
An Attention-Based Generative Adversarial Network for Producing Illustrative Sketches



Abstract
:1. Introduction
- We present a GAN-based framework that produces illustrative sketch styles from various photographs. To facilitate its production, we apply two ideas: an attention map-based approach for style extraction and production and a relaxed cycle consistency to evaluate the produced styles.
- We present an efficient training strategy for illustrative sketch styles. Our framework is trained on a dataset of portraits, and can be applied to produce illustrative sketch styles from landscapes, animals or objects.
2. Related Work
2.1. Conventional Schemes for Illustrative Sketches
2.2. General DL Schemes for Illustrative Sketches
2.3. Dedicated DL Schemes for Illustrative Sketches
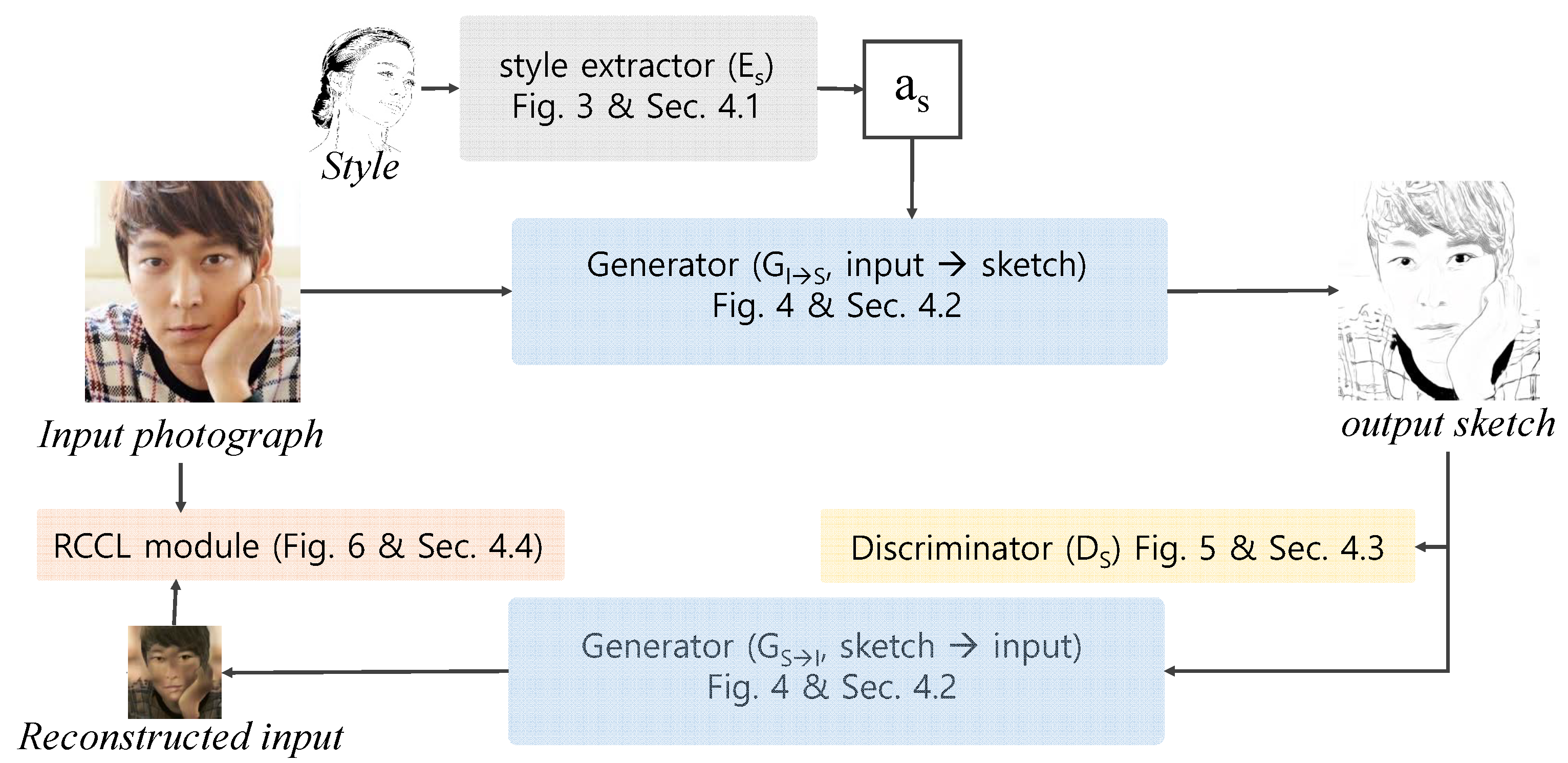
3. Outline of Our Framework
4. Modules of Our Framework
