
A Review on Electronic Health Record Text-Mining for Biomedical Name Entity Recognition in Healthcare Domain

Abstract
:1. Introduction
1.1. Background of Biomedical Name Entity Recognition (bNER)
1.2. Impact of Biomedical EHRs Analysis
1.3. Motivations of the Study
- This study examines DL techniques in bNER, as well as their applications in propagandist text in electronic health records, and it provides researchers and practitioners with the current understanding of these techniques. A major focus of this study is to consolidate bNER and provide the research community with relevant corpora for bNER.
- This study presents a broad review of DL techniques for bNER entries in clinical records, for online or electronic treatment, for the diagnosis and treatment of various diseases.
- The study proposes a new classification that categorizes DL-based bNER approaches, input representations, and encoders and decoders. The proposed classification receives context for tag decoding and predicts labels for words based on given sequences.
- Additionally, this study examines the most representative DL methods for solving bNER problems and challenges. As a result, we summarize the challenges and future directions facing healthcare propaganda and bNER systems in the coming years.
- Information extraction (IE) and NLP are two powerful tools that can be used to process and analyze text. IE is the process of identifying and classifying named entities in text. At the same time, NLP is a field of computer science that deals with the interaction between computers and human (natural) languages.
2. Material and Methods
2.1. Datasets and Tools
- Data provenance: This involves tracking the origin of data and how it has been processed. This can help to identify any errors or biases in the data.
- Data quality: This involves checking data quality to ensure it is accurate, complete, and consistent.
- Data auditing: This involves reviewing the data to identify errors or biases.
- Data visualization: This involves using graphs, charts, and other visuals to represent data in a way that makes it easy to understand. This can help to identify any errors or biases in the data.
- Expert review: This involves having an expert review the AI solution to ensure it is correct.
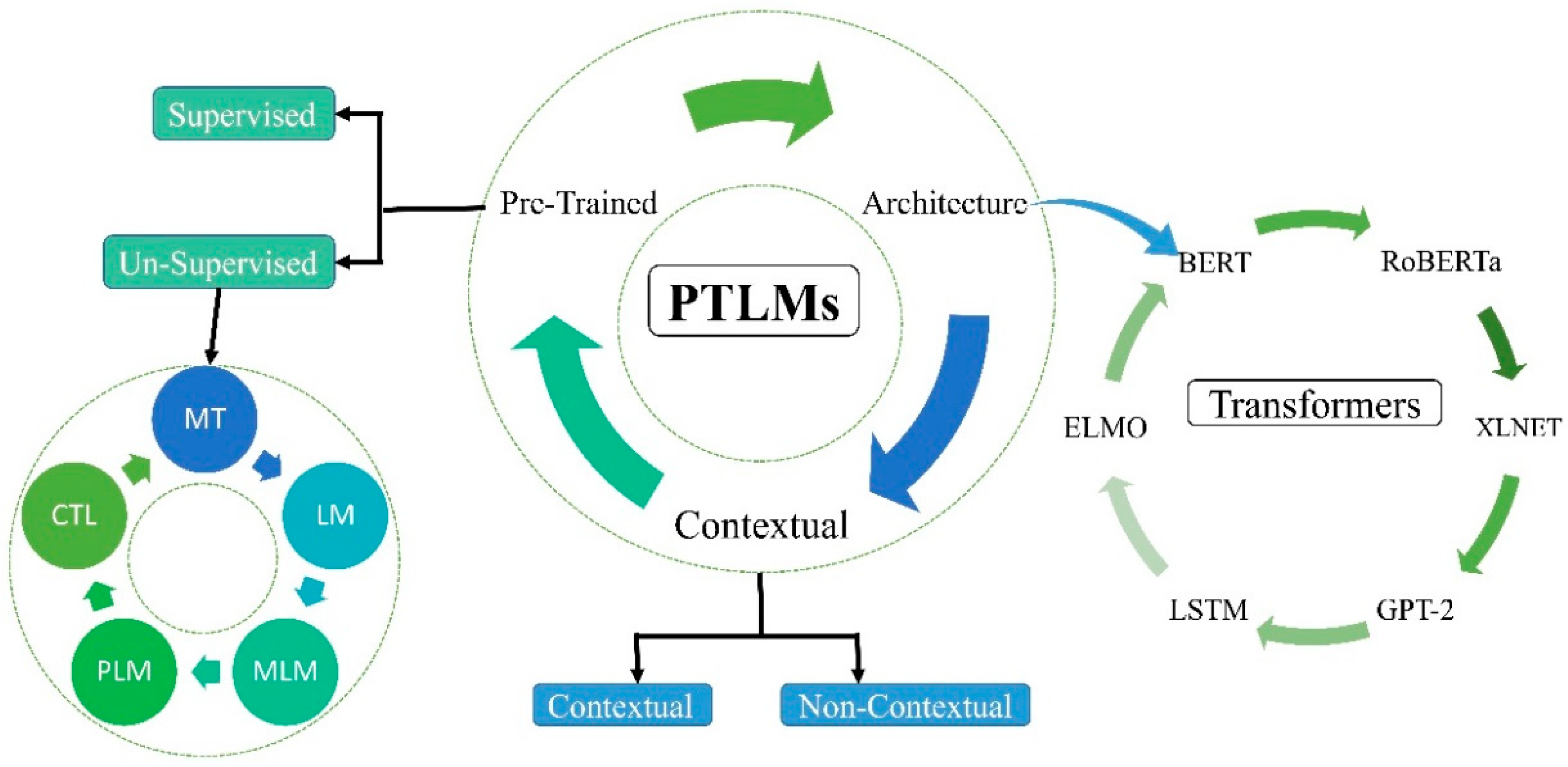
2.2. Deep Learning Role in bNER
2.3. Deep Learning-Based Healthcare System
2.4. Development of DL Sentiment Analyzer
2.4.1. Multi-Task Healthcare Analysis
- Corpus cleaning: The corpus may need to be cleaned before it can be annotated. This may involve removing stop words, punctuation, and other noise from the corpus.
- Feature extraction: Features can be extracted from the corpus to help the machine learning model learn to recognize biomedical entities. These features can be lexical, syntactic, or semantic in nature.
- Annotation: The next step is to annotate the corpus with biomedical entities. This can be done manually or automatically. Subtasks are:
- Entity segmentation: The corpus is first segmented into entities. This can be done using a variety of techniques, such as rule-based systems or machine-learning models.
- Entity labeling: Once the entities are segmented, they are labeled with the appropriate biomedical entity type. This can also be done using a variety of techniques, such as rule-based systems or machine-learning models.
- Model selection: The first step is to select a machine-learning model. This can be done by considering the corpus size, the entities’ complexity, and the model’s desired performance.
- Model training: The model is then trained on the annotated corpus. This can be done using various techniques, such as batch training or online training.
- Model evaluation: A held-out test set evaluates the model’s performance. This ensures that the model is not overfitting the training data.
- Precision: Precision is the fraction of entities that the model correctly identifies.
- Recall: Recall is the fraction of entities that are actually in the corpus and that are correctly identified by the model.
- F1-score: The F1-score is a weighted harmonic mean of precision and recall.
