
Atom Search Optimization with Deep Learning Enabled Arabic Sign Language Recognition for Speaking and Hearing Disability Persons


Abstract
:1. Introduction
2. Literature Review
3. The Proposed Model
3.1. Image Pre-Processing
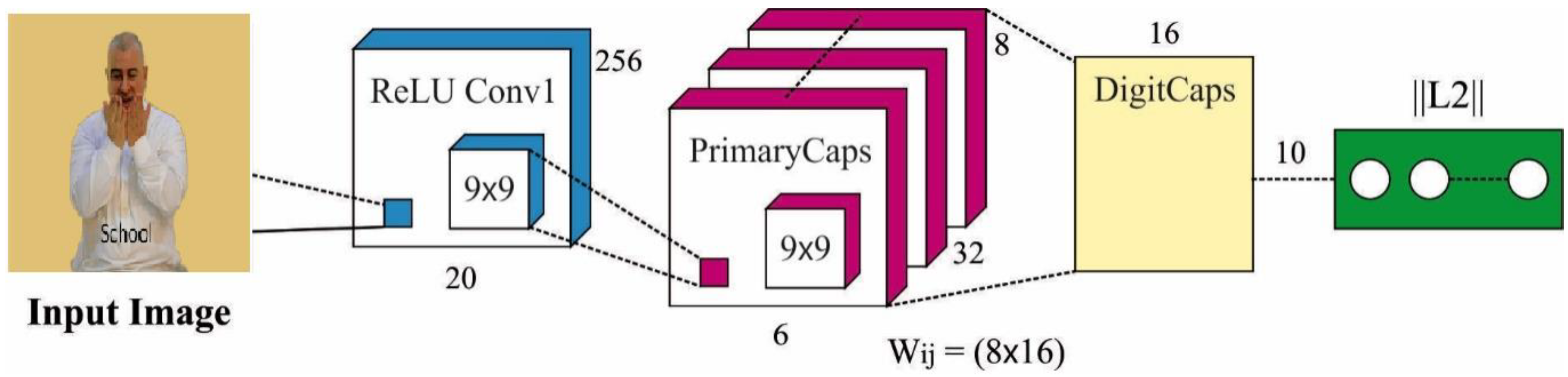
3.2. Feature Extraction: CapsNet Model
3.3. Sign Language Recognition: DCAE Model
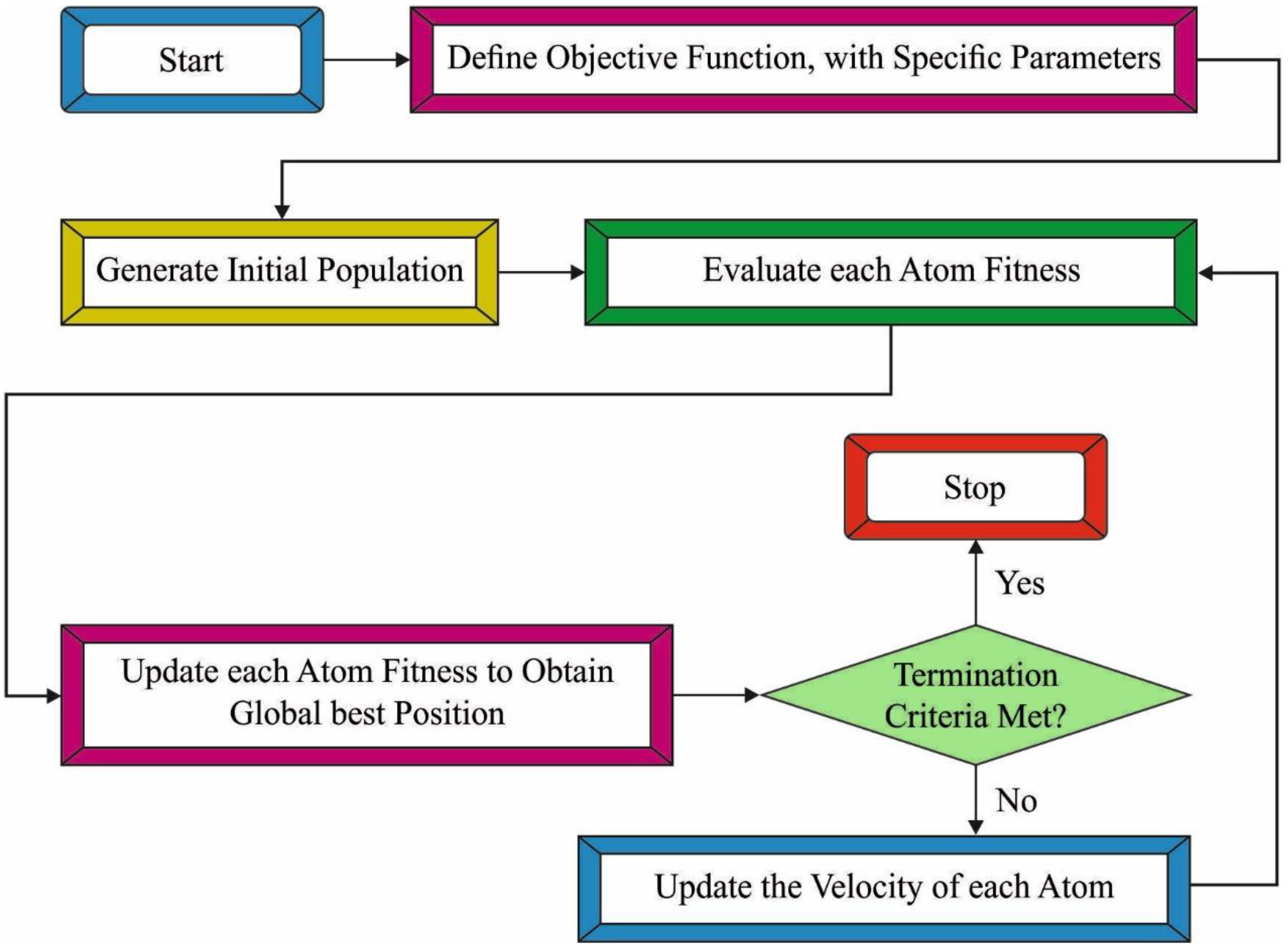
3.4. Hyperparameter Tuning: ASO Algorithm
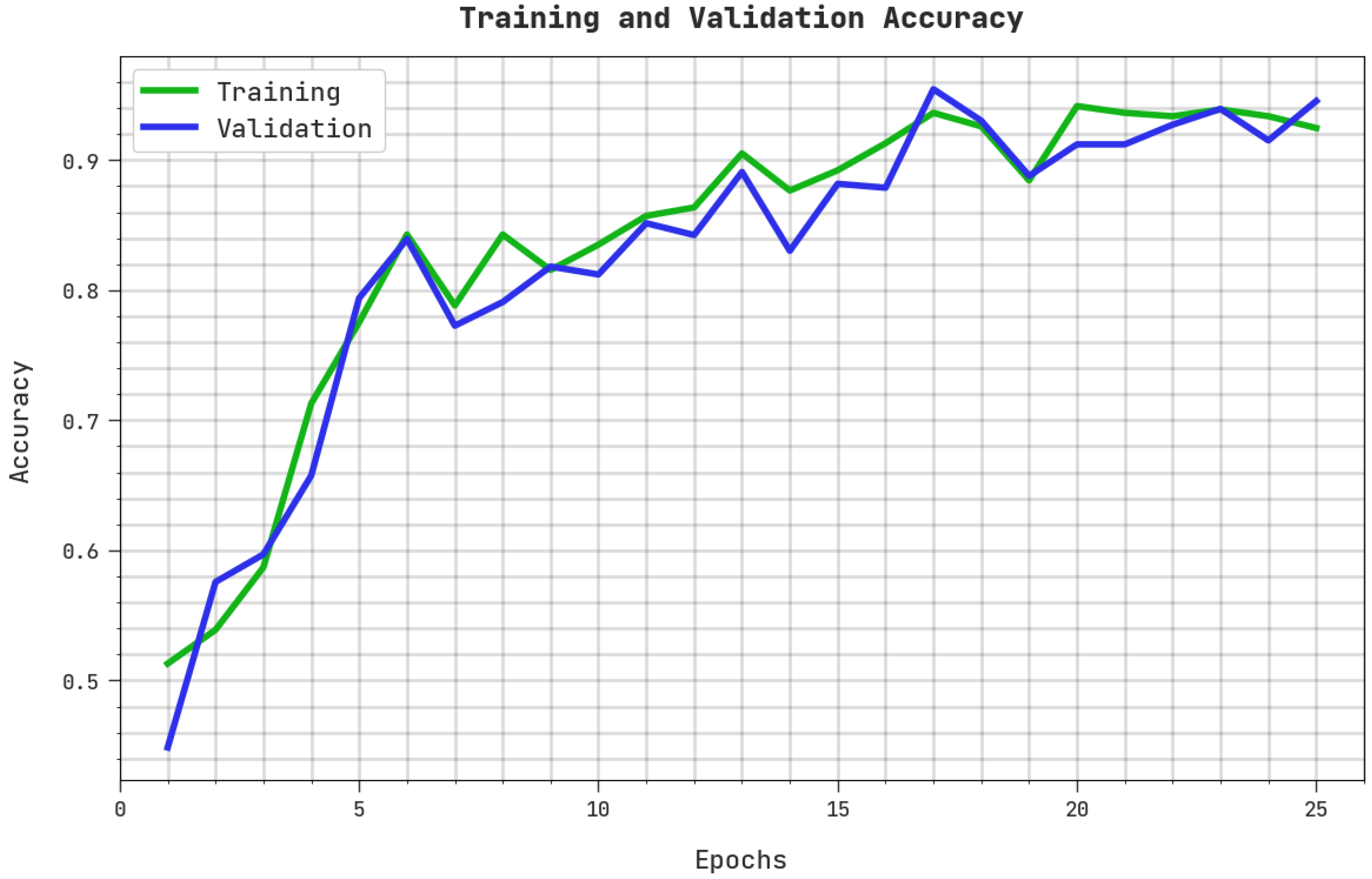
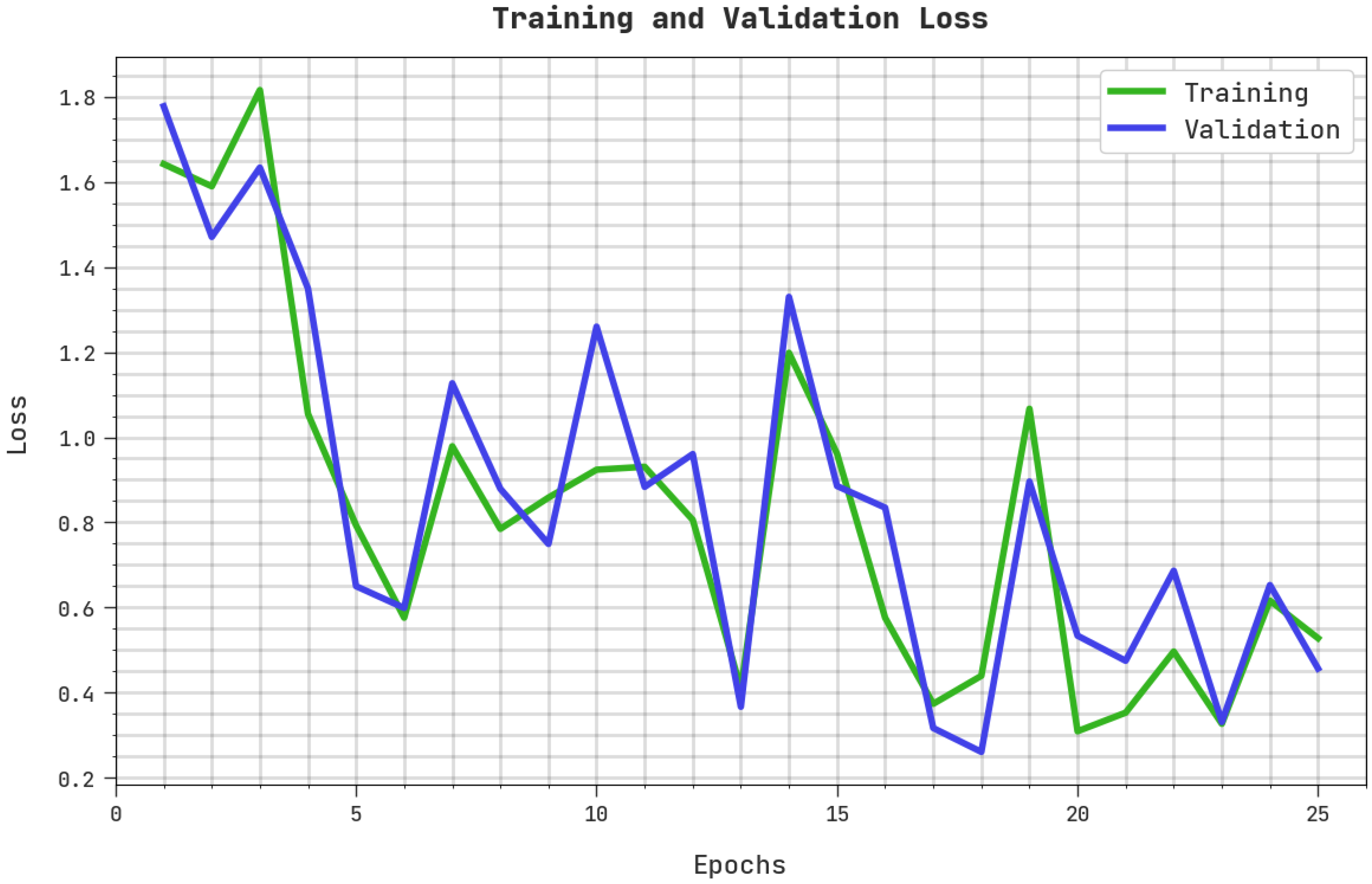
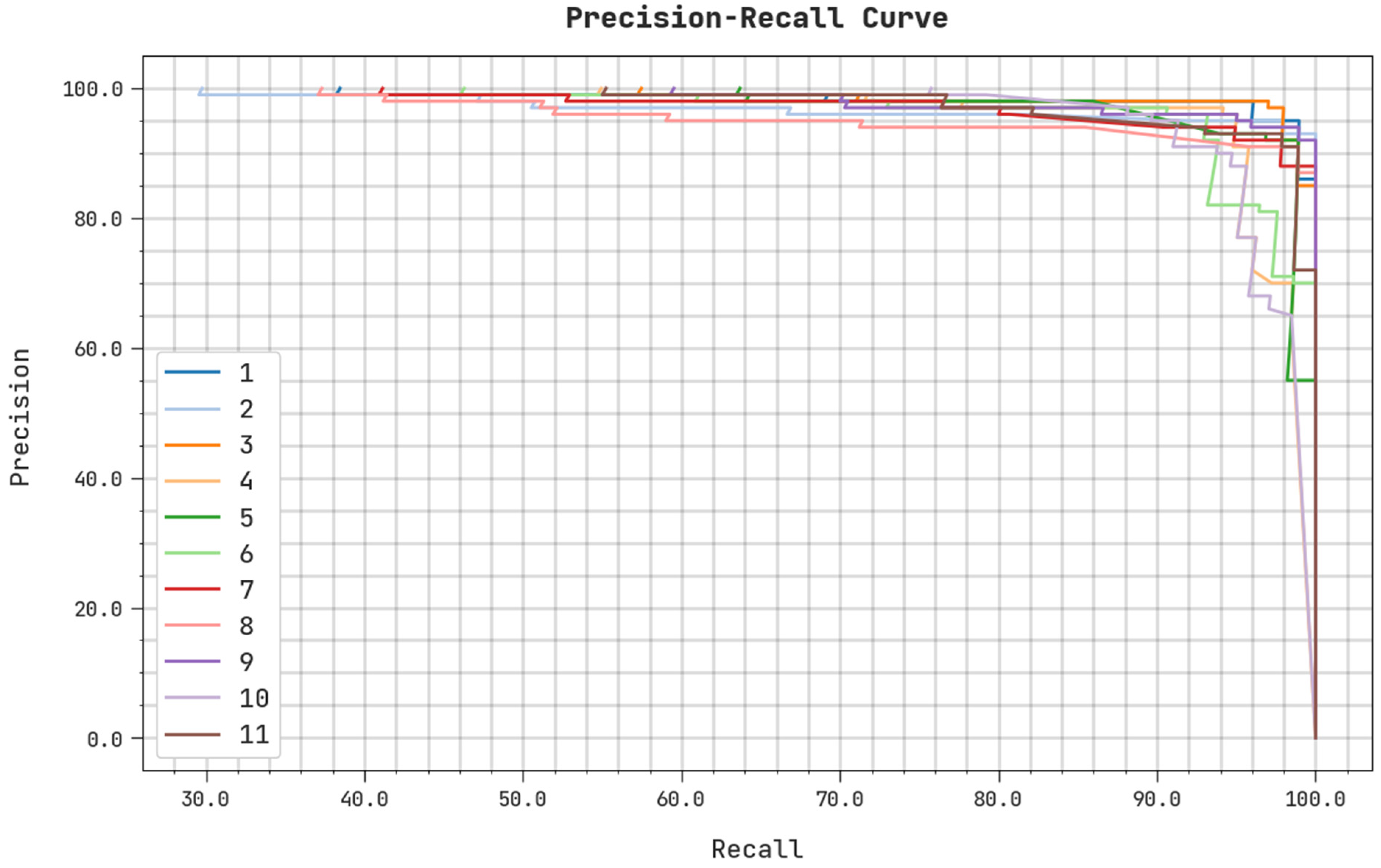
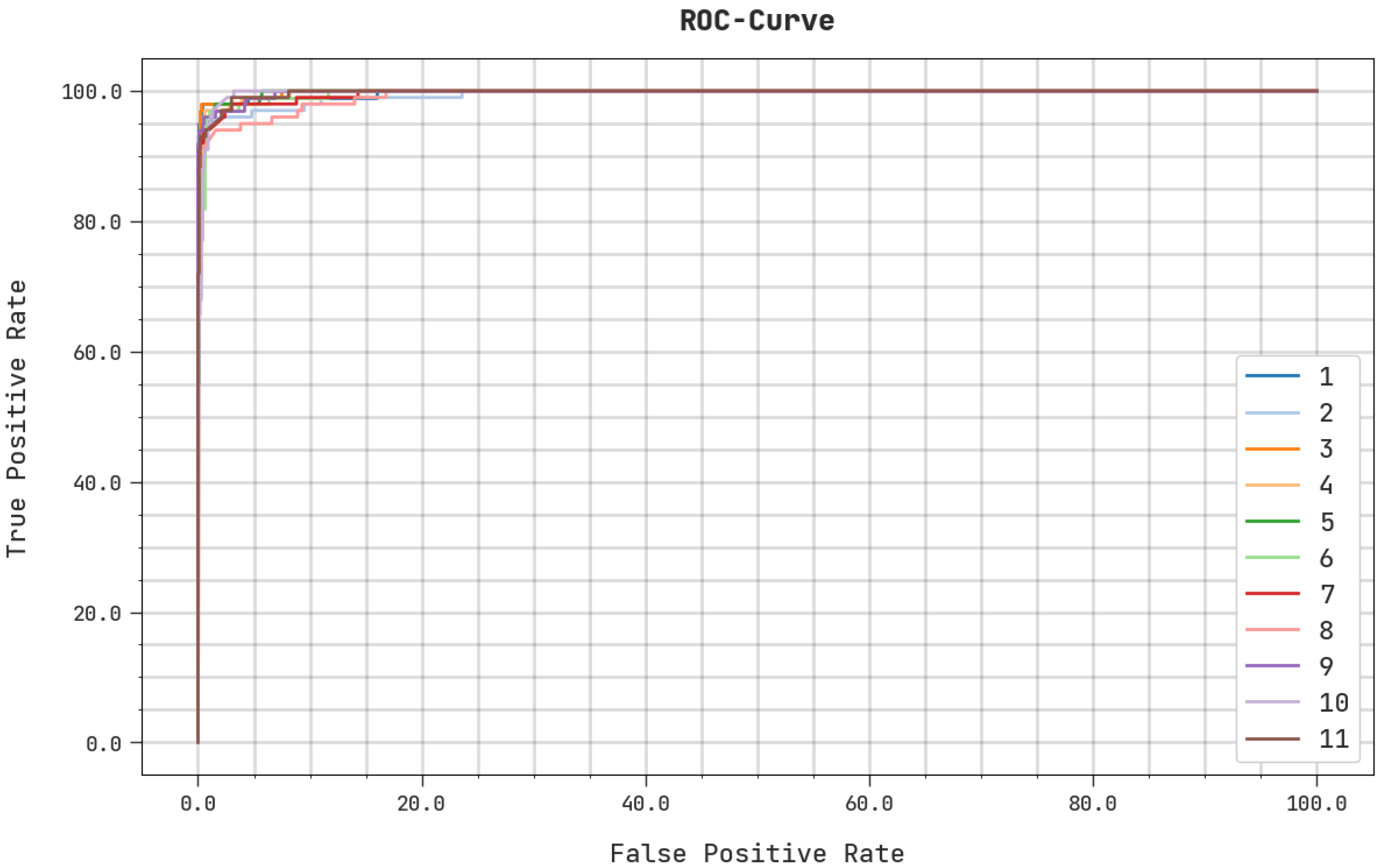
4. Result Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kamruzzaman, M.M. Arabic Sign Language Recognition and Generating Arabic Speech Using Convolutional Neural Network. Wirel. Commun. Mob. Comput. 2020, 2020, 1–9. [Google Scholar] [CrossRef]
- Boukdir, A.; Benaddy, M.; Ellahyani, A.; El Meslouhi, O.; Kardouchi, M. Isolated Video-Based Arabic Sign Language Recognition Using Convolutional and Recursive Neural Networks. Arab. J. Sci. Eng. 2021, 47, 2187–2199. [Google Scholar] [CrossRef]
