1. Introduction
Survey sampling theory, since its foundation in the 20th century with the works of Jerzy Neyman [
1,
2], has been the gold standard for applied research in the empirical sciences. Its methods have been primarily developed for contexts where a probability sampling is feasible; under this assumption, survey sampling methods allow us to obtain reliable estimates from a sample of a population, with an associated measure of the variability that arises from the randomness of the sample.
Traditional questionnaire administration modes, such as face-to-face or telephone surveys, have met (to a large extent) the conditions that guarantee probability sampling for a long time. However, in the last few years the winds of change have brought other data sources into the picture in response to the growing issues of those traditional modes (such as drops in response rates or increase of costs). The increasing prevalence of nonprobability surveys, such as web panels, interception surveys or large volume datasets collected automatically that are often used in big data (e.g., lists of tweets or transactions), has brought positive aspects like reducing survey time and cost per respondent, as well as enabling more possibilities for questionnaire design. On the other hand, collecting a strict probability sample using such methods is largely difficult because of the frame undercoverage that arises from drawing the sample from a subset of the target population (such as internet users) and the fact that the respondents are self-selected for many of those methods. These issues make methods for nonprobability samples even more important.
When using the aforementioned data sources for finite population inference, adjusting for selection bias should be considered. Among the various techniques to remove bias in web surveys, we could underline propensity score adjustment (PSA). This method, originally developed for reducing selection bias in non-randomized clinical trials [
3], is commonly used for dealing with missing data [
4], and was adapted to nonprobability surveys in the work of [
5,
6]. Among the alternatives, we could mention the statistical matching method, which is also known as
mass imputation in the literature, which was developed in [
7] as a technique to address selection bias in web surveys by means of predictive modelling.
These methods are often used using logistic models (to estimate the propensity to participate in the survey of each individual) and linear regressions (to predict the values of the interest variable), which may entail several disadvantages for large populations in comparison to modern prediction methods such as ML algorithms.
In recent decades, numerous machine learning (ML) methods have emerged that have proven to be more suitable for regression and classification than linear regression methods. Although there has been an exponential increase in the use of these techniques in many areas [
8,
9,
10], their application in the context of sampling in finite populations has been limited. A model-assisted estimator based on a neural network with skip-layer connections was developed in [
11]. A design-based model-assisted estimator using KNN (K-nearest neighbor method) was developed in [
12,
13]. Spline regression and random forests in post-stratification were used in [
14]. The effects of bagging on non-differentiable survey estimators including sample distribution functions and quantile were invesigated in [
15].
Recently, ML algorithms have been considered in the literature for the treatment of nonprobability samples. A simulation study using certain ML predictive algorithms (decision trees, k-nearest neighbors, Naive Bayes, Random Forest and Gradient Boosting Machine) is performed in [
16]. Their findings showed that ML methods have the potential to remove selection bias in nonprobability samples to a greater extent than logistic regression in some scenarios. This view had been previously supported by [
17]. The use of linear models and some ML algorithms in PSA to estimate propensities and in imputation for statistical matching was compared in [
18]. Other recent papers that use Regression Trees and boosting algorithms to remove bias in web surveys are [
19,
20].
A common machine learning algorithm under the Gradient Boosting framework is XGBoost [
21]. The use of this algorithm is motivated by the promising results obtained with boosting algorithms in general and Gradient Boosting Machines (GBM) in particular; for instance, the simulation study from [
16] showed that Gradient Boosting Machines can lead to selection bias reductions in situations of high dimensionality, or where the selection mechanism is Missing At Random (MAR). Boosting algorithms have been applied in propensity score weighting for non-randomized experiments, including Gradient Boosting Machines [
22,
23,
24,
25,
26,
27], showing on average better results than conventional parametric regression models. Given its theoretical advantage over GBM, which could lead to even better results in a broader range of situations, XGBoost will be used for this research to test its adequacy for mitigating selection bias in volunteer samples and lay a baseline performance result. We will apply this algorithm for several estimators based on different approaches.