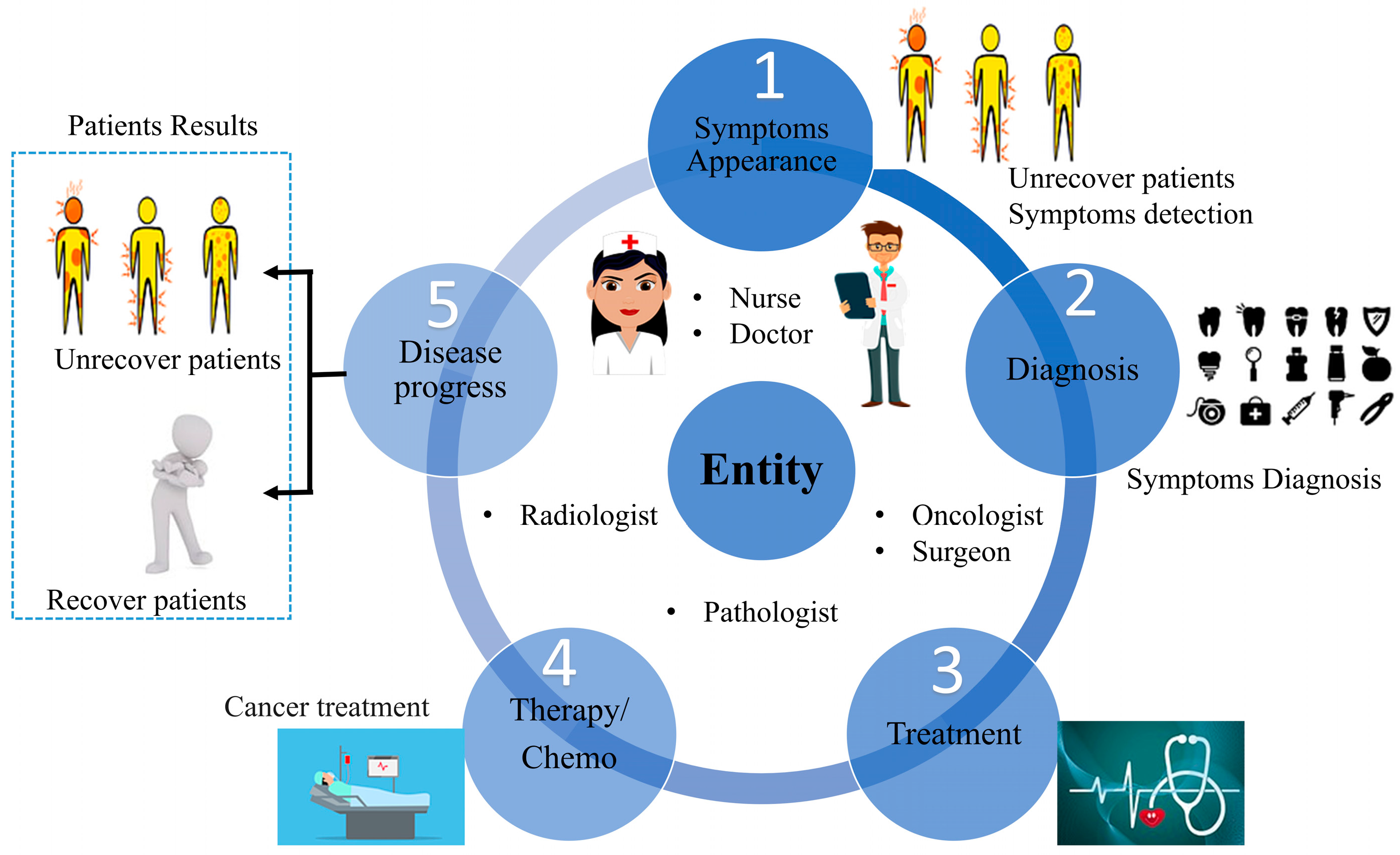
2.4.2. Healthcare Mining from EHR
2.4.3. Healthcare Context in AI
2.5. Tag Encoder-Decoder Architecture
3. In-Depth Healthcare Analytics
3.1. Clinical Decision Support
3.2. Healthcare Administration
3.3. Public Healthcare
4. Results
5. Discussion
5.1. Summary of Finding
5.2. Challenges of Text-Mining in Healthcare
5.3. Implications
5.4. Limitations and Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Savova, G.K.; Masanz, J.J.; Ogren, P.V.; Zheng, J.; Sohn, S.; Kipper-Schuler, K.C.; Chute, C.G. Mayo Clinical Text Analysis and Knowledge Extraction System (CTAKES): Architecture, Component Evaluation and Applications. J. Am. Med. Inform. Assoc. 2010, 17, 507–513. [Google Scholar] [CrossRef] [PubMed]
- Shickel, B.; Tighe, P.J.; Bihorac, A.; Rashidi, P. Deep EHR: A Survey of Recent Advances in Deep Learning Techniques for Electronic Health Record (EHR) Analysis. IEEE J. Biomed. Health Inform. 2017, 22, 1589–1604. [Google Scholar] [CrossRef] [PubMed]
- Han, S.; Zhang, R.F.; Shi, L.; Richie, R.; Liu, H.; Tseng, A.; Quan, W.; Ryan, N.; Brent, D.; Tsui, F.R. Classifying Social Determinants of Health from Unstructured Electronic Health Records Using Deep Learning-Based Natural Language Processing. J. Biomed. Inform. 2022, 127, 103984. [Google Scholar] [CrossRef]
- Park, J.; Artin, M.G.; Lee, K.E.; Pumpalova, Y.S.; Ingram, M.A.; May, B.L.; Park, M.; Hur, C.; Tatonetti, N.P. Deep Learning on Time Series Laboratory Test Results from Electronic Health Records for Early Detection of Pancreatic Cancer. J. Biomed. Inform. 2022, 131, 104095. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Wang, H.; He, T.; Liao, Y.; Jian, C. Recent Advances in Representation Learning for Electronic Health Records: A Systematic Review. J. Phys. Conf. Ser. 2022, 2188, 012007. [Google Scholar] [CrossRef]
- Li, I.; Pan, J.; Goldwasser, J.; Verma, N.; Wong, W.P.; Nuzumlalı, M.Y.; Rosand, B.; Li, Y.; Zhang, M.; Chang, D. Neural Natural Language Processing for Unstructured Data in Electronic Health Records: A Review. Comput. Sci. Rev. 2022, 46, 100511. [Google Scholar] [CrossRef]
- An, Y.; Xia, X.; Chen, X.; Wu, F.-X.; Wang, J. Chinese Clinical Named Entity Recognition via Multi-Head Self-Attention Based BiLSTM-CRF. Artif. Intell. Med. 2022, 127, 102282. [Google Scholar] [CrossRef]
- Chai, Z.; Jin, H.; Shi, S.; Zhan, S.; Zhuo, L.; Yang, Y. Hierarchical Shared Transfer Learning for Biomedical Named Entity Recognition. BMC Bioinform. 2022, 23, 8. [Google Scholar] [CrossRef]
- Chang, L.; Zhang, R.; Lv, J.; Zhou, W.; Bai, Y. A Review of Biomedical Named Entity Recognition. J. Comput. Methods Sci. Eng. 2022, 22, 893–900. [Google Scholar] [CrossRef]
- Dai, S.; Ding, Y.; Zhang, Z.; Zuo, W.; Huang, X.; Zhu, S. GrantExtractor: Accurate Grant Support Information Extraction from Biomedical Fulltext Based on Bi-LSTM-CRF. IEEE/ACM Trans. Comput. Biol. Bioinform. 2021, 18, 205–215. [Google Scholar] [CrossRef]
- Zhao, A.; Li, Z.; Zhao, G.; Cai, Y.; Xu, Y.; Zhu, X.; Cao, N.; Yang, J. A Pilot Study of WCA (a Chinese Jianpi Herbal Formula) Integrated to Systemic Chemotherapy (CT) in the First-Line Treatment for Advanced Gastric Cancer (AGC). J. Clin. Oncol. 2012, 30, 143. [Google Scholar] [CrossRef]
- Kajiura, S.; Hosokawa, A.; Yoshita, H.; Nakada, N.; Itaya, Y.; Ueda, A.; Ando, T.; Fujinami, H.; Ogawa, K.; Sugiyama, T. Preventive Effect of Rikkunshito, Traditional Japanese Medicine, for Chemotherapy-Induced Nausea and Vomiting. J. Clin. Oncol. 2012, 30, 135. [Google Scholar] [CrossRef]
- Festen, S.; Van der Wal-Huisman, H.; van der Leest, A.H.; Reyners, A.K.; de Bock, G.H.; de Graeff, P.; van Leeuwen, B.L. The Effect of Treatment Modifications by an Onco-Geriatric MDT on One-Year Mortality, Days Spent at Home and Postoperative Complications. J. Geriatr. Oncol. 2021, 12, 779–785. [Google Scholar] [CrossRef]
- Xu, Z.; Zhang, J.; Zhang, Q.; Xuan, Q.; Yip, P.S.F. A Comorbidity Knowledge-Aware Model for Disease Prognostic Prediction. IEEE Trans. Cybern. 2022, 52, 9809–9819. [Google Scholar] [CrossRef] [PubMed]
- Quinn, S.M.; Fernandez, H.; McCorkle, T.; Rogers, R.; Hussain, S.; Ford, C.A.; Barg, F.K.; Ginsburg, K.R.; Amaral, S. The Role of Resilience in Healthcare Transitions among Adolescent Kidney Transplant Recipients. Pediatr. Transplant. 2019, 23, e13559. [Google Scholar] [CrossRef]
- Eligüzel, N.; Çetinkaya, C.; Dereli, T. Application of Named Entity Recognition on Tweets during Earthquake Disaster: A Deep Learning-Based Approach. Soft Comput. 2022, 26, 395–421. [Google Scholar] [CrossRef]
- Nadeau, D.; Sekine, S. A Survey of Named Entity Recognition and Classification. Lingvisticae Investig. 2007, 30, 3–26. [Google Scholar] [CrossRef]
- Elbers, D.C.; La, J.; Minot, J.R.; Gramling, R.; Brophy, M.T.; Do, N.V.; Fillmore, N.R.; Dodds, P.S.; Danforth, C.M. Sentiment Analysis of Medical Record Notes for Lung Cancer Patients at the Department of Veterans Affairs. PLoS ONE 2023, 18, e0280931. [Google Scholar] [CrossRef]
- Liu, Y.; Gu, J.; Goyal, N.; Li, X.; Edunov, S.; Ghazvininejad, M.; Lewis, M.; Zettlemoyer, L. Multilingual Denoising Pre-Training for Neural Machine Translation. Trans. Assoc. Comput. Linguist. 2020, 8, 726–742. [Google Scholar] [CrossRef]
- Guo, Y.; Ma, Z.; Mao, J.; Qian, H.; Zhang, X.; Jiang, H.; Cao, Z.; Dou, Z. Webformer: Pre-Training with Web Pages for Information Retrieval. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; pp. 1502–1512. [Google Scholar]
- Wang, C.; Gao, J.; Rao, H.; Chen, A.; He, J.; Jiao, J.; Zou, N.; Gu, L. Named Entity Recognition (NER) for Chinese Agricultural Diseases and Pests Based on Discourse Topic and Attention Mechanism. Evol. Intell. 2022, 1–10. [Google Scholar] [CrossRef]
- Grishman, R.; Sundheim, B. Message Understanding Conference 6: A Brief History. In Proceedings of the COLING 1996 Volume 1: The 16th International Conference on Computational Linguistics, Copenhagen, Denmark, 5–9 August 1996. [Google Scholar]
- Kim, J.; Kim, Y.; Kang, S. Weakly Labeled Data Augmentation for Social Media Named Entity Recognition. Expert Syst. Appl. 2022, 209, 118217. [Google Scholar] [CrossRef]
- Litkowski, K.C.; Hargraves, O. SemEval-2007 Task 06: Word-Sense Disambiguation of Prepositions. In Proceedings of the Proceedings of the Fourth International Workshop on Semantic Evaluations (SemEval-2007), Prague, Czech Republic, 23–24 June 2007; pp. 24–29. [Google Scholar]
- Wacholder, N.; Ravin, Y.; Choi, M. Disambiguation of Proper Names in Text. In Proceedings of the Fifth Conference on Applied Natural Language Processing, Washington, DC, USA, 31 March–3 April 1997; pp. 202–208. [Google Scholar]
- Mansouri, A.; Affendey, L.S.; Mamat, A. Named Entity Recognition Approaches. Int. J. Comput. Sci. Netw. Secur. 2008, 8, 339–344. [Google Scholar]
- Kripke, S. Naming and Necessity; Semantics of Natural Language; Davidson, D., Harman, G., Eds.; D. Reidel: Dordrecht, The Netherlands, 1972. [Google Scholar]
- Balakrishnan, V.; Shi, Z.; Law, C.L.; Lim, R.; Teh, L.L.; Fan, Y. A Deep Learning Approach in Predicting Products’ Sentiment Ratings: A Comparative Analysis. J. Supercomput. 2022, 78, 7206–7226. [Google Scholar] [CrossRef] [PubMed]
- Severin, W.J.; Tankard, J.W. Communication Theories: Origins, Methods, and Uses in the Mass Media; Longman: New York, NY, USA, 1997. [Google Scholar]
