1. Introduction
Physical activity (PA), which can be defined as all types of body movements produced by skeletal muscles that require energy expenditure, plays a key role in the well-being of both mental and physical health. Nowadays, due to the increased manifestation of a sedentary lifestyle, many people are facing elevated health risks [
1]. Both moderate PAs, which include daily activities such as walking, and vigorous PAs, such as exercises and sports, can improve human health and quality of life. Furthermore, many studies have reported that PA can mitigate the risks of metabolic disorders [
2], cardiovascular diseases [
3], cancer [
4], neurological diseases [
5], and psychiatric disorders [
6,
7]. In this regard, it is important to monitor PA in daily life to provide an appropriate intervention to encourage exercise. Recently, wearable devices, or wearables, have been widely used with the advancement of smart devices and embedded sensors. The most commonly used wearables are wrist-worn smartwatches which can collect the user’s physiological data while performing the basic functions of smartphones [
8,
9,
10]. Wearable sensors can also be attached to various body positions of the torso (chest, waist, and hip) [
11,
12], lower limbs (legs and feet) [
13], upper limbs (forearm and finger) [
14], or head (scalp and ear) [
15,
16,
17], depending on their purpose.
Accelerometers, which measure acceleration in three dimensions—vertical, mediolateral, and anterior-posterior—have often been used in wearable sensors to measure PA objectively in the free-living environment. Numerous studies have attempted to distinguish PA from sedentary behaviors by adopting a cut-point approach with the accelerometry data [
18,
19,
20,
21,
22]. Cut-points are generated to differentiate moderate-to-vigorous physical activity (MVPA) by finding the optimal accelerometer activity counts that best correspond to the energy expenditure [
23,
24,
25]. However, because the cut-point approach has limitations in differentiating the activities of daily living from similar patterns of acceleration, it can lead to a biased estimation of energy expenditure [
26,
27]. For example, the energy expenditure of climbing stairs is nearly twice that of walking on a flat surface, although both activities produce similar patterns of acceleration [
28]. Therefore, it is more important to recognize the specific type of performed activity rather than its duration or intensity to quantify PA. Since the classification of a PA type enables more precise estimation of energy expenditure and provides more informative human behavioral data, wearable PA recognition can be applied to various fields, including healthcare and human–machine interfaces [
29,
30,
31].
In recent decades, various machine learning (ML) methods including deep learning (DL) techniques, which can learn the patterns of linear or nonlinear features extracted from the raw accelerometer data, have been adopted for the classification of human behavior. Most studies have utilized various ML and DL methods to classify six different types of PA, including walking on level ground, walking upstairs, walking downstairs, sitting, standing, and lying, using an open database presented by the UCI machine learning repository [
32,
33,
34]. In the subject-specific paradigm, where an independent classifier is trained and evaluated within each subject, ML classifiers such as k-nearest neighbors (k-NN), multilayer perceptron (MLP), and random forest exhibited great performance [
35,
36,
37]. In regard to the PA classification, the performance of the subject-specific paradigm was better than that of the group-level paradigm, which used the model pretrained with data from other subjects, due to the different sensor locations and behavioral patterns of each subject [
38,
39,
40]. In the group-level paradigms, DL approaches including convolutional neural networks (CNN) resulted in high PA classification accuracy [
41,
42,
43]. For example, Ronao and Cho achieved 94.79% performance for the classification of six PAs using a CNN in the UCI dataset [
41]. Ignatov also reported that the CNN outperformed RF and k-NN in the UCI and WISDM datasets [
42]. The author also demonstrated that the CNN approach led to successful classification in cross-dataset evaluation. Hassan et al. proposed a deep belief network (DBN)-based PA classifier that automatically extracts features from raw sensor data to classify 12 different exercises with 97.5% accuracy [
43]. Although these studies demonstrate the enhanced performance of DL-based classifiers compared with that of standard ML-based models, some studies reported that the ML approach with a well-defined feature set could outperform DL approaches when the resource, such as a hardware specification or the amount of the dataset, is limited. For instance, Montoye et al. proposed that RF outperformed other ML models, including neural networks, in classifying 21 PAs [
44].
