Analysis and Evaluation of COVID-19 Web Applications for Health Professionals: Challenges and Opportunities



Abstract
:1. Introduction
The Need for COVID-19 Research Applications
2. Challenges Faced by Health Professionals Due to COVID-19 and Converting Them to Opportunities
2.1. Identifying Most Relevant Research Portals and Resources
2.2. Multidisciplinary Research
2.3. Shortage of Area-specific Data and Applications
2.4. Limitations of Systematic Reviews
2.5. Need for Rapid Synthesis of Evidence
Opportunities for Health Professionals in the Era of COVID-19
2.6. Bringing Positive Reforms
2.7. Specific Applications for Health Professionals
2.8. Rapid Understanding of Scientific Progress
2.9. Better Integration for Improved Mitigation
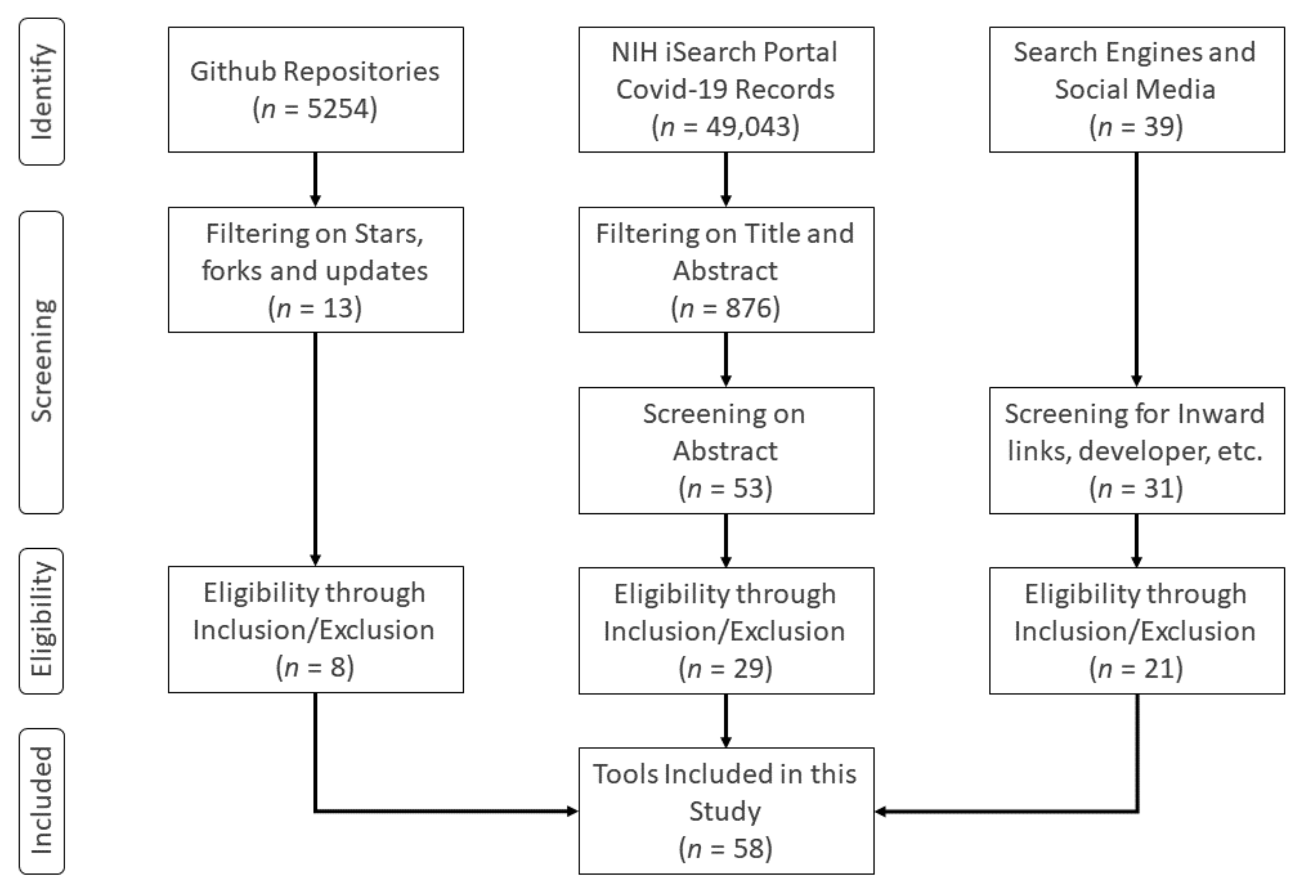
3. Research Methods and Tools
Inclusion/Exclusion Criteria
- For each application, evaluate its usefulness for healthcare researchers, analysts, statisticians, etc. in terms of the 17 features described in Section 4.