- Vosoughi, S.; Roy, D.; Aral, S. The Spread of True and False News Online. Science 2018, 359, 1146–1151. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Wang, X.; Min, G.; Hao, F.; Chen, C.P. An Efficient Feedback Control Mechanism for Positive/Negative Information Spread in Online Social Networks. IEEE Trans. Cybern. 2020, 52, 87–100. [Google Scholar] [CrossRef] [PubMed]
- Dobber, T.; Metoui, N.; Trilling, D.; Helberger, N.; de Vreese, C. Do (Microtargeted) Deepfakes Have Real Effects on Political Attitudes? Int. J. Press/Politics 2021, 26, 69–91. [Google Scholar] [CrossRef]
- House of Commons. Disinformation and ‘Fake News’: Final Report; House of Commons: London, UK, 2019. [Google Scholar]
- Wardle, C.; Derakhshan, H. Information Disorder: Toward an Interdisciplinary Framework for Research and Policymaking; Council of Europe: Strasbourg, France, 2017. [Google Scholar]
- Jowett, G.S.; O’donnell, V. Propaganda & Persuasion; Sage Publications: Thousand Oaks, CA, USA, 2018. [Google Scholar]
- Alhindi, T.; Pfeiffer, J.; Muresan, S. Fine-Tuned Neural Models for Propaganda Detection at the Sentence and Fragment Levels. arXiv 2019, arXiv:1910.09702. [Google Scholar]
- Barrón-Cedeno, A.; Jaradat, I.; Da San Martino, G.; Nakov, P. Proppy: Organizing the News Based on Their Propagandistic Content. Inf. Process. Manag. 2019, 56, 1849–1864. [Google Scholar] [CrossRef]
- Huang, J.; Li, G.; Huang, Q.; Wu, X. Joint Feature Selection and Classification for Multilabel Learning. IEEE Trans. Cybern. 2017, 48, 876–889. [Google Scholar] [CrossRef]
- Lu, C.; Reddy, C.K.; Ning, Y. Self-Supervised Graph Learning With Hyperbolic Embedding for Temporal Health Event Prediction. IEEE Trans. Cybern. 2023, 53, 2124–2136. [Google Scholar] [CrossRef]
- Yang, B.; Ye, M.; Tan, Q.; Yuen, P.C. Cross-Domain Missingness-Aware Time-Series Adaptation With Similarity Distillation in Medical Applications. IEEE Trans. Cybern. 2022, 52, 3394–3407. [Google Scholar] [CrossRef] [PubMed]
- Yang, Z.; Wu, N.; Liang, Y.; Zhang, H.; Ren, Y. SMSPL: Robust Multimodal Approach to Integrative Analysis of Multiomics Data. IEEE Trans. Cybern. 2022, 52, 2082–2095. [Google Scholar] [CrossRef] [PubMed]
- Mulyadi, A.W.; Jun, E.; Suk, H.-I. Uncertainty-Aware Variational-Recurrent Imputation Network for Clinical Time Series. IEEE Trans. Cybern. 2022, 52, 9684–9694. [Google Scholar] [CrossRef] [PubMed]
- Chiu, J.P.; Nichols, E. Named Entity Recognition with Bidirectional LSTM-CNNs. Trans. Assoc. Comput. Linguist. 2016, 4, 357–370. [Google Scholar] [CrossRef]
- Li, J.; Sun, A.; Han, J.; Li, C. A Survey on Deep Learning for Named Entity Recognition. IEEE Trans. Knowl. Data Eng. 2020, 34, 50–70. [Google Scholar] [CrossRef]
- Yin, X.; Huang, J.X.; Li, Z.; Zhou, X. A Survival Modeling Approach to Biomedical Search Result Diversification Using Wikipedia. IEEE Trans. Knowl. Data Eng. 2013, 25, 1201–1212. [Google Scholar] [CrossRef]
- Yin, D.; Cheng, S.; Pan, B.; Qiao, Y.; Zhao, W.; Wang, D. Chinese Named Entity Recognition Based on Knowledge Based Question Answering System. Appl. Sci. 2022, 12, 5373. [Google Scholar] [CrossRef]
- Tanabe, L.; Xie, N.; Thom, L.H.; Matten, W.; Wilbur, W.J. GENETAG: A Tagged Corpus for Gene/Protein Named Entity Recognition. BMC Bioinform. 2005, 6, S3. [Google Scholar] [CrossRef]
- Kundeti, S.R.; Vijayananda, J.; Mujjiga, S.; Kalyan, M. Clinical Named Entity Recognition: Challenges and Opportunities. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1937–1945. [Google Scholar]
- Song, B.; Li, F.; Liu, Y.; Zeng, X. Deep Learning Methods for Biomedical Named Entity Recognition: A Survey and Qualitative Comparison. Brief. Bioinform. 2021, 22, bbab282. [Google Scholar] [CrossRef]
- Liu, P.; Guo, Y.; Wang, F.; Li, G. Chinese Named Entity Recognition: The State of the Art. Neurocomputing 2022, 473, 37–53. [Google Scholar] [CrossRef]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural Language Processing (Almost) from Scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF Models for Sequence Tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Kim, N.H.; Kim, J.M.; Park, D.M.; Ji, S.R.; Kim, J.W. Analysis of Depression in Social Media Texts through the Patient Health Questionnaire-9 and Natural Language Processing. Digit. Health 2022, 8, 20552076221114204. [Google Scholar] [CrossRef] [PubMed]
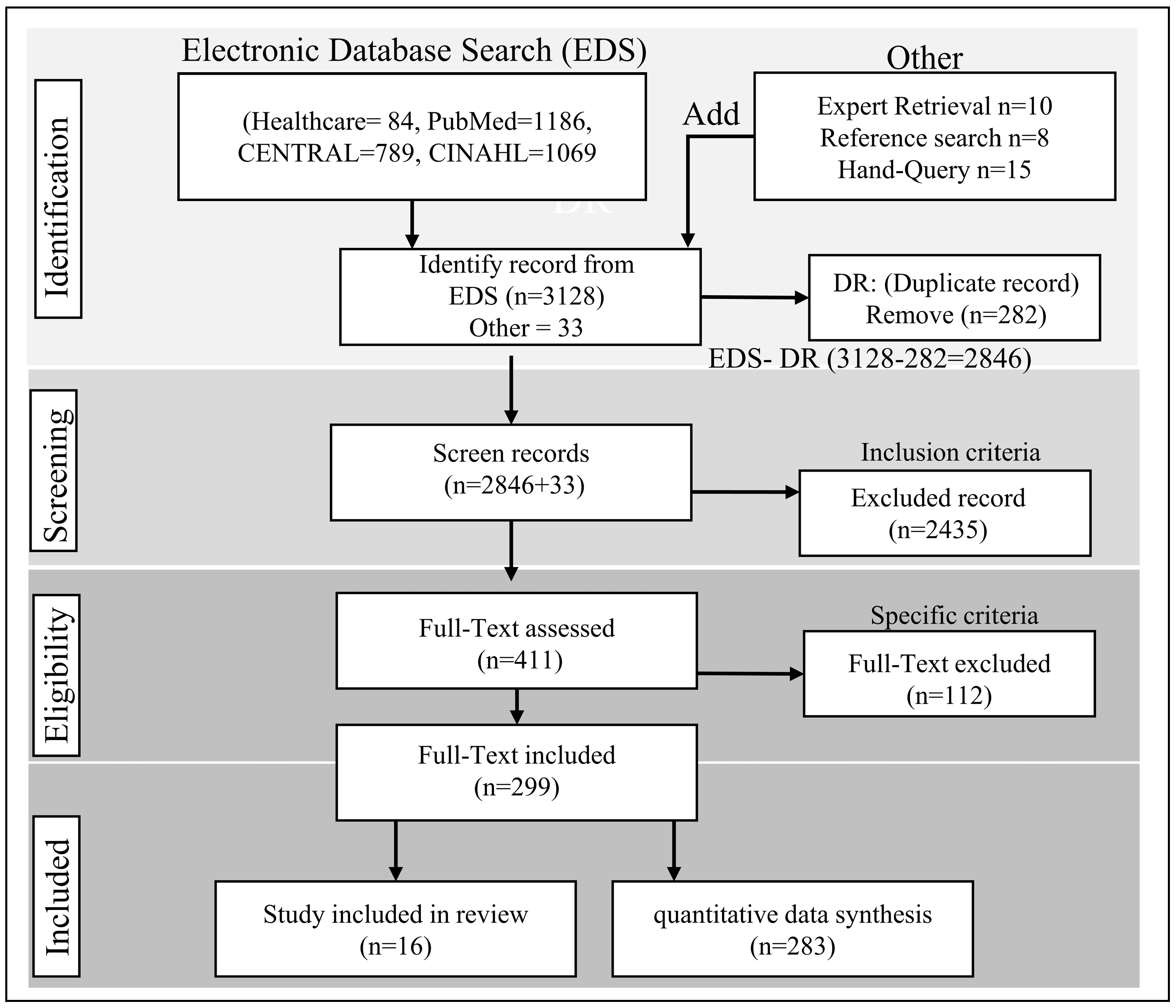
- Moher, D.; Liberati, A.; Tetzlaff, J.; Altman, D.G.; PRISMA Group. The Preferred Reporting Items for Systematic Reviews and Meta-Analyses: The PRISMA Statement. Ann. Intern. Med. 2009, 151, 264–269. [Google Scholar] [CrossRef]
- Haddaway, N.R.; Page, M.J.; Pritchard, C.C.; McGuinness, L.A. PRISMA2020: An R Package and Shiny App for Producing PRISMA 2020-Compliant Flow Diagrams, with Interactivity for Optimised Digital Transparency and Open Synthesis. Campbell Syst. Rev. 2022, 18, e1230. [Google Scholar] [CrossRef]
- Pustejovsky, J.; Ide, N.; Verhagen, M.; Suderman, K. Enhancing Access to Media Collections and Archives Using Computational Linguistic Tools. In CDH@ TLT; CEUR-WS: Bloomington, UK, 2017; pp. 19–28. [Google Scholar]
- Sundheim, B.M. Overview of Results of the MUC-6 Evaluation; Defence Technical Information Center: Fort Belvoir, VA, USA, 1995. [Google Scholar]
- Raza Abidi, S.S.; Goh, A. Applying Knowledge Discovery to Predict Infectious Disease Epidemics. In Proceedings of the PRICAI’98: Topics in Artificial Intelligence: 5th Pacific Rim International Conference on Artificial Intelligence, Singapore, 22–27 November 1998; Springer: Berlin/Heidelberg, Germany, 1998; pp. 170–181. [Google Scholar]
- Cios, K.J.; Moore, G.W. Uniqueness of Medical Data Mining. Artif. Intell. Med. 2002, 26, 1–24. [Google Scholar] [CrossRef]
- Seshia, S.A.; Sadigh, D.; Sastry, S.S. Toward Verified Artificial Intelligence. Commun. ACM 2022, 65, 46–55. [Google Scholar] [CrossRef]
- Krichen, M.; Mihoub, A.; Alzahrani, M.Y.; Adoni, W.Y.H.; Nahhal, T. Are Formal Methods Applicable To Machine Learning And Artificial Intelligence? In Proceedings of the 2022 2nd International Conference of Smart Systems and Emerging Technologies (SMARTTECH), Riyadh, Saudi Arabia, 9–11 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 48–53. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Batmaz, Z.; Yurekli, A.; Bilge, A.; Kaleli, C. A Review on Deep Learning for Recommender Systems: Challenges and Remedies. Artif. Intell. Rev. 2019, 52, 1–37. [Google Scholar] [CrossRef]
- Khan, A.H.; Siddqui, J.; Sohail, S.S. A Survey of Recommender Systems Based on Semi-Supervised Learning. In Proceedings of the International Conference on Innovative Computing and Communications; Springer: Singapore, 2022; pp. 319–327. [Google Scholar]
- Wang, R.; Hou, F.; Cahan, S.; Chen, L.; Jia, X.; Ji, W. Fine-Grained Entity Typing with a Type Taxonomy: A Systematic Review. IEEE Trans. Knowl. Data Eng. 2023, 35, 4794–4812. [Google Scholar] [CrossRef]
- Shen, Y.; Yun, H.; Lipton, Z.C.; Kronrod, Y.; Anandkumar, A. Deep Active Learning for Named Entity Recognition. arXiv 2017, arXiv:1707.05928. [Google Scholar]
- Bridges, J.; Hughes, J.; Farrington, N.; Richardson, A. Cancer Treatment Decision-Making Processes for Older Patients with Complex Needs: A Qualitative Study. BMJ Open 2015, 5, e009674. [Google Scholar] [CrossRef] [PubMed]
