The models we use have been detailed in the previous section. We focus on seven models: elastic net (logistic regression with regularization), a random forest, a gradient boosting modeling and a neural network approach with four different complexities. To rank the models with respect to the companies’ credit worthiness, the ROC curve and AUC criteria as RMSE criteria are used. An analysis of the main variables is provided: first, we use the 181 variables (54 variables have been removed); then, we use the first 10 variables selected by each model, comparing their performance with respect to the models we use. An analysis of these variables completes the study.
4.2.2. Results
Using 181 features, the seven models (M1 corresponding to the logistic regression, M2 to the random forest, M3 to the boosting approach and D1, D2, D3 and D4 for the different deep learning models) provide the ROC curve with the AUC criteria, and we also compute the RMSE criteria for each model.
Analyzing
Table 1 and
Table 2 using 181 variables, we observe that there exists a certain competition between the approaches relying on the random forest (M2) and the one relying on gradient boosting (M3). The interesting point is that the complex deep learning in which we have tried to maximize the use of optimization functions does not provide the best models.
On the validation set, we observe that the AUC criteria have the highest value with model M3, then model M2, then model D3, and for the four last places, the model D1, then D4, M1 and D2. If we consider the RMSE criteria, the model M3 provides the smallest error, then the model M2, then D1 and D4 and, finally, D2, M1 and D3. Thus, the model D3 has the highest error. We observe that the ranking of the performance metric is not the same using the AUC and RMSE criteria.
On the test set, we observe the same ranking for the AUC and for RMSE as with the training set, except for D1 and D4 that switch between the third and the fourth place. D3 provides the highest AUC among the deep learning models; however, it yields the highest error.
If the gradient boosting model remains the best fit (using the AUC) with the smallest error, we observe the stability of models on both the validation and test sets. In all scenarios, we observe that the deep learning