- Batnasan, G.; Gochoo, M.; Otgonbold, M.E.; Alnajjar, F.; Shih, T.K. ArSL21L: Arabic Sign Language Letter Dataset Benchmarking and an Educational Avatar for Metaverse Applications. In Proceedings of the 2022 IEEE Global Engineering Education Conference (EDUCON), Gammarth, Tunisia, 28–31 March 2022; IEEE: Piscataway, NJ, USA; pp. 1814–1821. [Google Scholar]
- More, V.; Sangamnerkar, S.; Thakare, V.; Mane, D.; Dolas, R. Sign language recognition using image processing. JournalNX 2021, 85–87. [Google Scholar]
- AlKhuraym, B.Y.; Ismail, M.M.B.; Bchir, O. Arabic Sign Language Recognition Using Lightweight CNN-Based Architecture. Int. J. Adv. Comput. Sci. Appl. 2022, 13, 438. [Google Scholar] [CrossRef]
- Tolentino, L.K.S.; Juan, R.O.S.; Thio-Ac, A.C.; Pamahoy, M.A.B.; Forteza, J.R.R.; Garcia, X.J.O. Static Sign Language Recognition Using Deep Learning. Int. J. Mach. Learn. Comput. 2019, 9, 821–827. [Google Scholar] [CrossRef]
- Islalm, M.S.; Rahman, M.M.; Rahman, M.H.; Arifuzzaman, M.; Sassi, R.; Aktaruzzaman, M. Recognition bangla sign language using convolutional neural network. In Proceedings of the 2019 International Conference on Innovation and Intelligence for Informatics, Computing, and Technologies (3ICT), Sakhir, Bahrain, 22–23 September 2019; IEEE: Piscataway, NJ, USA; pp. 1–6.
