
Spatio-Temporal Traffic Flow Prediction in Madrid: An Application of Residual Convolutional Neural Networks

 , ,
, ,
Abstract
:1. Introduction
1.1. Related Work
1.2. Overview
2. Materials and Methods
2.1. Study Design and Data Source
2.2. ARIMA Models
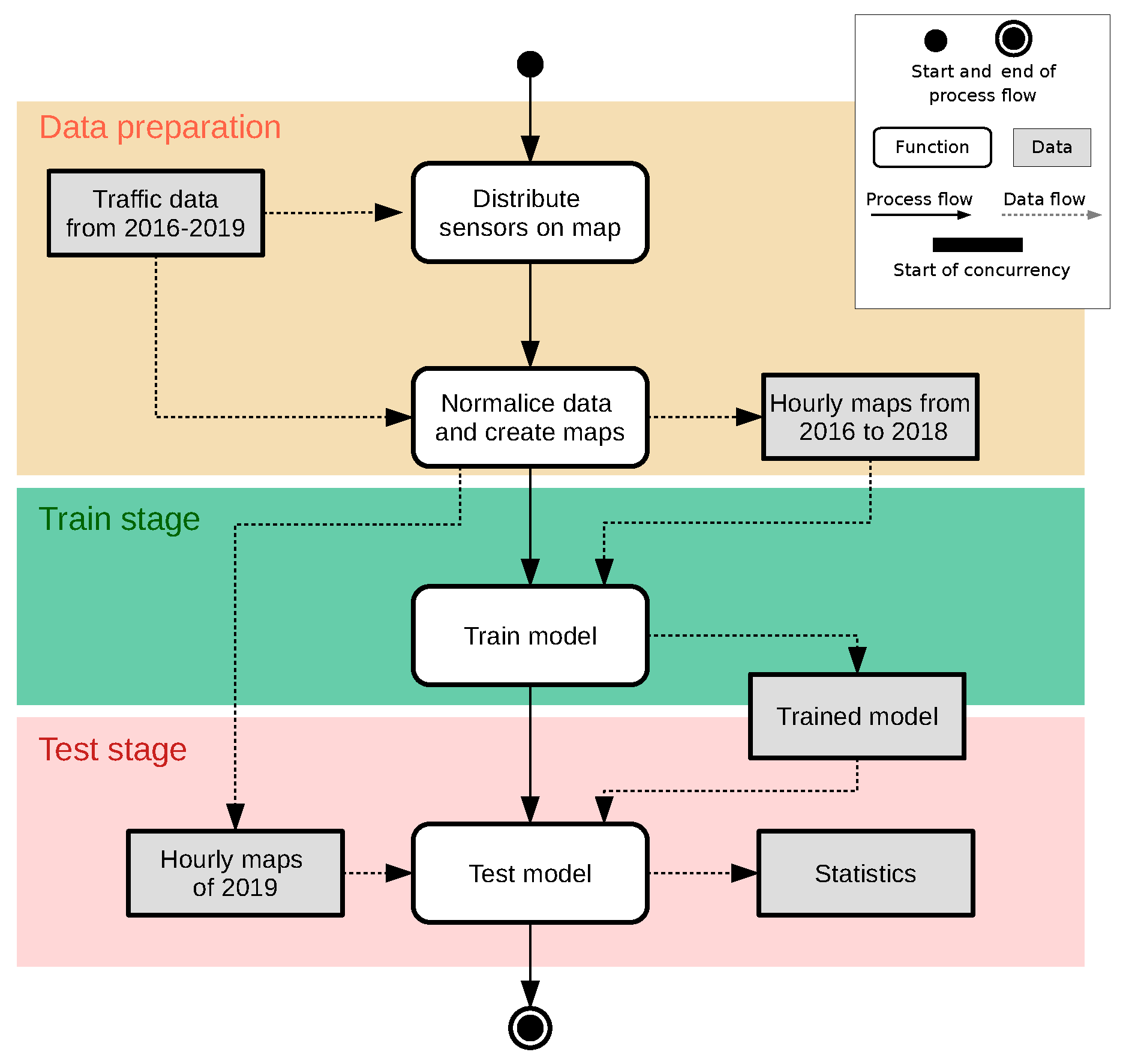
2.3. Visual Model
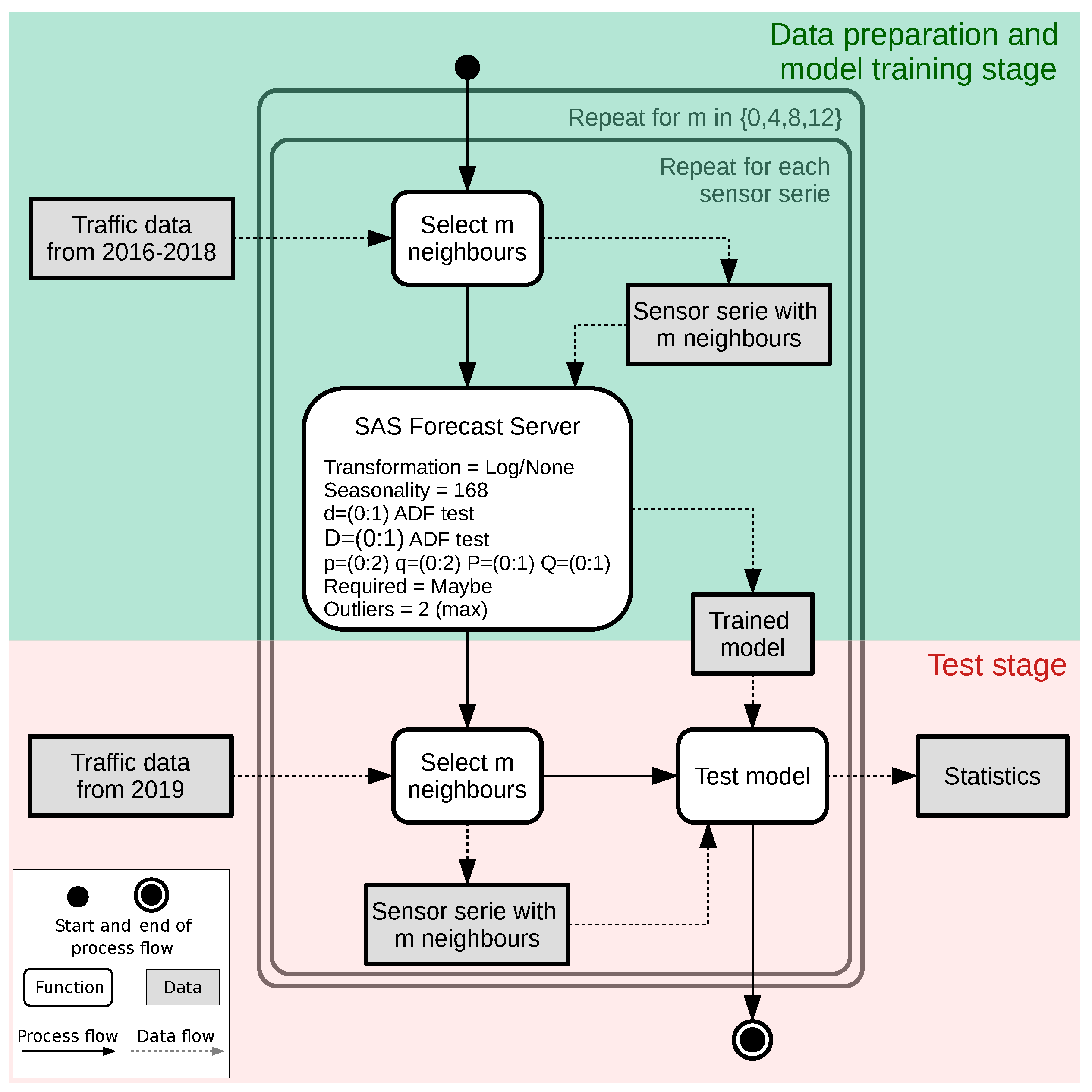
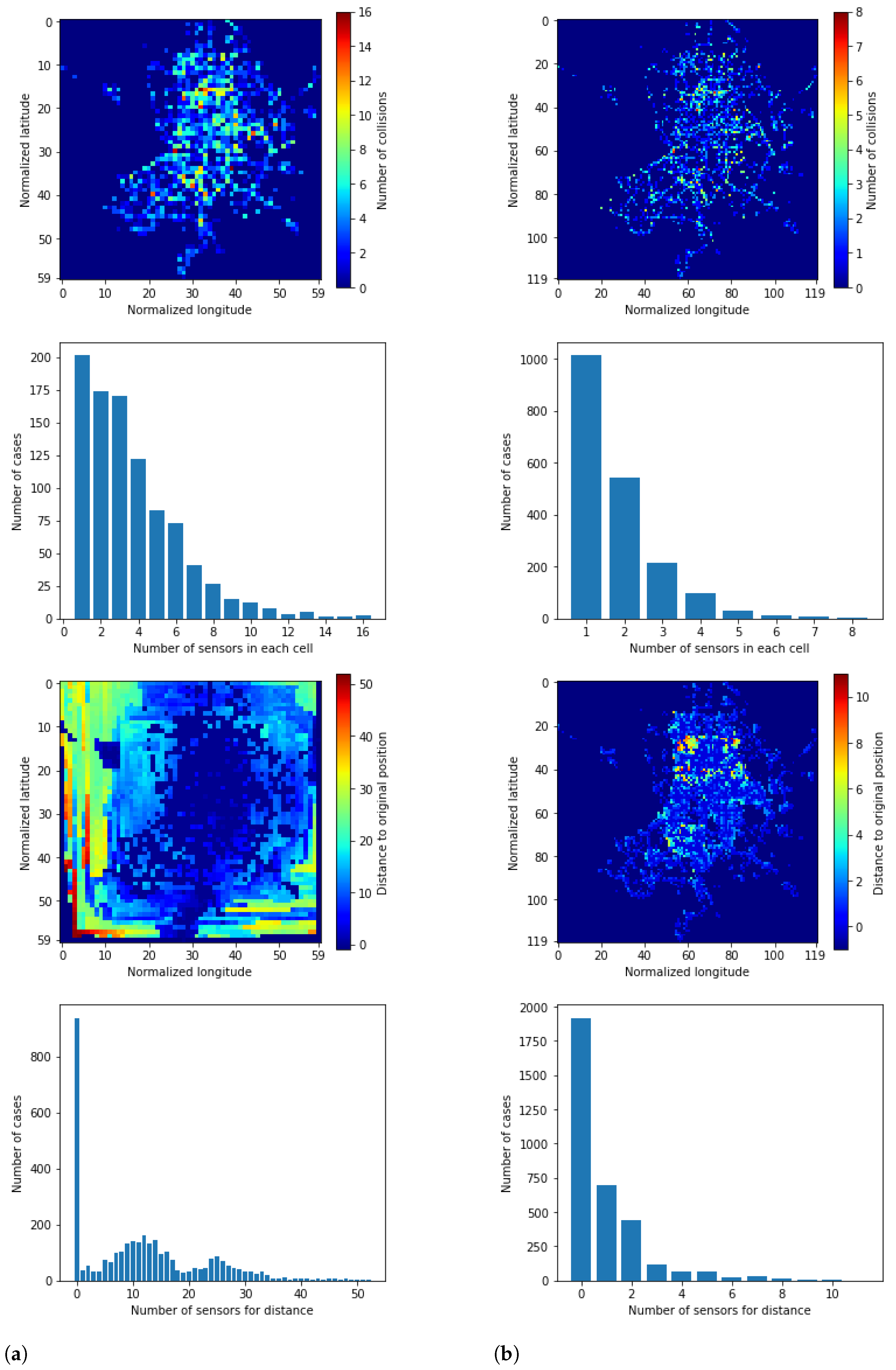
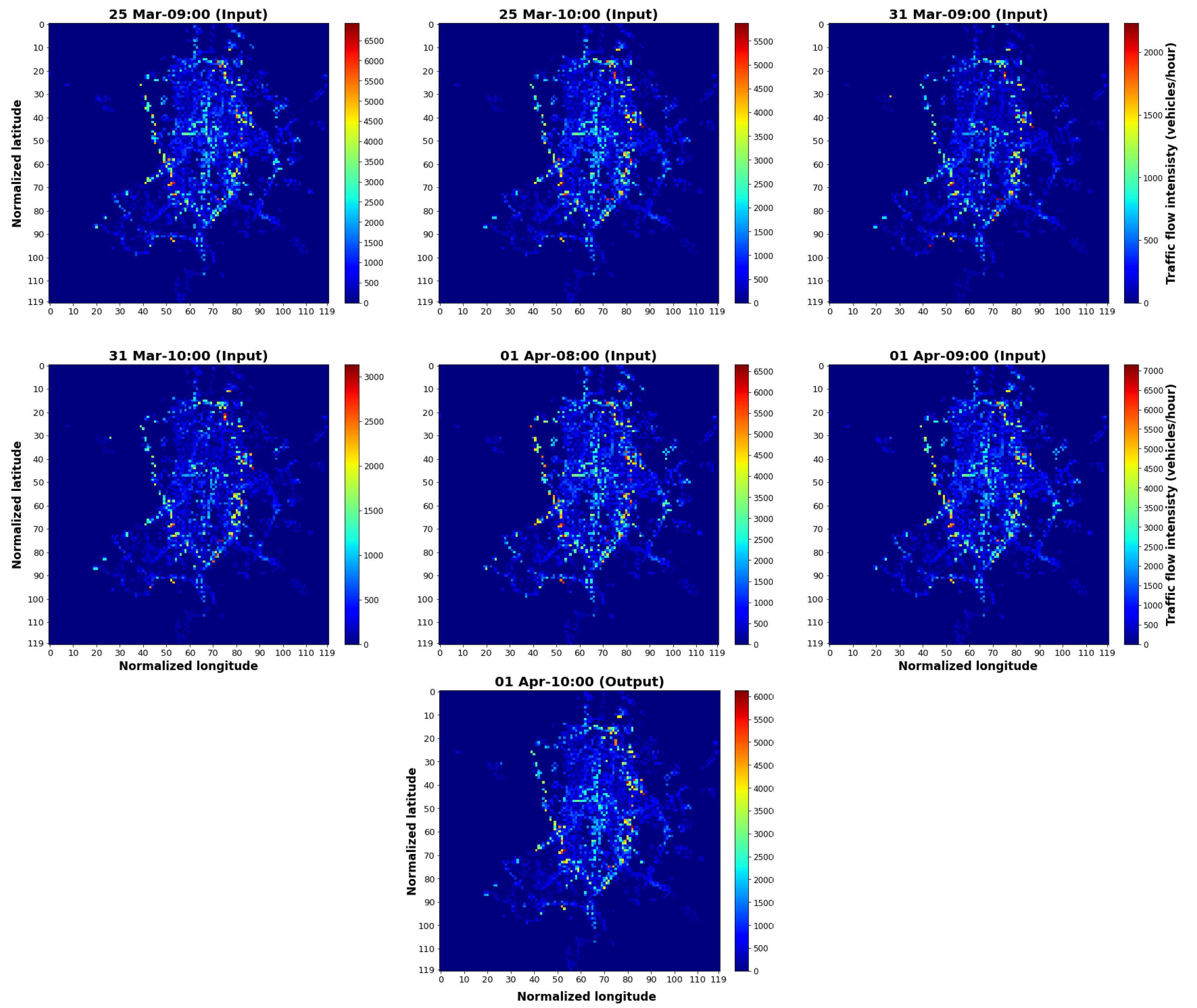
2.3.1. Data Preparation
| Algorithm 1: Algorithm that searches for an empty cell near a given position. |
 |
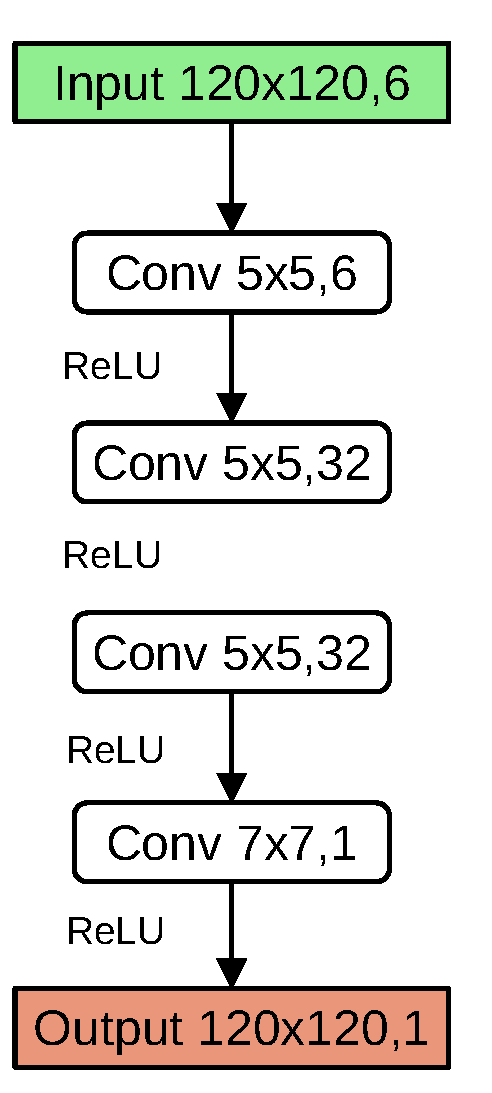
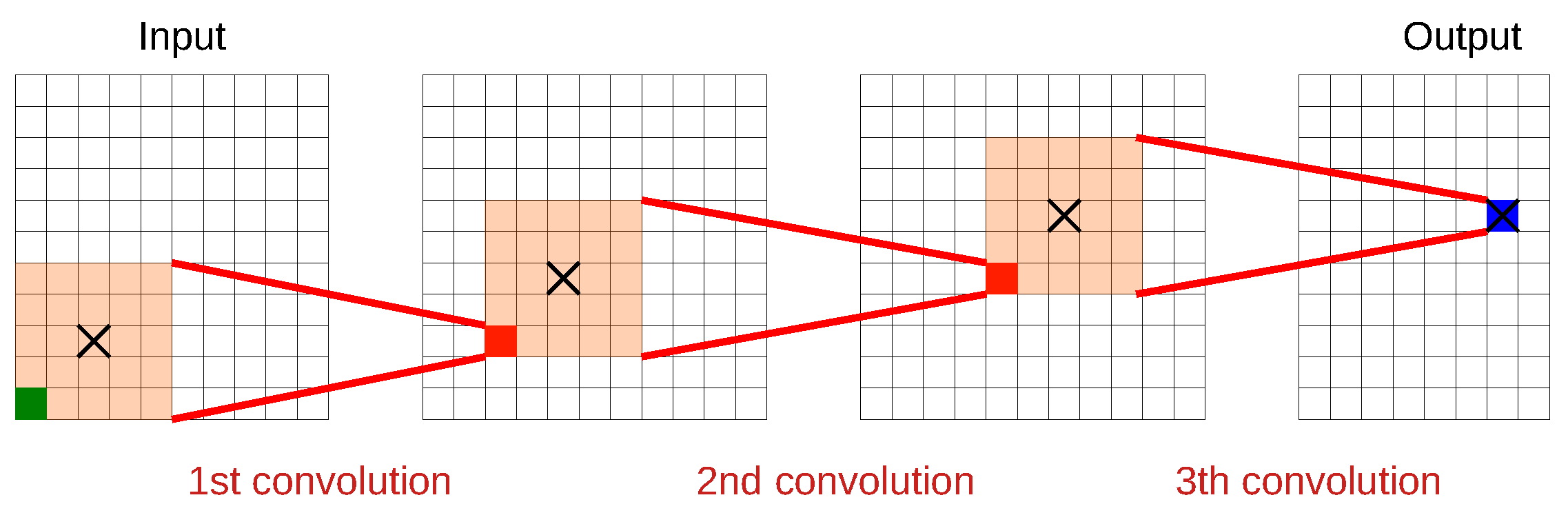
2.3.2. Preliminary Visual Model: Regression CNN
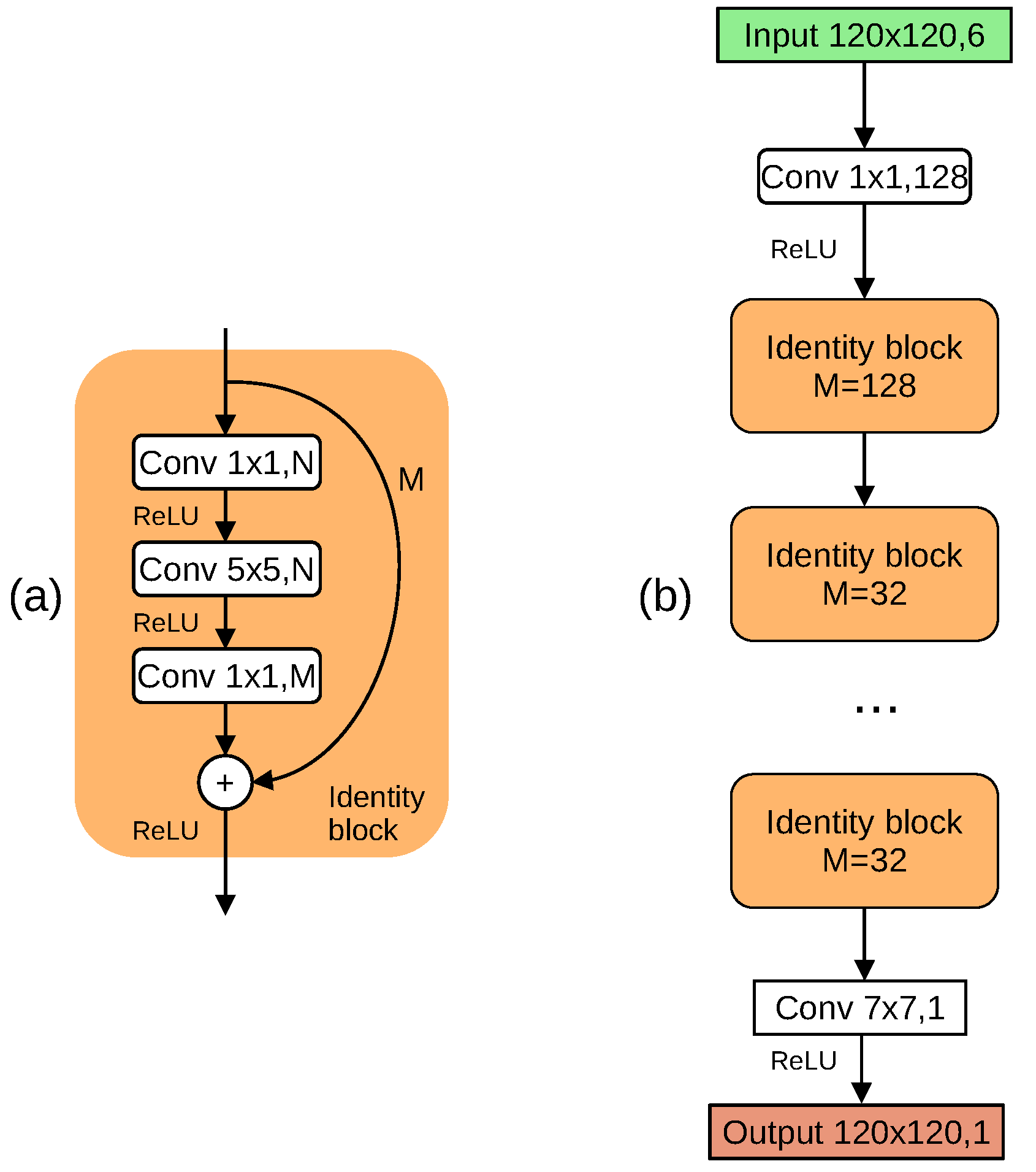
2.3.3. Regression ResNet Model
2.4. Performance Indexes
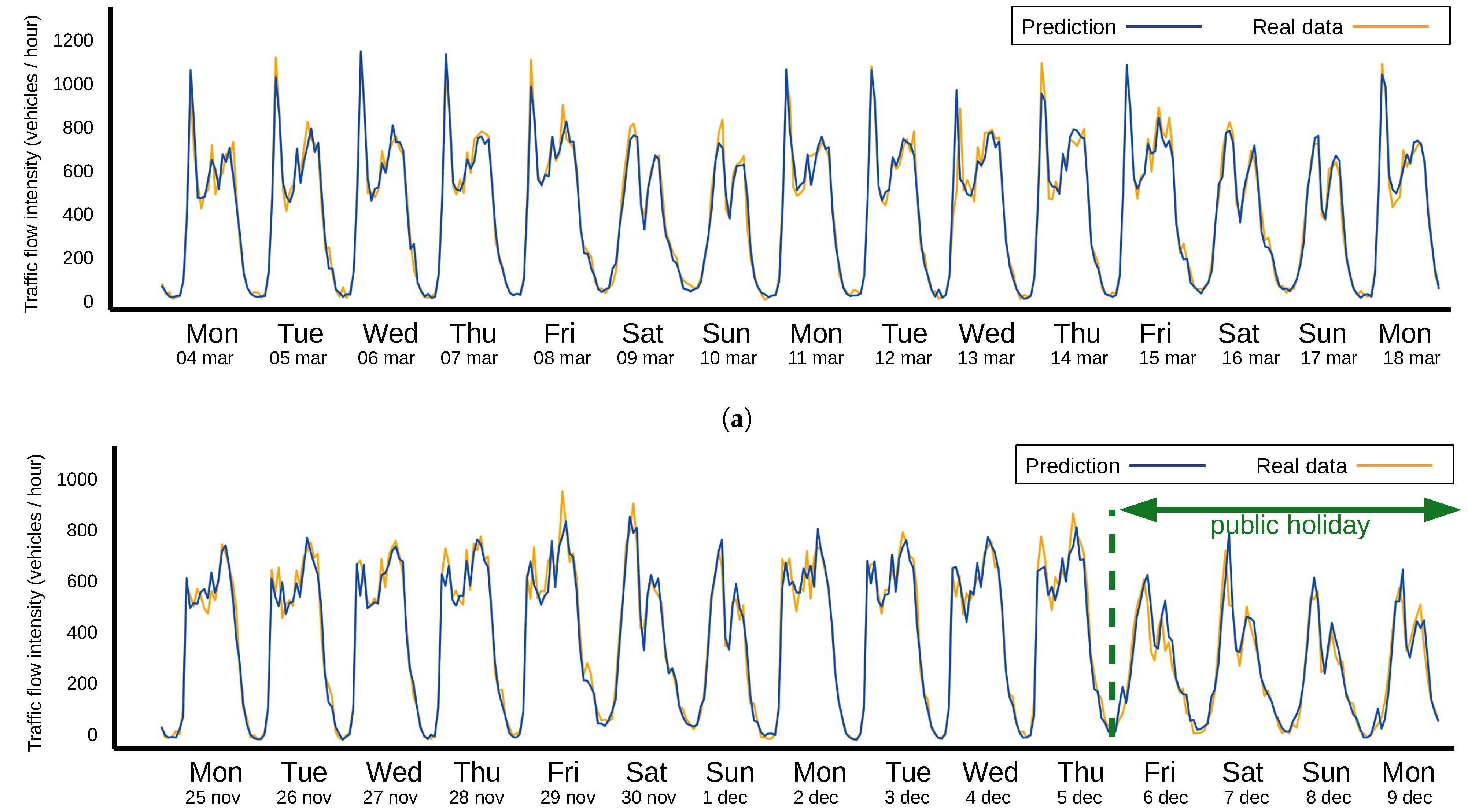
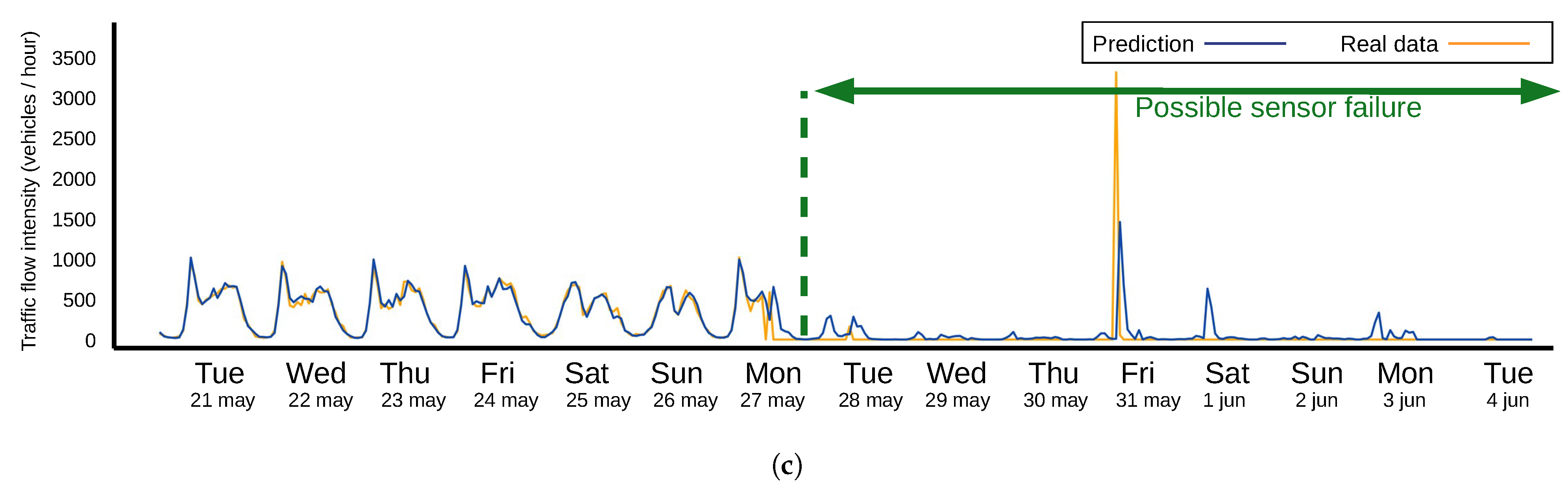
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, W.; Zhang, H.; Li, T.; Guo, J.; Huang, W.; Wei, Y.; Cao, J. An interpretable model for short term traffic flow prediction. Math. Comput. Simul. 2020, 171, 264–278. [Google Scholar] [CrossRef]
- Zhou, F.; Li, L.; Zhang, K.; Trajcevski, G. Urban flow prediction with spatial–temporal neural ODEs. Transp. Res. Part Emerg. Technol. 2021, 124, 102912. [Google Scholar] [CrossRef]
- Liu, T.; Wu, W.; Zhu, Y.; Tong, W. Predicting taxi demands via an attention-based convolutional recurrent neural network. Knowl. Based Syst. 2020, 206, 106294. [Google Scholar] [CrossRef]
