1. Introduction
Attention is an important indicator of a child’s physical and mental health. Attention deficit hyperactivity disorder (ADHD) is one of the most common behavioral problems in childhood, with an incidence of 4.31 to 5.83 percent of school-aged children in China, and the peak age of the disease is mostly concentrated at ages eight and nine, with a male-to-female ratio of 9:1 [
1]. Children with ADHD often exhibit behavioral traits such as an inability to concentrate, overactivity, and impulsivity, which cause them to encounter different degrees of difficulty in school and life [
2]. At the same time, the symptoms of ADHD can lead to a range of psychological problems, including low self-esteem, peer rejection, low self-confidence, and poor adaptability [
3]. Multiple studies have shown that 30 to 50 percent of children with ADHD have symptoms that do not disappear naturally with age [
4], due to the chronic nature of ADHD symptoms. Effective intervention training is needed for children with ADHD. In recent years, researchers have divided the attention training of children with ADHD into three categories: neurophysiological training, pen-and-paper training, and behavioral training.
Neurophysiological training includes two main methods: brain wave stimulation and drug therapy. Stimulant medication can quickly relieve ADHD symptoms but has side effects such as decreased appetite, difficulty falling asleep, and headaches [
5]. At the same time, medication does not improve the mental health of children with ADHD, and many children with ADHD have persistent residual symptoms after receiving medication treatment. Thus, neurophysiological training mainly manipulates concentration from a physiological point of view, which entails certain risks [
6]. Therefore, it is necessary to explore new interventions to help children with ADHD improve their symptoms and better adapt to society.
Pen-and-paper training mainly includes assessment scale training and pen-and-paper game training, which is a traditional attention training method that is time-consuming and labor-intensive. Parents or teachers are trained to fill in the Conners behavior scale [
7], which includes six items of character problems, learning problems, psychosomatic disorders, impulse hyperactivity, anxiety, and the hyperactivity index to understand aspects of children’s attention. Pen-and-paper tests mainly include scratch tests, digital breadth tests, writing tests, symbolic number pattern tests, etc. [
8]. Mindful concentration training is an intervention program for adolescent trait anxiety and social avoidance, in which the effectiveness of the intervention is verified through various scale tests [
9]. Cognitive training games have improved attention and executive function in school-aged children with ADHD through an adaptive repetitive hierarchical grading exercise [
10]. The one-to-one approach uses progressive level-breaking games to train concentration, assessing whether the intervention is sustainable based on the results of participants’ play performance and behavioral responses. The pen-and-paper training method is used to evaluate indicators such as persistence, selectivity, attention, inhibitory control, and working memory through experiments, which require a large number of teachers or parents and children to conduct one-on-one training. Therefore, this approach is time-consuming and inefficient.
Behavioral training is a potential method that combines traditional attention training methods with computer technology to reduce human interference in the training process, such as reducing scoring errors and improving efficiency. The most common method of attention training for children is the Stroop Word Color Interference Test (SWIT) [
11]. The Attention Continuity Performance Test (CPT) has been developed to test the scope of children’s persistent attention. Visual task training includes five training modules—instruction reception training, gaze training, visual tracking training, visual search training, and visual memory training [
12]. The principle of concentration training based on vision games involves the use of situational dialogue and emotional expression in one-on-one or many-to-one modesto help children with ADHD improve their attentiveness. At present, although some reviews have been conducted on human attention training based on human–computer interaction, there is no guidance for robot design in this field [
13,
14,
15,
16,
17]. A prototype design of a YOLO robot has been proposed, which could serve as a tool to stimulate new ideas and stimulate creativity, providing educational strategies for children’s creative development [
13]. Safinah Ali et al. designed a social robot for children based on the interactive mode of artificial creativity and experimentally demonstrated that children’s creativity was improved in the interactive game with the social robot [
14]. The findings of a survey of social robots indicated that social robots can be used as assistive robots for children’s play, learning, and cognitive development. A computer-aided technique for the testing of ADHD patients was proposed, which has gained FDA approval for the objective measurement of hyperactivity, impulsivity, and inattention, and for the assessment of ADHD [
15]. One of the major challenges in the use of human–robot interaction in concentration training is to improve the random freedom of HRI. For example, humans and robots are free and open in games, not restricted by third parties, and real-time interactivity has become an important way of improving the effects of HRI games [
18]. Therefore, the question of how to improve the real-time aspect and the degree of freedom in HRI games needs to be further explored. Immersive games offer a possible alternative. An immersive learning mode, combined with the use of a robot and virtual reality technology, played a positive role in improving efficiency in English learning and effectively promoting the balanced development of education [
15]. However, this method involves high requirements in terms of equipment, as well as a high cost and low efficiency.
According to the above findings, concentration training needs to solve the problems of the shortage of teachers, low efficiency, and high cost. With the development of human–robot interaction technology, HRI games have become a popular trend for children’s concentration training. However, non-verbal communication is very important in human–robot interaction just as it is in human–human interaction [
19,
20,
21]. Thus, natural interaction and real-time performance are two key issues in relation to the application of HRI games in concentration training. Experiments have shown that this new HRI game scenario is beneficial for concentration training, and there are thus two questions that need to be explored regarding natural relationships and reaction time [
22,
23,
24,
25]:
Does the gesture recognition-based immersive HRI game scenario realize the goal of unconstrained concentration training?
Are the contents of the immersive HRI game suitable for children’s concentration training, such as for visual short-time memory and response time?
The remainder of this paper is organized as follows. The second section discusses the related work. The third section presents the materials and methods. The findings from the content analysis of the related papers are described in the fourth section. Finally, the fifth section concludes and provides suggestions for further developments.
3. Materials and Methods
At present, common problems in concentration training are related to the fact that the venues and training tools have certain requirements, whereas the game content is singular, fixed, and conventional, and that the activity training process has low accuracy, complexity, and is not conducted in real time [
34]. To solve the above problems, an immersive HRI game based on the YOLOv5 algorithm for children’s concentration training was proposed and experimentally verified.
