
Strategies of Predictive Schemes and Clinical Diagnosis for Prognosis Using MIMIC-III: A Systematic Review

Abstract
:1. Introduction
- The study discusses significant challenges associated with the MIMIC-III dataset.
- An elaborative and concise review of predictive methods applied to the MIMIC-III dataset are carried out regarding classification, a standard predictive approach, and an early predictive approach.
- The study addresses various techniques used for clinical diagnosis of the MIMIC-III dataset, including disease characterization interpretation, detection decision approach, and evaluation-based scheme.
- In addition, the study examines the significant learning outcomes in terms of the strengths and weaknesses of existing methods to analyze the MIMIC-III dataset.
- The study also highlights essential open-ended issues.
2. Methodologies
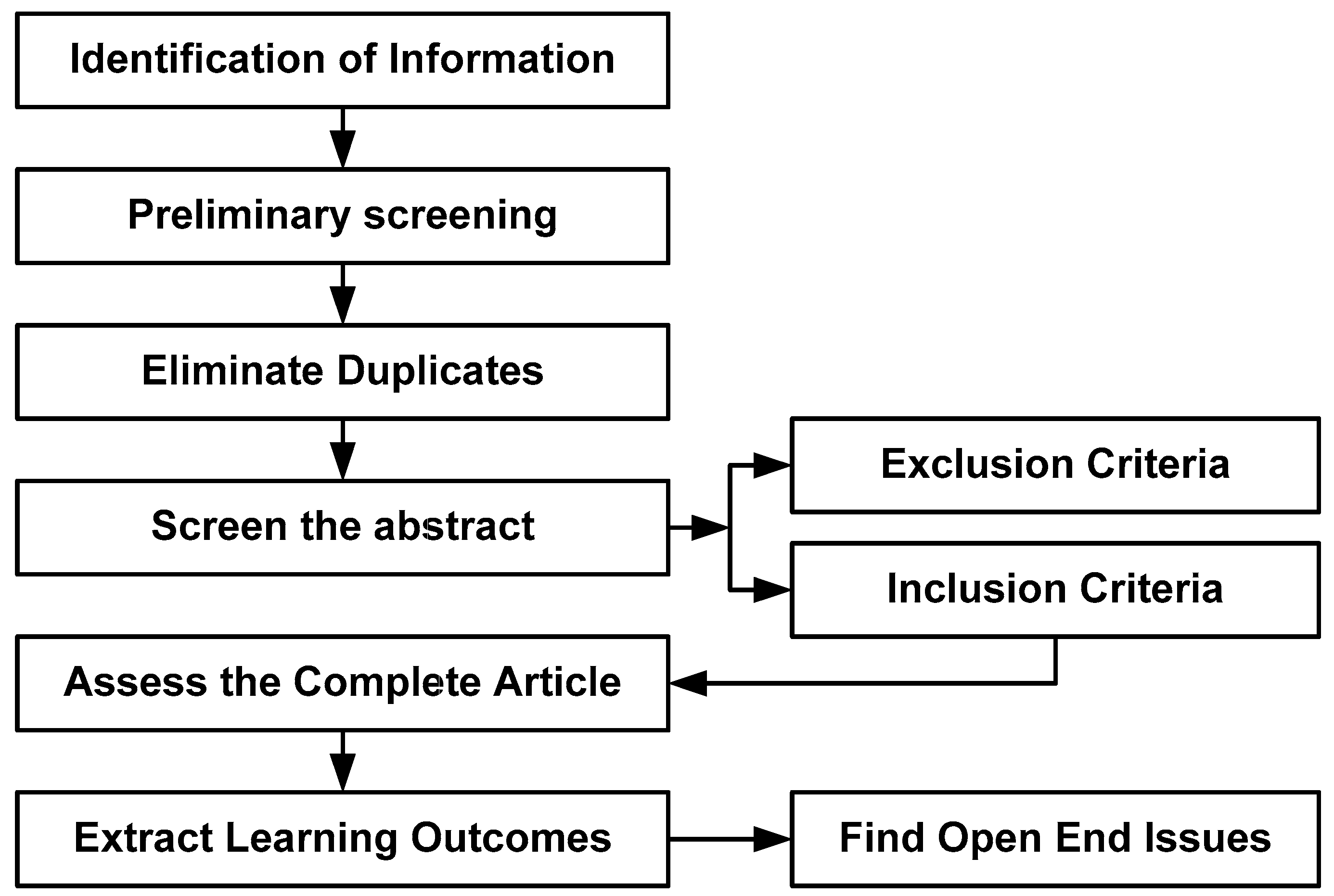
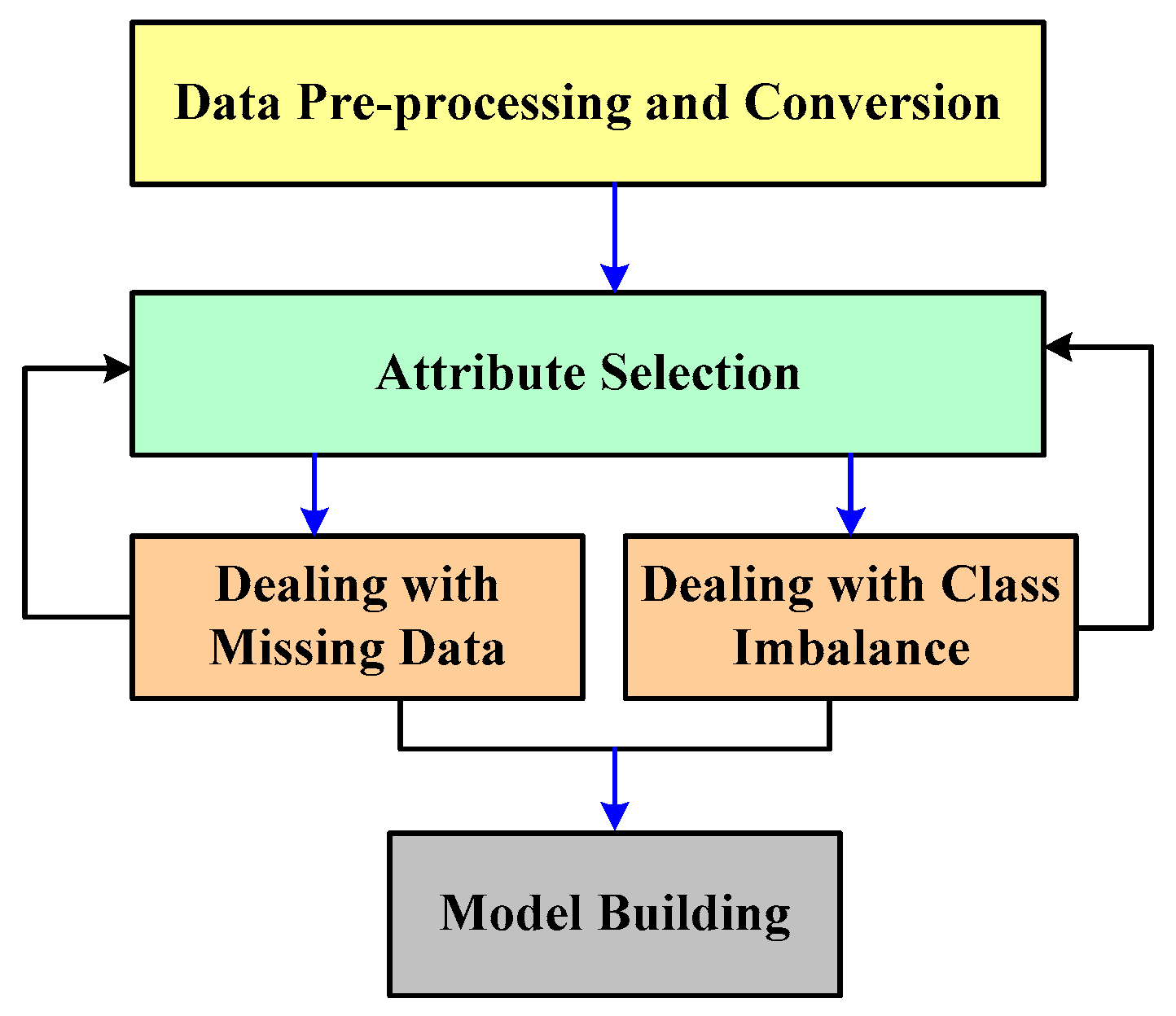
- Type of Research: A desk research methodology is adopted that mainly infers information based on information available from reliable internet sources and archives of scientific concepts [12]. This method uses aggregated data followed by summarized data to leverage the cumulative investigational effectiveness. This process of desk research methodology can be further elaborated from the adopted bibliographic research viewpoint considering the domain of research work [13].
