1. Introduction
There are many situations when one needs to discover a relationship between one or more independent variables, the inputs, and one real-valued dependent variable, i.e., the output—from data samples. This type of problem is known as regression, and a large number of algorithms have been proposed by researchers. Among the most popular ones, one can mention neural networks, support vector machine regression (ε-SVR, ν-SVR), decision trees (M5P, random forest, REPTree) or methods based on instances (k-nearest neighbor) or rules (M5, decision table).
The Large Margin Nearest Neighbor for Regression (LMNNR) algorithm [
1] has been used in several studies so far for a variety of applications and its performance has been compared to that of classic regression methods implemented in the popular collection of machine learning algorithms Weka [
2]. Thus, in [
1,
3], it was used for the prediction of corrosion resistance of some alloys containing titanium and molybdenum, widely used in dental applications. The material corrosion was quantified by the polarization resistance of the TiMo alloys.
The LMNNR algorithm was also applied in a different field, that of predicting students’ performance based on their active use of social media tools during the learning process [
4,
5]. The training data were collected over six winter semesters in consecutive years, from a total of 343 students. Almost 19,000 social media contributions were recorded and used to compute 14 numeric features for each student. Based on these, the final grade was predicted.
The results of LMNNR have been generally shown to be better than those of the other regression algorithms used for comparison. Although more variants for model training and model representation have been proposed, its main disadvantage is that its sensitivity to local optimal often requires multiple runs, and thus increases the training time.
In [
6], a modified nearest-neighbor regression method (kNN) is proposed for modeling the photocatalytic degradation of the Reactive Red 184 dye for which insufficient data are available. It can handle partial information without “filling in” additional computed values (mean values) or ignoring the incomplete instances. In the case of the photocatalytic degradation process, the kNN method recorded correlations of over 0.9.
A study based on an adaptive regression model appropriate for cases with insufficient or missing data was also performed in [
7]. Its aim was to investigate the electrochemical behavior of ZrTi alloys in artificial saliva. This method has only one internal parameter whose optimal value is found automatically.
The prediction of the sublimation rate of naphthalene in various working conditions was studied in [
8]. Different regression methods were applied and the performance of the original Large Margin Nearest Neighbor Regression algorithm (LMNNR) proved superior to those of other classical ones.
In the present study, three regression variants are applied for the free radical polymerization of methyl methacrylate (MMA) achieved in a batch bulk process. The first two variants are based on LMNNR trained either with an evolutionary algorithm or by gradient descent, where the derivatives are approximated by means of the central difference method. This is the first time that LMNNR has been applied for this process. Its difficulty is caused by the gel effect, corresponding to an abrupt conversion and molecular mass jump which may be missed by less accurate regression techniques. The third variant is a new, original algorithm named Nearest Neighbor Regression with Adaptive Distance Metrics Trained by Multiple Point Hill Climbing on Noisy Training Set Error (RADIAN) which is not based on the concept of a large margin but is inspired by denoising autoencoders used in deep learning [
9], where the input data are slightly corrupted, and the model is forced to learn the correct data from the corrupted version in order to prevent overfitting.
Regarding the results obtained for the polymerization of MMA with the above-mentioned methods, it is important to point out not only that they are very good, but also that they follow previous sustained efforts, made with different other methods whose results were inferior to those reported here.
2. Dataset
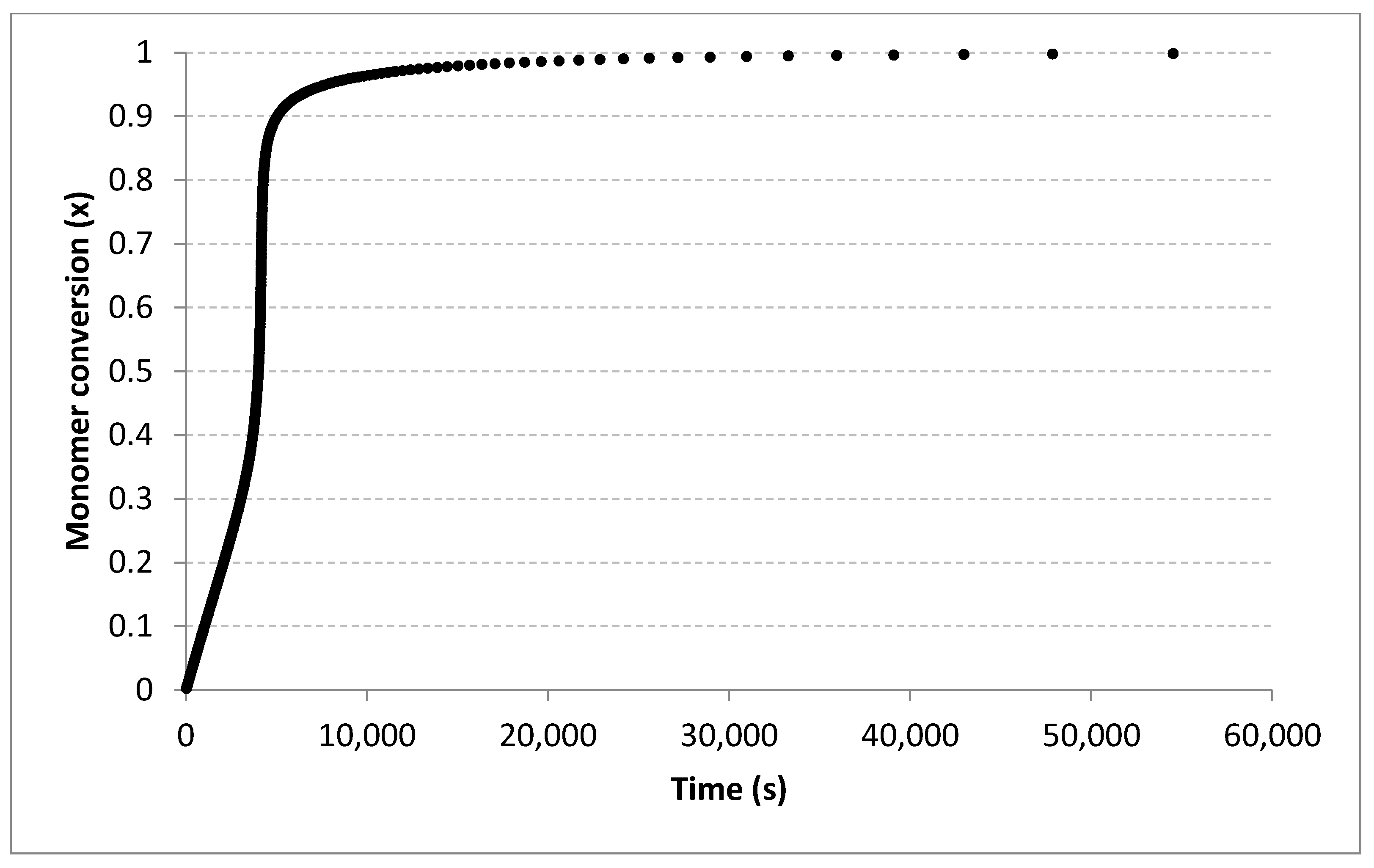
In order to test the functionality of the regression algorithms mentioned in the article, a real-world problem, namely the free radical polymerization of methyl methacrylate, was chosen as a case study. Two reasons justify this choice: the complexity of the process, so the difficulties in modeling and also the fact that our group has tried different modeling methods for this system, so that the obtained results can be compared with those reported in this paper.
Polymerization reactions present some difficulties in modeling and optimization actions, because of their specific features, as well as the general characteristics of the chemical processes. Reactions are complex and their mechanism is often not fully known. Developing accurate models implies precise knowledge of the phenomenology of the process, as well as of the physical and chemical laws that govern them. A series of approximations are often needed, influencing the accuracy of the model results. In addition, the complexity of the mathematical models causes supplementary difficulties regarding the solution mode and the time required for this operation, given the requirement of using the models in online optimal control procedures. Under these conditions, empirical models that use input–output data sets can be considered a preferable alternative to mechanistic models, both in terms of working methodology and the accuracy of results.