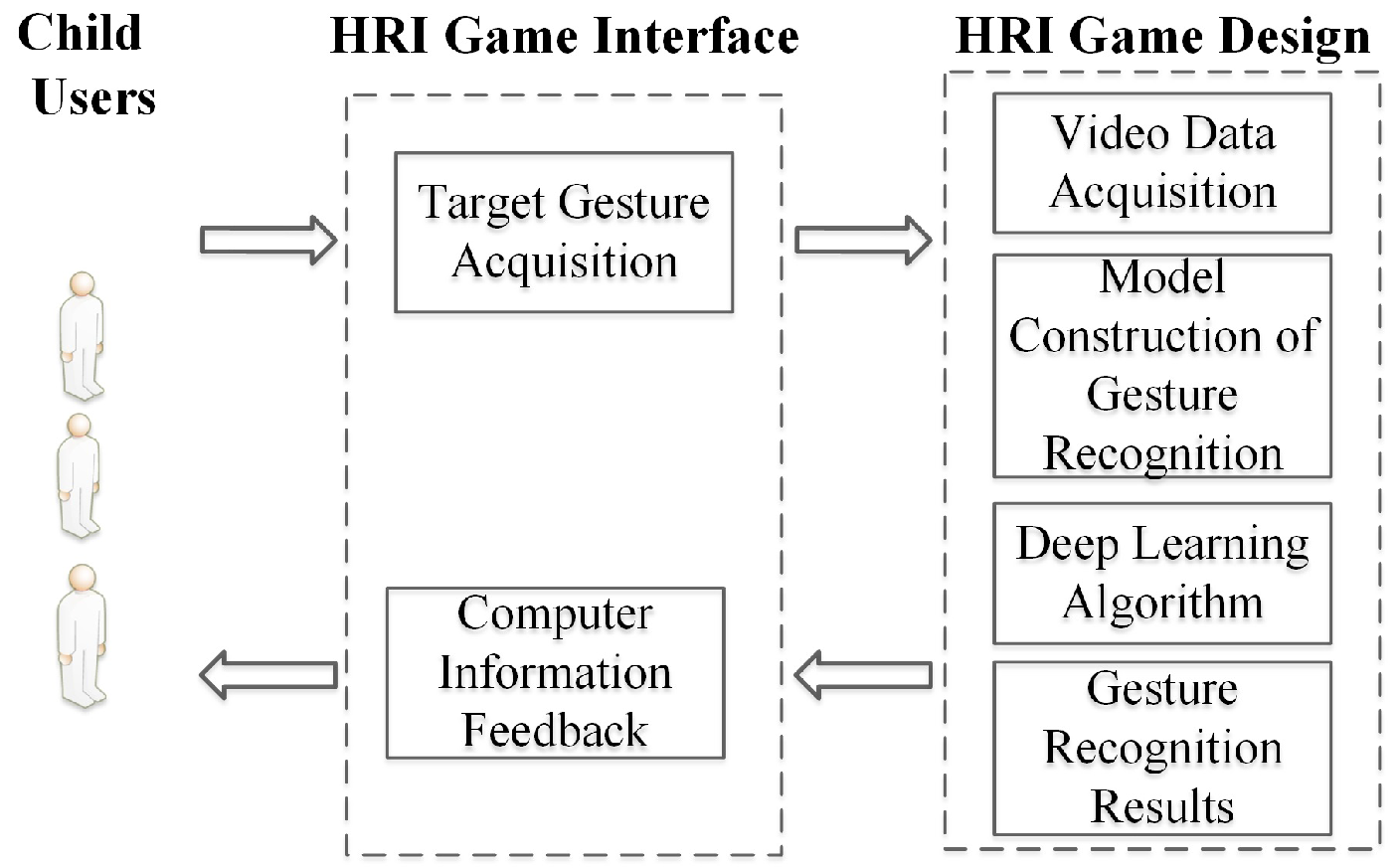
The immersive human–robot interaction game system proposed in this paper includes four functional modules: video data acquisition, model construction of the gesture recognition, a deep learning algorithm, and information feedback, as shown in
Figure 3. We designed an immersive human–robot interaction game called “Running Train”, which involved 120 children with attention deficits completing the game. The entire game was videotaped, and we analyzed the indicators of concentration in the experimental results. The game called “Train Run” is a kind of game that Chinese children are generally familiar with, which involves completing a game in sequence. In our experiments, child subjects played games in groups. Four children were included in each group, and they took turns to complete the HRI game according to the game’s rules.
The method of using the proposed immersive HRI game in children’s concentration training has the following advantages. Firstly, the trainee freely completes the concentration training and evaluation during the immersive games with the robot. Secondly, multiple trainees can be trained at the same time, without professional teachers, greatly improving the training efficiency and reducing labor costs. Finally, there was no specific requirements regarding the training location, which is convenient for the market application and promotion of the method.
The concentration training scenarios began with an immersive human–robot interactive game. The user provided feedback through gestures, according to the computer’s random orders, which were recorded in real time by the camera. Then the gesture recognition module processed the recorded gesture data. The functional module contained the definition of gestures, the construction of a gesture training model, the deep learning algorithm, and the feedback of the gesture recognition results.
During the game, four children sat on four fixed chairs and performed corresponding gestures according to the computer’s orders. The children’s gestures were captured by the HRI game system with a webcam. Then, the corresponding gestures were identified. Next, the system provided corresponding feedback to the children. Children played freely without human interference during the HRI games. Every child played with the robot in a real and unobstructed interactive game. During the games, the robot calculated each child’s reaction time and accuracy during the game. Finally, the HRI game produced each sub-result of the game as an output. The experimental setup, procedure, measurement, results, and participant information are described below.
3.1. Experimental Setup
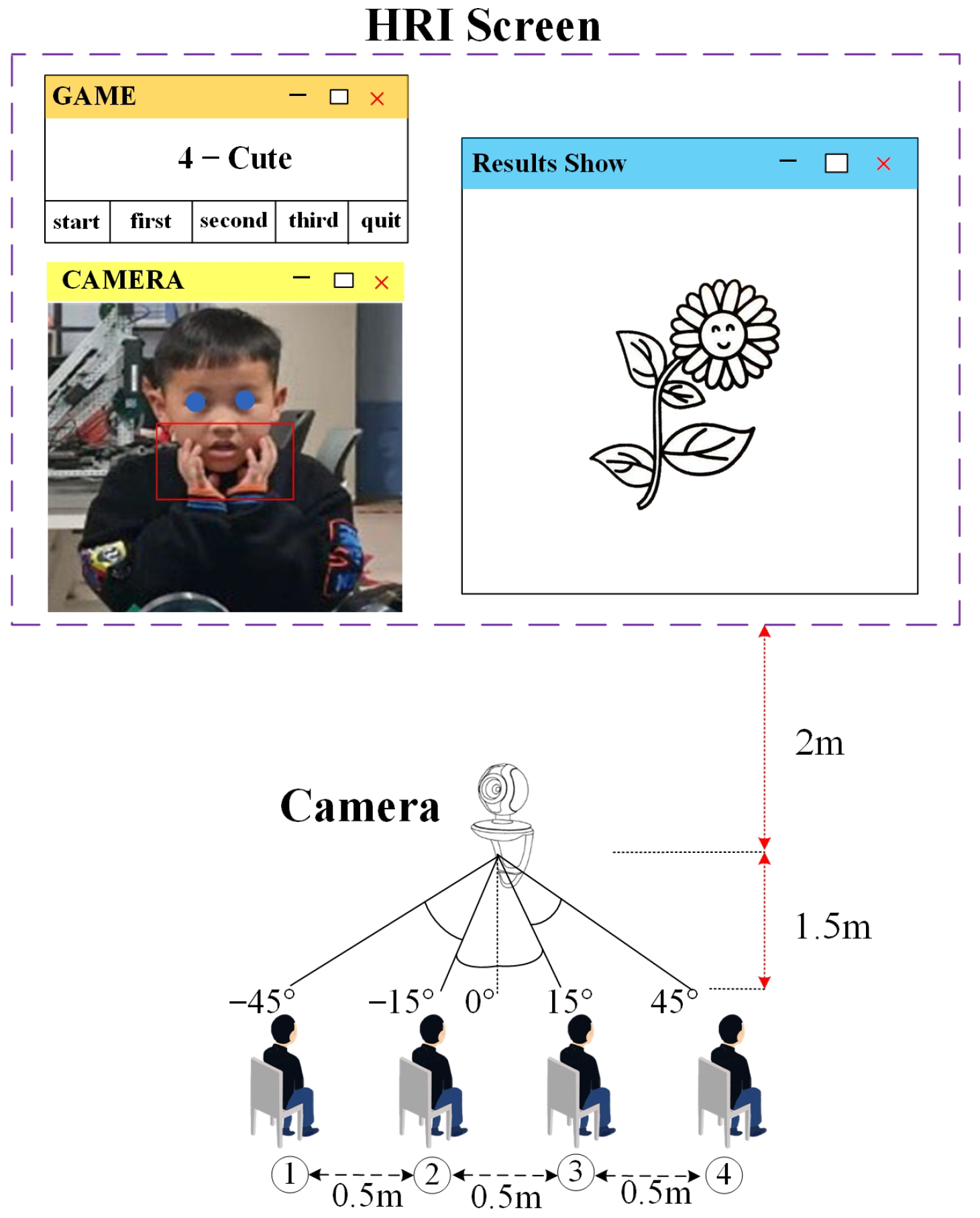
The experimental setup contained child users, a camera, wireless computers, and projectors, as shown in
Figure 4. To show the process of the children’s game and the game results more specifically, we depict an instance of the children’s game as an example in
Figure 4. The experimental site was in an ordinary classroom, and the camera was placed on the podium, two meters away from the large screen. Four chairs were numbered from 1 to 4 and were placed 1.5 m away from the camera in the vertical direction. During the game, the children faced and gestured towards the camera, and directions were projectedonto the wall in the HRI games. That is, during the entire game process, the children faced the wall to play the games. The size of the game screen was about 2.5 m wide and 1.5 m high.The size of the game screen was approximately 2.5 m wide and 1.5 m high. In the layout of the test site, we put the camera above the center of the screen, assuming that the front angle of the camera was 0°. The chair and camera orientations were set to −45°, −15°, 0°, 15°, and 45° from left to right, respectively. Because of limited experimental funding, every child was not given a screen. Four children did not play at the same time. The game was played in groups. Each group of game members included four children, who completed three rounds of games with different requirements. At the same time, only one child completed the gesture recognition game. A specific description of the game instructions is presented in