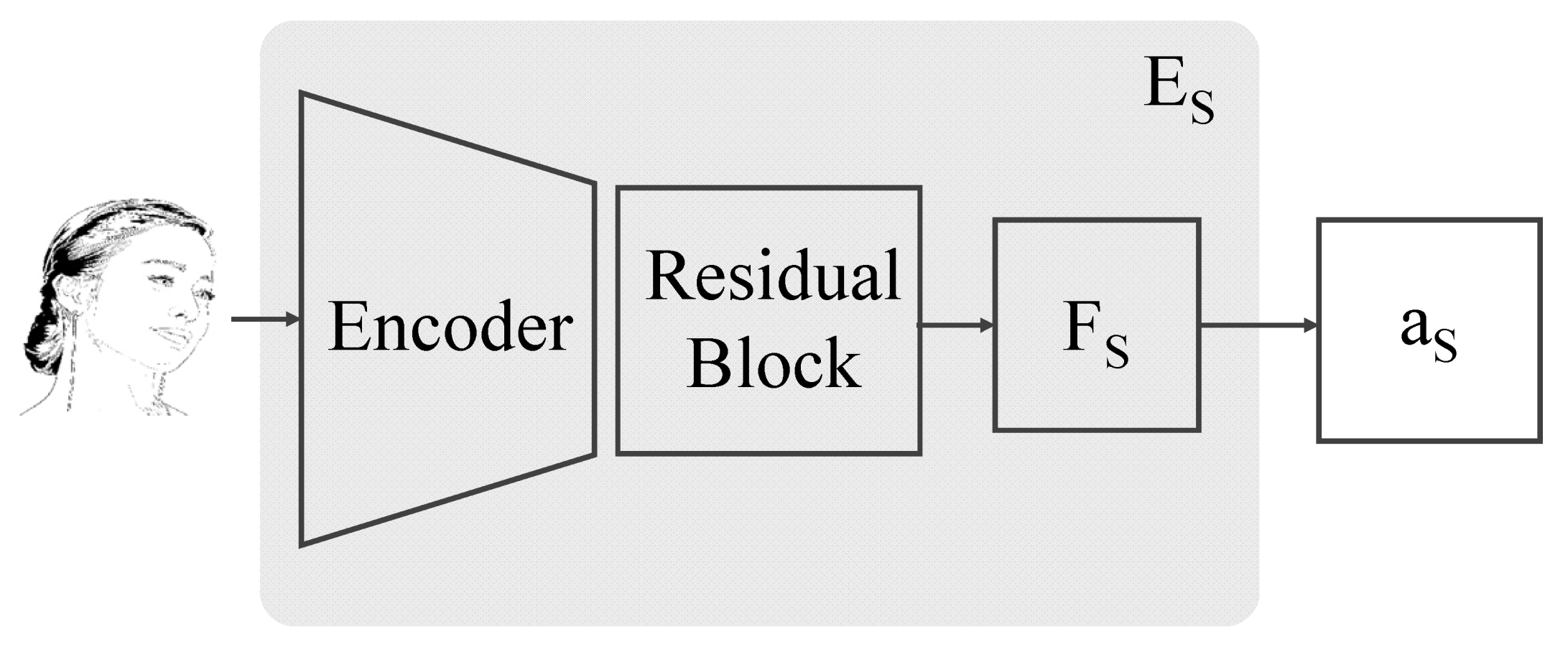
4.1. Style Extraction Module
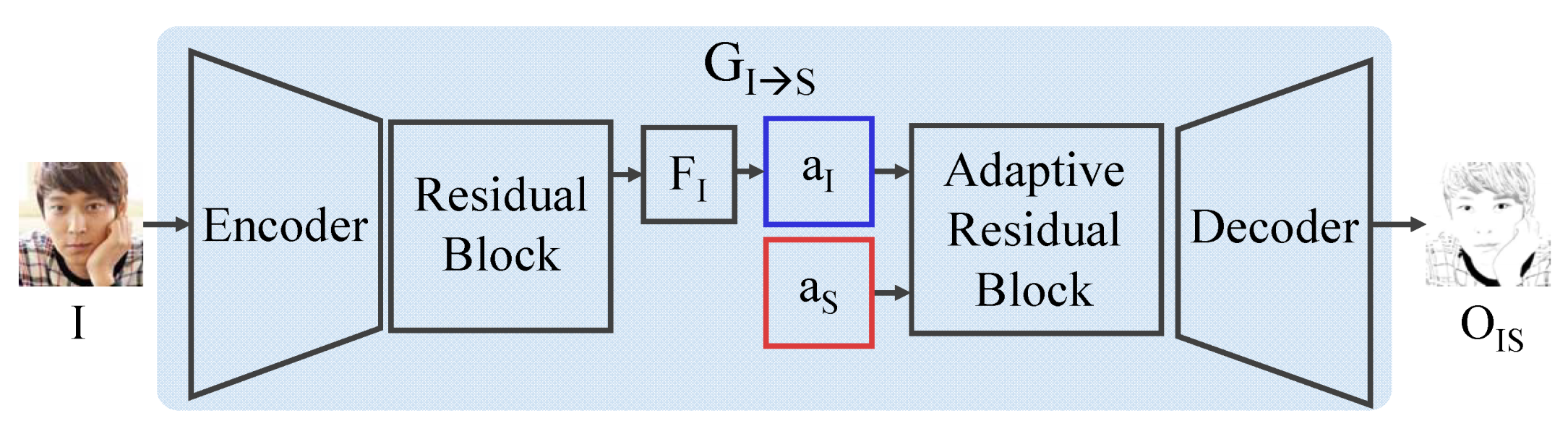
4.2. Generator
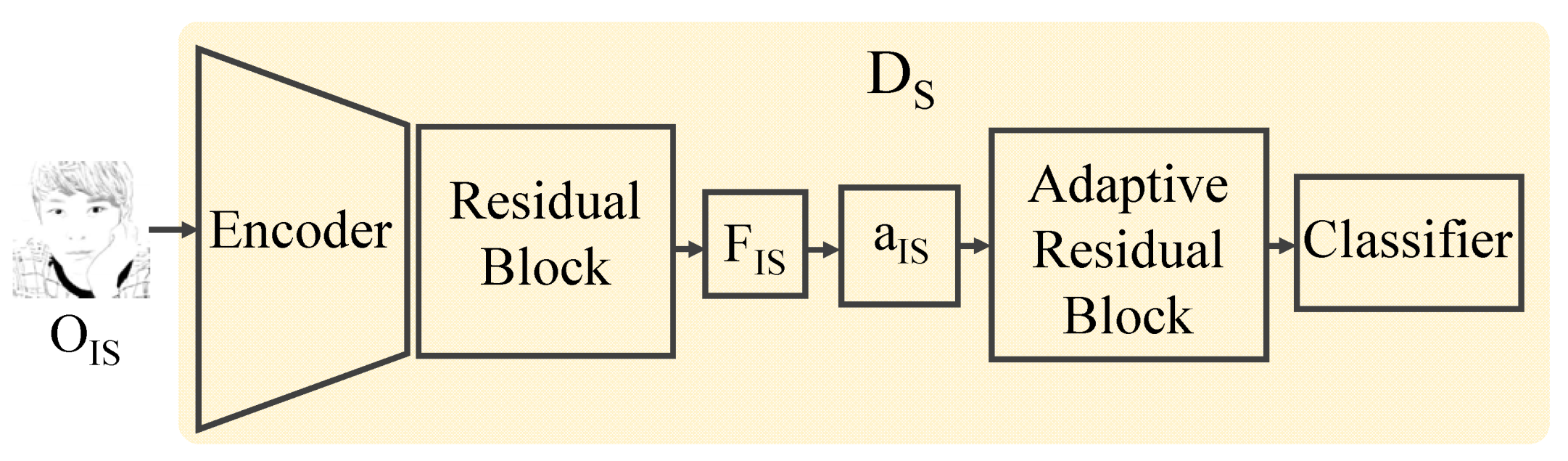
4.3. Discriminator
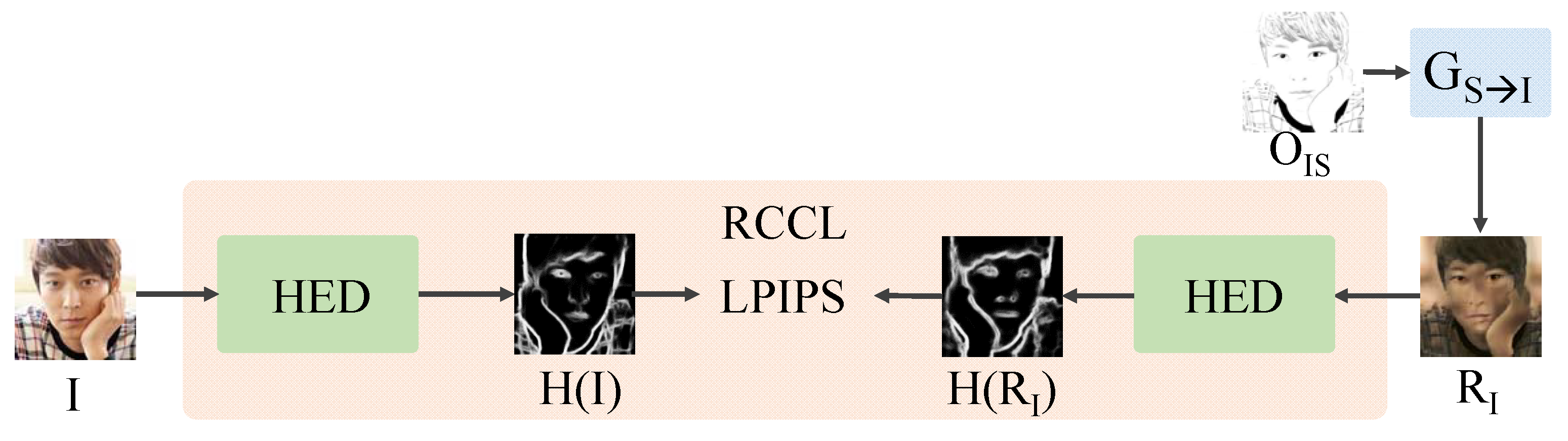
4.4. RCCL Module
5. Loss Function
5.1. Adversarial Loss
5.2. Cycle Consistency Loss
5.3. Identity Loss
5.4. CAM Loss
5.5. Total Loss
6. Implementation and Results
6.1. Training Dataset
6.2. Implementation Environments
6.3. Results
6.3.1. Results with Ground Truth
6.3.2. Results from Various Images
6.3.3. Comparison with Existing Works
6.3.4. Comparison with Commercial Apps
7. Analysis
7.1. Evaluations
7.1.1. Human Study
- (Q1: Quality) Which of the images looks most visually pleasing?
- (Q2: Similarity) Which of the images looks most similar to the input image in the rightmost column?
- (Q3: Artifact) Which of the images show the fewest artifacts?
