insurance, home insurance, auto insurance, P&C insurance, ratemaking, reserving).
- Query actuarial journals (in no particular order, Risks, ASTIN Bulletin, Insurance: Mathematics and Economics (IME), Scandinavian Actuarial Journal (SAJ), Variance, North American Actuarial Journal (NAAJ), European Actuarial Journal (EAJ)).
- For each pertinent article, we searched references therein for similar contributions.
1.2. Scope of This Review and Similar Work
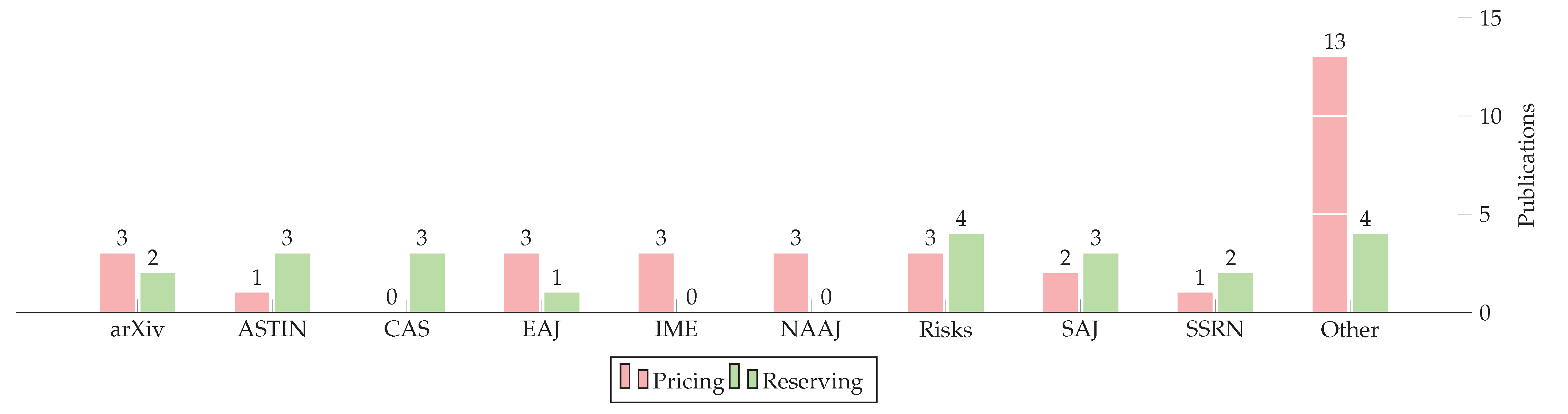
1.3. Generalized Data on This Review
2. Neural Networks
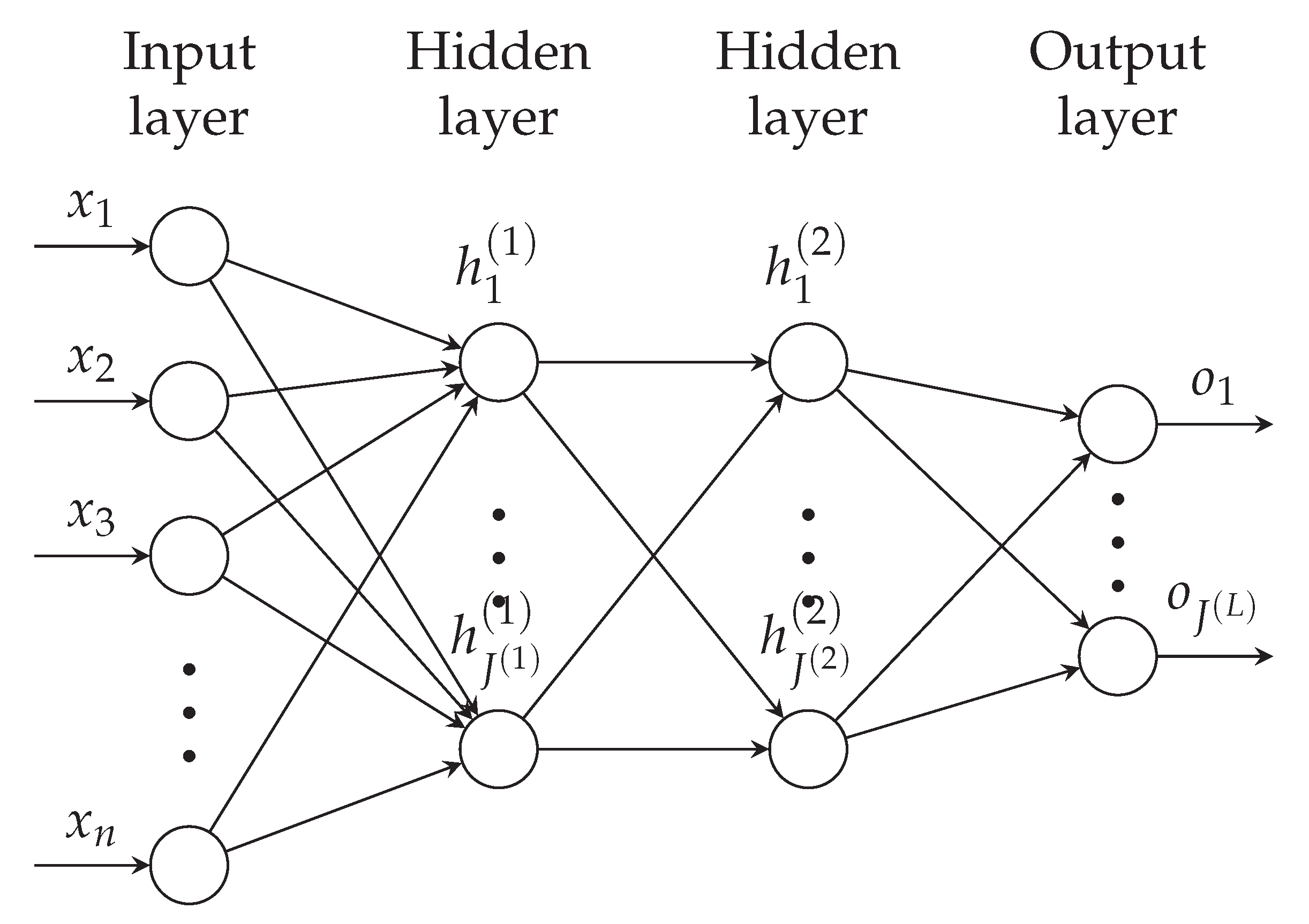
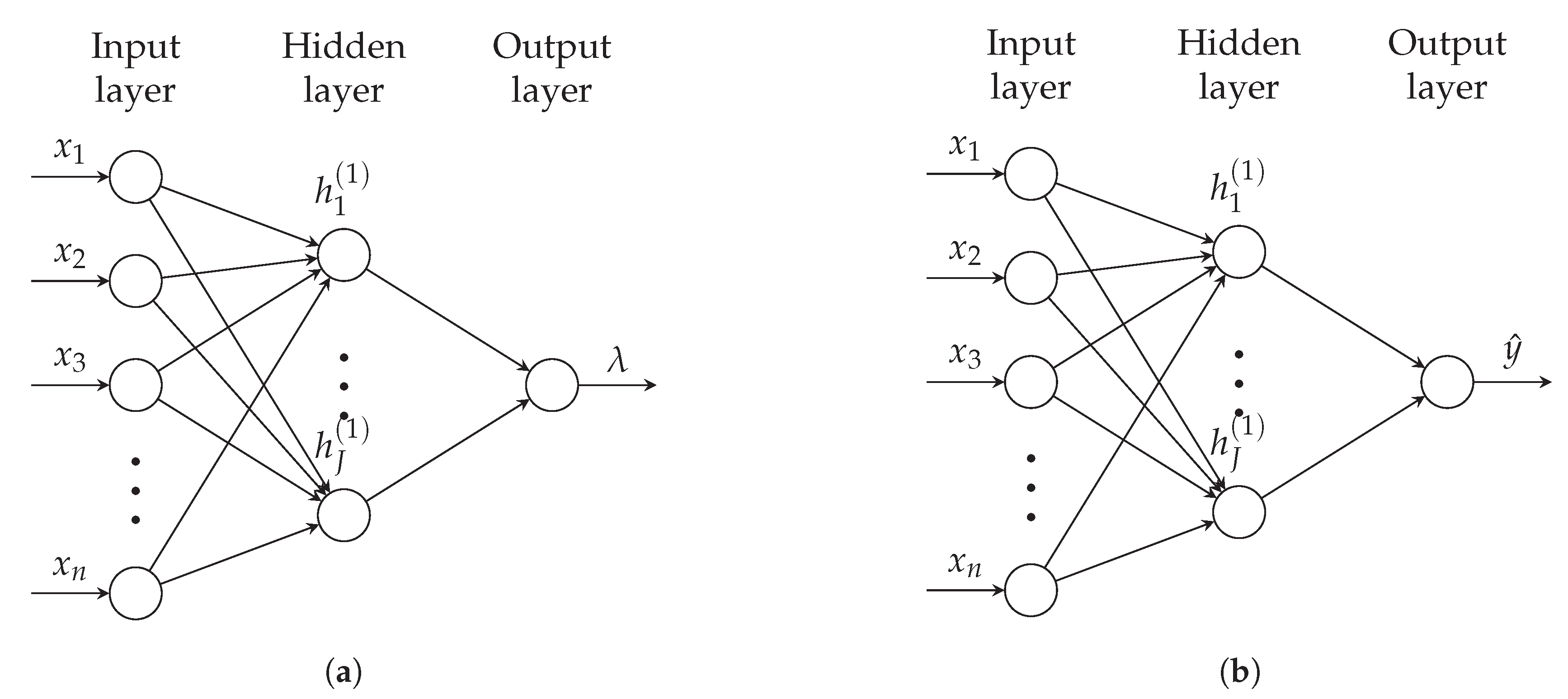
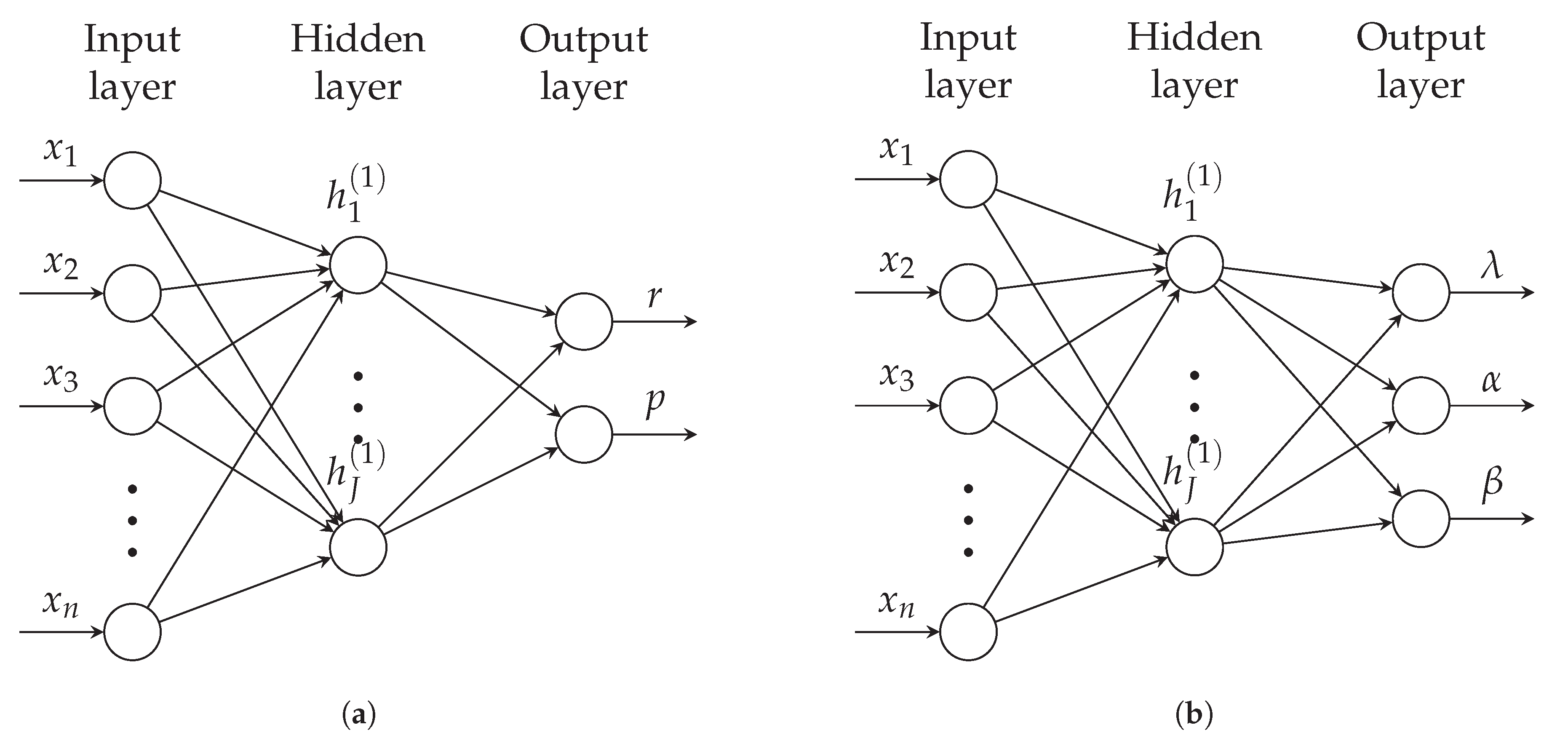
2.1. Basics and Notation
2.2. Estimating Probability Distribution Parameters with Neural Networks
3. Pricing with Machine Learning
3.1. Conventional Pricing
3.2. Neural Pricing
3.3. Telematics Pricing
3.3.1. Pay-as-You-Drive
- be proportional to the expected loss;
- be practical (objective and inexpensive to obtain and verify);
- consider preexisting exposure base established within the industry.
3.3.2. Pay-How-You-Drive
3.4. Outlook on Pricing
4. Reserving with Machine Learning
4.1. Aggregate Reserving
- aggregation of multiple claims at the portfolio level or other grouping types if the actuary believes that development patterns are heterogeneous within the portfolio;
- aggregation of continuous-time into interval time, usually yearly, quarterly or monthly.
4.2. Neural Aggregate Reserving
4.3. Individual Reserving
- claim status (open, close, reopen), a classification task;
- activity status (presence of claim or change in case reserve indicator during the period), a classification task;
- individual payment value or change in case reserve value conditional on the presence of claim during the period, a regression task;
- involvement of lawyers or doctors, a classification task.