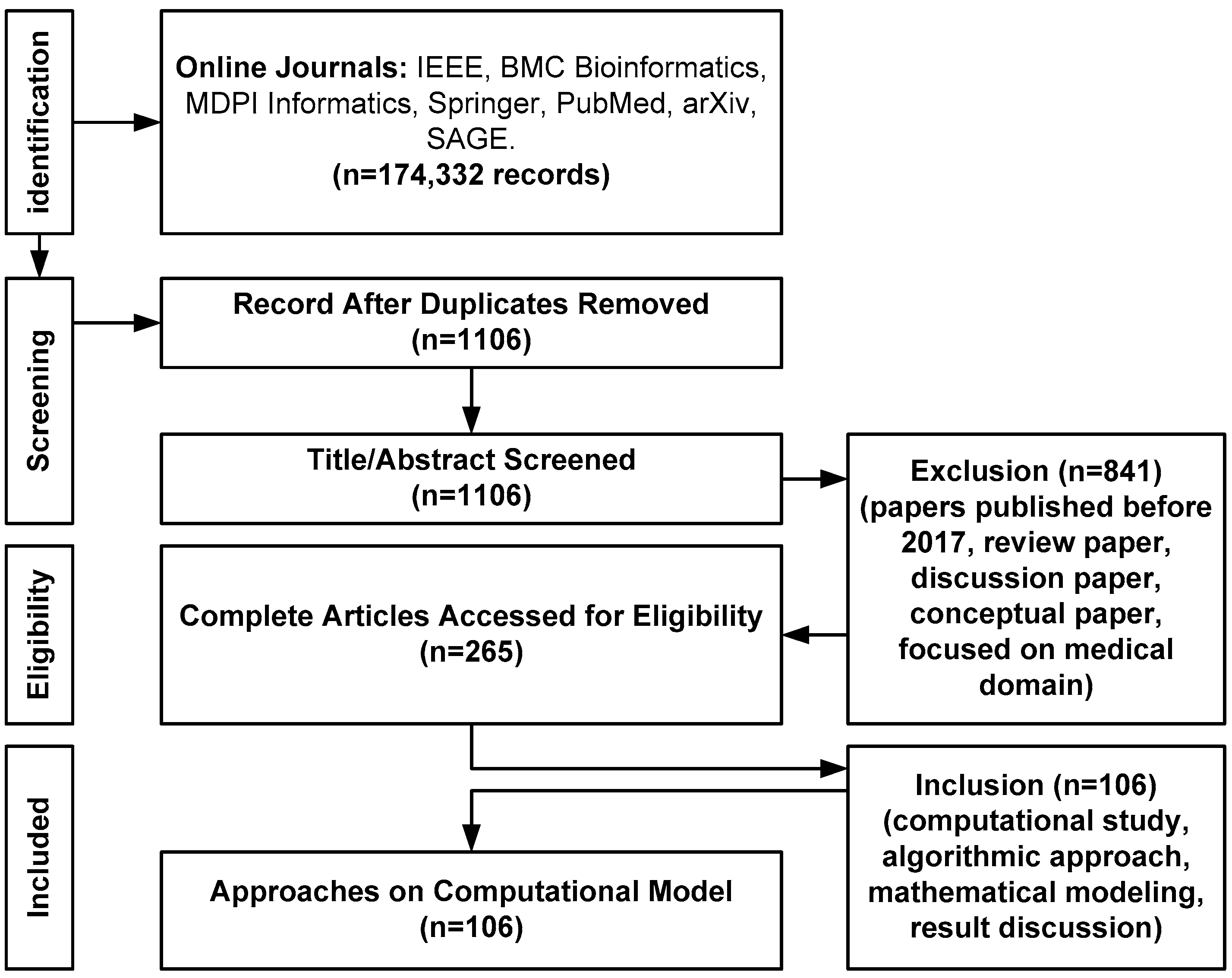
- Data Collection Method: The proposed scheme constructs a bibliography from varied sources of technical and experimental documents and articles [14]. The proposed study uses the Google search engine to find the names of all reputed Q1 and Q2 publishers and does not use the Google search engine to find the direct manuscript owing to the irrelevant number of hits. Using a Google search engine, the study identifies various relevant and top-notch journals to find the proposed topic. For, e.g., IEEE Transaction on Biomedical Engineering, IEEE Transactions on Industrial Informatics, IEEE/ACM Transactions on Computational Biology and Bioinformatics, BMC Medical Informatics and Decision Making (Springer), BMC Journal of Translational Medicine (Springer), International Journal of Medical Informatics (Elsevier), etc. The proposed study adopts PRISMA guidelines to construct its search strategy. The first author Sarika R. Khope has consulted journals such as IEEE, BMC, Elsevier, and MDPI, while the second author Susan Elias has referred to journals such as PubMed, arXiv, SAGE, and Springer. While performing the primary search using the above-mentioned query keywords during the period of 2013–2023, there are a total of 174,332 records. Finally, after applying a filter for the last 5 years, a total of 23,533 records have been obtained, which is finally subjected to filtering where EndNote has been used to remove the duplicates, and this has resulted in 1106 records as exhibited in Table 1.
- ○
- Inclusion Criteria: All the filtered study papers should discuss or offer a potential guideline toward design/algorithmic implementation approach using the MIMIC-III dataset. The keywords for inclusion criteria are: (i) primary keyword: MIMIC-III, (ii) secondary key word: result analysis, numerical analysis, experimental data, mathematical modelling, algorithm discussion.
- ○
- Exclusion Criteria: Any publication before 2017 has not been considered in the presented study. In addition, papers related to theoretical and iterative discussions are avoided. The keywords for exclusion criteria are: (i) primary keyword: MIMIC II, publication year less than 2017; (ii) secondary keyword: review, survey without significant insights.
- Constructing Structure of Manuscript Discussion: The MIMIC-III dataset is mainly used to analyze critical information during the hospital stay. Hence, various applications in this regard are connected to multiple predictive approaches [15]. It is also noted that machine learning and deep learning are the core technologies used in this perspective [16,17]. Therefore, the paper discusses classification and the usual predictive approach followed by an early predictive approach that covers most of the existing trends in bibliographic research. On the other hand, there are also various approaches to clinical diagnosis in order to offer more clinical insight. Hence, the paper discusses disease characterization-based techniques, detection techniques, and evaluation-based techniques associated with disease diagnosis for the MIMIC-III Dataset. This assists in offering a better flow of discussion toward assessing the impact of all existing research-based implementation models on disease diagnosis on the MIMIC-III dataset.
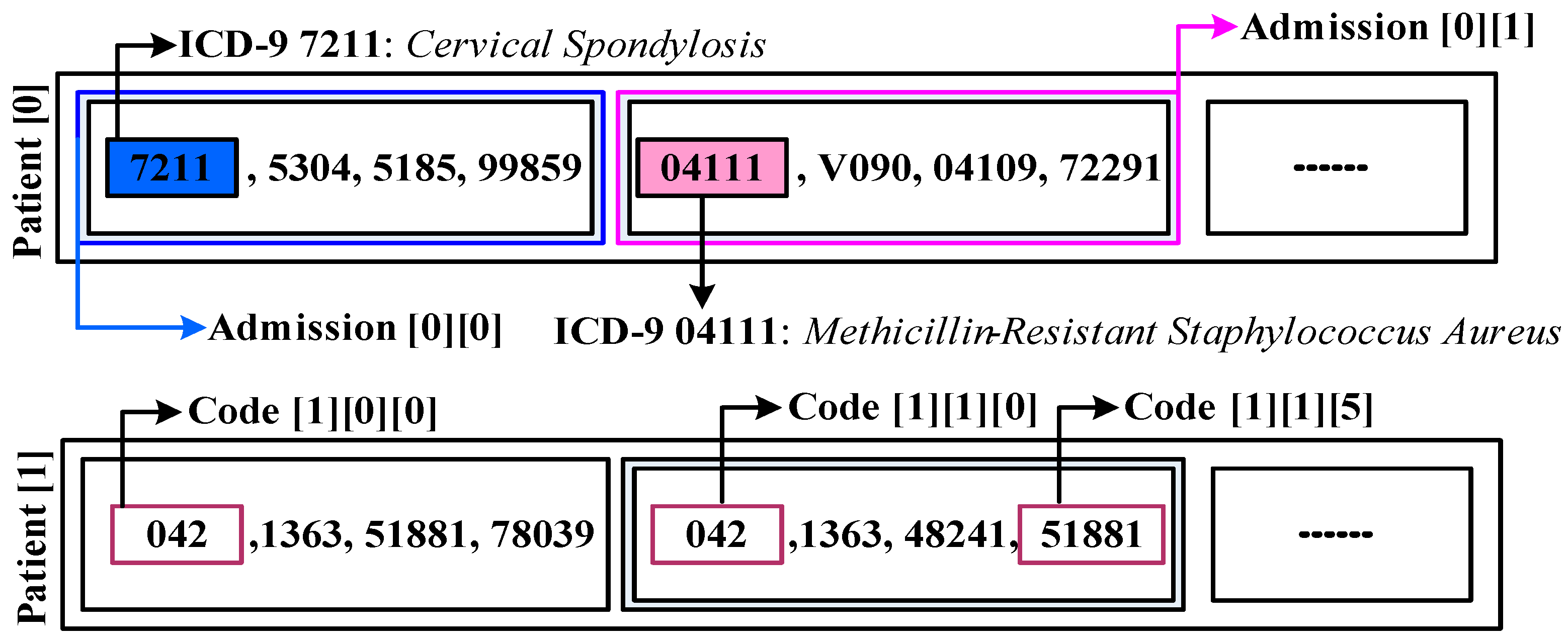
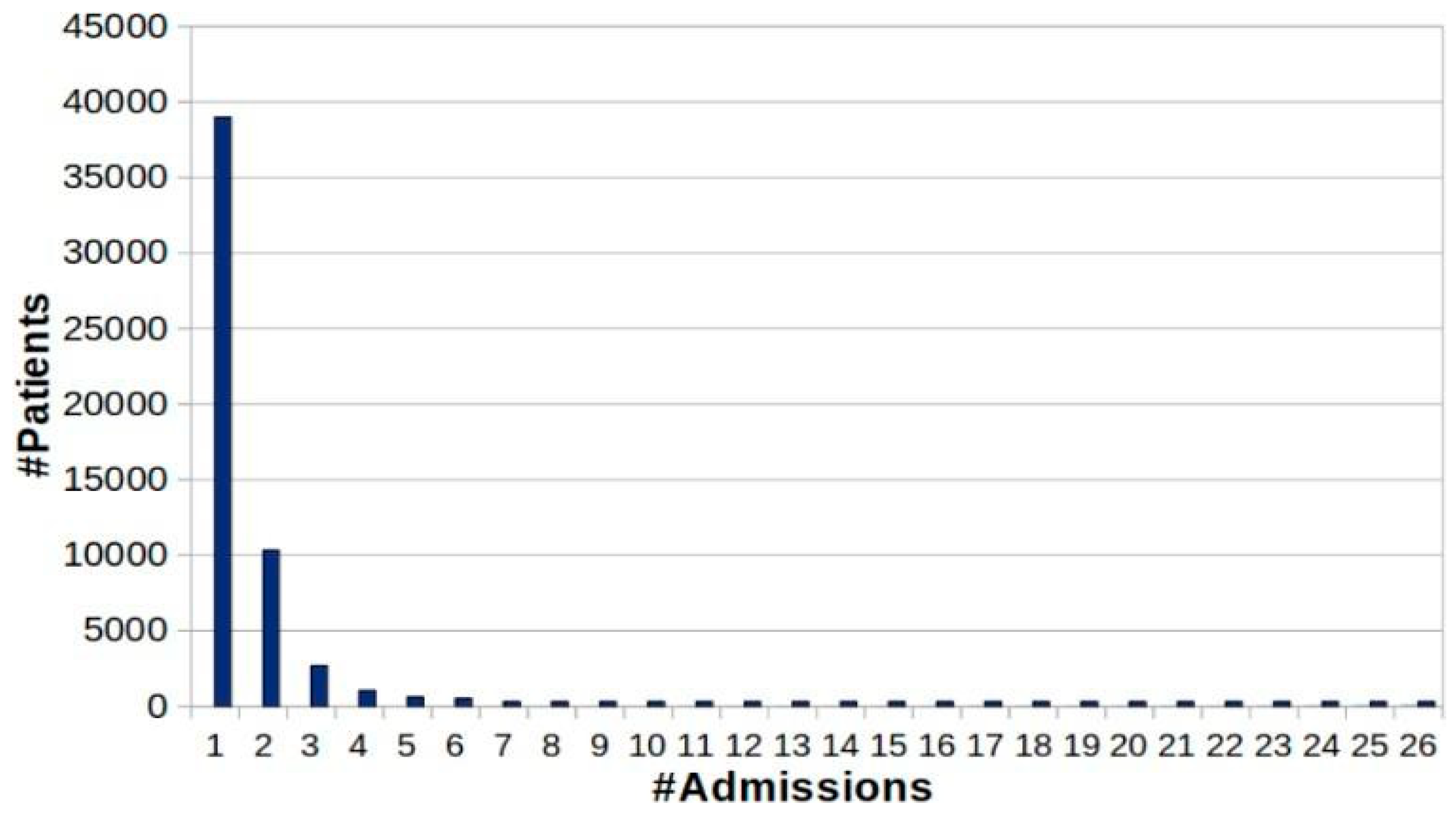
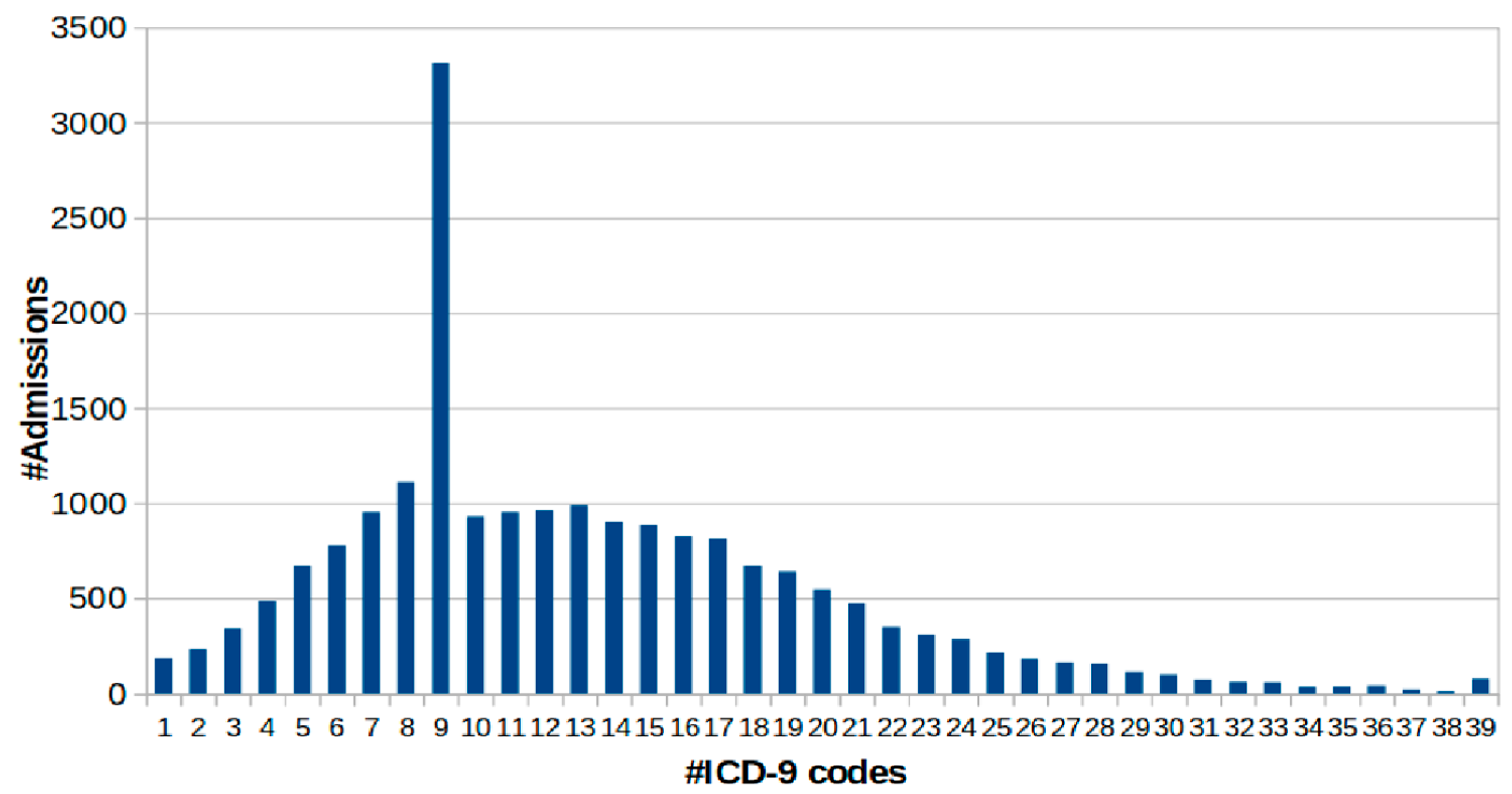
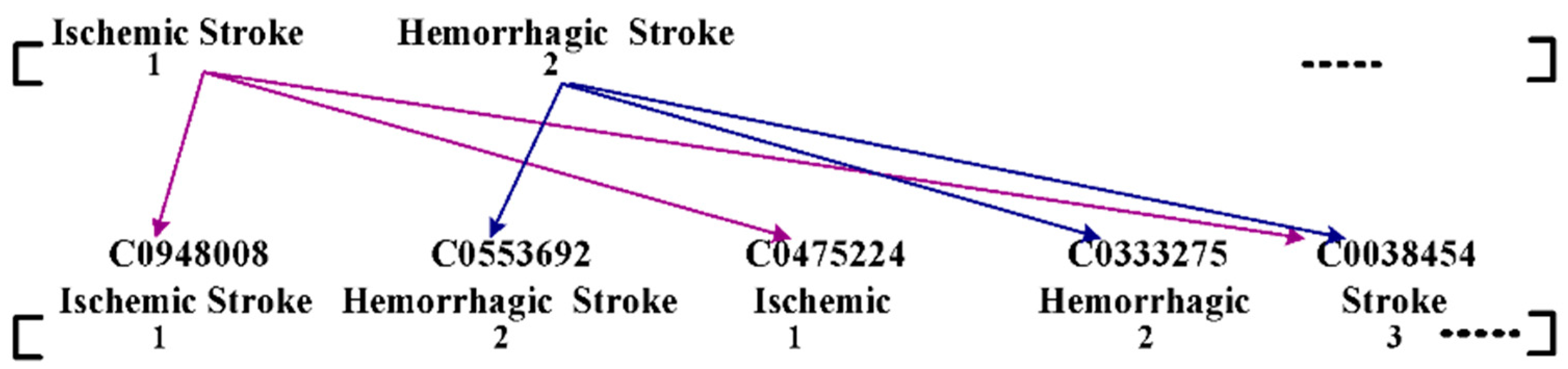
3. Significance/Challenges of MIMIC-III
- (i)
- Adopting highly granular standards, such as ICD-9, and
- (ii)
- Reducing cardinality. The cumulative quantified admission is discovered from the cardinality perspective.
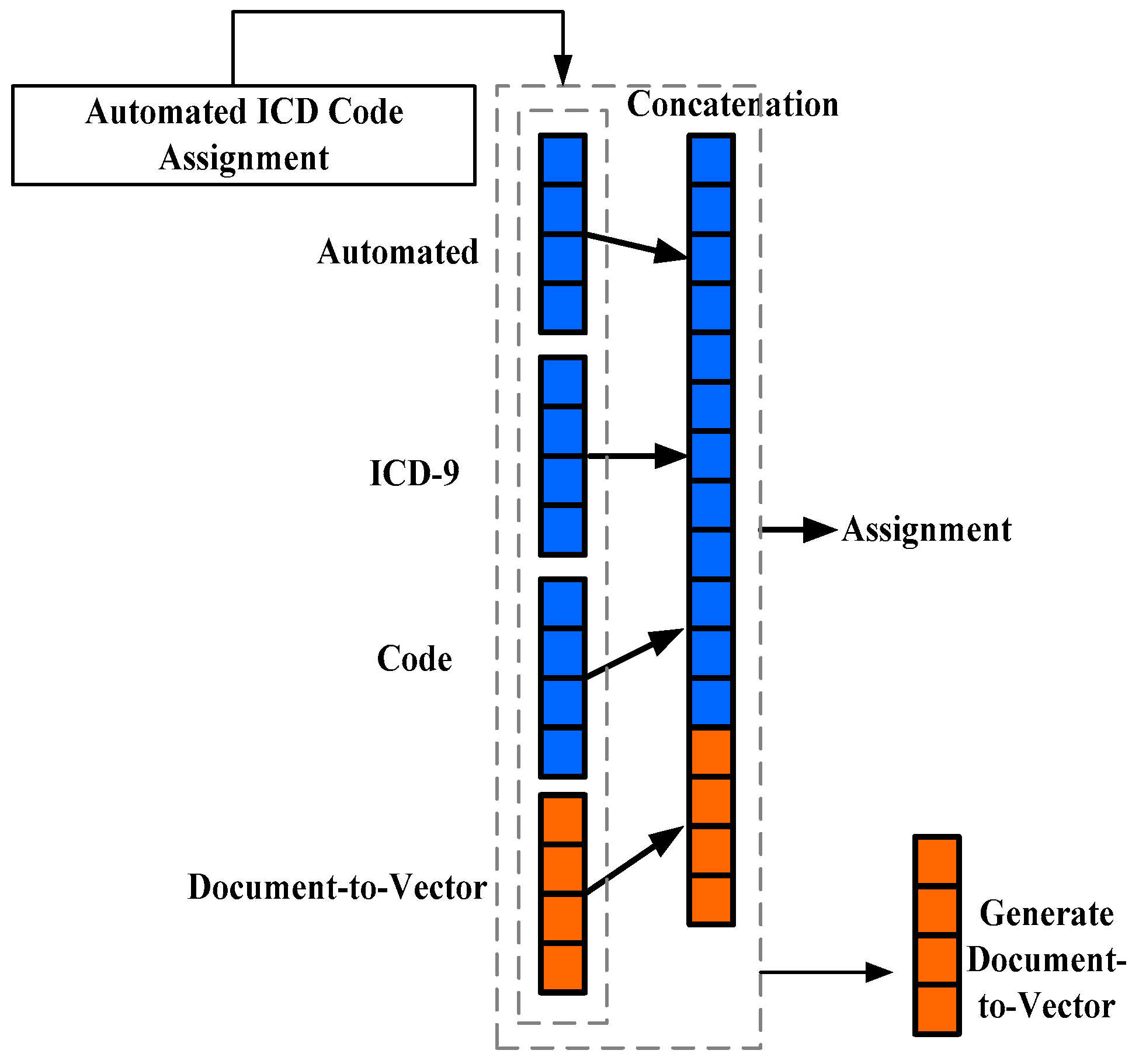
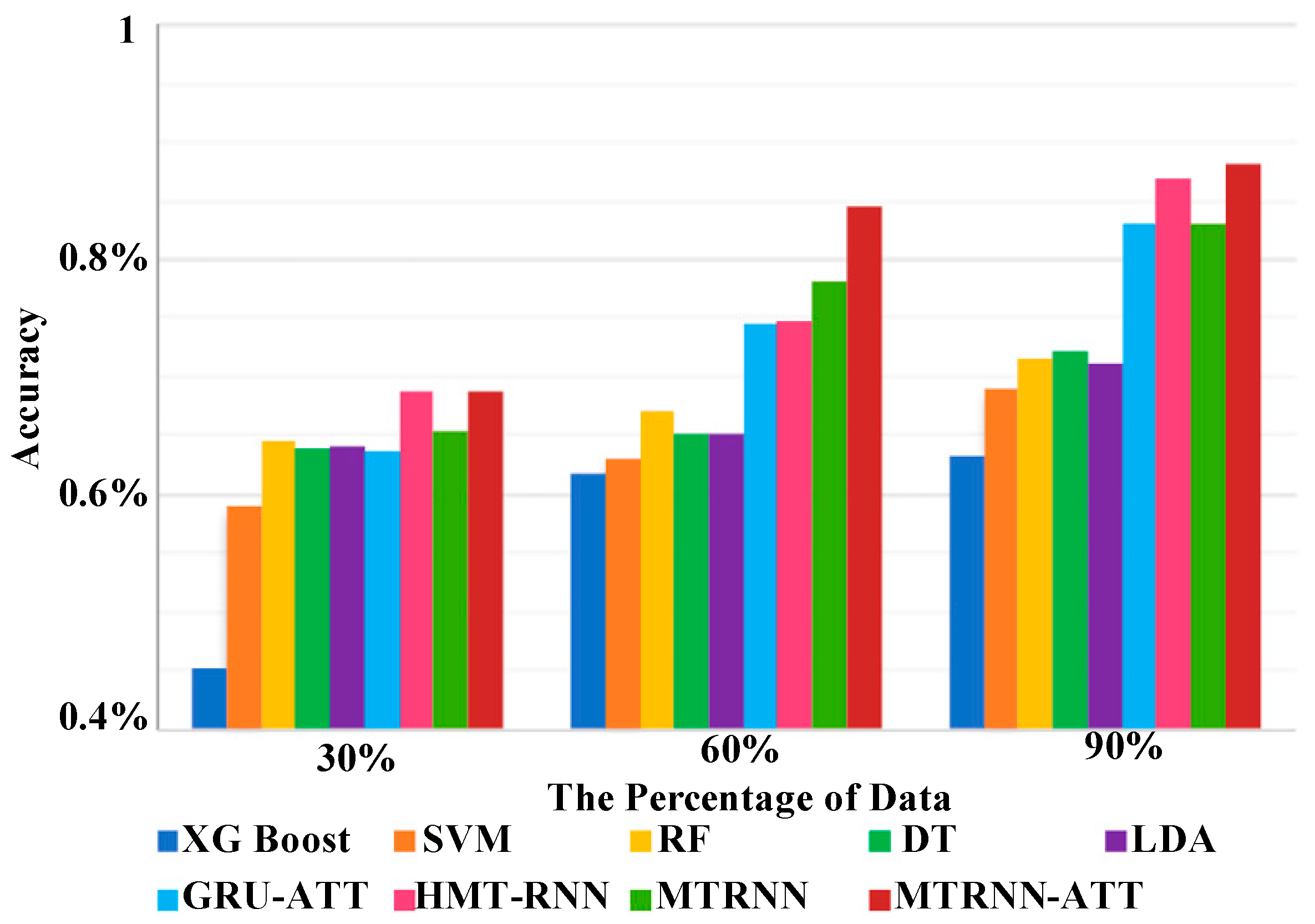
4. Predictive Approaches for MIMIC-III
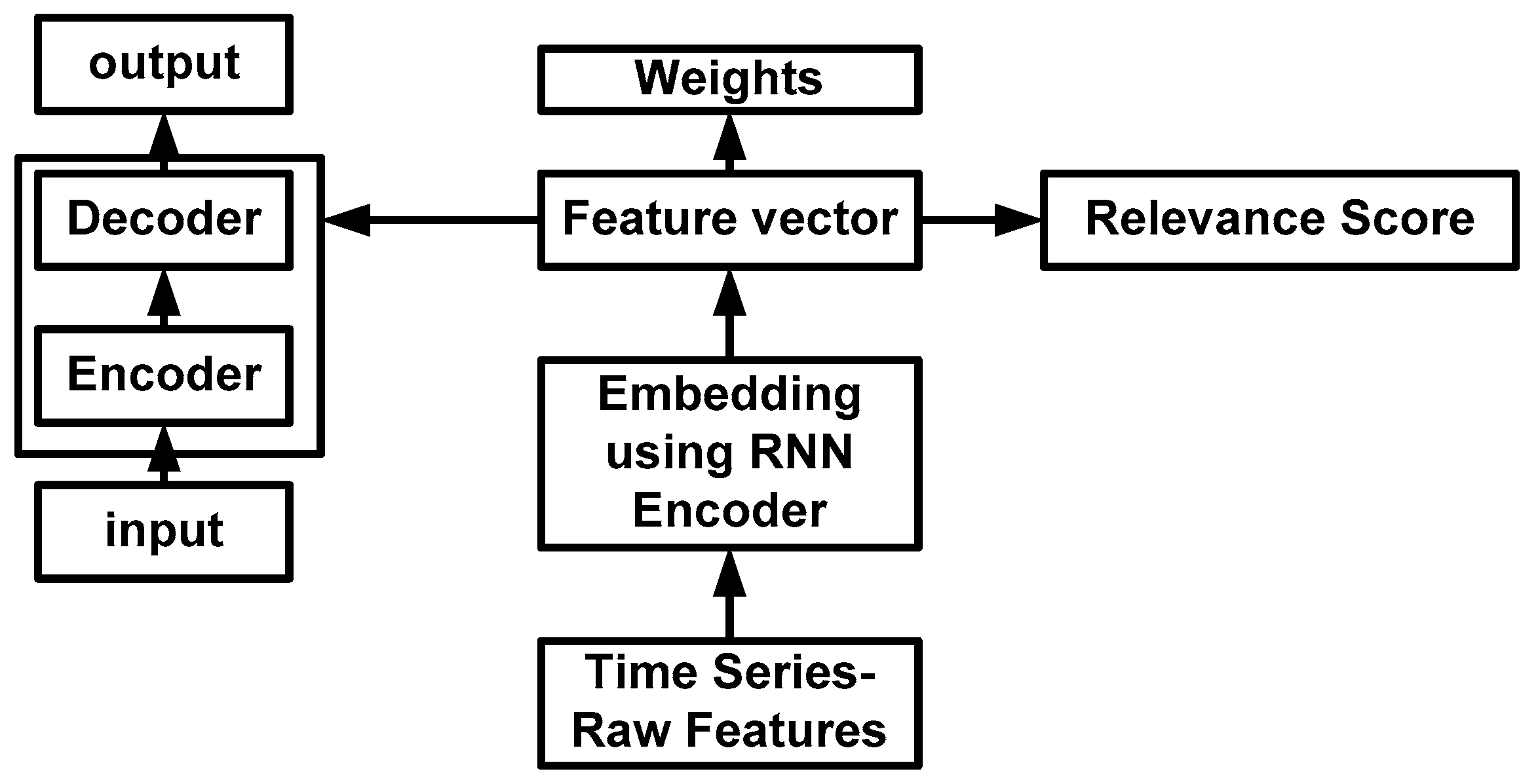
4.1. Classification-Based Approach
4.2. Numbering and Spacing
4.3. Early Predictive Approach
5. Clinical Diagnosis with MIMIC-III
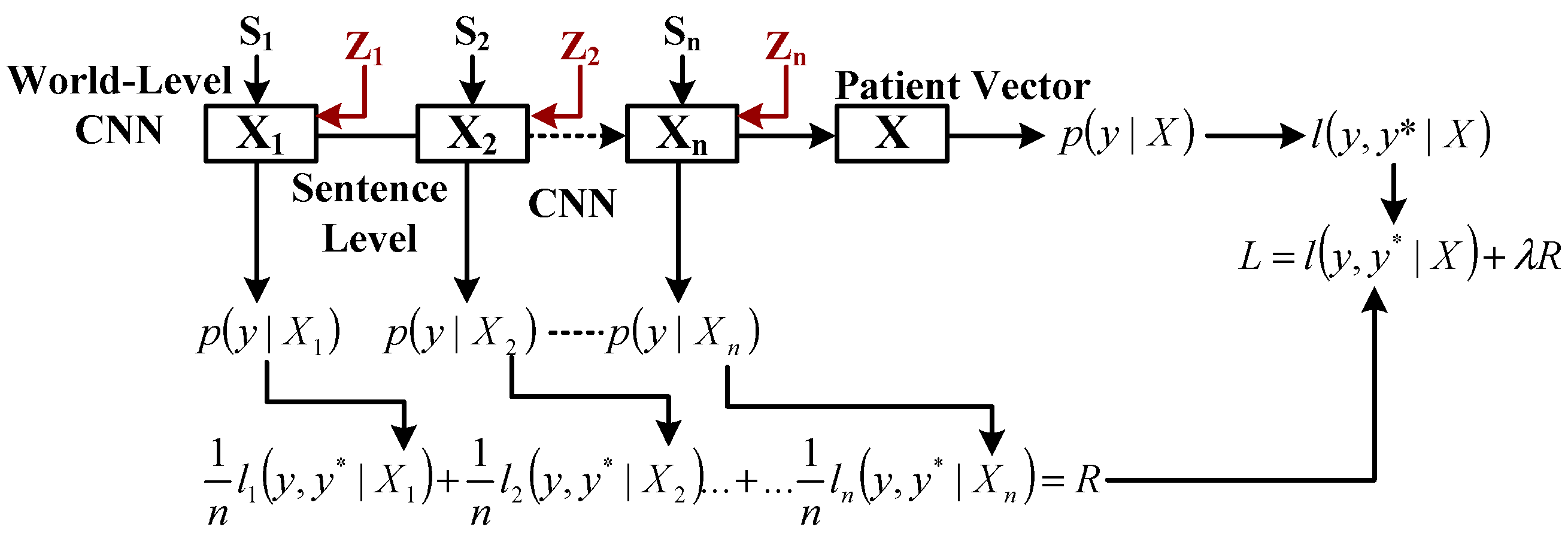
5.1. Disease Characterization Interpretation
5.2. Detection-Decisions Approach
5.3. Evaluation-Based Approach
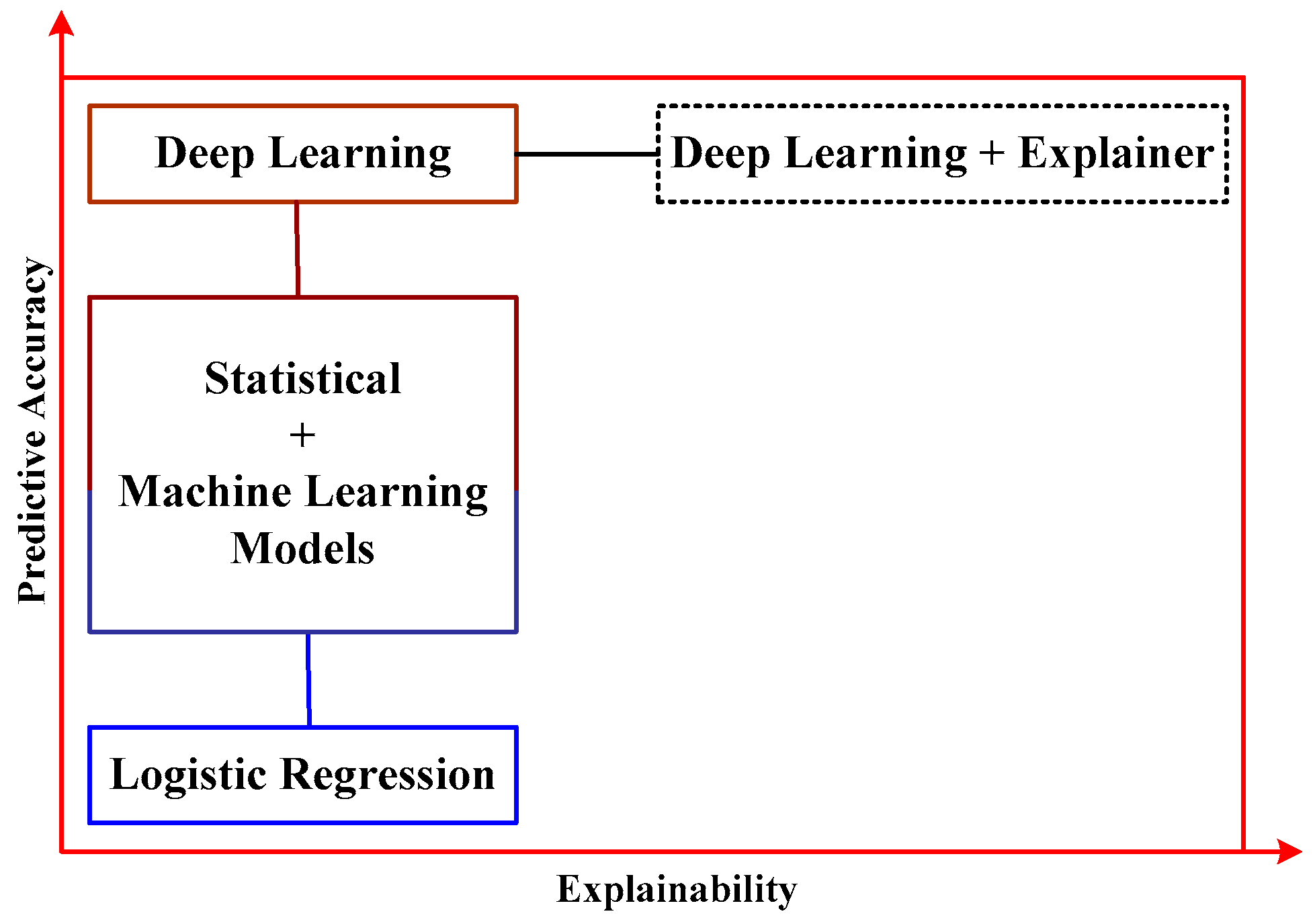
6. Learning Outcome of the Study
7. Open-End Issues
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Leung, C.K.; Fung, D.L.X.; Saad, B.; Leduchowski, T.O.; Bouchard, R.L.; Jin, H.; Cuzzocrea, A.; Zhang, C.Y. Data science for healthcare predictive analytics. In Proceedings of the 24th Symposium on International Database Engineering & Applications (2020), Seoul, Republic of Korea, 12–14 August 2020; pp. 1–10. [Google Scholar]
- Dash, S.; Shakyawar, S.K.; Sharma, M.; Kaushik, S. Big data in healthcare: Management, analysis and future prospects. J. Big. Data 2019, 6, 54. [Google Scholar] [CrossRef] [Green Version]
- Wang, B.; Zhang, J. Logistic Regression Analysis for LncRNA-Disease Association Prediction Based on Random Forest and Clinical Stage Data. IEEE Access 2020, 8, 35004–35017. [Google Scholar] [CrossRef]