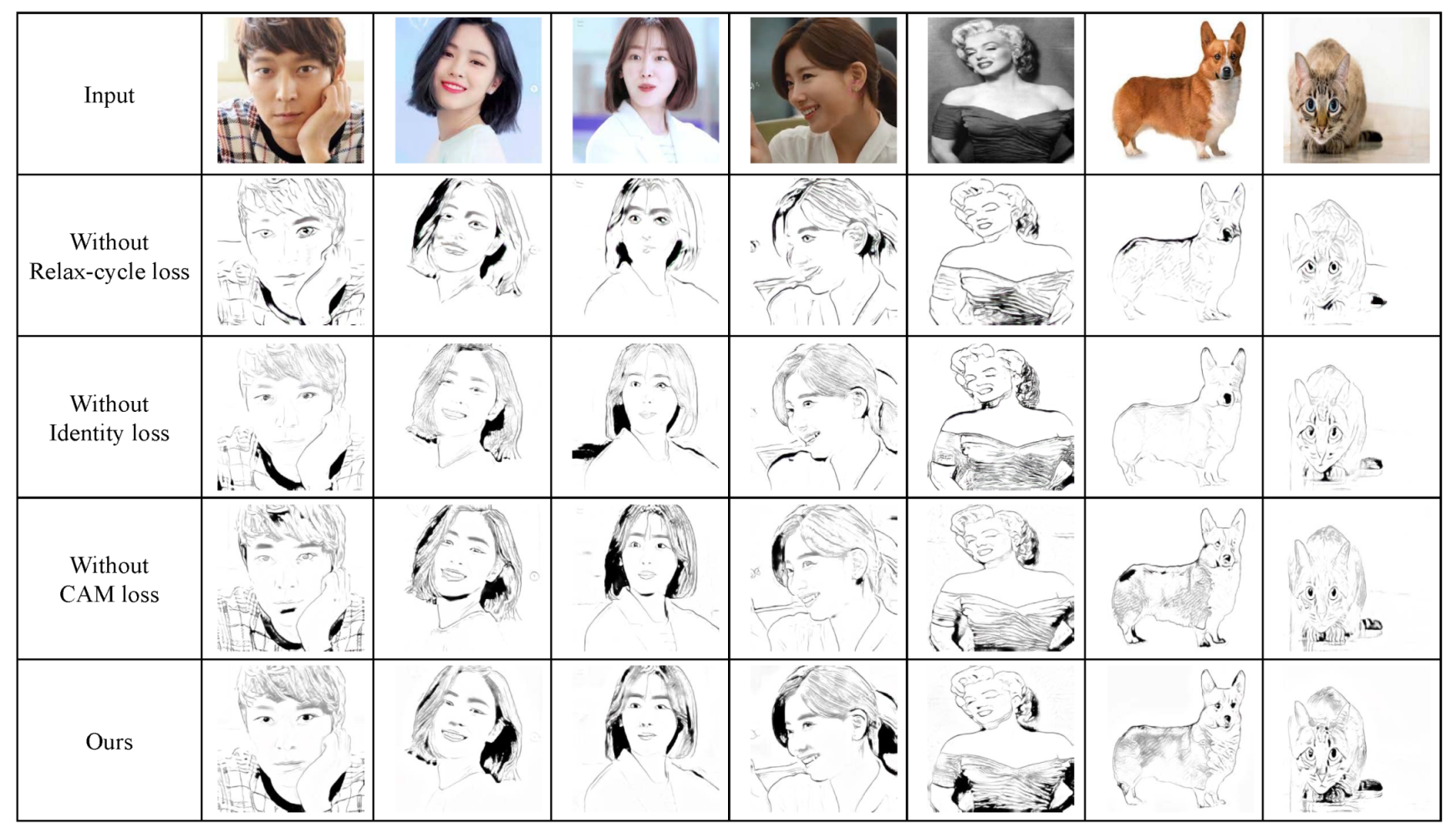
7.1.2. Ablation Study
7.1.3. FID Evaluation
7.2. Discussion
7.3. Limitation
8. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- DeCarlo, D.; Finkelstein, A.; Rusinkiewicz, S.; Santella, A. Suggestive Contours for Conveying Shape. ACM Trans. Graph. 2003, 22, 848–855. [Google Scholar] [CrossRef]
- Kang, H.; Lee, S.; Chui, C. Coherent Line Drawing. In Proceedings of the NPAR 2007, San Diego, CA, USA, 4–5 August 2007; pp. 43–50. [Google Scholar]
- Winnemoller, H.; Olsen, S.; Gooch, B. Real-time video abstraction. ACM Trans. Graph. 2006, 25, 1221–1226. [Google Scholar] [CrossRef]
- Winnemoller, H.; Kyprianidis, J.E.; Olsen, S.C. XDoG: An EXtended Difference-of-Gaussians Compendium Including Advanced Image Stylization. Comput. Graph. 2012, 36, 740–753. [Google Scholar] [CrossRef] [Green Version]
- Yang, H.; Kwon, Y.; Min, K. A Stylized approach for pencil drawing from photographs. Comput. Graph. Forum 2012, 31, 1471–1480. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 2223–2232. [Google Scholar]
- Huang, X.; Liu, M.Y.; Belongie, S.; Kautz, J. Multimodal unsupervised image-to-image translation. In Proceedings of the ECCV 2018, Munich, Germany, 8–14 September 2018; pp. 172–189. [Google Scholar]
- Yi, R.; Liu, Y.; Lai, Y.; Rosin, P.L. APDrawingGAN: Generating Artistic Portrait Drawings From Face Photos With Hierarchical GANs. In Proceedings of the CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 10735–10744. [Google Scholar]
- Yi, R.; Liu, Y.J.; Lai, Y.K.; Rosin, P.L. Unpaired Portrait Drawing Generation via Asymmetric Cycle Mapping. In Proceedings of the CVPR 2020, Online, 14–19 June 2020; pp. 8217–8225. [Google Scholar]
- Kim, Y.; Yu, J.; Yu, X.; Lee, S. Line-Art Illustration of Dynamic and Specular Surfaces. ACM Trans. Graph. 2008, 27, 156:1–156:10. [Google Scholar] [CrossRef]
- Paiva, A.; Brazil, E.; Petronetto, F.; Sousa, M.C. Fluid-based hatching for tone mapping in line illustrations. Vis. Comput. 2009, 25, 519–527. [Google Scholar] [CrossRef]
- Coconu, L.; Deussen, O.; Hege, H.-C. Real-Time Pen-and-Ink Illustration of Landscapes. In Proceedings of the NPAR 2006, Annecy, France, 5–7 June 2006; pp. 27–35. [Google Scholar]