- Give preference to those applications which cover broader areas or regions. Country- or state-specific applications were discounted because most of them were similar in nature and those which stand out had either very limited scope of coverage or contained exceptional data collection and processing capabilities and could not be generalized in other cases.
- Applications intended only for public use were excluded because of their generalization (based on the description provided by the developer and our evaluation of the applications).
- Criteria like support for multiple human languages or support for multiple types of devices (mobile phones, tablets, and PCs) were not included because English has been the primary language of research around the world and computers are the main devices used by the researchers.
- In case of identifying many applications with similar purpose or functionality, evaluate each one of them and exclude those which are deficient in features or which have more limitations as compared to those to be included.
- We excluded all those databases which are maintained by a single publisher (e.g., Elsevier, Lancet, PubMed, etc.) as their repositories are included in the search portals we have included in our list.
- We further categorized the included applications into different categories based on the nature of the information they provide e.g., portals specific to genetic sequencing and modeling, academic/scientific literature portals, and statistical forecast portals, etc. Competing candidates in the same category were re-evaluated and only the most useful one was retained at the end.
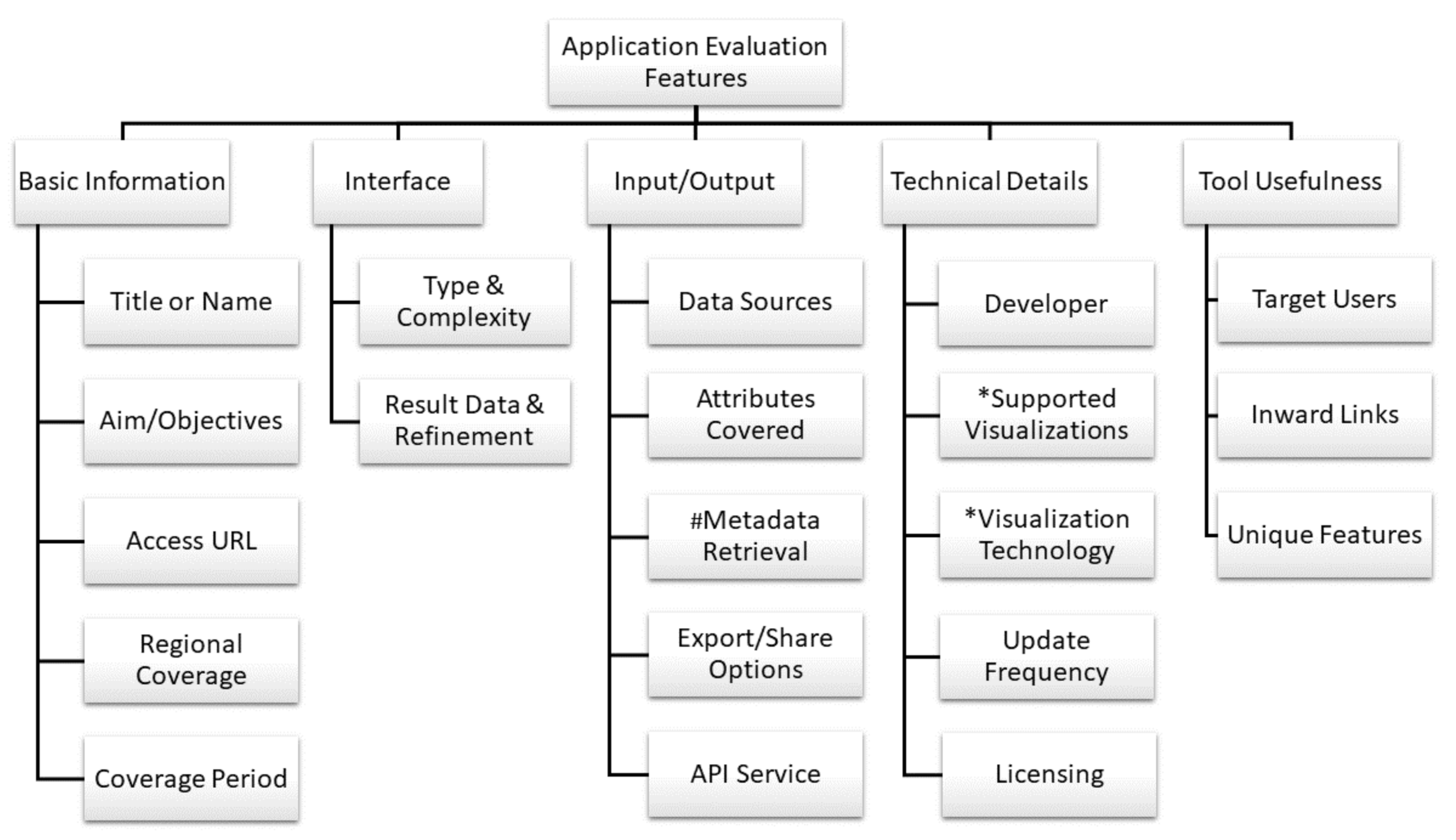
4. Framework for Evaluation of COVID-19 Applications
4.1. Basic Information about the Application
4.1.1. Title/Name of the Application
4.1.2. Aims/Objectives
4.1.3. Web Access Link (URL)
4.1.4. Regional Coverage and Coverage Period
4.2. Interface of the Application
4.2.1. Interface Type and Complexity
4.2.2. Result Data and Refinement
4.3. Input/Output of the Application
4.3.1. Sources for Data Acquisition
4.3.2. Attributes Covered
4.3.3. Metadata Retrieval
4.3.4. Export/Sharing Options
4.3.5. Provision of Application Programming Interface (API)
4.4. Technical Details
4.4.1. Developer
4.4.2. Supported Visualizations
4.4.3. Visualization Tool or Framework
4.4.4. Update Frequency
4.4.5. Licensing
4.4.6. Support for Customization
4.5. Application Usefulness
4.5.1. Target Users
4.5.2. Inward Links
4.5.3. Unique Features
5. COVID-19 Applications for Health Professionals
- Search portals
- Visualization dashboards
- Epidemiological models
5.1. COVID-19 Search Portals
5.1.1. Understanding the Scientific Progress
5.1.2. Searching for Scientific Publications in COVID-19
5.1.3. Question/Answer-Based Information Searching
5.1.4. Searching for Genetic and Biological Data
5.1.5. CORD-19-Based Applications
5.2. COVID-19 Tracking Dashboards
5.2.1. Disease Tracking, Statistics, and Analysis Dashboards
5.2.2. Clinical-Trials Tracking
5.2.3. Disease Modeling Dashboards
