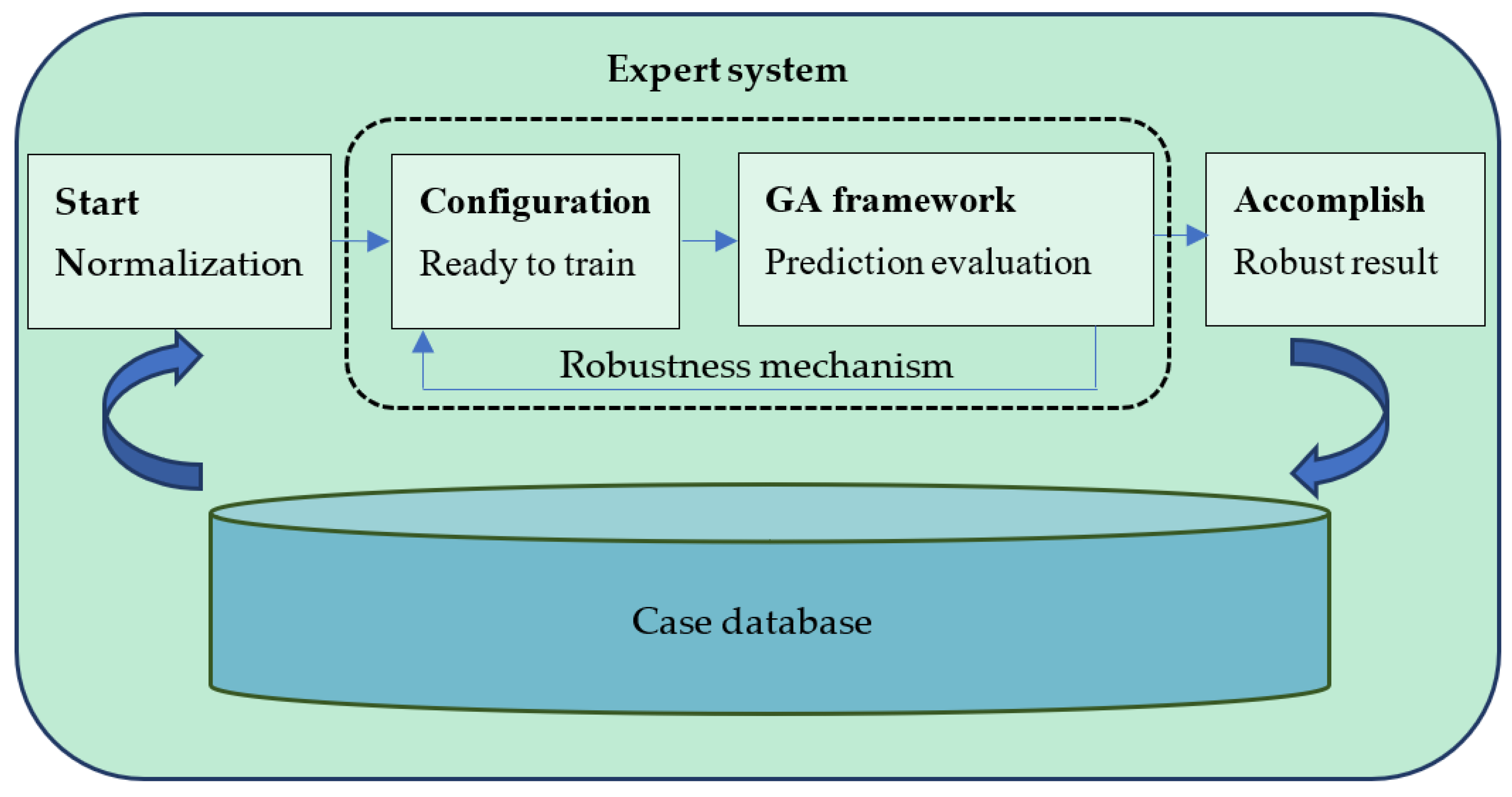
2.2. Optimization of the System
To enhance the predictive performance of the proposed system, this study applies a genetic algorithm (GA) to feature selection. GAs have been widely used as a means to optimize expert systems [
34,
35,
36]. It is an optimizing technique that mimics the evolutionary process of biological chromosomes. Based on the concept of genetic evolution, it repeatedly searches for feasible solutions in order to find an optimal solution to the given problem. The operating process of the GA is briefly explained as follows:
First of all, the GA stochastically generates an initial set of feasible solutions (called the initial population), in which each feasible solution is called chromosome and coded by a value of 0 or 1 (see
Figure 3). Later, the fitness of each feasible solution is computed. The fitness function can be customized by users. A higher fitness value usually indicates a better solution. In the optimization of an expert system, the fitness function is usually defined as the accuracy of the inferential result.
