1. Introduction
In lifetime data analysis, due to the complex internal structure and external environment, units frequently fail for a variety of causes, such failure causes are called competing risks in the literature and compete with each other in the whole life cycle. In standard sketches, the observed competing risks data of each unit is the earliest occurrence among all the causes, and the data includes the lifetime as well as the cause indicator. Under conventional studies, discussions for the competing risks model are usually made based on the assumption that all causes of failure are independent for the purpose of simplicity and concision. Such independent based competing risks models have been discussed by many authors, for example, some works of Mao and Shi [
1], Varghese and Vaidyanathan [
2], Davies and Volterman [
3], Lodhi et al. [
4], and Ren and Gui [
5]. For more details, one can refer to the monographs by Crowder [
6] for review. However, according to the actual operating mechanism of living products, the assumption of independence is often untenable in practice. For example, in the study of colon cancer, the factors of failure are cancer recurrence or death, and Lin et al. [
7] mentioned that these two factors are dependent. For a plane with four engines, if one of the engines breaks down, the other engines will bear more pressure and have a greater possibility of failure. Thus, the plane has a higher risk of breaking down. It can be found that as the causes of plane failure, these engines are positively dependent. In addition, the dependent competing risks also exist in the diabetic retinopathy study that was carried out by the National Eye Institute. This study aimed to discuss the effect of laser treatment in delaying the onset of blindness in patients with diabetic retinopathy. For each patient in this study, one eye was chosen for laser treatment and the other was not. The final observed data includes the minimum time to blindness and indicator pointing the treated or other eye failed first. Besides, the study also recorded the associated data on simultaneous blindness of both eyes. Obviously, there is some connection between the lifetimes of two eyes for each patient in this situation. Hence, it is more appropriate to utilize a dependent competing risks model to describe the relationship between all failure causes. In general, the dependent competing risks model could be used to provide more accurate inferential results than the independent one. When two dependent failure causes of an individual exist, the Marshall–Olkin bivariate type model may provide better fitting for dependent competing risk data. In literature, the Marshall–Olkin bivariate exponential (MOBE) distribution was firstly proposed by Marshall and Olkin [
8] due to its nice distributional properties and concise form, and some other Marshall–Olkin bivariate type distributions have also been further extended and studied by many authors. For instance, Feizjavdian and Hashemi [
9] investigated Diabetic retinopathy data by using Marshall–Olkin bivariate Weibull distribution (MOBW). Bayesian analysis of dependent competing risks model utilizing Marshall–Olkin bivariate Pareto (MOBP) distribution was considered by Paul et al. [
10]. Shen and Xu [
11] studied the parameter estimation of MOBW distribution based on different methods. Wang et al. [
12] considered the statistical inference of the dependent competing risks model by using the MOBW distribution.
Observations collected in practice often appear as censored data and/or truncated data due to complex practical limitations. When both truncation and censoring phenomenon occur, such observations are called truncated and censored data in literature, and the left truncated and right censored (LTRC) data is one of the most important characteristics among them. This type of data is very common in many application fields such as economics, medicine, engineering, biology, among others. For left truncation, it means that only after a certain time point, the failure of a product occurs and is observed; whereas right censoring means that a product fails after a certain time point, but its specific failure time cannot be observed. In recent years, the inferential studies for LTRC data has been discussed by many researchers (e.g., Shen [
13], Zhao et al. [
14] and Ranjan et al. [
15]). Especially, there is successful application of LTRC data from the real-life example introduced by Hong et al. [
16], where the mentioned data set is about the lifetimes of approximately 150,000 high-voltage power transformers in the electrical industry of the US. These power transformers were installed at different time points, and their working status began to be recorded after 1980 but the recording work stopped after 2008. Obviously, the power transformers data could be viewed as LTRC data. If a power transformer was installed before 1980 and failed afore 1980, then its information would be unobserved. If it was installed before 1980 but failed after 1980, then its information could be available and it was regarded as left truncated data. Further, if a transformer failed after 2008 and the real failure time could not be obtained, then it would be recorded as right censored data. Therefore, due to its widely applications in practice, analysis work for LTRC data has been extensively discussed by many authors. For example, Emura and Shiu [
17] studied the estimation of unknown parameters and model selection for LTRC data. Jiang et al. [
18] developed a nonparametric likelihood-based estimation procedure by using B-splines. Kundu et al. [
19] provided the Bayesian inference for the unknown parameters of MOBW distribution when LTRC competing risk model is available with independent causes.