Although many studies demonstrated that the ML and DL techniques were useful for predicting a wide range of daily living activities, most studies have utilized the accelerometer data collected in the laboratory environment where participants were instructed to perform certain activities. Therefore, in these controlled settings, the length of the data for each PA could be balanced. However, in a free-living situation, people spend most of their time indulging in a few activities such as sedentary or light behavior, including walking on level ground. On the other hand, people relatively do not engage much in moderate or vigorous PAs, including ascending stairs or running. Since the ML and DL approaches require a large amount of data for each class, the data imbalance between each PA could pose a challenge in building robust ML classifiers. In general, when using an imbalanced dataset, ML models are prone to making biased predictions toward the majority class. In many studies on PA classification, the recognition rate of the minority class was much lower than that of the majority class despite high overall accuracy [
38,
39,
45,
46].
In this regard, this study aims to comprehensively examine the influence of the data imbalance between PA classes by adopting multiple ML and DL methods after performing data balancing techniques. Undersampling and oversampling methods are often used in ML and DL studies to adjust the class distribution. Undersampling methods reduce the size of the majority class by randomly discarding samples in the majority class. The oversampling method is more frequently adopted in ML and DL studies. Random oversampling, in which random samples in the minority class are simply duplicated, can induce an overfitting problem. Therefore, the synthetic oversampling techniques, which generate novel samples that have similar statistical properties to the samples in the minority class, are generally more preferred.
This study utilized an open database presented in PhysioNet [
47], which contains labeled raw accelerometer data during walking on level ground, ascending and descending stairs, and driving. Since there was a huge variation between the durations of each PA (walking on level ground: 262.80 min (26.88%), ascending stairs: 46.65 min (4.67%), descending stairs: 44.59 min (4.56%), and driving: 623.58 min (63.79%)), this dataset was considered adequate to examine the influence of the data imbalance problem. In the original study that provided this dataset, the decision trees (DTs) were trained with spectral features to identify different types of walking [
39]. Despite the high performance in the subject-specific paradigm, relatively poor performance was shown in the group-level paradigm due to the poor recognition rate of the minority class. While the classification of walking and sedentary behaviors such as driving exhibited relatively high performance, that of different walking types was more challenging due to similar PA patterns [
22,
39]. In other studies, the recognition rate of walking upstairs and walking downstairs was much lower than that of other PAs even with the balanced distribution of PAs [
41,
45,
46].
We aim to investigate the influence of multiple classification techniques fused with data sampling techniques on the imbalanced PA dataset. We propose a feature set consisting of temporal, spectral, and nonlinear features, which have been widely used not only in PA classification but also in the analysis of time series data such as biosignals. We also propose that an ensemble learning method that makes predictions with multiple decision trees (DTs) efficiently captures multi-domain features related to the PA classification and is robust to small datasets. The main contribution of this study can be described as follows:
Undersampling and oversampling with ensemble methods could resolve the class imbalance between different PA types;
When using ensemble methods with well-defined features, undersampling was more efficient than the oversampling approach, since it requires a low computational cost while maintaining high classification performance;
Ensemble methods based on decision trees (DTs) successfully made decision criteria based on the multi-domain features and the locations of the accelerometers.
The remainder of this paper is organized as follows.
Section 2 contains the data description and proposed methods, including feature extraction, data sampling, ensemble learning, and comparative ML models.
Section 3 describes the classification performance based on data sampling techniques and ML models, along with the contribution of each feature set to the PA classification. Finally, in
Section 4 and
Section 5, the main findings, implications of this study, and the conclusion are described.