- Cho, M.; Ha, J.; Park, C.; Park, S. Combinatorial Feature Embedding Based on CNN and LSTM for Biomedical Named Entity Recognition. J. Biomed. Inform. 2020, 103, 103381. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Chen, H.; Zhao, Y.; Liu, Q.; Yin, D. Learning Tag Dependencies for Sequence Tagging. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence (IJCAI-18), Stockholm, Sweden, 13–19 July 2018; pp. 4581–4587. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A Robustly Optimized Bert Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Islam, M.R.; Kamal, A.R.M.; Sultana, N.; Islam, R.; Moni, M.A. Detecting Depression Using K-Nearest Neighbors (Knn) Classification Technique. In Proceedings of the 2018 International Conference on Computer, Communication, Chemical, Material and Electronic Engineering (IC4ME2), Rajshahi, Bangladesh, 8–9 February 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–4. [Google Scholar]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N. Deep Neural Networks for Acoustic Modeling in Speech Recognition: The Shared Views of Four Research Groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Wang, N.; Yeung, D.-Y. Learning a Deep Compact Image Representation for Visual Tracking. Adv. Neural Inf. Process. Syst. 2013, 26, 809–817. [Google Scholar]
- Vo, N.N.; He, X.; Liu, S.; Xu, G. Deep Learning for Decision Making and the Optimization of Socially Responsible Investments and Portfolio. Decis. Support Syst. 2019, 124, 113097. [Google Scholar] [CrossRef]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent Trends in Deep Learning Based Natural Language Processing. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Reddy, M.; Nardelli, J.C.; Pereira, Y.L.; Oliveira, L.B.; Silva, T.H.; Vasconcelos, M.; Horowitz, M. Higher Education’s Influence on Social Networks and Entrepreneurship in Brazil. Soc. Netw. Anal. Min. 2023, 13, 1–21. [Google Scholar] [CrossRef]
- Khanday, A.M.U.D.; Khan, Q.R.; Rabani, S.T. Identifying Propaganda from Online Social Networks during COVID-19 Using Machine Learning Techniques. Int. J. Inf. Technol. 2021, 13, 115–122. [Google Scholar] [CrossRef]
- Nitish, S.; Darsini, R.; Shashank, G.S.; Tejas, V.; Arya, A. Bidirectional Encoder Representation from Transformers (BERT) Variants for Procedural Long-Form Answer Extraction. In Proceedings of the 2022 12th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 27–28 January 2022; pp. 71–76. [Google Scholar] [CrossRef]
- Habibi, M.; Weber, L.; Neves, M.; Wiegandt, D.L.; Leser, U. Deep Learning with Word Embeddings Improves Biomedical Named Entity Recognition. Bioinformatics 2017, 33, i37–i48. [Google Scholar] [CrossRef] [PubMed]
- Weber, L.; Münchmeyer, J.; Rocktäschel, T.; Habibi, M.; Leser, U. HUNER: Improving Biomedical NER with Pretraining. Bioinformatics 2020, 36, 295–302. [Google Scholar] [CrossRef] [PubMed]
- Wei, C.-H.; Kao, H.-Y.; Lu, Z. PubTator: A Web-Based Text Mining Tool for Assisting Biocuration. Nucleic Acids Res. 2013, 41, W518–W522. [Google Scholar] [CrossRef]
- Thomas, P.; Starlinger, J.; Vowinkel, A.; Arzt, S.; Leser, U. GeneView: A Comprehensive Semantic Search Engine for PubMed. Nucleic Acids Res. 2012, 40, W585–W591. [Google Scholar] [CrossRef]
- Kim, J.-D.; Ohta, T.; Tateisi, Y.; Tsujii, J. GENIA Corpus—A Semantically Annotated Corpus for Bio-Textmining. Bioinformatics 2003, 19, i180–i182. [Google Scholar] [CrossRef] [PubMed]
- Song, Y.; Kim, E.; Lee, G.G.; Yi, B.-K. POSBIOTM—NER: A Trainable Biomedical Named-Entity Recognition System. Bioinformatics 2005, 21, 2794–2796. [Google Scholar] [CrossRef] [PubMed]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef]
- Adewumi, T.P.; Liwicki, F.; Liwicki, M. Exploring Swedish & English FastText Embeddings for NER with the Transformer. arXiv 2020, arXiv:2007.16007. [Google Scholar]
- Sun, C.; Yang, Z.; Luo, L.; Wang, L.; Zhang, Y.; Lin, H.; Wang, J. A Deep Learning Approach with Deep Contextualized Word Representations for Chemical–Protein Interaction Extraction from Biomedical Literature. IEEE Access 2019, 7, 151034–151046. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Zhou, Y. Pro-ISIS Fanboys Network Analysis and Attack Detection through Twitter Data. In Proceedings of the 2017 IEEE 2nd International Conference on Big Data Analysis (ICBDA), Beijing, China, 10–12 March 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 386–390. [Google Scholar]
- Sarwar, A.; Ali, M.; Manhas, J.; Sharma, V. Diagnosis of Diabetes Type-II Using Hybrid Machine Learning Based Ensemble Model. Int. J. Inf. Technol. 2020, 12, 419–428. [Google Scholar] [CrossRef]
- Gao, J.; Zheng, P.; Jia, Y.; Chen, H.; Mao, Y.; Chen, S.; Wang, Y.; Fu, H.; Dai, J. Mental Health Problems and Social Media Exposure during COVID-19 Outbreak. PLoS ONE 2020, 15, e0231924. [Google Scholar]
- Al-Zaman, M.S. COVID-19-Related Social Media Fake News in India. J. Media 2021, 2, 100–114. [Google Scholar] [CrossRef]
- Gisondi, M.A.; Barber, R.; Faust, J.S.; Raja, A.; Strehlow, M.C.; Westafer, L.M.; Gottlieb, M. A Deadly Infodemic: Social Media and the Power of COVID-19 Misinformation. J. Med. Internet Res. 2022, 24, e35552. [Google Scholar] [CrossRef]
- Mane, H.; Yue, X.; Yu, W.; Doig, A.C.; Wei, H.; Delcid, N.; Harris, A.-G.; Nguyen, T.T.; Nguyen, Q.C. Examination of the Public’s Reaction on Twitter to the Over-Turning of Roe v Wade and Abortion Bans. Healthcare 2022, 10, 2390. [Google Scholar] [CrossRef]
- Ong, S.-Q.; Pauzi, M.B.M.; Gan, K.H. Text Mining and Determinants of Sentiments towards the COVID-19 Vaccine Booster of Twitter Users in Malaysia. Healthcare 2022, 10, 994. [Google Scholar] [CrossRef]
- Reshi, A.A.; Rustam, F.; Aljedaani, W.; Shafi, S.; Alhossan, A.; Alrabiah, Z.; Ahmad, A.; Alsuwailem, H.; Almangour, T.A.; Alshammari, M.A.; et al. COVID-19 Vaccination-Related Sentiments Analysis: A Case Study Using Worldwide Twitter Dataset. Healthcare 2022, 10, 411. [Google Scholar] [CrossRef]
- Rahim, A.I.A.; Ibrahim, M.I.; Chua, S.-L.; Musa, K.I. Hospital Facebook Reviews Analysis Using a Machine Learning Sentiment Analyzer and Quality Classifier. Healthcare 2021, 9, 1679. [Google Scholar] [CrossRef]
- Lee, K.; Mileski, M.; Fohn, J.; Frye, L.; Brooks, L. Facilitators and Barriers Surrounding the Role of Administration in Employee Job Satisfaction in Long-Term Care Facilities: A Systematic Review. Healthcare 2020, 8, 360. [Google Scholar] [CrossRef]
- Shah, A.M.; Yan, X.; Qayyum, A.; Naqvi, R.A.; Shah, S.J. Mining Topic and Sentiment Dynamics in Physician Rating Websites during the Early Wave of the COVID-19 Pandemic: Machine Learning Approach. Int. J. Med. Inform. 2021, 149, 104434. [Google Scholar] [CrossRef]
- Hu, Y.; Wen, G.; Liao, H.; Wang, C.; Dai, D.; Yu, Z. Automatic Construction of Chinese Herbal Prescriptions From Tongue Images Using CNNs and Auxiliary Latent Therapy Topics. IEEE Trans. Cybern. 2021, 51, 708–721. [Google Scholar] [CrossRef] [PubMed]
- Rodriguez, N.E.; Nguyen, M.; McInnes, B.T. Effects of Data and Entity Ablation on Multitask Learning Models for Biomedical Entity Recognition. J. Biomed. Inform. 2022, 130, 104062. [Google Scholar] [CrossRef] [PubMed]
- Caruana, R. Multitask Learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Lin, Y.; Yang, S.; Stoyanov, V.; Ji, H. A Multi-Lingual Multi-Task Architecture for Low-Resource Sequence Labeling. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Volume 1: Long Papers. pp. 799–809. [Google Scholar]
- Wang, P.; Xu, B.; Xu, J.; Tian, G.; Liu, C.-L.; Hao, H. Semantic Expansion Using Word Embedding Clustering and Convolutional Neural Network for Improving Short Text Classification. Neurocomputing 2016, 174, 806–814. [Google Scholar] [CrossRef]
- Zhang, Y.; Lu, W.; Ou, W.; Zhang, G.; Zhang, X.; Cheng, J.; Zhang, W. Chinese Medical Question Answer Selection via Hybrid Models Based on CNN and GRU. Multimed. Tools Appl. 2020, 79, 14751–14776. [Google Scholar] [CrossRef]
