
XCM: An Explainable Convolutional Neural Network for Multivariate Time Series Classification


Abstract
:1. Introduction
- We present XCM, an end-to-end new compact and explainable convolutional neural network for MTS classification which supports its predictions with faithful explanations;
- We show that XCM outperforms the state-of-the-art MTS classifiers on both the large and small UEA datasets [7];
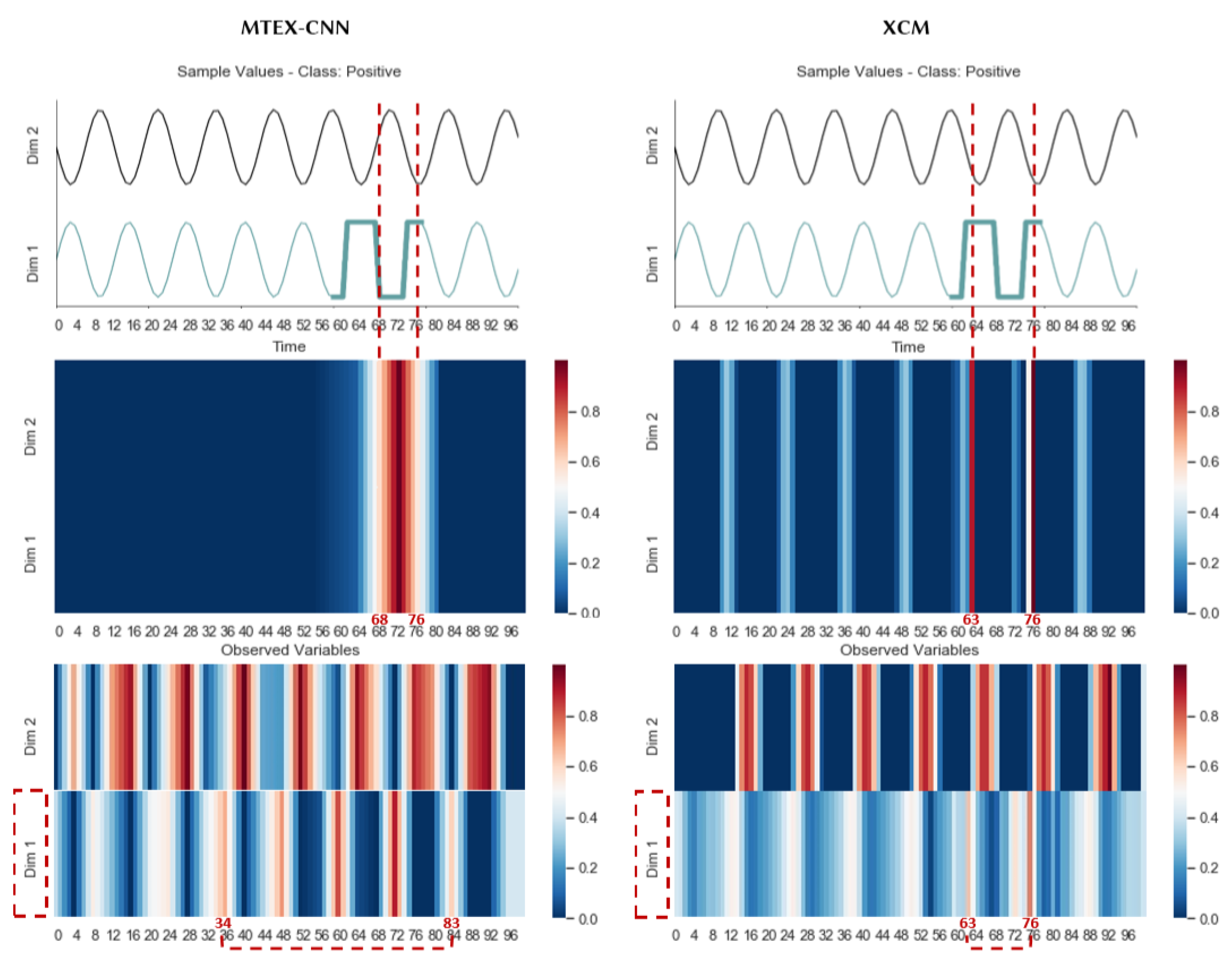
- We illustrate on a synthetic dataset that XCM enables a more precise identification of the regions of the input data that are important for predictions compared to the current faithfully explainable deep learning MTS classifier MTEX-CNN;
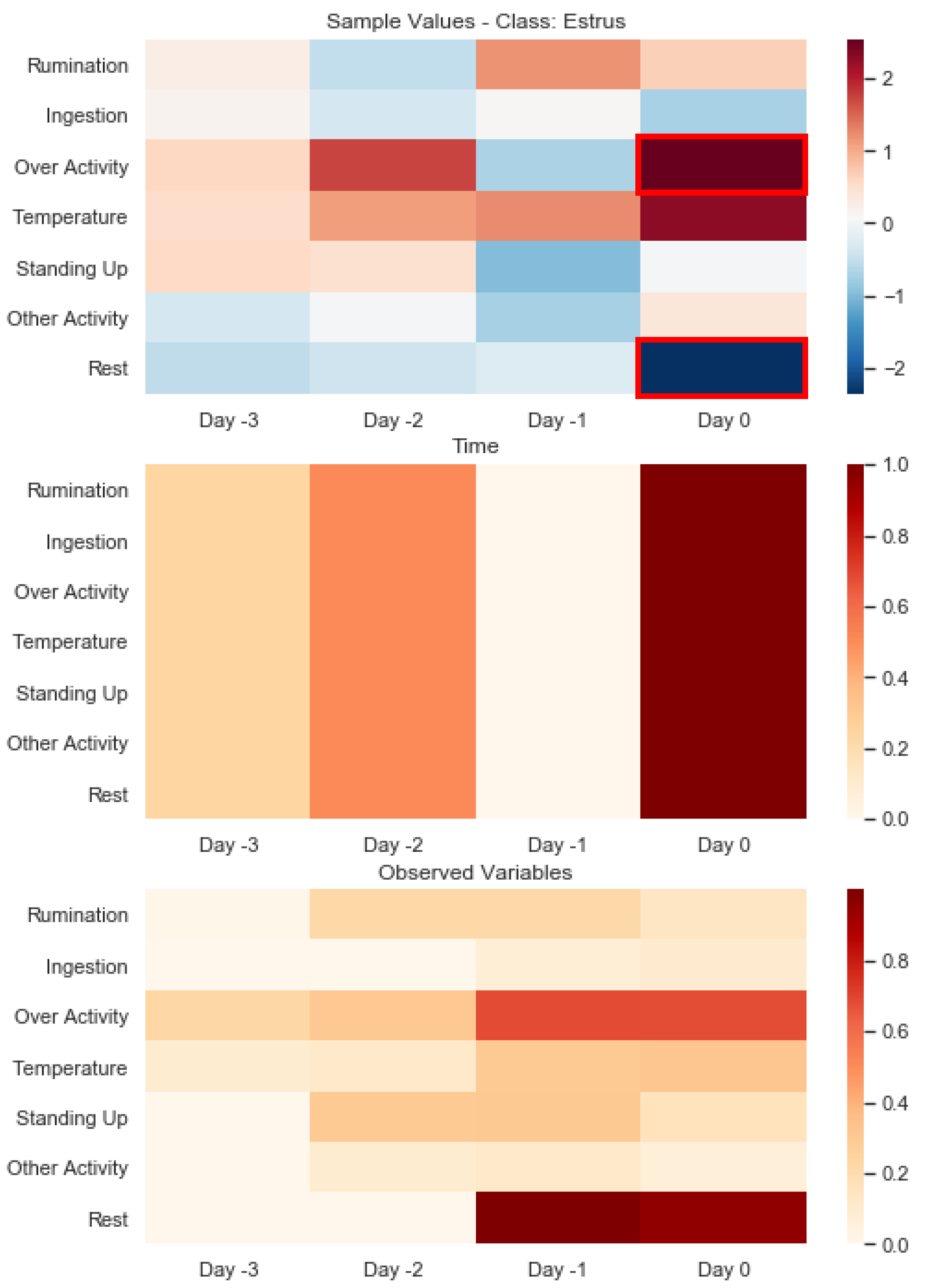
- We show that XCM outperforms the current most accurate state-of-the-art algorithm on a real-world application while enhancing explainability by providing faithful and more informative explanations.
2. Related Work
2.1. Background
2.2. MTS Classifiers
2.3. Explainability
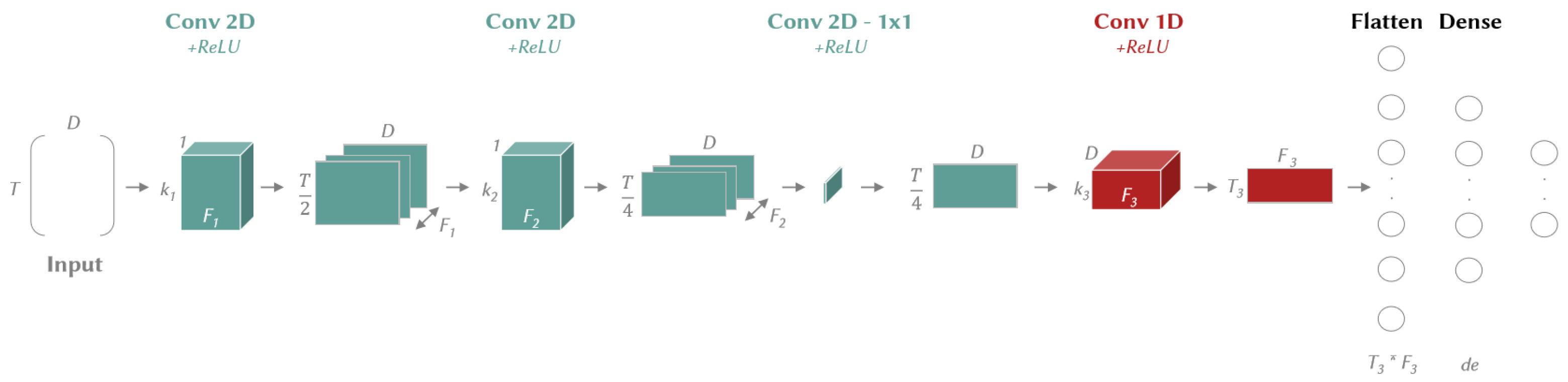
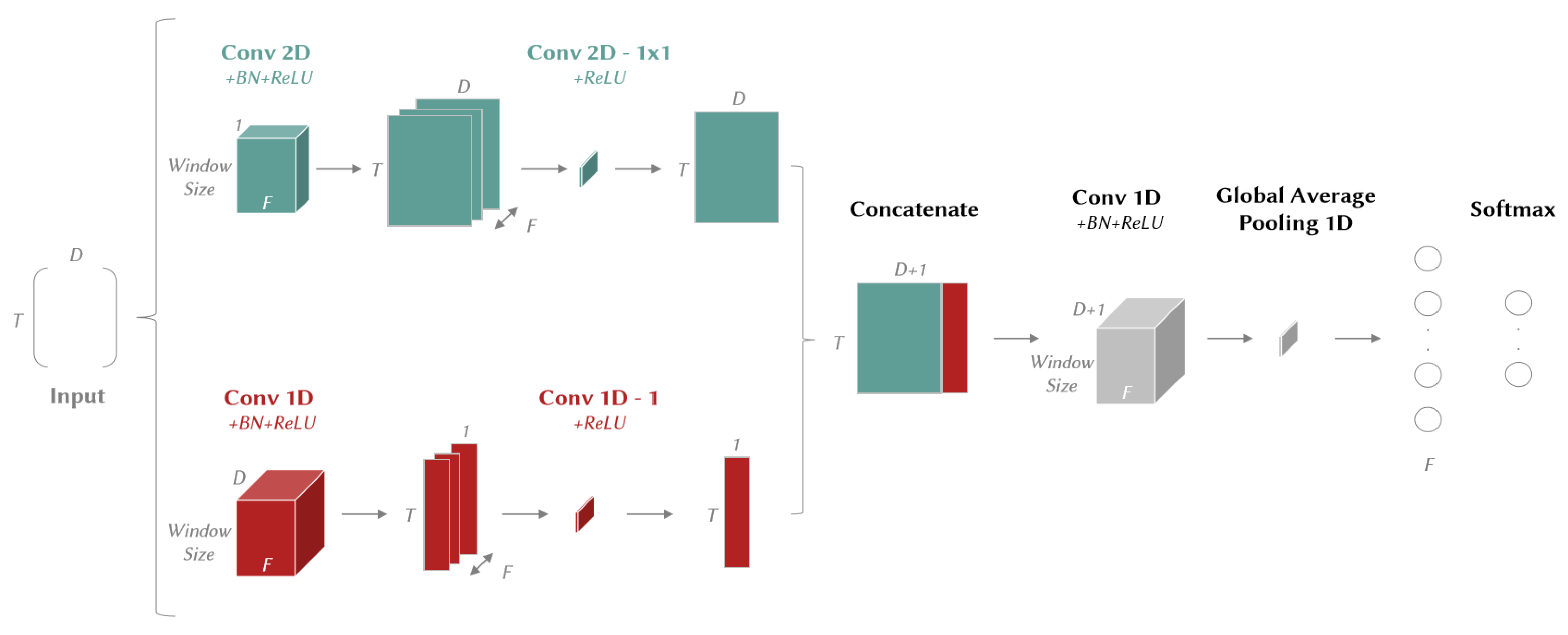
3. XCM
3.1. Architecture
3.2. Explainability
4. Evaluation
4.1. Datasets
4.2. Algorithms
- DTW, DTW and ED—with and without normalization (n): we reported the results published in the UEA archive [7];
- MLSTM-FCN: we used the implementation available (https://github.com/houshd/MLSTM-FCN (accessed on 1 November 2021)) and ran it with the parameter settings recommended by the authors in the paper [5] (128-256-128 filters, kernel sizes 8/5/3, initialization of convolution kernels Uniform He, reduction ratio of 16, 250 training epochs, dropout of 0.8, Adam optimizer) and with the following hyperparameters: batch size , number of LSTM cells ;
- MTEX-CNN: we implemented the algorithm with Keras in Python 3.6 based on the description of the paper [12]. We ran it with the parameter settings recommended by the authors (Stage 1: two convolution layers with half padding and ReLU activation, kernel sizes and , strides , feature maps 64 and 128, dropout 0.4. Stage 2: one convolution layer with ReLU activation, strides 2, kernel size 2, feature maps 128, dropout 0.4. Dense layer dimension 128 and L2 regularization 0.2) and with the following hyperparameter: batch size ;