- Ismail, M.H.; Dawwd, S.A.; Ali, F.H. Dynamic hand gesture recognition of Arabic sign language by using deep convolutional neural networks. Indones. J. Electr. Eng. Comput. Sci. 2022, 25, 952–962. [Google Scholar] [CrossRef]
- Song, Y.; Liu, J. An improved adaptive weighted median filter algorithm. J. Phys. Conf. Ser. 2019, 1187, 042107. [Google Scholar] [CrossRef]
- Alsaadi, Z.; Alshamani, E.; Alrehaili, M.; Alrashdi, A.A.D.; Albelwi, S.; Elfaki, A.O. A Real Time Arabic Sign Language Alphabets (ArSLA) Recognition Model Using Deep Learning Architecture. Computers 2022, 11, 78. [Google Scholar] [CrossRef]
- Sruthi, C.J.; Lijiya, A. Signet: A deep learning based indian sign language recognition system. In Proceedings of the 2019 International Conference on Communication and Signal Processing (ICCSP), Melmaruvathur, India, 4–6 April 2019; IEEE: Piscataway, NJ, USA; pp. 0596–0600. [Google Scholar]
- Wen, F.; Zhang, Z.; He, T.; Lee, C. AI enabled sign language recognition and VR space bidirectional communication using triboelectric smart glove. Nat. Commun. 2021, 12, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Khan, S.A.; Joy, A.D.; Asaduzzaman, S.M.; Hossain, M. An efficient sign language translator device using convolutional neural network and customized ROI segmentation. In Proceedings of the 2019 2nd International Conference on Communication Engineering and Technology (ICCET), Nagoya, Japan, 12–15 April 2019; IEEE: Piscataway, NJ, USA; pp. 152–156. [Google Scholar]
- Nguyen, H.B.; Do, H.N. Deep learning for american sign language fingerspelling recognition system. In Proceedings of the 2019 26th International Conference on Telecommunications (ICT), Hanoi, Vietnam, 8–10 April 2019; pp. 314–318. [Google Scholar]
- Mannan, A.; Abbasi, A.; Javed, A.R.; Ahsan, A.; Gadekallu, T.R.; Xin, Q. Hypertuned Deep Convolutional Neural Network for Sign Language Recognition. Comput. Intell. Neurosci. 2022, 2022, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Sharma, C.M.; Tomar, K.; Mishra, R.K.; Chariar, V.M. Indian sign language recognition using fine-tuned deep transfer learning model. In Proceedings of the International Conference on Innovations in Computer and Information Science (ICICIS), Ganzhou, China, 15–16 September 2021; pp. 62–67. [Google Scholar]