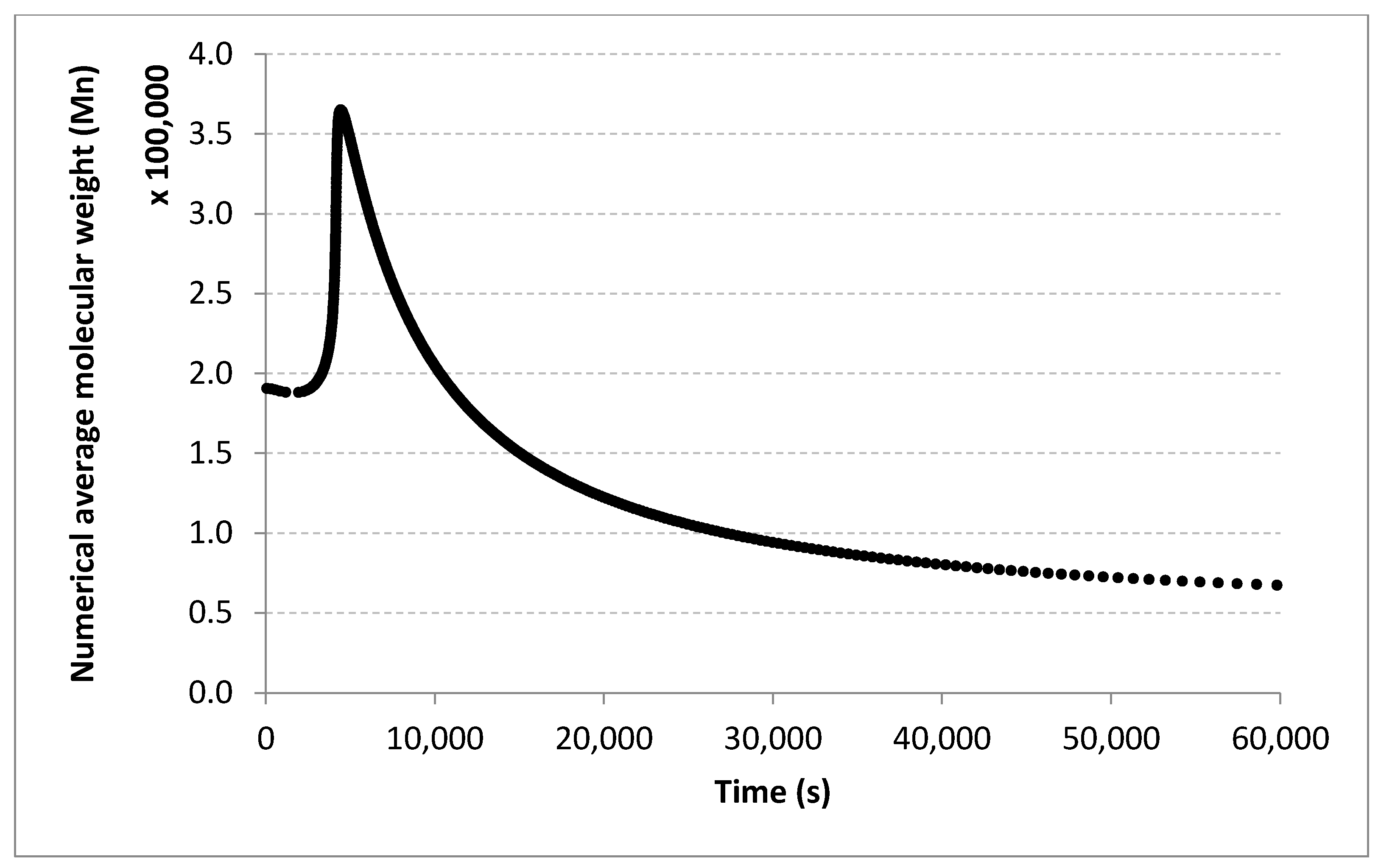
The free radical polymerization is characterized by diffusion-controlled effects. As the viscosity of the reaction mass increases, there is a sudden increase in the conversion and molecular masses, as a result of the diffusion difficulties encountered by the increasing macroradicals. The so-called glass and gel phenomena appear as a result of decreasing the values of the propagation and termination rate constants. The result of the manifestation of controlled diffusion phenomena is the end of polymerization reaction before the complete consumption of the reactants.
From the point of view of the modeling action, the diffusion-controlled effects are more difficult to model, especially since their phenomenology is not completely elucidated. Various models have been proposed, with a pronounced empirical character, e.g., [
10] or [
11], but their efficiency and application are limited. In addition, they have a pronounced empirical character, including many constants that can be determined by matching the experimental data, which means their dependence on each set of reaction conditions (temperature, concentrations of reactants etc.).
Some of the reasons listed above involve the need to apply modeling methods leading to better results, a variant being represented by neural networks, applied in the form of different methodologies. The following examples belong to our working group and have the role of justifying the new methodology described and applied in this paper and highlighting the results obtained, better than in the previous approaches. Therefore, several previous results will be presented.
The first series of attempts [
12,
13] implied the design of neural networks of feed-forward type, by the method of successive trials, to correlate the conversion and molecular masses with the reaction conditions. If satisfactory results were obtained for the conversion, for the molecular masses, especially for the average gravimetric molecular mass, the accuracy was below the minimum required. A more complex approach, which led to better results [
14] was based on combining a simplified phenomenological model with neural networks, obtaining hybrid models. Several modeling modalities were considered, namely the neural networks have replaced different parts of the model—in general the parts difficult to model due to diffusion-controlled phenomena. The results obtained were much better than the models represented by single neural networks, but also not very satisfactory for gravimetrical molecular weight.
Another example is represented by the use of a hybrid stacked recurrent neural model for a batch MMA polymerization reactor [
15]. Stacked recurrent neural networks are developed for modeling the gel effect, and they are associated with a simplified phenomenological model to obtain a complete model, improved in performance and robustness because of the multiple neural networks included in the model. The results are satisfactory, but there is still room for improvement.
Regarding the mentioned methods, their complexity should be noted, deriving from the need to determine optimal neural networks and their combination with other instruments.
4. Description of the Algorithms
4.1. Large Margin Nearest Neighbor Regression Trained with an Evolutionary Algorithm (LMNNR-EA)
The first method solves the problem defined by Equation (7) by means of an evolutionary algorithm. The advantages of applying an evolutionary algorithm for optimization is that prototypes, with different weight values, can be used instead of a single set of weights. The prototype positions are precomputed using the k-means algorithm. Since the resulting clusters tend to be (hyper-)spherical, the method is suitable for the complex problems addressed, as the distances are computed with different variants of Euclidean metrics.
4.2. Large Margin Nearest Neighbor Regression Trained with Approximate Gradient Descent (LMNNR-AGD)
Gradient descent optimization is a more-or-less de facto standard for recent machine learning methods, especially (deep) neural networks. It is usually faster than evolutionary optimization, however it is sensitive to the initial value estimate which may cause it to converge to a local optimum.
For the problems addressed here, the standard gradient descent method cannot be applied for several reasons. First, the objective function is not continuous because of the max function in Equation (10). In addition, for the expressions of the components of the objective functions defined by Equations (9) and (10) the analytical form of the gradient is difficult to express. Thirdly, the positions of the prototypes need to be optimized simultaneously with the weights.
In the evolutionary approach, the space of the problem has proved to be large enough so that finding the position of the prototypes is not feasible, and that is why the compromise solution using clustering was used. With gradient-based optimization this becomes possible. Still, when the position of the prototypes changes, the neighbor instances also change. Therefore, the objective function is calculated differently, considering different or similar instances, with different weights. This is also difficult to express in the analytical formulation of the gradient.
Thus, we decided to use an approximate differential method, following the definition of the central difference for the derivative. That is, for a very small value
ε:
in which the truncation error is
O(
ε2).
The value of the step size
γ is very important for the convergence speed. Therefore, it can be dynamically adjusted, so that it is higher at the beginning and decreasing as the algorithm approaches the solution. It was considered that the value of the step starts from about 1 and then decreases with the number of iterations, following a quadratic reciprocal evolution, but preventing it from going below 0.1:
where
n is the number of iterations, and the values of the
a,
b and
c parameters can be set to adjust the slope of the curve.
4.3. Nearest Neighbor Regression with Adaptive Distance Metrics Trained by Multiple Point Hill Climbing on Noisy Training Set Error (RADIAN)
The Nearest Neighbor Regression with Adaptive Distance Metrics Trained by Multiple Point Hill Climbing on Noisy Training Set Error (RADIAN) algorithm is not based on the concept of a large margin but is inspired by a technique used in deep learning, i.e., denoising autoencoders. This is a type of deep network that learns the presented data itself, but transfers it through an intermediate layer, usually a bottleneck with a number of neurons smaller than the dimensionality of the problem, so this layer will capture the essential characteristics of the data. In order to prevent the phenomenon of overfitting, the input data are slightly corrupted and the autoencoder is forced to learn the correct data from the corrupted version.
The overall concept of learning a distance metric and the distribution of the prototypes in the problem space are the same as for the previous algorithms. However, the prototype weights and positions are set so as to minimize the mean square error on a slightly corrupted version of the training set, where the instances inputs are slightly changed with a small random quantity:
where
xij is the value of the data,
r is a random uniform number in the [0, 1) interval and
ε is a small number, e.g.,
ε = 0.001.
The minimization is performed here by multiple point hill climbing. This method combines the approach of gradient descent with the search for a solution from multiple initial points, similar in a way to the parallel search performed by evolutionary algorithms. In standard hill climbing, several neighbors of the current point are generated, e.g., by an equation similar to (15). The point with a better (lower) objective function is selected as the new current point and the procedure is repeated for a number of steps. However, this behavior is similar to gradient descent, which is prone to local optima. Therefore, the search is performed from multiple starting points, so the probability of starting in a neighborhood of the global optimum is increased.
An idea for future investigation is to initialize the positions of the prototypes using the k-means clustering algorithm, instead of random initialization, such that they fill the problem space more uniformly.
From the initial results, it seems that this simple algorithm outperforms the other two for the problems under study.