2. Materials and Methods
2.1. Data Description
For this study, the open database of raw accelerometry data of 32 healthy subjects (13 males and 19 females) was adopted from PhysioNet [
46]. In the database, three-axial acceleration was measured from the left wrist, left hip, left ankle, and right ankle. All subjects but one, who identified as ambidextrous, were right-handed. Their average age, height, and weight were 39.03 ± 8.84 years (23–54), 68.31 ± 4.30 inches (58–76), and 169.69 ± 49.61 lbs (100–310), respectively. Throughout the experiment conducted at Indiana University, all subjects wore ActiGraph GT3X+ accelerometer devices (Actigraph, Pensacola, FL, USA) for data collection while performing various PAs. The four devices were attached on the outside of both ankles, the top side of the left wrist similar to a regular watch, and the belt of the subject on the left hip. The sampling rate was 100 Hz for all devices, and all devices were synchronized. Desynchronization between the devices existed, but no serious desynchronization was observed.
The experiment started with a walking session on a trail of 0.66 miles, where the subjects were asked to walk on level ground, descend stairs, and ascend stairs for a total of 9–13.5 min. Walking on level ground was repeated five times, while descending and ascending stairs were repeated six times. In the following driving session, the subjects drove on a city road and highway trails of 12.8 miles for approximately 18–30 min. Throughout the experiment, the subjects were instructed to walk at their usual pace and to drive along a predetermined route to simulate free-living activities. To identify the exact time points, the subjects were told to clap three times at the start and end of each activity, which induced a corresponding amplitude change in the accelerometry data. The periods of clapping and non-study activity, which refers to a few seconds before and after each activity, were excluded from this study because they were only used to mark the time points of each trial.
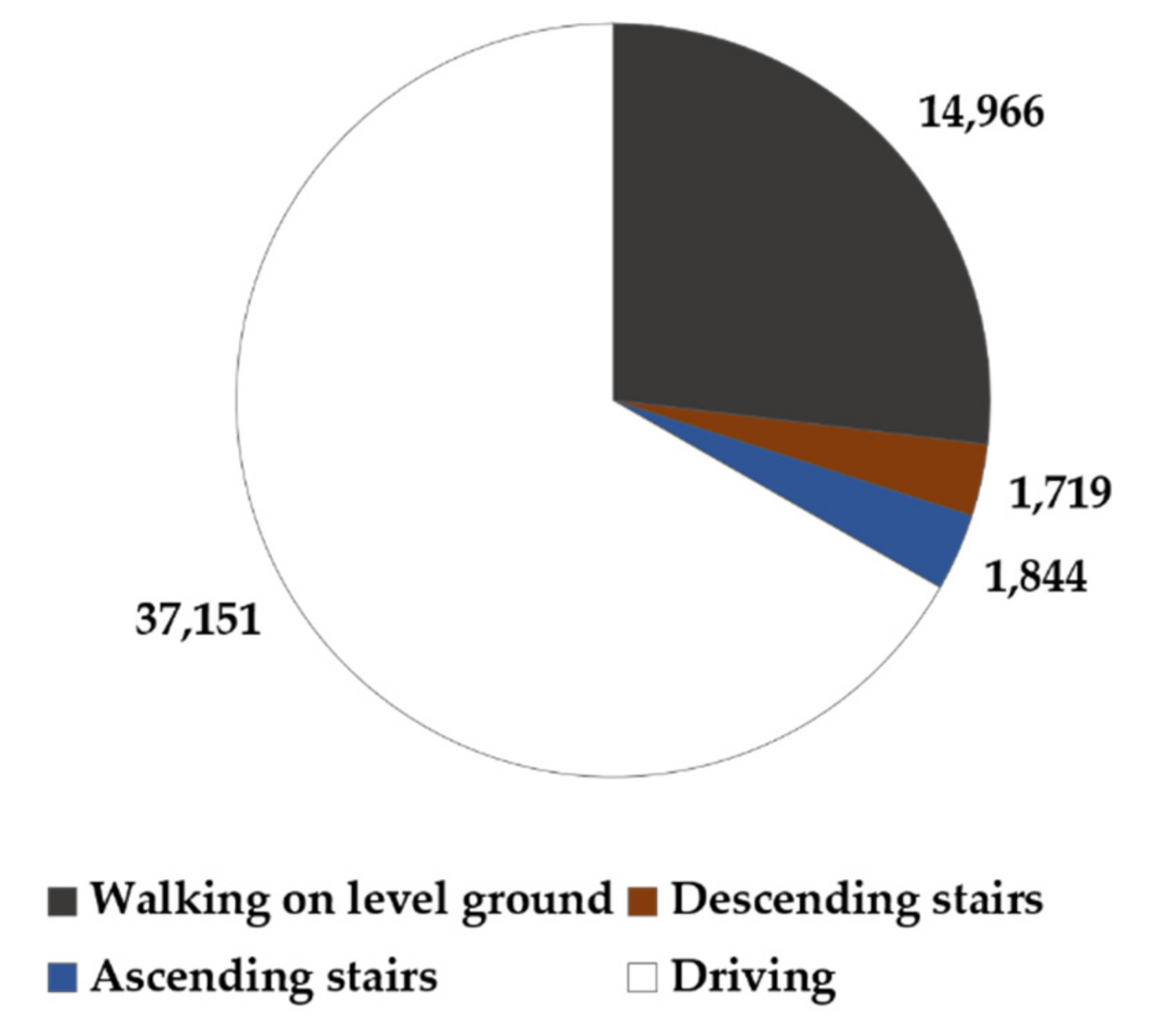
Classification results were provided every 5 s because the features were extracted from a 5-s window. Epochs of transition where two different PAs overlapped were excluded from the analysis. As a result, a total of 55,680 epochs for 4 PAs were collected from 32 subjects. The ratio of each PA was 66.72% for driving, 26.88% for walking on level ground, 3.31% for ascending stairs, and 3.09% for descending stairs. The data distribution for each PA class is shown in
Figure 1.