The paper is organized as follows. In
Section 2, the existing methods for correcting selection bias in volunteer samples using a reference probability sample are described. In
Section 3, the XGBoost method is presented and its use for estimating population mean in our context is proposed. The results from several simulation studies are presented in
Section 4. An application to a real survey is presented in
Section 5. Finally, the findings and their implications are discussed in
Section 6.
2. Context
Let U denote a finite population of size N, . Let be a convenience (or volunteer) nonprobability sample of size . Let y be the variable of interest in the survey estimation.
The population mean,
, can be estimated with the naive estimator based on the sample mean of
y in
:
If the convenience sample
suffers from selection bias, this estimator will provide biased results. This can happen if there is an important fraction of the population with zero chance of being included in the sample (coverage bias) and if there are significant differences in the inclusion probabilities among the different members of the population (selection bias) [
28,
29].
Let be a reference sample of size selected from U under a probability sampling design with (where denotes the samples which contain the unit i) the first order inclusion probability for individual i, we denote by the design weights for the units in the reference sample. Let be the values presented by individual i for a vector of covariates . Those covariates are common to both samples, while we only have measurements of the variable of interest y for the individuals in the convenience sample.
In this context, propensity score adjustment (PSA) can be used to reduce the selection bias that would affect the unweighted estimates. This approach aims to estimate the propensity of an individual to be included in the nonprobability sample by combining the data from both samples,
and
, and training a predictive model on the variable
, with
if
and
if
. PSA assumes that the selection mechanism of
is ignorable and follows a parametric model:
for some vector
. The procedure is to estimate the parameter
by using logistic regression and transform the estimated propensities to weights by inverting them
where
is the estimated propensity for the individual
based on logistic regression. Thus the inverse propensity score weighting estimator (IPSW) [
30] is:
Propensities can be transformed into weights using other procedures, such as stratifying the vector of propensities to form groups of individuals with similar propensities and assign all individuals in a group the same weight [
6,
31].
If the design weights are used in the computation of
, the estimator
is valid provided the participation rate is small, given that the optimization procedure leads to the pseudologlikelihood function developed in [
32] which provides an unbiased and consistent estimator of the propensities except for an extra term that depends on the size of
relative to
U, and therefore can be considered as negligible if
. A modification of PSA is the TrIPW estimator developed in [
19], that uses a modified version of the Classification And Regression Trees (CART) algorithm [
33], and does not require the participation rate to be small. Although IPSW and TrIPW can be considered PSA approaches, the methodology of the latter is slighty different, as it takes into account design weights in the tree building by definition, while in the IPSW approach it is not required to use design weights. The propensity for each individual
is estimated as:
where
represents the terminal node of the CART algorithm trained on
U in which
i-th individual of
lies. The formula above represents the proportion of population individuals that would be classified in the terminal node 1 and also belong to
. Given that
is not available, the propensity described above has to be estimated from the information contained in the available samples using a modified CART algorithm and estimating proportions by taking design weights into account to be used for estimating population and subpopulation sizes as follows:
where
is the first order inclusion probability for individual
j in
. The equation above substitutes the unknown number of individuals from the population that would fit in
by its estimated value through the sum of the sampling weights of individuals from
that belong to
. These values
are now used to construct a Hajek type estimator of
as:
where
. This non-parametric approach shows acceptable results under non-linearity conditions [
19].
In a similar way to PSA, propensity scores are used to measure the similarity between the covariates of the probabilistic and nonprobability samples. The new approach is called Kernel Weighting [
34]. These propensity scores were made through the use of logistic regression, as explained previously.
