1. Introduction
Leakages in water distribution networks can cause great cumulative losses as small leakages can remain undetected for long periods of time. Direct losses are typically followed by the overall reduction of the functionality of the water distribution network, which usually manifests as a pressure drop on the user end. Moreover, leakages can potentially cause health hazards since microbiological contamination can enter the water distribution network and reach end users. Porous soil introduces additional difficulties, as even greater leakages can remain undetected since water is absorbed in the soil, and there is no evidence of the leakage on the surface. Thus, different technologies and methodologies have been proposed for leakage detection and localization. In a work by Jacobsz and Jahnke [
1], leak detection using discrete fiber optic sensing was investigated. In a recent study by Nkemeni et al. [
2], a wireless sensor network application was investigated, where processing for leak detection is performed at the sensor nodes. In a work by Wu et al. [
3], a two-stage method was proposed, which first detects outliers from flow measurements using a clustering algorithm and then detects whether burst occurred. In the work of Rajeswaran et al. [
4], a multi-stage graph partitioning algorithm was presented, which uses flow measurements to indicate a minimum number of additional measuring locations needed to narrow down leak location in large-size networks. In the work by Cody et al. [
5], a linear prediction signal processing technique was used to extract features from acoustic data, which can detect and localize pipe leaks. In a work by Bohorquez et al. [
6], an artificial neural network was applied to detect leak size and location in a single water pipeline.
Problems with leak detection and localization in pipelines that are used for transportation of hydrocarbon fluids are also extensively explored, since leaks can cause serious damage to people and the environment due to often hazardous fluid that is transported. A number of investigations were conducted, including a data-driven approach using the Kantorovich distance [
7], feature extraction from acoustic signals [
8], application of a least squares twin support vector machine [
9], and a multi-layer perceptron neural network (MLPNN) [
10]. A detailed overview of leak detection technologies in pipelines can be found in a review paper by Adegboye et al. [
11].
Additionally, a number of studies considered strategies for optimal sensor placement since it greatly influences leak detection and localization methods efficiency. The optimization approach is most widely used, and thus different enhancements were considered, such as a clustering process prior to optimization [
12], hybrid feature selection method [
13], methods that reduce the optimization search space [
14], and an investigation of the influence of measurement uncertainty [
15]. A detailed overview of leakage detection methodologies can be found in review papers by Wu and Liu [
16], Chan et al. [
17], and Zaman et al. [
18].
Software-based leakage detection methods can be divided into transient-based, model-based, and data-driven approaches. The transient-based approach is based on various analyses of pressure signals; the model-based approach analyzes residuals, i.e., compares pressure measurements with the pressure estimation based on a hydraulic network model; and the data-driven approach relies on collected data and mathematical operations in order to determine anomalies in pressure. In recent years, machine learning methods have been increasingly used for leakage detection and localization. Zhou et al. [