In this study, a group-level paradigm was adopted to classify four PAs, including walking on level ground, ascending stairs, descending stairs, and driving. The accelerometer data recorded from three different body parts were independently analyzed to see if the place of sensor attachment influenced the PA classification. Accelerometer data were randomly divided into training and test data at a 7:1 ratio. Thus, among 32 subjects, 28 were assigned to the training set, while the remaining subjects were assigned to the test set. This process was repeated eight times by permuting the training and test data set. Thus eightfold cross-validation was used for this study.
In training, the imbalance of data between classes can adversely affect the ML training process. In this dataset, the average amount of data for driving was more than twice that for walking on level ground and 20 times that for descending or ascending stairs (
Figure 1). To avoid the class imbalance problem, two training methods were adopted to balance the data: undersampling and oversampling (
Figure 2). In undersampling, random epochs from the majority class were deleted without making changes to the data in the minority class. Random selection of the deleted epochs was repeated 10 times, and the performance was averaged for evaluation. In oversampling, randomly selected epochs in the minority class were replicated to balance the majority class. To reduce the overfitting problem, synthetic minority oversampling techniques (SMOTE), which create novel data based on the k-nearest neighbors of the minority class, were utilized instead of simple duplication [
48]. These undersampling and oversampling procedures were only applied to the training and not the test dataset to avoid bias in ML.
2.2. Feature Extraction for the Machine Learning Approach
To identify the relevant features from the raw accelerometer data, three types of feature domains, which are frequently used for signal processing, were measured in this study: the temporal, spectral, and nonlinear domain features. All features were extracted from a 5-s window with a 4-s overlap so that the PA was classified every second (
Figure 3). To reduce the subject variability of each feature in a cross-patient paradigm, all extracted features were normalized to have zero means and one standard deviation based on z-score standardization. Eight ML methods, including (1) RF, (2) AdaBoost, (3) DT, (4) k-NN, (5) linear discriminant analysis (LDA), (6) quadratic discriminant analysis (QDA), (7) support vector machine (SVM), and (8) MLP, were evaluated using the extracted features. In addition, to compare the influence of the feature extraction method, four types of DL methods including (1) gated recurrent unit (GRU), (2) bidirectional long short-term memory (BiLSTM), and (3) a one-dimensional CNN (1D CNN) were utilized to train the raw data.
