
Deep Learning-Based Prediction of Diabetic Retinopathy Using CLAHE and ESRGAN for Enhancement

Abstract
:1. Introduction
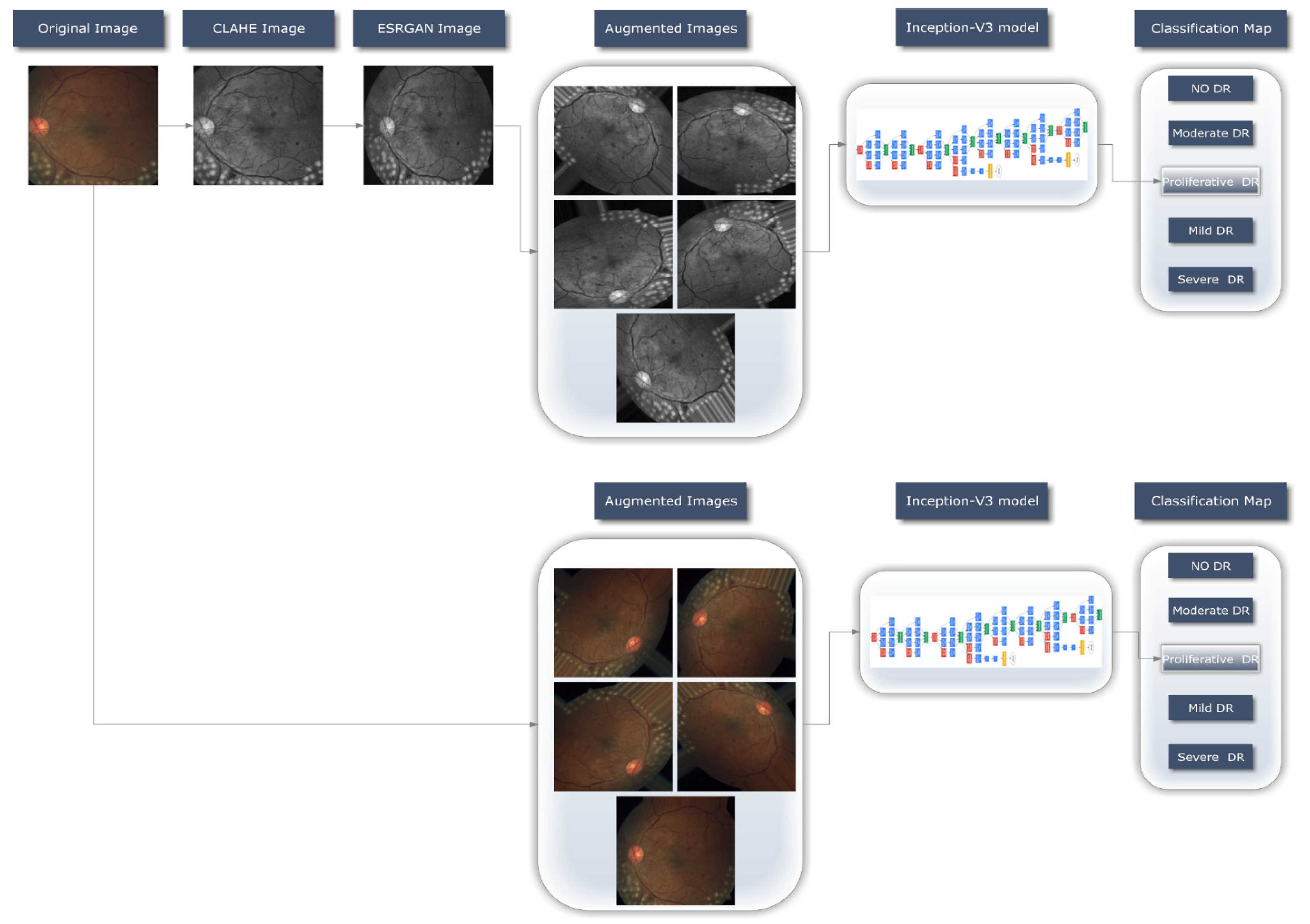
- Our objective was to develop a quick, fully automated DL based DR categorization that may be used in practice to aid ophthalmologists in assessing DR. DR can be prevented if it is detected and treated quickly after it first appears. To achieve this goal, we trained a model using innovative image preprocessing techniques and an Inception-V3 [14,15] model for diagnosis using the publicly available APTOS dataset [16].
- By employing the technique of augmentation, we ensured that the APTOS dataset contained a consistent amount of data.
- Accuracy (Acc), confusion matrix (CM), precision (Prec), recall (Re), top n accuracy, and the F1-score (F1sc) were the indicators used in a comprehensive comparative study to determine the viability of the proposed system.
- Pre-trained networks trained on the APTOS data set were fine-tuned with the use of an Inception-V3 weight-tuning algorithm.
- By adopting a varied training procedure backed by various permutations of training strategies, the general reliability of the suggested method was enhanced, and overfitting was avoided (e.g., learning rate, data augmentation, batch size, and validation patience).
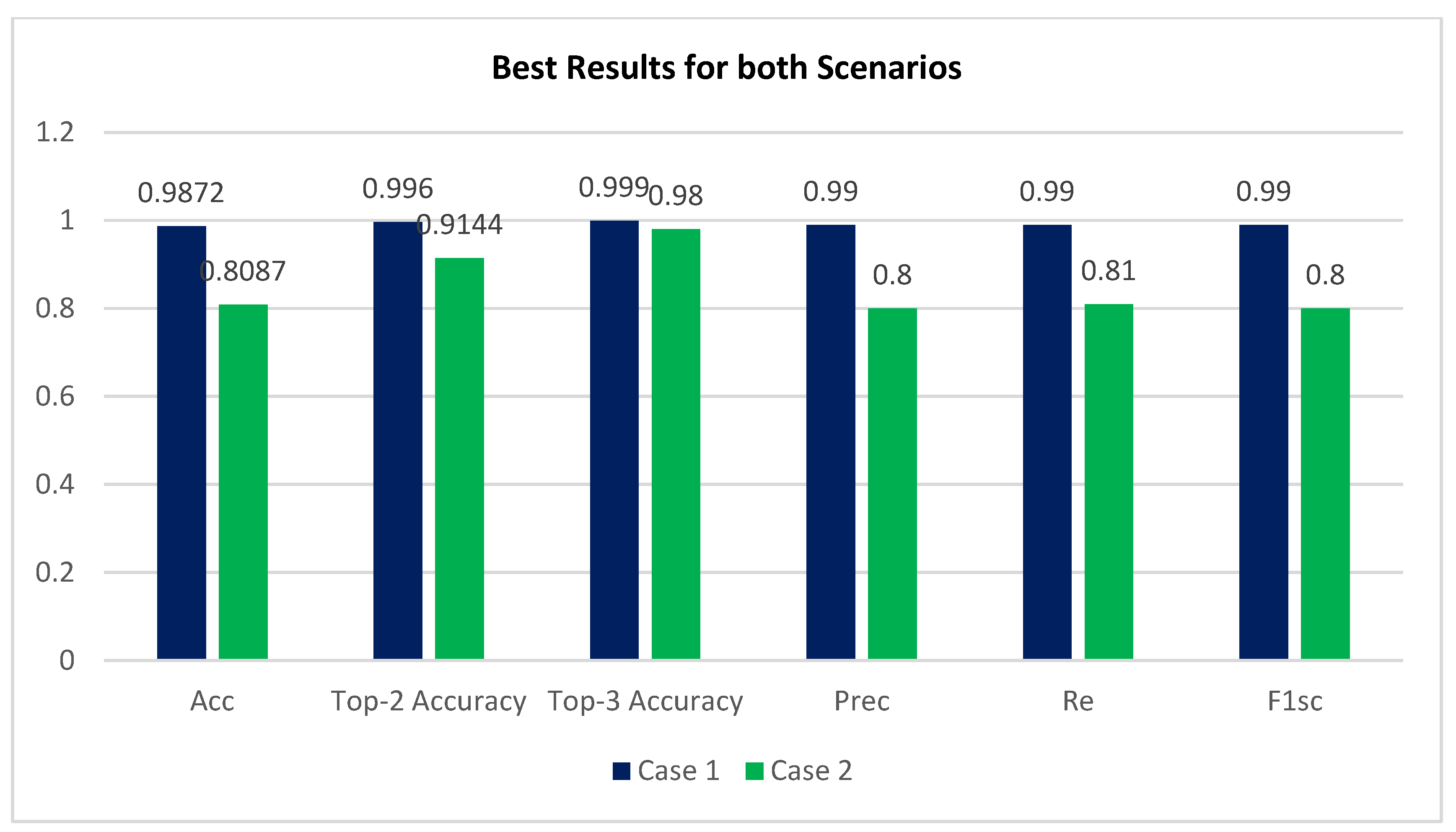
- The APTOS dataset was used during both the training and evaluation phases of the model’s development. By employing stringent 80:20 hold-out validation, the model achieved a remarkable 98.71% accuracy of classification using enhancement techniques and 80.87% without using enhancement techniques.