- Zhang, C.; Zhu, F.; Wang, X.; Sun, L.; Tang, H.; Lv, Y. Taxi Demand Prediction Using Parallel Multi-Task Learning Model. IEEE Trans. Intell. Transp. Syst. 2020, 1–10. [Google Scholar] [CrossRef]
- Zhang, D.; Xiao, F.; Shen, M.; Zhong, S. DNEAT: A novel dynamic node-edge attention network for origin-destination demand prediction. Transp. Res. Part Emerg. Technol. 2021, 122, 102851. [Google Scholar] [CrossRef]
- Qi, L.; Zhou, M.; Luan, W. A Two-level Traffic Light Control Strategy for Preventing Incident-Based Urban Traffic Congestion. IEEE Trans. Intell. Transp. Syst. 2018, 19, 13–24. [Google Scholar] [CrossRef]
- Afrin, T.; Yodo, N. A Probabilistic Estimation of Traffic Congestion Using Bayesian Network. Measurement 2021, 109051. [Google Scholar] [CrossRef]
- Dai, G.; Hu, X.; Ge, Y.; Ning, Z.; Liu, Y. Attention based simplified deep residual network for citywide crowd flows prediction. Front. Comput. Sci. 2021, 15, 152317. [Google Scholar] [CrossRef]
- Huang, C.; Zhang, C.; Zhao, J.; Wu, X.; Chawla, N.; Yin, D. MiST: A Multiview and Multimodal Spatial-Temporal Learning Framework for Citywide Abnormal Event Forecasting. In Proceedings of the International World Wide Web Conference, San Francisco, CA, USA, 13 May 2019; pp. 717–728. [Google Scholar]
- Ma, J.; Chan, J.; Ristanoski, G.; Rajasegarar, S.; Leckie, C. Bus travel time prediction with real-time traffic information. Transp. Res. Part Emerg. Technol. 2019, 105, 536–549. [Google Scholar] [CrossRef]