Section 3.2. The purpose of the experiment was to verify whether the human–robot interaction system was effective for children’s concentration training and evaluation.
The immersive human–robot interaction games described here have no venue requirements, and experiments can be carried out freely in ordinary teaching places. No third-party intervention is required during the play process, and concentration training and assessment can be carried out with only children participating in the game. The immersive human–robot interaction concentration training game we designed enables free training at any time, anywhere, and is independent of the conditions of the training site, and thus has a very wide range of applications, such as humanoid robot design for HRI, screening and intervention for children with depression, screening and intervention for children with autism, and so on.
In order to test the concentration training effects of this human–robot interaction game, we selected 120 children with inattention issues from five primary schools in Jiangbei District and Yinzhou, Ningbo City, to conduct a game experiment (age: 9–12 years old, 60 boys, 60 girls). All of these children were able to perform normal imitation behaviors according to the testers, and they had no difficulty in movement; hence, they were acceptable for the study.
3.2. Experimental Procedure and Measurement
In the experiment, all child players were divided into groups of four children, assuming A, B, C, and D, and they participated in the gesture game together, with the children being able to play freely and autonomously. Gesture commands were specified by the robot and displayed on a large screen via a projector. Children made corresponding gestures according to the gesture instructions within the limited time of two seconds and were awarded one point for correct completion of the gesture and zero points for incorrect completion. At the same time, the robot recorded the time when the child completed the gesture through the camera. Each group of children played three rounds of games. In the first round of the game, four children in a permutation and combination completed the specified gestures in sites 1 to 4, respectively. In the second round of the game, the four children sat in a fixed site, numbered from 1 to 4, and randomly completed a random gesture, choosing one of the five. The positions and gestures of the four children in the third round were randomly determined. The total number of times each child completed the game in each round was 24, and each child completed three rounds. Since 120 children participated in the experiment, a total of 8640 game results were obtained. We normalized these 8640 data for analysis.
There was no third-party participation in the game process, the game process is videotaped, and the game system provided feedback on the correct or wrong results in real time, according to the gestures made by the children, recording the accumulated game scores of each child. At the same time, the game system also recorded the time at which the children completed the gestures and calculated each child’s reaction time. Finally, we evaluated the effect of the concentration training game by calculating and comparing the accuracy of playtime and movements in all samples.
Concentration assessment indicators included object recognition, visual short-term memory [
35], focused attention, response time [
36], and so on. The experimental results were processed and analyzed using Python and SPSS software. For the accuracy analysis of the gesture response, we used mixed-effects repeated measures of ANOVA, in which gestures, direction, and order of play were random effects and the physical distance was a fixed effect. During the game, the children underwent concentration assessment and training based on the feedback provided by the machine.