- Lv, J.; Zhang, Z.; Jin, L.; Li, S.; Li, X.; Xu, G.; Sun, X. Trigger Is Non-Central: Jointly Event Extraction via Label-Aware Representations with Multi-Task Learning. Knowl.-Based Syst. 2022, 252, 109480. [Google Scholar] [CrossRef]
- Chai, Z.; Jin, H.; Shi, S.; Zhan, S.; Zhuo, L.; Yang, Y.; Lian, Q. Noise Reduction Learning Based on XLNet-CRF for Biomedical Named Entity Recognition. IEEE/ACM Trans. Comput. Biol. Bioinform. 2022, 20, 595–605. [Google Scholar] [CrossRef] [PubMed]
- Hanisch, D.; Fundel, K.; Mevissen, H.-T.; Zimmer, R.; Fluck, J. ProMiner: Rule-Based Protein and Gene Entity Recognition. BMC Bioinform. 2005, 6, S14. [Google Scholar] [CrossRef]
- Crichton, G.; Pyysalo, S.; Chiu, B.; Korhonen, A. A Neural Network Multi-Task Learning Approach to Biomedical Named Entity Recognition. BMC Bioinform. 2017, 18, 368. [Google Scholar] [CrossRef]
- Leemans, S.J.; van Zelst, S.J.; Lu, X. Partial-Order-Based Process Mining: A Survey and Outlook. Knowl. Inf. Syst. 2023, 65, 1–29. [Google Scholar] [CrossRef]
- Fahrenkrog-Petersen, S.A.; Kabierski, M.; van der Aa, H.; Weidlich, M. Semantics-Aware Mechanisms for Control-Flow Anonymization in Process Mining. Inf. Syst. 2023, 114, 102169. [Google Scholar] [CrossRef]
- Elhaj, H.; Achour, N.; Tania, M.H.; Aciksari, K. A Comparative Study of Supervised Machine Learning Approaches to Predict Patient Triage Outcomes in Hospital Emergency Departments. Array 2023, 17, 100281. [Google Scholar] [CrossRef]
- Pandya, S.; Gadekallu, T.R.; Reddy, P.K.; Wang, W.; Alazab, M. InfusedHeart: A Novel Knowledge-Infused Learning Framework for Diagnosis of Cardiovascular Events. IEEE Trans. Comput. Soc. Syst. 2022. [Google Scholar] [CrossRef]
- Ozmen Garibay, O.; Winslow, B.; Andolina, S.; Antona, M.; Bodenschatz, A.; Coursaris, C.; Falco, G.; Fiore, S.M.; Garibay, I.; Grieman, K. Six Human-Centered Artificial Intelligence Grand Challenges. Int. J. Hum.-Comput. Interact. 2023, 39, 391–437. [Google Scholar] [CrossRef]
- Albawi, S.; Arif, M.H.; Waleed, J. Skin Cancer Classification Dermatologist-Level Based on Deep Learning Model. Acta Scientiarum. Technol. 2023, 45, e61531. [Google Scholar] [CrossRef]
- Chia, M.A.; Hersch, F.; Sayres, R.; Bavishi, P.; Tiwari, R.; Keane, P.A.; Turner, A.W. Validation of a Deep Learning System for the Detection of Diabetic Retinopathy in Indigenous Australians. Br. J. Ophthalmol. 2023, 63, 2092-F0081. [Google Scholar] [CrossRef] [PubMed]
- Peng, H.; Wu, C.; Nguyen, D.; Schuemann, J.; Mairani, A.; Pu, Y.; Jiang, S. Recent Advancements of Artificial Intelligence in Particle Therapy. IEEE Trans. Radiat. Plasma Med. Sci. 2023, 7, 213–224. [Google Scholar] [CrossRef]
- Liu, S.; Wang, X.; Xiang, Y.; Xu, H.; Wang, H.; Tang, B. Multi-Channel Fusion LSTM for Medical Event Prediction Using EHRs. J. Biomed. Inform. 2022, 127, 104011. [Google Scholar] [CrossRef]
- Biswas, S.; Dash, S. LSTM-CNN Deep Learning–Based Hybrid System for Real-Time COVID-19 Data Analysis and Prediction Using Twitter Data. In Assessing COVID-19 and Other Pandemics and Epidemics Using Computational Modelling and Data Analysis; Springer: Cham, Switzerland, 2022; pp. 239–257. [Google Scholar]
- Amethiya, Y.; Pipariya, P.; Patel, S.; Shah, M. Comparative Analysis of Breast Cancer Detection Using Machine Learning and Biosensors. Intell. Med. 2022, 2, 69–81. [Google Scholar] [CrossRef]
- Dubin, J.R.; Simon, S.D.; Norrell, K.; Perera, J.; Gowen, J.; Cil, A. Risk of Recall among Medical Devices Undergoing US Food and Drug Administration 510 (k) Clearance and Premarket Approval, 2008–2017. JAMA Netw. Open 2021, 4, e217274. [Google Scholar] [CrossRef]
- Sayres, R.; Taly, A.; Rahimy, E.; Blumer, K.; Coz, D.; Hammel, N.; Krause, J.; Narayanaswamy, A.; Rastegar, Z.; Wu, D. Using a Deep Learning Algorithm and Integrated Gradients Explanation to Assist Grading for Diabetic Retinopathy. Ophthalmology 2019, 126, 552–564. [Google Scholar] [CrossRef] [PubMed]
- Wong, K.C.; Moradi, M.; Wu, J.; Syeda-Mahmood, T. Identifying Disease-Free Chest x-Ray Images with Deep Transfer Learning. In Medical Imaging 2019: Computer-Aided Diagnosis; SPIE: Bellingham, WA, USA, 2019; Volume 10950, pp. 179–184. [Google Scholar]
- Wu, T.; Sultan, L.R.; Tian, J.; Cary, T.W.; Sehgal, C.M. Machine Learning for Diagnostic Ultrasound of Triple-Negative Breast Cancer. Breast Cancer Res. Treat. 2019, 173, 365–373. [Google Scholar] [CrossRef] [PubMed]
- Keren, L.; Bosse, M.; Marquez, D.; Angoshtari, R.; Jain, S.; Varma, S.; Yang, S.-R.; Kurian, A.; Van Valen, D.; West, R. A Structured Tumor-Immune Microenvironment in Triple Negative Breast Cancer Revealed by Multiplexed Ion Beam Imaging. Cell 2018, 174, 1373–1387. [Google Scholar] [CrossRef] [PubMed]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-Level Classification of Skin Cancer with Deep Neural Networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef]
- Subbiah, V. The next Generation of Evidence-Based Medicine. Nat. Med. 2023, 29, 49–58. [Google Scholar] [CrossRef]
- Zhuo, J.; Cao, Y.; Zhu, J.; Zhang, B.; Nie, Z. Segment-Level Sequence Modeling Using Gated Recursive Semi-Markov Conditional Random Fields. In Proceedings of the Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Volume 1: Long Papers. pp. 1413–1423. [Google Scholar]
- Rei, M.; Crichton, G.K.; Pyysalo, S. Attending to Characters in Neural Sequence Labeling Models. arXiv 2016, arXiv:1611.04361. [Google Scholar]
- Naim, J.; Hossain, T.; Tasneem, F.; Chy, A.N.; Aono, M. Leveraging Fusion of Sequence Tagging Models for Toxic Spans Detection. Neurocomputing 2022, 500, 688–702. [Google Scholar] [CrossRef]
- Luo, Y.; Xiao, F.; Zhao, H. Hierarchical Contextualized Representation for Named Entity Recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8441–8448. [Google Scholar]
- Aguilar, G.; Maharjan, S.; López-Monroy, A.P.; Solorio, T. A Multi-Task Approach for Named Entity Recognition in Social Media Data. arXiv 2019, arXiv:1906.04135. [Google Scholar]
- Graves, A.; Schmidhuber, J. Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef]
- Tjandra, A.; Sakti, S.; Manurung, R.; Adriani, M.; Nakamura, S. Gated Recurrent Neural Tensor Network. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 448–455. [Google Scholar]
- Yuan, M.; Ren, J. Numerical Feature Transformation-Based Sequence Generation Model for Multi-Disease Diagnosis. Int. J. Pattern Recognit. Artif. Intell. 2021, 35, 2159034. [Google Scholar] [CrossRef]
- Liu, Y.; Gou, X. A Text Classification Method Based on Graph Attention Networks. In Proceedings of the 2021 International Conference on Information Technology and Biomedical Engineering (ICITBE), Nanchang, China, 24–26 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 35–39. [Google Scholar]
- Schuster, M.; Paliwal, K.K. Bidirectional Recurrent Neural Networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Zhao, Q.; Xu, D.; Li, J.; Zhao, L.; Rajput, F.A. Knowledge Guided Distance Supervision for Biomedical Relation Extraction in Chinese Electronic Medical Records. Expert Syst. Appl. 2022, 204, 117606. [Google Scholar] [CrossRef]
- Chen, Y.; Yao, Z.; Chi, H.; Gabbay, D.; Yuan, B.; Bentzen, B.; Liao, B. BTPK-Based Learning: An Interpretable Method for Named Entity Recognition. arXiv 2022, arXiv:2201.09523. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations Using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Liu, X.; Cheng, M.; Zhang, H.; Hsieh, C.-J. Towards Robust Neural Networks via Random Self-Ensemble. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 369–385. [Google Scholar]