5.2.4. Sentiment and Mental Condition Tracking Dashboards
5.3. Epidemiological Models
5.4. Discussion on COVID-19 Applications
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- WHO. Novel Coronavirus (2019-nCoV) Situation Report-13. Available online: https://bit.ly/2PAs8tF (accessed on 9 August 2020).
- Bradley, E. Keeping a Close Watch on Coronavirus Domains. Available online: https://www.nominet.uk/keeping-a-close-watch-on-coronavirus-domains/ (accessed on 24 July 2020).
- Rochman, N.D.; Wolf, Y.I.; Faure, G.; Zhang, F.; Koonin, E.V. Ongoing Adaptive Evolution and Globalization of Sars-Cov-2. bioRxiv 2020. [Google Scholar] [CrossRef]
- Baker, T.B.; Gustafson, D.H.; Shah, D. How can research keep up with eHealth? Ten strategies for increasing the timeliness and usefulness of eHealth research. J. Med. Int. Res. 2014, 16, e36. [Google Scholar] [CrossRef] [PubMed]
- Kaufman, N. Using health information technology to prevent and treat diabetes. Diabetes Technol. Ther. 2013, 15, S-60. [Google Scholar] [CrossRef]
- Cameron, D. A Software Engineer Learns HTML5, JavaScript and jQuery: A Guide to Standards-Based Web Applications; Cisdal Publishing: Wellington, New Zealand, 2013. [Google Scholar]
- Migus, A.; Netter, P.; Boitard, C.; Clement, B.; Allilaire, J.F.; Ardaillou, R.; Berche, P.; Charpentier, B.; Debre, P.; Galibert, F.; et al. COVID-19 epidemic phases: Criteria, challenges and issues for the future. Bull. Acad. Natl. Med. 2020. [Google Scholar] [CrossRef]
- Wolkewitz, M.; Puljak, L. Methodological challenges of analysing COVID-19 data during the pandemic. BMC Med. Res. Methodol. 2020, 20, 81. [Google Scholar] [CrossRef] [Green Version]
- Chernozhukov, V.; Kasaha, H.; Schrimpf, P. Causal impact of masks, policies, behavior on early COVID-19 pandemic in the US. arXiv 2020, arXiv:2005.14168. [Google Scholar]
- Kaushik, M.; Agarwal, D.; Gupta, A.K. Cross-sectional study on the role of public awareness in preventing the spread of COVID-19 outbreak in India. Postgrad. Med. J. 2020. [Google Scholar] [CrossRef]
- Wang, R.; Chen, J.; Gao, K.; Hozumi, Y.; Yin, C.; Wei, G.W. Characterizing SARS-CoV-2 mutations in the United States. arXiv 2020, arXiv:2007.12692. [Google Scholar]
- Elavarasi, A.; Prasad, M.; Seth, T.; Sahoo, R.K.; Madan, K.; Nischal, N.; Soneja, M.; Sharma, A.; Maulik, S.K.; Garg, P.; et al. Chloroquine and Hydroxychloroquine for the Treatment of COVID-19: A Systematic Review and Meta-analysis. J. Gen. Intern. Med. 2020, 171, 1–7. [Google Scholar]
- Karia, R.; Gupta, I.; Khandait, H.; Yadav, A.; Yadav, A. COVID-19 and its Modes of Transmission. SN Compr. Clin. Med. 2020, 1–4. [Google Scholar] [CrossRef]
- Salvador-Carulla, L.; Rosenberg, S.; Mendoza, J.; Tabatabaei-Jafari, H. Rapid response to crisis: Health System Lessons from the active period of COVID-19: A Framework for Rapid Response. Health Policy Technol. 2020, 446. [Google Scholar] [CrossRef]
- National Institute of Health (NIH). NIH Office of the Portfolio Analysis. Available online: https://icite.od.nih.gov/covid19/search/ (accessed on 9 August 2020).