Motivated by the reasons mentioned above and due to the simplicity and practicability of the Marshall–Olkin type bivariate distribution, this paper aims to discuss the statistical inference for LTRC data with dependent competing risks. When the dependent causes of failure is modeled by Marshall–Olkin Rayleigh (MOBR) distribution, various estimators are provided for unknown model parameters from classical and Bayesian perspectives, and extensive simulation studies and real life examples are carried out to compare the performance of different methods.In addition, for the sake of clarity, the main motivations and contributions of our paper could be presented as follows. Firstly, although there are many inferential works along with LTRC data, studies for LTRC data with multiple causes of failure is rare in existing literatures. One of main applicability of the proposed approaches is that our paper takes the competing risks into account for LTRC data which sometimes seems more meaningful and proper for practical situations. Secondly, due to complex internal and external operating mechanism of components, dependent failure causes are more appropriate to model the cross correlation between different causes of failure. Thus, the later proposed dependent lifetime distribution may feature appealing fitting performance for various competing risks. Finally, from practical perspective, competing risks are mostly positively dependent due to the phenomenon that one cause’s survival would increase the chance of another cause’s survival in many applicative situations. Therefore, multivariate statistical models having positive dependence will provide proper fitting performance in analysis. In this paper, a Marshall–Olkin type bivariate model is used for LTRC competing risks data. To the best of our acknowledge, this problem has not been discussed before in literature.
The rest of this paper is organized as follows. Model description, some notations, and prior information are presented in
Section 2. When there is no order restriction among parameters, classical and Bayesian estimations are discussed in
Section 3 and
Section 4, respectively. In
Section 5, both classical and Bayesian inferences are presented under parameter restriction situation. The prediction issue for right censored sample is addressed in
Section 6. In
Section 7, simulation studies are conducted and two real life examples are analyzed for illustration. Finally, some concluding remarks are given in
Section 8.
4. Bayesian Inference
As an alternative method to likelihood inference, Bayesian inference has received wide attentions in statistical analysis due to its capability of incorporating prior knowledge. In this section, the Bayesian estimates (BEs) under squared error loss function are provided when there is no order restriction for model parameters and corresponding Bayesian high posterior density (HPD) credible intervals of unknown parameters are also constructed.
Based on expressions (
6) and (
9) and denote
, the posterior density of
,
and
can be obtained as
From (
11), it can be known that the posterior distribution of parameter vector
follows GD
. Besides, for any function of
,
and
namely
, its Bayesian estimation
under squared error loss can be expressed as
It is seen that there is no closed form for BE
. In order to find the associated estimate, following Algorithm 1 is utilized where the associated HPD credible interval is also provided.
| Algorithm 1 The Bayesian estimate for . |
Step 1: Generate parameter from Gamma–Dirichlet distribution GD. Step 2: Repeat Step 1 M times, and can be obtained. Step 3: The approximate Bayesian estimate can be computed from
Step 4: Denote . To construct credible interval of , arrange in ascending order as . Then for arbitrary , a credible interval of can be established as
where denotes the greatest integer less than or equal to y. Therefore, the HPD credible interval can be constructed as
where th satisfying
|
6. Prediction
Besides parameter estimation, it is of importance to discuss the prediction issue for the lifetime of censored samples in both theoretical study and practical application. This prediction problem has been discussed by many authors. For example, the work of Abdel-Hamid [
22], Ahmed [
23], Kotb and Raqab [
24] and Zhang and Shi [
25]. Recall that
and
are the set of right censored samples and right censored time of the
ith sample respectively. Since the real failure time of right censored sample is unobserved, we focus on the sample which belongs to
in this section. The likelihood-based point predictions (LPPs) for the lifetime of right censored samples are established, and associated likelihood-based prediction intervals (LPIs) are constructed too. Besides, the Bayesian predictors (BPs) and Bayesian prediction intervals (BPIs) for the lifetime of these right censored samples are also given as another alternative prediction methods.