- Lin, J.C.-W.; Shao, Y.; Djenouri, Y.; Yun, U. ASRNN: A Recurrent Neural Network with an Attention Model for Sequence Labeling. Knowl.-Based Syst. 2021, 212, 106548. [Google Scholar] [CrossRef]
- Luong, M.-T.; Manning, C.D. Achieving Open Vocabulary Neural Machine Translation with Hybrid Word-Character Models. arXiv 2016, arXiv:1604.00788. [Google Scholar]
- Xiangyu, X.; Tong, Z.; Wei, Y.; Jinglei, Z.; Rui, X.; Shikun, Z. A Hybrid Character Representation for Chinese Event Detection. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–8. [Google Scholar]
- Ho, K.K.; Chan, J.Y.; Chiu, D.K. Fake News and Misinformation During the Pandemic: What We Know and What We Do Not Know. IT Prof. 2022, 24, 19–24. [Google Scholar] [CrossRef]
- Zheng, S.; Wang, F.; Bao, H.; Hao, Y.; Zhou, P.; Xu, B. Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme. arXiv 2017, arXiv:1706.05075. [Google Scholar]
- Chen, K.; Song, X.; Yuan, H.; Ren, X. Fully Convolutional Encoder-Decoder With an Attention Mechanism for Practical Pedestrian Trajectory Prediction. IEEE Trans. Intell. Transp. Syst. 2022, 23, 20046–20060. [Google Scholar] [CrossRef]
- Horiguchi, S.; Fujita, Y.; Watanabe, S.; Xue, Y.; García, P. Encoder-Decoder Based Attractors for End-to-End Neural Diarization. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 1493–1507. [Google Scholar] [CrossRef]
- Dos Santos, C.; Zadrozny, B. Learning Character-Level Representations for Part-of-Speech Tagging. In Proceedings of the International Conference on Machine Learning, PMLR, Beijing, China, 21–26 June 2014; pp. 1818–1826. [Google Scholar]
- Nguyen, T.-S.; Nguyen, L.-M. Nested Named Entity Recognition Using Multilayer Recurrent Neural Networks. In Proceedings of the International Conference of the Pacific Association for Computational Linguistics, Yangon, Myanmar, 16–18 August 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 233–246. [Google Scholar]
- Katiyar, A.; Cardie, C. Nested Named Entity Recognition Revisited. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Volume 1. [Google Scholar]
- Jagfeld, G.; Jenne, S.; Vu, N.T. Sequence-to-Sequence Models for Data-to-Text Natural Language Generation: Word-vs. Character-Based Processing and Output Diversity. arXiv 2018, arXiv:1810.04864. [Google Scholar]
- Gao, T.; Fisch, A.; Chen, D. Making Pre-Trained Language Models Better Few-Shot Learners. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Online, 1–6 August 2021; Volume 1: Long Papers. Association for Computational Linguistics: Cedarville, OH, USA, 2021; pp. 3816–3830. [Google Scholar]
- Qiu, X.; Sun, T.; Xu, Y.; Shao, Y.; Dai, N.; Huang, X. Pre-Trained Models for Natural Language Processing: A Survey. Sci. China Technol. Sci. 2020, 63, 1872–1897. [Google Scholar] [CrossRef]
- Tsipouras, M.G.; Exarchos, T.P.; Fotiadis, D.I.; Kotsia, A.P.; Vakalis, K.V.; Naka, K.K.; Michalis, L.K. Automated Diagnosis of Coronary Artery Disease Based on Data Mining and Fuzzy Modeling. IEEE Trans. Inf. Technol. Biomed. 2008, 12, 447–458. [Google Scholar] [CrossRef]
- Rakha, E.A.; Reis-Filho, J.S.; Ellis, I.O. Basal-like Breast Cancer: A Critical Review. J. Clin. Oncol. 2008, 26, 2568–2581. [Google Scholar] [CrossRef] [PubMed]
- Tapak, L.; Mahjub, H.; Hamidi, O.; Poorolajal, J. Real-Data Comparison of Data Mining Methods in Prediction of Diabetes in Iran. Healthc. Inform. Res. 2013, 19, 177–185. [Google Scholar] [CrossRef] [PubMed]
- Iqbal, U.; Hsu, C.-K.; Nguyen, P.A.A.; Clinciu, D.L.; Lu, R.; Syed-Abdul, S.; Yang, H.-C.; Wang, Y.-C.; Huang, C.-Y.; Huang, C.-W. Cancer-Disease Associations: A Visualization and Animation through Medical Big Data. Comput. Methods Programs Biomed. 2016, 127, 44–51. [Google Scholar] [CrossRef]
- Agrawal, A.; Misra, S.; Narayanan, R.; Polepeddi, L.; Choudhary, A. Lung Cancer Survival Prediction Using Ensemble Data Mining on SEER Data. Sci. Program. 2012, 20, 29–42. [Google Scholar] [CrossRef]
- Yeh, J.-Y.; Wu, T.-H.; Tsao, C.-W. Using Data Mining Techniques to Predict Hospitalization of Hemodialysis Patients. Decis. Support Syst. 2011, 50, 439–448. [Google Scholar] [CrossRef]
- Arvisais-Anhalt, S.; Lehmann, C.U.; Bishop, J.A.; Balani, J.; Boutte, L.; Morales, M.; Park, J.Y.; Araj, E. Searching Full-Text Anatomic Pathology Reports Using Business Intelligence Software. J. Pathol. Inform. 2022, 13, 100014. [Google Scholar] [CrossRef]
- Pur, A.; Bohanec, M.; Lavrač, N.; Cestnik, B. Primary Health-Care Network Monitoring: A Hierarchical Resource Allocation Modeling Approach. Int. J. Health Plan. Manag. 2010, 25, 119–135. [Google Scholar] [CrossRef]
- Koskela, T.-H.; Ryynanen, O.-P.; Soini, E.J. Risk Factors for Persistent Frequent Use of the Primary Health Care Services among Frequent Attenders: A Bayesian Approach. Scand. J. Prim. Health Care 2010, 28, 55–61. [Google Scholar] [CrossRef] [PubMed]
- Oliwa, T.; Maron, S.B.; Chase, L.M.; Lomnicki, S.; Catenacci, D.V.; Furner, B.; Volchenboum, S.L. Obtaining Knowledge in Pathology Reports through a Natural Language Processing Approach with Classification, Named-Entity Recognition, and Relation-Extraction Heuristics. JCO Clin. Cancer Inform. 2019, 3, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Nimmagadda, S.L.; Dreher, H.V. On Robust Methodologies for Managing Public Health Care Systems. Int. J. Environ. Res. Public Health 2014, 11, 1106–1140. [Google Scholar] [CrossRef] [PubMed]
- Kostkova, P.; Fowler, D.; Wiseman, S.; Weinberg, J.R. Major Infection Events over 5 Years: How Is Media Coverage Influencing Online Information Needs of Health Care Professionals and the Public? J. Med. Internet Res. 2013, 15, e107. [Google Scholar] [CrossRef]
- Rathore, M.M.; Ahmad, A.; Paul, A.; Wan, J.; Zhang, D. Real-Time Medical Emergency Response System: Exploiting IoT and Big Data for Public Health. J. Med. Syst. 2016, 40, 283. [Google Scholar] [CrossRef]
- Lavrač, N.; Bohanec, M.; Pur, A.; Cestnik, B.; Debeljak, M.; Kobler, A. Data Mining and Visualization for Decision Support and Modeling of Public Health-Care Resources. J. Biomed. Inform. 2007, 40, 438–447. [Google Scholar] [CrossRef]
- Zhang, T.; Wang, Y.; Wang, X.; Yang, Y.; Ye, Y. Constructing Fine-Grained Entity Recognition Corpora Based on Clinical Records of Traditional Chinese Medicine. BMC Med. Inform. Decis. Mak. 2020, 20, 64. [Google Scholar] [CrossRef]
- Jones, R.A.; Hollen, P.J.; Wenzel, J.; Weiss, G.; Song, D.; Sims, T.; Petroni, G. Understanding Advanced Prostate Cancer Decision-Making Utilizing an Interactive Decision Aid. Cancer Nurs. 2018, 41, 2. [Google Scholar] [CrossRef]
- Kishwar, A.; Zafar, A. Fake News Detection on Pakistani News Using Machine Learning and Deep Learning. Expert Syst. Appl. 2023, 211, 118558. [Google Scholar] [CrossRef]
- Shah, A.; Yan, X.B.; Shah, S.A. Tracking Patients Healthcare Experiences during the COVID-19 Outbreak: Topic Modeling and Sentiment Analysis of Doctor Reviews. J. Eng. Res. 2021, 9, 219–239. [Google Scholar] [CrossRef]
- Shah, A.M.; Naqvi, R.A.; Jeong, O.-R. Detecting Topic and Sentiment Trends in Physician Rating Websites: Analysis of Online Reviews Using 3-Wave Datasets. Int. J. Environ. Res. Public Health 2021, 18, 4743. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Corpus | Date | Text-Source | Tag | Data URL 1 |
|---|---|---|---|---|
| MUC-2, MUC-3, MUC-4, | 1995 | MUC Data Sets | https://www-nlpir.nist.gov/related_projects/ (accessed on 5 January 2023) | |