- Alaa, A.M.; Yoon, J.; Hu, S.; van der Schaar, M. Personalized Risk Scoring for Critical Care Prognosis Using Mixtures of Gaussian Processes. IEEE Trans. Biomed. Eng. 2017, 65, 207–218. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shickel, B.; Tighe, P.J.; Bihorac, A.; Rashidi, P. Deep EHR: A Survey of Recent Advances in Deep Learning Techniques for Electronic Health Record (EHR) Analysis. IEEE J. Biomed. Health Inform. 2018, 22, 1589–1604. [Google Scholar] [CrossRef]
- Yadav, P.; Steinbach, M.; Kumar, V.; Simon, G. Mining Electronic Health Records (EHRs). ACM Comput. Surv. 2018, 50, 1–40. [Google Scholar] [CrossRef]
- Wu, P.Y.; Cheng, C.W.; Kaddi, C.D.; Venugopalan, J.; Hoffman, R.; Wang, M.D. –Omic and Electronic Health Record Big Data Analytics for Precision Medicine. IEEE Trans. Biomed. Eng. 2017, 64, 263–273. [Google Scholar]
- Zhang, C.; Ma, R.; Sun, S.; Li, Y.; Wang, Y.; Yan, Z. Optimizing the Electronic Health Records Through Big Data Analytics: A Knowledge-Based View. IEEE Access 2019, 7, 136223–136231. [Google Scholar] [CrossRef]
- Chen, D.; Chen, Y.; Brownlow, B.N.; Kanjamala, P.P.; Arredondo, C.A.G.; Radspinner, B.L.; Raveling, M.A. Real-Time or Near Real-Time Persisting Daily Healthcare Data Into HDFS and ElasticSearch Index Inside a Big Data Platform. IEEE Trans. Ind. Inform. 2016, 13, 595–606. [Google Scholar] [CrossRef]
- Ramakrishnan, N.; Hanauer, D.; Keller, B. Mining Electronic Health Records. Computer 2010, 43, 77–81. [Google Scholar] [CrossRef]
- Johnson, A.; Pollard, T.; Mark, R. MIMIC-III Clinical Database Demo. PhysioNet 2019, 10, C2HM2Q. [Google Scholar]
- Lavrakas, P.J. Encyclopedia of Survey Research Methods; Lavrakas, P., Ed.; Sage Publications, Inc.: Thousand Oaks, CA, USA, 2008. [Google Scholar] [CrossRef]
- Allen, M. Bibliographic Research. In The SAGE Encyclopedia of Communication Research Methods; Sage Publications: Thousand Oaks, CA, USA, 2017. [Google Scholar] [CrossRef]
- Dattolo, A.; Corbatto, M. Assisting researchers in bibliographic tasks: A new usable, real-time tool for analyzing bibliographies. J. Assoc. Inf. Sci. Technol. 2021, 73, 757–776. [Google Scholar] [CrossRef]
- Huang, K.; Altosaar, J.; Ranganath, R. ClinicalBERT: Modeling clinical notes and predicting hospital readmission. arXiv 2019. [Google Scholar] [CrossRef]
- Nallabasannagari, A.; Reddiboina, M.; Seltzer, R.; Zeffiro, T.; Sharma, A.; Bhandari, M. All Data Inclusive, Deep Learning Models to Predict Critical Events in the Medical Information Mart for Intensive Care III Database (MIMIC III). arXiv 2020, arXiv:2009.01366. [Google Scholar] [CrossRef]
- Syed, M.; Syed, S.; Sexton, K.; Syeda, H.; Garza, M.; Zozus, M.; Syed, F.; Begum, S.; Syed, A.; Sanford, J.; et al. Application of Machine Learning in Intensive Care Unit (ICU) Settings Using MIMIC Dataset: Systematic Review. Informatics 2021, 8, 16. [Google Scholar] [CrossRef] [PubMed]
- Zeng, Z.; Deng, Y.; Li, X.; Naumann, T.; Luo, Y. Natural Language Processing for EHR-Based Computational Phenotyping. IEEE/ACM Trans. Comput. Biol. Bioinform. 2018, 16, 139–153. [Google Scholar] [CrossRef] [PubMed]
- Chen, M.; Hao, Y.; Hwang, K.; Wang, L.; Wang, L. Disease Prediction by Machine Learning Over Big Data From Healthcare Communities. IEEE Access 2017, 5, 8869–8879. [Google Scholar] [CrossRef]
- Golembiewski, E.; Allen, K.S.; Blackmon, A.M.; Hinrichs, R.J.; Vest, J.R. Combining Nonclinical Determinants of Health and Clinical Data for Research and Evaluation: Rapid Review. JMIR Public Health Surveill. 2019, 5, e12846. [Google Scholar] [CrossRef] [Green Version]
- Ridzuan, F.; Zainon, W.M.N.W. A Review on Data Cleansing Methods for Big Data. Procedia Comput. Sci. 2019, 161, 731–738. [Google Scholar]
- Wan, L.; Song, J.; He, V.; Roman, J.; Whah, G.; Peng, S.; Zhang, L.; He, Y. Development of the International Classification of Diseases Ontology (ICDO) and its application for COVID-19 diagnostic data analysis. BMC Bioinform. 2021, 22, 508. [Google Scholar] [CrossRef]
- Mapiye, D.; Mokoatle, M.; Makoro, D.; Muller, S.J.; Dlamini, G.S.; Mashiyane, J.; Joseph, L.; Ismail, N.; Omar, S.V. Phenotype Prediction of DNA Sequence Data: A Machine- and Statistical Learning Approach. In Proceedings of the 2020 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), Via del Mar, Chile, 27–29 October 2020; pp. 1–10. [Google Scholar] [CrossRef]
- Jaskari, J.; Myllarinen, J.; Leskinen, M.; Rad, A.B.; Hollmen, J.; Andersson, S.; Sarkka, S. Machine Learning Methods for Neonatal Mortality and Morbidity Classification. IEEE Access 2020, 8, 123347–123358. [Google Scholar] [CrossRef]
- Mahendran, N.; Vincent, P.M.D.R.; Srinivasan, K.; Sharma, V.; Jayakody, D.N.K. Realizing a Stacking Generalization Model to Improve the Prediction Accuracy of Major Depressive Disorder in Adults. IEEE Access 2020, 8, 49509–49522. [Google Scholar] [CrossRef]
- Shi, H.; Xie, P.; Hu, Z.; Zhang, M.; Xing, E. Towards Automated ICD Coding Using Deep, Learning. arXiv 2017, arXiv:1711.04075v3. [Google Scholar]
- Elsayad, A.S.; El Desouky, A.I.; Salem, M.M.; Badawy, M. A Deep Learning H2O Framework for Emergency Prediction in Biomedical Big Data. IEEE Access 2020, 8, 97231–97242. [Google Scholar] [CrossRef]