4.4. Neural Individual Reserving
4.5. Outlook on Reserving
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| AVB | adversarial variational Bayes |
| CART | classification and regression trees |
| DT | decision tree |
| EF | exponential family |
| GAM | generalized additive model |
| GBM | gradient boosting machine |
| GBT | gradient boosted trees |
| GLM | generalized linear model |
| knn | k-nearest neighbour |
| LDA | linear discriminant analysis |
| LR | logistic regression |
| NB | naïve Bayes |
| NLL | negative log-likelihood |
| NN | neural network |
| P&C | property and casualty |
| RF | random forest |
| RNN | recurrent neural network |
| SVM | support vector machine |
| SVR | support vector regression |
| SVC | support vector classifier |
References
- Albrecher, Hansjörg, Antoine Bommier, Damir Filipović, Pablo Koch-Medina, Stéphane Loisel, and Hato Schmeiser. 2019. Insurance: Models, digitalization, and data science. European Actuarial Journal 9: 349–60. [Google Scholar] [CrossRef]
- Asimit, Vali, Ioannis Kyriakou, and Jens Perch Nielsen. 2020. Special issue “Machine Learning in Insurance”. Risks 8: 54. [Google Scholar] [CrossRef]
- Ayuso, Mercedes, Montserrat Guillén, and Ana María Pérez-Marín. 2014. Time and distance to first accident and driving patterns of young drivers with pay-as-you-drive insurance. Accident Analysis & Prevention 73: 125–31. [Google Scholar] [CrossRef]
- Barry, Laurence. 2019. Insurance, big data and changing conceptions of fairness. European Journal of Sociology/Archives Européennes de Sociologie, 1–26. [Google Scholar] [CrossRef]
- Barry, Laurence, and Arthur Charpentier. 2020. Personalization as a promise: Can big data change the practice of insurance? Big Data & Society 7. [Google Scholar] [CrossRef]
- Baudry, Maximilien, and Christian Y. Robert. 2019. A machine learning approach for individual claims reserving in insurance. Applied Stochastic Models in Business and Industry. [Google Scholar] [CrossRef]
- Benidis, Konstantinos, Syama Sundar Rangapuram, Valentin Flunkert, Bernie Wang, Danielle Maddix, Caner Turkmen, Jan Gasthaus, Michael Bohlke-Schneider, David Salinas, Lorenzo Stella, and et al. 2020. Neural forecasting: Introduction and literature overview. arXiv arXiv:2004.10240. [Google Scholar]
- Blesa, Angel, David Íñiguez, Rubén Moreno, and Gonzalo Ruiz. 2020. Use of open data to improve automobile insurance premium rating. International Journal of Market Research 62: 58–78. [Google Scholar] [CrossRef]
- Blier-Wong, Christopher, Jean-Thomas Baillargeon, Hélène Cossette, Luc Lamontagne, and Etienne Marceau. 2020. Encoding neighbor information into geographical embeddings using convolutional neural networks. Paper presented at Thirty-Third International Flairs Conference, North Miami Beach, FL, USA, May 17–20. [Google Scholar]
- Bothwell, Peter T., Mary Jo Kannon, Benjamin Avanzi, Joseph Marino Izzo, Stephen A. Knobloch, Raymond S. Nichols, James L. Norris, Ying Pan, Dimitri Semenovich, Tracy A. Spadola, and et al. 2016. Data & Technology Working Party Report. Technical Report. Arlington: Casualty Actuarial Society. [Google Scholar]
- Boucher, Jean-Philippe, Steven Côté, and Montserrat Guillen. 2017. Exposure as duration and distance in telematics motor insurance using generalized additive models. Risks 5: 54. [Google Scholar] [CrossRef] [Green Version]
- Boucher, Jean-Philippe, Ana Maria Pérez-Marín, and Miguel Santolino. 2013. Pay-As-You-Drive insurance: The effect of the kilometers on the risk of accident. In Anales del Instituto de Actuarios Españoles. Madrid: Instituto de Actuarios Españoles, vol. 19, pp. 135–54. [Google Scholar]
- Bruer, Michaela, Frank Cuypers, Pedro Fonseca, Louise Francis, Oscar Hu, Jason Paschalides, Thomas Rampley, and Raymond Wilson. 2015. ASTIN Big Data/Data Analytics Working Party. Phase 1 paper; Technical report. April. Available online: https://www.actuaries.org/ASTIN/Documents/ASTIN_Data_Analytics_Final_20150518.pdf (accessed on 19 July 2019).
- Carrato, Alessandro, and Michele Visintin. 2019. From the chain ladder to individual claims reserving using machine learning techniques. Paper presented at ASTIN Colloquium, Cape Town, South Africa, April 2–5; vol. 1, pp. 1–19. [Google Scholar]
- Castignani, German, Thierry Derrmann, Raphaël Frank, and Thomas Engel. 2015. Driver behavior profiling using smartphones: A low-cost platform for driver monitoring. IEEE Intelligent Transportation Systems Magazine 7: 91–102. [Google Scholar] [CrossRef]
- Casualty Actuarial Society, and Committee on Ratemaking Principles. 1988. Statement of Principles Regarding Property and Casualty Insurance Ratemaking. Arlington: Casualty Actuarial Society Committee on Ratemaking Principles. [Google Scholar]
- Cevolini, Alberto, and Elena Esposito. 2020. From pool to profile: Social consequences of algorithmic prediction in insurance. Big Data & Society 7. [Google Scholar] [CrossRef]
- Chapados, Nicolas, Yoshua Bengio, Pascal Vincent, Joumana Ghosn, Charles Dugas, Ichiro Takeuchi, and Linyan Meng. 2002. Estimating car insurance premia: A case study in high-dimensional data inference. In Advances in Neural Information Processing Systems. Cambridge: The MIT Press, pp. 1369–76. [Google Scholar]
- Chen, Kuan-Ting, and Huei-Yen Winnie Chen. 2019. Driving style clustering using naturalistic driving data. Transportation Research Record 2673: 176–88. [Google Scholar] [CrossRef]
- Christmann, Andreas. 2004. An approach to model complex high—Dimensional insurance data. Allgemeines Statistisches Archiv 88: 375–96. [Google Scholar] [CrossRef]
- Corlosquet-Habart, Marine, and Jacques Janssen. 2018. Big Data for Insurance Companies. Hoboken: John Wiley & Sons. [Google Scholar] [CrossRef]
- Crevecoeur, Jonas, and Katrien Antonio. 2020. A hierarchical reserving model for reported non-life insurance claims. arXiv arXiv:1910.12692. [Google Scholar]
- Côté, Marie-Pier, Brian Hartman, Olivier Mercier, Joshua Meyers, Jared Cummings, and Elijah Harmon. 2020. Synthesizing property & casualty ratemaking datasets using generative adversarial networks. arXiv arXiv:2008.06110. [Google Scholar]
- De Felice, Massimo, and Franco Moriconi. 2019. Claim watching and individual claims reserving using classification and regression trees. Risks 7: 102. [Google Scholar] [CrossRef] [Green Version]
- Delong, Lukasz, Mathias Lindholm, and Mario V Wuthrich. 2020. Collective Reserving Using Individual Claims Data. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3582398 (accessed on 15 August 2020).