- Aly, S.; Aly, W. DeepArSLR: A Novel Signer-Independent Deep Learning Framework for Isolated Arabic Sign Language Gestures Recognition. IEEE Access 2020, 8, 83199–83212. [Google Scholar] [CrossRef]
- Mazzia, V.; Salvetti, F.; Chiaberge, M. Efficient-capsnet: Capsule network with self-attention routing. Sci. Rep. 2021, 11, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Q.; Zhao, P.; Zhang, D.; Wang, H. MR-DCAE: Manifold regularization-based deep convolutional autoencoder for unauthorized broadcasting identification. Int. J. Intell. Syst. 2021, 36, 7204–7238. [Google Scholar] [CrossRef]
- Barshandeh, S.; Haghzadeh, M. A new hybrid chaotic atom search optimization based on tree-seed algorithm and Levy flight for solving optimization problems. Eng. Comput. 2020, 37, 3079–3122. [Google Scholar] [CrossRef]
- Kothadiya, D.; Bhatt, C.; Sapariya, K.; Patel, K.; Gil-González, A.B.; Corchado, J.M. Deepsign: Sign Language Detection and Recognition Using Deep Learning. Electronics 2022, 11, 1780. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label | Arabic Word | Meaning | No. of Samples |
|---|---|---|---|
| 1 |  | Friend | 100 |
| 2 |  | Neighbor | 100 |
| 3 |  | Guest | 100 |
| 4 |  | Gift | 100 |
| 5 |  | Enemy | 100 |
| 6 |  | To Smell | 100 |
| 7 |  | To Help | 100 |
| 8 |  | Thank You | 100 |
| 9 |  | Come in | 100 |
| 10 |  | Shame | 100 |
| 11 |  | House | 100 |
| Total Number of Samples | 1100 | ||
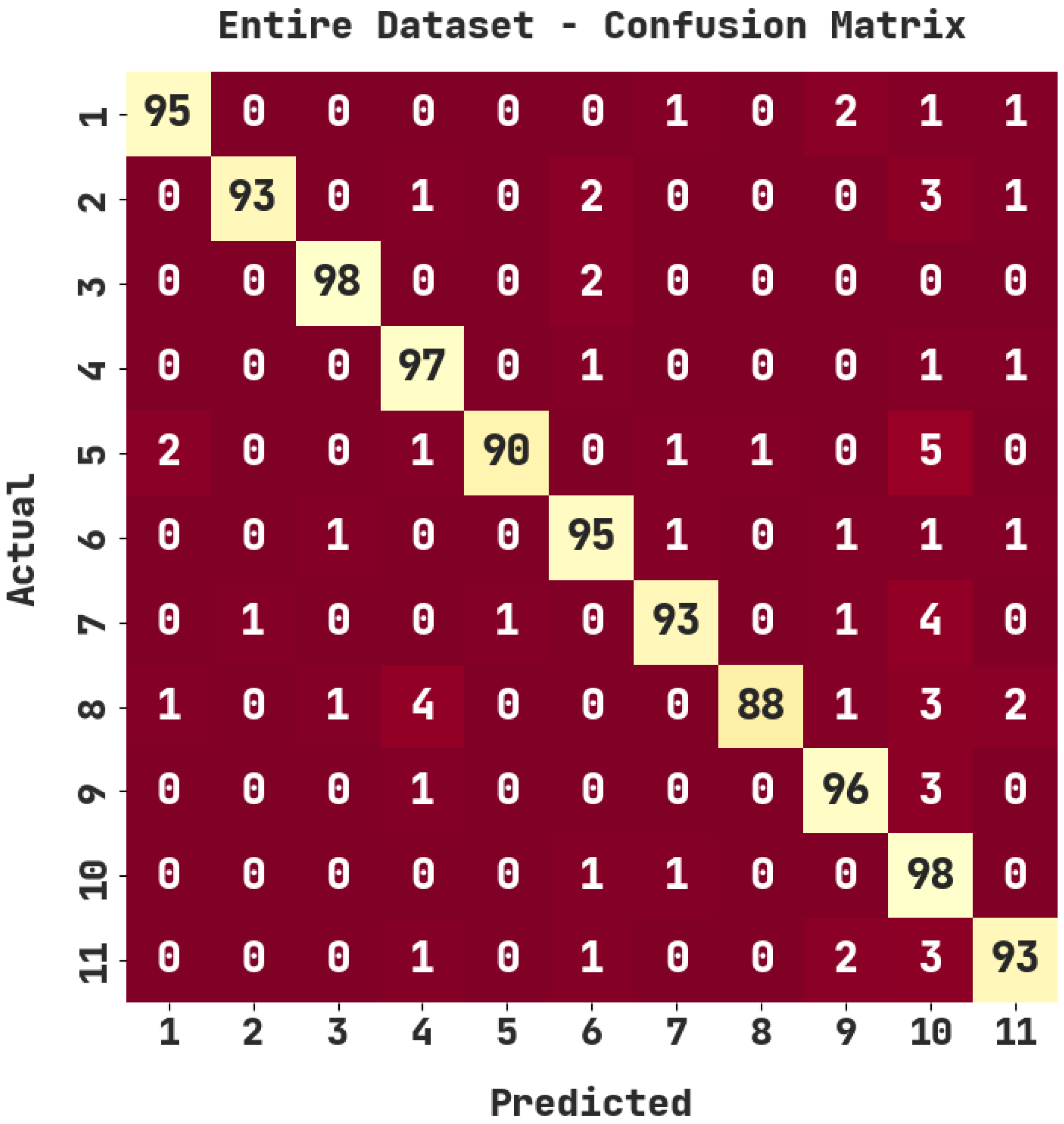
| Entire Dataset | |||||
|---|---|---|---|---|---|
| Labels | Accuracy | Precision | Recall | F1-Score | Jaccard Index |
| 1 | 99.27 | 96.94 | 95.00 | 95.96 | 92.23 |
| 2 | 99.27 | 98.94 | 93.00 | 95.88 | 92.08 |
| 3 | 99.64 | 98.00 | 98.00 | 98.00 | 96.08 |
| 4 | 99.00 | 92.38 | 97.00 | 94.63 | 89.81 |
| 5 | 99.00 | 98.90 | 90.00 | 94.24 | 89.11 |
| 6 | 98.91 | 93.14 | 95.00 | 94.06 | 88.79 |
| 7 | 99.00 | 95.88 | 93.00 | 94.42 | 89.42 |
| 8 | 98.82 | 98.88 | 88.00 | 93.12 | 87.13 |
| 9 | 99.00 | 93.20 | 96.00 | 94.58 | 89.72 |
| 10 | 97.64 | 80.33 | 98.00 | 88.29 | 79.03 |
| 11 | 98.82 | 93.94 | 93.00 | 93.47 | 87.74 |
| Average | 98.94 | 94.59 | 94.18 | 94.24 | 89.19 |
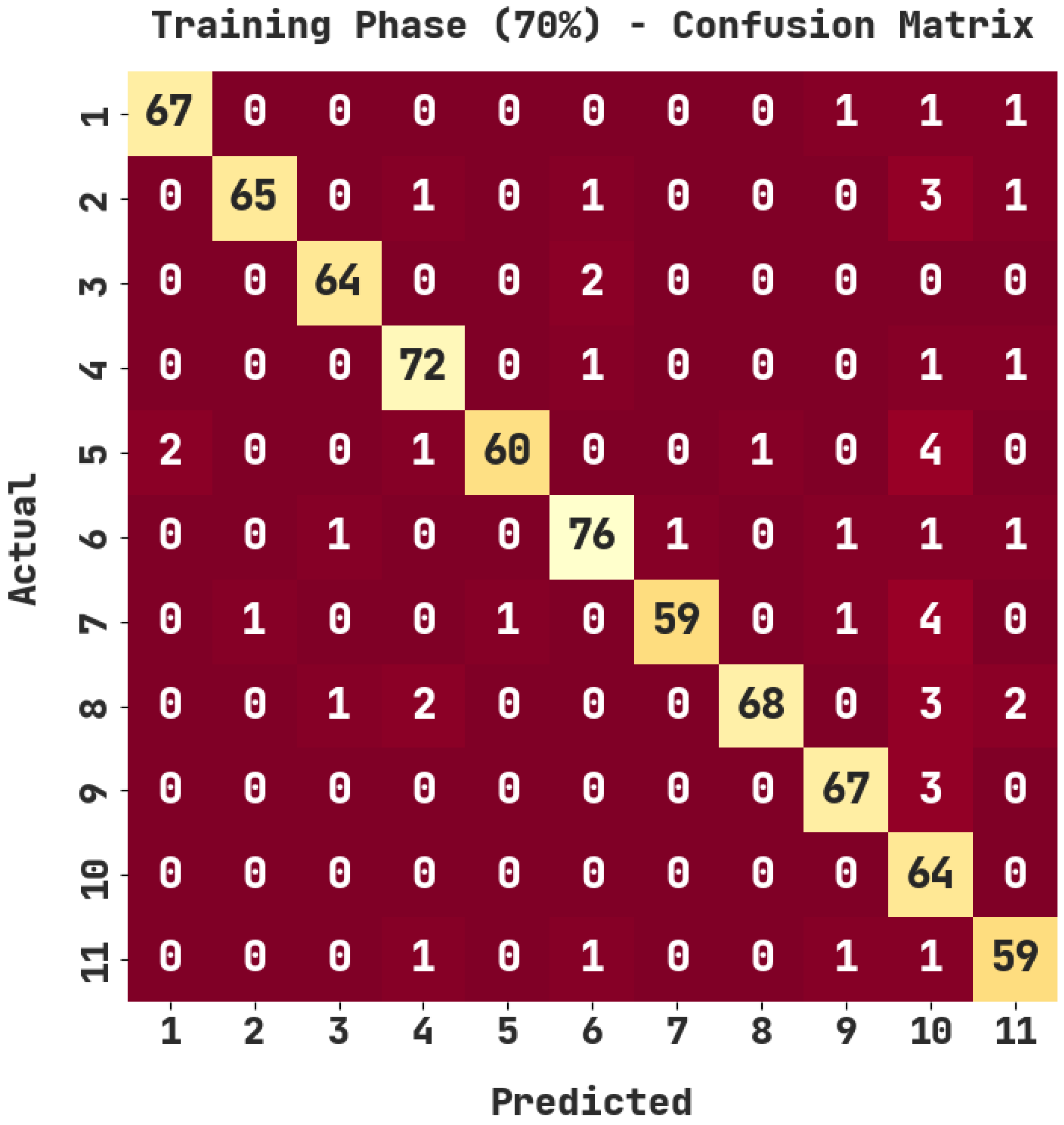