- Xu, J.; Kaplan, C.S. Artistic thresholding. In Proceedings of the NPAR 2008, Annecy, France, 9–11 June 2008; pp. 39–47. [Google Scholar]
- Mould, D.; Grant, K. Stylized Black and White Images from Photographs. In Proceedings of the NPAR 2008, Annecy, France, 9–11 June 2008; pp. 49–58. [Google Scholar]
- Rosin, P.L.; Lai, Y.-K. Towards Artistic Minimal Rendering. In Proceedings of the NPAR 2010, Annecy, France, 7–10 June 2010; pp. 119–127. [Google Scholar]
- Benard, P.; Lu, J.; Cole, F.; Finkelstein, A.; Thollot, J. Active Strokes: Coherent Line Stylization for Animated 3D Models. In Proceedings of the NPAR 2012, Annecy, France, 4–6 June 2012; pp. 37–46. [Google Scholar]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. DualGAN: Unsupervised Dual Learning for Image-to-Image Translation. In Proceedings of the CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 2849–2857. [Google Scholar]
- Tang, H.; Xu, D.; Seba, N.; Yan, Y. Attention-Guided Generative Adversarial Networks for Unsupervised Image-to-Image Translation. In Proceedings of the IJCNN 2019, Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Xie, X.; Dong, Y.; Li, Y.; Wang, S. AT-GAN: Attention Transfer GAN for Image-to-Image Translation. In Proceedings of the 4th International Conference on Digital Signal Processing, Online, 19–21 June 2020; pp. 102–106. [Google Scholar]
- Kim, J.; Kim, M.; Kang, H.; Lee, K. U-gat-it: Unsupervised generative attentional networks with adaptive layer-instance normalization for image-to-image translation. In Proceedings of the ICLR 2020, Online, 26–30 April 2020. [Google Scholar]
- Xie, S.; Tu, Z. Holistically-Nested Edge Detection. In Proceedings of the ICCV 2015, Santiago, Chile, 7–13 December 2015; pp. 1395–1403. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.; Shechtman, E.; Wang, O. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In Proceedings of the CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 586–595. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Description | Generator | Discriminator | |||
|---|---|---|---|---|---|
| Encoder | Decoder | ||||
| initial block | ReflectionPad(3) Conv(input_nc,64) InstanceNorm(64) ReLU(True) | Linear(256,256) ReLU(True) Linear(256,256) ReLU(True) | ReflectionPad(1) Conv(input_nc,64) LeakyReLU(0.2,True) | ||