- Runjic, E.; Behmen, D.; Pieper, D.; Mathes, T.; Tricco, A.C.; Moher, D.; Puljak, L. Following Cochrane review protocols to completion 10 years later: A retrospective cohort study and author survey. J. Clin. Epidemiol. 2019, 111, 41–48. [Google Scholar] [CrossRef] [PubMed]
- Runjic, E.; Rombey, T.; Pieper, D.; Puljak, L. Half of systematic reviews about pain registered in PROSPERO were not published and the majority had inaccurate status. J. Clin. Epidemiol. 2019, 116, 114–121. [Google Scholar] [CrossRef] [PubMed]
- Patel, N.V. The US Has no Idea How to Manage All the Testing Data it’s Collecting; MIT Technology Review: Cambridge, MA, USA, 2020. Available online: https://bit.ly/2WWFiFv. (accessed on 24 July 2020).
- Blecher, G.; Blashki, G.A.; Judkins, S. Crisis as opportunity: How COVID-19 will reshape the Australian health system. Med. J. Aust. 2020. [Google Scholar] [CrossRef]
- Wang, L.L.; Lo, K.; Chandrasekhar, Y.; Reas, R.; Yang, J.; Eide, D.; Funk, K.; Kinney, R.; Liu, Z.; Merrill, W.; et al. CORD-19: The COVID-19 Open Research Dataset. arXiv 2020, arXiv:2004.10706v2. [Google Scholar]
- Millar, J.E.; Neyton, L.; Seth, S.; Dunning, J.; Merson, L.; Murthy, S.; Russell, C.D.; Keating, S.; Swets, M.; Sudre, C.H.; et al. Robust, reproducible clinical patterns in hospitalised patients with COVID-19. medRxiv 2020. [Google Scholar] [CrossRef]
- Verganti, R. Overcrowded: Designing Meaningful Products in a World Awash with Ideas; MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Spender, J.C.; Corvello, V.; Grimaldi, M.; Rippa, P. Startups and open innovation: A review of the literature. Eur. J. Innov. Manag. 2017, 20, 4–30. [Google Scholar] [CrossRef]
- Delgado, M.; Kim, J.D.; Mills, K. The Servicification of the US Economy: The Role of Startups versus Incumbent Firms. In The Role of Innovation and Entrepreneurship in Economic Growth; University of Chicago Press: Chicago, IL, USA, 2020. [Google Scholar]
- Albert, W.; Tullis, T. Measuring the User Experience: Collecting, Analyzing, and Presenting Usability Metrics; Newnes, Elsevier: Amsterdam, The Netherlands, 2013. [Google Scholar]
- Krug, S. Don’t Make Me Think!: A Common Sense Approach to Web Usability; New Riders Publishing: Thousand Oaks, CA, USA, 2000. [Google Scholar]
- Lee, S.; Kim, D.; Lee, K.; Choi, J.; Kim, S.; Jeon, M.; Lim, S.; Choi, D.; Kim, S.; Tan, A.C.; et al. BEST: Next-generation biomedical entity search tool for knowledge discovery from biomedical literature. PLoS ONE 2016, 11, e0164680. [Google Scholar] [CrossRef]
- Brandizi, M.; Singh, A.; Rawlings, C.; Hassani-Pak, K. Towards FAIRer biological knowledge networks using a hybrid linked data and graph database approach. J. Integr. Bioinform. 2018, 15. [Google Scholar] [CrossRef]
- Wei, C.H.; Allot, A.; Leaman, R.; Lu, Z. PubTator central: Automated concept annotation for biomedical full text articles. Nucleic Acids Res. 2019, 47, W587–W593. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ammar, W.; Groeneveld, D.; Bhagavatula, C.; Beltagy, I.; Crawford, M.; Downey, D.; Dunkelberger, J.; Elgohary, A.; Feldman, S.; Ha, V.A.; et al. Construction of the Literature Graph in Semantic Scholar. arXiv 2018, arXiv:1805.02262. [Google Scholar]
- Liu, Y.; Liu, Z.; Chua, T.S.; Sun, M. Topical word embeddings. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–29 January 2015. [Google Scholar]
- Lee, J.; Yi, S.S.; Jeong, M.; Sung, M.; Yoon, W.; Choi, Y.; Ko, M.; Kang, J. Answering Questions on COVID-19 in Real-Time. arXiv 2020, arXiv:2006.15830. [Google Scholar]
- Kim, D.; Lee, J.; So, C.H.; Jeon, H.; Jeong, M.; Choi, Y.; Yoon, W.; Sung, M.; Kang, J. A neural named entity recognition and multi-type normalization tool for biomedical text mining. IEEE Access 2019, 7, 73729–73740. [Google Scholar] [CrossRef]
- Sung, M.; Jeon, H.; Lee, J.; Kang, J. Biomedical Entity Representations with Synonym Marginalization. arXiv 2020, arXiv:2005.00239. [Google Scholar]
- Hassani-Pak, K. KnetMiner—An Integrated Data Platform for Gene Mining and Biological Knowledge Discovery. 2017. Available online: https://pub.uni-bielefeld.de/record/2915227 (accessed on 24 July 2020).