4. Results
4.1. Gesture Recognition
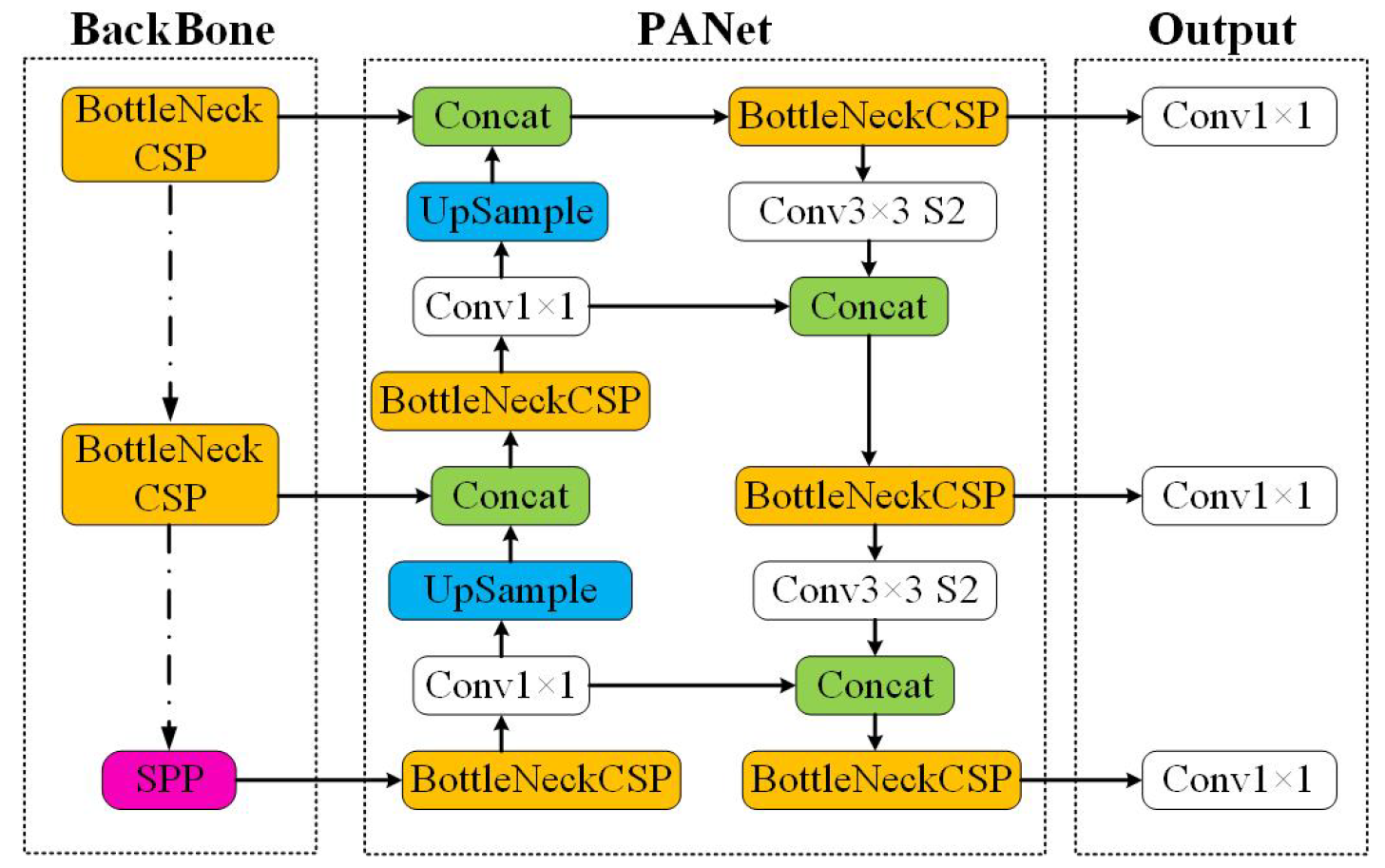
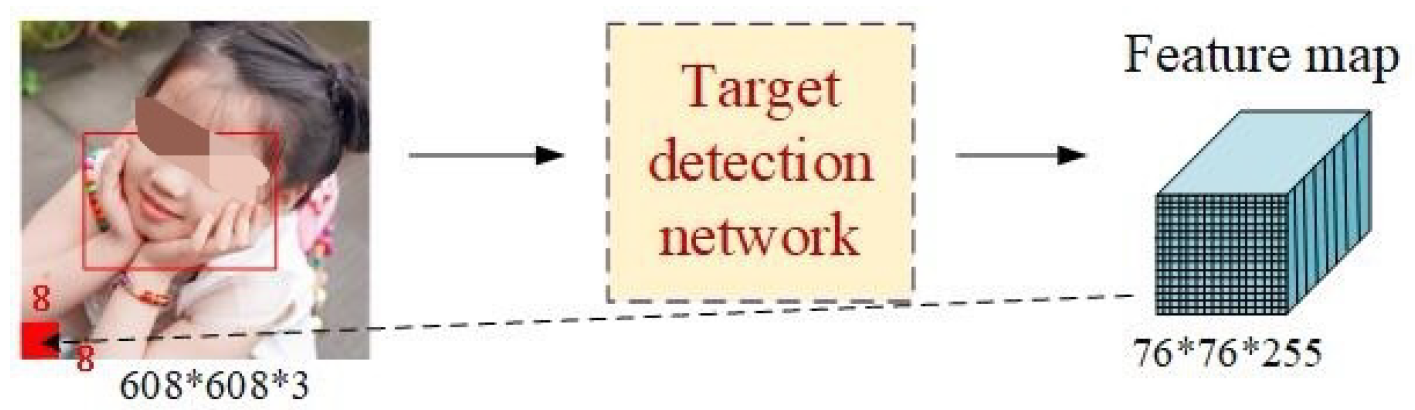
In the experiments, we adopted HRI games based on gesture recognition. The gesture recognition algorithm consisted of network training and gesture recognition [
37]. In the network training stage, the improved feature extraction network was used to fit the feature distribution of training samples, and the fitting error was estimated according to the deviation between the gesture label and the network output; that is, the recognition result and the updating direction of network weights at all levels were determined by calculating the error gradient. After network training, in the gesture recognition step we used the weight files obtained in the training stage to restore the deep network and then used the network to complete the feature extraction from the test data. Finally, the YOLOv5 target recognition algorithm for this experiment was used to decode the network output data, and the results of the gesture recognition process were obtained. The gesture recognition training samples based on the YOLOv5 algorithm are shown in
Figure 5.
The training of the YOLOv5 model was as follows.
Preparing the image dataset. We collected 10,000 images, 2000 images for each of the five gestures that expressed ‘OK’, ‘No’, ‘Yes’, ‘Cute’, and ‘Love’. All images were obtained from partner schools. The dataset contained images in indoor and outdoor environments, images of different gestures by a single person, and different gestures by multiple people in one image. If the images contained different gestures, the images belonged to different gesture classes.
Labeling the image: The labels of the 5 categories were set to 1, 2, 3, 4, and 5, respectively. we used the Colabeler (
http://www.colabeler.com/, 17 April 2021) tool to annotate and label our images and exported them in YOLOv5’s annotation format. We used rectangular boxes to label various gestures.
Training the model: We ran a deep learning experiment on a Linux Server with a GPU (NVIDIA GeForce RTX 2080 Ti graphics card). yolov5s.pt was used for the pretrained weighted models in the YOLOv5 algorithm. The number of iterations was set to 3000 batches. The size of each batch was set to 16. The image resolution, as the feature parameter (-imgsz), was set to 640 × 640, and the patience was set to 1000. Other parameters retained their default values.
Evaluating the model: We conducted 5-fold cross-validation in order to evaluate the model’s performance. The average accuracy of the training recognition was 98.7% in the test set.
After we had trained and evaluated the model, we used the model to classify the images from the video that was processed frame by frame and made a prediction for each frame.
4.2. Visual Short-Term Memory
The children’s performance in the game was summarized and analyzed. Visual short-term memory is an important characteristic of human concentration. In our experiments, visual short-term memory was measured based on the accuracy value expressed by the gesture completion rate in the games. The higher the accuracy rate, the better the visual short-term memory; therefore, the better the concentration. To facilitate the analysis, the accuracy results were all normalized. There were some factors that affected accuracy, such as location, sex, and age. The effect of these factors on the training effectiveness of the concentration game was analyzed. We specifically discussed the impact of physical distance and orientation on gesture recognition accuracy in our previously published paper [
37]. In order to compare and analyze the data, we performed Z-Score normalization on the children’s game scores, which are shown in
Figure 6 and
Figure 7.