For
we compute the distance of its estimated propensity score from each
i in the nonprobability sample (whose result varies from −1 to 1) as:
Then, a zero-centered kernel function is applied to smooth distances. Thus, the pseudoweights can be calculated:
where
is the applied kernel function (i.e., Gaussian):
and
h is the bandwidth. To calculate the optimal bandwidth, Silverman’s method is used [
35]:
where
is the square root of the variance,
IQR is the interquartile range and
n is the length of the distances vector. Finally the KW weight is given by:
and the
KW estimator of the population mean is:
Another variation of KW is Boosted Kernel Weighting. Its only difference is the usage of machine learning instead of logistic regression to get the propensities [
20]. These authors use four ML methods: model-based recursive partitioning, conditional random forests, gradient boosting machines and model-based boosting to estimate propensities and deduce in their simulation study that boosting methods result in KW with lower bias in several settings without increasing variance.
PSA is often used for reducing selection bias in nonprobability surveys, but empirical evidence of its effectiveness is mixed. A study with four web panel surveys was developed in [
36], showing that the reduction in bias is likely to be partial and unpredictable. Alternative methods for selection bias adjustment are based in superpopulation models. Statistical matching (SM) is an approach developed by [
7] and applied to nonresponse treatment in [
37]. This method aims to predict
y in the probability sample (where
y has not been measured) using covariates
and the volunteer sample
to fit the models that will be used to predict values of
y in the reference sample. SM assumes that
y is a realization of a superpopulation random variable
Y, which follows a functional relationship with the set of covariates
such that:
It is often assumed that the relationship between
y and
is linear, meaning that
, the random vector
is assumed to have zero mean and the coefficients
can be estimated by the usual methods in linear regression such as Ordinary Least Squares or maximum likelihood. The matching estimator is then given by:
where
the imputed value of
and
the design weight of the individual
i in
.
It remains unclear which of the two methods (PSA or SM) is more efficient, although a recent experiment by [
18] showed a higher efficiency of statistical matching.
Recently, [
32] proposed a new doubly robust estimator based on the previous linear model (
13), and showed that this estimator can be conveniently used for inferences from nonprobability samples. The estimator is defined as:
This estimator follows the idea of the model-assisted generalized difference estimator given in [
38] and has the property of being robust to modelling misspecifications either in the propensity estimation or in the matching imputation.
Alternatively, a more direct method has been proposed in [
39] to combine SM and PSA. The main idea is to use PSA weights in the predictive models used in Statistical Matching, given that those models use the nonprobability sample as training data. This is a feasible strategy given that most machine learning algorithms allow the weighting of the training data. For example, the previous linear model (
13) can minimize a weighted Mean Square Error instead. Let
the value of
imputed by a model trained that uses
as training weights. The proposed estimator will be:
In the next section we introduce a powerful machine learning technique that can be used both for predicting the unknown values in the probability sample (which can be used to obtain the imputed values in the estimators described previously) and also for calculating the propensity scores.
3. XGBoost Estimators
We assume that covariates have been measured on both samples, while the variable of interest y has been measured only in the volunteer sample, .
We will use XGBoost to obtain the imputed values in the matching estimator. XGBoost is a widely known state-of-the-art machine learning system for several problems. For example, it was used in 17 out of 29 winning solutions published during 2015 at Kaggle, a famous machine learning platform for hosting competitions [
21].
It works as a decision tree ensemble. Decision trees set split points based on until reaching a final estimation of .
As described in the original paper [
21], when they work as an ensemble model the final prediction is defined as follows:
where
K is the number of trees forming the ensemble and
; with
representing the structure of each tree which, given
, returns its corresponding final node and
the score on the
i-th final node. The final prediction is the sum of the scores obtained.
The trees
,
, are built aiming to minimize the following regularized objective function:
where the first term
l is a differentiable convex function which measures the error of the estimations. For example, when estimating a quantitative variable, the squared error can be used:
The second term regularizes the function penalizing complex trees. It penalizes having too many final nodes (
T) and returning too high scores:
where
and
are hyperparameters which control how much is this regularization prioritized to control overfitting [
40] over minimizing the error for the training set.
The objective function is minimized iteratively with the Gradient Tree Boosting method [
41]. For the
t-th iteration,
is added in order to minimize the following objective:
where
is the estimated value of
y for the
i-th unit in the
t-th iteration. This objective is optimized via second-order approximation [
42]:
where
and
.