19] and Pérez-Pérez et al. [
20] investigated leak detection in a single pipeline. In the Zhou et al. [
19]’s work, a convolutional neural network (CNN) was used to pinpoint leak locations in a 1500 m long pipe segment for different leak sizes, where the better prediction was obtained for greater leakages. Pérez-Pérez et al. [
20] used a combined artificial neural network (ANN), where the ANN is first used to estimate the friction factor of the pipe and then to localize leak location. Tests were conducted for a 64.48 m pipe, for which it was reported that an average percentage error of 0.47% was achieved. Mounce et al. [
21] proposed a system using an artificial neural network for online detection of bursts in water distribution networks that was shown to have 44% of alarms when burst really occurred, 32% of alarms in cases of unusual short-term increased demand, 9% of alarms due to industrial events and only 15% were false alarms, indicating the applicability of the proposed method. In the work of Jensen et al. [
22], a sensitivity analysis of pressure residuals was performed to isolate possible leakage locations. The proposed methodology was applied to the actual water distribution network, where only a few false alarms occurred, and frequent alarms occured during the leakage. It was observed that the proposed methodology can isolate a limited set of candidate nodes, where better performance was observed for greater flows in the system. In the work of Zhang et al. [
23], a data-driven and model-based approach was utilized, where large-scale water distribution networks were divided into leakage zones that were categories for multi-class support vector machine prediction. Large-scale networks were divided into up to 25 zones, with a classification accuracy of above 90% for a division into 25 zones, which further increased with smaller divisions into leakage zones. However, it must be taken into consideration that further leak localization needs to be conducted after the leak zone is determined to provide the exact leak location. Soldevila et al. [
24] used a mixed model-based and data-driven approach in which the K-nearest neighbors (k-NN) algorithm is used to localize leaks. The proposed methodology was applied to three different sized networks, with leak, demand, and sensor measurement uncertainties. For the Hanoi benchmark network, for all considered uncertainties in the study, an accuracy greater than 90% was reported for the time horizon of one day using pressure sensor measurements from two sensors. Additionally, some network nodes were grouped since leaks from those nodes cannot be distinguished due to similar pressure measurements. Further study was presented by Soldevila et al. [
25], where Bayesian classifiers were applied and greater accuracy than when using a k-NN approach was obtained. Both proposed methods were successfully applied to real water distribution network case studies where leak locations detected by the proposed methods were in the vicinity of the real leak locations. In the work of Quinones-Grueiro et al. [
26], an unsupervised approach to leak detection was conducted for the Hanoi distribution network using three pressure sensors, where the average reported classification accuracy was 85% for leak magnitudes smaller than 2.5% of the total demand of the network for leaks detected within a time interval of one day. In the work of Zhou et al. [