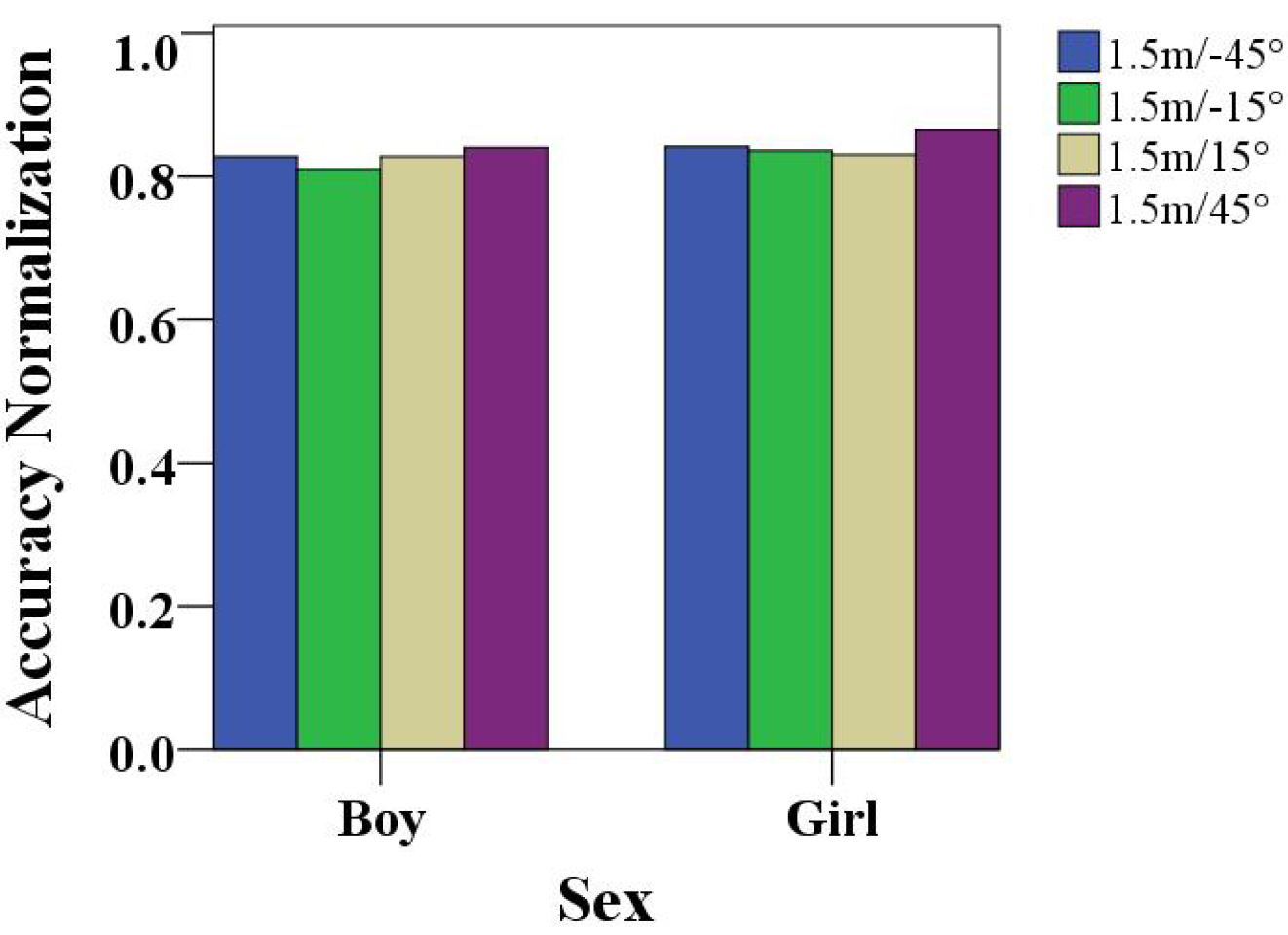
Children sat in fixed chairs, which were placed at the same distances from the camera. A comparison of the performances of boys and girls playing at different angles is shown in
Figure 6. When the boys and girls sat at different angles in the chair to complete the gesture game, in terms of the performance standardization value, we observed that the boys’ performances in the −15° angle were low, and the −45°, 15°, and 45° angle scores were relatively high. In particular, boys were more focused at the 45° angle in the attention training game. The 45° angle had the highest performance standard value for girls as well, indicating that the 45° angle was the best angle for children to play attention training games. Meanwhile, girls performed better than boys according to the analysis.
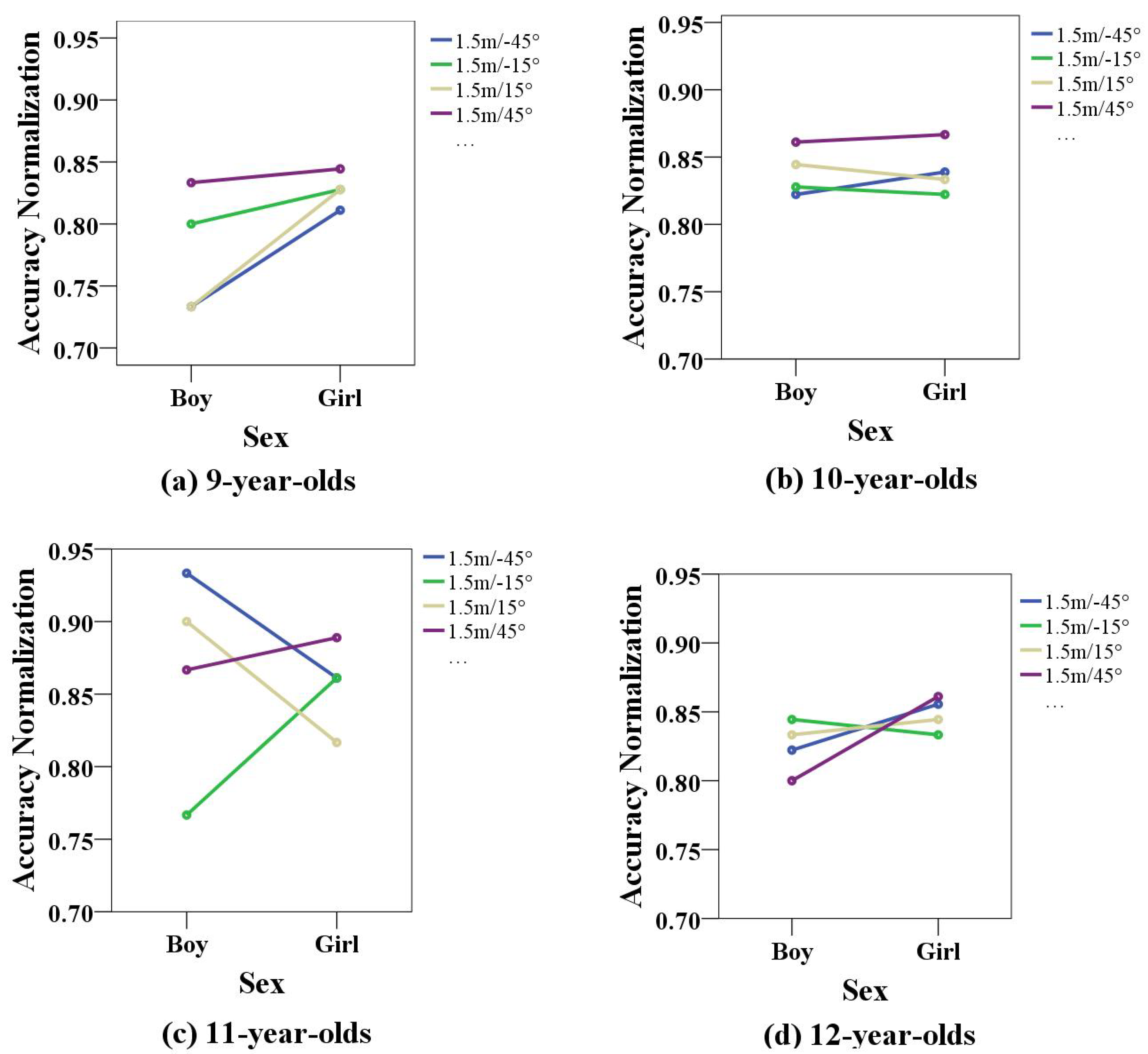
The results of the human–computer interactive games for children of different ages were analyzed, in terms of sex and angle, for children from 9 to 12 years old, as shown in
Figure 7a–d. According to the results, the 9-year-old boys had lower accuracy at the 15° and −45° angles and higher accuracy at the −15° and 45° angles, indicating that the −15° and 45°angles were more suitable for them. The accuracy normalization values of the girls at all four angles were above 0.8, indicating that the game performance of 9-year-old girls was significantly better than that of boys at the same age. Additionally, the results obtained at a 45° angle were significantly better than those obtained at other positions. The concentration of 9-year-old girls was significantly better than that of boys, and the concentration training results obtained in chair 4 were significantly better than those obtained in the other positions. As shown in the figure, the standard scores of 10-year-old children at all four angles were above 0.82, indicating that children in this age group had a better attention level, and the 45° angle was also the best angle for the game. The 11-year-old boys’ scores at the −15° angle were low, and the scores at all other angles were above 0.85, indicating that the game angles of −45°, 15°, and 45° were better. The accuracy normalization values of girls were generally above 0.8, indicating that girls had better concentration. The accuracy normalization values for 12-year-old children were above 0.8, and boys’ scores were generally lower than the girls’ scores, indicating that the four directions were more suitable for concentration training for children at this age, and children in this age group were less active than in the younger age group.