2. Related Work
3. Research Methodology
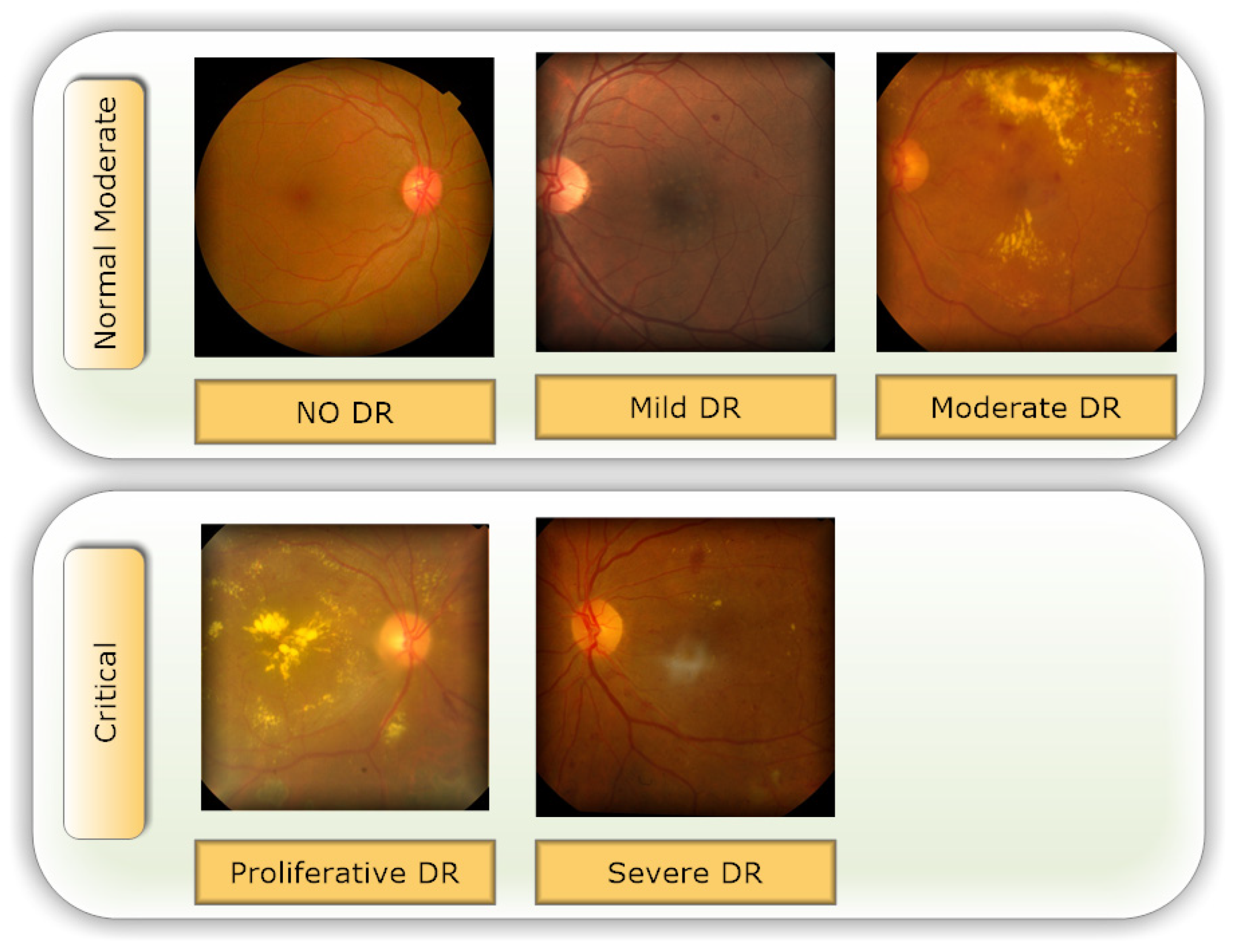
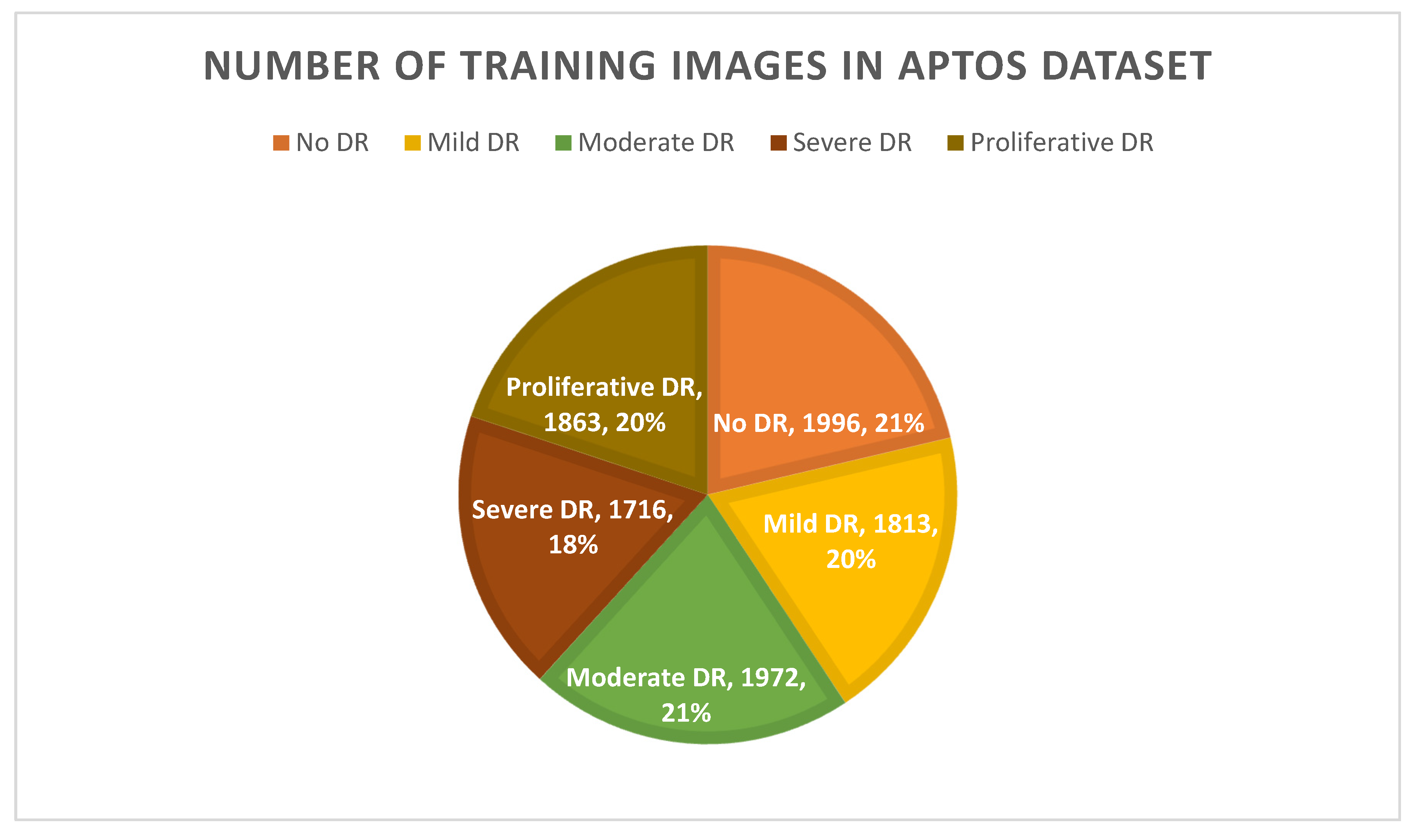
3.1. Data Set Description