- Li, J.P.; Haq, A.U.; Din, S.U.; Khan, J.; Khan, A.; Saboor, A. Heart Disease Identification Method Using Machine Learning Classification in E-Healthcare. IEEE Access 2020, 8, 107562–107582. [Google Scholar] [CrossRef]
- Nigam, P. Applying Deep Learning to ICD-9 Multi-Label Classification from Medical Records; Technical Report; Stanford University: Stanford, CA, USA, 2016. [Google Scholar]
- Baumel, T.; N-Kassis, J.; Cohen, R.; Elhadad, M.; Elhadad, N. Multi-label classification of patient notes a case study on ICD code assignment. arXiv 2017, arXiv:1709.09587. [Google Scholar]
- Bao, W.; Lin, H.; Zhang, Y.; Wang, J.; Zhang, S. Medical code prediction via capsule networks and ICD knowledge. BMC Med. Inform. Decis. Mak. 2021, 21, 55. [Google Scholar] [CrossRef]
- Sagi, T.; Hansen, E.R.; Hose, K.; Lip, G.Y.H.; Bjerregaard Larsen, T.; Skjøth, F. Towards Assigning Diagnosis Codes Using Medication History. In Artificial Intelligence in Medicine, Proceedings of the AIME 2020, Minneapolis, MN, USA, 25–28 August 2020; Michalowski, M., Moskovitch, R., Eds.; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2020; Volume 12299. [Google Scholar]
- Ye, J.; Yao, L.; Shen, J.; Janarthanam, R.; Luo, Y. Predicting mortality in critically ill patients with diabetes using machine learning and clinical notes. BMC Med. Inform. Decis. Mak. 2020, 20, 295. [Google Scholar] [CrossRef]
- Hou, N.; Li, M.; He, L.; Xie, B.; Wang, L.; Zhang, R.; Yu, Y.; Sun, X.; Pan, Z.; Wang, K. Predicting 30-days mortality for MIMIC-III patients with sepsis-3: A machine learning ap-proach using XGboost. J. Transl. Med. 2020, 18, 462. [Google Scholar] [CrossRef]
- Veith, N.; Steele, R. Machine learning-based prediction of ICU patient mortality at the time of admission. In Proceedings of the 2nd International Conference on Information System and Data Mining, Lakeland, FL, USA, 9–11 April 2018; pp. 34–38. [Google Scholar]
- Gong, J.; Naumann, T.; Szolovits, P.; Guttag, J. Predicting clinical outcomes across changing electronic health record systems. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 1497–1505. [Google Scholar]
- Rojas, J.C.; Carey, K.A.; Edelson, D.P.; Venable, L.R.; Howell, M.D.; Churpek, M.M. Predicting Intensive Care Unit Readmission with Machine Learning Using Electronic Health Record Data. Ann. Am. Thorac. Soc. 2018, 15, 846–853. [Google Scholar] [CrossRef] [PubMed]
- Gentimis, T.; Alnaser, A.J.; Durante, A.; Cook, K.; Steele, R. Predicting hospital length of stay using neural networks on mimic iii data. In Proceedings of the 2017 IEEE 15th Intl Conf on Dependable, Autonomic and Secure Computing, 15th Intl Conf on Pervasive Intelligence and Computing, 3rd Intl Conf on Big Data Intelligence and Computing, and Cyber Science and Technology Congress (DASC/PiCom/DataCom/CyberSciTech), Orlando, FL, USA, 6–10 November 2017; pp. 1194–1201. [Google Scholar]
- Chen, W.; Wang, S.; Long, G.; Yao, L.; Sheng, Q.Z.; Li, X. Dynamic Illness Severity Prediction via Multi-task RNNs for Intensive Care Unit. In Proceedings of the IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; pp. 917–922. [Google Scholar] [CrossRef]
- Meiring, C.; Dixit, A.; Harris, S.; Maccallum, N.S.; Brealey, D.A.; Watkinson, P.; Jones, A.; Ashworth, S.; Beale, R.; Brett, S.J.; et al. Optimal intensive care outcome prediction over time using machine learning. PLoS ONE 2018, 13, e0206862. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jin, B.; Yang, H.; Sun, L.; Liu, C.; Qu, Y.; Tong, J. A treatment engine by predicting next-period prescriptions. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1608–1616. [Google Scholar]
- Xia, J.; Pan, S.; Zhu, M.; Cai, G.; Yan, M.; Su, Q.; Yan, J.; Ning, G. A Long Short-Term Memory Ensemble Approach for Improving the Outcome Prediction in Intensive Care Unit. Comput. Math. Methods Med. 2019, 2019, 8152713. [Google Scholar] [CrossRef]
- Yu, K.; Zhang, M.; Cui, T.; Hauskrecht, M. Monitoring ICU Mortality Risk with A Long Short-Term Memory Recurrent Neural Network. Biocomputing 2020, 25, 103–114. [Google Scholar] [CrossRef]
- Li, Q.; Huang, L.F.; Zhong, J.; Li, L.; Li, Q.; Hu, J. Data-driven Discovery of a Sepsis Patients Severity Prediction in the ICU via Pre-training BiLSTM Networks. In Proceedings of the 2019 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), San Diego, CA, USA, 18–21 November 2019; pp. 668–673. [Google Scholar] [CrossRef]
- Yang, H.; Kuang, L.; Xia, F. Multimodal temporal-clinical note network for mortality prediction. J. Biomed. Semant. 2021, 12, 3. [Google Scholar] [CrossRef]
- Aljuffri, A.; Reinbrecht, C.; Hamdioui, S.; Taouil, M. Impact of Data Pre-Processing Techniques on Deep Learning Based Power Attacks. In Proceedings of the 2021 16th International Conference on Design & Technology of Integrated Systems in Nanoscale Era (DTIS), Montpellier, France, 28–30 June 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Zelaya, C.V.G. Towards Explaining the Effects of Data Preprocessing on Machine Learning. In Proceedings of the 2019 IEEE 35th International Conference on Data Engineering (ICDE), Macao, China, 8–11 April 2019; pp. 2086–2090. [Google Scholar] [CrossRef]