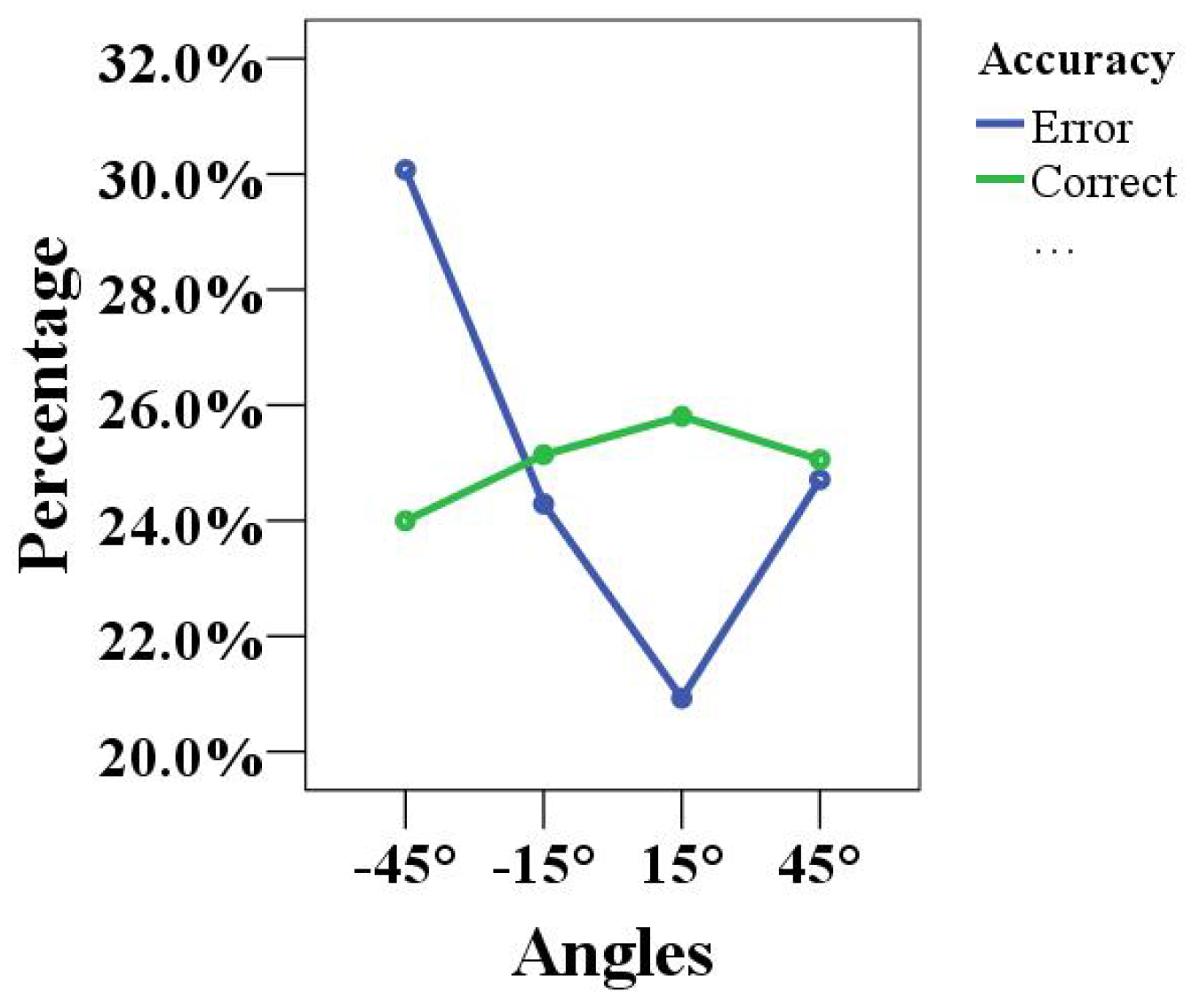
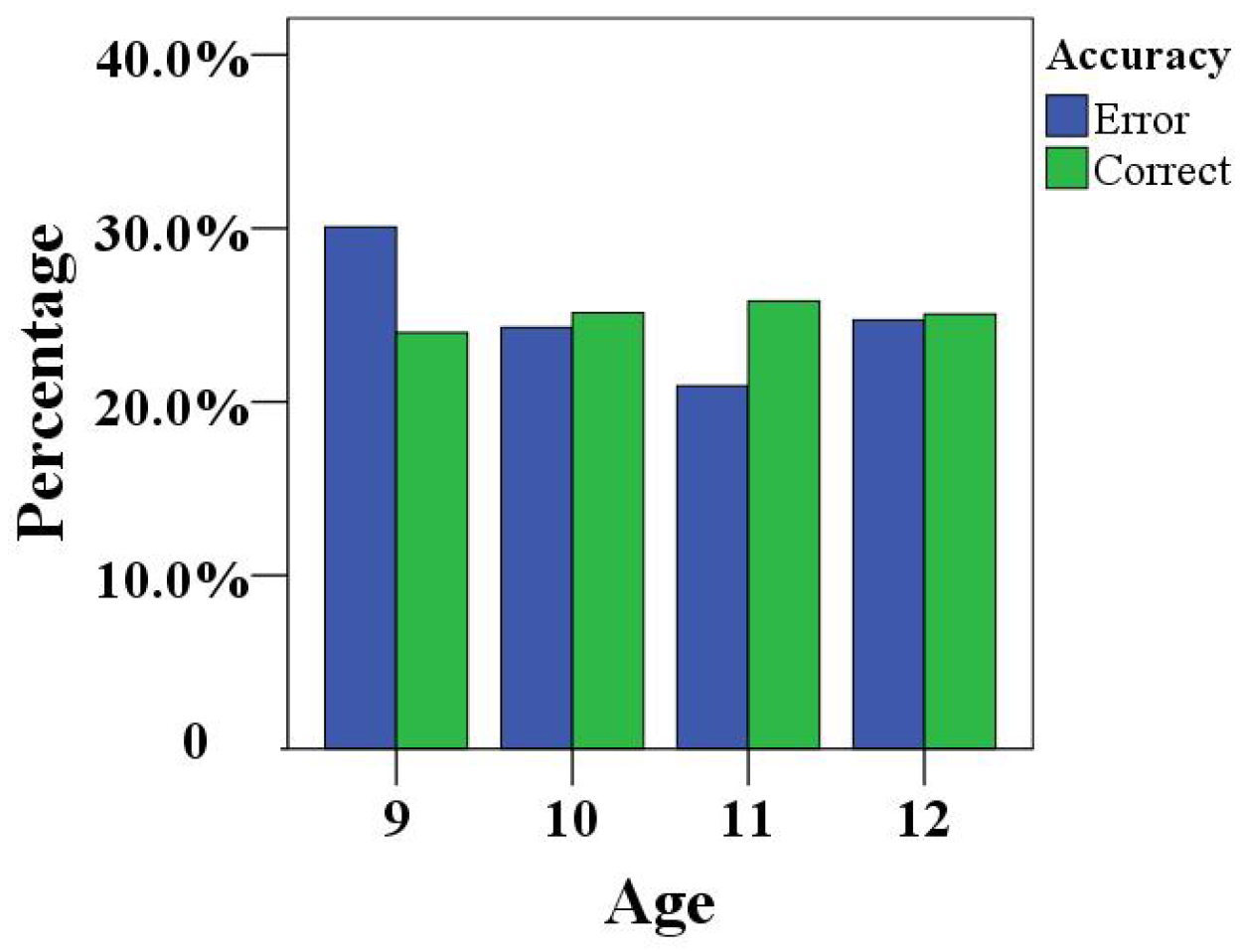
In addition, a summary analysis of the accuracy of the children’s completion of the game at four different angles (blue line indicates the error percentage, green line indicates the correct percentage) is shown in
Figure 8. The error percentage at the −45° angle was close to 30.0%, and the accuracy rate was less than 25%, indicating that the concentration training at this angle was not ideal. The 45° angle exhibited the opposite result, with an accuracy rate higher than the error percentage. There was a great difference between the accuracy rate and the error percentage at the other two angles (−15° and 15°). Therefore, it was once again proven that the concentration training effect of the 45° angle in human–robot interaction games was the most significant.
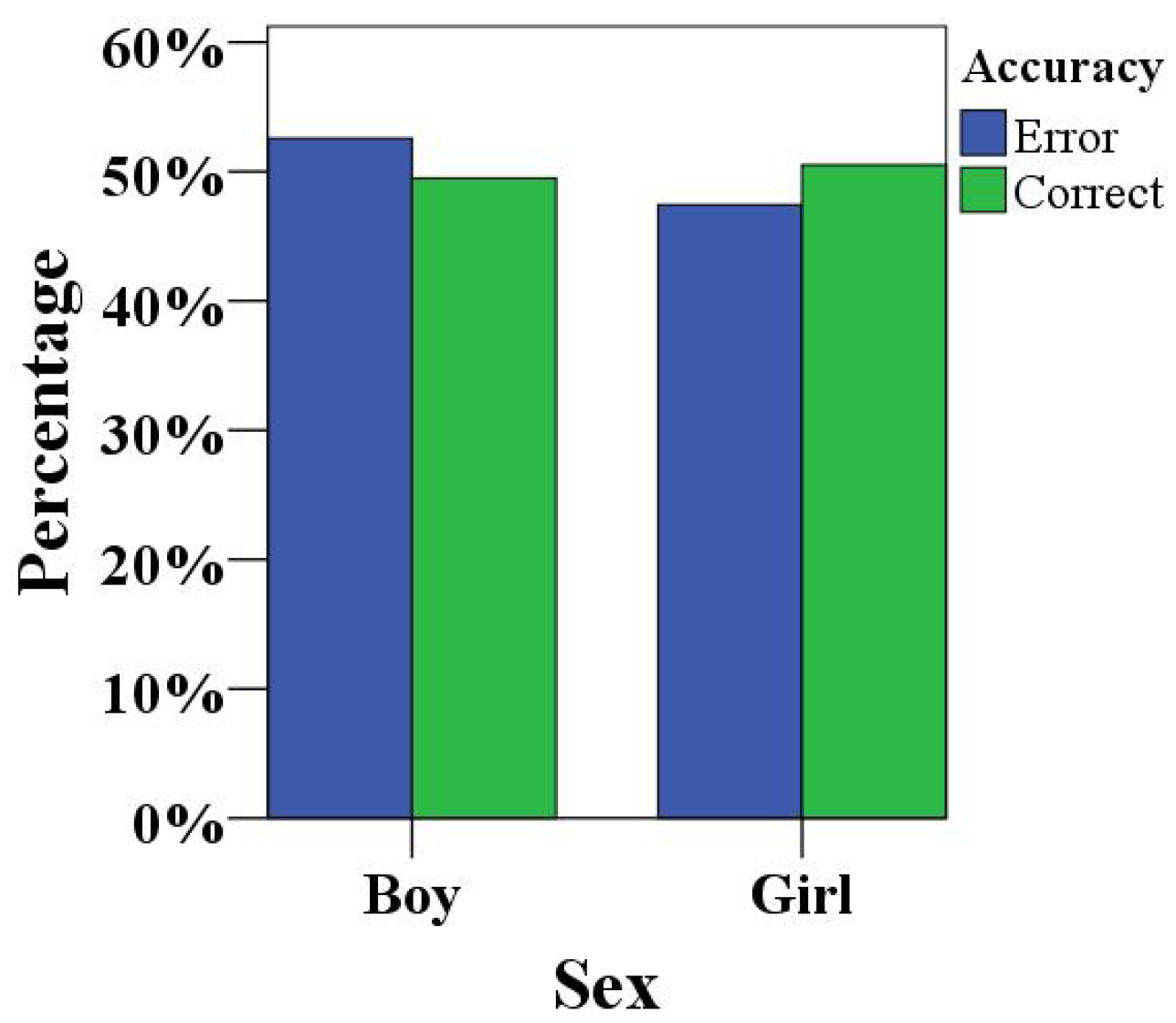
On the other hand, we have summarized the accuracy of results obtained by children participating in the HRI concentration training games, sorted by sex, as shown in
Figure 9. The accuracy rate, in terms of concentration, in children of different sexes was distributed between 49% and 50%, and the error rate was distributed between 52% and 53%, which showed that the accuracy rate of the boys’ game performance was average. The accuracy rates of the girls’ game results were distributed between 50% and 51%, and the error rate was distributed between 47% and 48%, which was lower than the error rates of the boys’ game results, which showed that there were certain differences in the accuracy rates of children of different sexes in the HRI concentration training, but they were not significant.
According to the comprehensive analysis of the game performance of children of different ages, as shown in
Figure 10, the error rate of the gesture completion error rate of 9-year-old children was slightly higher than the correct rate, whereas the accuracy rate among 11-year-old children was higher than the error rate, and the gaps between the accuracy rates and error rates obtained by 10-year-old and those obtained by 12-year-old children were very small. It can be seen that the concentration performance of 9-year-old children was poor; the performance of the other children were better.