3.2. Proposed Methodology
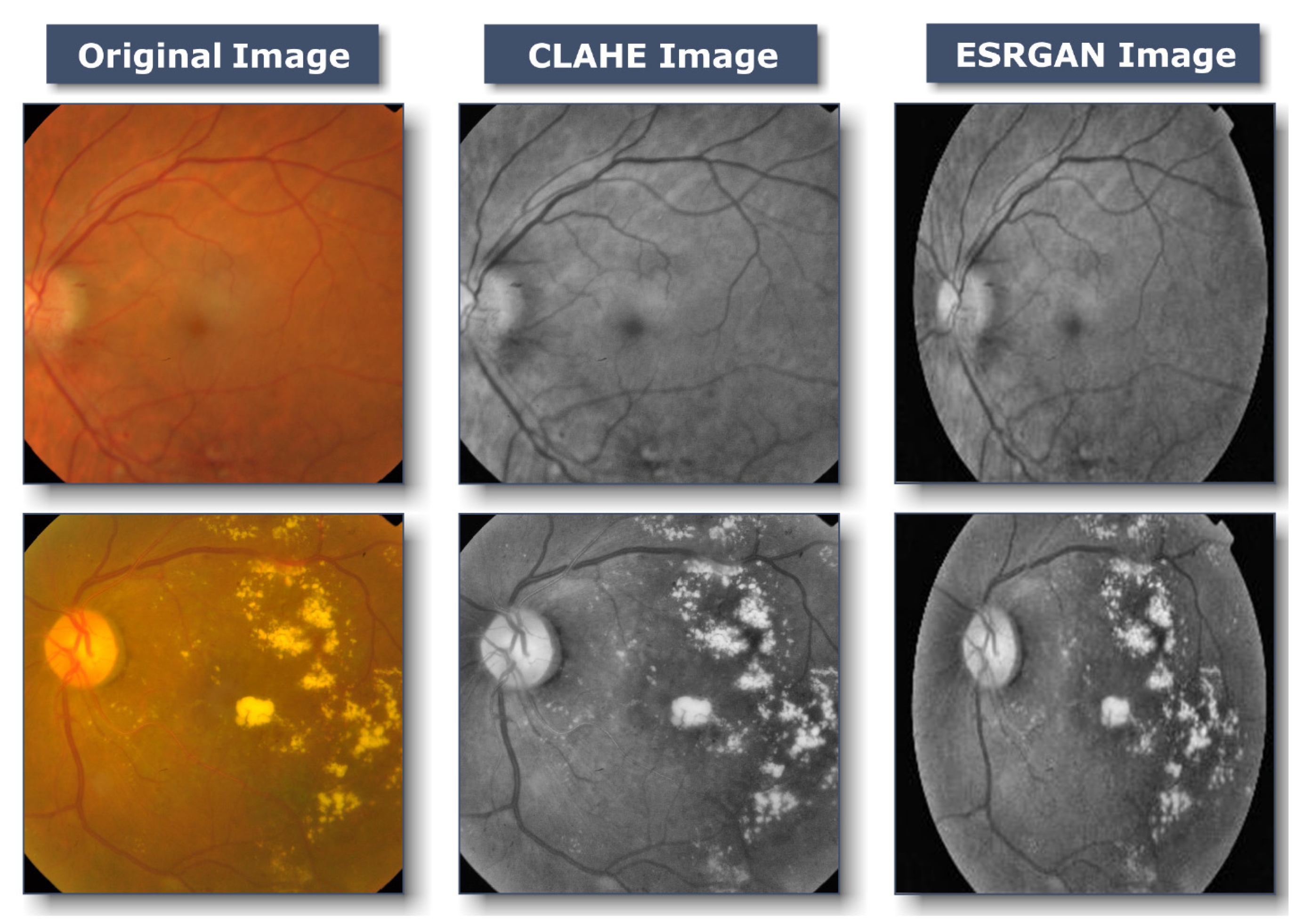
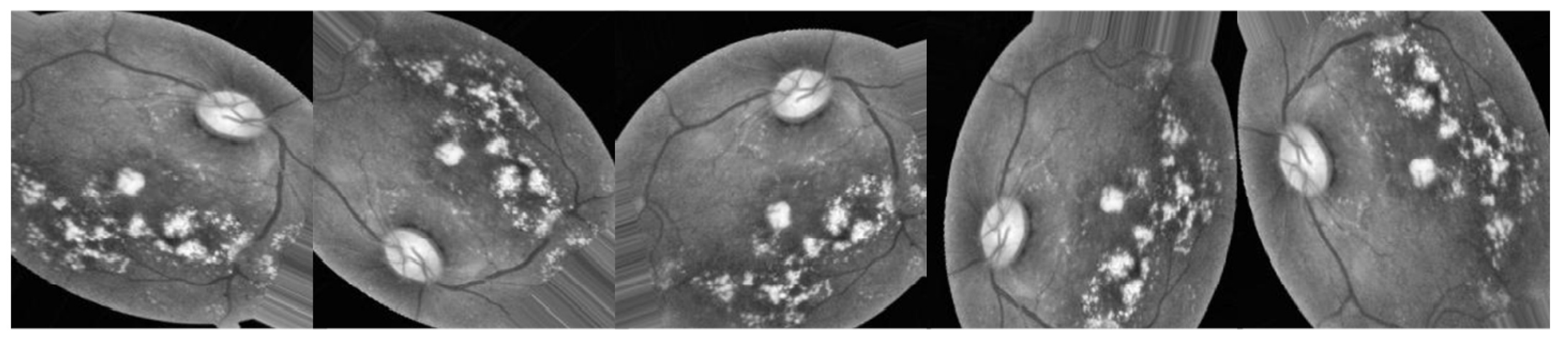
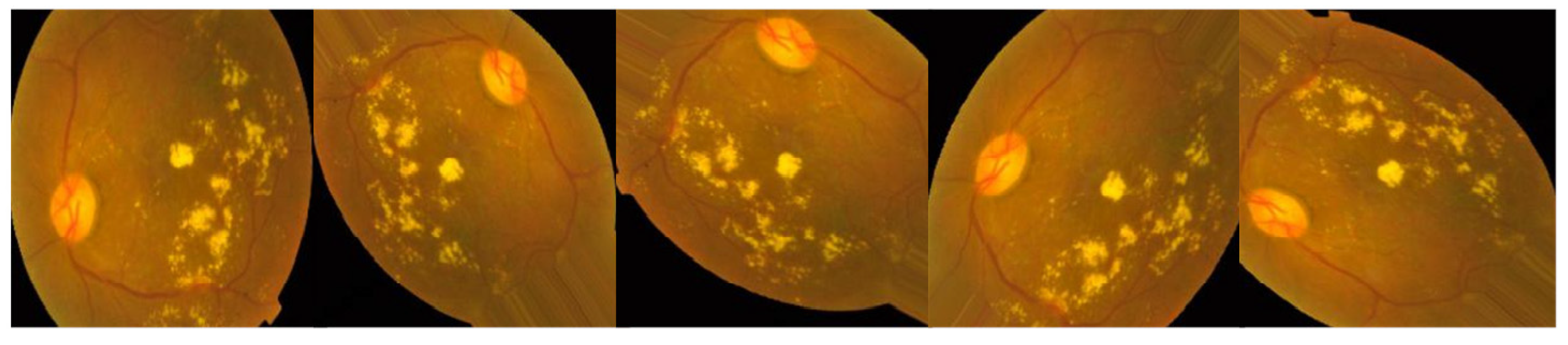