6. Results and Discussion
In a previous study [
22] we compared the results of several well-known algorithms from the Weka collection [
2] with those of LMNNR for the three formulated problems, i.e., the conversion, average numerical and gravimetric molecular weights. The algorithms considered from Weka were: kNN, random forest, REPTree, M5 rules, additive regression, ε-SVR and ν-SVR, each with different values for their parameters. The data were split into 2/3 for training and 1/3 for testing.
Table 1 presents a concise comparison between the best classical algorithm (random forest) and LMNNR (with one prototype, five optimization neighbors and five regression neighbors) in terms of the coefficient of determination (
R2) obtained for both the training and testing sets.
The fact that LMNNR obtains a perfect correlation for the training set is not surprising, since it is an instance-based method. It is, however, commendable that it outperforms the best Weka algorithm on the testing set. Therefore, in the present study, we focus only on the results of LMNNR in two variants and the newly introduced algorithm RADIAN and perform a comprehensive experimental study with different settings regarding the distribution of data and the parameters of the algorithms.
In order to assess the performance of the algorithms, cross-validation was used. The most common method is to split the data into ten groups (or bins) and use nine groups for training and one group for testing, and repeat the process ten times, every time with a different test group. In this study, in order to assess different aspects of the learning process, we use three cross-validation variants:
Standard cross-validation with 10 groups, and in each step the data are split 90% for training and 10% for testing;
Cross-validation with three groups, and in each step the data are split 67% for training and 33% for testing: this is similar to the simpler 2/3–1/3 split (e.g., used in [
22], but more relevant statistically. This is a means to roughly compare results to those obtained in the previous work. However, a direct comparison is not possible;
A cross-validation-like procedure with 10 groups, and in each step the data are split 10% for training and 90% for testing. This scenario is used to assess the generalization capability of the models more “aggressively”.
In terms of the parameters used for the algorithms, two settings were used, as displayed in
Table 2:
Setting 1: the parameters allow for greater, more general search capabilities, the values are larger, but this leads to a longer execution time;
Setting 2: the values of the parameters are smaller. This setting allows us to see whether a shorter execution time can still provide acceptable results.
Table 3 and
Table 4 present the experimental results obtained for some combinations of data splits and algorithm parameter configurations, for the three considered problems, i.e.,
x,
Mn and