- Xu, S.; Zhang, R.; Cheng, W.; Xu, J. MTLM: A multi-task learning model for travel time estimation. GeoInformatica 2020. [Google Scholar] [CrossRef]
- Abdollahi, M.; Khaleghi, T.; Yang, K. An integrated feature learning approach using deep learning for travel time prediction. Expert Syst. Appl. 2020, 139, 112864. [Google Scholar] [CrossRef]
- Vijayalakshmi, B.; Ramar, K.; Jhanjhi, N.; Verma, S.; Kaliappan, M.; Vijayalakshmi, K.; Vimal, S.; Ghosh, U. An attention-based deep learning model for traffic flow prediction using spatiotemporal features towards sustainable smart city. Int. J. Commun. Syst. 2021, 34, e4609. [Google Scholar] [CrossRef]
- Hosseini, M.K.; Talebpour, A. Traffic Prediction using Time-Space Diagram: A Convolutional Neural Network Approach. Transp. Res. Rec. 2019, 2673, 425–435. [Google Scholar] [CrossRef]
- Chen, L.; Zheng, L.; Yang, J.; Xia, D.; Liu, W. Short-term traffic flow prediction: From the perspective of traffic flow decomposition. Neurocomputing 2020, 413, 444–456. [Google Scholar] [CrossRef]
- Chen, D.; Hu, F.; Nian, G.; Yang, T. Deep Residual Learning for Nonlinear Regression. Entropy 2020, 22, 193. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lathuilière, S.; Mesejo, P.; Alameda-Pineda, X.; Horaud, R. A Comprehensive Analysis of Deep Regression. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2065–2081. [Google Scholar] [CrossRef] [Green Version]