27], after the burst was detected, additional pressure sensors were placed at optimal locations and deep learning was employed to identify burst locations. The proposed methodology was applied to 58 synthetic burst cases, where in 57 cases the top five most probable pipes were correctly identified, and in 37 cases the top pipe was correctly located. However, it must be noted that the requirement for additional measurements can extend reaction time in case of a pipe burst. In the work of Sun et al. [
28], a classification approach was utilized where pressure measurements in network nodes with no pressure sensors were estimated using the Kriging method. The Hanoi water distribution network was considered with a wide range of sensors, and it was reported that in the average case 70% accuracy was achieved; however, for some sensor layouts the reported accuracy was below 20%, which is believed to be due to the Kriging interpolation error. Javadiha et al. [
29] used a convolutional neural network with pressure measurements for the Hanoi network, where for a one day time horizon the model accuracy varied from 56% for four sensors to 94% for 12 sensors considering leak size uncertainty, sensor noise, and base demand uncertainty. The Kriging method was also used in work by Soldevila et al. [
30] with satisfactory leak localization in a real water distribution network case; however, when compared with their previous work, the Kriging method did not provide better results.
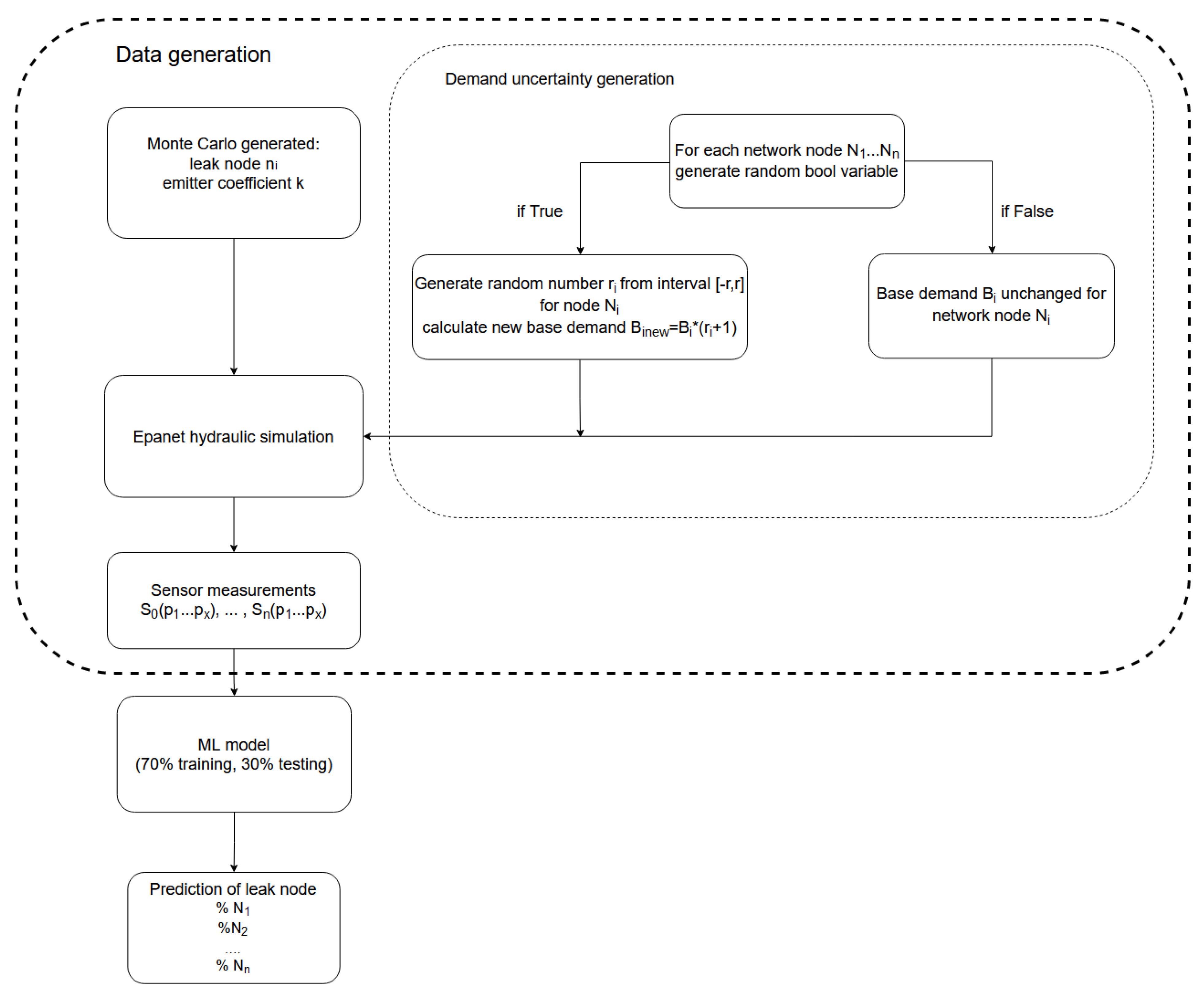
The main drawback of the machine learning approach is that only a small amount of real data measurements can be obtained for leak events. Additionally, when a new installation is made in the water distribution network, all previous records are not valid, consequently reducing the number of inputs for the prediction model. This is a common problem in rapidly developing urban areas. Thus, in this paper, a machine learning approach is presented, in which a great number of leak scenarios for randomly chosen network nodes and with different leak sizes under different demand conditions were conducted, to obtain a database of pressure sensor measurements that are inputs for the prediction model. This idea is similar to that proposed by Grbčić et al. [
31] and Lučin et al. [
32], where a number of Monte Carlo simulations were conducted to obtain a large number of inputs for a machine learning prediction model that successfully detects the location of contamination source and determines the number of contamination sources. To the authors’ knowledge, the currently proposed methodology has not been previously applied to the leak localization problem to obtain a large amount of synthetic data.
Model-based methods’ accuracy is greatly dependent on model calibration, where model uncertainties can decrease the method’s efficiency. In this work, model uncertainties are taken into consideration by including randomness for leak and demand values, so as to describe as many possible combinations of different leak scenarios. Machine learning classification is then utilized to detect the most appropriate leak scenario, which will be utilized to determine leak location. A random forest classifier was tested for leak localization on two different sized benchmark networks. Investigation of the influence of sensor layout and number of sensors on model accuracy was conducted. Different prediction models were constructed for different sizes of leaks and for different ranges of demand uncertainty to estimate model accuracy. This approach allows for a large number of varying measurements to be simulated in a short amount of time, thus providing relatively quick localization, which is suitable for use in real conditions. Additional model uncertainties such as pipe diameters, node elevations, etc. can easily be incorporated into the presented methodology.