- WEASEL+MUSE: we used the implementation available (https://github.com/patrickzib/SFA (accessed on 1 November 2021)) and ran it with the parameter settings recommended by the authors in the paper [6] (chi = 2, bias = 1, p = 0.1, c = 5 and L2R_LR_DUAL solver) and with the following hyperparameters: SFA word lengths , SFA quantization method {equi-depth, equi-frequency}, windows length [4, max(MTS length)];
- XCM: we implemented the algorithm with Keras in Python 3.6. 2D convolution layers with: 128 feature maps, kernel size: , strides , padding same and ReLU activation. In addition, 1D convolution layers with: 128 feature maps, kernel size: , strides 1, padding same and ReLU activation. The hyperparameters are: batch size and (the time window size—kernel size), expressed as a percentage of the total size of the MTS ;
- XCM-Seq: XCM variant with 2D and 1D convolution blocks in sequence (see description in Section 3.1). We used the same setting as XCM.
4.3. Hyperparameters
4.4. Metrics
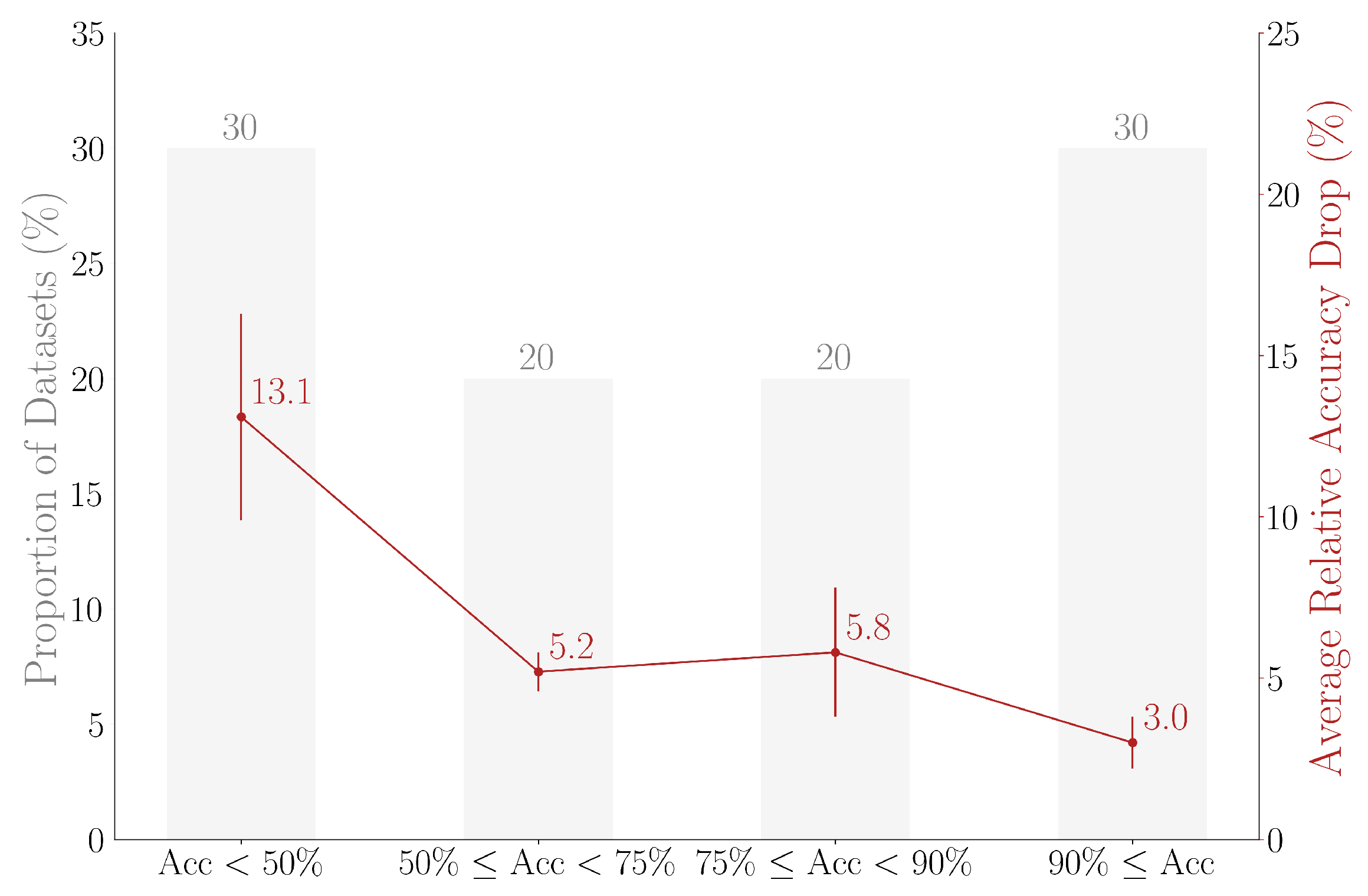
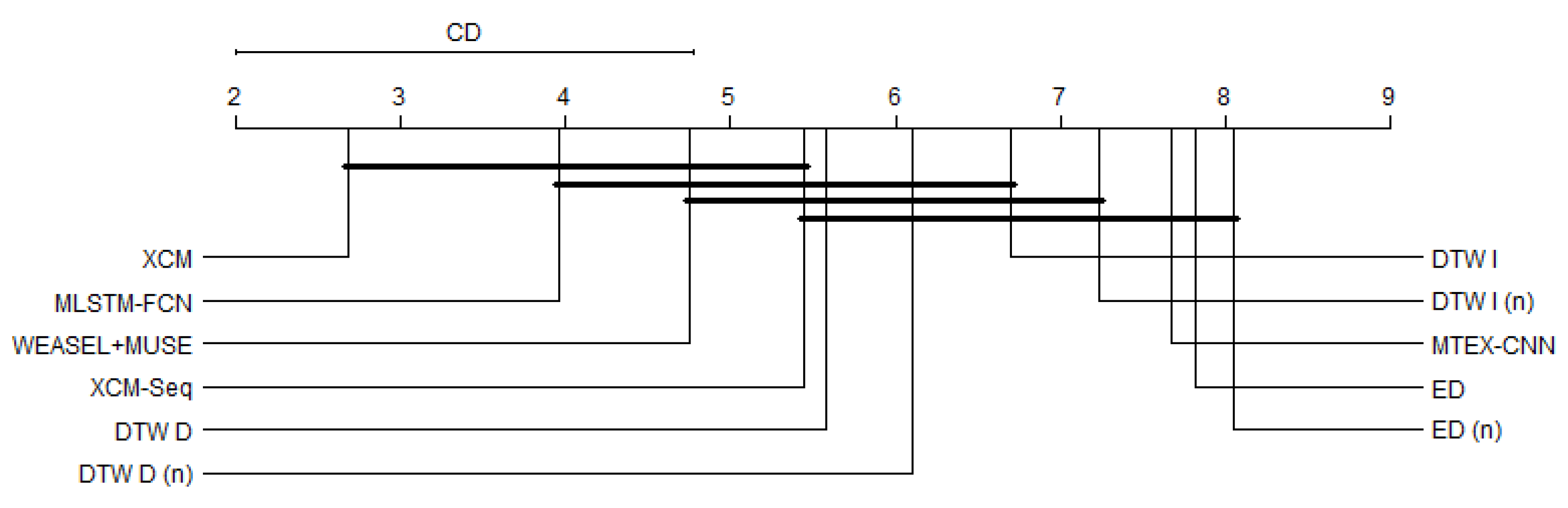
5. Results
5.1. Performance
5.2. Explainability
5.3. Real-World Application
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, C.; Bian, J.; Xing, C.; Liu, T. Investment Behaviors Can Tell What Inside: Exploring Stock Intrinsic Properties for Stock Trend Prediction. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- Li, J.; Rong, Y.; Meng, H.; Lu, Z.; Kwok, T.; Cheng, H. TATC: Predicting Alzheimer’s Disease with Actigraphy Data. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, London, UK, 19–23 August 2018. [Google Scholar]
- Jiang, R.; Song, X.; Huang, D.; Song, X.; Xia, T.; Cai, Z.; Wang, Z.; Kim, K.; Shibasaki, R. DeepUrbanEvent: A System for Predicting Citywide Crowd Dynamics at Big Events. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- Fauvel, K.; Balouek-Thomert, D.; Melgar, D.; Silva, P.; Simonet, A.; Antoniu, G.; Costan, A.; Masson, V.; Parashar, M.; Rodero, I.; et al. A Distributed Multi-Sensor Machine Learning Approach to Earthquake Early Warning. In Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Karim, F.; Majumdar, S.; Darabi, H.; Harford, S. Multivariate LSTM-FCNs for Time Series Classification. Neural Netw. 2019, 116, 237–245. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schäfer, P.; Leser, U. Multivariate Time Series Classification with WEASEL+MUSE. arXiv 2017, arXiv:1711.11343. [Google Scholar]
- Bagnall, A.; Lines, J.; Keogh, E. The UEA Multivariate Time Series Classification Archive, 2018. arXiv 2018, arXiv:1811.00075. [Google Scholar]