- Huang, W.; Jia, W.; Guo, J.; Williams, B.M.; Shi, G.; Wei, Y.; Cao, J. Real-Time Prediction of Seasonal Heteroscedasticity in Vehicular Traffic Flow Series. IEEE Trans. Intell. Transp. Syst. 2018, 19, 3170–3180. [Google Scholar] [CrossRef]
- Wang, Y.; Li, L.; Xu, X. A Piecewise Hybrid of ARIMA and SVMs for Short-Term Traffic Flow Prediction. In Neural Information Processing; Liu, D., Xie, S., Li, Y., Zhao, D., El-Alfy, E.S.M., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 493–502. [Google Scholar]
- Chi, Z.; Shi, L. Short-Term Traffic Flow Forecasting Using ARIMA-SVM Algorithm and R. In Proceedings of the 2018 5th International Conference on Information Science and Control Engineering (ICISCE), Zhengzhou, China, 20–22 July 2018; pp. 517–522. [Google Scholar]
- Polson, N.G.; Sokolov, V.O. Deep learning for short-term traffic flow prediction. Transp. Res. Part Emerg. Technol. 2017, 79, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Tealab, A. Time series forecasting using artificial neural networks methodologies: A systematic review. Future Comput. Inform. J. 2018, 3, 334–340. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Gers, F.A.; Schmidhuber, E. LSTM recurrent networks learn simple context-free and context-sensitive languages. IEEE Trans. Neural Netw. 2001, 12, 1333–1340. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Graves, A.; Schmidhuber, J. Offline Handwriting Recognition with Multidimensional Recurrent Neural Networks. In Advances in Neural Information Processing Systems; Koller, D., Schuurmans, D., Bengio, Y., Bottou, L., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2009; Volume 21, pp. 545–552. [Google Scholar]