Next, the GA uses the genes in the chromosomes to compute the next generation. The proposed system adopts the GA as a predictor because of its evolution mechanism including selection, crossover, and mutation. These mechanisms can help the system achieve a high prediction accuracy. Selection decides which chromosomes can survive or should be eliminated; crossover is used to exchange partial sections of the chromosomes among parents to create the chromosomes of the next generation. Finally, mutation selects one gene from chromosomes for mutation. The probability of mutation is usually very low. Through repetitive executions of the above genetic operation, offspring with better fitness can be generated, and this operation stops when the stopping rule is met.
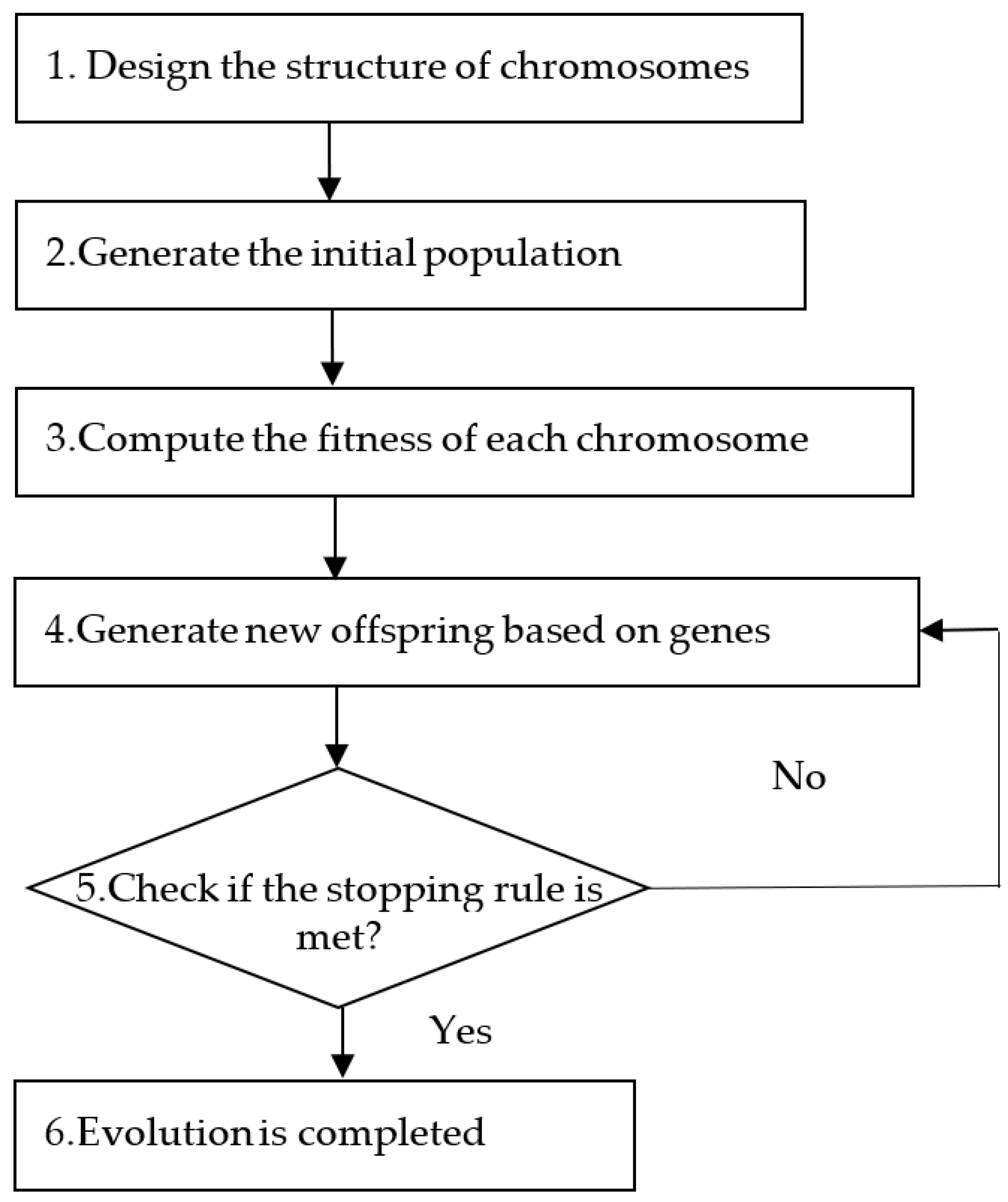
The GA framework designed for this system is as illustrated in
Figure 2. The proposed system applies the GA to select features in the dataset. This training procedure consists of six steps as explained below:
Step 1. Design the structure of chromosomes
In order to obtain an optimal combination of features, we encode feature selection in chromosomes using 0 or 1, as shown in
Figure 3. For instance, “0” denotes the corresponding item is unselected, while “1” denotes the item is selected.