- Hassani-Pak, K.; Singh, A.; Brandizi, M.; Hearnshaw, J.; Phillips, A.L.; Doonan, J.H.; Rawlings, C. KnetMiner-Intelligent search and visualisation of connected data to explain complex traits and diseases. bioRxiv 2020. [Google Scholar] [CrossRef] [Green Version]
- Hassani-Pak, K.; Singh, A.; Brandizi, M.; Hearnshaw, J.; Amberkar, S.; Phillips, A.L.; Doonan, J.H.; Rawlings, C. KnetMiner: A comprehensive approach for supporting evidence-based gene discovery and complex trait analysis across species. bioRxiv 2020. [Google Scholar] [CrossRef] [Green Version]
- Hadfield, J.; Megill, C.; Bell, S.M.; Huddleston, J.; Potter, B.; Callender, C.; Sagulenko, P.; Bedford, T.; Neher, R.A. Nextstrain: Real-time tracking of pathogen evolution. Bioinformatics 2018, 34, 4121–4123. [Google Scholar] [CrossRef]
- Klein, A.; Magge, A.; O’Connor, K.; Cai, H.; Weissenbacher, D.; Gonzalez-Hernandez, G. A Chronological and Geographical Analysis of Personal Reports of COVID-19 on Twitter. medRxiv 2020. [Google Scholar] [CrossRef]
- Pellert, M.; Lasser, J.; Metzler, H.; Garcia, D. Dashboard of sentiment in Austrian social media during COVID-19. arXiv 2020, arXiv:2006.11158. [Google Scholar]
- Dong, E.; Du, H.; Gardner, L. An interactive web-based dashboard to track COVID-19 in real time. Lancet Infect. Dis. 2020, 20, 533–534. [Google Scholar] [CrossRef]
- Max Roser; Hannah Ritchie; Esteban Ortiz-Ospina; Hasell, J. Coronavirus Pandemic (COVID-19). Our World in Data. Available online: https://ourworldindata.org/coronavirus (accessed on 28 July 2020).
- Peng, D.; Wang, Z.; Xu, Y. Challenges and opportunities in mental health services during the COVID-19 pandemic. Gen. Psychiatry 2020, 33. [Google Scholar] [CrossRef]
- Farooqi, A.; Snoek, F.; Khunti, K. Management of chronic cardiometabolic conditions and mental health during COVID-19. Prim. Care Diabetes 2020. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Wang, Z.; Liu, X.; Yang, X.; Zheng, M.; Bai, X. The impacts of a COVID-19 epidemic focus and general belief in a just world on individual emotions. Personal. Individ. Differ. 2020, 168, 110349. [Google Scholar] [CrossRef]
- Medford, R.J.; Saleh, S.N.; Sumarsono, A.; Perl, T.M.; Lehmann, C.U. An “Infodemic”: Leveraging High-Volume Twitter Data to Understand Public Sentiment for the COVID-19 Outbreak. medRxiv 2020. [Google Scholar] [CrossRef] [Green Version]
- El Aferni, A.; Guettari, M.; Tajouri, T. Mathematical model of Boltzmann’s sigmoidal equation applicable to the spreading of the coronavirus (COVID-19) waves. Environ. Sci. Pollut. Res. 2020, 469, 1–9. [Google Scholar]
- Alvarez, L.; Colom, M.; Morel, J.M. A variational model for computing the effective reproduction number of SARS-CoV-2. medRxiv 2020. [Google Scholar] [CrossRef]
- Djaoue, S.; Kolaye, G.G.; Abboubakar, H.; Ari, A.A.A.; Damakoa, I. Mathematical modeling, analysis and numerical simulation of the COVID-19 transmission with mitigation of control strategies used in Cameroon. Chaos Solitons Fractals 2020, 139, 110281. [Google Scholar] [CrossRef]
- Kefayati, S.; Huang, H.; Chakraborty, P.; Roberts, F.; Gopalakrishnan, V.; Srinivasan, R.; Pethe, S.; Madan, P.; Deshpande, A.; Liu, X.; et al. On machine learning-based short-term adjustment of epidemiological projections of COVID-19 in us. medRxiv 2020. [Google Scholar] [CrossRef]
- Ardabili, S.F.; Mosavi, A.; Ghamisi, P.; Ferdinand, F.; Varkonyi-Koczy, A.R.; Reuter, U.; Rabczuk, T.; Atkinson, P.M. COVID-19 Outbreak Prediction with Machine Learning. 2020. Available online: https://ssrn.com/abstract=3580188 (accessed on 28 July 2020).