- Lv, Y.; Duan, Y.; Kang, W.; Li, Z.; Wang, F. Traffic Flow Prediction With Big Data: A Deep Learning Approach. IEEE Trans. Intell. Transp. Syst. 2015, 16, 865–873. [Google Scholar] [CrossRef]
- Zhao, X.; Gu, Y.; Chen, L.; Shao, Z. Urban Short-Term Traffic Flow Prediction Based on Stacked Autoencoder. In Proceedings of the CICTP 2019, Nanjing, China, 6–8 July 2019; pp. 5178–5188. [Google Scholar]
- Zhao, Z.; Chen, W.; Wu, X.; Chen, P.C.Y.; Liu, J. LSTM network: A deep learning approach for short-term traffic forecast. IET Intell. Transp. Syst. 2017, 11, 68–75. [Google Scholar] [CrossRef] [Green Version]
- Fu, R.; Zhang, Z.; Li, L. Using LSTM and GRU neural network methods for traffic flow prediction. In Proceedings of the 2016 31st Youth Academic Annual Conference of Chinese Association of Automation (YAC), Wuhan, China, 11–13 November 2016; pp. 324–328. [Google Scholar]
- Liu, Y.; Zheng, H.; Feng, X.; Chen, Z. Short-term traffic flow prediction with Conv-LSTM. In Proceedings of the 2017 9th International Conference on Wireless Communications and Signal Processing (WCSP), Nanjing, China, 11–13 October 2017; pp. 1–6. [Google Scholar]
- Huang, W.; Song, G.; Hong, H.; Xie, K. Deep Architecture for Traffic Flow Prediction: Deep Belief Networks With Multitask Learning. IEEE Trans. Intell. Transp. Syst. 2014, 15, 2191–2201. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 30 June 2016; pp. 770–778. [Google Scholar]