Step 2. Generate the initial population
Before execution of the genetic algorithm, the system has to generate an initial population comprising n chromosomes, each containing randomly generated parameter values. Each chromosome represents a possible solution (the initial feature selection). Given a total of x features, each chromosome is represented by x genes, and each generation has n chromosomes. Through evolution from one generation to the next of each generation, a better solution can be progressively obtained.
Step 3. Compute the fitness of each chromosome
To compute the fitness of each chromosome, we divide the case dataset into two subsets, including a training dataset and a test dataset. The training dataset is the main dataset for training the expert system, whereas the test dataset provides the subject to be tested by the expert system. The training dataset is larger than the test dataset.
For any chromosome , some features in both the training dataset and the test dataset need to be removed, weakened, or reinforced according to the set of features stored in the chromosome. Assume that and , respectively, denote the modified training dataset and the modified test dataset. The fitness of chromosome i can be computed through the following steps:
- (1)
Compute the predicted level (PL) for each case in the test dataset. For each case
in the test dataset, we apply the nearest neighbor method to find the most similar case in the training dataset
to predict the level of this case (the level is represented by
). The similarity between cases is measured using Euclidean distance.
- (2)
Compute the fitness of chromosome . The fitness of chromosome
can be expressed using the following function:
where
denotes the number of cases in
;
indicates whether the predicted level (
) matches the actual level (
). If
=
,
; otherwise,
. The fitness of a chromosome represents the prediction accuracy obtained based on the corresponding feature selection. This value is continuously updated as the evolution progresses. Moreover, it is also used as an indicator to assess the quality of each chromosome. It provides a reference for subsequent genetic evolution. A better chromosome is more likely to be chosen for crossover.
Step 4. Apply genetic operators to derive new offspring
After a new generation is generated, the max fitness value searched for in the previous generation may be changed. As mentioned above, these genetic operators, including chromosome selection, crossover, and mutation, are intended to help generate new chromosomes. The selection operator determines whether a chromosome should be kept or eliminated depending on its fitness value. Chromosomes with a higher fitness value are more likely to survive. For crossover and mutation, the probabilities should be defined in advance.
Step 5. Repeat Step 3 and Step 4 until the stopping rule is met
Step 3 and Step 4 are iteratively executed until the stopping rule is satisfied. By the time that the expert system terminates the evolution based on the stopping rule, an optimal solution will be generated. This solution contains the finally selected features, which are most useful for the prediction of new cases and optimization of the weighting of features in the system.
Step 6. Evolution is completed
After genetic evolutions, the system outputs selected features.
However, system configuration affects the solution performance of the GA framework and further reduce the robustness of the system.
To enhance the robustness of the proposed system, a GA and the Taguchi method are integrated into the expert system.
The Taguchi method [
50] is utilized to optimize the system. It uses an orthogonal array and a signal-to-noise ratio (SN ratio) to help expert systems find an optimal system configuration. The advantage of using an orthogonal array is that it can significantly reduce the total number of runs of the experiment to slash the time cost, whereas the advantage of using an SN ratio is that the quality of the system can be measured. The Taguchi method designed for the system consists of three processes: firstly, set up the parameters of system; secondly, define the levels of each parameter; finally, generate the orthogonal array for the system. An example is given as follows. Assume that there are three parameters, and each parameter has three levels. For a full factorial experiment, the system needs to perform 27 experiments, which is quite time-consuming. Using the Taguchi method, this system generates an orthogonal array and needs to perform only nine sets (i.e.,
) of experiments to obtain a reliable solution. In this way, while the system execution time is being drastically reduced, the system quality can also be ensured.
After the configuration training is completed, the system will measure the mean-square error (
MSE) of the expected results based on the data from each run. The
MSE value has a smaller-the-better characteristic. It is expressed as follows:
where
is the number of observations in the test data,
is the predicted value for the
observation, and
is the actual value of the
observation.
After measuring the
MSE value for each run, the system will estimate the
SN ratio for each configuration. The
SN ratio has a larger-the-better characteristic. It is expressed as follows:
where
is the number of repetitions for each configuration, and
denotes the result of the
run.
Finally, the system will obtain the robust configuration
with the highest total
SN ratio from all the runs. It can be expressed as follows:
where
is the number of levels for each parameter.