| MUC-6 | 1995 | Wall Street Journal | 7 | https://catalog.ldc.upenn.edu/LDC2003T13 (accessed on 5 January 2023) |
| MUC-6 Plus | 1995 | Additional news | 7 | https://catalog.ldc.upenn.edu/LDC96T10 (accessed on 5 January 2023) |
| MUC-7 | 1997 | New York Times news | 7 | https://catalog.ldc.upenn.edu/LDC2001T02 (accessed on 5 January 2023) |
| CoNLL03 | 2003 | Reuters news | 4 | https://www.clips.uantwerpen.be/conll2003/ner/ (accessed on 5 January 2023) |
| ACE 2003 | 2003 | Wikipedia | 7 | https://www-nlpir.nist.gov/ (accessed on 5 January 2023) |
| ACE 2005 | 2003 | Wikipedia | 7 | https://catalog.ldc.upenn.edu/LDC2004T09 (accessed on 5 January 2023) |
| OntoNotes | 2005 | Wikipedia | 18 | https://catalog.ldc.upenn.edu/LDC2013T19 (accessed on 5 January 2023) |
| BTC | 2016 | - | http://www.i2b2.org (accessed on 5 January 2023) | |
| i2b2-2006 | 2007 | Medical | - | https://www.i2b2.org/NLP/DataSets/Main.php (accessed on 5 January 2023) |
| CADEC | 2015 | Medical | - | http://data.csiro.au/ (accessed on 5 January 2023) |
| CONLL03 | 2003 | News | 4 | https://github.com/synalp/NER/tree/master/corpus/CoNLL-2003 (accessed on 5 January 2023) |
| BiLingual NER | ||||
| UNER | 2008 | SSEAL | URDU | http://www.iiu.edu.pk/?page_id=5181 (accessed on 5 January 2023) |
| MK-PUCIT | 2019 | - | URDU | https://www.dropbox.com/sh/1ivw7ykm2tugg94/AAB9t5wnN7FynESpo7TjJW8la (accessed on 5 January 2023) |
| ACE-03 | 2003 | Wikipedia | Ch/Ar | https://catalog.ldc.upenn.edu/LDC2004T09 (accessed on 5 January 2023) |
| ACE-04 | 2004 | Wikipedia | Ch/Ar | https://catalog.ldc.upenn.edu/LDC2005T09 (accessed on 5 January 2023) |
| ACE-07 | 2007 | Wikipedia | Ch/Ar | https://catalog.ldc.upenn.edu/LDC2006T06 (accessed on 5 January 2023) |
| QUAERO | - | French Medical | Fr | https://quaerofrenchmed.limsi.fr/ (accessed on 5 January 2023) |
| KIND | - | - | It | https://github.com/dhfbk/KIND (accessed on 5 January 2023) |
| hr500k | - | - | Cr | http://hdl.handle.net/11356/1183 (accessed on 5 January 2023) |
| CoNLL03 | 2003 | German | Gr | https://www.clips.uantwerpen.be/conll2003/ner/ (accessed on 5 January 2023) |
| CoNLL03 | 2003 | Dutch | Du | https://www.clips.uantwerpen.be/conll2002/ner/ (accessed on 5 January 2023) |
| Reference | Year | Method | Application | Field | Limitations | Key Features |
|---|---|---|---|---|---|---|
| [115] | 2023 | Neural network (NN) | Develops and implements a NN-based method for skin cancer prediction | Dermatology | This investigation failed to identify the optimal CNN architecture. | Image recognition |
| [116] | 2023 | DL systems | Comparing the performance of a DL against a retinal specialist vision-threatening all-cause referable | Ophthalmology | This study does not use: DLS-driven DR screening, a focus on probable validation, and real-world implementation. | Image recognition |
| [117] | 2022 | Neural network | Image segmentation review and six optimizations of the radiotherapy dose. | Oncology | Many-to-one mapping; intrinsic fitting error; patient-specific tissue heterogeneities | Image recognition |
| [118] | 2022 | Multi-channel LSTM | To signify a medical event that is strongly linked to the prediction task using EHRs | Medical event prediction | Fast knowledge and effectively managing the clinical result from intricate and heterogeneous EHRs | NLP |
| [119] | 2022 | LSTM-CNN | Twitter analysis and prediction of real-time COVID-19 data | Pathology | State-of-the-art results, implementing bidirectional LSTM | NLP |
| [120] | 2022 | ResNet-CNN-BiLSTM | To conclude, what kind of cyberbullying is being committed, and classify the individuals involved | Psychological care | The validity and reliability of the data, as well as biosensor and biomarker-based techniques, are affected by a number of factors, such as sample quality, instrument accuracy, and environmental conditions. | NLP |
| [121] | 2021 | NN | Diagnosing cardiovascular diseases using cardiac MRI images | Radiology | Lack of generalizability of the results, which ends with lesion classification, is not automated here during MRI analysis. | Image recognition |
| [122] | 2019 | NN-integrated gradients | Grading diabetic retinopathy more rapidly and precisely | Ophthalmology | Insufficient discussion or interpretation of the results. It is likely that the length of the grading process will affect the experience in some way. | Image recognition |
| [123] | 2019 | NN | To regulate which of the X-ray images showed a healthy chest | Radiology | Optimization of the probability threshold for classification of an Inception-ResNet-v2 model trained on ImageNet | Image recognition |
| [124] | 2019 | LR (Logistic regression) | Ultrasound inspections are used to establish the criteria for classifying breast cancer known as triple negative (TN). | Radiology | Lacking computerized segmentation of the masses, fewer people are involved in sampling bias. | Image recognition |
| [125] | 2018 | - | Multi-step processing, including deep-learning-based segmentation, revealed variability in the composition of tumor-immune | It offers a unique challenge when it comes to de-noising MIBI-TOF data due to two properties: Low intensity values, low abundant antigens, and signal is sparse and pixelated | Image recognition | |
| [126] | 2017 | Neural network | To achieve dermatologist-level accuracy when diagnosing skin cancer | Dermatology | CNNs require large amounts of data to train. Collecting large amount of labeled skin cancer images is difficult and time-consuming. | Image recognition |
| Work | Input Representation | Encoder/Decoder 1 | F1-Score | |
|---|---|---|---|---|
| Word | Character | |||
| [129,130] | Google Word2vec | LSTM | LSTM/CRF | 0.8409 |
| [131] | Globel Vector | LSTM | LSTM/CRF | 0.9337 |
| [132] | Twitter Word2vec | CNN | LSTM/CRF | 0.4186 |
| [88] | WordPiece | - | Transformer/Softmax | 0.9208 |
| Author | Symptom 1 | Data Source | Topic Relation |
|---|---|---|---|
| Tsipouras et al. [155] | Coronary disease | Cardiology department University Hospital Greece | Coronary heart disease treatment |
| Rakha et al. [156] | Cancer | Breast cancer data set, Wisconsin | Breast cancer classification patients with innovative algorithm |
| Tapak et al. [157] | Diabetes | Iranian national non-communicable diseases risk factors surveillance | Evaluation of diabetes classification accuracy algorithms |
| Iqbal et al. [158] | Cancer | Taiwan National Health Insurance Database | Visualization tool for cancer |
| Agrawal et al. [159] | Lung cancer | SEER Program of the National Cancer Institute, USA | Lung cancer survival prediction |
| Yeh et al. [160] | Other | Hemodialysis center in Taiwan | Hospitalization prediction of Hemodialysis patients |
| Author | Research 1 | Data Source | Limitation Analysis |
|---|---|---|---|
| Arvisais et al. [161] | cloud computing | Not specified | Reports from radiology repositories |
| Pur et al. [162] | Utilization, quality, and costs of healthcare | National Institute of Public Health; Health Care Institute, Celje; Slovenian | Framework and model for monitoring HC networks’ resource allocation |
| Koskela et al. [163] | Management of patients | Tampere Health Centre, Finland | Predicting persistent healthcare attendance by examining risk factors |
| Oliwa et al. [164] | Healthcare quality | Pathology company in Australia | Efficient pathology ordering organization |
| Author | Research | Data Source | Limitation Analysis |
|---|---|---|---|
| Nimmagada et al. [165] | Healthcare | World Health Organization | Programs designed to prevent health problems |