- Tian, Y.; Zhang, K.; Li, J.; Lin, X.; Yang, B. LSTM-based traffic flow prediction with missing data. Neurocomputing 2018, 318, 297–305. [Google Scholar] [CrossRef]
- Liang, Y.; Ouyang, K.; Jing, L.; Ruan, S.; Liu, Y.; Zhang, J.; Rosenblum, D.S.; Zheng, Y. UrbanFM: Inferring Fine-Grained Urban Flows. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ’19), Anchorage, AK, USA, 4–8 August 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 3132–3142. [Google Scholar]
- Zhang, J.; Zheng, Y.; Sun, J.; Qi, D. Flow Prediction in Spatio-Temporal Networks Based on Multitask Deep Learning. IEEE Trans. Knowl. Data Eng. 2020, 32, 468–478. [Google Scholar] [CrossRef]
- Liu, Q.; Wu, S.; Wang, L.; Tan, T. Predicting the next Location: A Recurrent Model with Spatial and Temporal Contexts. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence (AAAI’16), Phoenix, AZ, USA, 12–17 February 2016; pp. 194–200. [Google Scholar]
- Feng, J.; Li, Y.; Zhang, C.; Sun, F.; Meng, F.; Guo, A.; Jin, D. DeepMove: Predicting Human Mobility with Attentional Recurrent Networks. In Proceedings of the 2018 World Wide Web Conference, International World Wide Web Conferences Steering Committee: Republic and Canton of Geneva, CHE (WWW ’18), Geneva, Switzerland, 3–5 June 2018; pp. 1459–1468. [Google Scholar]