| Training Phase (70%) | |||||
|---|---|---|---|---|---|
| Labels | Accuracy | Precision | Recall | F1-Score | Jaccard Index |
| 1 | 99.35 | 97.10 | 95.71 | 96.40 | 93.06 |
| 2 | 99.09 | 98.48 | 91.55 | 94.89 | 90.28 |
| 3 | 99.48 | 96.97 | 96.97 | 96.97 | 94.12 |
| 4 | 98.96 | 93.51 | 96.00 | 94.74 | 90.00 |
| 5 | 98.83 | 98.36 | 88.24 | 93.02 | 86.96 |
| 6 | 98.70 | 93.83 | 93.83 | 93.83 | 88.37 |
| 7 | 98.96 | 98.33 | 89.39 | 93.65 | 88.06 |
| 8 | 98.83 | 98.55 | 89.47 | 93.79 | 88.31 |
| 9 | 99.09 | 94.37 | 95.71 | 95.04 | 90.54 |
| 10 | 97.27 | 75.29 | 100.00 | 85.91 | 75.29 |
| 11 | 98.70 | 90.77 | 93.65 | 92.19 | 85.51 |
| Average | 98.84 | 94.14 | 93.68 | 93.67 | 88.23 |
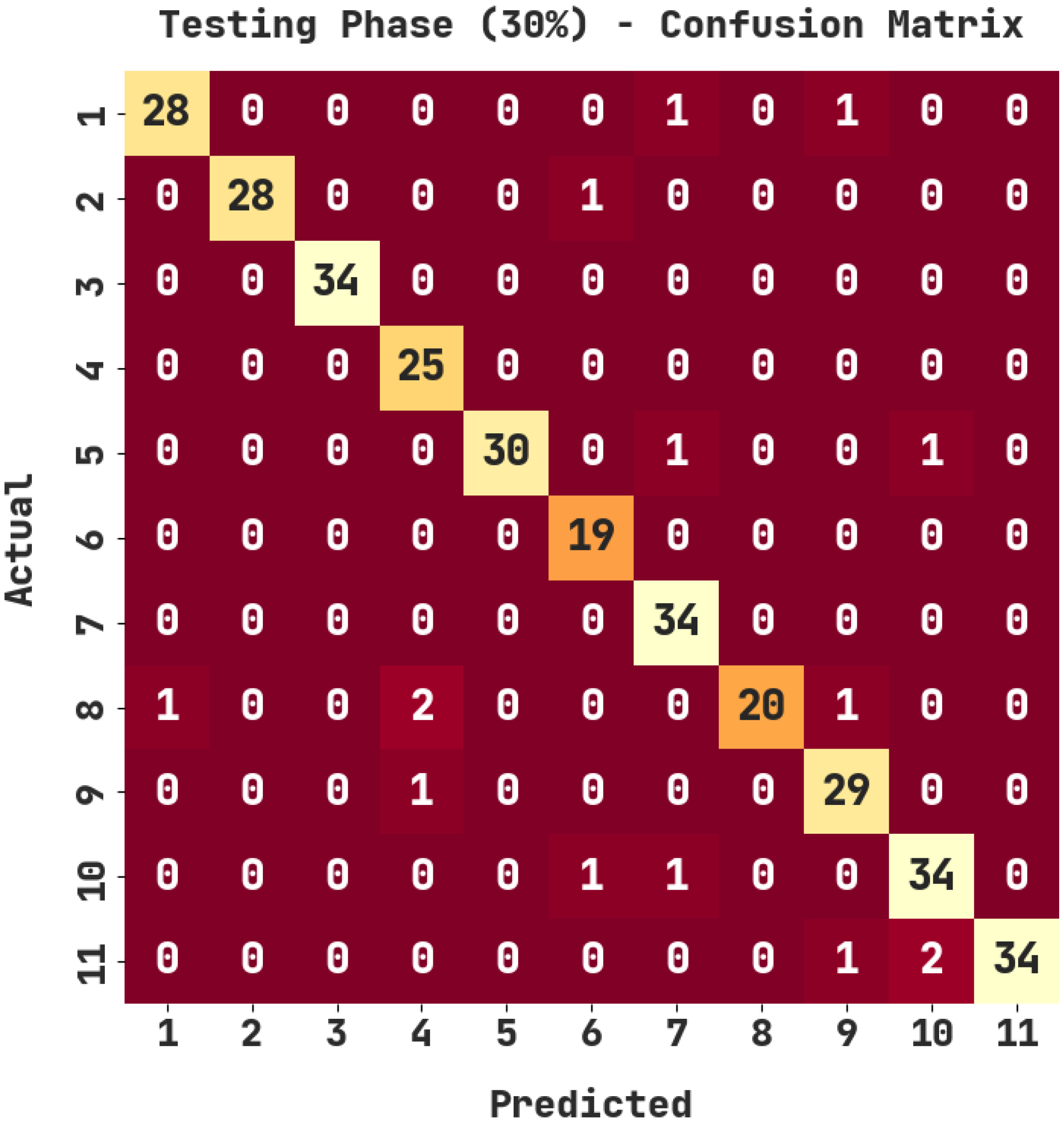
| Testing Phase (30%) | |||||
|---|---|---|---|---|---|
| Labels | Accuracy | Precision | Recall | F1-Score | Jaccard Index |
| 1 | 99.09 | 96.55 | 93.33 | 94.92 | 90.32 |
| 2 | 99.70 | 100.00 | 96.55 | 98.25 | 96.55 |
| 3 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| 4 | 99.09 | 89.29 | 100.00 | 94.34 | 89.29 |
| 5 | 99.39 | 100.00 | 93.75 | 96.77 | 93.75 |
| 6 | 99.39 | 90.48 | 100.00 | 95.00 | 90.48 |