- Fangyu, W.; Jianhui, Z.; Youjun, B.; Bo, C. Research on imbalanced data set preprocessing based on deep learning. In Proceedings of the 2021 Asia-Pacific Conference on Communications Technology and Computer Science (ACCTCS), Shenyang, China, 22–24 January 2021; pp. 75–79. [Google Scholar] [CrossRef]
- Gupta, P.; Malhotra, P.; Vig, L.; Shroff, G. Transfer learning for clinical time series analysis using recurrent neural networks. arXiv 2018, arXiv:1807.01705. [Google Scholar]
- Rodrigues-Jr, J.F.; Gutierrez, M.A.; Spadon, G.; Brandoli, B.; Amer-Yahia, S. LIG-Doctor: Efficient patient trajectory prediction using bidirectional minimal gated-recurrent networks. Inf. Sci. 2021, 545, 813–827. [Google Scholar] [CrossRef]
- Su, C.; Gao, S.; Li, S. GATE: Graph-Attention Augmented Temporal Neural Network for Medication Recommendation. IEEE Access 2020, 8, 125447–125458. [Google Scholar] [CrossRef]
- Mao, Q.; Jay, M.; Hoffman, J.L.; Calvert, J.; Barton, C.; Shimabukuro, D.; Shieh, L.; Chettipally, U.; Fletcher, G.; Kerem, Y.; et al. Multicentre validation of a sepsis prediction algorithm using only vital sign data in the emergency department, general ward and ICU. BMJ Open 2018, 8, e017833. [Google Scholar] [CrossRef] [Green Version]
- Scherpf, M.; Gräßer, F.; Malberg, H.; Zaunseder, S. Predicting sepsis with a recurrent neural network using the MIMIC III database. Comput. Biol. Med. 2019, 113, 103395. [Google Scholar] [CrossRef]
- Desautels, T.; Calvert, J.; Hoffman, J.; Jay, M.; Kerem, Y.; Shieh, L.; Shimabukuro, D.; Chettipally, U.; Feldman, M.D.; Barton, C.; et al. Prediction of Sepsis in the Intensive Care Unit With Minimal Electronic Health Record Data: A Machine Learning Approach. JMIR Public Health Surveill. 2016, 4, e28. [Google Scholar] [CrossRef]
- Xu, Y.; Biswal, S.; Deshpande, S.; Maher, K.; Sun, J. Raim: Recurrent attentive and intensive model of multimodal patient monitoring data. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 2565–2573. [Google Scholar]
- Nanayakkara, S.; Fogarty, S.; Tremeer, M.; Ross, K.; Richards, B.; Bergmeir, C.; Xu, S.; Stub, D.; Smith, K.; Tacey, M.; et al. Characterising risk of in-hospital mortality following cardiac arrest using machine learning: A retrospective international registry study. PLoS Med. 2018, 15, e1002709. [Google Scholar] [CrossRef] [Green Version]
- Parreco, J.; Hidalgo, A.E.; Badilla, A.D.; Ilyas, O.; Rattan, R. Predicting central line-associated bloodstream infections and mortality using supervised machine learning. J. Crit. Care 2018, 45, 156–162. [Google Scholar] [CrossRef] [PubMed]
- Grnarova, P.; Schmidt, F.; Hyland, S.L.; Eickhoff, C. Neural document embeddings for intensive care patient mortality prediction. arXiv 2016, arXiv:1612.00467. [Google Scholar]
- Zhang, Z.; Ho, K.M.; Hong, Y. Machine learning for the prediction of volume responsiveness in patients with oliguric acute kidney injury in critical care. Crit. Care 2019, 23, 112. [Google Scholar] [CrossRef] [Green Version]
- Davoodi, R.; Moradi, M. Mortality prediction in intensive care units (ICUs) using a deep rule-based fuzzy classi-fier. J. Biomed. Inform. 2018, 79, 48–59. [Google Scholar] [CrossRef]
- Ding, N.; Guo, C.; Li, C.; Zhou, Y.; Chai, X. An Artificial Neural Networks Model for Early Predicting In-Hospital Mortality in Acute Pancreatitis in MIMIC-III. BioMed Res. Int. 2021, 2021, 6638919. [Google Scholar] [CrossRef]
- Zimmerman, L.P.; Reyfman, P.A.; Smith, A.D.R.; Zeng, Z.; Kho, A.; Sanchez-Pinto, L.N.; Luo, Y. Early prediction of acute kidney injury following ICU admission using a multivariate panel of physiological measurements. BMC Med. Inform. Decis. Mak. 2019, 19, 16. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, K.; Hu, Y.; Kong, G. Predicting in-hospital mortality of patients with acute kidney injury in the ICU using random forest model. Int. J. Med. Inform. 2019, 125, 55–61. [Google Scholar] [CrossRef] [PubMed]
- Nestor, B.; McDermott, M.; Boag, W.; Berner, G.; Naumann, T.; Hughes, M.; Goldenberg, A.; Ghassemi, M. Feature robustness in non-stationary health records: Caveats to deployable model performance in common clinical machine learning tasks. PMLR 2019, 106, 381–405. [Google Scholar]
- Suresh, H.; Gong, J.; Guttag, J. Learning tasks for multitask learning: Heterogenous patient populations in the icu. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 802–810. [Google Scholar]
- Li, Y.; Yao, L.; Mao, C.; Srivastava, A.; Jiang, X.; Luo, Y. Early Prediction of Acute Kidney Injury in Critical Care Setting Using Clinical Notes. In Proceedings of the 2018 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Madrid, Spain, 3–6 December 2018; pp. 683–686. [Google Scholar] [CrossRef] [Green Version]
- Sadeghi, R.; Banerjee, T.; Romine, W. Early hospital mortality prediction using vital signals. Smart Health 2018, 9–10, 265–274. [Google Scholar] [CrossRef]