- Gao, Q.; Zhou, F.; Trajcevski, G.; Zhang, K.; Zhong, T.; Zhang, F. Predicting Human Mobility via Variational Attention. In Proceedings of the The World Wide Web Conference (WWW ’19), San Francisco, CA, USA, 13–17 May 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 2750–2756. [Google Scholar]
- Abadi, A.; Rajabioun, T.; Ioannou, P.A. Traffic Flow Prediction for Road Transportation Networks With Limited Traffic Data. IEEE Trans. Intell. Transp. Syst. 2015, 16, 653–662. [Google Scholar] [CrossRef]
- Alghamdi, T.; Elgazzar, K.; Bayoumi, M.; Sharaf, T.; Shah, S. Forecasting Traffic Congestion Using ARIMA Modeling. In Proceedings of the 2019 15th International Wireless Communications Mobile Computing Conference (IWCMC), Tangier, Morocco, 24–28 June 2019; pp. 1227–1232. [Google Scholar]
- Box, G.; Jenkins, G.M. Time Series Analysis: Forecasting and Control; Holden-Day: San Francisco, CA, USA, 1976. [Google Scholar]
- LeCun, Y.; Haffner, P.; Bottou, L.; Bengio, Y. Object Recognition with Gradient-Based Learning. In Shape, Contour and Grouping in Computer Vision; Springer: Berlin/Heidelberg, Germany, 1999; p. 319. [Google Scholar]
- Lindgren, F.; Rue, H.; Lindström, J. An explicit link between Gaussian fields and Gaussian Markov random fields: The stochastic partial differential equation approach. J. R. Stat. Soc. Ser. Stat. Methodol. 2011, 73, 423–498. [Google Scholar] [CrossRef] [Green Version]
- Rue, H.; Martino, S.; Chopin, N. Approximate Bayesian inference for latent Gaussian models by using integrated nested Laplace approximations. J. R. Stat. Soc. Ser. B 2009, 71, 319–392. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Details | Results | |||