- Deng, Kan. 1998. Omega: On-Line Memory-Based General Purpose System Classifier. Ph. D. thesis, Carnegie Mellon University, Pittsburgh, PA, USA. [Google Scholar]
- Denuit, Michel, Donatien Hainaut, and Julien Trufin. 2019a. Effective Statistical Learning Methods for Actuaries I. Berlin and Heidelberg: Springer. [Google Scholar] [CrossRef]
- Denuit, Michel, Donatien Hainaut, and Julien Trufin. 2019b. Effective Statistical Learning Methods for Actuaries II. Berlin and Heidelberg: Springer. [Google Scholar] [CrossRef]
- Denuit, Michel, Donatien Hainaut, and Julien Trufin. 2019c. Effective Statistical Learning Methods for Actuaries III. Berlin and Heidelberg: Springer. [Google Scholar] [CrossRef]
- Denuit, Michel, and Stefan Lang. 2004. Non-life rate-making with Bayesian GAMs. Insurance: Mathematics and Economics 35: 627–47. [Google Scholar] [CrossRef]
- Diana, Alex, Jim E. Griffin, Jaideep Oberoi, and Ji Yao. 2019. Machine-Learning Methods for Insurance Applications: A Survey. Schaumburg: Society of Actuaries. [Google Scholar]
- Diao, Liqun, and Chengguo Weng. 2019. Regression tree credibility model. North American Actuarial Journal 23: 169–96. [Google Scholar] [CrossRef]
- Dugas, Charles, Yoshua Bengio, Nicolas Chapados, Pascal Vincent, Germain Denoncourt, and Christian Fournier. 2003. Statistical Learning Algorithms Applied to Automobile Insurance Ratemaking. Arlington: Casualty Actuarial Society Forum, pp. 179–213. [Google Scholar]
- England, Peter D., and Richard J. Verrall. 2001. A Flexible Framework for Stochastic Claims Reserving. Arlington: Casualty Actuarial Society, vol. 88, pp. 1–38. [Google Scholar]
- Fallah, Nader, Hong Gu, Kazem Mohammad, Seyyed Ali Seyyedsalehi, Keramat Nourijelyani, and Mohammad Reza Eshraghian. 2009. Nonlinear Poisson regression using neural networks: A simulation study. Neural Computing and Applications 18: 939. [Google Scholar] [CrossRef]
- Fauzan, Muhammad Arief, and Hendri Murfi. 2018. The accuracy of XGBoost for insurance claim prediction. International Journal of Advances in Soft Computing & Its Applications 10: 159–71. [Google Scholar]
- Ferrario, Andrea, and Roger Hämmerli. 2019. On Boosting: Theory and Applications. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3402687 (accessed on 15 August 2020).
- Ferrario, Andrea, Alexander Noll, and Mario V. Wuthrich. 2018. Insights from Inside Neural Networks. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3226852 (accessed on 15 August 2020).
- Ferreira, Jair, Eduardo Carvalho, Bruno V Ferreira, Cleidson de Souza, Yoshihiko Suhara, Alex Pentland, and Gustavo Pessin. 2017. Driver behavior profiling: An investigation with different smartphone sensors and machine learning. PLoS ONE 12: e0174959. [Google Scholar] [CrossRef] [PubMed]
- Fontaine, Simon, Yi Yang, Wei Qian, Yuwen Gu, and Bo Fan. 2019. A unified approach to sparse Tweedie modeling of multisource insurance claim data. Technometrics, 1–18. [Google Scholar] [CrossRef]
- Francis, Louise. 2001. Neural Networks Demystified. Arlington: Casualty Actuarial Society Forum, pp. 253–320. [Google Scholar]
- Frees, Edward W., Richard A. Derrig, and Glenn Meyers. 2014a. Predictive Modeling Applications in Actuarial Science. Cambridge: Cambridge University Press, vol. 1. [Google Scholar]
- Frees, Edward W., Richard A. Derrig, and Glenn Meyers. 2014b. Predictive Modeling Applications in Actuarial Science. Cambridge: Cambridge University Press, vol. 2. [Google Scholar]
- Frezal, Sylvestre, and Laurence Barry. 2019. Fairness in uncertainty: Some limits and misinterpretations of actuarial fairness. Journal of Business Ethics, 1–10. [Google Scholar] [CrossRef]
- Friedman, Jerome, Trevor Hastie, and Robert Tibshirani. 2001. The Elements of Statistical Learning. New York: Springer Series in Statistics, vol. 1. [Google Scholar]
- Friedman, Jerome H., and Bogdan E. Popescu. 2008. Predictive learning via rule ensembles. The Annals of Applied Statistics 2: 916–54. [Google Scholar] [CrossRef]
- Fung, Tsz Chai, Andrei L. Badescu, and X. Sheldon Lin. 2019a. A class of mixture of experts models for general insurance: Application to correlated claim frequencies. ASTIN Bulletin: The Journal of the IAA 49: 647–88. [Google Scholar] [CrossRef]
- Fung, Tsz Chai, Andrei L. Badescu, and X. Sheldon Lin. 2019b. A class of mixture of experts models for general insurance: Theoretical developments. Insurance: Mathematics and Economics 89: 111–27. [Google Scholar] [CrossRef]
- Fung, Tsz Chai, Andrei L. Badescu, and X. Sheldon Lin. 2020. A new class of severity regression models with an application to IBNR prediction. North American Actuarial Journal, 1–26. [Google Scholar] [CrossRef]
- Gabrielli, Andrea. 2020a. An Individual Claims Reserving Model for Reported Claims. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3612930 (accessed on 15 August 2020).
- Gabrielli, Andrea. 2020b. A neural network boosted double overdispersed Poisson claims reserving model. ASTIN Bulletin: The Journal of the IAA 50: 25–60. [Google Scholar] [CrossRef]
- Gabrielli, Andrea, Ronald Richman, and Mario V. Wüthrich. 2019. Neural network embedding of the over-dispersed Poisson reserving model. Scandinavian Actuarial Journal. [Google Scholar] [CrossRef]
- Gabrielli, Andrea, and Mario Wüthrich. 2018. An individual claims history simulation machine. Risks 6: 29. [Google Scholar] [CrossRef] [Green Version]
- Gao, Guangyuan, Shengwang Meng, and Mario V. Wüthrich. 2018. Claims frequency modeling using telematics car driving data. Scandinavian Actuarial Journal, 1–20. [Google Scholar] [CrossRef]
- Gao, Guangyuan, He Wang, and Mario V. Wuthrich. 2020. Boosting Poisson Regression Models with Telematics Car Driving Data. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3596034 (accessed on 15 August 2020).
- Gao, Guangyuan, and Mario V. Wüthrich. 2018. Feature extraction from telematics car driving heatmaps. European Actuarial Journal 8: 383–406. [Google Scholar] [CrossRef]
- Gao, Guangyuan, and Mario V. Wüthrich. 2019. Convolutional neural network classification of telematics car driving data. Risks 7: 6. [Google Scholar] [CrossRef] [Green Version]
- Gao, Guangyuan, Mario V. Wüthrich, and Hanfang Yang. 2019. Evaluation of driving risk at different speeds. Insurance: Mathematics and Economics 88: 108–19. [Google Scholar] [CrossRef]
- Giles, C Lee, Steve Lawrence, and Ah Chung Tsoi. 1997. Rule inference for financial prediction using recurrent neural networks. In Proceedings of the IEEE/IAFE 1997 Computational Intelligence for Financial Engineering (CIFEr). Piscataway: IEEE, pp. 253–59. [Google Scholar] [CrossRef]
- Goodfellow, Ian, Yoshua Bengio, and Aaron Courville. 2016. Deep Learning. Cambridge: MIT Press. [Google Scholar]
- Grize, Yves-Laurent, Wolfram Fischer, and Christian Lützelschwab. 2020. Machine learning applications in nonlife insurance. Applied Stochastic Models in Business and Industry. [Google Scholar] [CrossRef]
- Guelman, Leo. 2012. Gradient boosting trees for auto insurance loss cost modeling and prediction. Expert Systems with Applications 39: 3659–67. [Google Scholar] [CrossRef]
- Harej, Bor, R. Gächter, and S. Jamal. 2017. Individual Claim Development with Machine Learning. Report of the ASTIN Working Party of the International Actuarial Association. Available online: http://www.actuaries.org/ASTIN/Documents/ASTIN_ICDML_WP_Report_final.pdf (accessed on 19 July 2019).