Mw. Each algorithm was run ten times, and its best performance was evaluated using the coefficient of correlation (
r) and the mean squared error (MSE).
The best results in these tables are emphasized with italic font. One can see that the performance of the three algorithms is comparable, however, the third one is an order of magnitude faster. The differential approach converges faster, that is why Algorithm 2 is most of the time better than Algorithm 1.
Obviously, the best results are obtained if a comprehensive data set (data 1) and high values of the parameters specific to each algorithm (settings 1) are used. Of the three output parameters, the conversion has the best models, compared to the average molecular masses.
When only 10% of the data is used for training, the results are less accurate than those obtained for 90%, but it must be underlined that they are still quite good, with a correlation coefficient above 0.9. Finally, with the 67–33% split, the results are almost as good as those obtained with the 90–10% split. This proves that the generalization capabilities of the model are very good. It is important to mention that with the distributions 67–33% and 90–10%, good results are obtained even with setting 2 (shorter execution time).
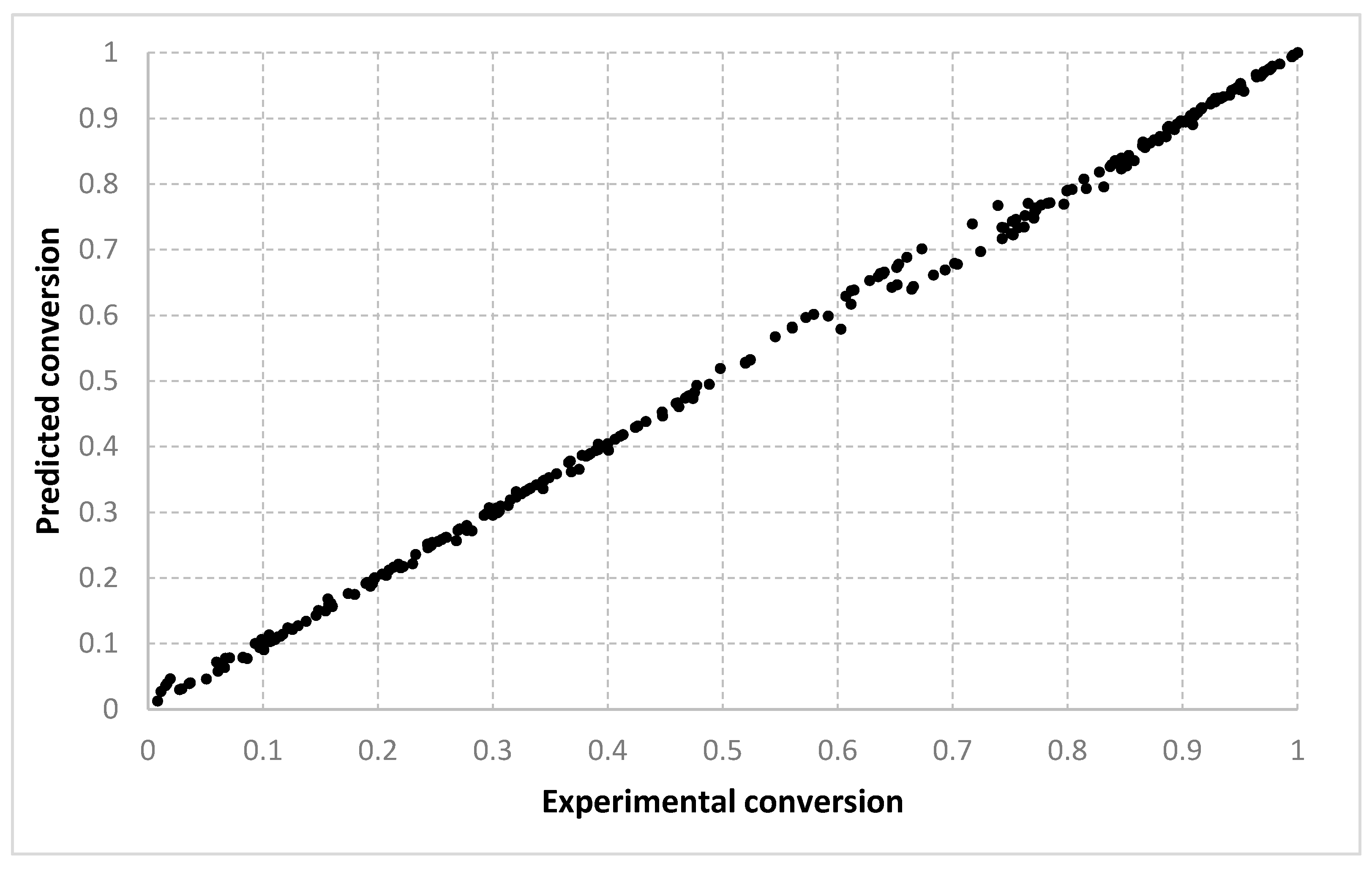
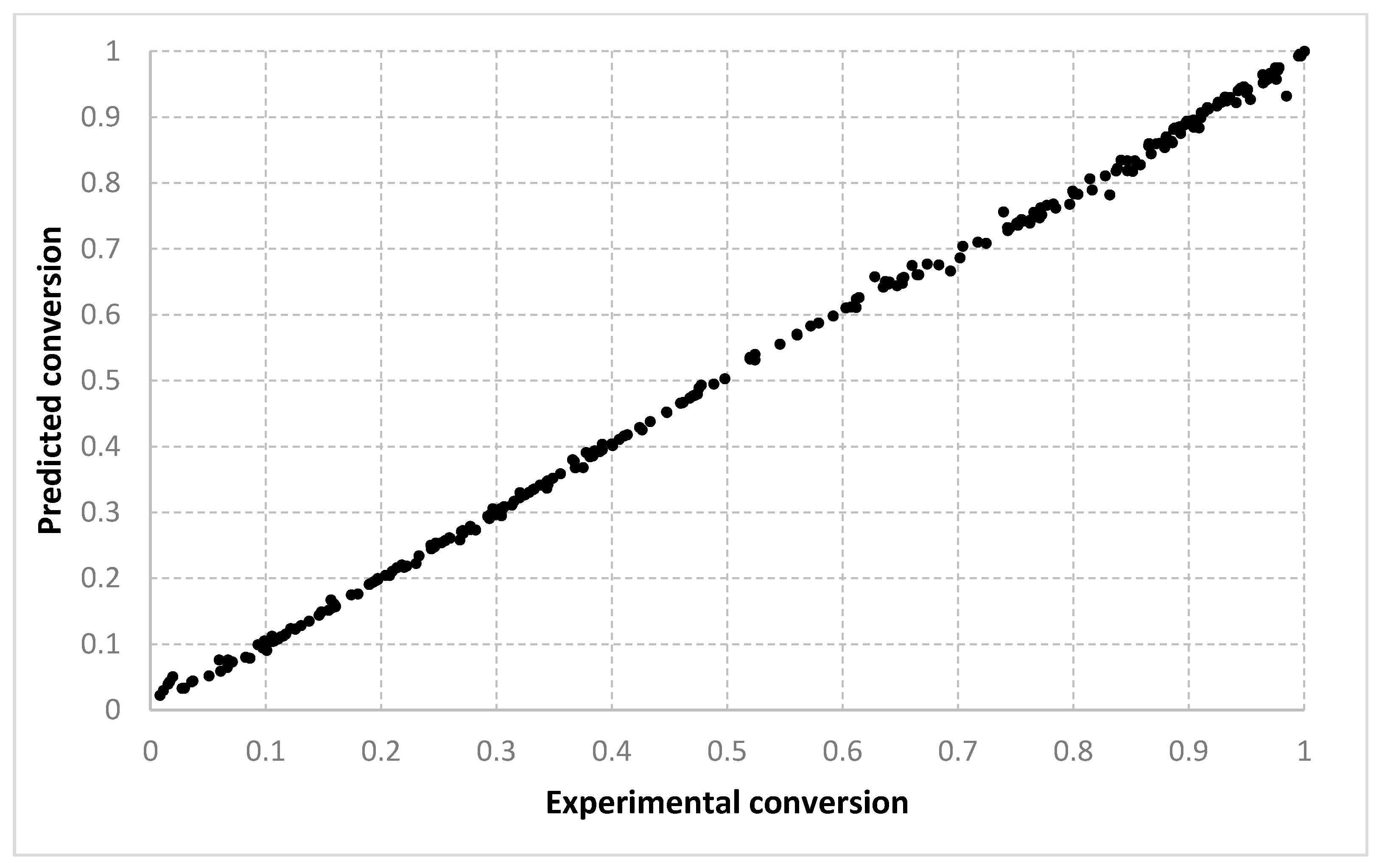
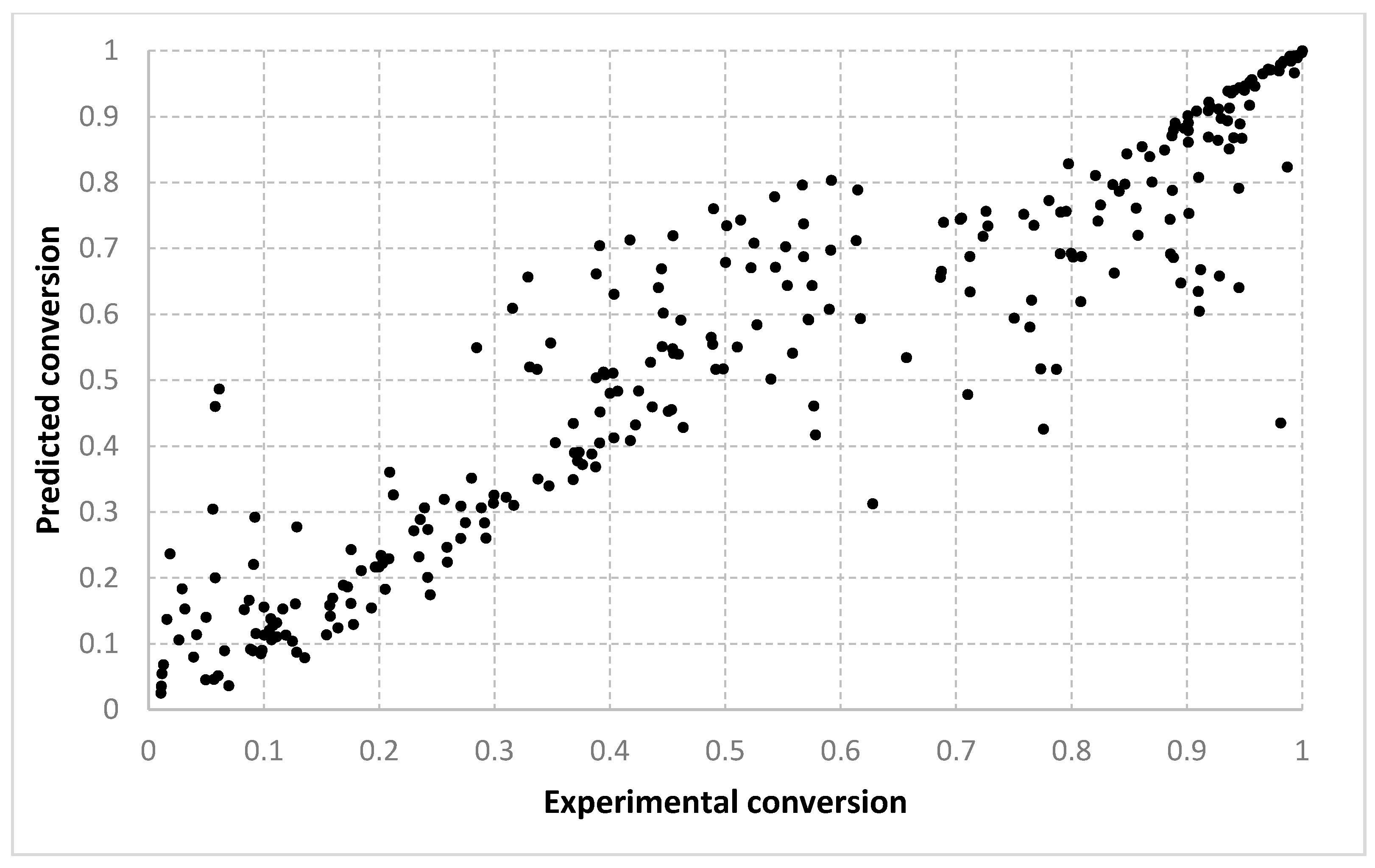
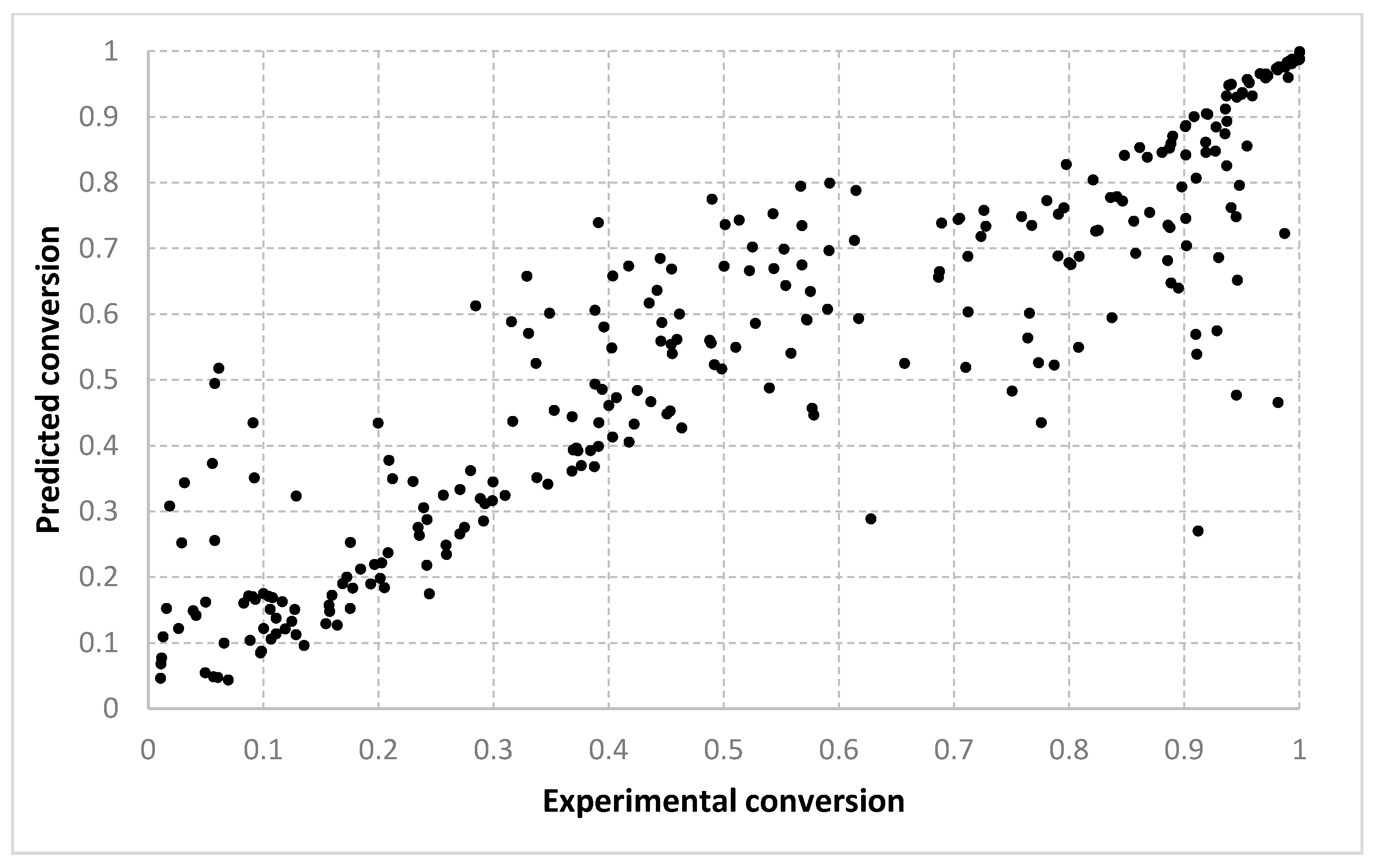
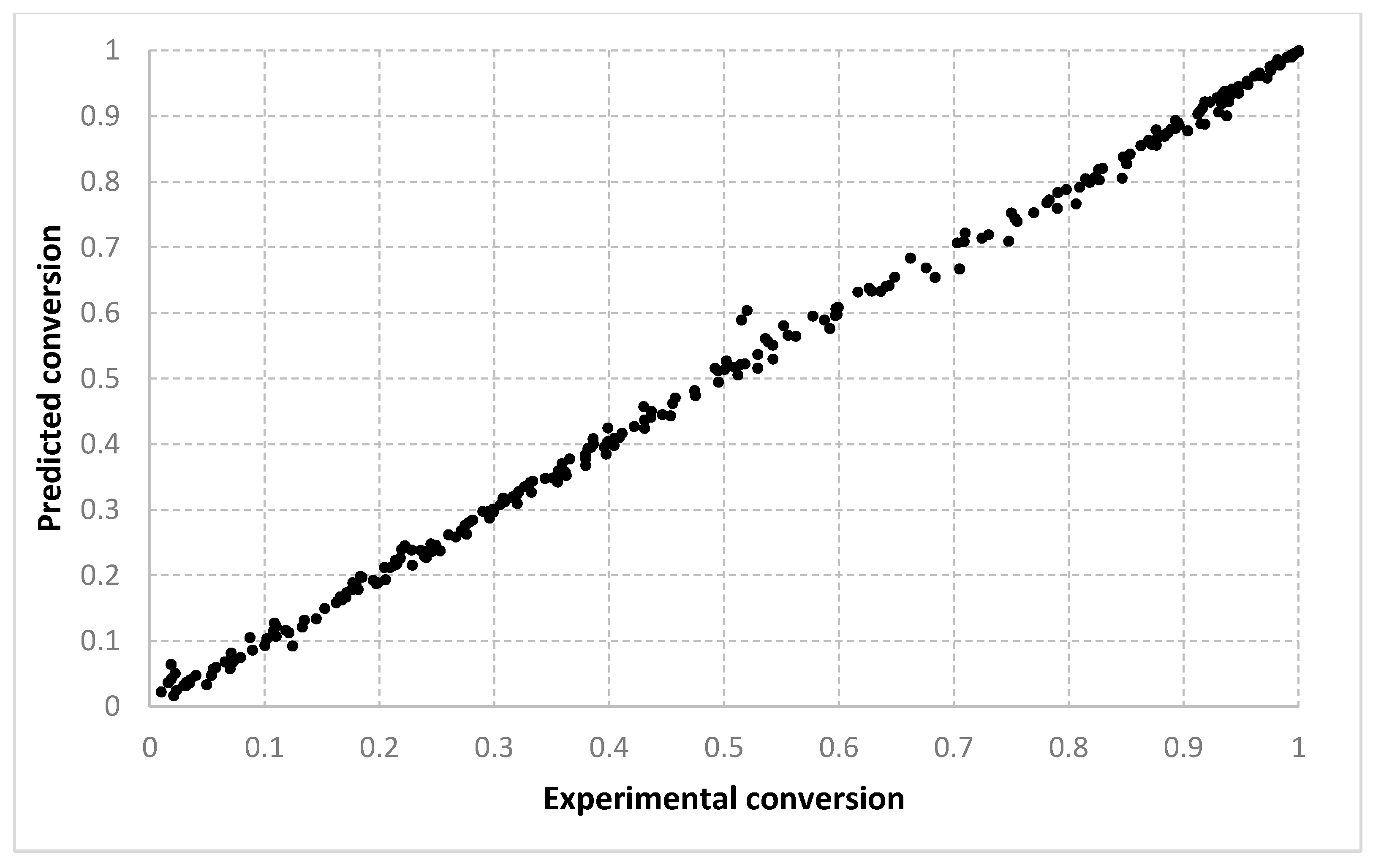