In practice, it is impossible to evaluate every possible tree structure
q. The loss reduction caused by a potential split point is calculated instead as:
where
and
are the sets of units corresponding to the left and right side of the split, and
. Split points are added iteratively based on this formula.
XGBoost implements Gradient Tree Boosting with several techniques which improve its efficiency and efficacy. These include shrinkage (in order to limit the influence of each individual tree) and advanced strategies for finding split point candidates, among others [
21].
By imputing missing values in the target variable for individuals in the probability sample with their corresponding predicted value, we propose the following SM estimator for the population mean
:
where
the predicted value of
.
Other possibility to make estimators is to consider the idea of generalized difference estimator [
43] where an additional term is added to the
estimator that takes into account the error made in the estimates given by the model from the nonprobabilistic sample (since in this sample we have the true and the estimated values for
y).
Following this idea we propose the estimator:
where
. This estimator is similar to the the doubly robust estimator by [
32], but they use parametric regression models for estimating
.
XGBoost also allows weighting the training data. First we estimate the propensities by logistic regression. Then, the model is trained using the weights
in the objective function. Let
be the value of
imputed by said model. Finally, we make the XGT-estimator:
Finally, a new kernel weighting estimator
can be considered, as detailed in (
12), but using XGBoost for estimating propensities. That is, the proposed estimator is formulated as:
where
and
are calculated as in (
8) but the propensities
are estimated using the XGBoots method as
where
representing the structure of each tree and
the covariates used for modelling the propensities (that may or may not coincide with the variables used to predict the outcome variable
y).
The proposed XGBoost estimators (
24)–(
27) are computationally similar, given that the algorithm does the same work in all of them. However, the XGBoosted kernel weighting variant will be computationally preferable when there are many variables to estimate because only one model has to be trained in order to calculate the weights. Even though XGBoost models are more expensive to train than linear models, training time is insignificant for a single model in any modern processor. However, the difference could be significant when many models have to be trained. The efficiency of each method can be studied by analyzing the variance of the resulting estimator; however, that variance cannot be developed in simple form. Alternatively, resampling methods can be applied to each of the proposed estimators to estimate the variance (see [
44]).
3.1. Hyperparameter Optimization
The XGBoost algorithm contains several tuning hyperparameters which determine its functioning for each specific case. Its default values may be used. However, poor results may be obtained due to the fact that said default values are not suitable for some cases. In order to determine its real potential, we will also consider a hyperparameter optimization process for the matching estimator and for the Boosted Kernel Weighting estimator . This will also determine how relevant these kind of optimizations can be.
The process will be carried out via the Tree-structured Parzen Estimator (TPE) algorithm [
45]. Each tested hyperparameters set will be validated calculating its Rooted Mean Squared Error for several simulations in order to determine the optimal values. In a real case scenario, simulations cannot be carried out and therefore this strategy should be replaced with cross-validation techniques [
46].
Among the wide variety of parameters considered by XGBoost, we have selected the most important ones for the search space:
Number of estimators : How many trees form the ensemble. The default value is 100.
Learning rate : How much weight shrinkage is applied after each boosting step. The default value is 0.3.
Maximum depth : How many splits can each tree contain. The default value is 6.
Minimum child weight : How much instance weight is needed in total to consider a new partition. The default value is 1.
4. Simulation Study
4.1. Simulated Populations
Several simulation experiments are performed in order to demonstrate how much XGBoost can improve the estimations obtained with classic logistic/linear regression.
The first experiment replicates the simulated populations used in the study by [
47]. The populations and propensities proposed are replicated, but XGBoost is introduced as the machine learning algorithm used for each estimator proposed. This way, its performance can be compared with the results obtained using logistic/linear regression (the algorithm used in the original paper). The methodological rationale behind the use of this study is to explore the behavior of XGBoost in those situations where the relationship between covariates and target variables is non-linear, and therefore cannot be represented by linear regression if it is not explicitly stated by the practitioner when specifying the model. XGBoost (and other Machine Learning algorithms) are able to represent those non-linearities via boosted decision trees based on learning from data. On the other hand, using artificial data allows us to control the selection mechanisms and the relationships between variables, as well as assess their relevance in the final results. When using real data, these relationships can only be drawn in a conjectural way, although the results might be more representative of real world situations.