2.2.1. Temporal Features
In the temporal domain, eight features corresponding to the magnitude and statistical measures were calculated from each axis of the raw accelerometer data. The peak-to-peak amplitude, which subtracts the minimum value in the epoch from the maximum value, was used to estimate the intensity of the x, y, and z axes [
36,
44]. The root mean square (RMS) was also used to evaluate the absolute intensity instead of the mean value itself. The second, third, and fourth moments that represent the statistics of the data were also calculated in each epoch [
49,
50]. The second moment refers to the variance, which measures the variability of data distribution. In this study, a standard deviation for each epoch was used as a feature. The third and fourth moments denote the skewness and kurtosis that represent the properties of the data distribution. Two Hjorth parameters, namely statistical time domain measures known for their low computational costs, were used to measure the degree of complexity in the accelerometer data [
51]. Hjorth mobility represents the mean frequency of the power spectrum. The Hjorth complexity estimates the change in frequency while mobility is proportional to the standard deviation of the power spectrum. Furthermore, the number of zero-crossing, which counts the number of intercepts with zero value in each epoch, was used to estimate the fundamental frequency [
36]. The details of each feature are described in
Table 1.
2.2.2. Spectral Features
A short-time Fourier transform (STFT) was adopted to extract the spectral domain features. In the STFT, time series data were converted into a time–frequency domain using a fast Fourier transform (FFT) algorithm with a 5-s window and 1-s sliding window. The Hamming window was applied to minimize the side lobe. Then, 12 spectral features were extracted using power spectral densities (PSDs) corresponding to the 0–15-Hz frequency band obtained from the STFT (
Table 2) [
36,
44,
49,
50]. Since PSDs were obtained for each 5-s window, the frequency resolution was 0.2 Hz, and thus 75 PSDs were selected as candidates for the spectral features. First, the total energy was obtained by summing all PSDs and entropy, which represents the randomness of PSDs [
49]. Then, three peak powers with the largest power and the three dominant frequencies that corresponded to those peak powers were selected among the 75 PSDs. The dominant frequencies were sorted in ascending order. Furthermore, since several studies have reported that the frequency of the resting state and walking behavior each lie within 0.5 Hz and 1.5–2.5 Hz, the dominant frequency smaller than 2.5 Hz and their corresponding peak powers were used for this study [
44,
50]. The energy and entropy of PSDs smaller than 2.5 Hz were also included in the spectral feature set.