| ResAdaILNBlock | None | ReflectionPad(1) Conv(256,256) AdaILN(256) ReLU(True) | ×6 | None | |
| ReflectionPad(1) Conv(256,256) AdaILN(256) | |||||
| each block descriptions | # Down-Sample ReflectionPad(1) Conv(64,128) InstanceNorm(256) ReLU(True) | ReflectionPad(1) Conv(256,128) INL(128) ReLU(True) | ReflectionPad(1) Conv(64,128) LeakyReLU(0.2,True) | ||
| ReflectionPad(1) Conv(128,256) InstanceNorm(256) ReLU(True) | ReflectionPad(1) Conv(128,64) ILN(64) ReLU(True) | Reflectionpad(1) Conv(64,128) LeakyReLU(0.2,True) | |||
| ResBlock | # Down-sampling Bottleneck ReflectionPad(1) Conv(256,256) InstanceNorm(256) | ×6 | None | ReflectionPad(1) Conv(256,512) LeakyReLU(0.2,True) | |
| ReLU(True) ReflectionPad(1) Conv(256,256) InstanceNorm(256) | |||||
| Final block | Linear(256,1,False) Conv(512,256) ReLU(True) | ReflectionPad(3) Conv(64,output_nc Tanh() | Linear(512,1) Conv(1024,512) LeakyReLU(0.2,True) LeakyReLU(0.2,True) ReflectionPad(1) Conv(512,1) | ||
| Linear(256,256) ReLU(True) Linear(256,256) ReLU(True) | |||||
| Description | Each Block Information | |||||
|---|---|---|---|---|---|---|
| HED | VGGNet | Conv(3,64,3,1,1) ReLU (False) Conv(64,64,3,1,1) ReLU (False) | MaxPool (2,2) Conv(64,128,3,1,1) ReLU (False) Conv(128,128,3,1,1) ReLU (False) | MaxPool(2,2) Conv(128,256,3,1,1) ReLU (False) Conv(256,256,3,1,1) ReLU (False) Conv(256,256,3,1,1) ReLU (False) | MaxPool (2,2) Conv(256,512,3,1,1) ReLU (False) Conv(512,512,3,1,1) ReLU (False) Conv(512,512,3,1,1) ReLU (False) | MaxPool (2,2) Conv(512,512,3,1,1) ReLU (False) Conv(512,512,3,1,1) ReLU (False) Conv(512,512,3,1,1) ReLU (False) |
| Side Output | Conv(64,1,1,1,0) | Conv(128,1,1,1,0) | Conv(256,1,1,1,0) | Conv(512,1,1,1,0) | Conv(512,1,1,1,0) | |
| LPIPS | dropout(0.5) Conv(64,1,1,1,0,False) | dropout(0.5) Conv(192,1,1,1,0,False) | dropout(0.5) Conv(384,1,1,1,0,False) | dropout(0.5) Conv(256,1,1,1,0,False) | dropout(0.5) Conv(256,1,1,1,0,False) | |
| Model | DualGAN | pix2pix | CycleGAN | FDoG | U-GAT-IT | MUNIT | Ours |
|---|---|---|---|---|---|---|---|
| train | 60,000 | 66,400 | 66,000 | NA | 39,630 | 432,000 | 76,500 |
| test | 0.2 | 0.632 | 0.3 | 3.86 | 0.133 | 0.264 | 0.251 |
| Type | DualGAN | pix2pix | CycleGAN | FDoG | U-GAT-IT | MUNIT | Ours | Total | |
|---|---|---|---|---|---|---|---|---|---|