Therefore, three finite populations are generated following these models:
where
20,000,
,
and
; with
,
and
.
is the error term, controlled by
,
and
. Their values are adjusted in order to set the correlation coefficient,
, between
y with and without the error term at some desired level.
The propensities
for the nonprobabilistic samples are generated following these three models:
where
,
and
are set such that
for each case, with
the target sample size.
The probabilistic samples are obtained using inclusion probabilities proportional to , with c such that .
Using the described probabilities, a nonprobabilistic sample
of size
and a probabilistic sample
of size
are repeatedly drawn from the chosen population. The proposed estimators are applied with said samples so the metrics, relative bias (
) and mean square error (
), are obtained as follows:
where
is the mean estimated from the
b-th sample and
.
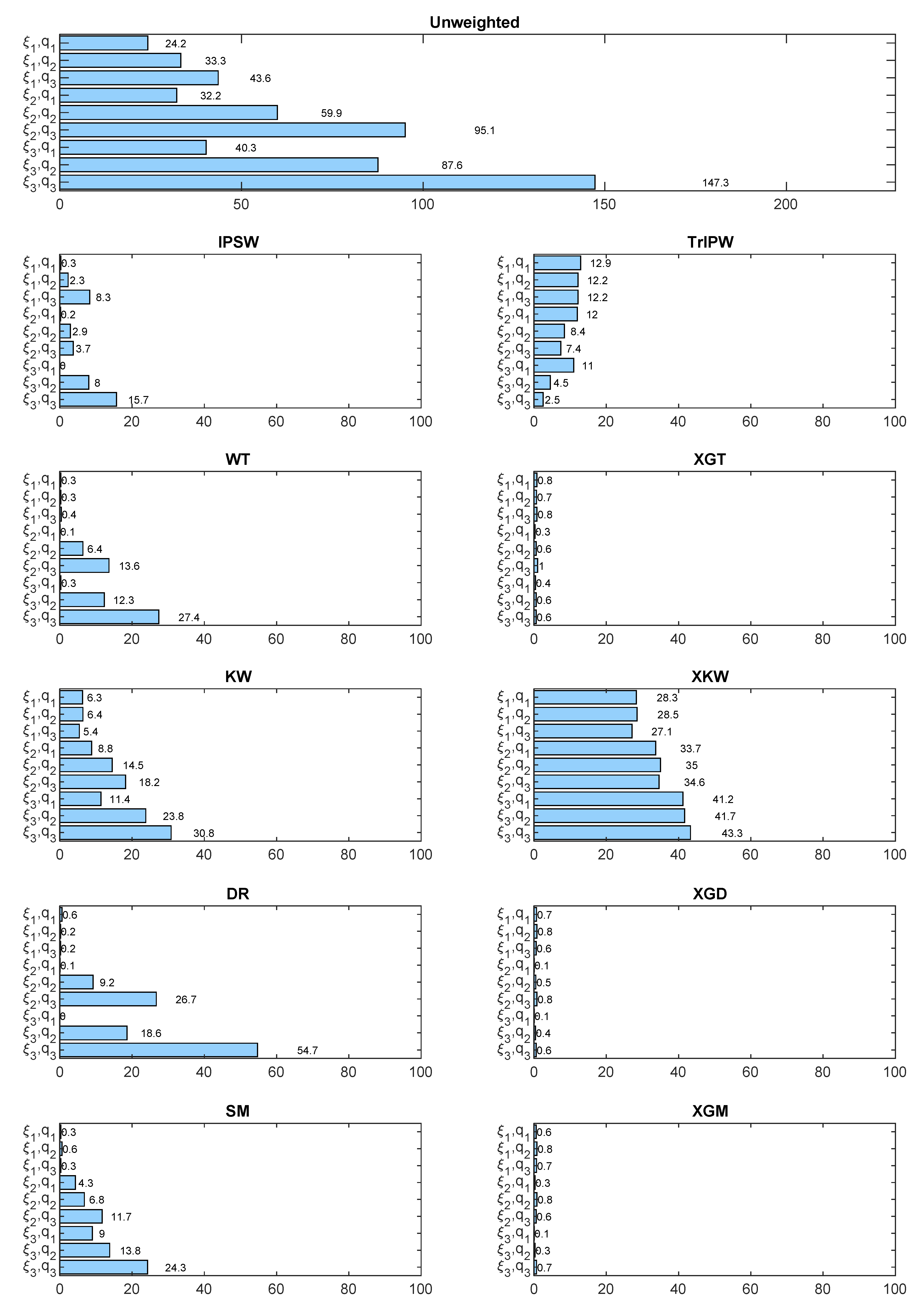
The estimators considered are: the unweighted sample mean (), IPSW with logistic regression (), Tree-Based Inverse Propensity Weighted estimation(), Kernel Weighting (), Matching with linear regression (), Doubly Robust with linear regression for Matching and logistic regression for PSA (), Training with linear regression for Matching and logistic regression for PSA (), XGBoosted kernel weighting (), Matching with XGBoost (), Doubly Robust with linear regression for PSA and XGBoost for Matching () and Training with linear regression for PSA and XGBoost for Matching (). For those using XGBoost, only its default hyperparameters are considered in this simulation.
Models and are linear models. Therefore, linear/logistic regression is theoretically unbeatable for those models. However, it can be observed that XGBoost can also effectively remove the bias in those cases. The difficulties of linear/logistic regression arise as the non-linearity of the models is increased. XGBoost is, however, still able to learn the model in those scenarios. The decrease in bias and MSE of the XGBoost technique with respect to linear/logistic regression is very noticeable in the case of the and model, and it is observed how this good behavior is accentuated as the correlation between the variables increases.
That is not the case for the
or
estimators. They seem to be suffering from overfitting [
40]. Further analysis from simulations considering real populations and hyperparameter optimization will determine if their performance can be fixed.
Regarding doubly robust estimators, again the high learning capacity of Matching with XGBoost causes that combining it with PSA does not necessarily improves the results. In practice, the complexity of real data models may change that fact.