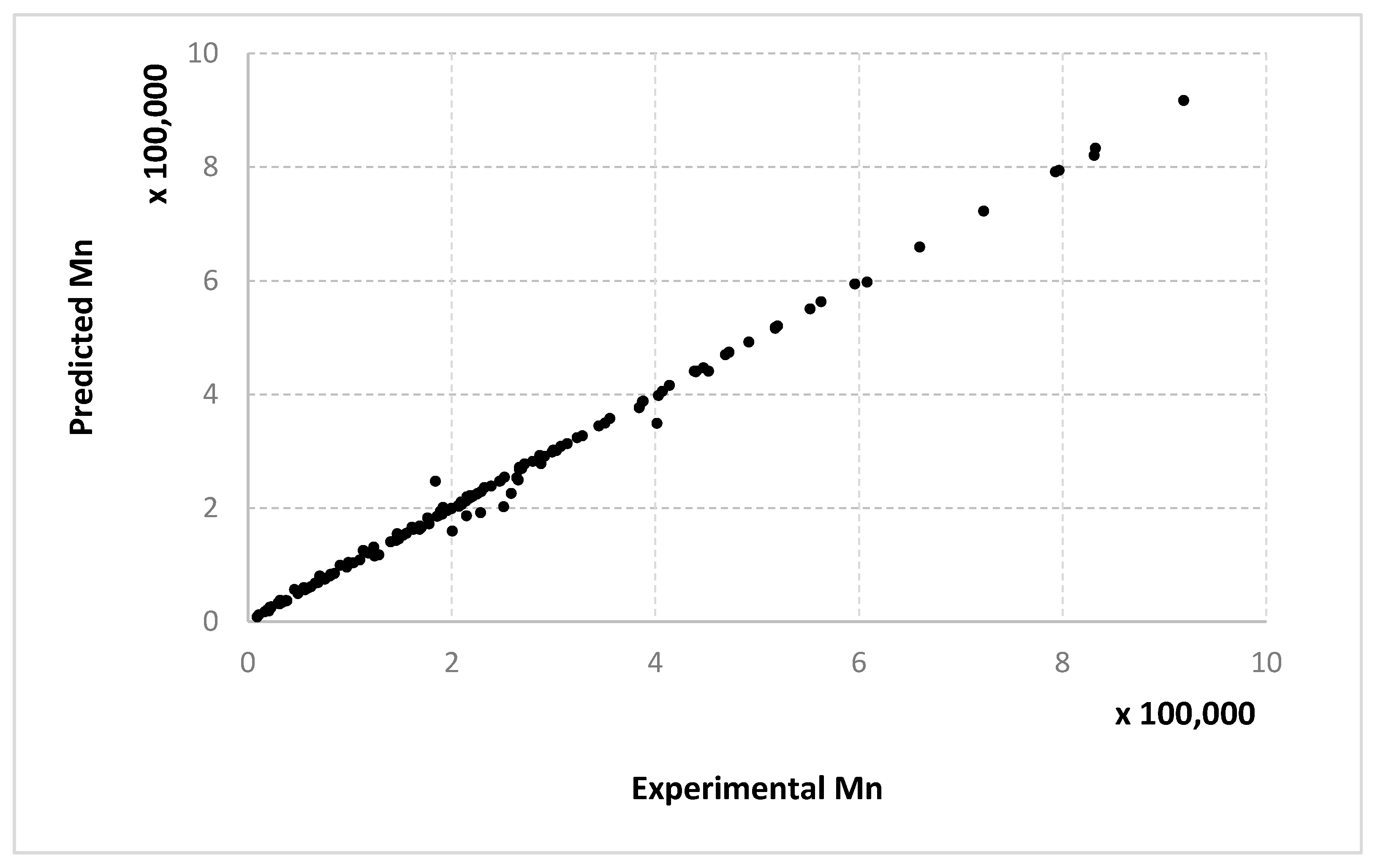
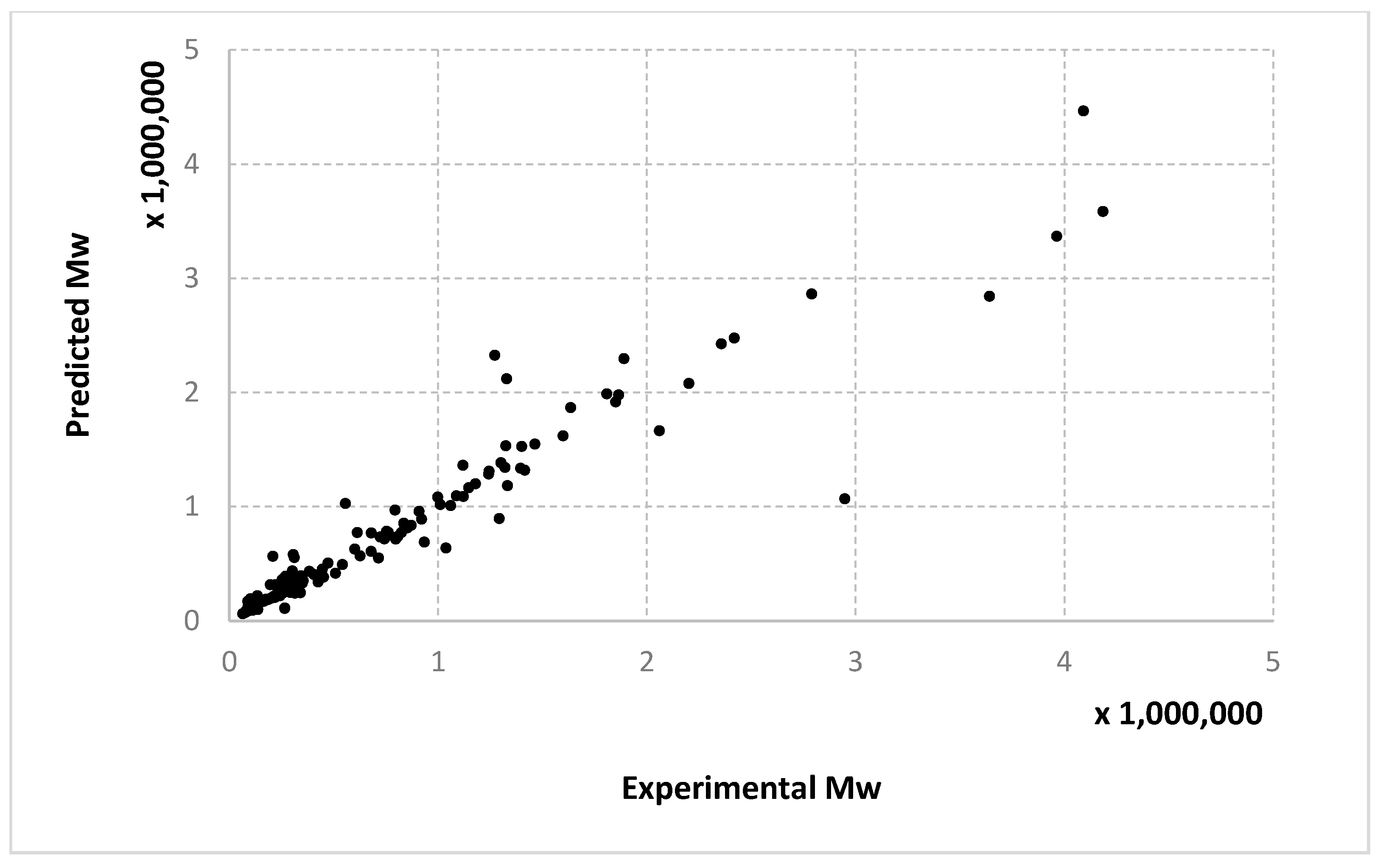
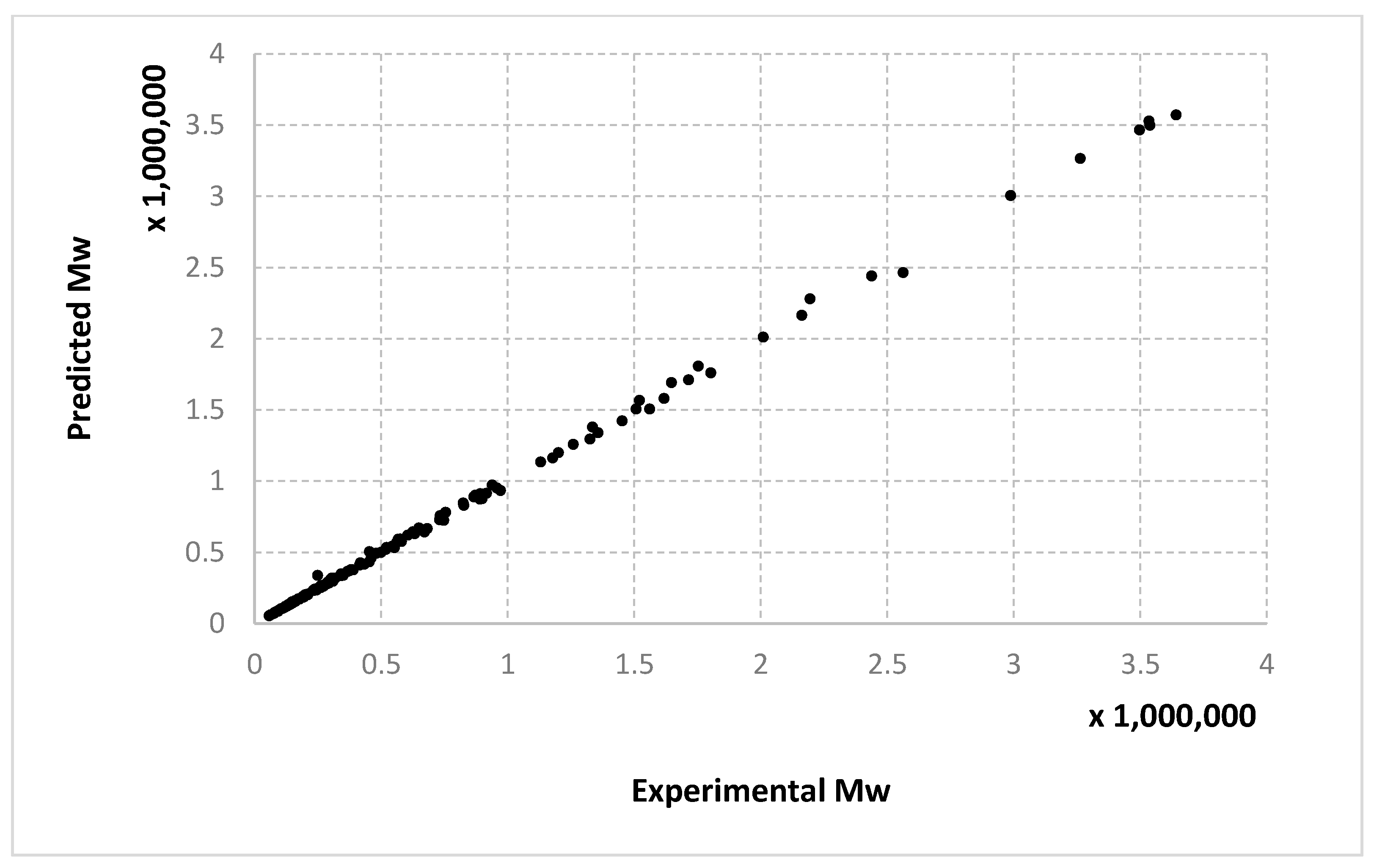
The results obtained for different algorithms, parameter setting, data splitting or amount of data are rendered suggestively in
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7,
Figure 8,
Figure 9,
Figure 10,
Figure 11,
Figure 12,
Figure 13 and
Figure 14 where predicted data are compared with the experimental data.
For the conversion, very good results were obtained with all three algorithms, with both types of settings. As shown in
Figure 3,
Figure 4,
Figure 5,
Figure 6 and
Figure 7, the best fit is obtained with the 90–10% split. With setting 2, slightly better solutions are found. We consider that this is because with two prototypes (i.e., setting 1), the search is being performed in a much larger space. When only one prototype is used (i.e., setting 2), the results are also more continuous. With a 10–90% split, the dispersion of the desired vs. predicted plot is greater. Visually, similar outcomes are achieved for both the LMNNR and RADIAN algorithms. The distribution of the 67–33% split, as seen in
Table 3 and
Table 4, has an aspect more similar to the 90–10% than to the 10–90% split, with an only slightly larger dispersion. This shows that training with two thirds of the data is enough for good generalization, compared with the extreme case when training only with a tenth of the data (
Figure 7 vs.
Figure 5).