| (Q1) | human | 0 | 0 | 11 | 0 | 0 | 10 | 29 | 50 |
| animal | 0 | 0 | 14 | 0 | 0 | 9 | 27 | 50 | |
| landscape | 0 | 0 | 13 | 0 | 0 | 12 | 25 | 50 | |
| synthesized | 0 | 0 | 9 | 0 | 0 | 15 | 26 | 50 | |
| total | 0 | 0 | 47 | 0 | 0 | 46 | 107 | 200 | |
| (Q2) | human | 0 | 0 | 9 | 0 | 0 | 13 | 28 | 50 |
| animal | 0 | 0 | 15 | 0 | 0 | 12 | 23 | 50 | |
| landscape | 0 | 0 | 12 | 0 | 0 | 14 | 24 | 50 | |
| synthesized | 0 | 0 | 14 | 0 | 0 | 10 | 26 | 50 | |
| total | 0 | 0 | 50 | 0 | 0 | 49 | 101 | 200 | |
| (Q3) | human | 0 | 0 | 8 | 0 | 0 | 15 | 24 | 50 |
| animal | 0 | 0 | 7 | 0 | 0 | 11 | 30 | 50 | |
| landscape | 0 | 0 | 11 | 0 | 0 | 12 | 23 | 50 | |
| synthesized | 0 | 0 | 9 | 0 | 0 | 12 | 26 | 50 | |
| total | 0 | 0 | 35 | 0 | 0 | 50 | 103 | 200 |
| Type | DualGAN | pix2pix | CycleGAN | FDoG | U-GAT-IT | MUNIT | Ours |
|---|---|---|---|---|---|---|---|
| portrait | 398.28 | 296.59 | 254.05 | 303.92 | 248.18 | 239.69 | 226.26 |
| animal | 467.88 | 433.30 | 380.49 | 388.78 | 374.39 | 373.75 | 325.43 |
| landscape | 554.68 | 578.25 | 545.93 | 488.84 | 471.21 | 493.50 | 493.50 |
| synthesized | 459.39 | 471.72 | 403.98 | 402.86 | 404.13 | 359.90 | 359.90 |
| average | 470.06 | 444.96 | 396.11 | 396.10 | 374.48 | 366.71 | 366.71 |
| DualGAN | pix2pix | CycleGAN | FDoG | U-GAT-IT | MUNIT | |
|---|---|---|---|---|---|---|
| average | 470.06 | 444.96 | 396.11 | 396.10 | 374.48 | 366.71 |
| s | 113.76 | 141.79 | 142.14 | 116.06 | 126.06 | 126.22 |
| d | 1.23 | 0.81 | 0.47 | 0.57 | 0.37 | 0.29 |
| Effect size | greater than very large | greater than large | greater than small | greater than medium | greater than small | greater than small |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yeom, J.; Yang, H.; Min, K. An Attention-Based Generative Adversarial Network for Producing Illustrative Sketches. Mathematics 2021, 9, 2791. https://doi.org/10.3390/math9212791
Yeom J, Yang H, Min K. An Attention-Based Generative Adversarial Network for Producing Illustrative Sketches. Mathematics. 2021; 9(21):2791. https://doi.org/10.3390/math9212791
Chicago/Turabian StyleYeom, Jihyeon, Heekyung Yang, and Kyungha Min. 2021. "An Attention-Based Generative Adversarial Network for Producing Illustrative Sketches" Mathematics 9, no. 21: 2791. https://doi.org/10.3390/math9212791