- Schäfer, P.; Högqvist, M. SFA: A Symbolic Fourier Approximation and Index for Similarity Search in High Dimensional Datasets. In Proceedings of the 15th International Conference on Extending Database Technology, Berlin, Germany, 27–30 March 2012; pp. 516–527. [Google Scholar]
- Rudin, C. Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead. Nat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef] [Green Version]
- Selvaraju, R.; Das, A.; Vedantam, R.; Cogswell, M.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 2019, 128, 336–359. [Google Scholar] [CrossRef] [Green Version]
- Adebayo, J.; Gilmer, J.; Muelly, M.; Goodfellow, I.; Hardt, M.; Kim, B. Sanity Checks for Saliency Maps. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Assaf, R.; Giurgiu, I.; Bagehorn, F.; Schumann, A. MTEX-CNN: Multivariate Time Series EXplanations for Predictions with Convolutional Neural Networks. In Proceedings of the IEEE International Conference on Data Mining, Beijing, China, 8–11 November 2019. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q. Sequence to Sequence Learning with Neural Networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics, Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Cristian Borges Gamboa, J. Deep Learning for Time-Series Analysis. arXiv 2017, arXiv:1701.01887. [Google Scholar]
- Seto, S.; Zhang, W.; Zhou, Y. Multivariate Time Series Classification Using Dynamic Time Warping Template Selection for Human Activity Recognition. In Proceedings of the IEEE Symposium Series on Computational Intelligence, Cape Town, South Africa, 7–10 December 2015. [Google Scholar]
- Vidal, E.; Casacuberta, F.; Segovia, H. Is the DTW “Distance” Really a Metric? An Algorithm Reducing the Number of DTW Comparisons in Isolated Word Recognition. Speech Commun. 1985, 4, 333–344. [Google Scholar] [CrossRef]
- Shokoohi-Yekta, M.; Hu, B.; Jin, H.; Wang, J.; Keogh, E. Generalizing DTW to the Multi-Dimensional Case Requires an Adaptive Approach. Data Min. Knowl. Discov. 2017, 31, 1–31. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Karlsson, I.; Papapetrou, P.; Boström, H. Generalized Random Shapelet Forests. Data Min. Knowl. Discov. 2016, 30, 1053–1085. [Google Scholar] [CrossRef]
- Wistuba, M.; Grabocka, J.; Schmidt-Thieme, L. Ultra-Fast Shapelets for Time Series Classification. arXiv 2015, arXiv:1503.05018. [Google Scholar]