|---|---|---|---|---|
| Model | Parameters | MAE | MAPE | SMAPE |
| ARIMA | 27,200 | 40.85 | 20.00% | 9.50% |
| ARIMA () | 40,800 | 40.45 | 19.81% | 9.35% |
| ARIMA () | 54,400 | 40.22 | 19.75% | 9.33% |
| ARIMA () | 69,000 | 40.11 | 19.78% | 9.35% |
| CNN () | 7169 | 51.65 | 22.79% | 11.82% |
| CNN () | 154,753 | 51.52 | 22.62% | 11.56% |
| CNN () | 302,337 | 50.98 | 22.45% | 11.21% |
| ResNet () | 109,601 | 38.93 | 18.75% | 9.35% |
| ResNet () | 262,049 | 37.92 | 18.22% | 8.29% |
| ResNet () | 482,465 | 39.65 | 19.08% | 9.16% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vélez-Serrano, D.; Álvaro-Meca, A.; Sebastián-Huerta, F.; Vélez-Serrano, J. Spatio-Temporal Traffic Flow Prediction in Madrid: An Application of Residual Convolutional Neural Networks. Mathematics 2021, 9, 1068. https://doi.org/10.3390/math9091068
Vélez-Serrano D, Álvaro-Meca A, Sebastián-Huerta F, Vélez-Serrano J. Spatio-Temporal Traffic Flow Prediction in Madrid: An Application of Residual Convolutional Neural Networks. Mathematics. 2021; 9(9):1068. https://doi.org/10.3390/math9091068
Chicago/Turabian StyleVélez-Serrano, Daniel, Alejandro Álvaro-Meca, Fernando Sebastián-Huerta, and Jose Vélez-Serrano. 2021. "Spatio-Temporal Traffic Flow Prediction in Madrid: An Application of Residual Convolutional Neural Networks" Mathematics 9, no. 9: 1068. https://doi.org/10.3390/math9091068