- Henckaerts, Roel, Katrien Antonio, Maxime Clijsters, and Roel Verbelen. 2018. A data driven binning strategy for the construction of insurance tariff classes. Scandinavian Actuarial Journal 2018: 681–705. [Google Scholar] [CrossRef] [Green Version]
- Henckaerts, Roel, Katrien Antonio, and Marie-Pier Côté. 2020. Model-agnostic interpretable and data-driven surrogates suited for highly regulated industries. arXiv arXiv:2007.06894. [Google Scholar]
- Henckaerts, Roel, Marie-Pier Côté, Katrien Antonio, and Roel Verbelen. 2020. Boosting insights in insurance tariff plans with tree-based machine learning methods. North American Actuarial Journal, 1–31. [Google Scholar] [CrossRef]
- Hu, Sen, T. Brendan Murphy, and Adrian O’Hagan. 2019. Bivariate gamma mixture of experts models for joint insurance claims modeling. arXiv arXiv:1904.04699. [Google Scholar]
- Hu, Sen, Adrian O’Hagan, and Thomas Brendan Murphy. 2018. Motor insurance claim modelling with factor collapsing and Bayesian model averaging. Stat 7: e180. [Google Scholar] [CrossRef]
- Jamal, Salma, Stefano Canto, Ross Fernwood, Claudio Giancaterino, Munir Hiabu, Lorenzo Invernizzi, Tetiana Korzhynska, Zachary Martin, and Hong Shen. 2018. Machine Learning & Traditional Methods Synergy in Non-Life Reserving. Report of the ASTIN Working Party of the International Actuarial Association. Available online: https://www.actuaries.org/IAA/Documents/ASTIN/ASTIN_MLTMS%20Report_SJAMAL.pdf (accessed on 19 July 2019).
- Jurek, A., and D. Zakrzewska. 2008. Improving naïve Bayes models of insurance risk by unsupervised classification. Paper presented at 2008 International Multiconference on Computer Science and Information Technology, Wisła, Poland, October 18–20; pp. 137–44. [Google Scholar] [CrossRef]
- Kašćelan, Vladimir, Ljiljana Kašćelan, and Milijana Novović Burić. 2016. A nonparametric data mining approach for risk prediction in car insurance: A case study from the Montenegrin market. Economic Research-Ekonomska Istraživanja 29: 545–58. [Google Scholar] [CrossRef] [Green Version]
- Keller, Benno. 2018. Big Data and Insurance: Implications for Innovation, Competition and Privacy. Geneva: The Geneva Association. [Google Scholar]
- Klein, Nadja, Michel Denuit, Stefan Lang, and Thomas Kneib. 2014. Nonlife ratemaking and risk management with Bayesian generalized additive models for location, scale, and shape. Insurance: Mathematics and Economics 55: 225–49. [Google Scholar] [CrossRef]
- Kuo, Kevin. 2019a. Deeptriangle: A deep learning approach to loss reserving. Risks 7: 97. [Google Scholar] [CrossRef] [Green Version]
- Kuo, Kevin. 2019b. Generative synthesis of insurance datasets. arXiv arXiv:1912.02423. [Google Scholar]
- Kuo, Kevin. 2020. Individual claims forecasting with bayesian mixture density networks. arXiv arXiv:2003.02453. [Google Scholar]
- Kuo, Kevin, and Daniel Lupton. 2020. Towards explainability of machine learning models in insurance pricing. arXiv arXiv:2003.10674. [Google Scholar]
- LaMonica, Michael A., Cecil D. Bykerk, William A. Reimert, William C. Cutlip, Lawrence J. Sher, Lew H. Nathan, Karen F. Terry, Godfrey Perrott, and William C. Weller. 2011. Actuarial Standard of Practice no. 12: Risk Classification. Arlington: Casualty Actuarial Society. [Google Scholar]
- LeCun, Yann, Yoshua Bengio, and Geoffrey Hinton. 2015. Deep learning. Nature 521: 436. [Google Scholar] [CrossRef]
- Lee, Simon, and Katrien Antonio. 2015. Why high dimensional modeling in actuarial science? Paper presented at IACA Colloquia, Sydney, Australia, August 23–27. [Google Scholar]
- Lee, Simon C. K., and Sheldon Lin. 2018. Delta boosting machine with application to general insurance. North American Actuarial Journal 22: 405–25. [Google Scholar] [CrossRef]
- Lim, Bryan, and Stefan Zohren. 2020. Time series forecasting with deep learning: A survey. arXiv arXiv:2004.13408. [Google Scholar]
- Lindholm, Mathias, Ronald Richman, Andreas Tsanakas, and Mario V Wuthrich. 2020. Discrimination-Free Insurance Pricing. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3520676 (accessed on 15 August 2020).
- Lindholm, Mathias, Richard Verrall, Felix Wahl, and Henning Zakrisson. 2020. Machine Learning, Regression Models, and Prediction of Claims Reserves. Arlington: Casualty Actuarial Society E-Forum. [Google Scholar]
- Liu, Yue, Bing-Jie Wang, and Shao-Gao Lv. 2014. Using multi-class AdaBoost tree for prediction frequency of auto insurance. Journal of Applied Finance and Banking 4: 45. [Google Scholar]
- Llaguno, Lenard Shuichi, Emmanuel Theodore Bardis, Robert Allan Chin, Christina Link Gwilliam, Julie A. Hagerstrand, and Evan C. Petzoldt. 2017. Reserving with Machine Learning: Applications for Loyalty Programs and Individual Insurance Claims. Arlington: Casualty Actuarial Society Forum. [Google Scholar]
- Lopes, Helio, Jocelia Barcellos, Jessica Kubrusly, and Cristiano Fernandes. 2012. A non-parametric method for incurred but not reported claim reserve estimation. International Journal for Uncertainty Quantification 2. [Google Scholar] [CrossRef]
- Lopez, Olivier, and Xavier Milhaud. 2020. Individual reserving and nonparametric estimation of claim amounts subject to large reporting delays. Scandinavian Actuarial Journal, 1–20. [Google Scholar] [CrossRef]
- Lopez, Olivier, Xavier Milhaud, and Pierre-Emmanuel Thérond. 2019. A tree-based algorithm adapted to microlevel reserving and long development claims. ASTIN Bulletin. [Google Scholar] [CrossRef] [Green Version]
- Lopez, Olivier, Xavier Milhaud, and Pierre-E Thérond. 2016. Tree-based censored regression with applications in insurance. Electronic Journal of Statistics 10: 2685–716. [Google Scholar] [CrossRef]
- Lowe, Julian, and Louise Pryor. 1996. Neural networks ν. GLMs in pricing general insurance. Workshop. [Google Scholar]
- Maknickienė, Nijolė, Aleksandras Vytautas Rutkauskas, and Algirdas Maknickas. 2011. Investigation of financial market prediction by recurrent neural network. Innovative Technologies for Science, Business and Education 2: 3–8. [Google Scholar]
- Maynard, Trevor, Anna Bordon, Joe Brit Berry, David Barbican Baxter, William Skertic, Bradley TMK Gotch, Nirav TMK Shah, Andrew Nephila Wilkinson, Shree Hiscox Khare, Kristian Beazley Jones, and et al. 2019. What Role for AI in Insurance Pricing? Available online: https://www.researchgate.net/publication/337110892_WHAT_ROLE_FOR_AI_IN_INSURANCE_PRICING_A_PREPRINT (accessed on 10 July 2020).
- Mulquiney, Peter. 2006. Artificial neural networks in insurance loss reserving. In 9th Joint International Conference on Information Sciences (JCIS-06). Paris: Atlantis Press. [Google Scholar] [CrossRef] [Green Version]
- Narwani, Bhumika, Yash Muchhala, Jatin Nawani, and Renuka Pawar. 2020. Categorizing driving patterns based on telematics data using supervised and unsupervised learning. In 2020 4th International Conference on Intelligent Computing and Control Systems (ICICCS). Piscataway: IEEE, pp. 302–6. [Google Scholar] [CrossRef]
- Noll, Alexander, Robert Salzmann, and Mario V. Wuthrich. 2018. Case Study: French Motor Third-Party Liability Claims. Available at SSRN 3164764. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3164764 (accessed on 19 July 2019).