- Baydogan, M.; Runger, G. Time Series Representation and Similarity Based on Local Autopatterns. Data Min. Knowl. Discov. 2016, 30, 476–509. [Google Scholar] [CrossRef]
- Tuncel, K.; Baydogan, M. Autoregressive Forests for Multivariate Time Series Modeling. Pattern Recognit. 2018, 73, 202–215. [Google Scholar] [CrossRef]
- Baydogan, M.; Runger, G. Learning a Symbolic Representation for Multivariate Time Series Classification. Data Min. Knowl. Discov. 2014, 29, 400–422. [Google Scholar] [CrossRef]
- Wang, Z.; Yan, W.; Oates, T. Time Series Classification from Scratch with Deep Neural Networks: A Strong Baseline. In Proceedings of the 2017 International Joint Conference on Neural Networks, Anchorage, AK, USA, 14–19 May 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Zhang, X.; Gao, Y.; Lin, J.; Lu, C. TapNet: Multivariate Time Series Classification with Attentional Prototypical Network. In Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Zerveas, G.; Jayaraman, S.; Patel, D.; Bhamidipaty, A.; Eickhoff, C. A Transformer-Based Framework for Multivariate Time Series Representation Learning. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual Event, 14–18 August 2021. [Google Scholar]
- Du, M.; Liu, N.; Hu, X. Techniques for Interpretable Machine Learning. Commun. ACM 2020, 63, 68–77. [Google Scholar] [CrossRef] [Green Version]
- Ribeiro, M.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Lundberg, S.; Lee, S. A Unified Approach to Interpreting Model Predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Ribeiro, M.; Singh, S.; Guestrin, C. Anchors: High-Precision Model-Agnostic Explanations. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Guidotti, R.; Monreale, A.; Giannotti, F.; Pedreschi, D.; Ruggieri, S.; Turini, F. Factual and Counterfactual Explanations for Black Box Decision Making. IEEE Intell. Syst. 2019, 34, 14–23. [Google Scholar] [CrossRef]
- Ancona, M.; Ceolini, E.; Öztireli, C.; Gross, M. Towards Better Understanding of Gradient-Based Attribution Methods for Deep Neural Networks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 1–3 May 2018. [Google Scholar]
- Erhan, D.; Bengio, Y.; Courville, A.; Vincent, P. Visualizing Higher-Layer Features of a Deep Network. In Proceedings of the ICML Workshop on Learning Feature Hierarchies, Montreal, QC, Canada, 9 June 2009. [Google Scholar]