3.2.1. Preprocessing Using CLAHE and ESRGAN
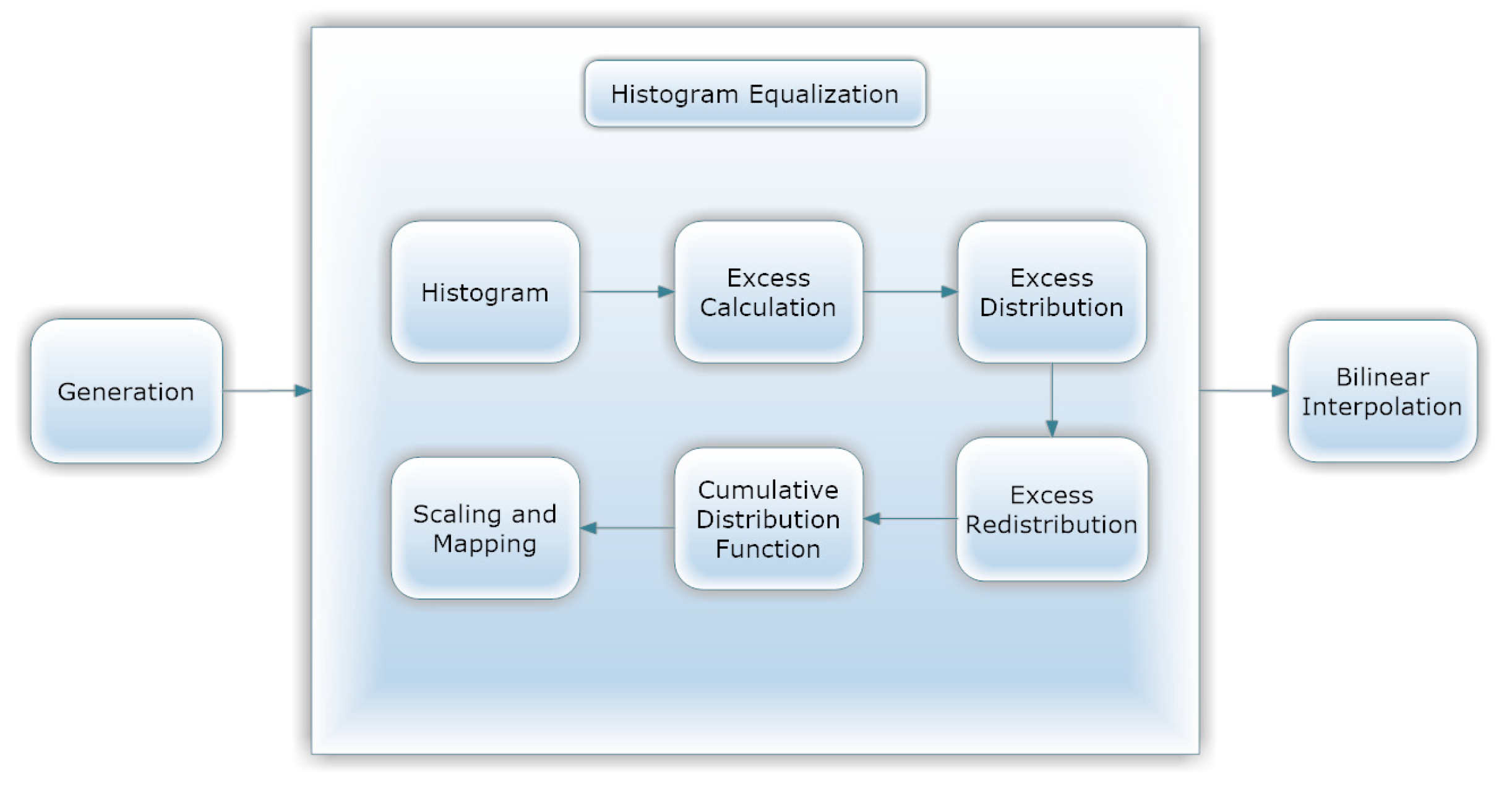
- CLAHE
- Resize each picture to 224 × 224 × 3 pixels.