For
, let
be the future failure time of censored sample, the conditional PDF and SF of
for given
can be written as
and
respectively.
6.1. Classical Prediction
In order to obtain the LPP and LPI for , a theorem is presented as follows.
Theorem 4. Let the latent LTRC competing risk data (3) follow MOBR and be the future time of censored sample. For given , one has that - (1)
the point prediction of is given by - (2)
the prediction interval for is constructed as
Based on Theorem 4, by using the substitution method as for , then the LPP and LPI for can be established respectively.
6.2. Bayesian Prediction
In order to find the BP and BPI for , another theorem is proposed as follows.
Theorem 5. Let the latent LTRC competing risk data (3) follow MOBR and be the future failure time of censored sample. For given joint prior density and , one has that - (1)
The BP of under squared error loss function can be given by - (2)
The associated BPI of can be obtained by solving the following equations
8. Conclusions
In this paper, classical and Bayesian inferences for LTRC dependent competing risks data have been discussed. When the dependent competing risks is distributed by the Marshall–Olkin bivariate Rayleigh model, the maximum likelihood estimators of unknown parameters are established, and associated approximate confidence intervals are also constructed. Furthermore, Bayesian estimates and corresponding high posterior density credible intervals are developed as well. In addition, when order restriction information between parameters is available, the point and interval estimates for unknown parameters are also provided based on classical and Bayesian frameworks. In order to investigate the lifetimes of censored samples, prediction formulae are also developed from classical and Bayesian perspectives, respectively. Finally, extensive simulation studies and two real life examples are carried out to evaluate the performance of proposed methods, and the results show that both classical and Bayesian inference works satisfactorily. Moreover, if the priori information is sufficient, the results indicate that the Bayesian method perform better than the classical one under both order and non-order restriction situations.
In addition, although the main contents of the paper focus on the LTRC competing risks data with MOBR model, the work can also be extended (with proper modifications) to a more general Marshall–Olkin type bivariate model with baseline CDF as
where
,
is a baseline CDF and
B is the support of the baseline CDF
. This distribution family is called the proportional hazard rate model in literature and includes exponential distribution, Rayleigh distribution, Pareto distribution (one parameter) as its special cases. To be specific, let
follow proportional hazard rate model with parameter
,
and
, then the joint SF of
can be expressed as
Following the similar procedures established above, statistical inferences for the LTRC dependent competing risks data from this Marshall–Olkin type bivariate model could be obtained based on both likelihood and Bayesian methods.