- Springenberg, J.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for Simplicity: The All Convolutional Net. In Proceedings of the International Conference on Learning Representations (Workshop Track), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Bach, S.; Binder, A.; Montavon, G.; Klauschen, F.; Müller, K.; Samek, W. On Pixel-Wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation. PLoS ONE 2015, 10, e0130140. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shrikumar, A.; Greenside, P.; Shcherbina, A.; Kundaje, A. Not Just a Black Box: Learning Important Features Through Propagating Activation Differences. arXiv 2016, arXiv:1605.01713. [Google Scholar]
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic Attribution for Deep Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Shrikumar, A.; Greenside, P.; Kundaje, A. Learning Important Features through Propagating Activation Differences. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in Network. arXiv 2014, arXiv:1312.4400. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Nair, V.; Hinton, G. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Bjorck, N.; Gomes, C.; Selman, B.; Weinberger, K. Understanding Batch Normalization. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Demšar, J. Statistical Comparisons of Classifiers over Multiple Data Sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Searchinger, T.; Waite, R.; Hanson, C.; Ranganathan, J.; Dumas, P.; Matthews, E. Creating a Sustainable Food Future; World Resources Institute: Washington, DC, USA, 2018. [Google Scholar]
- Bascom, S.; Young, A. A Summary of the Reasons Why Farmers Cull Cows. J. Dairy Sci. 1998, 81, 2299–2305. [Google Scholar] [CrossRef]
- Cutullic, E.; Delaby, L.; Gallard, Y.; Disenhaus, C. Dairy Cows’ Reproductive Response to Feeding Level Differs According to the Reproductive Stage and the Breed. Animal 2011, 5, 731–740. [Google Scholar] [CrossRef] [PubMed]
- Tenghe, A.; Bouwman, A.; Berglund, B.; Strandberg, E.; Blom, J.; Veerkamp, R. Estimating genetic parameters for fertility in dairy cows from in-line milk progesterone profiles. J. Dairy Sci. 2015, 98, 5763–5773. [Google Scholar] [CrossRef] [Green Version]
- Steeneveld, W.; Hogeveen, H. Characterization of Dutch Dairy Farms Using Sensor Systems for Cow Management. J. Dairy Sci. 2015, 98, 709–717. [Google Scholar] [CrossRef] [PubMed]