2.2.3. Nonlinear Features
Nonlinear features were utilized to examine the inherent nonlinearity embedded in the accelerometer signals. The time delay parameter τ and embedding dimension d were used to reconstruct the time series data in the phase space [
52]. The time delay parameter that represents the time lag to reconstruct an attractor in the phase space can be estimated using auto mutual information (AMI). Since mutual information (MI) quantifies the amount of information shared between two variables, AMI measures the autocorrelation between the original time series
and the delayed time series
. The following equation describes the AMI function:
where
and
are the probability functions of the original signal
and time-delayed signal
, respectively, while
indicates the joint probability of two signals. Then, the optimal time delay
can be determined with an index of the first local minimum of the AMI. The embedding dimension, which is defined as the minimal number of data points to reconstruct signals in the phase space, can be calculated with the false nearest neighbor (FNN). The FNN determines the minimum embedding dimension by observing the changes in the nearby neighbors as the embedding dimension is increased from
m to
m + 1. If two points with a time delay
are separated in a certain dimension, then it means the attractors in the phase space are not preserved. As a result, the first time index at a point where the FNN rate dropped to 0 and did not decrease in the higher dimension was determined as the embedding dimension. The FNN utilizes the equations below:
where
is the Euclidean distance in the
m-dimensional space between
and the
rth nearest neighbor
and
is the predefined tolerance threshold. Then, the time delay and the embedding dimension were used to calculate the Lyapunov exponent and sample entropy. The Lyapunov exponent
quantifies the stability of the signals by estimating the divergence rate of two trajectories that were initially close to each other as in the following equation [
53]:
The largest Lyapunov exponent is commonly used to determine the predictability of signals, and its positive, negative, and zero values refer to chaotic, steady, and periodic signals, respectively. The sample entropy (SampEn), a variant of the approximate entropy (ApEn), quantifies the complexity of the time series data [
54]. Unlike ApEn, which finds the repetitive patterns of signals, SampEn eliminates self-matches, which makes it independent of the data length [
55]. SampEn can be defined as follows:
where the function
denotes the Chebyshev distance between two points that are not equivalent (
i ≠
j). A larger SampEn means that the signal is more unpredictable and irregular. Finally, the Hurst exponent
H measures the long-term memory of time series data [
56]. It estimates the self-similarity of signals by fitting the power law as follows:
where
indicates the expected value and
C is constant. The function PTP denotes the peak-to-peak function that subtracts the minimum value from the maximum value, as described in
Table 1. The value
H being in the range of 0.5–1 indicates that the signals are persistently auto-correlated, while an
H value of 0.5 implies that the signals are brown noise, meaning that they are completely uncorrelated.
2.3. Ensemble Learning
Ensemble learning, which employs multiple models to make predictions on given data, aims to compensate for the potential problems that could arise from using a single classifier. Previous studies have shown that ensemble learning can mitigate the class imbalance problem which is common in machine learning, where classifiers can easily develop a bias toward the majority class [
57]. The use of multiple learners in ensemble learning can also lower the risk of getting stuck in a local minimum, which is common when using an individual learner. The basic assumption is that the final output generated by ensemble learning leads to better prediction than that of the individual classifiers. Ensemble learning can be implemented in a sequential or parallel process. RF is one of the ensemble techniques, first introduced by Breiman in 2001, which uses bootstrap aggregation (bagging) to construct ensembles to deal with classification and regression problems [
58]. It utilizes ensemble learning in a parallel process in which predictions made from multiple classifiers, called decision trees (DTs), are averaged to yield the final output (
Figure 4). Each training data are randomly drawn from the original data set so that input variation is given to each learner. Each of the DTs starts with a root node, where a feature is used as a threshold to split the data into two branches, giving it a tree-like shape [
59]. The same step is repeated using different features until the leaf node of the tree is reached, where a prediction of the class label is made. While the conventional DT is prone to overfitting the training data, RF is less likely to overfit due to its ensemble design. In RF, the data are randomly split into training and validation sets. For each set, decision trees are generated through bagging, which is a procedure of repeatedly drawing random samples from the dataset. Then, the final class label is determined by employing a majority vote, which means that the class label estimated by most of the trees is given as the final prediction. This majority vote system helps reduce the variance in predictions. A previous study has also shown that RF performed the best among a total of 11 classification algorithms, even with noisy and imbalanced data [
60].
Boosting is another ensemble learning method, which sequentially generates multiple models based on the errors of the previous model (
Figure 5). One of the most popular boosting algorithms is AdaBoost, where each decision tree in the ensemble is assigned a weighted error rate based on the previous model, which is used to determine the decision power of each tree [
61]. Unlike RF, where the learners are independently trained with random subsamples, AdaBoost trains individual learners with the entire data in a serial manner by increasing the error weights of misclassified instances. Each learner is also assigned another set of learner weights which is inversely correlated with the assigned error weights. Thus, the larger the weighted error rate assigned to a tree, the less influence the tree has in majority voting for the final prediction. In this study, after testing for the optimal parameters, the number of decision trees was set to 100 for both RF and AdaBoost.