- Javan, S.L.; Sepehri, M.M.; Javan, M.L.; Khatibi, T. An intelligent warning model for early prediction of cardiac arrest in sepsis patients. Comput. Methods Programs Biomed. 2019, 178, 47–58. [Google Scholar] [CrossRef]
- Awad, A.; Bader-El-Den, M.; McNicholas, J.; Briggs, J. Early hospital mortality prediction of intensive care unit patients using an ensemble learning approach. Int. J. Med. Inform. 2017, 108, 185–195. [Google Scholar] [CrossRef] [Green Version]
- García-Gallo, J.; Fonseca-Ruiz, N.J.; Celi, L.A.; Duitama-Muñoz, J.F. A machine learning-based model for 1-year mortality prediction in patients admitted to an Intensive Care Unit with a diagnosis of sepsis. Med. Intensive 2020, 44, 160–170. [Google Scholar] [CrossRef] [PubMed]
- Bashar, S.K.; Hossain, M.B.; Ding, E.; Walkey, A.J.; McManus, D.D.; Chon, K.H. Atrial Fibrillation Detection During Sepsis: Study on MIMIC III ICU Data. IEEE J. Biomed. Health Inform. 2020, 24, 3124–3135. [Google Scholar] [CrossRef] [PubMed]
- Fan, T.; Wang, H.; Wang, J.; Wang, W.; Guan, H.; Zhang, C. Nomogram to predict the risk of acute kidney injury in patients with diabetic ketoacidosis: An analysis of the MIMIC-III database. BMC Endocr. Disord. 2021, 21, 37. [Google Scholar] [CrossRef] [PubMed]
- Dai, Z.; Liu, S.; Wu, J.; Li, M.; Liu, J.; Li, K. Analysis of adult disease characteristics and mortality on MIMIC-III. PLoS ONE 2020, 15, e0232176. [Google Scholar] [CrossRef]
- Prakash, A.; Zhao, S.; Hasan, S.; Datla, V.; Lee, K.; Qadir, A.; Liu, J.; Farri, O. Condensed Memory Networks for Clinical Diagnostic Inferencing. arXiv 2016, arXiv:1612.01848. [Google Scholar] [CrossRef]
- Tulkens, S.; Suster, S.; Daelemans, W. Using Distributed Representations to Disambiguate Biomedical and Clinical Concepts. arXiv 2016, arXiv:1608.05605. [Google Scholar] [CrossRef] [Green Version]
- Mullenbach, J.; Wiegreffe, S.; Duke, J.; Sun, J.; Eisenstein, J. Explainable Prediction of Medical Codes from Clinical Text. In Proceedings of the 8th ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics, Boston, MA, USA, 20–23 August 2017; pp. 233–240. [Google Scholar] [CrossRef] [Green Version]
- Sha, Y.; Wang, M.D. Interpretable Predictions of Clinical Outcomes with An Attention-based Recurrent Neural Network. In Proceedings of the 8th ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics, Boston, MA, USA, 20–23 August 2017; pp. 233–240. [Google Scholar] [CrossRef]
- Che, Z.; Liu, Y. Deep learning solutions to computational phenotyping in health care. In Proceedings of the 2017 IEEE International Conference on Data Mining Workshops (ICDMW), New Orleans, LA, USA, 18–21 November 2017; pp. 1100–1109. [Google Scholar]
- Choi, E.; Bahadori, M.T.; Song, L.; Stewart, W.F.; Sun, J. GRAM: Graph-based attention model for healthcare repre-sentation learning. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 787–795. [Google Scholar]
- McWilliams, C.J.; Lawson, D.J.; Santos-Rodriguez, R.; Gilchrist, I.D.; Champneys, A.; Gould, T.H.; Thomas, M.J.; Bourdeaux, C.P. Towards a decision support tool for intensive care discharge: Machine learning algorithm development using electronic healthcare data from MIMIC-III and Bristol, UK. BMJ Open 2019, 9, e025925. [Google Scholar] [CrossRef] [Green Version]
- Alon, G.; Chen, E.; Savova, G.; Eickhoff, C. Diagnosis Prevalence vs. Efficacy in Machine-learning Based Diagnostic Decision Support. arXiv 2020, arXiv:2006.13737. [Google Scholar]
- Chen, W.; Long, G.; Yao, L.; Sheng, Q.S. AMRNN: Attended multi-task recurrent neural networks for dynamic illness severity prediction. World Wide Web 2020, 23, 2753–2770. [Google Scholar] [CrossRef]
- Kaji, D.A.; Zech, J.R.; Kim, J.; Cho, S.K.; Dangayach, N.S.; Costa, A.; Oermann, E.K. An attention based deep learning model of clinical events in the intensive care unit. PLoS ONE 2019, 14, e0211057. [Google Scholar] [CrossRef] [Green Version]
- Raghu, A.; Komorowski, M.; Singh, S. Model-based reinforcement learning for sepsis treatment. arXiv 2018, arXiv:1811.09602. [Google Scholar]
- Huang, J.; Osorio, C.; Sy, L.W. An empirical evaluation of deep learning for ICD-9 code assignment using MIMIC-III clinical notes. Comput. Methods Programs Biomed. 2019, 177, 141–153. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gehrmann, S.; Dernoncourt, F.; Li, Y.; Carlson, E.T.; Wu, J.T.; Welt, J.; Foote, J. Comparing rule-based and deep learning models for patient phenotyping. arXiv 2017, arXiv:1703.08705. [Google Scholar]
- Beaulieu-Jones, B.K.; Orzechowski, P.; Moore, J.H. Mapping Patient Trajectories using Longitudinal Extraction and Deep Learning in the MIMIC-III Critical Care Database Biocomputing. Pac. Symp Biocomput. 2018, 23, 123–132. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Purushotham, S.; Meng, C.; Che, Z.; Liu, Y. Benchmarking deep learning models on large healthcare datasets. J. Biomed. Inform. 2018, 83, 112–134. [Google Scholar] [CrossRef]