- Chanvallon, A.; Coyral-Castel, S.; Gatien, J.; Lamy, J.; Ribaud, D.; Allain, C.; Clément, P.; Salvetti, P. Comparison of Three Devices for the Automated Detection of Estrus in Dairy Cows. Theriogenology 2014, 82, 734–741. [Google Scholar] [CrossRef] [PubMed]
- Gaillard, C.; Barbu, H.; Sørensen, M.; Sehested, J.; Callesen, H.; Vestergaard, M. Milk Yield and Estrous Behavior During Eight Consecutive Estruses in Holstein Cows Fed Standardized or High Energy Diets and Grouped According to Live Weight Changes in Early Lactation. J. Dairy Sci. 2016, 99, 3134–3143. [Google Scholar] [CrossRef] [PubMed] [Green Version]
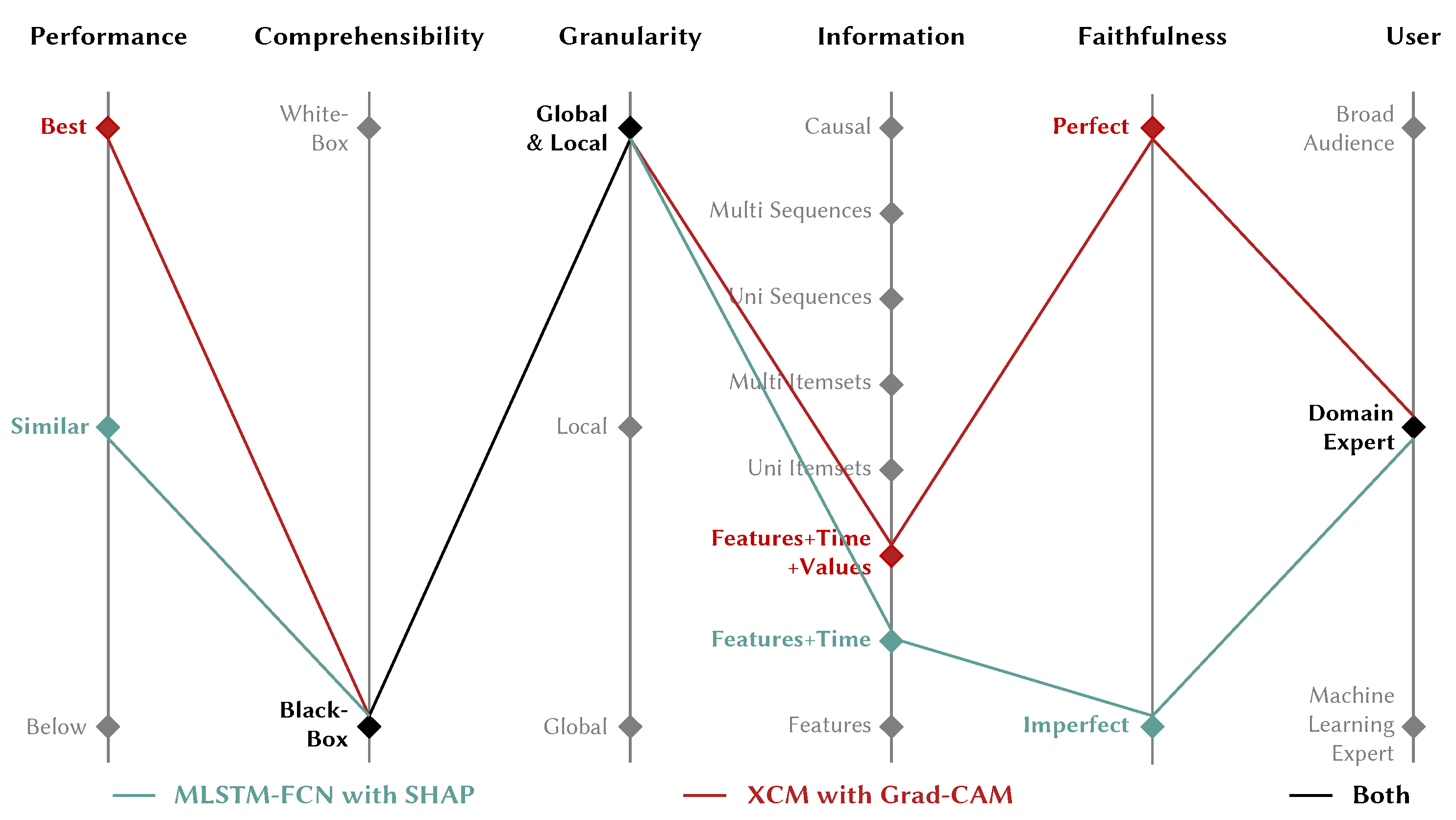
- Fauvel, K.; Masson, V.; Fromont, É. A Performance-Explainability Framework to Benchmark Machine Learning Methods: Application to Multivariate Time Series Classifiers. In Proceedings of the IJCAI-PRICAI 2020 Workshop on Explainable AI, Virtual Event, 8 January 2021. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ED | DTW | MLSTM FCN | MTEX CNN | WEASEL+ MUSE | XCM | |
|---|---|---|---|---|---|---|
| Performance | ||||||
| Small Datasets | ✓ | ✓ | ||||
| Large Datasets | ✓ | ✓ | ||||
| Explainability | ||||||
| Faithful Explainability | ✓ | ✓ | ✓ | ✓ |
| Datasets | Type | Train | Test | Length | Dimensions | Classes |
|---|---|---|---|---|---|---|
| Articulary Word Recognition | Motion | 275 | 300 | 144 | 9 | 25 |
| Atrial Fibrilation | ECG | 15 | 15 | 640 | 2 | 3 |
| Basic Motions | HAR | 40 | 40 | 100 | 6 | 4 |
| Character Trajectories | Motion | 1422 | 1436 | 182 | 3 | 20 |
| Cricket | HAR | 108 | 72 | 1197 | 6 | 12 |
| Duck Duck Geese | AS | 60 | 40 | 270 | 1345 | 5 |
| Eigen Worms | Motion | 128 | 131 | 17,984 | 6 | 5 |
| Epilepsy | HAR | 137 | 138 | 206 | 3 | 4 |
| Ering | HAR | 30 | 30 | 65 | 4 | 6 |
| Ethanol Concentration | Other | 261 | 263 | 1751 | 3 | 4 |
| Face Detection | EEG/MEG | 5890 | 3524 | 62 | 144 | 2 |
| Finger Movements | EEG/MEG | 316 | 100 | 50 | 28 | 2 |
| Hand Movement Direction | EEG/MEG | 320 | 147 | 400 | 10 | 4 |
| Handwriting | HAR | 150 | 850 | 152 | 3 | 26 |
| Heartbeat | AS | 204 | 205 | 405 | 61 | 2 |
| Insect Wingbeat | AS | 30,000 | 20,000 | 200 | 30 | 10 |
| Japanese Vowels | AS | 270 | 370 | 29 | 12 | 9 |
| Libras | HAR | 180 | 180 | 45 | 2 | 15 |
| LSST | Other | 2459 | 2466 | 36 | 6 | 14 |
| Motor Imagery | EEG/MEG | 278 | 100 | 3000 | 64 | 2 |
| NATOPS | HAR | 180 | 180 | 51 | 24 | 6 |