models do not outperform the tree-based models (M2, M3). The comparison between the results obtained with the AUC criteria and the RMSE criteria indicate that a unique criterion is not sufficient.
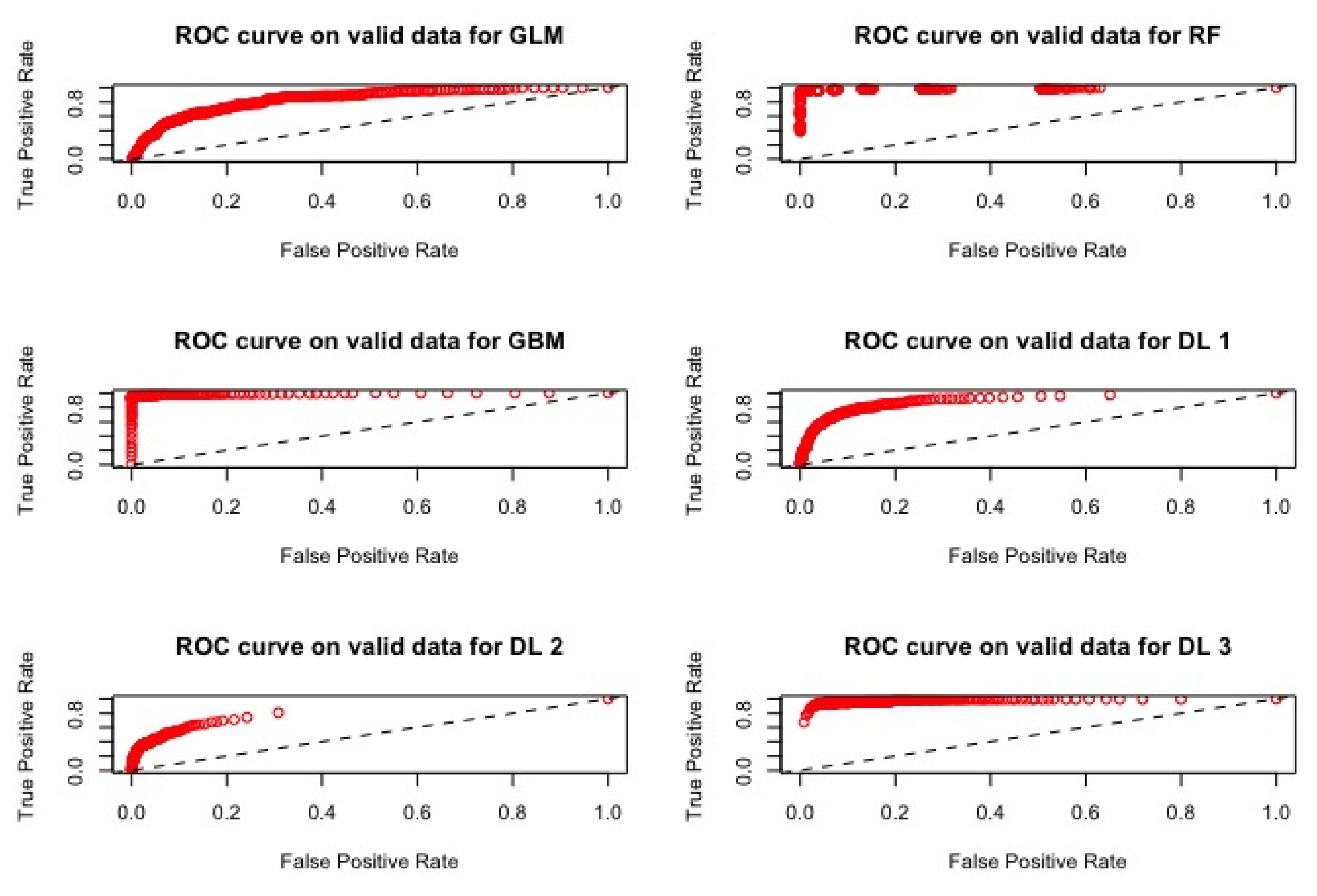
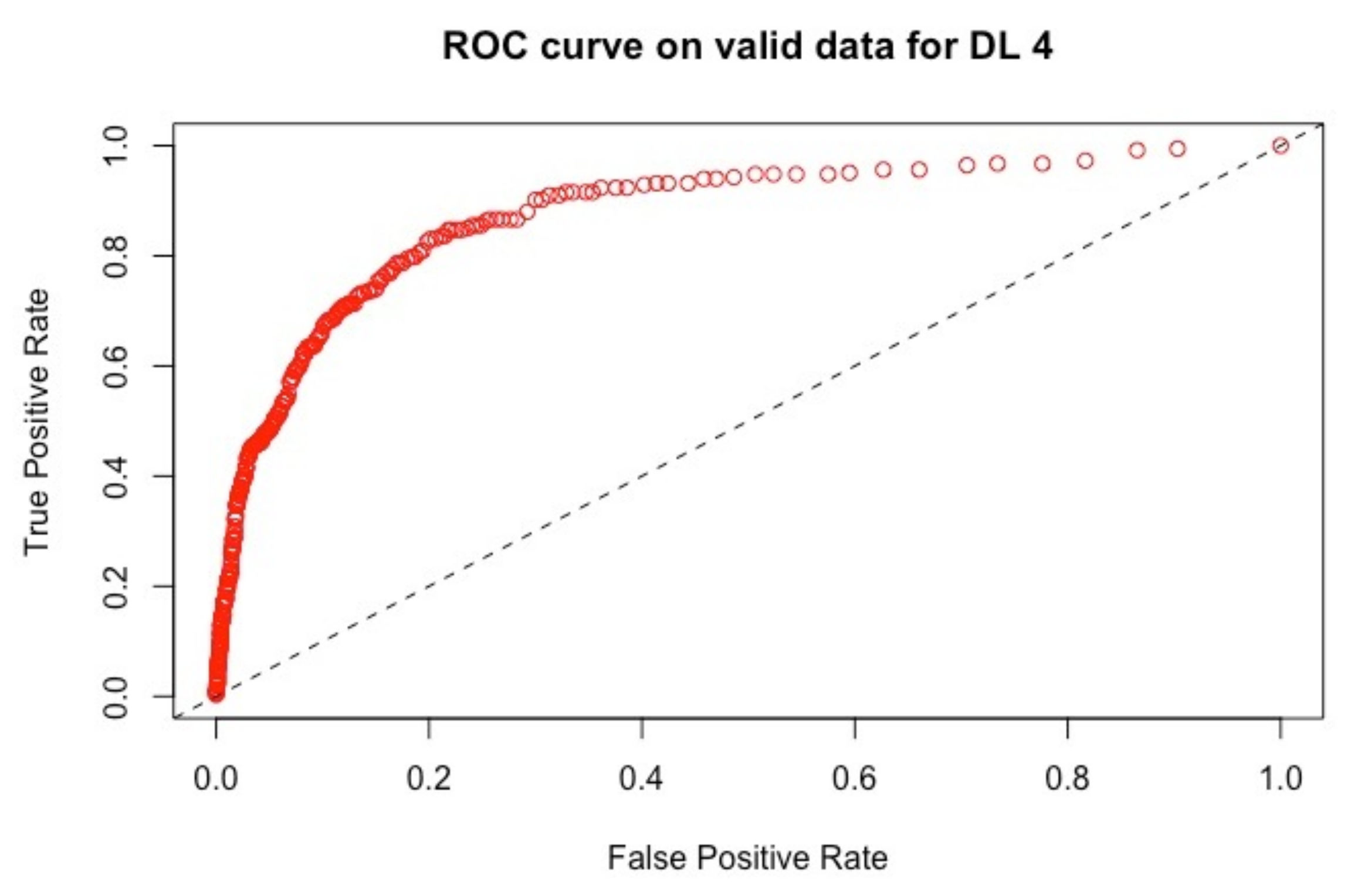
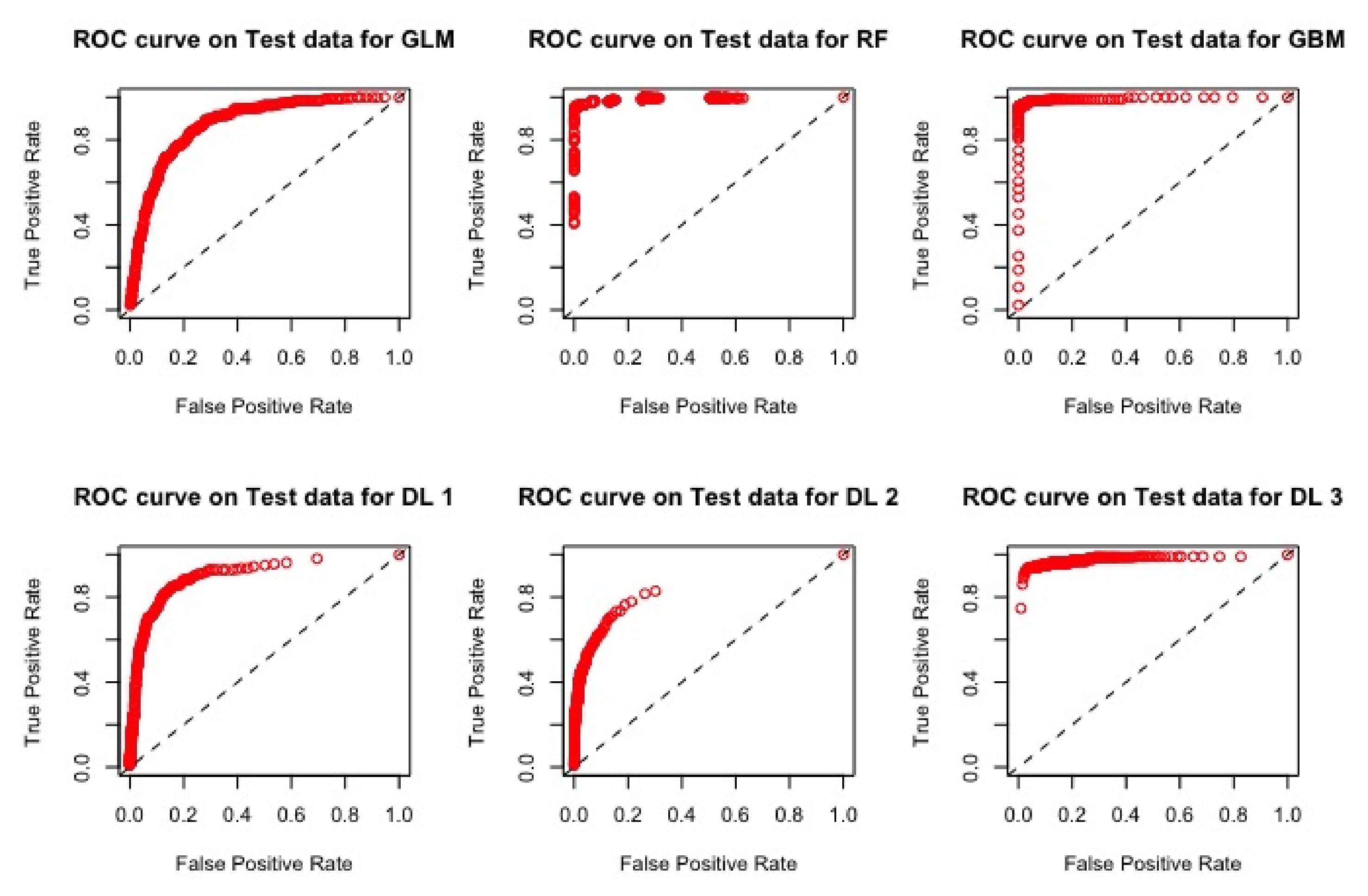
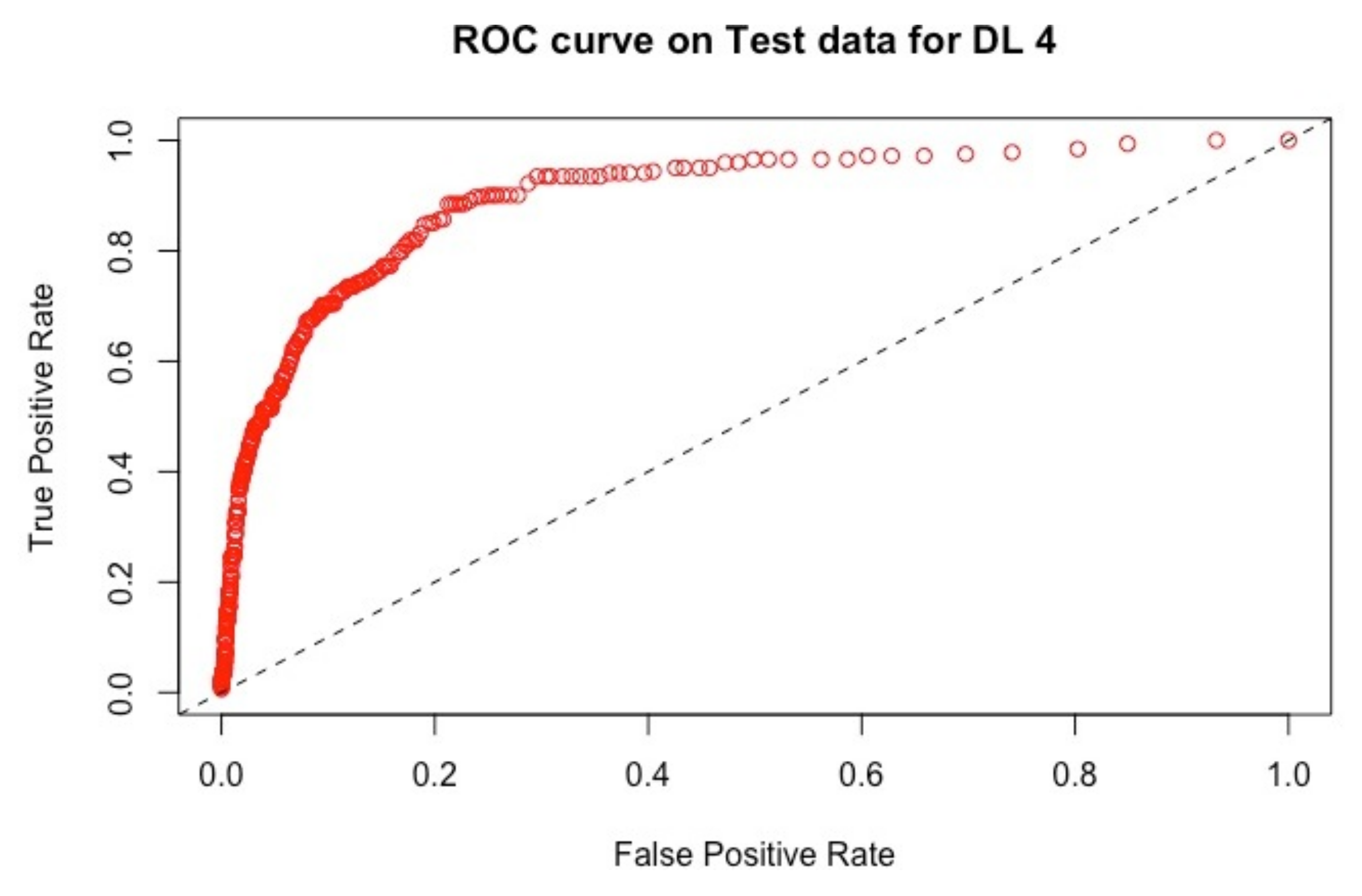
The ROC curves corresponding to these results are provided in
Figure 1,
Figure 2,
Figure 3 and
Figure 4: they illustrate the speed at which the ROC curve attains the value of one on the y-axis with respect to the value of the specificity. The best curve can be observed on the second row and first column for the validation set in
Figure 1 and for the test in
Figure 3, which corresponds to the model M3.