4.2. Real Populations
Following the experiment described in the previous section, the study is repeated with real populations. The same estimators are considered. Default XGBoost hyperparameters are used for an initial simulation. The relative bias is kept as a metric but the mean squared error is replaced by the relative rooted mean squared error (
) in order to obtain comparable results.
Two datasets are used following two different sampling strategies for each one. In each simulation run, three possibilities for sample sizes, , and , are considered.
The first population, denoted as P1, corresponds to the Hotel Booking Demand Dataset [
48]. It includes the data of bookings for a resort hotel and a city hotel due to arrive between the 1 July 2015 and 31 August 2017. In total, it has 119,390 bookings of which 34% are from the resort hotel and 66% from the city hotel. For the first nonprobability sampling strategy, denoted as S1, resort bookings have 10 times more probability of being chosen than city bookings. For the second nonprobability sampling strategy, denoted as S2, city bookings have five times more probability of being chosen than resort bookings. The target variable is the mean number of weeknights (Friday included) which are booked. In order to estimate it, a probability sample
is also obtained via a simple random sampling. The remaining variables included in the dataset are used as covariates, excluding the reservation status and the reservation status date, with a total of 28 covariates.
The second population, denoted as P2, is the Adult Dataset [
49]. It includes census income information for 32,561 adult individuals from the 1994 Census database of the United States. For the first nonprobability sampling strategy, denoted as S1, individuals who make over
$50K a year have double the probability of being chosen. For the second nonprobability sampling strategy, denoted as S2, individuals who make over
$50K per year have a propensity to participate multiplied by
, where
a is the individual’s age. The target is estimating the proportion of individuals who make over
$50K per year. Therefore, in this case, the target variable in the dataset is binary instead of continuous. Also, in this scenario, the propensities depend on the target variable itself and this dependance may not even be linear. Every other variable in the dataset is used as covariate, for a total of 14 covariates. The probabilistic samples are obtained via simple random sampling.