| PenDigits | Motion | 7494 | 3498 | 8 | 2 | 10 |
| PEMS-SF | Other | 267 | 173 | 144 | 963 | 7 |
| Phoneme | AS | 3315 | 3353 | 217 | 11 | 39 |
| Racket Sports | HAR | 151 | 152 | 30 | 6 | 4 |
| Self Regulation SCP1 | EEG/MEG | 268 | 293 | 896 | 6 | 2 |
| Self Regulation SCP2 | EEG/MEG | 200 | 180 | 1152 | 7 | 2 |
| Spoken Arabic Digits | AS | 6599 | 2199 | 93 | 13 | 10 |
| Stand Walk Jump | ECG | 12 | 15 | 2500 | 4 | 3 |
| U Wave Gesture Library | HAR | 120 | 320 | 315 | 3 | 8 |
| Datasets | XC | XC Seq | MC | MF | WM | ED | DW | DW | ED (n) | DW (n) | DW (n) | XC Parameters | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Batch | Win % | ||||||||||||
| Articulary Word Recognition | 98.3 | 92.7 | 92.3 | 98.6 | 99.3 | 97.0 | 98.0 | 98.7 | 97.0 | 98.0 | 98.7 | 32 | 80 |
| Atrial Fibrilation | 46.7 | 33.3 | 33.3 | 20.0 | 26.7 | 26.7 | 26.7 | 20.0 | 26.7 | 26.7 | 22.0 | 1 | 60 |
| Basic Motions | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 67.5 | 100.0 | 97.5 | 67.6 | 100.0 | 97.5 | 32 | 20 |
| Character Trajectories | 99.5 | 98.8 | 97.4 | 99.3 | 99.0 | 96.4 | 96.9 | 99.0 | 96.4 | 96.9 | 98.9 | 32 | 80 |
| Cricket | 100.0 | 93.1 | 90.3 | 98.6 | 98.6 | 94.4 | 98.6 | 100.0 | 94.4 | 98.6 | 100.0 | 32 | 20 |
| Duck Duck Geese | 70.0 | 52.5 | 65.0 | 67.5 | 57.5 | 27.5 | 55.0 | 60.0 | 27.5 | 55.0 | 60.0 | 8 | 80 |
| Eigen Worms | 43.5 | 45.0 | 41.9 | 80.9 | 89.0 | 55.0 | 60.3 | 61.8 | 54.9 | 61.8 | 32 | 40 | |
| Epilepsy | 99.3 | 93.5 | 94.9 | 96.4 | 99.3 | 66.7 | 97.8 | 96.4 | 66.6 | 97.8 | 96.4 | 32 | 20 |
| Ering | 13.3 | 13.3 | 13.3 | 13.3 | 13.3 | 13.3 | 13.3 | 13.3 | 13.3 | 13.3 | 13.3 | 32 | 20 |
| Ethanol Concentration | 34.6 | 31.6 | 30.8 | 29.4 | 31.6 | 29.3 | 30.4 | 32.3 | 29.3 | 30.4 | 32.3 | 32 | 80 |
| Face Detection | 63.9 | 63.8 | 50.0 | 57.4 | 54.5 | 51.9 | 51.3 | 52.9 | 51.9 | 52.9 | 32 | 60 | |
| Finger Movements | 60.0 | 60.0 | 49.0 | 61.0 | 54.0 | 55.0 | 52.0 | 53.0 | 55.0 | 52.0 | 53.0 | 32 | 40 |
| Hand Movement Direction | 44.6 | 40.1 | 18.9 | 37.8 | 37.8 | 27.9 | 30.6 | 23.1 | 27.8 | 30.6 | 23.1 | 32 | 80 |
| Handwriting | 41.2 | 38.6 | 24.6 | 54.9 | 53.1 | 37.1 | 50.9 | 60.7 | 20.0 | 31.6 | 28.6 | 32 | 60 |
| Heartbeat | 77.6 | 74.1 | 72.2 | 71.4 | 72.7 | 62.0 | 65.9 | 71.7 | 61.9 | 65.8 | 71.7 | 32 | 80 |
| Insect Wingbeat | 10.5 | 10.5 | 10.5 | 10.5 | 12.8 | 11.5 | 12.8 | 32 | 20 | ||||
| Japanese Vowels | 98.6 | 94.6 | 95.1 | 99.2 | 97.8 | 92.4 | 95.9 | 94.9 | 92.4 | 95.9 | 94.9 | 32 | 80 |