- Gates, L.E.; Hamed, A.A. The Anatomy of the SARS-CoV-2 Biomedical Literature: Introducing the CovidX Network Algorithm for Drug Repurposing Recommendation. J. Med. Internet. Res. 2020, 22, e21169. [Google Scholar] [CrossRef]
- Guo, X.; Mirzaalian, H.; Sabir, E.; Jaiswal, A.; Abd-Almageed, W. Cord19sts: COVID-19 semantic textual similarity dataset. arXiv 2020, arXiv:2007.02461. [Google Scholar]
- Cury, R.C.; Megyeri, I.; Macedo, R.; Batlle, J.; Kim, S.; Baker, B.; Harris, R.; Clark, R.H. Natural language processing and machine learning for detection of respiratory illness by chest ct imaging and tracking of COVID-19 pandemic in the US. SSRN Electron. J. 2020. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| No. | Name/Title | Objectives/Goal | Access | Data Sources |
|---|---|---|---|---|
| 1 | COVID-19 Primer | Quickly understand the scientific progress for COVID-19 | https://covid19primer.com/dashboard | PubMed, bioRxiv, medRxiv, arXiv |
| 2 | iSearch COVID-19 Portfolio | Searching for Peer-reviewed, preprint articles, letters to the editors, and journal comments | https://icite.od.nih.gov/covid19/search/ | Articles from PubMed and preprints from arXiv, bioRxiv, ChemRxiv, medRxiv, Research Square, and SSRN |
| 3 | LitCovid | Curated literature hub for tracking up-to-date scientific information about COVID-19 | https://www.ncbi.nlm.nih.gov/research/coronavirus/ | PubMed |
| 4 | Covid Scholar | Using Artificial Intelligence (Natural Language Processing) to power search on research papers related to COVID-19 | https://covidscholar.org/ | CORD-19 Dataset (Semantic Scholar), Elsevier Novel Coronavirus Information Center, LitCovid, The Lens |
| 5 | COVID-19 Research Explorer | Get answers to complex scientific questions related to COVID-19 | https://covid19-research-explorer.appspot.com/ | CORD-19 (Semantic Scholar) |
| 6 | covidAsk | Questions, Answers in real-time | https://covidask.korea.ac.kr/ | CORD-19, Allen Institute for AI papers |
| 7 | KnetMiner | Ranking of genes and visualization of integrated biological data within an easy-to-use, web environment, in a graph format | https://knetminer.org/COVID-19/ | KnetMiner proprietary |
| 8 | The Lens Human Coronaviruses Data Initiative | Scholarly research works metadata and biological sequences from patents in a machine-readable/explorable form | https://about.lens.org/COVID-19/ | Microsoft Academic, PubMed, CrossRef, Core, and WIPO |
| 9 | COVID-19 Data Portal | Facilitates data sharing and analysis in order to accelerate coronavirus research | https://www.covid19dataportal.org/ | ENA, UniProt, PDBe, EMDB, Expression Atlas and Europe PMC and lit. sources |
| 10 | CORD-19 (COVID-19 Open Research Dataset) and Related applications (See Section 5.1.5) | A group of applications and resources on COVID-19 to bring together computing community, biomedical experts, and policymakers to fight COVID-19 [20] | http://www.semanticscholar.org/cord19 | Web crawling, WHO, Google Scholar, Microsoft Academic Search, CiteSeerX, etc. |
| No. | Intended Users | Complexity of Query | Results Returned | Result Refinement |
|---|---|---|---|---|
| ≻ 1 | Researchers, policy-makers, public | Keyword and phrase-based query can be made | List of publications with title, publication date, journal name, and article source | Results can be refined according to certain criteria such as Date, last 7 days, etc. |
| ≻ 2 | Researchers in need of general COVID-19 literature by trusted sources, with support of various metadata search | Support searching through the metadata fields (title, abstract, journal, author, devices, conditions, chemicals, and drugs) | List of publications with title, publication date (sorted), journal name and link to details and PDF document | Does not support searching within the result |
| ≻ 3 | Scientific literature into the biology of the virus and the diagnosis and management of those who have been infected | Each article automatically annotated with six different entity types Gene, Disease, Chemical, Mutation, Species, CellLine with color coding through PubTator Central | Abstract and link to the journal for full article as well as annotated six different entity types for further selection of the entity | Results can be refined for various domains such as chemical And/Or journals, etc. One can search within the related articles |