The bias and relative rooted mean squared error results for each case with each estimator can be viewed in
Table 1 and
Table 2 respectively.
Again, as it happened with the simulated data, a significant improvement in the estimations can be observed when using XGBoost instead of linear or single tree regressors. This improvement is more relevant now since the datasets are more complex and closer to real scenarios. The results are also better, as more data is avaliable. In the majority of cases, the Matching based variants obtain the best results. However, for some specific cases, XGBoosted Kernel Weighting is better. This probably happens where the algorithm is not overlearning. This assumption is confirmed by later simulations considering hyperparameter optimization in which the methods always behave reliably.
Regarding doubly robust estimators, combining SM with PSA may yield slightly more accurate estimations in these cases with XGBoost as well. This improvement can be more noticeable if a more direct approach like is applied instead of a basic combination like .
Some of these results may be improved by applying variable selection, specifically those using linear of logistic regression. Tree based algorithms like XGBoost or CART apply variable selection internally by themselves.
Finally, as explained in
Section 3.1, hyperparameter optimization is also considered via the Tree-structured Parzen Estimator (TPE) algorithm [
45], as implemented in the software package
Optuna [
50]. The TPE algorithm is able to quickly discard inappropiate settings, so a wide search space may be specified. We have run simulations for the boosted matching estimator
and for the XGBoosted kernel weighting estimator
. The sample size for this scenario is 1000 since it is the hardest case. Each hyperparameter set evaluated by the algorithm is validated measuring its Mean Squared Error among 50 sub-simulations. Once the best values for each specific case are selected with this procedure, they are used for a new simulation in the same conditions as the one without optimization. Every real population and sampling strategy is considered.
The results can be observed in
Table 3 and
Table 4. The optimization considerably improves the estimations. In some cases, this improvement is so significant that the method which was the worst one without optimization is now the best alternative. Therefore, the importance of applying this kind of procedure is confirmed in order to obtain reliable results, especially for those estimators that have shown to suffer greatly from overlearning.
5. Application to a Survey on Social Effects of COVID-19 in Spain
This section illustrates the estimation procedures that we have empirically described in a web survey in which respondents were selected by targeting Internet ads at specific profiles.
ESPACOV [
51] is a survey that was conducted in Spain in the fourth week of the strict lockdown imposed on 14 March 2020, and provides information on the living conditions of the population, acquired habits, health and consequences of the state of alarm and home confinement. ESPACOV was run by the Institute for Advanced Social Studies (IESA) and the sample was collected via paid advertisements on Google Ads and Facebook/Instagram (nonprobability sampling). A total of 1881 interviews were completed.
Table 5 compares unweighted sample distributions by age group and sex and by education level with Spanish population data [
52,
53].
Due to coverage and participation bias, people with tertiary education are over-represented, and less educated people vastly under-represented. There are also representation issues in the different age groups for each sex.
We have considered the April 2020 Barometer of the Spanish Center for Sociological Research [
54] as the source of auxiliary information. The barometers are probability surveys carried out on a monthly basis, and their main objective is to measure Spanish public opinion at that time. They involve interviews with approximately 2500 randomly-chosen people from all over the country, with extensive social and demographic information on them being gathered for analysis as well as their opinions. The survey follows a multi-stage, stratified cluster sampling, with selection of the primary sampling units (municipalities) and of the secondary units (census sections) randomly with proportional allocation, and of the last units (individuals) by random routes and sex and age quotas. The barometer dataset is often viewed as a reliable source of official statistics and contains a number of common variables with the ESPACOV dataset. More precisely, these include gender, age, province, municipality size, education level, working status and self-positioning in the ideological scale (10-point Likert, where 1 represents “far left” and 10 “far right”).