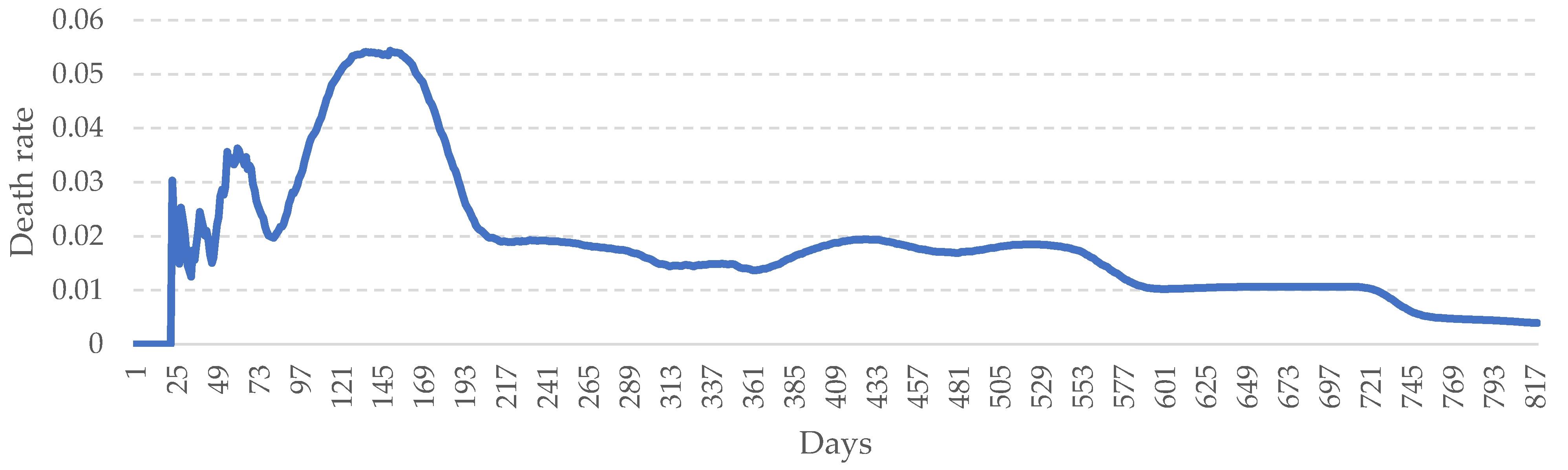
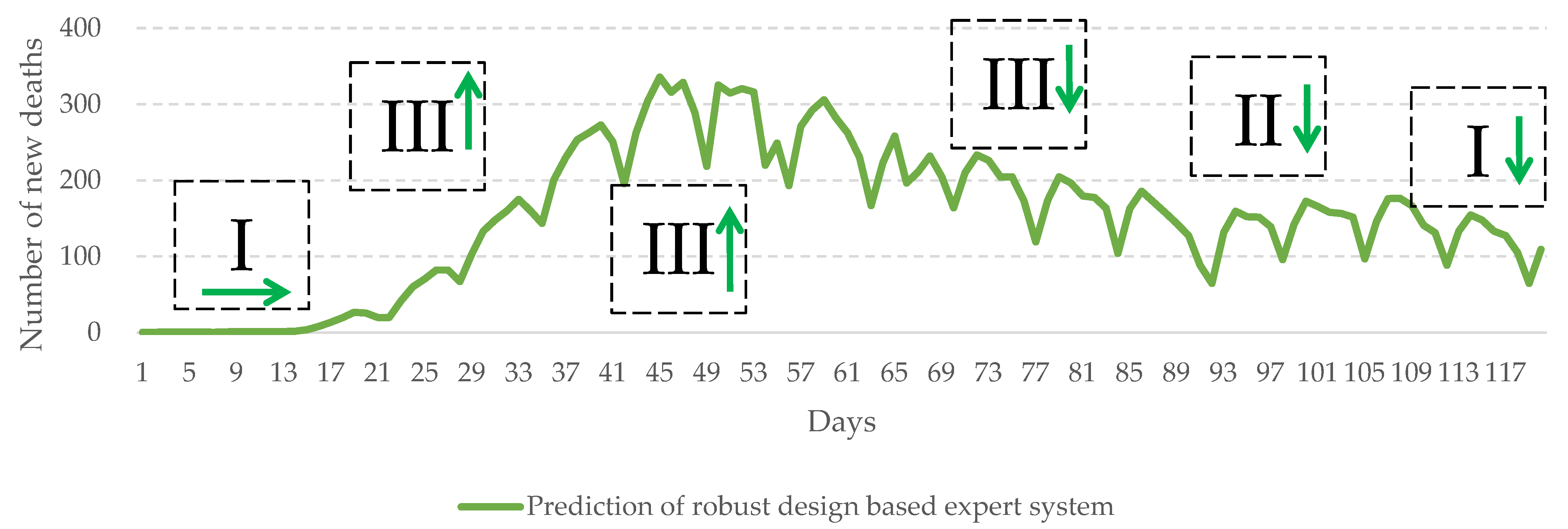
Details on data collection and performance of the system are provided in
Section 3.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}