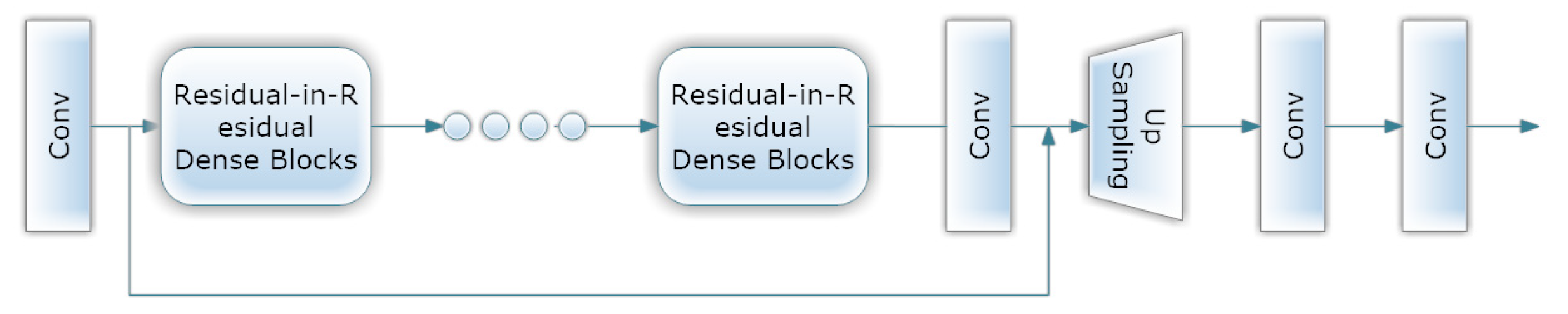
- ESRGAN
- Normalization
3.2.2. Data Augmentation
3.2.3. Learning Model (Inception-V3)
4. Experimental Results
4.1. Instruction and Setup of Inception-V3
4.2. Evaluative Parameters
4.3. Performance of Inception-V3 Model Outcomes
4.4. Evaluation Considering a Variety of Other Methodologies
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Atwany, M.Z.; Sahyoun, A.H.; Yaqub, M. Deep learning techniques for diabetic retinopathy classification: A survey. IEEE Access 2022, 10, 28642–28655. [Google Scholar] [CrossRef]
- Amin, J.; Sharif, M.; Yasmin, M. A review on recent developments for detection of diabetic retinopathy. Scientifica 2016, 2016, 6838976. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kharroubi, A.T.; Darwish, H.M. Diabetes mellitus: The epidemic of the century. World J. Diabetes 2015, 6, 850. [Google Scholar] [CrossRef] [PubMed]
- Alwakid, G.; Gouda, W.; Humayun, M. Enhancement of Diabetic Retinopathy Prognostication Utilizing Deep Learning, CLAHE, and ESRGAN. Preprints 2023, 2023020218. [Google Scholar] [CrossRef]
- Mamtora, S.; Wong, Y.; Bell, D.; Sandinha, T. Bilateral birdshot retinochoroiditis and retinal astrocytoma. Case Rep. Ophthalmol. Med. 2017, 2017, 6586157. [Google Scholar] [CrossRef]
- Taylor, R.; Batey, D. Handbook of Retinal Screening in Diabetes: Diagnosis and Management; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Imran, M.; Ullah, A.; Arif, M.; Noor, R. A unified technique for entropy enhancement based diabetic retinopathy detection using hybrid neural network. Comput. Biol. Med. 2022, 145, 105424. [Google Scholar]
- Alyoubi, W.L.; Shalash, W.M.; Abulkhair, M.F. Diabetic retinopathy detection through deep learning techniques: A review. Inform. Med. Unlocked 2020, 20, 100377. [Google Scholar] [CrossRef]
- Dubow, M.; Pinhas, A.; Shah, N.; Cooper, R.F.; Gan, A.; Gentile, R.C.; Hendrix, V.; Sulai, Y.N.; Carroll, J.; Chui, T.Y. Classification of human retinal microaneurysms using adaptive optics scanning light ophthalmoscope fluorescein angiography. Investig. Ophthalmol. Vis. Sci. 2014, 55, 1299–1309. [Google Scholar] [CrossRef]
- Mazhar, K.; Varma, R.; Choudhury, F.; McKean-Cowdin, R.; Shtir, C.J.; Azen, S.P.; Group, L.A.L.E.S. Severity of diabetic retinopathy and health-related quality of life: The Los Angeles Latino Eye Study. Ophthalmology 2011, 118, 649–655. [Google Scholar] [CrossRef] [Green Version]
- Willis, J.R.; Doan, Q.V.; Gleeson, M.; Haskova, Z.; Ramulu, P.; Morse, L.; Cantrell, R.A. Vision-related functional burden of diabetic retinopathy across severity levels in the United States. JAMA Ophthalmol. 2017, 135, 926–932. [Google Scholar] [CrossRef]
- Vora, P.; Shrestha, S. Detecting diabetic retinopathy using embedded computer vision. Appl. Sci. 2020, 10, 7274. [Google Scholar] [CrossRef]
- Murugesan, N.; Üstunkaya, T.; Feener, E.P. Thrombosis and hemorrhage in diabetic retinopathy: A perspective from an inflammatory standpoint. Semin. Thromb. Hemost. 2015, 41, 659–664. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Association for the Advancement of Artificial Intelligence: Washington, DC, USA, 2017. [Google Scholar]
- Xia, X.; Xu, C.; Nan, B. Inception-v3 for flower classification. In Proceedings of the 2017 2nd International Conference on Image, Vision and Computing (ICIVC), Chengdu, China, 2–4 June 2017; pp. 783–787. [Google Scholar]
- APTOS 2019 Blindness Detection Detect Diabetic Retinopathy to Stop Blindness before It’s too Late. 2019. Available online: https://www.kaggle.com/c/aptos2019-blindnessdetection/data (accessed on 28 August 2022).
- Pizer, S.M.; Amburn, E.P.; Austin, J.D.; Cromartie, R.; Geselowitz, A.; Greer, T.; ter Haar Romeny, B.; Zimmerman, J.B.; Zuiderveld, K. Adaptive histogram equalization and its variations. Comput. Vis. Graph. Image Process. 1987, 39, 355–368. [Google Scholar] [CrossRef]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Al-Antary, M.T.; Arafa, Y. Multi-scale attention network for diabetic retinopathy classification. IEEE Access 2021, 9, 54190–54200. [Google Scholar] [CrossRef]
- Gargeya, R.; Leng, T. Automated identification of diabetic retinopathy using deep learning. Ophthalmology 2017, 124, 962–969. [Google Scholar] [CrossRef]
- Ali, R.; Hardie, R.C.; Narayanan, B.N.; Kebede, T.M. IMNets: Deep learning using an incremental modular network synthesis approach for medical imaging applications. Appl. Sci. 2022, 12, 5500. [Google Scholar] [CrossRef]
- Kazakh-British, N.P.; Pak, A.; Abdullina, D. Automatic detection of blood vessels and classification in retinal images for diabetic retinopathy diagnosis with application of convolution neural network. In Proceedings of the 2018 International Conference on Sensors, Signal and Image Processing, Prague, Czech Republic, 12–14 October 2018; pp. 60–63. [Google Scholar]
- Pak, A.; Ziyaden, A.; Tukeshev, K.; Jaxylykova, A.; Abdullina, D. Comparative analysis of deep learning methods of detection of diabetic retinopathy. Cogent Eng. 2020, 7, 1805144. [Google Scholar] [CrossRef]
- Macsik, P.; Pavlovicova, J.; Goga, J.; Kajan, S. Local Binary CNN for Diabetic Retinopathy Classification on Fundus Images. Acta Polytech. Hung. 2022, 19, 27–45. [Google Scholar]
- Khalifa, N.E.M.; Loey, M.; Taha, M.H.N.; Mohamed, H.N.E.T. Deep transfer learning models for medical diabetic retinopathy detection. Acta Inform. Med. 2019, 27, 327. [Google Scholar] [CrossRef]
- Hemanth, D.J.; Deperlioglu, O.; Kose, U. An enhanced diabetic retinopathy detection and classification approach using deep convolutional neural network. Neural Comput. Appl. 2020, 32, 707–721. [Google Scholar] [CrossRef]
- Maqsood, S.; Damaševičius, R.; Maskeliūnas, R. Hemorrhage detection based on 3D CNN deep learning framework and feature fusion for evaluating retinal abnormality in diabetic patients. Sensors 2021, 21, 3865. [Google Scholar] [CrossRef] [PubMed]
- Das, S.; Kharbanda, K.; Suchetha, M.; Raman, R.; Dhas, E. Deep learning architecture based on segmented fundus image features for classification of diabetic retinopathy. Biomed. Signal Process. Control 2021, 68, 102600. [Google Scholar] [CrossRef]
- Wang, Y.; Yu, M.; Hu, B.; Jin, X.; Li, Y.; Zhang, X.; Zhang, Y.; Gong, D.; Wu, C.; Zhang, B. Deep learning-based detection and stage grading for optimising diagnosis of diabetic retinopathy. Diabetes/Metab. Res. Rev. 2021, 37, e3445. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Yue, K.; Cheng, S.; Pan, C.; Sun, J.; Li, W. Hybrid model structure for diabetic retinopathy classification. J. Healthc. Eng. 2020, 2020, 8840174. [Google Scholar] [CrossRef]
- Saranya, P.; Umamaheswari, K.; Patnaik, S.C.; Patyal, J.S. Red Lesion Detection in Color Fundus Images for Diabetic Retinopathy Detection. In Proceedings of the International Conference on Deep Learning, Computing and Intelligence, Chennai, India, 7–8 January 2021; pp. 561–569. [Google Scholar]
- Thomas, N.M.; Albert Jerome, S. Grading and Classification of Retinal Images for Detecting Diabetic Retinopathy Using Convolutional Neural Network. In Advances in Electrical and Computer Technologies; Springer: Singapore, 2022; pp. 607–614. [Google Scholar]
- Crane, A.; Dastjerdi, M. Effect of Simulated Cataract on the Accuracy of an Artificial Intelligence Algorithm in Detecting Diabetic Retinopathy in Color Fundus Photos. Investig. Ophthalmol. Vis. Sci. 2022, 63, 2100–F0089. [Google Scholar]
- Majumder, S.; Kehtarnavaz, N. Multitasking deep learning model for detection of five stages of diabetic retinopathy. IEEE Access 2021, 9, 123220–123230. [Google Scholar] [CrossRef]
- Deshpande, A.; Pardhi, J. Automated detection of Diabetic Retinopathy using VGG-16 architecture. Int. Res. J. Eng. Technol. 2021, 8, 3790–3794. [Google Scholar]
- Yadav, S.; Awasthi, P.; Pathak, S. Retina Image and Diabetic Retinopathy: A Deep Learning Based Approach. Available online: https://www.irjmets.com/uploadedfiles/paper/issue_6_june_2022/26368/final/fin_irjmets1656163002.pdf (accessed on 28 July 2022).