- Oancea, Bogdan, and Ştefan Cristian Ciucu. 2014. Time series forecasting using neural networks. arXiv arXiv:1401.1333. [Google Scholar]
- Paglia, Antoine, and Martial V. Phelippe-Guinvarc’h. 2011. Tarification des risques en assurance non-vie, une approche par modèle d’apprentissage statistique. Bulletin français d’Actuariat 11: 49–81. [Google Scholar]
- Panlilio, Alex, Ben Canagaretna, Steven Perkins, Valerie du Preez, and Zhixin Lim. 2018. Practical Application of Machine Learning Within Actuarial Work. London: Institute and Faculty of Actuaries. [Google Scholar]
- Pechon, Florian, Julien Trufin, and Michel Denuit. 2019. Preliminary selection of risk factors in P&C ratemaking. Variance 13: 124–40. [Google Scholar]
- Pelessoni, Renato, and Liviana Picech. 1998. Some Applications of Unsupervised Neural Networks in Rate Making Procedure. London: Faculty & Institute of Actuaries. [Google Scholar]
- Pesantez-Narvaez, Jessica, Montserrat Guillen, and Manuela Alcañiz. 2019. Predicting motor insurance claims using telematics data—XGBoost versus logistic regression. Risks 7: 70. [Google Scholar] [CrossRef] [Green Version]
- Pigeon, Mathieu, and Francis Duval. 2019. Individual loss reserving using a gradient boosting-based approach. Risks 7: 79. [Google Scholar] [CrossRef] [Green Version]
- Počuča, Nikola, Petar Jevtić, Paul D. McNicholas, and Tatjana Miljkovic. 2020. Modeling frequency and severity of claims with the zero-inflated generalized cluster-weighted models. Insurance: Mathematics and Economics. [Google Scholar] [CrossRef]
- Quan, Zhiyu, and Emiliano A. Valdez. 2018. Predictive analytics of insurance claims using multivariate decision trees. Dependence Modeling 6: 377–407. [Google Scholar] [CrossRef]
- Richman, Ronald. 2020a. AI in actuarial science—A review of recent advances—Part 1. Annals of Actuarial Science, 1–23. [Google Scholar] [CrossRef]
- Richman, Ronald. 2020b. AI in actuarial science—A review of recent advances—Part 2. Annals of Actuarial Science, 1–29. [Google Scholar] [CrossRef]
- Richman, Ronald, and Mario V. Wüthrich. 2020. Nagging predictors. Risks 8: 83. [Google Scholar] [CrossRef]
- Richman, Ronald, Nicolai von Rummell, and Mario V. Wuthrich. 2019. Believing the Bot—Model Risk in the Era of Deep Learning. Available at SSRN 3444833. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3444833 (accessed on 15 August 2020).
- Rioux, Jean-Yves, Arthur Da Silva, Harrison Jones, and Hadi Saleh. 2019. The Use of Predictive Analytics in the Canadian Life Insurance Industry. Schaumburg: Society of Actuaries and Ottawa, Canadian Institute of Actuaries. [Google Scholar]
- Roman, Jovina, and Akhtar Jameel. 1996. Backpropagation and recurrent neural networks in financial analysis of multiple stock market returns. In Proceedings of HICSS-29: 29th Hawaii International Conference on System Sciences. Piscataway: IEEE, vol. 2, pp. 454–60. [Google Scholar] [CrossRef]
- Rout, Ajit Kumar, PK Dash, Rajashree Dash, and Ranjeeta Bisoi. 2017. Forecasting financial time series using a low complexity recurrent neural network and evolutionary learning approach. Journal of King Saud University-Computer and Information Sciences 29: 536–52. [Google Scholar] [CrossRef] [Green Version]
- Sakthivel, K. M., and C. S. Rajitha. 2017. Artificial intelligence for estimation of future claim frequency in non-life insurance. Global Journal of Pure and Applied Mathematics 13: 10. [Google Scholar]
- Salman, Raied, and Vojislav Kecman. 2012. Regression as classification. In 2012 Proceedings of IEEE Southeastcon. Piscataway: IEEE, pp. 1–6. [Google Scholar] [CrossRef]
- Schelldorfer, Jürg, and Mario V. Wuthrich. 2019. Nesting Classical Actuarial Models into Neural Networks. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3320525 (accessed on 15 August 2020).
- Śmietanka, Małgorzata, Adriano Koshiyama, and Philip Treleaven. 2020. Algorithms in Future Insurance Markets. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3641518 (accessed on 15 August 2020).
- So, Banghee, Jean-Philippe Boucher, and Emiliano A. Valdez. 2020. Cost-sensitive multi-class AdaBoost for understanding driving behavior with telematics. arXiv arXiv:2007.03100. [Google Scholar] [CrossRef]
- Spedicato, Giorgio Alfredo, ACAS Gian Paolo Clemente, and Florian Schewe. 2014. The Use of GAMLSS in Assessing the Distribution of Unpaid Claims Reserves. Arlington: Casualty Actuarial Society E-Forum, vol. 2. [Google Scholar]
- Speights, David B., Joel B. Brodsky, and Durya L. Chudova. 1999. Using Neural Networks to Predict Claim Duration in the Presence of Right Censoring and Covariates. Arlington: Casualty Actuarial Society Forum, pp. 255–78. [Google Scholar]
- Taylor, Greg. 2019. Loss reserving models: Granular and machine learning forms. Risks 7: 82. [Google Scholar] [CrossRef] [Green Version]
- Taylor, Greg. 2020. Risks special issue on “Granular Models and Machine Learning Models”. Risks 8: 1. [Google Scholar] [CrossRef] [Green Version]
- Taylor, Greg, Gráinne McGuire, and James Sullivan. 2008. Individual claim loss reserving conditioned by case estimates. Annals of Actuarial Science 3: 215–56. [Google Scholar] [CrossRef]
- Verbelen, Roel, Katrien Antonio, and Gerda Claeskens. 2018. Unravelling the predictive power of telematics data in car insurance pricing. Journal of the Royal Statistical Society: Series C (Applied Statistics) 67: 1275–304. [Google Scholar] [CrossRef] [Green Version]
- Wang, Jie, Jun Wang, Wen Fang, and Hongli Niu. 2016. Financial time series prediction using Elman recurrent random neural networks. Computational Intelligence and Neuroscience. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Qun, Ruixin Zhang, Yangting Wang, and Shuaikang Lv. 2020. Machine learning-based driving style identification of truck drivers in open-pit mines. Electronics 9: 19. [Google Scholar] [CrossRef] [Green Version]
- Weidner, Wiltrud, Fabian W. G. Transchel, and Robert Weidner. 2016. Classification of scale-sensitive telematic observables for riskindividual pricing. European Actuarial Journal 6: 3–24. [Google Scholar] [CrossRef]
- Weidner, Wiltrud, Fabian W. G. Transchel, and Robert Weidner. 2017. Telematic driving profile classification in car insurance pricing. Annals of Actuarial Science 11: 213–36. [Google Scholar] [CrossRef] [Green Version]
- Werner, Geoff, and Claudine Modlin. 2010. Basic Ratemaking. Arlington: Casualty Actuarial Society. [Google Scholar]
- Wüthrich, Mario V. 2017. Covariate selection from telematics car driving data. European Actuarial Journal 7: 89–108. [Google Scholar] [CrossRef]
- Wüthrich, Mario V. 2018a. Machine learning in individual claims reserving. Scandinavian Actuarial Journal 2018: 465–80. [Google Scholar] [CrossRef]
- Wüthrich, Mario V. 2018b. Neural networks applied to Chain–Ladder reserving. European Actuarial Journal 8: 407–36. [Google Scholar] [CrossRef]
- Wüthrich, Mario V. 2019. Bias regularization in neural network models for general insurance pricing. European Actuarial Journal, 1–24. [Google Scholar] [CrossRef]
- Wuthrich, Mario V. 2019. From generalized linear models to neural networks, and back. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3491790 (accessed on 15 August 2020).