2.4. Evaluation Metrics
In this study, the influences of the undersampling and oversampling methods for balancing classes were examined based on the classification performance of ensemble learning, including RF and AdaBoost. Furthermore, the ensemble methods were compared to other ML models that are frequently exploited for various classification tasks. In most ML and DL studies, classification performance is assessed using the sensitivity, specificity, precision, F1-score, and accuracy. Sensitivity, which is also known as recall, measures the ratio between true positives (TP) and actual positives (TP + FN, where FN refers to false negatives). Therefore, it evaluates the performance of the model based on its ability to correctly recognize the target. Specificity measures the percentage of true negatives (TNs) out of the actual non-target cases (TN + FP), where FP refers to false positives), indicating the model’s ability to correctly classify non-target classes. Specificity is inversely proportional to sensitivity in that it increases as the sensitivity decreases and vice versa. Another evaluation metric is precision, which refers to the fraction of the actual target class (TP) among those classified as the target class (TP + FP). Next is the F1-score, which combines precision and recall by taking their harmonic mean, which is also frequently used for evaluating ML classifiers. Finally, there is the accuracy, the most commonly used evaluation metric, which calculates the ratio of correctly predicted cases (TP + TN) to the total predictions (TP + TN + FP + FN).
However, when evaluating the performance for imbalanced data, F1-score and accuracy can be unreliable, since they do not take the data distribution into account. Therefore, this study mainly adopted balanced accuracy, which can be defined as the average of the recall obtained from each class, for evaluating the multi-class ML classifiers. To compare the classification performance depending on the undersampling or oversampling approach or the classification performance among multiple ML classifiers, the Kruskal–Wallis test was utilized for each evaluation metric. Furthermore, multiple comparison problems were corrected using the Tukey–Kramer method.
4. Discussion
This study aimed to distinguish four PAs using raw accelerometer data collected from three different body parts: the wrist, hip, and ankle. Two ensemble learning methods of RF and AdaBoost were compared with other comparative ML and DL models in terms of differentiating sedentary behavior (driving) and three types of walking modalities (walking on level ground, ascending stairs, and descending stairs). Since the previous study on this dataset reported lower performance in the group-level classification compared with that in the subject-specific paradigm, this study aimed to improve the classification performance in the group-level paradigm [
39]. Furthermore, to overcome the data imbalance problem in different PA types which deteriorates the classification performance, undersampling and oversampling methods were adopted in this study (
Figure 2). Feature-based ML classifiers including RF and AdaBoost exhibited enhanced performance by solving the data imbalance problem using undersampling and oversampling methods (
Figure 6). In the previous study that utilized the same dataset with DT, the sensitivity of the minority class was poor despite the high sensitivity of the majority class [
39]. They reported that the sensitivities of ascending stairs and descending stairs in the group-level paradigm were approximately 40–55% when using wrist or hip sensors. The sensitivities of these minority classes ranged between 60% and 70% even with the data from the ankle-worn sensor. In this study, we demonstrated that the balanced accuracy and average recall of the minority classes were much higher than in the previous study. When using the ankle accelerometer, both the balanced accuracy and average recall were higher than 90%. When using the wrist or hip accelerometer, the balanced accuracy was approximately 80%, and the average recall of the minority classes was larger than 70%. Alharbi et al. also suggested that oversampling methods, including SMOTE and its variations, could enhance the classification of the minority class with different datasets [
62]. For example, the classification accuracy of ascending stairs, which accounts for 6% of the PAMAP2 dataset, was 45.9% without oversampling but was enhanced to 60% with oversampling. However, they did not investigate the effect of undersampling on the classification performance.