The rest of the paper is organized as follows. In
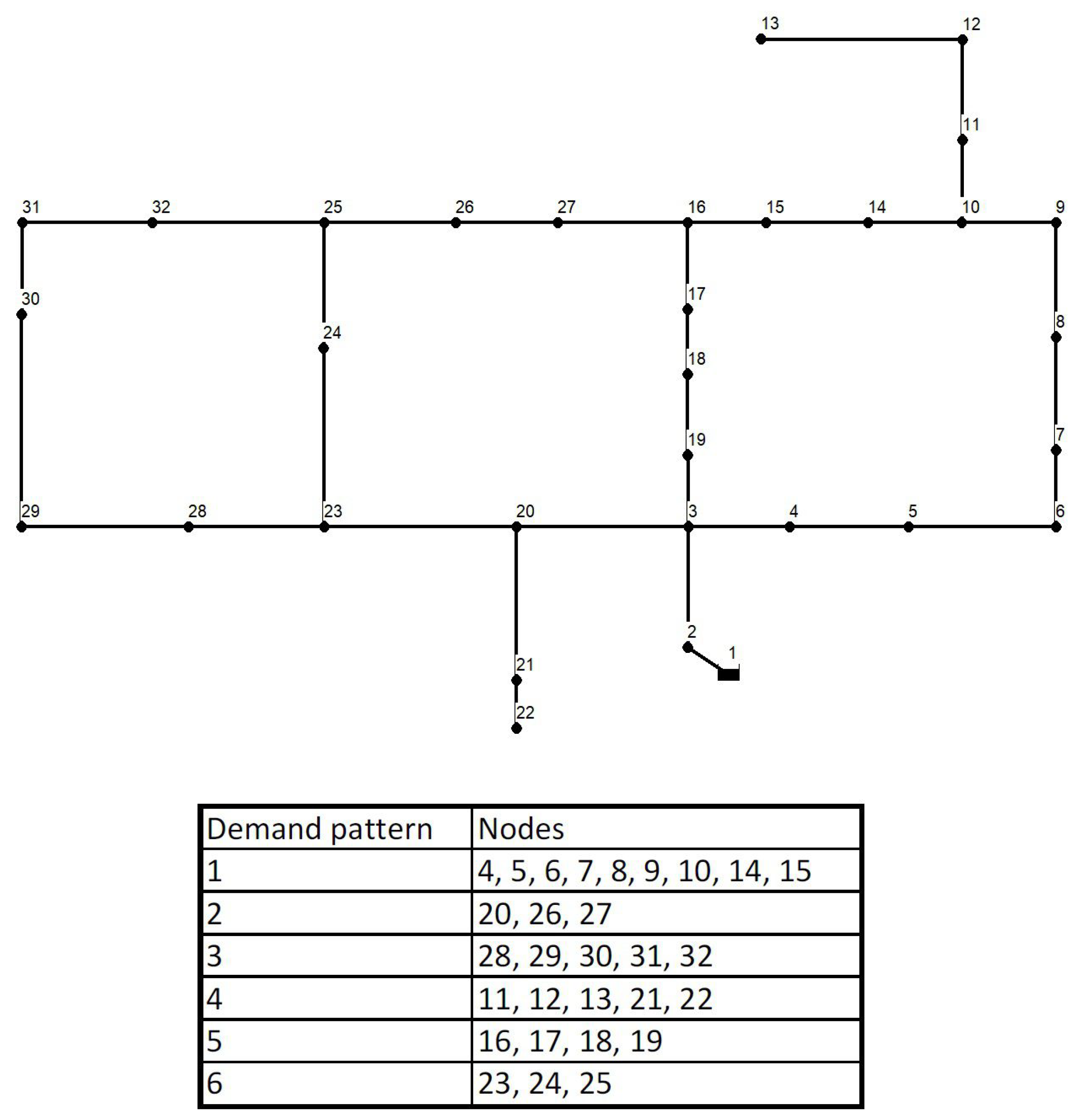
Section 2, the problem statement is defined with a description of the used benchmark water distribution networks and a description of the proposed methodology using a random forest classifier. In
Section 3, results are presented for both benchmark networks investigating the influence of a different number of prediction model inputs and features, of different ranges of demand uncertainties and leak sizes, and of sensor layout on model accuracy. Additionally, an example of the application of the prediction model is presented. In
Section 4, the main observations regarding the obtained results are presented with proposed further research. In
Section 5, final remarks are presented.