| Kostkova et al. [166] | Healthcare quality | National electronic Library of Infection | Public and professional information seeking behavior |
| Rathore et al. [167] | Healthcare data | Internet of Things and big data for real-time emergency response | UCI machine learning depository |
| Lavrač et al. [168] | Healthcare quality | Slovenian national Institute of Public Health | Innovative use of data mining |
| 1 Metrics | Tangible | Reliability | Responsive | Assurance | Empathy | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NB | SVM | LR | NB | SVM | LR | NB | SVM | LR | NB | SVM | LR | NB | SVM | LR | |
| Binary relevance | |||||||||||||||
| Acc | 0.675 | 0.7 | 0.68 | 0.69 | 0.71 | 0.71 | 0.63 | 0.64 | 0.65 | 0.64 | 0.71 | 0.73 | 0.78 | 0.78 | 0.79 |
| F1 | 0.39 | 0.58 | 0.47 | 0.81 | 0.82 | 0.81 | 0.48 | 0.55 | 0.54 | 0.68 | 0.72 | 0.73 | 0.87 | 0.87 | 0.88 |
| P | 0.76 | 0.69 | 0.67 | 0.68 | 0.76 | 0.71 | 0.66 | 0.61 | 0.67 | 0.6 | 0.71 | 0.71 | 0.78 | 0.8 | 0.79 |
| R | 0.27 | 0.51 | 0.36 | 0.99 | 0.88 | 0.97 | 0.39 | 0.51 | 0.46 | 0.79 | 0.73 | 0.75 | 1 | 0.8 | 0.99 |
| Label powerset | |||||||||||||||
| Acc | 0.66 | 0.6 | 0.64 | 0.69 | 0.68 | 0.7 | 0.55 | 0.61 | 0.61 | 0.56 | 0.63 | 0.67 | 0.78 | 0.78 | 0.8 |
| F1 | 0.53 | 0.52 | 0.48 | 0.81 | 0.79 | 0.81 | 0.63 | 0.61 | 0.62 | 0.67 | 0.68 | 0.67 | 0.87 | 0.87 | 0.88 |
| P | 0.61 | 0.61 | 0.57 | 0.69 | 0.72 | 0.71 | 0.5 | 0.55 | 0.55 | 0.52 | 0.59 | 0.56 | 0.78 | 0.81 | 0.8 |
| R | 0.49 | 0.4 | 0.43 | 0.99 | 0.88 | 0.92 | 0.87 | 0.68 | 0.73 | 0.94 | 0.81 | 0.82 | 0.9 | 0.97 | 0.9 |
| Classifier chain | |||||||||||||||
| Acc | 0.67 | 0.71 | 0.68 | 0.69 | 0.73 | 0.71 | 0.63 | 0.65 | 0.64 | 0.65 | 0.63 | 0.71 | 0.78 | 0.79 | 0.79 |
| F1 | 0.399 | 0.58 | 0.47 | 0.81 | 0.81 | 0.82 | 0.47 | 0.57 | 0.57 | 0.68 | 0.72 | 0.7 | 0.87 | 0.87 | 0.88 |
| P | 0.76 | 0.69 | 0.67 | 0.68 | 0.76 | 0.71 | 0.67 | 0.63 | 0.61 | 0.61 | 0.72 | 0.71 | 0.78 | 0.82 | 0.8 |
| R | 0.27 | 0.51 | 0.37 | 0.9 | 0.87 | 0.94 | 0.37 | 0.53 | 0.5 | 0.7 | 0.74 | 0.7 | 1 | 0.92 | 0.98 |
| Rak-EL | |||||||||||||||
| Acc | 0.63 | 0.71 | 0.67 | 0.69 | 0.7 | 0.71 | 0.62 | 0.63 | 0.65 | 0.64 | 0.68 | 0.69 | 0.78 | 0.78 | 0.79 |
| F1 | 0.27 | 0.58 | 0.49 | 0.81 | 0.8 | 0.81 | 0.52 | 0.55 | 0.56 | 0.65 | 0.68 | 0.69 | 0.87 | 0.8 | 0.88 |
| P | 0.68 | 0.7 | 0.65 | 0.69 | 0.73 | 0.73 | 0.65 | 0.59 | 0.64 | 0.63 | 0.66 | 0.67 | 0.78 | 0.87 | 0.8 |
| R | 0.17 | 0.49 | 0.39 | 0.9 | 0.9 | 0.93 | 0.5 | 0.52 | 0.52 | 0.71 | 0.71 | 0.72 | 1 | 0.95 | 0.98 |
| Classifier | Accuracy | F1-Score | Precision | Recall | |
|---|---|---|---|---|---|
| Binary Relevance | NB | 14.71% | 0.73 | 0.70 | 0.76 |
| SVM | 21.1% | 0.75 | 0.74 | 0.76 | |
| LR | 19.3% | 0.75 | 0.73 | 0.77 | |
| Classifier Chain | NB | 14.9% | 0.74 | 0.63 | 0.89 |
| SVM | 21.5% | 0.73 | 0.67 | 0.79 | |
| LR | 19.1% | 0.73 | 0.66 | 0.82 | |
| Label Powerset | NB | 13.0% | 0.73 | 0.70 | 0.75 |
| SVM | 16.6% | 0.75 | 0.75 | 0.76 | |
| LR | 15.8% | 0.74 | 0.72 | 0.77 | |
| ML-KNN, BR-KNN 1 | NB | 18.0% | 0.72 | 0.69 | 0.74 |
| SVM | 14.0% | 0.74 | 0.72 | 0.76 | |
| Rak-EL | NB | 15.7% | 0.74 | 0.72 | 0.76 |
| SVM | 18.6% | 0.71 | 0.69 | 0.73 | |
| LR | 18.0% | 0.68 | 0.73 | 0.64 | |
| Author | Year | Method | Study Population | Design | Summary | Objective |
|---|---|---|---|---|---|---|
| Shickel et al. [2] | 2018 | DL to clinical tasks | EHR Projects | Review | Data mining for clinical tasks based on EHRs. Applications include information extraction, representation learning, outcome prediction, and phenotyping. | Model interpretability, data heterogeneity, and the lack of universal benchmarks are among the limitations found in current research. |
| Festen et al. [13] | 2021 | Descriptive statistics | Two hundred fourteen patients with cancer of 70 year Recruited from a University Medical Center, Netherlands. | Quantitative | (1) Implementing nurse-driven geriatric assessment. (2) Evaluate the patient’s preferences regarding treatment outcomes. (3) Considered patient assessments in their decision-making. | The geriatric assessment of older cancer patients is incorporated into a novel care pathway. A multidisciplinary team (MDT) of oncogeriatric experts could modify treatment. |
| Quinn et al. [15] | 2019 | Content analysis. | patients 32 (17 stable, 15 unstable | Survey | Healthcare team confidence and connection are associated with stable HCT. In contrast to complete independence or autonomy, interdependence involves building connections with healthcare providers and eliciting their support. | Researchers determined that resilience constructs play a protective role in helping AYA with KT maintain stable HCT. |
| Song et al. [49] | 2021 | DL-based methods for BioNER and datasets | Biomedical text mining | Review | Algorithms used in deep learning can be categorized into four types: that which is based on one neural network, that which is based on multi-task learning, that which is based on transfer learning, and that which is based on hybrid models. | Dataset size and type determine the results of these algorithms when applied to BioNER in a wide variety of domains. |
| Bridge et al. [67] | 2015 | Face-to-face interviews. Framework Analysis. | Healthcare professionals (n = 22; nurse; n = 11 physician) Recruited NHS hospital in UK. | Qualitative | (1) Provide quality, timely, and accurate information to patients. (2) In the meeting, patients’ complex information is given attention. (3) Promoting patient autonomy. (4) Participate in multidisciplinary teams. | Identify factors shaping cancer treatment decisions for older people with complex needs, including health and social care. |
| Jones et al. [170] | 2018 | Semi-structured interview. | Thirty-five sets of patients and their decision partners, Recruited from Cancer Center, USA | Qualitative | (1) Making the discussion more thorough between patients and decision partners with the use of decision aids. (2) Facilitating patient-provider relationships via decision aids. | Patient and partner experiences with an interactive decision aid utilized to make informed, shared treatment choices for advanced prostate cancer. |
| Peng et al. [117] | 2022 | AI utilization in particle therapy | Image segmentation review and six optimization of the radiotherapy dose. | Oncology review | Research on AI-powered particle therapy based on a comprehensive literature review. Creating data, interpreting it, incorporating fundamental physical processes, and rigorously validating it are all as important as the actual AI model development. | The aim is to present six aspect included: dose calculation, treatment planning, image guidance, range and dose verification, adaptive replanning and quality assurance |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmad, P.N.; Shah, A.M.; Lee, K. A Review on Electronic Health Record Text-Mining for Biomedical Name Entity Recognition in Healthcare Domain. Healthcare 2023, 11, 1268. https://doi.org/10.3390/healthcare11091268
Ahmad PN, Shah AM, Lee K. A Review on Electronic Health Record Text-Mining for Biomedical Name Entity Recognition in Healthcare Domain. Healthcare. 2023; 11(9):1268. https://doi.org/10.3390/healthcare11091268
Chicago/Turabian StyleAhmad, Pir Noman, Adnan Muhammad Shah, and KangYoon Lee. 2023. "A Review on Electronic Health Record Text-Mining for Biomedical Name Entity Recognition in Healthcare Domain" Healthcare 11, no. 9: 1268. https://doi.org/10.3390/healthcare11091268