| ≻ 4 | Researchers in COVID-19 and related domain | The search can be narrowed down by selecting various options such as peer-reviewed articles or not | List of publications with title, publication date (sorted), journal name and link to source of the article | Select an article for details of the meta data as well as other related articles through document embedding |
| ≻ 5 | Researchers, scientists | Question is formulated in natural language (English) | List of publications with title, highlighted possible answers, journal name and link to the article | Results can be refined by follow-up questions into original query |
| ≻ 6 | Researchers | Question can be formulated in natural language English | Answers and displays important entities relevant to the questions from BEST [27] and CORD [20] | Only can copy the title from answer section and can navigate in the entities section |
| ≻ 7 | Biomedical, genetic, and clinical research | Explore genes related to the search inputs, according to networks of connected knowledge [28] | Accession, gene name, CHRO, start, evidence | A number of views can be selected from Gene View, Map View, Evidence View, Network View |
| ≻ 8 | Medical and biological Researchers | Query can be made very complex over range of parameters with Query Editor | List of patent/publications with title, authors name, publication date, journal name, | If any one result is selected, then it gives details of the articles metadata as well. |
| ≻ 9 | Virologists, genetics researchers, biochemists | Search through keywords only | A list of items with some description, specific to type of search | The results are divided into subsections according to subject or topic and can be explored further |
| ≻ 10 | Global research community | Supports different queries depending upon the sub-tool/application (see in discussions) | Semantic Scholar: list of publications with title, publication date (sorted), journal name and link to source of the article | Results can be refined for the conference or journal, date, publication type, and authors |
| No. | Metadata Retrieval | Export/Sharing of Results | Unique Features | API Service | Latest Data |
|---|---|---|---|---|---|
| ≻ 1 | In the sub interface for papers, paper title, authors’ names, journal name, DOI | Not available | Combines dashboards, papers, and social media at one place | None | 48,031 papers |
| ≻ 2 | Journal information, article content (abstract, title, condition, chemicals and drugs, target, devices), authors’ data, bibliometrics, etc. | Results with customized features selection described in the metadata | Curated manually by experts, offers various statistics related to articles, sources, | None | 52,907 |
| ≻ 3 | Overall lists more than 30 features to choose from | Annotated publications in batches, in BioC, PubTator or JSON formats. RSS feeds for specific topic | Curated by ML and then manually, Categorized by different research topics and geographic locations for improved access | PubTator Central (PTC) API [29] | 36,239 publications |
| ≻ 4 | Journal information, article content (title, abstract, authors’ names), tag (treatment), etc. | Depends if publisher provides support | Combines patent data for COVID-19 | None | 67,000 COVID-19 specific articles |
| ≻ 5 | Title of the relevant paper, Journal name, date of publication | Not available | Use of neural network model for terms retrieval | None | More than 50,000 articles according to Google |
| ≻ 6 | Title of the relevant paper, PMID | Not available | Uses NLP to process papers and answers question using NER process | http://github.com/dmis-lab/covidAsk | Data is from CORD-19 database |
| ≻ 7 | Gene specific data such as ACCESSION, GENE NAME, CHRO, START, EVIDENCE | Sharing with registered collaborators supported | Graph patterns and search ranking techniques for genes relevance to search words | Available as KnetSpace API | genes: 27,599, concepts: 674,969, relations: 1,652,520 |
| ≻ 8 | Abstract, Access information, affiliations, citing patents, citing works, etc. | Citation can be exported as RIS, BibTex, CSV, JSON | This search portal contains patents for COVID-19 as well scholarly research work | PatSeq Bulk Download and scholarly API are available | Not available |
| ≻ 9 | Depending on the search type additional details (e.g., organism, gene, length, strain, taxonomy) are shown | Data can be downloaded in bulk | Data can be submitted by users; part of the wider European COVID-19 Data Platform | None | 52,271 viral sequences, 890 host sequence, 62 expressions, 582 proteins, 1463 biochemistry records |