4. Discussion
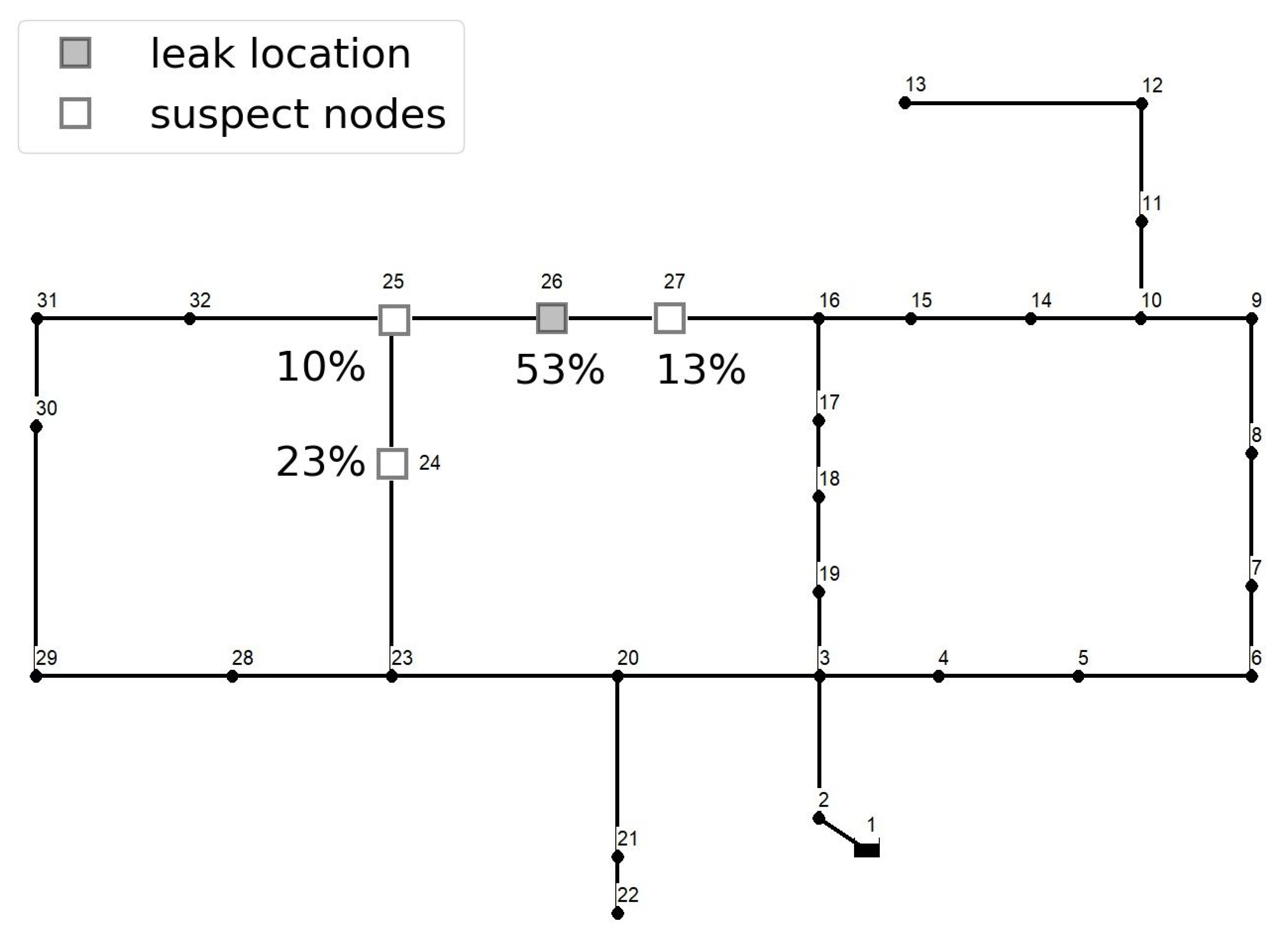
Based on the presented results, it can be concluded that the proposed methodology can be successfully applied to small-sized and medium-sized networks. With the increase in network size, model accuracy considerably decreases. It is important to note, however, that this behavior is not unexpected as the same assumptions and amount of data (i.e., inputs) are utilized for small and larger cases. Despite this, meaningful results and adequate localization can be achieved when the top three and five network nodes based on leak location probability are considered. This indicates that leak nodes can be localized on a more general water distribution network with one prediction model, where exact location can be detected if coupled with another prediction model that focuses on a specific network zone or employs a different leak localization methodology. Both approaches should be further investigated.
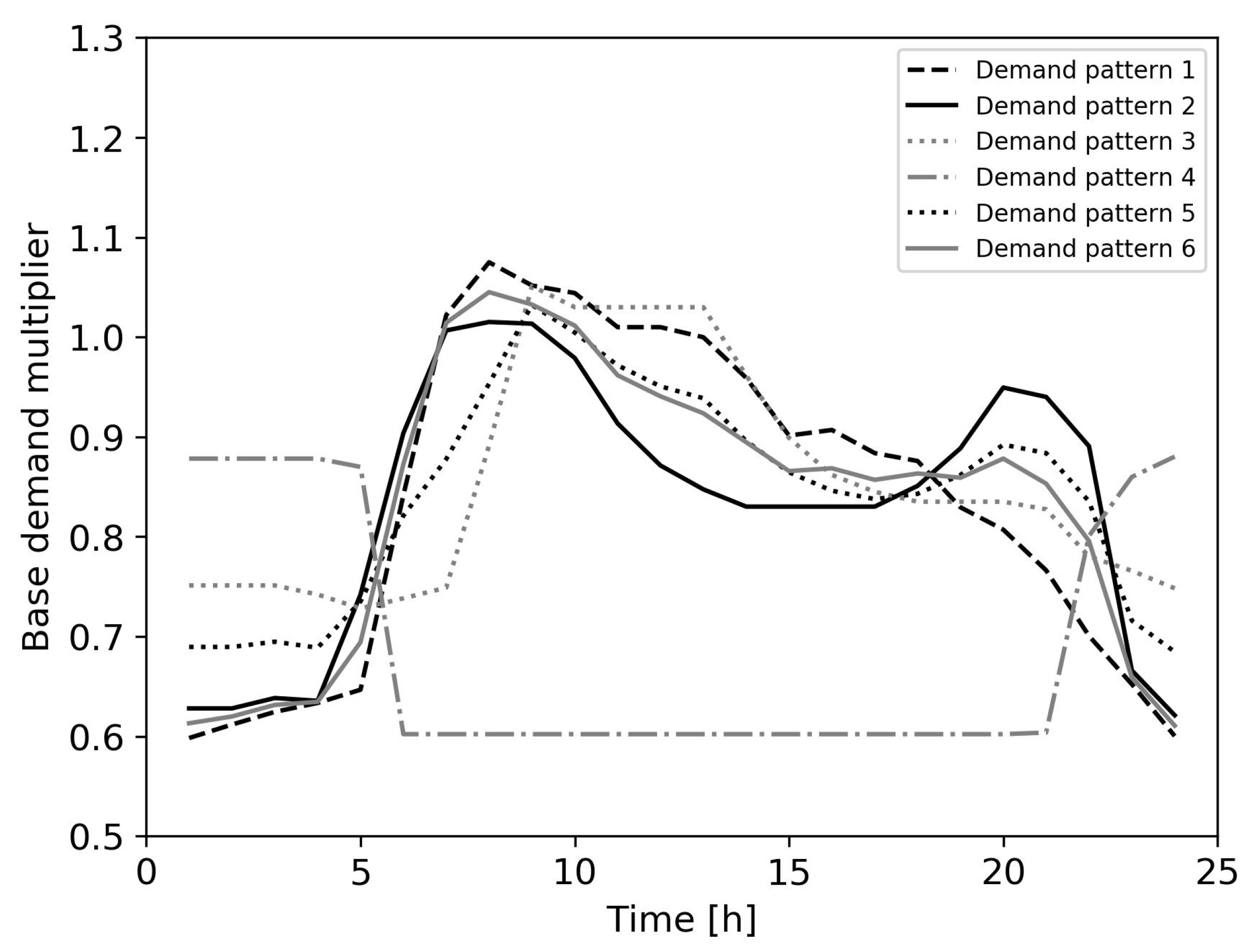
It can be observed that the greatest accuracy was achieved for prediction models trained with smaller demand variation and greater leak coefficients. This is expected since in the case of no demand variation, 500,000 simulations provide a considerable amount of combinations of leak events, where the prediction model simply