Models M1–M3 and D1–D4 have all used the same 181 variables for fittings. In terms of variable importance, we do not obtain the same top 10 variables for all the models
Gedeon (
1997). The top 10 variables’ importance for the models are presented in
Table 3 and correspond to 57 different variables. We refer to them as
(they represent a subset of the original variables
. Some variables are used by several algorithms, but in not more than three occurrences.
Table 4 provides a brief description of some of the variables.
We now investigate the performance of these algorithms using only the 10 variables selected by each algorithm. We do then the same for the seven models. The results for the criteria AUC and RMSE are provided in
Table 5,
Table 6,
Table 7,
Table 8,
Table 9,
Table 10 and
Table 11. Only the results obtained with the test set are provided.
All the tables showed similar results. The M2 and M3 models performed significantly bettercompared to the other five models in terms of the AUC. The deep learning models and the based logistic model poorly performed on these new datasets. Now, looking at the RMSE for the two best models, M3 is the best in all cases. The highest AUC and lowest RMSE among the seven models on these datasets is provided by the M3 model using the M3 top variables (
Table 7).
Comparing the results provided by the best model using only the top 10 variables with the model fitted using the whole variable set (181 variables), we observe that the M3 model is the best in terms of highest AUC and smallest RMSE. The tree-based models provide stable results, whatever the number of variables used, which is not the case when we fit the deep learning models. Indeed, if we look at their performance when they use their top ten variables, this one is very poor: refer to Line 4 in
Table 8, Line 5 in
Table 9, Line 6 in
Table 10 and Line 7 in
Table 11.
In summary, the class of tree-based algorithms (M2 and M3) outperforms. In terms of the AUC and RMSE, the logistic regression model (M1) and the multilayer neural network models (deep learning D1–D4)) considered in this study in both the validation and test datasets using all 181 features, we observe that the gradient boosting model (M3) demonstrated high performance for the binary classification problem compared to the random forest model (M2), given the lower RMSE values.
Upon the selection of the top 10 variables from each model to be used for modeling, we obtain the same conclusion of higher performance with models M2 and M3, with M3 as the best classifier in terms of both the AUC and RMSE. The gradient boosting model (M3) recorded the highest performance on the test dataset in the top 10 variables selected out of the 181 variables by this model M3.
Now, we look at the profile of the top 10 variables selected by each model. We denote
, the variables chosen by the models among the 181 original variables; we refer to
Table 3 and
Table 4. In this last table, we provide information on the variables that have been selected for this exercise. For instance, model M2 selects three variables already provided by model M1. Model M3 selects only one variable provided by model M1. The model D1 uses three variables of model M1. The model D2 selects one variable selected by model M2. Model D3 selects one variable used by model D1. The model D4 selects one variable selected by M1.
The classification of the variables used by each model is as follows: the variables of the model M1 correspond to flow data and aggregated balance sheets (assets and liabilities). As concerns financial statement data, the model M2 selects financial statement data and detailed financial statements (equities and debt). The model M3 selects detailed financial statements (equities and debt). The model D1 selects financial statement data and at the lowest level of granularity of financial statement data (long-term bank debt). The models D2 and D3 select an even lower level of granularity of financial statement data (short-term bank debt and leasing). The model D4 has selected the most granular data, for instance the ratio between elements as the financial statements.
Thus, we observe an important difference in the way the models select and work with the data they consider for scoring a company and as a result accepting to provide them with a loan. The model M1 selects more global and aggregated financial variables. The models M2 and M3 select detailed financial variables. The models relying on deep learning select more granular financial variables, which provide more detailed information on the customer. There is no appropriate discrimination among the deep learning models of selected variables and associated performance on the test set. It appears that the model M3 is capable of distinguishing the information provided by the data and only retains the information that improves the fit of the model. The tree-based models, M2 and M3, turn out to be the best and stable binary classifiers as they properly create split directions, thus keeping only the efficient information. From an economic stand point, the profile of the selected top 10 variables from the model M3 will be essential in deciding whether to provide a loan or not.






{kind=link}
{kind=link}
{kind=link}
{kind=link}