The improvement in classification was not only due to the data balancing techniques but also the improved classifiers and the abundance of features. In
Figure 8, among the feature-based ML classifiers, DT exhibited the lowest classification performance. While single DT is vulnerable to overfitting, ensemble methods such as RF and AdaBoost that utilize multiple trees are robust to noise and outliers. Although other ML models like LDA outperformed the ensemble methods with hip-worn sensors, the ensemble methods exhibited moderate performance regardless of the sensor locations while examining the influence of each feature on the classification criteria. Unlike the previous study on the same dataset, which extracted features from the vector magnitude that combined the three axes, this study extracted 25 temporal, spectral, and nonlinear features, which were used in PA classification as well as biosignal analysis along each of the three axes. Therefore, we utilized 75 features to train each classifier. By examining the feature importance collected from RF, we found that the features along the y axis were useful in classifying the walking types and sedentary behaviors when using the ankle- or wrist-worn sensors. In particular, the standard deviation and spectral features in the range of 0–2.5 Hz played important roles. Unlike these two sensors, where the features along the y axis were significant, when using the hip-worn sensor, the features along all three axes played important roles. This could be due to the more complex movement of a hip joint compared with that of a wrist or ankle during walking activities.
The features extracted from the ankle accelerometer data resulted in a higher classification performance than those from the hip- and wrist-worn sensors (
Figure 6). Therefore, rather than hip- or wrist-worn sensors, ankle accelerometers which can be embedded in shoes are more adequate for differentiating different walking activities. Nonetheless, PA classification with hip- and wrist-worn sensors can also be conveniently measured, since the former can be embedded in a smartphone which can be placed in a pants pocket, and the latter can be embedded in a smartwatch. Since most PAs require arm and foot movement, the combination of multiple wearable sensors will be useful for differentiating diverse activities. For example, a study that utilized the WISDM dataset successfully classified 18 PAs, including walking types and household activities [
34].
Although many studies reported that DL approaches were useful for the multi-class classification of PAs, the durations of each PA were balanced in most datasets. Since DL models require a substantial amount of data for each class, it is difficult to apply them in a free-living situation, where data imbalance between PAs is common. In a free-living situation, a larger portion of most people’s time is spent in sedentary behaviors like driving or walking on level ground instead of ascending or descending stairs. In this study, the performance of the DL models severely deteriorated with the undersampling approach. On the other hand, when using ML classifiers, the classification performance did not differ between the undersampling and oversampling methods. Since the computational cost was dramatically reduced with the undersampling method, ML classifiers including RF and AdaBoost, which were robust for the undersampled data, were more efficient if relevant features could be extracted (
Figure 7). With the oversampled data, the performance of the DL models was enhanced to a level comparable to some ML models (
Figure 6). If sufficient data were collected from each PA, the DL models would have demonstrated great performance in various classification tasks. For example, Ronald et al. achieved 95.09% accuracy in the classification of six activities using the Inception-ResNet-based deep learning model (iSPLInception) even in the between-subject paradigm [
63]. Despite the great performance, DL models require a high computational cost. In this study, the average training time of the GRU model which only used two hidden layers was approximately 74 times that of RF.
In future studies, the classification performance of ensemble learning on the accelerometer data from more diverse PAs can be compared with that of other ML and DL models. Since this study classified only four PAs highly related to lower limb motion, the classification accuracy was almost perfect using the ankle-worn sensors. Meanwhile, the performance declined when using hip- or wrist-worn sensors. Therefore, to obtain good performance in the classification of more diverse PAs, the development or adoption of novel features to capture the distinct patterns of each PA is necessary. To overcome the limitation of this study, the DL approach, which can automatically capture distinct patterns of the data, can be applied in future studies. Since the DL approaches in this study only utilized two layers, a more advanced DL model with varying hyperparameters must be tested for potential improvement in performance. Finally, the DL models can be improved with sufficient accelerometer data for each PA as well as more advanced data augmentation techniques, such as a generative adversarial network (GAN).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}