| Libras | 84.4 | 79.4 | 81.1 | 92.2 | 89.4 | 83.3 | 89.4 | 87.2 | 83.3 | 89.4 | 87.0 | 32 | 80 |
| LSST | 61.2 | 54.2 | 31.5 | 64.6 | 62.8 | 45.6 | 57.5 | 55.1 | 45.6 | 57.5 | 55.1 | 32 | 100 |
| Motor Imagery | 54.0 | 53.0 | 50.0 | 53.0 | 50.0 | 51.0 | 39.0 | 50.0 | 51.0 | 50.0 | 8 | 40 | |
| NATOPS | 97.8 | 93.9 | 88.3 | 96.7 | 88.3 | 85.0 | 85.0 | 88.3 | 85.0 | 85.0 | 88.3 | 32 | 40 |
| PenDigits | 99.1 | 96.7 | 87.8 | 99.0 | 96.9 | 97.3 | 93.9 | 97.7 | 97.3 | 93.9 | 97.7 | 8 | 60 |
| PEMS-SF | 75.7 | 80.9 | 11.6 | 69.9 | 70.5 | 73.4 | 71.1 | 70.5 | 73.4 | 71.1 | 32 | 80 | |
| Phoneme | 22.5 | 11.9 | 2.6 | 27.5 | 19.0 | 10.4 | 15.1 | 15.1 | 10.4 | 15.1 | 15.1 | 32 | 40 |
| Racket Sports | 89.5 | 86.8 | 82.9 | 89.4 | 91.4 | 86.4 | 84.2 | 80.3 | 86.8 | 84.2 | 80.3 | 32 | 80 |
| Self Regulation SCP1 | 87.8 | 81.6 | 78.5 | 86.7 | 74.4 | 77.1 | 76.5 | 77.5 | 77.1 | 76.5 | 77.5 | 32 | 80 |
| Self Regulation SCP2 | 54.4 | 55.0 | 50.0 | 52.2 | 52.2 | 48.3 | 53.3 | 53.9 | 48.3 | 53.3 | 53.9 | 32 | 80 |
| Spoken Arabic Digits | 99.5 | 99.4 | 98.6 | 99.4 | 98.2 | 96.7 | 96.0 | 96.3 | 96.7 | 95.9 | 96.3 | 32 | 80 |
| Stand Walk Jump | 40.0 | 46.7 | 53.3 | 46.7 | 33.3 | 20.0 | 33.3 | 20.0 | 20.0 | 33.3 | 20.0 | 32 | 60 |
| U Wave Gesture Library | 89.4 | 81.9 | 81.2 | 86.3 | 90.3 | 88.1 | 86.9 | 90.3 | 88.1 | 86.8 | 90.3 | 32 | 100 |
| Average Rank | 2.3 | 5.0 | 7.2 | 3.5 | 4.0 | 7.1 | 5.9 | 4.8 | 7.4 | 6.4 | 5.3 | ||
| Wins/Ties | 16 | 4 | 3 | 7 | 7 | 2 | 2 | 4 | 2 | 2 | 3 | ||
| XCM | MLSTM-FCN | Commercial Solution | |
|---|---|---|---|
| F1-Score | 69.7 ± 1.5 | 63.1 ± 1.5 | 55.3 ± 5.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fauvel, K.; Lin, T.; Masson, V.; Fromont, É.; Termier, A. XCM: An Explainable Convolutional Neural Network for Multivariate Time Series Classification. Mathematics 2021, 9, 3137. https://doi.org/10.3390/math9233137
Fauvel K, Lin T, Masson V, Fromont É, Termier A. XCM: An Explainable Convolutional Neural Network for Multivariate Time Series Classification. Mathematics. 2021; 9(23):3137. https://doi.org/10.3390/math9233137
Chicago/Turabian StyleFauvel, Kevin, Tao Lin, Véronique Masson, Élisa Fromont, and Alexandre Termier. 2021. "XCM: An Explainable Convolutional Neural Network for Multivariate Time Series Classification" Mathematics 9, no. 23: 3137. https://doi.org/10.3390/math9233137