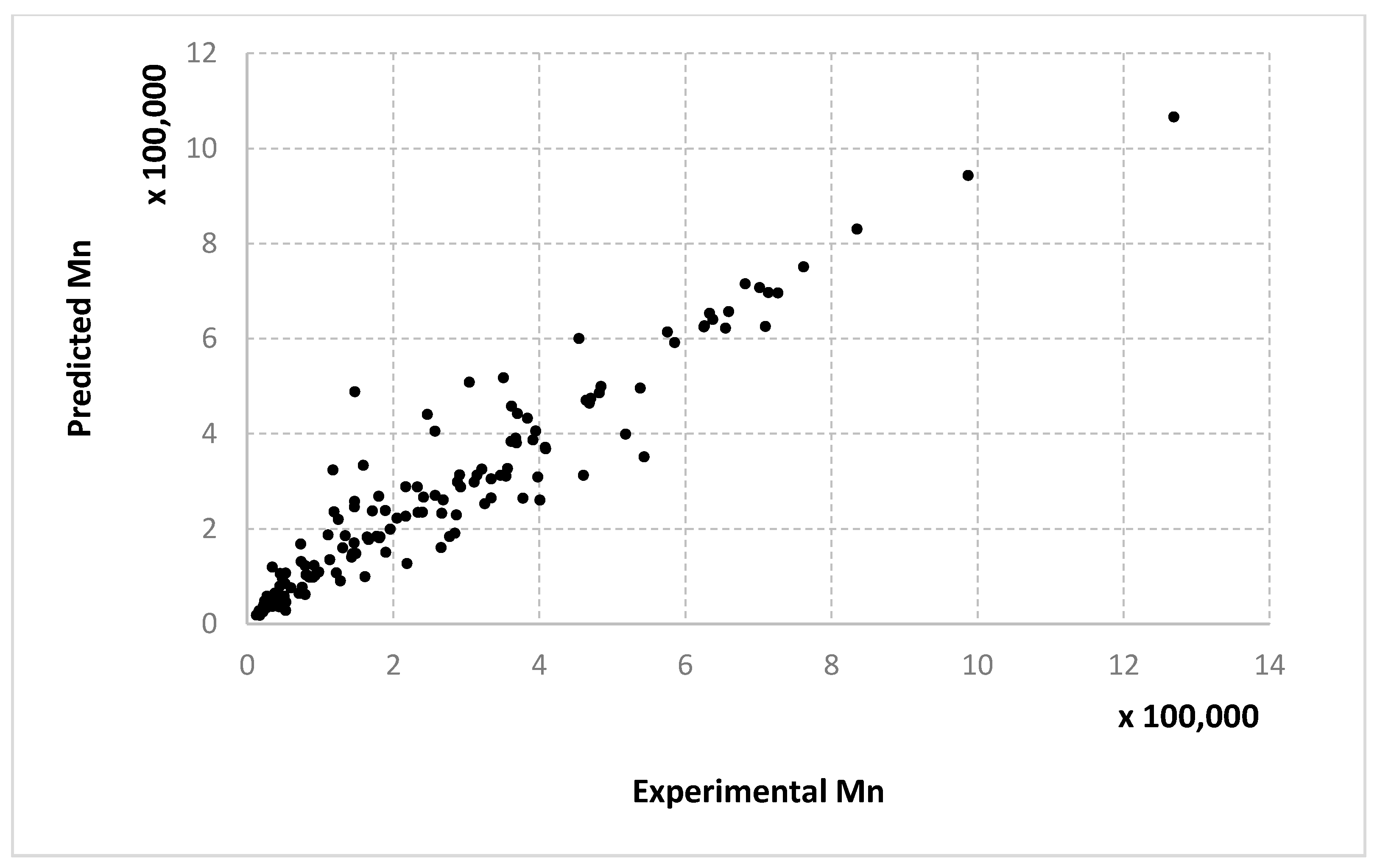
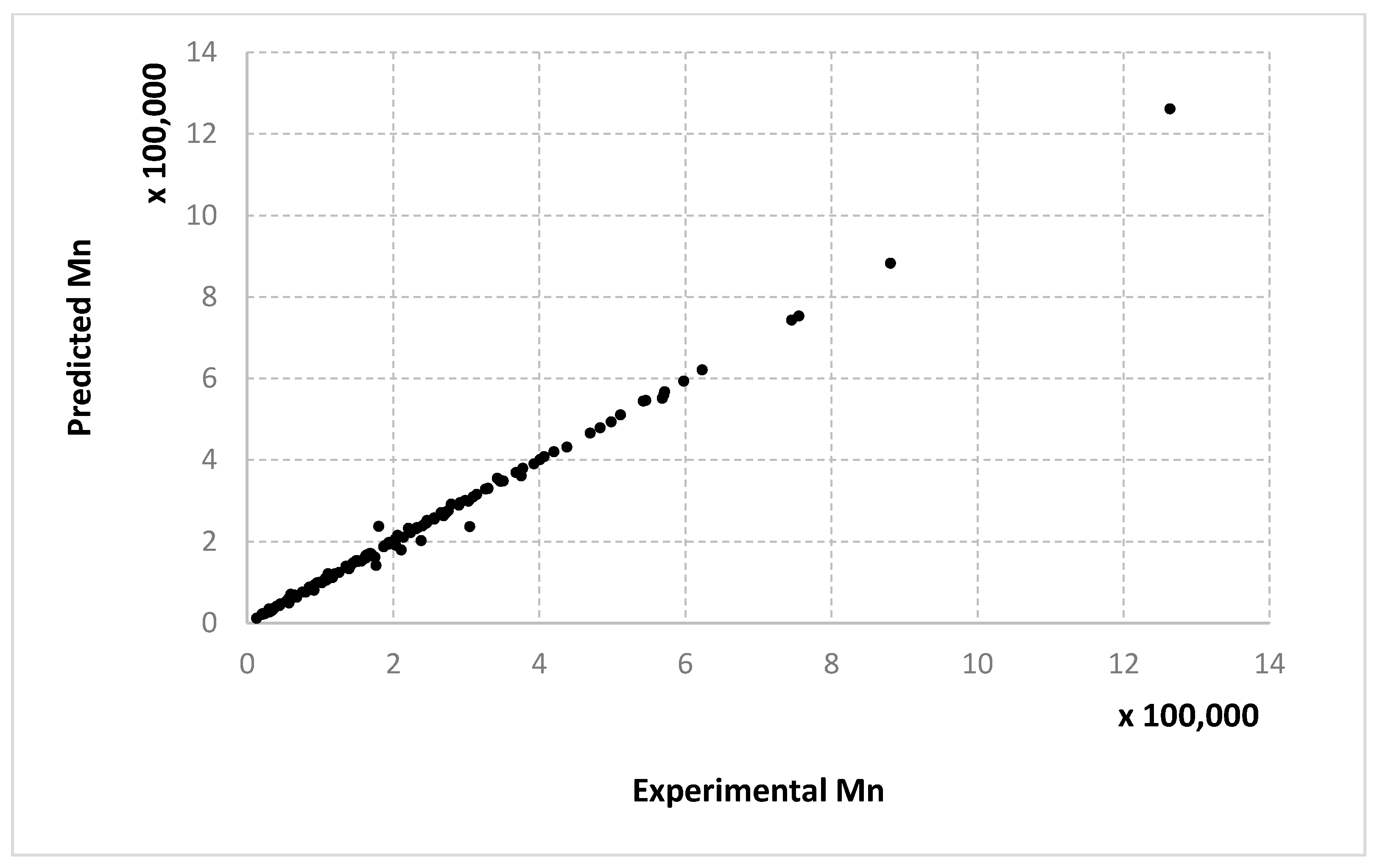
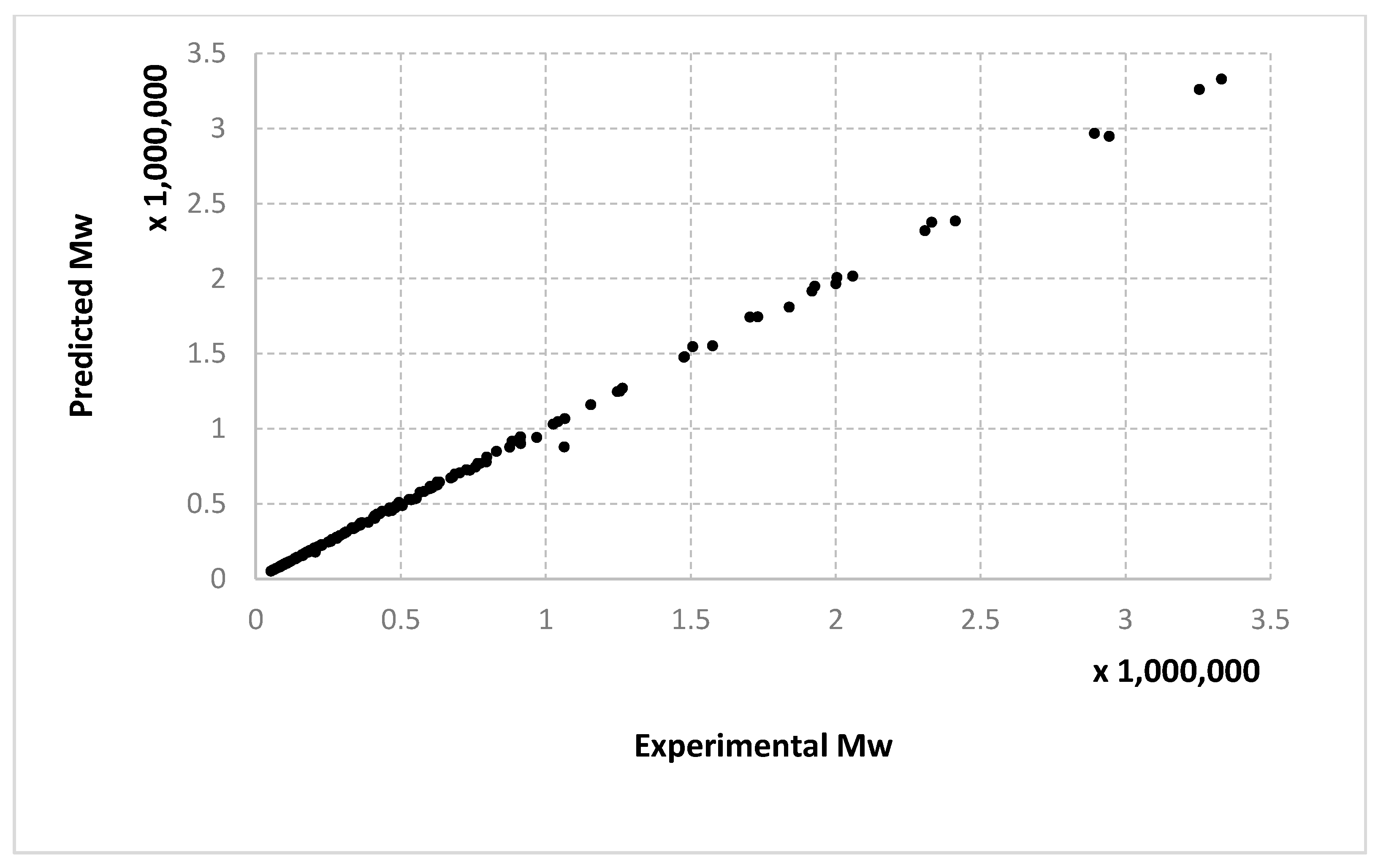
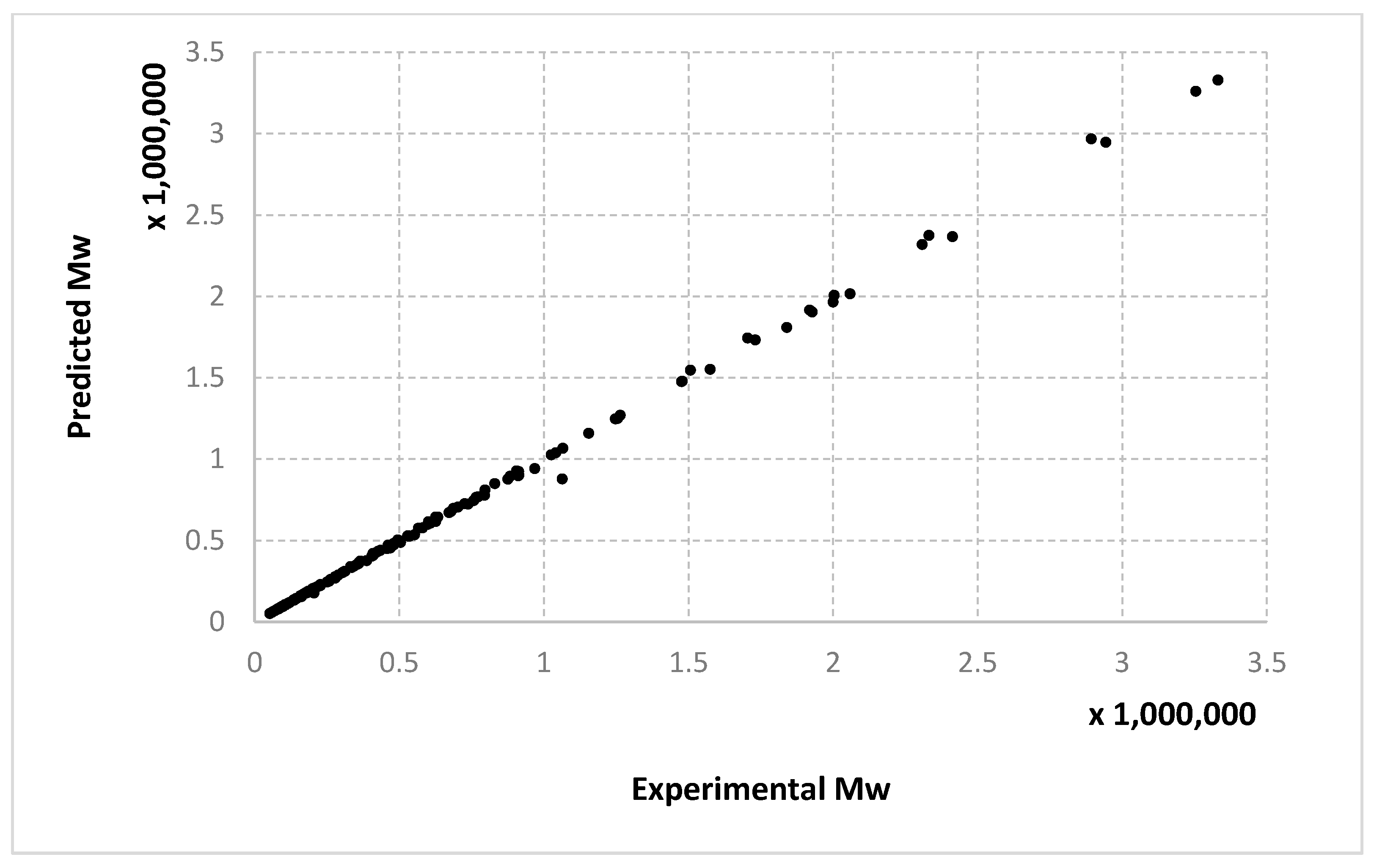
For molecular masses, the conclusions are similar to those obtained for the conversion, with no significant differences between the algorithms. However, one can see here that most of the data in the first half of the domain are much denser than the data from the second half. For
Mn,
Figure 8,
Figure 9 and
Figure 10 only display the performance of the RADIAN algorithm (i.e., Algorithm 3). In this case, it is also the data split that has the strongest effect on the results.
Very similar outcomes are encountered for the Mw output and the LMNNR-EA algorithm (i.e., Algorithm 1). However, in this case, the dispersion of the graph for the 10–90% split is less than those for x an Mn. This is in fact an indicator about the minimum amount of training information needed in order to generalize well.
We remind the reader that the data presented in
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7,
Figure 8,
Figure 9,
Figure 10,
Figure 11,
Figure 12,
Figure 13 and
Figure 14 refer only to the test data, i.e., the aggregated predictions of the models for the test groups.
The results obtained can also be analyzed in terms of variance of the performance metrics. For all algorithms, the variance decreases when the size of the training set increases. For example, for conversion, in the case of the 10–90% split, the standard deviation σ is about 3–5% of the mean value μ. In the case of the 67–33% split, it becomes 0.1–2% of the mean value and decreases even more for the 90–10% split. The variance can be further decreased by identifying outliers. Since the methods are heuristic, some runs simply fail to provide good solutions. By removing data outside the μ ± 2σ range, the variance is reduced especially for larger training sets, e.g., the new resulting standard deviation is about 10 times smaller. Algorithm 1 has the largest variance among the three methods, while algorithms 2 and 3 have comparable variance.
In terms of execution time, the computations take longer as the size of the training set increases. For example, one fold of cross-validation for conversion takes about 6.7 s for the 10–90% split and 54 s for the 90–10% split for Algorithm 1. Algorithm 2 takes about 5 s and 32 s, respectively. Algorithm 3 requires about 0.7 s and 5.8 s, respectively. These studies were made using a computer with a 4-core 2 GHz Intel processor and 8 GB of RAM. Of course, specific times depend on the particular structure of the training data, especially the number of attributes, and the parameters of the algorithms. In particular, the complexity of Algorithm 1 mainly depends on the number of individuals in the population and the number of generations of the evolutionary algorithm. The complexity of Algorithm 2 mainly depends on the number of iterations of the approximate gradient descent procedure. The complexity of Algorithm 3 mainly depends on the number of hill-climbing steps and the number of neighbors that are generated in each step.