4.3. Response Time
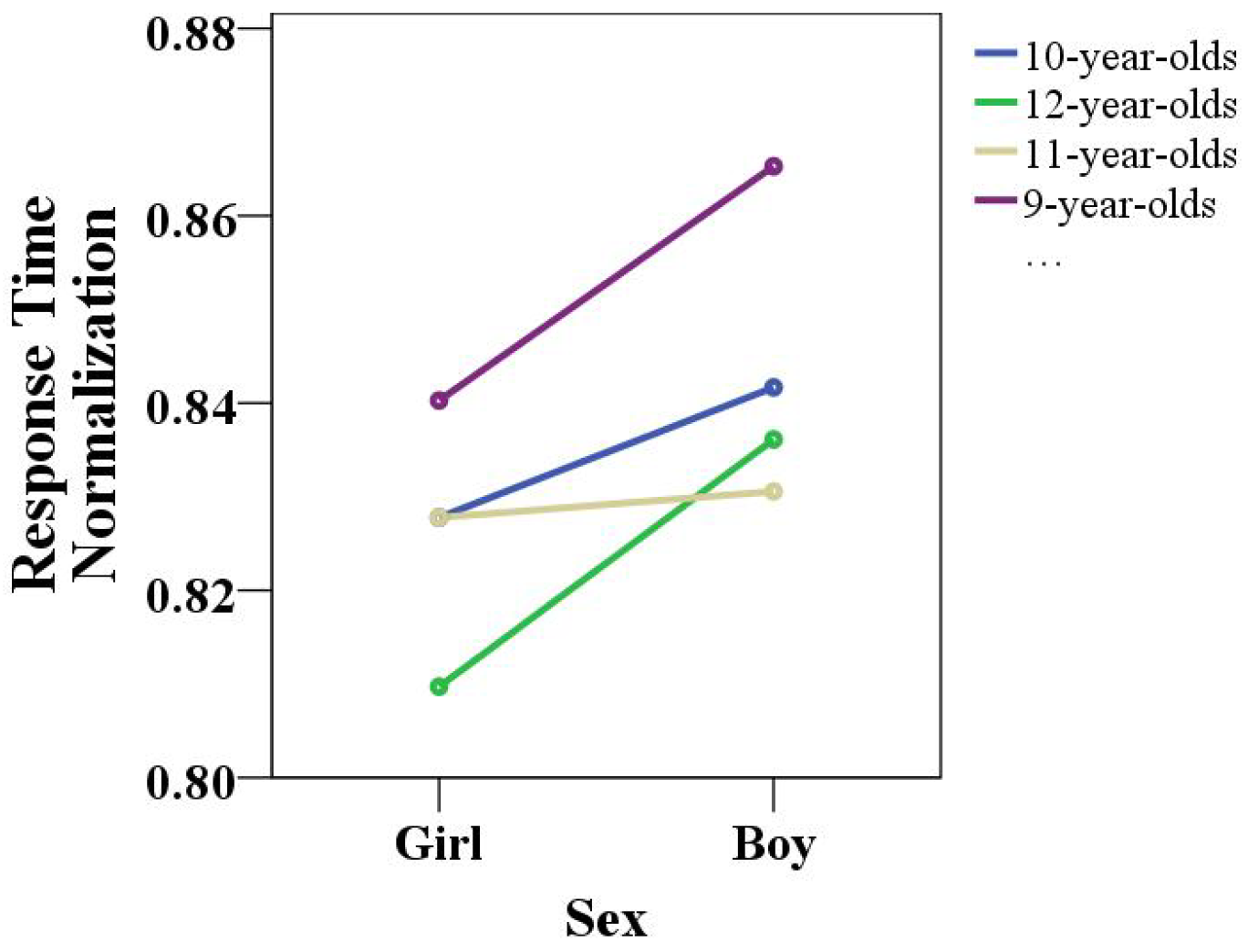
The response time is an important indicator of children’s concentration traits. During the game, the game system recorded all children’s scores in real time; that is, the time difference from the robot issuing the gesture instructions to the child making the corresponding gesture feedback was recorded. There were certain differences in the reaction times of children of different ages. The average of the play response time for children of each age was normalized, and the results are shown in
Figure 11 A normalized value of 0.8 indicated a response time of 1 s, and 0.88 indicated a response time of 3 s. During the experiment, the calculation time error due to the inherent performance of the equipment was about 0.4 s.
According to the comprehensive analysis, the 12-year-olds had the fastest reaction time, whereas the 9-year-olds had the slowest relative reaction time. The gap in reaction time between 10- and and 11-year-olds was small. In addition, a comprehensive analysis of the reaction times of children of different ages showed that the reaction time of girls was faster than that of boys. The response time was automatically calculated by the HRI game platform without human intervention, so the testing of this time interval was very simple, efficient, and reliable. Since the feedback time interval of children’s gestures is an important indicator of children’s concentration, testing the children’s feedback time provides an important basis for verifying the HRI game as an effective method for children’s concentration training. The difference in game reaction time proved that the HRI game can be used to carry out concentration training reliably, efficiently, and easily.
5. Conclusions
We proposed a concentration training method based on immersive HRI games. The immersive HRI game consisted of four functional modules, including a definition of the system’s geometry, the construction of a gesture training model, a deep learning algorithm, and providing feedback for the gesture recognition results. The deep learning algorithm YOLOv5 was used to realize gesture recognition, which ensured the real-time use and accuracy of the HRI gesture game. We built a gesture recognition model containing 10,000 pictures of children’s gestures, using the YOLOv5 algorithm to achieve a gesture recognition accuracy of 98.7%.
As an exploratory study, in order to verify the effectiveness of the HRI game in children’s concentration training, we specially invited 120 children aged from 9 to 12 to participate in the experiments. The factors that influenced the effect of concentration training, such as distance, direction, and age, were experimentally analyzed, which provided important experimental reference data for the subsequent design of the robot applied for HRI. We obtained 8640 experimental data. The aim of this experiment was to test the indicators of object recognition, visual short-term memory, and response time in order to evaluate children’s concentration. According to the analysis of the experimental results, we found that the subjects’ gender, age, distance, and orientaiton in relation to the camera all had a significant impact on the experimental results during the HRI game. The experimental results showed that a game distance of 1.5 m and an orientation of 45° were the best conditions for children to play concentration training games. Girls performed significantly better than boys. The influence of the effect of the position among the older children was significantly weaker than that observed among the younger children. Additionally, the response time of girls was lower than that of boys. All these results showed that immersive HRI games based on gesture recognition could provide a concentration training platform for children.
The immersive HRI game proposed in this paper was played in a preset game scenario without third-party interference between children and robots. Furthermore, the reliability, effectiveness, real-time performance, and convenience of the proposed method are verified. The theoretical basis is to further promote the application and development of HRI games in concentration training. As this paper is a preliminary study, the focus is on performance and game reaction times to demonstrate the feasibility of applying the method to attention assessment and training. Due to the limitations of experimental conditions and game content, the game method proposed in this paper has not fully verified all indicators of children’s attention training. Meanwhile, we don’t study the improvement effect of children’s concentration training by using the HRI game method proposed in this paper. However, the research results of this paper can provide a reference for the subsequent design of HRI games and educational robots. In the next phase, we will further optimize the content of the game to improve the effectiveness of concentration training.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}