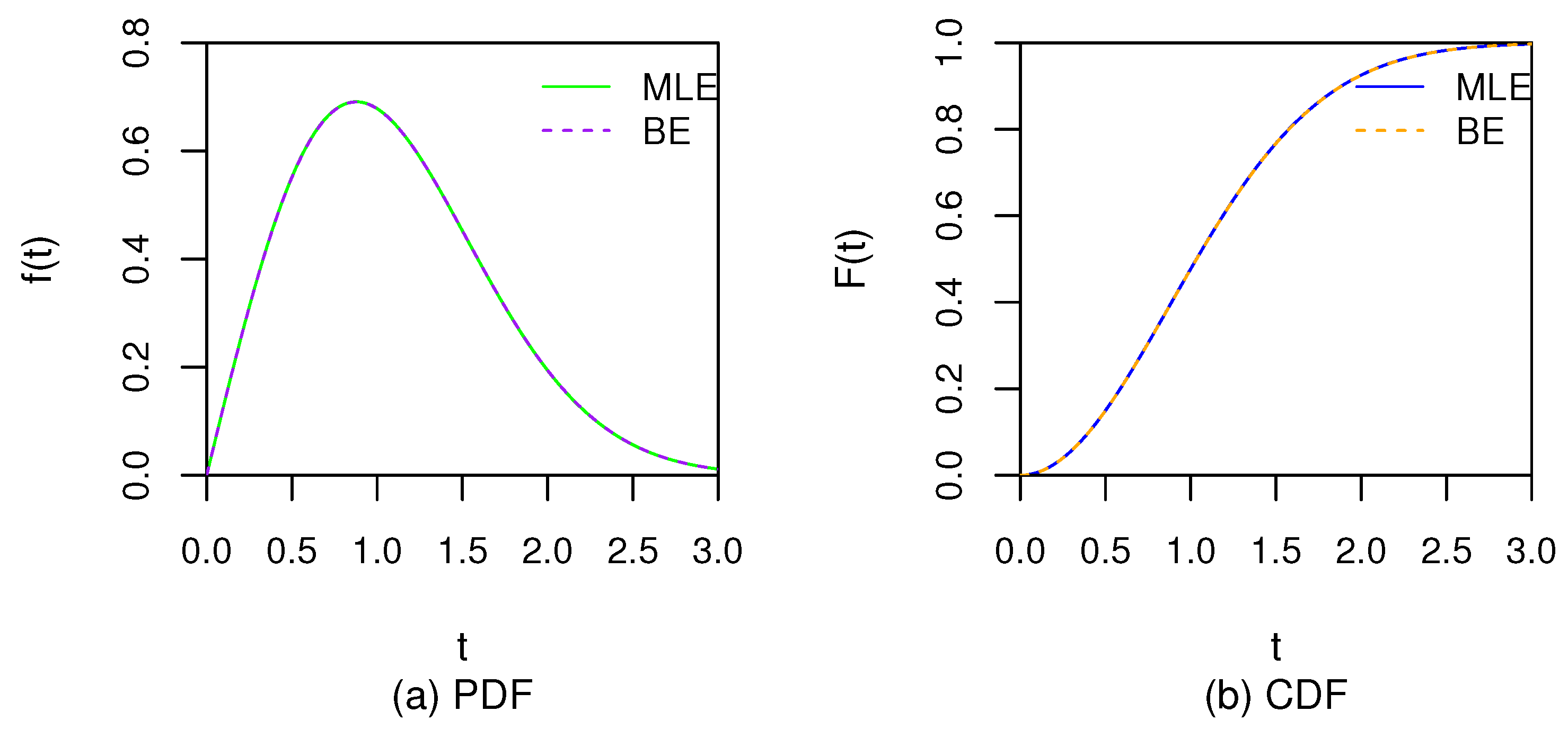
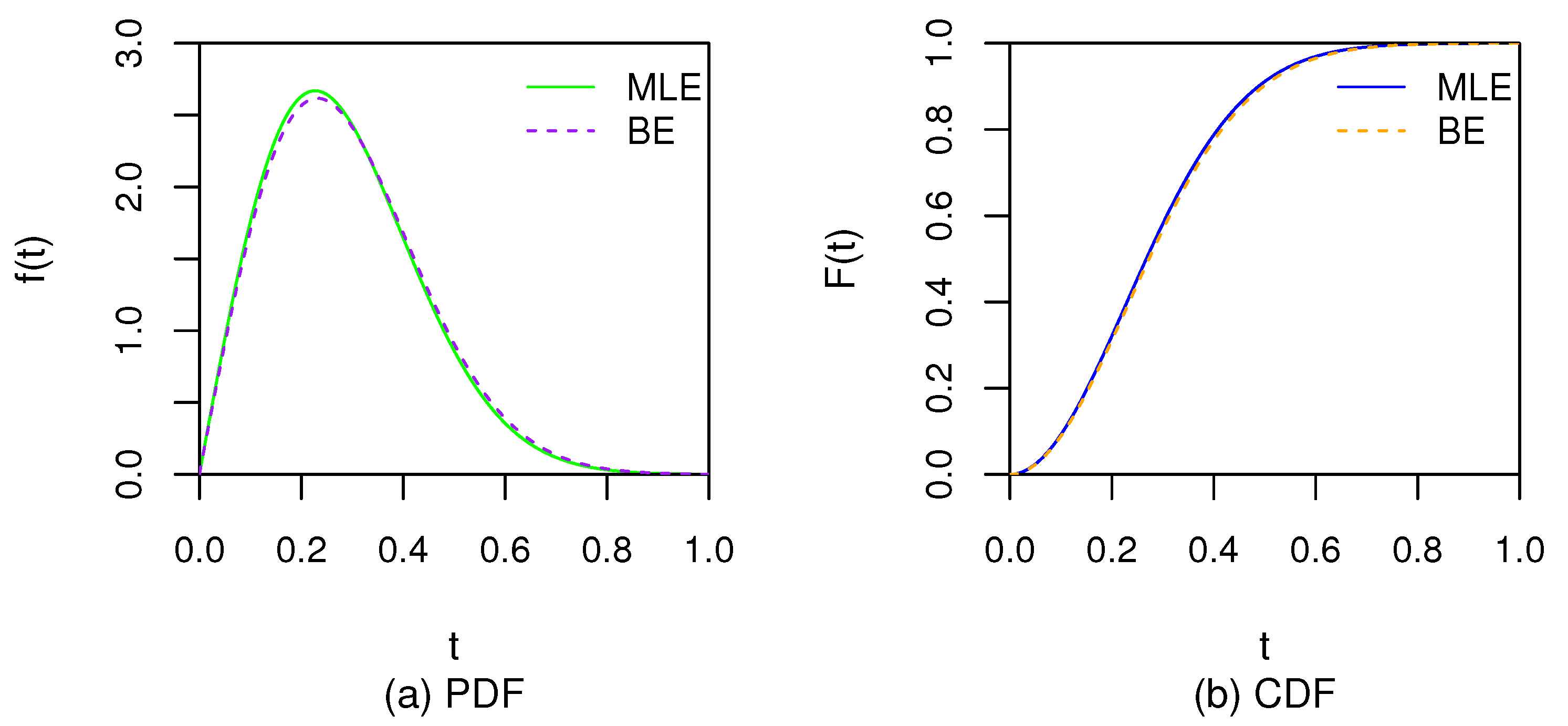
The current study includes the statistical inferences of population parameters and prediction of failure time for the censored units based on the LTRC dependent competing risks data from identical Marshall–Olkin type bivariate distribution. The left truncated time and right censored time for each unit under study could be different. When all left truncated times are equal to 0 and all right censored times are infinity, the LTRC dependent competing risks data is random sample obtained from the identical Marshall–Olkin type bivariate distribution. Therefore, the developed methodologies are not for non-stationary data. Based on the application and theoretical experiences from random sample, both Bayesian and MLE procedures are getting more accurate results when sample size is getting larger.
Table 1,
Table 2,
Table 3 and
Table 4 show both methods are getting more accurate estimates in terms of MSE and AB and
Table 5,
Table 6,
Table 7 and
Table 8 show both methods are getting more accurate confidence or credible interval in terms of AL as well as CP when sample size is getting larger under the same TR rate. Hence, both proposed estimation procedures are applicable for larger datasets. Specially, the limit distribution of MLE has been proved to be normal distribution when sample size
n approaches to infinity in
Section 3.2. The asymptotic normal distribution has true unknown parameters as mean vector and variance-covariance that is the inverse of Fisher information. When using a finite sample size, the estimated variance-covariance is usually not accurate and the estimated variance of MLE is usually inflated due to the TR rate and/or censored rate. However, the Bayesian procedure does not use limit distribution that usually requires larger sample size to get more accurate results. Therefore, the ACIs are usually not stable and have larger length than the HPDs given a sample size and TR rate; meanwhile the CPs for ACIs are sometimes much larger than or less than the nominal level; while all HPDs have CPs nearby the nominal level. However, the Bayesian method through the MCMC procedure usually needs more computation time than MLE does.




{kind=link}
{kind=link}