7. Conclusions
Instance-based classification and regression algorithms can provide very good results for complex decision boundaries, especially when the size of the training dataset is big and the number of dimensions of the problem space is not very large. The distance metric is crucial for this class of algorithms, and a significant increase in performance can be achieved by changing it depending on the specific problem under study. The optimal distance metric can be obtained by solving an optimization problem that tries to decrease the distance between the instances with similar output values and increase the distance between the instances with different output values. This process is actually equivalent to maximizing the margin between the instances with different output values. In this way, the concept of a large margin, introduced in the context of support vector machines, can also be applied to instance-based regression. The LMNNR algorithm uses this idea together with prototypes, where each prototype can have its own custom distance metric, which can be helpful when a large number of instances are available.
The corresponding optimization problem can be solved either by an evolutionary algorithm or by an approximate gradient descent method. The results are competitive compared with those obtained by classical algorithms such as support vector machines, k-nearest neighbor and random forest.
Another original regression method is designed by considering an idea from denoising autoencoders, a kind of deep neural networks. In our case, the weights that define the custom distance metric and the positions of the prototypes are computed so as to minimize the mean square error on a corrupted version of the training data created by adding a small amount of noise.
The quality of the results is also supported by the adaptive sampling technique that provides the machine learning algorithms with the most relevant data by taking into account the rate of variation of the outputs involved in the chemical process.
As future directions of research, one may investigate whether similar results can be obtained using alternative techniques, e.g., principal analysis decomposition or (deep) neural networks [
9,
23,
24].
Concerning the case study of the free radical polymerization of MMA, the conclusions that give the necessary practical indications are the following:
The accuracy of the modeling for the variables of interest—monomer conversion and molecular masses of the polymer—depends on the applied algorithm, the settings of their parameters and the way of splitting the data. The last factor has the greater importance;
Conversion is easier to model than molecular weights, but, with a proper combination of settings and data sharing, very good results can be obtained for all parameters of interest;
Although good results have been identified for all three algorithms, RADIAN is preferred because it is considerably faster than the other two, which is an important factor for online optimal control procedures.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}