- Harutyunyan, H.; Khachatrian, H.; Kale, D.C.; Ver Steeg, G.; Galstyan, A. Multitask learning and benchmarking with clinical time series data. Sci. Data 2019, 6, 96. [Google Scholar] [CrossRef] [Green Version]
- Meyer, A.; Zverinski, D.; Pfahringer, B.; Kempfert, J.; Kuehne, T.; Sündermann, S.H.; Stamm, C.; Hofmann, T.; Falk, V.; Eickhoff, C. Machine learning for real-time prediction of complications in critical care: A retrospective study. Lancet Respir. Med. 2018, 6, 905–914. [Google Scholar] [CrossRef]
- Islam, M.; Nasrin, T.; Walther, B.A.; Wu, C.-C.; Yang, H.-C.; Li, Y.-C. Prediction of sepsis patients using machine learning approach: A meta-analysis. Comput. Methods Programs Biomed. 2018, 170, 1–9. [Google Scholar] [CrossRef]
- Roehrs, A.; Costa, C.A.; Righi, R.R.; Rigo, S.J.; Wichman, M.H. Toward a model for personal health record Interoperability. IEEE J. Biomed. Health Inform. 2018, 23, 867–873. [Google Scholar] [CrossRef]
- Su, L.; Liu, C.; Li, D.; He, J.; Zheng, F.; Jiang, H.; Wang, H.; Gong, M.; Hong, N.; Zhu, W.; et al. Toward Optimal Heparin Dosing by Comparing Multiple Machine Learning Methods: Retrospective Study. JMIR Public Health Surveill. 2020, 8, e17648. [Google Scholar] [CrossRef]
- Johnson, A.E.W.; Pollard, T.J.; Shen, L.; Lehman, L.-W.H.; Feng, M.; Ghassemi, M.; Moody, B.; Szolovits, P.; Celi, L.A.; Mark, R.G. MIMIC-III, a freely accessible critical care database. Sci. Data 2016, 3, 160035. [Google Scholar] [CrossRef] [Green Version]
- Shafaf, N.; Malek, H. Applications of Machine Learning Approaches in Emergency Medicine; A Review Article. Arch. Acad. Emerg. Med. 2019, 7, e34. [Google Scholar] [CrossRef]
- Zeng, M.; Li, M.; Fei, Z.; Yu, Y.; Pan, Y.; Wang, J. Automatic ICD-9 coding via deep transfer learning. Neurocomputing 2019, 324, 43–50. [Google Scholar] [CrossRef]
- Peek, N.; Rodrigues, P.P. Three controversies in health data science. Int. J. Data Sci. Anal. 2018, 6, 261–269. [Google Scholar] [CrossRef] [Green Version]
- Kraus, J.M.; Lausser, L.; Kuhn, P.; Jobst, F.; Bock, M.; Halanke, C.; Hummel, M.; Heuschmann, P.; Kestler, H.A. Big data and precision medicine: Challenges and strategies with healthcare data. Int. J. Data Sci. Anal. 2018, 6, 241–249. [Google Scholar] [CrossRef]
- Redondo, A.; Rios-Sanchez, B.; Vigueras, G.; Otero, B.; Hernendez, R.; Torrente, M.; Menasalvas, E.; Provencio, M.; Rodriguez-Gonzalez, A. Towards Treatment Patterns Validation in Lung Cancer Patients. In Proceedings of the 2021 IEEE 8th International Con-ference on Data Science and Advanced Analytics, Porto, Portugal, 6–9 October 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Jasinska-Piadlo, A.; Bond, R.; Biglarbeigi, P.; Brisk, R.; Campbell, P.; McEneaneny, D. What can machines learn about heart failure? A systematic literature review. Int. J. Data Sci. Anal. 2021, 13, 163–183. [Google Scholar] [CrossRef]
- Sheth, A.; Yip, H.Y.; Shekarpour, S. Extending Patient-Chatbot Experience with Internet-of-Things and Background Knowledge: Case Studies with Healthcare Applications. IEEE Intell. Syst. 2019, 34, 24–30. [Google Scholar] [CrossRef] [PubMed]
- Lu, J.; Fung, B.C.M.; Cheung, W.K. Embedding for Anomaly Detection on Health Insurance Claims. In Proceedings of the 2020 IEEE 7th International Conference on Data Science and Advanced Analytics (DSAA), Sydney, NSW, Australia, 6–9 October 2020; pp. 459–468. [Google Scholar] [CrossRef]
- Chen, Y.; Qin, X.; Wang, J.; Yu, C.; Gao, W. FedHealth: A Federated Transfer Learning Framework for Wearable Healthcare. IEEE Intell. Syst. 2020, 35, 83–93. [Google Scholar] [CrossRef] [Green Version]
- Solarte-Pabon, O.; Blazquez-Herranz, A.; Torrente, M.; Rodriguez-Gonzalez, A.; Provencio, M.; Menasalvas, E. Extracting Cancer Treatments from Clinical Text written in Spanish: A Deep Learning Approach. In Proceedings of the 2021 IEEE 8th International Conference on Data Science and Advanced Analytics (DSAA), Porto, Portugal, 6–9 October 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Oba, Y.; Tezuka, T.; Sanuki, M.; Wagatsuma, Y. Interpretable Prediction of Diabetes from Tabular Health Screening Records Using an Attentional Neural Network. In Proceedings of the 2021 IEEE 8th International Conference on Data Science and Advanced Analytics (DSAA), Porto, Portugal, 6–9 October 2021; pp. 1–11. [Google Scholar] [CrossRef]
- Kokciyan, N.; Sassoon, I.; Sklar, E.; Modgil, S.; Parsons, S. Applying Metalevel Argumentation Frameworks to Support Medical Decision Making. IEEE Intell. Syst. 2021, 36, 64–71. [Google Scholar] [CrossRef]
- Johnson, A.; Bulgarelli, L.; Pollard, T.; Horng, S.; Celi, L.A.; Mark, R. MIMIC-IV. PhysioNet. 2023. Available online: https://physionet.org/content/mimiciv/2.2 (accessed on 10 December 2022).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
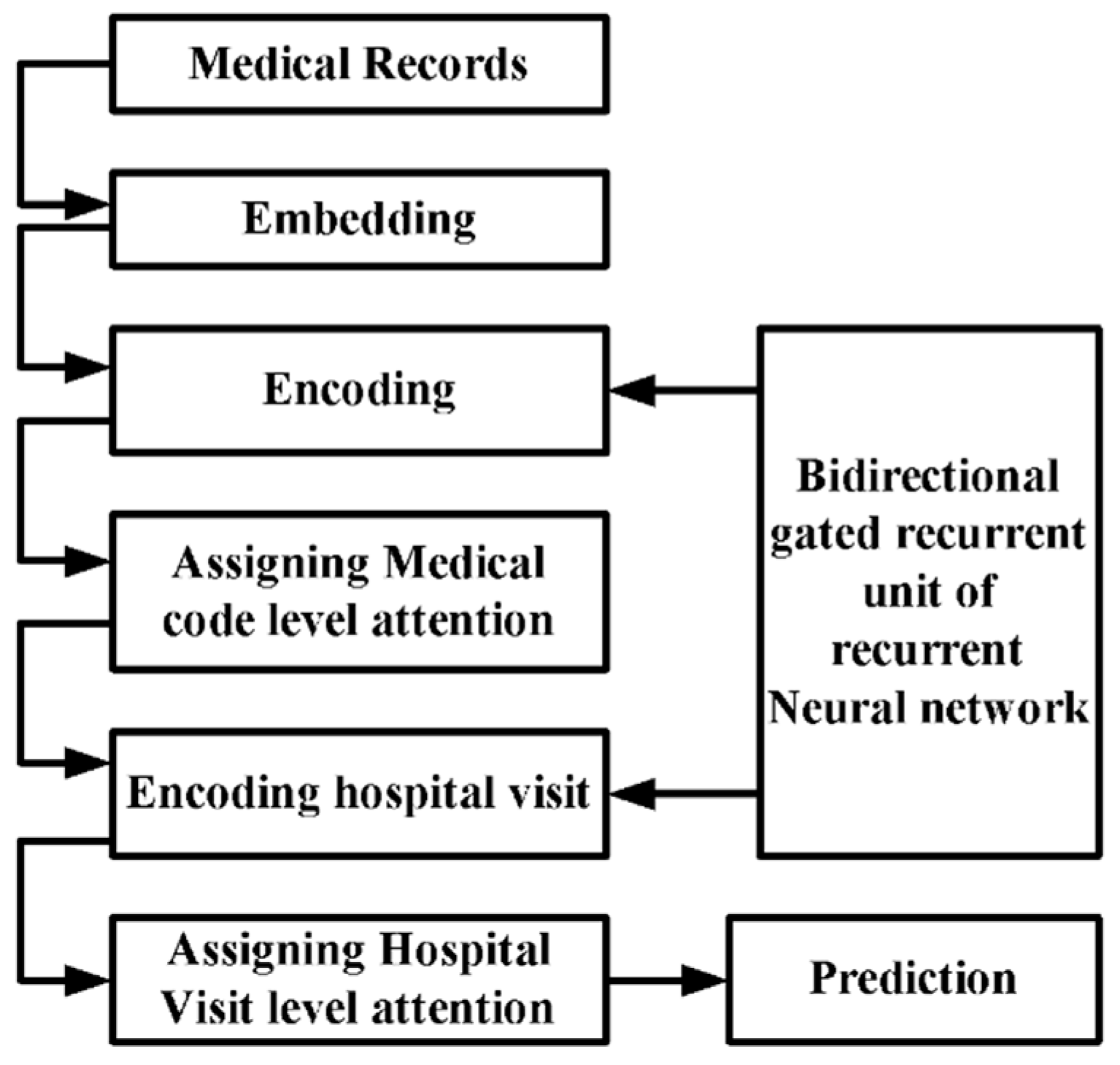{kind=link}
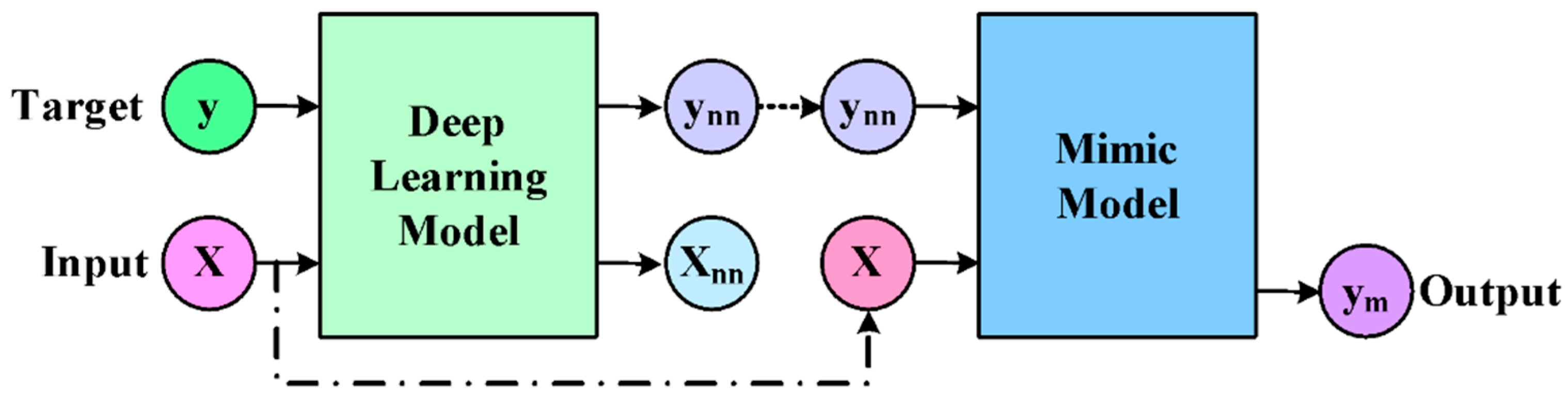{kind=link}
| Bibliographic Database/Google Search Engine | Total Result | Final Result |
|---|---|---|
| IEEE | 453 | 62 |
| BMC | 238 | 93 |
| Elsevier | 117 | 52 |
| MDPI | 4798 | 310 |
| PubMed | 13,552 | 402 |
| arXiv | 328 | 72 |
| SAGE | 4 | 4 |