| 7 | 99.09 | 91.89 | 100.00 | 95.77 | 91.89 |
| 8 | 98.79 | 100.00 | 83.33 | 90.91 | 83.33 |
| 9 | 98.79 | 90.62 | 96.67 | 93.55 | 87.88 |
| 10 | 98.48 | 91.89 | 94.44 | 93.15 | 87.18 |
| 11 | 99.09 | 100.00 | 91.89 | 95.77 | 91.89 |
| Average | 99.17 | 95.52 | 95.45 | 95.31 | 91.14 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marzouk, R.; Alrowais, F.; Al-Wesabi, F.N.; Hilal, A.M. Atom Search Optimization with Deep Learning Enabled Arabic Sign Language Recognition for Speaking and Hearing Disability Persons. Healthcare 2022, 10, 1606. https://doi.org/10.3390/healthcare10091606
Marzouk R, Alrowais F, Al-Wesabi FN, Hilal AM. Atom Search Optimization with Deep Learning Enabled Arabic Sign Language Recognition for Speaking and Hearing Disability Persons. Healthcare. 2022; 10(9):1606. https://doi.org/10.3390/healthcare10091606
Chicago/Turabian StyleMarzouk, Radwa, Fadwa Alrowais, Fahd N. Al-Wesabi, and Anwer Mustafa Hilal. 2022. "Atom Search Optimization with Deep Learning Enabled Arabic Sign Language Recognition for Speaking and Hearing Disability Persons" Healthcare 10, no. 9: 1606. https://doi.org/10.3390/healthcare10091606