- Kobat, S.G.; Baygin, N.; Yusufoglu, E.; Baygin, M.; Barua, P.D.; Dogan, S.; Yaman, O.; Celiker, U.; Yildirim, H.; Tan, R.-S. Automated Diabetic Retinopathy Detection Using Horizontal and Vertical Patch Division-Based Pre-Trained DenseNET with Digital Fundus Images. Diagnostics 2022, 12, 1975. [Google Scholar] [CrossRef]
- Reza, A.M. Realization of the contrast limited adaptive histogram equalization (CLAHE) for real-time image enhancement. J. VLSI Signal Process. Syst. Signal Image Video Technol. 2004, 38, 35–44. [Google Scholar] [CrossRef]
- Tondin, B.; Barth, A.; Sanches, P.; Júnior, D.; Müller, A.; Thomé, P.; Wink, P.; Martins, A.; Susin, A. Development of an Automatic Antibiogram Reader System Using Circular Hough Transform and Radial Profile Analysis. In Proceedings of the XXVII Brazilian Congress on Biomedical Engineering: CBEB 2020, Vitória, Brazil, 26–30 October 2020; pp. 1837–1842. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Change Loy, C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018; Springer: Cham, Switzerland. [Google Scholar]
- Jolicoeur-Martineau, A. The relativistic discriminator: A key element missing from standard GAN. arXiv 2018, arXiv:1807.00734. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Krause, J.; Sapp, B.; Howard, A.; Zhou, H.; Toshev, A.; Duerig, T.; Philbin, J.; Fei-Fei, L. The unreasonable effectiveness of noisy data for fine-grained recognition. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 301–320. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; Volume 25. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Serre, T.; Wolf, L.; Bileschi, S.; Riesenhuber, M.; Poggio, T. Robust object recognition with cortex-like mechanisms. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 411–426. [Google Scholar] [CrossRef]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Arora, S.; Bhaskara, A.; Ge, R.; Ma, T. Provable bounds for learning some deep representations. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 584–592. [Google Scholar]
- Adak, C.; Karkera, T.; Chattopadhyay, S.; Saqib, M. Detecting Severity of Diabetic Retinopathy from Fundus Images using Ensembled Transformers. arXiv 2023, arXiv:2301.00973. [Google Scholar]
- Maqsood, Z.; Gupta, M.K. Automatic Detection of Diabetic Retinopathy on the Edge. In Cyber Security, Privacy and Networking; Springer: Singapore, 2022; pp. 129–139. [Google Scholar]
- Lahmar, C.; Idri, A. Deep hybrid architectures for diabetic retinopathy classification. Comput. Methods Biomech. Biomed. Eng. Imaging Vis. 2022, 11, 166–184. [Google Scholar] [CrossRef]
- Oulhadj, M.; Riffi, J.; Chaimae, K.; Mahraz, A.M.; Ahmed, B.; Yahyaouy, A.; Fouad, C.; Meriem, A.; Idriss, B.A.; Tairi, H. Diabetic retinopathy prediction based on deep learning and deformable registration. Multimed. Tools Appl. 2022, 81, 28709–28727. [Google Scholar] [CrossRef]
- Gangwar, A.K.; Ravi, V. Diabetic retinopathy detection using transfer learning and deep learning. In Evolution in Computational Intelligence; Springer: Singapore, 2021; pp. 679–689. [Google Scholar]
- Lahmar, C.; Idri, A. On the value of deep learning for diagnosing diabetic retinopathy. Health Technol. 2022, 12, 89–105. [Google Scholar] [CrossRef]