chooses from the most similar event. When demand variation is introduced, model accuracy decreases as the demand variation range increases. However, several prediction models can be constructed with different demand patterns, e.g., a night demand model, a workday demand model, etc., where in case of a leak event, the prediction model with the most similar demand pattern can be chosen for leak localization. When considering leak coefficients, independent prediction models can also be built; for example, prediction models to detect small, medium, and large leaks. The greatest accuracy is achieved for the large leaks, which can be greatly beneficial in the case of large bursts in the water distribution network. This kind of events needs quick intervention since the water supply to end users is usually interrupted until the burst is repaired. A prediction model can indicate leak location so rapid intervention can be achieved.
Another potential issue stems from the fact that the calibrated model relies on data that might already incorporate leaks. Consequently, predominantly new leaks can be predicted, as existing leaks are incorporated in the calibrated model itself. As existing leaks become larger with time and due to the material deterioration, older leak locations can eventually be detected as well, although they would appear as a comparatively smaller leak than they actually are; this is not a crucial problem, however. This drawback can be mitigated by coupling or employing as standalone older calibrated models that predate the current one.
The study of the influence of the report time step indicates that with a smaller amount of features, similar accuracy can be achieved, and thus a greater number of inputs can be considered to achieve better model accuracy. The optimum number of features and inputs should be further investigated to provide the best accuracy and model complexity ratio. This is especially important if the proposed methodology is to be used on more complex water distribution networks. This approach is valid if existing leaks that are undetected for a longer period of time are to be found. However, in the case of a pipe burst event, the prediction model with a smaller time step should be considered to reduce reaction time in case of the event. This should be further investigated since larger pipe bursts considerably change water distribution network dynamics and the measurement period should be considerably smaller than one day (as is in the current paper) to provide rapid reaction. Additionally, techniques for data dimensionality reduction should be explored to possibly reduce the model complexity.