We apply the proposed methods to estimate the population mean of the variable “Rate the government action to control the pandemic, from 0 to 10”. The values of the estimators
,
,
,
,
,
,
,
,
and
are computed for each variable. The unadjusted simple sample mean
from the nonprobability sample is also included. Results from using the common set of covariates which are available in both datasets are presented in
Table 6.
The results generally show that the application of bias correction techniques provides an important shift (towards a lower mean rate) with respect to the unweighted estimate, especially for those which were the most reliable ones during the simulations (
,
and
). Standard deviations were estimated via bootstraping [
44]. 2000 resamples with replacement are obtained in order to calculate the deviation for each method. They show a small and expectable increase in variance from the unweighted case except for the
estimator. As seen in the simulations, this behavior is to be expected and should be solved via hyperparameter tuning.
However, the chosen variable is closely related to the ideological scale covariate. We also apply the methods to estimate the population means of the variables, rating, from 1 to 5, the confidence in the following groups/institutions to manage the current health crisis: health workers, the armed forces, the police, the Spanish government and scientists. The results are presented in
Table 7. They show that the differences are not as significant when the target variables are not related to the covariates used.
6. Conclusions
A long and ongoing literature is concerned with the evaluation of selection bias in web surveys. Propensity scorse and matching estimators based on linear models are the established workhorses in this literature. The emerging literature in statistical learning might help to increase the precision of the estimates obtained by these methods.
Although machine learning methods have many well-documented advantages in prediction and classification, it is not obvious that using them for propensity scores and matching estimation in a nonprobability framework will reduce the bias in the estimation of parameters. In this work we present four different methods to estimate parameters based on the use of an important ML technique, the XGBoots method, to predict the values of the target variable in the probability sample and also to determine the propensities of participating in the nonprobability sample.
Our work contributes to the literature in evaluating the performance of classical and machine learning based PSA estimators, matching estimators as well as other methods of estimation from web survey data that are more innovative.
To be as close as possible to other recent estimation works in nonprobability surveys, we have replicated the experiment carried out by [
47]. When comparing results from both simulations, we observe that estimators involving XGBoost provide better results overall in certain non-linear situations in comparison to the case where linear models are used. These results are relevant considering that, in practice, models will rarely be linear. In fact, they will likely be much more complex than the ones considered in this simulation. For this reason, we compare the different estimators in two real datasets. We compared performance of XGBoost to a classical regression approach, with the former providing good results in terms of bias and Mean Square Error reduction.
Our findings are mixed. Our evidence suggests the usage of XGBoost is more powerful at removing selection bias in nonprobability samples than traditional linear regression models in scenarios where the propensity model is not linear and the auxiliary variables used for adjustments are related to both the propensity and the variable of interest. In addition, the simulations also show the efficiency of the use of recent training techniques like [
34,
39] compared to the alternatives of PSA, matching, and double robust [
32] techniques.
However, these results can also be unreliable when the algorithms suffer from overfitting. Hyperparameter optimization has shown to be highly effective at controlling this issue. These kind of procedures are therefore important when producing estimations. We will look further into this matter in future works.
The proposed method is also used to analyze a nonprobability survey sample on the social effects of COVID-19. The results of this application show that selection bias correction techniques have the potential to provide substantial changes in the estimates of population means in nonprobability samples.
In conclusion, the improved learning capacity of XGBoost is capable of significantly reducing bias and MSE in certain scenarios according to our simulations, but it is important to explore its limits with real use cases. Generally speaking, our results illustrate several methods to do inference with nonprobability samples and highlight the importance and usefulness of auxiliary information from probability survey samples. Propensity Score Adjustment and model-based methods are recommended when the sample can be subject to strong selection bias. XGBoost can yield more accurate predictions when the data behavior is more complex, which typically occurs in situations with high dimensionality. Those are the scenarios where we could particularly benefit the most from Xgboost, although it is suitable for most of the situations.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}