- Wuthrich, Mario V., and Christoph Buser. 2019. Data analytics for non-life insurance pricing. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2870308 (accessed on 19 July 2019).
- Wüthrich, Mario V., and Michael Merz. 2019. Yes, we CANN! ASTIN Bulletin: The Journal of the IAA 49: 1–3. [Google Scholar] [CrossRef] [Green Version]
- Yang, Yaodong, Rui Luo, and Yuanyuan Liu. 2019. Adversarial variational Bayes methods for Tweedie compound Poisson mixed models. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Piscataway: IEEE, pp. 3377–81. [Google Scholar] [CrossRef]
- Yang, Yi, Wei Qian, and Hui Zou. 2018. Insurance premium prediction via gradient tree-boosted Tweedie compound Poisson models. Journal of Business & Economic Statistics 36: 456–70. [Google Scholar] [CrossRef] [Green Version]
- Yao, Ji, and Dani Katz. 2013. An update from Advanced Pricing Techniques GIRO Working Party. Technical report. London: Institute and Faculty of Actuaries. [Google Scholar]
- Ye, Chenglong, Lin Zhang, Mingxuan Han, Yanjia Yu, Bingxin Zhao, and Yuhong Yang. 2018. Combining predictions of auto insurance claims. arXiv arXiv:1808.08982. [Google Scholar]
- Zhou, He, Wei Qian, and Yi Yang. 2020. Tweedie gradient boosting for extremely unbalanced zero-inflated data. Communications in Statistics-Simulation and Computation, 1–23. [Google Scholar] [CrossRef]
| 1. | Overviews consist of white papers, case studies, reviews, surveys and reports if published in research journals or conference proceedings, sponsored by professional actuarial organizations or large insurance companies. |
| 2. | |
| 3. | |
| 4. | Claim Models Taylor (2020), Machine Learning Asimit et al. (2020) and Finance, insurance and risk management (https://www.mdpi.com/journal/risks/special_issues/Machine_Learning_Finance_Insurance_Risk_Management). |
| 5. | Embeddings are vectorial representations of data created with deep neural networks to compress high dimensional data, categorical data or unstructured data. |
| 6. | See also https://github.com/kasaai/simulationmachine for a user-friendly package. |








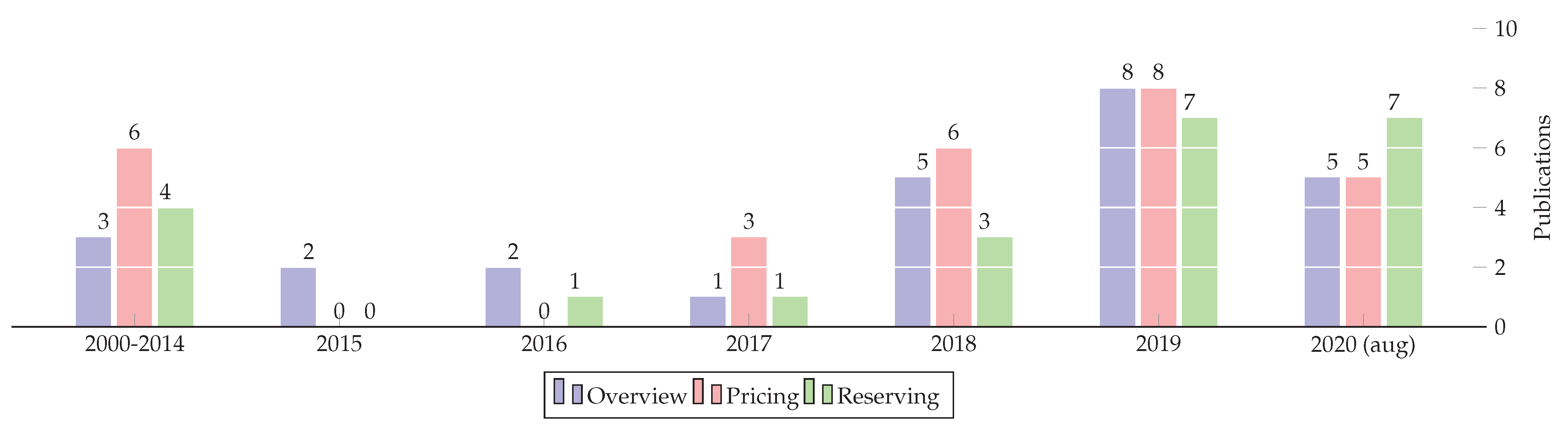{kind=link}
{kind=link}
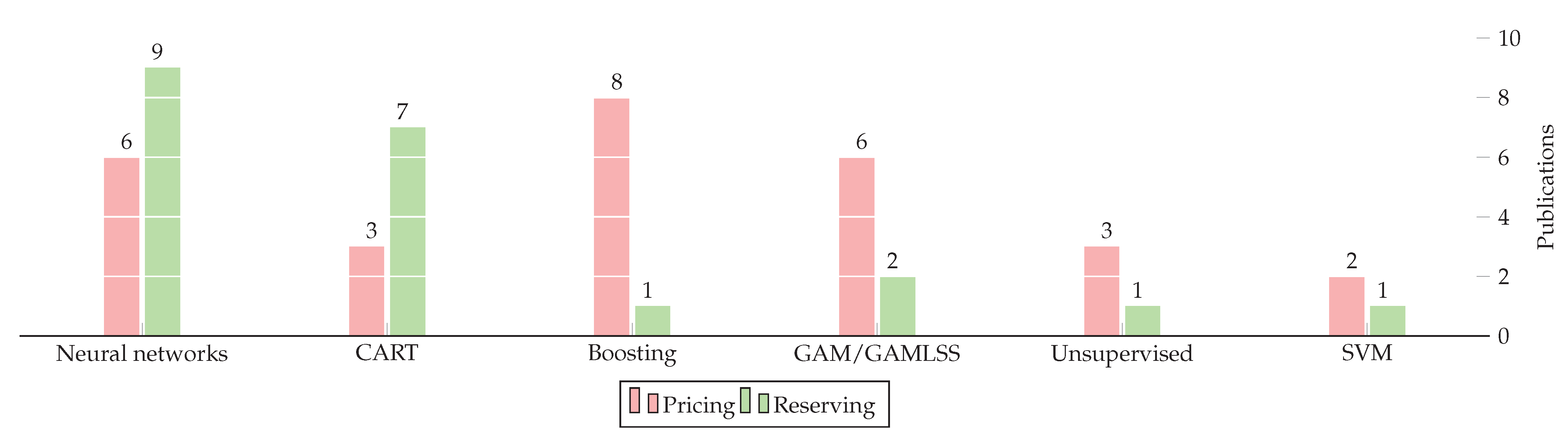{kind=link}
{kind=link}
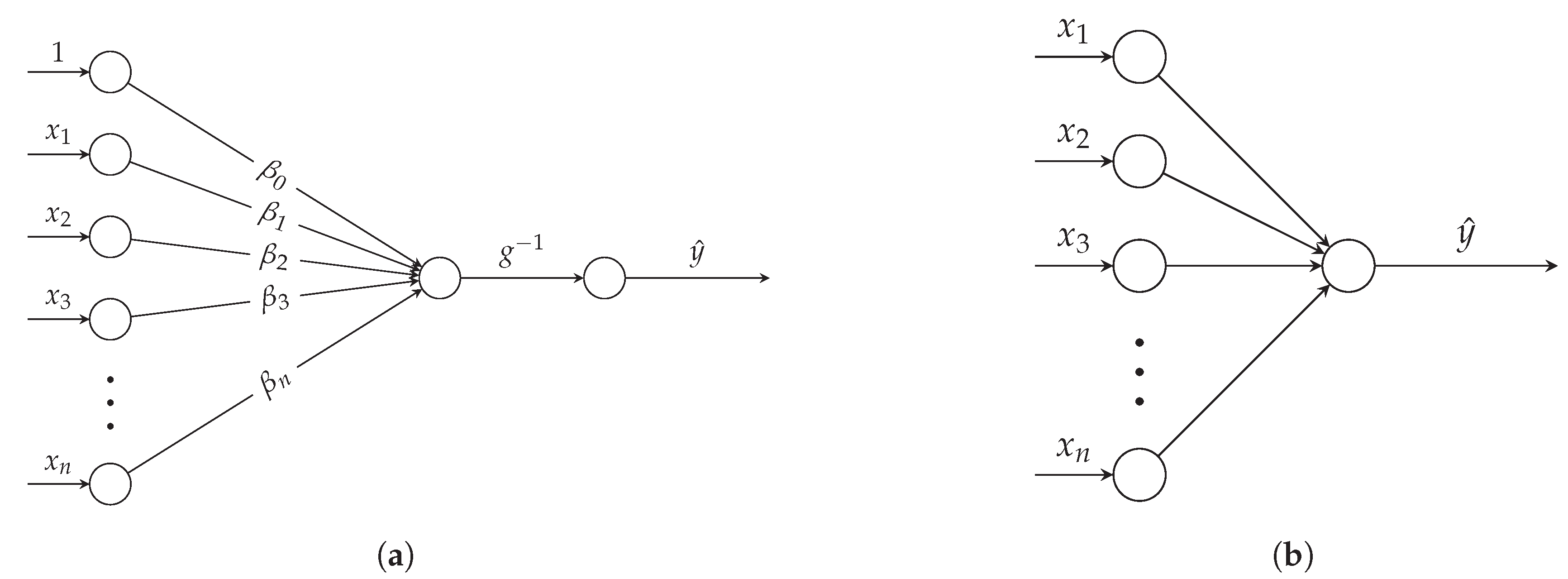{kind=link}
{kind=link}
{kind=link}
| Description | Reference | Methodologies/Approaches |
|---|---|---|
| Book | Frees et al. (2014a, 2014b) | GLM, GAM |
| Comparative study | Dugas et al. (2003) | GLM, DT, NN, SVM |
| Comparative study | Noll et al. (2018) | GLM, DT, GBT, NN |
| Comparative study | Diana et al. (2019) | GLM, RF, GBT, NN |
| Comparative study | Lee and Antonio (2015) | GLM, GAM, NN, GBT, CART |
| Comparative study | Kašćelan et al. (2016) | SVR, Kernel LR |
| Comparative study | Fauzan and Murfi (2018) | GBT, AdaBoost, RF, NN |
| Comparative study | Maynard et al. (2019) | XGBoost, RF, LR, NN, |
| Lecture notes | Wuthrich and Buser (2019) | GLM, GAM, NN, RF, GBM, SVM |
| Lecture notes | Denuit et al. (2019a, 2019b, 2019c) | GLM, GAM, GBM, NN |
| Report | Bothwell et al. (2016) | – |
| Report | Harej et al. (2017) | NN |
| Report | Jamal et al. (2018) | RF, NN, GBM |