- Canayaz, M. Classification of diabetic retinopathy with feature selection over deep features using nature-inspired wrapper methods. Appl. Soft Comput. 2022, 128, 109462. [Google Scholar] [CrossRef]
- Escorcia-Gutierrez, J.; Cuello, J.; Barraza, C.; Gamarra, M.; Romero-Aroca, P.; Caicedo, E.; Valls, A.; Puig, D. Analysis of Pre-trained Convolutional Neural Network Models in Diabetic Retinopathy Detection through Retinal Fundus Images. In Proceedings of the 21st International Conference on Computer Information Systems and Industrial Management, Barranquilla, Colombia, 15–17 July 2022; Springer International Publishing: Cham, Switzerland; pp. 202–213. [Google Scholar]
- Lin, C.-L.; Wu, K.-C. Development of Revised ResNet-50 for Diabetic Retinopathy Detection. Res. Sq. 2023. [Google Scholar] [CrossRef]
- Salluri, D.K.; Sistla, V.; Kolli, V.K.K. HRUNET: Hybrid Residual U-Net for automatic severity prediction of Diabetic Retinopathy. Comput. Methods Biomech. Biomed. Eng. Imaging Vis. 2022, 1–12. [Google Scholar] [CrossRef]
- Yadav, S.; Awasthi, P. Diabetic retinopathy detection using deep learning and inception-v3 model. Int. Res. J. Mod. Eng. Technol. Sci. 2022, 4, 1731–1735. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Year | Technique | Total Number of Images | Classes | Dataset | Accuracy | Precision | Recall | Receiver Operating Characteristic ROC |
|---|---|---|---|---|---|---|---|---|---|
| [19] | 2021 | Multi-scale attention network (MSA-Net) | 5 | APTOS | 84.6% | 90.5% | 91% | - | |
| Eyepacs | 87.5% | 78.7% | 90.6% | 76.7% | |||||
| [24] | 2022 | Local binary convolutional neural network (LBCNN) | 2 | APTOS | 97.41% | 96.59% | 94.63% | 98.71% | |
| [31] | 2022 | Support vector machine (SVM) | Test: 1928 | 2 | APTOS | 94.5% | 75.6% | ||
| Test: 103 | IDRiD | 93.3% | 78.5% | ||||||
| [32] | 2022 | CNN | 2 | APTOS | 95.3% | ||||
| [33] | 2022 | Inception-ResNet-v2 | 5 | APTOS | 82.18% | ||||
| [34] | 2021 | Squeeze Excitation Densely Connected deep CNN | 5 | APTOS | 96% | ||||
| EyePACS | 93% | ||||||||
| [35] | 2021 | VGG-16 | Test = 1728 | 5 | APTOS | 74.58% | |||
| [36] | 2022 | VGG16 | 13,626 | 2 | APTOS | 73.26% | 99% | 99% | |
| DenseNet121 | 96.11% | ||||||||
| [37] | 2022 | DenseNet201 | 3662 | 5 | APTOS | 93.85% | 90.90% | 80.60% | |
| 2355 | 3 | New Dataset | 94.06% | 94.74% | 94.45% |
| Class Index | DR Level | # Images |
|---|---|---|
| 0 | No DR | 1805 |
| 1 | Mild DR | 370 |
| 2 | Moderate DR | 999 |
| 3 | Severe DR | 193 |
| 4 | Proliferate DR | 295 |
| Batch Size | Learning Rate | Accuracy | Mean | Standard Deviation |
|---|---|---|---|---|
| 2 | 0.00001 | 0.983202 | 0.982543 | 0.001140989 |
| 0.0001 | 0.983202 | |||
| 0.001 | 0.981225 | |||
| 4 | 0.00001 | 0.982213 | 0.982213 | 0 |
| 0.0001 | 0.982213 | |||
| 0.001 | 0.982213 | |||
| 8 | 0.00001 | 0.982213 | 0.980237 | 0.008088282 |
| 0.0001 | 0.987154 | |||
| 0.001 | 0.971344 | |||
| 16 | 0.00001 | 0.980237 | 0.980896 | 0.001141024 |
| 0.0001 | 0.982213 | |||
| 0.001 | 0.980237 | |||
| 32 | 0.00001 | 0.979249 | 0.979249 | 0.000988126 |
| 0.0001 | 0.978261 | |||
| 0.001 | 0.980237 | |||
| 64 | 0.00001 | 0.978261 | 0.977931 | 0.000570495 |
| 0.0001 | 0.978261 | |||
| 0.001 | 0.977273 |
| Freeze | Batch Size | Learning Rate | Accuracy | Mean | Standard Deviation |
|---|---|---|---|---|---|
| 140 | 2 | 0.00001 | 0.779599 | 0.761992 | 0.021731047 |