| Springer | 4043 | 111 |
| Total | 23,533 | 1106 |
| Scheme | Studies | Advantages | Limitation |
|---|---|---|---|
| Classification-based | ICD-based Li et al. [28], Nigam [29], and Baumel [30], | Practical analysis, when integrated with deep learning | It needs a massive number of data to come to the conclusion |
| Capsule Network— Bao et al. [31] | No validation of medical studies yet | It is a slow-running algorithm | |
| NLP—Ye et al. [33] | A more straightforward analysis of medical data | Applicable for the specific task | |
| XGboost—Hou et al. [34] | Supports missing managing data | It does not offer scalability | |
| Normal Predictive | text analysis and a bag of events-(Gong et al. [36]) | Simplified and customized model for analysis | Specific to text data |
| WEKA—Gentimis et al. [38], | Offers portability in analysis | Not meant for handling massive medical data | |
| Recurrent neural network (Chen et al. [39]), Rodrigues-Jr et al. [50], Su et al. [51]. Xu et al. [55], | Supports temporal-based prediction | Suffers from the complex training process | |
| Logistic Regression—Meiring et al. [40] | Simpler implementation without assumption | Linearity assumption | |
| LSTM model—Jin et al. [41], Xia et al. [42], Yu et al. [43], Li et al. [44], and Yang et al. [45] | Independent from finer adjustment | Does not address overfitting issues | |
| Integrated ML approach—Nanayakkara et al. [56] | Customized for the detection of various disease | Computationally complex process | |
| Document-Embedding & neural network, Grnarova et al. [58]). | Effective for all text-based medical report | Absence of benchmarking | |
| -Deep Learning & Fuzzy Logic, Davoodi, and Moradi [60] | Higher accuracy | Needs formulation of higher training epoch and a large number of rules | |
| Early Predictive | ANN—Ding et al. [61] | The efficient and more straightforward training process | Fluctuation in training time |
| -Multivariate Logistic Regression—Zimmerman et al. [62] | Effective for analyzing the relationship between parameters | Computationally expensive process | |
| Integrated ML approach Li et al. [66] | Customized for the detection of various disease | Computationally complex process | |
| time-series, multivariate features—Javan et al. [68] | Effective for temporal-based prediction | Requires higher iteration for training | |
| Clinical Diagnosis | Detection of atrial fibrillation and kidney injury—Bashar et al. [71] and Fan et al. [72] | Progressive modeling toward disease analysis | Use-case specific |
| Clinical conclusion of diagnosis—Dai et al. [73]). | Simplified inference system | Dependent on the type of dataset | |
| Neural network—Prakash et al. [74], | The efficient and more straightforward training process | Fluctuation in training time | |
| convolution neural network—Mullenbach et al. [76] | Autonomous feature detection | Slower processing | |
| Gated-recurrent neural network—Sha and Wang [77]). | Enhances the capacity of memory | Dependent on the specific form of medical data | |
| Characterization of data—Che and Liu [78]). | Adequate for concluding clinical inference | Dependent on the type of medical data structure | |
| recurrent neural networks—Choi et al. [79] | Memory efficient and offers scalable performance | It does not address the gradient vanishing issue | |
| decisive logic construction—McWilliams et al. [80] | Adequate for concluding clinical inference | Needs specific customization of data | |
| multi-layer perceptron Alon et al. [81], | Offers adaptive learning | Inclusion of a large number of parameters | |
| LSTM-Chen et al. [82], Kaji et al. [83]. | Better control of network flow offers flexibility over output control | Does not address overfitting issues | |
| Reinforcement learning—Raghu et al. [84]). | Capable of solving a complex problem | Dependent on extensive computation resource | |
| Deep learning (Huang et al. [85]). | Practical learning of high-level features | Offers extra computational cost for training complex forms of data | |
| Comparative study—between deep learning and rule-based-Gehrmann et al. [86], | It offers a better evaluation platform | Not benchmarked with other variants of ML | |
| prognosis model—Purushotham et al. [88] | Simplified model of diagnosis | It does not draw a relationship among the essential clinical variables. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khope, S.R.; Elias, S. Strategies of Predictive Schemes and Clinical Diagnosis for Prognosis Using MIMIC-III: A Systematic Review. Healthcare 2023, 11, 710. https://doi.org/10.3390/healthcare11050710
Khope SR, Elias S. Strategies of Predictive Schemes and Clinical Diagnosis for Prognosis Using MIMIC-III: A Systematic Review. Healthcare. 2023; 11(5):710. https://doi.org/10.3390/healthcare11050710
Chicago/Turabian StyleKhope, Sarika R., and Susan Elias. 2023. "Strategies of Predictive Schemes and Clinical Diagnosis for Prognosis Using MIMIC-III: A Systematic Review" Healthcare 11, no. 5: 710. https://doi.org/10.3390/healthcare11050710