| Review | Corlosquet-Habart and Janssen (2018) | NN, RF, GBM, SVM |
| Review | Albrecher et al. (2019) | – |
| Review | Grize et al. (2020) | CART, NN, XGBoost |
| Review | Śmietanka et al. (2020) | – |
| Review | Richman(2020a, 2020b) | NN |
| Survey | Rioux et al. (2019) | – |
| White paper | Bruer et al. (2015) | – |
| White paper | Panlilio et al. (2018) | GLM, GBT, NN |
| White paper | Richman et al. (2019) | NN |
| Reference | Models |
|---|---|
| Christmann (2004) | LR, SVR |
| Denuit and Lang (2004) | GAM |
| Paglia and Phelippe-Guinvarc’h (2011) | CART |
| Guelman (2012) | GBT |
| Liu et al. (2014) | SVC |
| Klein et al. (2014) | GAMLSS |
| Sakthivel and Rajitha (2017) | NN |
| Henckaerts et al. (2018) | GAMLSS |
| Quan and Valdez (2018) | DT |
| Yang et al. (2018) | GBT |
| Lee and Lin (2018) | Boosting |
| Yang et al. (2019) | NN |
| Wüthrich and Merz (2019) | GLM, NN |
| Fontaine et al. (2019) | GLM |
| Diao and Weng (2019) | CART |
| Wüthrich (2019) | NN |
| So et al. (2020) | Adaboost |
| Zhou et al. (2020) | GBT |
| Henckaerts et al. (2020) | GBT |
| Reference | Models |
|---|---|
| Boucher et al. (2017) | GAM |
| Wüthrich (2017) | k-means |
| Gao and Wüthrich (2018) | PCA, AE |
| Gao et al. (2018) | GAM |
| Gao et al. (2019) | GAM |
| Pesantez-Narvaez et al. (2019) | LR, GBT |
| Gao and Wüthrich (2019) | CNN |
| Narwani et al. (2020) | LR, GBT, k-means |
| Gao et al. (2020) | CNN |
| Description | Reference | Approaches | Type |
|---|---|---|---|
| ODP | England and Verrall (2001) | GAM | Agg |
| ODP | Spedicato et al. (2014) | GAMLSS | Agg |
| IBNR | Lopes et al. (2012) | SVR | Agg |
| CL | Wüthrich (2018b) | NN | Agg |
| Tot Res | Kuo (2019a) | RNN | Agg |
| ODP | Gabrielli et al. (2019) | NN | Agg |
| ODP | Gabrielli (2020b) | NN | Agg |
| — | Mulquiney (2006) | NN | Ind |
| Tot Res | Wüthrich (2018a) | CART | Ind |
| RBNS | Llaguno et al. (2017) | — | Ind |
| RBNS | Lopez et al. (2016) | CART | Ind |
| Tot Res | Baudry and Robert (2019) | CART | Ind |
| Simulation | Gabrielli and Wüthrich (2018) | NN | Ind |
| Tot Res | Pigeon and Duval (2019) | GBT | Ind |
| RBNS | Lopez et al. (2019) | CART | Ind |
| RBNS | Kuo (2020) | RNN | Ind |
| RBNS | Lopez and Milhaud (2020) | CART | Ind |
| RBNS | Gabrielli (2020a) | NN | Ind |
| RBNS | De Felice and Moriconi (2019) | CART | Ind |
| CL | Carrato and Visintin (2019) | k-means | Ind |
| Tot Res | Delong et al. (2020) | NN | Ind |
| RBNS | Crevecoeur and Antonio (2020) | GBM | Ind |
| RBNS | Lopez and Milhaud (2020) | CART | Ind |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Blier-Wong, C.; Cossette, H.; Lamontagne, L.; Marceau, E. Machine Learning in P&C Insurance: A Review for Pricing and Reserving. Risks 2021, 9, 4. https://doi.org/10.3390/risks9010004
Blier-Wong C, Cossette H, Lamontagne L, Marceau E. Machine Learning in P&C Insurance: A Review for Pricing and Reserving. Risks. 2021; 9(1):4. https://doi.org/10.3390/risks9010004
Chicago/Turabian StyleBlier-Wong, Christopher, Hélène Cossette, Luc Lamontagne, and Etienne Marceau. 2021. "Machine Learning in P&C Insurance: A Review for Pricing and Reserving" Risks 9, no. 1: 4. https://doi.org/10.3390/risks9010004