| ≻ 10 | Journal information, article content (title, abstract, authors’ names) | Not available | Blend of ML, NLP, and MV for adding semantic analysis and ontology into the Semantic Scholar [30] | Semantic Scholar API: http://api.semanticscholar.org/ | 186,000 articles mentioning “COVID-19” indexed |
| No. | Dashboard Name/Title | Link | CoverageSince | Update Frequency | Data Sources |
|---|---|---|---|---|---|
| 1 | JHU Coronavirus Resource Center | https://coronavirus.jhu.edu/ | 2020-01-01 | Daily, Real-time | Curated by CSSE team |
| 2 | Our World in Data: COVID-19 | https://ourworldindata.org/coronavirus | 2020-01-01 | Daily | European Center for Disease Prevention and Control (ECDC) |
| 3 | Worldometer: COVID-19 CORONAVIRUS PANDEMIC | https://www.worldometers.info/coronavirus/ | 2020-01-01 | Daily, Real-time | Official websites, social media accounts, press briefings and daily report released by health ministries, government institutions, government authorities |
| 4 | The Net York Times Coronavirus Map: Tracking the Global Outbreak | https://www.nytimes.com/interactive/2020/world/coronavirus-maps.html | 2020-01-01 | Daily | Local governments, CSSE/JHU and WHO |
| 5 | Global Coronavirus COVID-19 Clinical Trial Tracker | https://www.covid-trials.org/ | 2020-05-01 | Weekly | WHO International Clinical Trials Registry Platform, various countries’ Clinical Trials Registries, clinicaltrials.gov |
| 6 | IHME COVID-19 Projections | https://covid19.healthdata.org/ | 2020-03-30 | Depending on data | Local and national governments, hospital networks and associations, the World Health Organization, third-party aggregators |
| 7 | Genomic epidemiology of SAR-CoV-2 | https://nextstrain.org/sars-cov-2 | 2019-12-01 | Daily | Various Research Groups around the world, |
| 8 | Penn COVID-19 US Twitter Map | https://www.arcgis.com/apps/opsdashboard/index.html | 2020-05-08 | Daily | Tweets collected from Twitter API, CSSE/JHU |
| 9 | Tracking of Emotional Expressions | http://www.mpellert.at/covid19_monitor_austria/ | 2020-04-22 | Daily | derstandard.at, Twitter |
| No. | Open Source | Technical Details | Visualization Technology | Regional Coverage | Export/Share Options | Backlinks | Target Users |
|---|---|---|---|---|---|---|---|
| ≻ 1 | No | On website Data and code also available | Plotly | Global | Facebook, Twitter, LinkedIn, Email | 6,150,102 | Public, data scientists, medical science researchers |
| ≻ 2 | Yes | On website Data and code also available | Open Graph Protocol, Polyfill IO | Global | CSV | 270,243 | Policy-makers, data scientists, statisticians, human and social science researchers |
| ≻ 3 | No | On website Data also available | ArcGIS, Open Graph Protocol | Global | Twitter, Facebook, Email | 8,943,983 | Public, statisticians, researchers |
| ≻ 4 | Yes | On website | Open Graph Protocol, CSS, JavaScript | Global | Facebook, Twitter, LinkedIn, Email | 143,564 | Public, journalists, researchers |
| ≻ 5 | No | On website Data also available | Shiny, Leaflet | Global | CSV | 994 | Researchers, policy-makers |
| ≻ 6 | No | On website | Javascript/SVG | Global | 245,631 | Policy-makers | |
| ≻ 7 | Yes | On websiteResearch article [38] Data and code also available | HTML/Javascript | Global | Not available | 4778 | Genetics researchers, virologists, epidemiologists, public health officials, and community scientists |
| ≻ 8 | No | Research article [39] | ArcGIS | USA | Not available | Not available | Public, researchers, policy-makers |
| ≻ 9 | No | Research article [40] | Flexdashboard, Plotly | Austria | Not available | 7 | Public and policy-makers |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mukhtar, H.; Ahmad, H.F.; Khan, M.Z.; Ullah, N. Analysis and Evaluation of COVID-19 Web Applications for Health Professionals: Challenges and Opportunities. Healthcare 2020, 8, 466. https://doi.org/10.3390/healthcare8040466
Mukhtar H, Ahmad HF, Khan MZ, Ullah N. Analysis and Evaluation of COVID-19 Web Applications for Health Professionals: Challenges and Opportunities. Healthcare. 2020; 8(4):466. https://doi.org/10.3390/healthcare8040466
Chicago/Turabian StyleMukhtar, Hamid, Hafiz Farooq Ahmad, Muhammad Zahid Khan, and Nasim Ullah. 2020. "Analysis and Evaluation of COVID-19 Web Applications for Health Professionals: Challenges and Opportunities" Healthcare 8, no. 4: 466. https://doi.org/10.3390/healthcare8040466