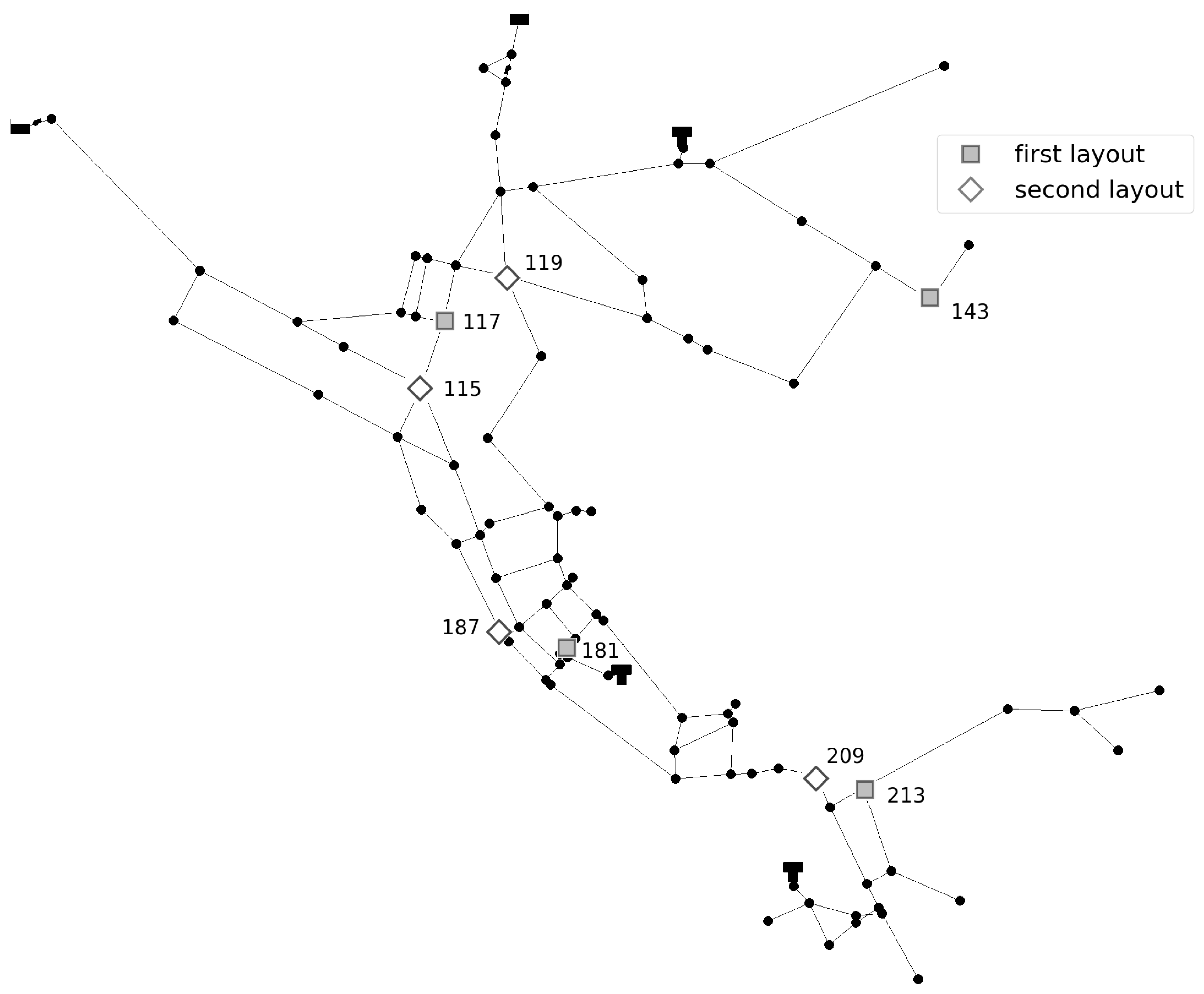
The sensor layouts considered in this paper can be considered sparse. Improvement in prediction model accuracy can be achieved if additional sensors are installed in the water distribution network. Additionally, a combination of pressure and flow sensors should be investigated since additional data could be beneficial to the model and water distribution networks have a combination of both types of sensors. Further study should be focused on investigating other classification models, for example K-NN and ANN, which were successfully applied in previous literature using model-based approaches, which could possibly provide greater model accuracy. The coupling of multiple prediction models should also be investigated, where one model would provide coarse leak localization and the second model would provide the exact location of the leak. Moreover, future studies should account for uncertainties such as pipe diameter and pipe roughness with the methodology tested on real water distribution networks.
Although computationally demanding, the proposed methodology with introduced randomness can successfully describe a wide range of operating conditions, thus providing a considerable amount of data that cannot be obtained from field measurements. With growing computational power, the proposed methodology could be successfully utilized, as once they are generated, prediction models can be employed to evaluate a network with a considerably lower amount of computational resources and time.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}