| 0.0001 | 0.76867 | ||||
| 0.001 | 0.737705 | ||||
| 4 | 0.00001 | 0.783242 | 0.780814 | 0.005855271 | |
| 0.0001 | 0.785064 | ||||
| 0.00001 | 0.774135 | ||||
| 8 | 0.00001 | 0.777778 | 0.780814 | 0.002782382 | |
| 0.0001 | 0.781421 | ||||
| 0.001 | 0.783242 | ||||
| 16 | 0.00001 | 0.790528 | 0.7881 | 0.004206547 | |
| 0.0001 | 0.783242 | ||||
| 0.001 | 0.790528 | ||||
| 32 | 0.00001 | 0.786885 | 0.788707 | 0.01014166 | |
| 0.0001 | 0.799636 | ||||
| 0.001 | 0.779599 | ||||
| 64 | 0.00001 | 0.794171 | 0.798421 | 0.008985212 | |
| 0.0001 | 0.808743 | ||||
| 0.001 | 0.79235 |
| Acc | Prec | Re | F1sc | Top-2 Accuracy | Top-3 Accuracy |
|---|---|---|---|---|---|
| 0.9872 | 0.99 | 0.99 | 0.99 | 0.996 | 0.999 |
| Acc | Prec | Re | F1sc | Top-2 Accuracy | Top-3 Accuracy |
|---|---|---|---|---|---|
| 0.8087 | 0.80 | 0.81 | 0.80 | 0.9144 | 0.9800 |
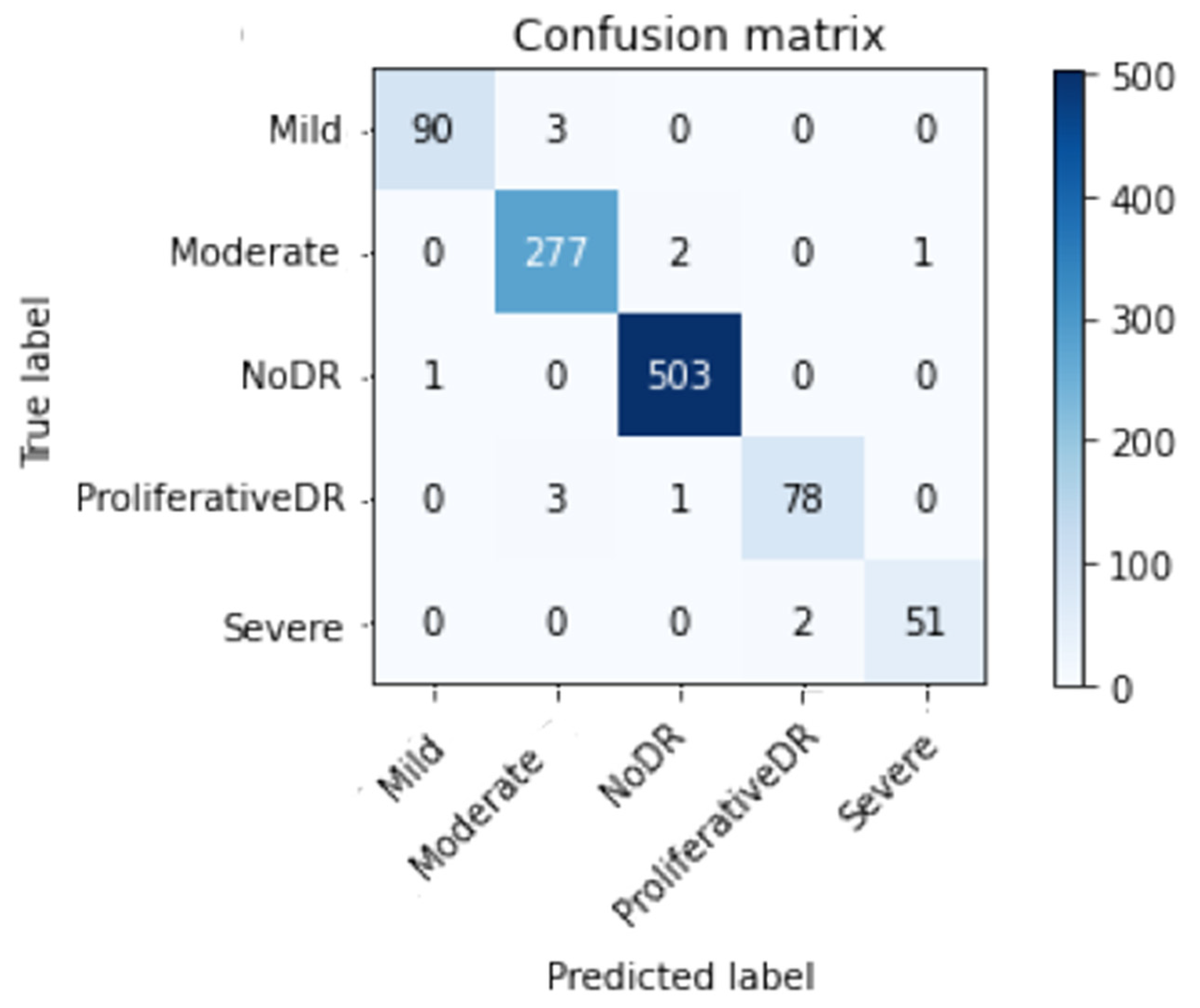
| Prec | Re | F1sc | Total Images | |
|---|---|---|---|---|
| Mild DR | 0.99 | 0.97 | 0.98 | 93 |
| Moderate DR | 0.98 | 0.99 | 0.98 | 280 |
| No DR | 0.99 | 1.00 | 1.00 | 504 |
| Proliferative DR | 0.97 | 0.95 | 0.96 | 82 |
| Severe DR | 0.98 | 0.96 | 0.97 | 53 |
| Average | 0.99 | 0.99 | 0.99 | 1012 |
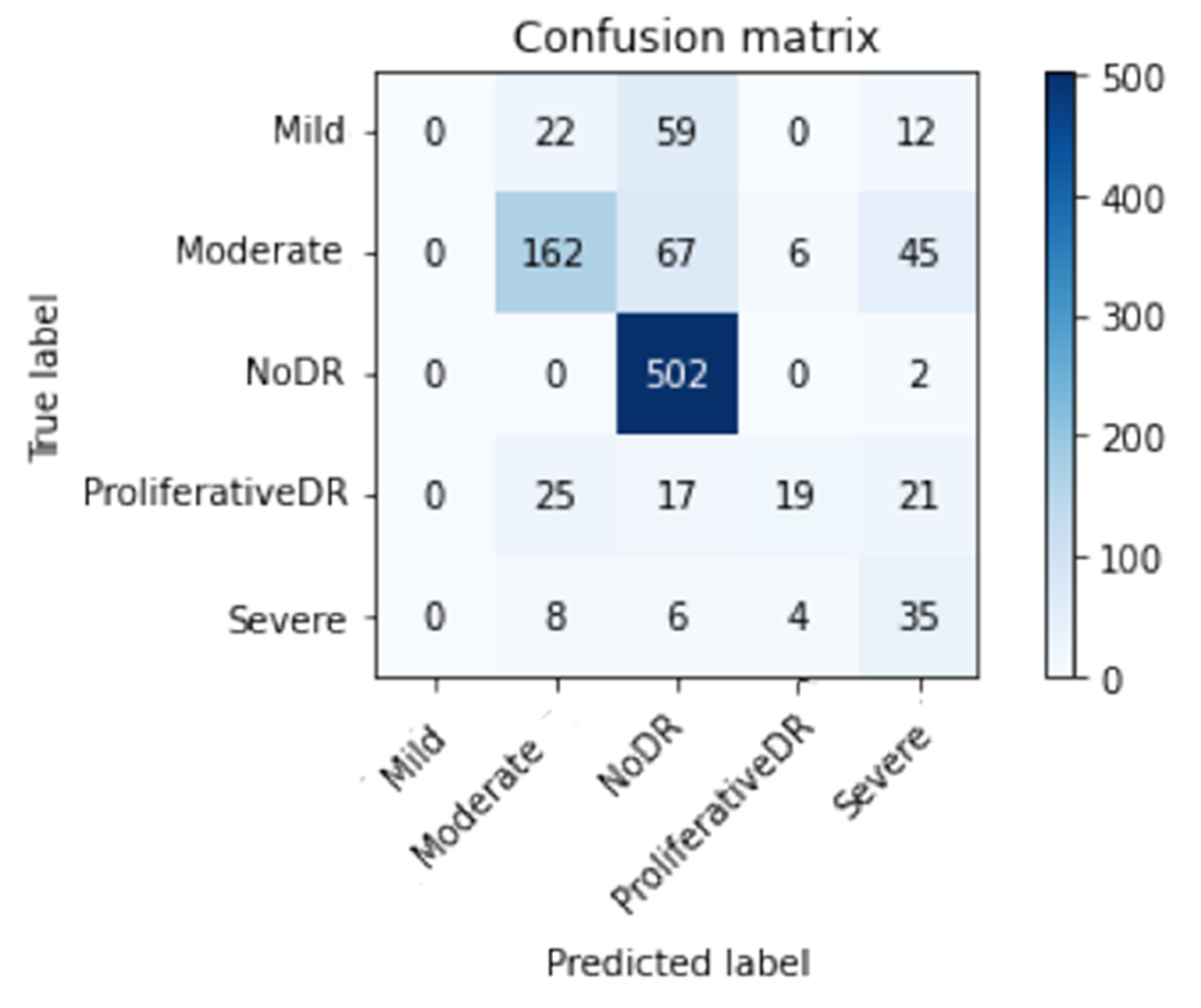
| Prec | Re | F1sc | Total Images | |
|---|---|---|---|---|
| Mild DR | 0.58 | 0.62 | 0.60 | 93 |
| Moderate DR | 0.70 | 0.78 | 0.74 | 280 |
| No DR | 0.97 | 0.97 | 0.97 | 504 |
| Proliferative DR | 0.68 | 0.48 | 0.56 | 82 |
| Severe DR | 0.43 | 0.31 | 0.36 | 53 |
| Average | 0.80 | 0.81 | 0.80 | 1012 |
| Reference | Technique | Accuracy |
|---|---|---|
| [19] | MSA-Net | 84.6% |
| [24] | LBCNN | 97.41% |
| [31] | SVM | 94.5% |
| [32] | CNN | 95.3% |
| [33] | Inception-ResNet-v2 | 97.0%, |
| [35] | VGG-16 | 74.58% |
| [36] | VGG16 | 73.26% |
| DenseNet121 | 96.11% | |
| [37] | DenseNet201 | 93.85% |
| [50] | Vision Transformer, Bidirectional Encoder representation for image Transformer, Class-Attention in Image Transformers, Data efficient image Transformers | 94.63% |
| [51] | EfficientNet-B6 | 86.03% |
| [52] | SVM classifier and MobileNet_V2 for feature extraction | 88.80% |
| [53] | Densenet-121, Xception, Inception-v3, Resnet-50 | 85.28% |
| [54] | Inception-ResNet-v2 | 72.33% |
| [55] | MobileNet_V2 | 93.09% |
| [56] | EfficientNet and DenseNet | 96.32% |
| [57] | VGG16 | 96.86% |
| [58] | Resnet-50 | 77.22% |
| [59] | Hybrid Residual U-Net | 94% |
| [60] | Inception-v3 | 88.1% |
| Proposed Methodology | Inception-V3 (without using CLAHE + ESRGAN) Case 2 | 80.87% |
| Inception-V3 (using CLAHE + ESRGAN) Case 1 | 98.7% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alwakid, G.; Gouda, W.; Humayun, M. Deep Learning-Based Prediction of Diabetic Retinopathy Using CLAHE and ESRGAN for Enhancement. Healthcare 2023, 11, 863. https://doi.org/10.3390/healthcare11060863
Alwakid G, Gouda W, Humayun M. Deep Learning-Based Prediction of Diabetic Retinopathy Using CLAHE and ESRGAN for Enhancement. Healthcare. 2023; 11(6):863. https://doi.org/10.3390/healthcare11060863
Chicago/Turabian StyleAlwakid, Ghadah, Walaa Gouda, and Mamoona Humayun. 2023. "Deep Learning-Based Prediction of Diabetic Retinopathy Using CLAHE and ESRGAN for Enhancement" Healthcare 11, no. 6: 863. https://doi.org/10.3390/healthcare11060863