
Exploring an Efficient POI Recommendation Model Based on User Characteristics and Spatial-Temporal Factors


Abstract
:1. Introduction
- (1)
- A hybrid POI recommendation model is proposed, which fully considers user preference, user influence, forgetting characteristics, trajectory, geographic location relevance, and category.
- (2)
- A method to quantify the emotion of a user’s comment is suggested, regarding the influence of the emotional degree and emotional polarity of the comment text.
- (3)
- Aiming at the feature that the user’s preference on POI visited recently is higher than that one visited previously, an effective forgetting function is proposed.
- (4)
- Considering the correlation between the locations of POIs, a two-dimensional kernel density estimation function is used to estimate the individualized two-dimensional check-in probability density of each user and to obtain the probability.
- (5)
- The influence of the POI categories on the user’s check-in behavior is analyzed. Weighting the POI category preference to calculate the user’s preference for the category is performed afterward.
2. Literature Review
3. Hybrid POI Recommendation Model
3.1. POI Recommendation Sub-Model Integrated with Multidimensional Factors
3.1.1. User Preference Analysis Based on Historical Scores and Comments
3.1.2. User Influence Calculation
3.1.3. User Trajectory Similarity
3.1.4. User Similarity Based on Multidimensional Factors
3.2. Recommendation of Sub-Model Based on the Position Correlation among POIs
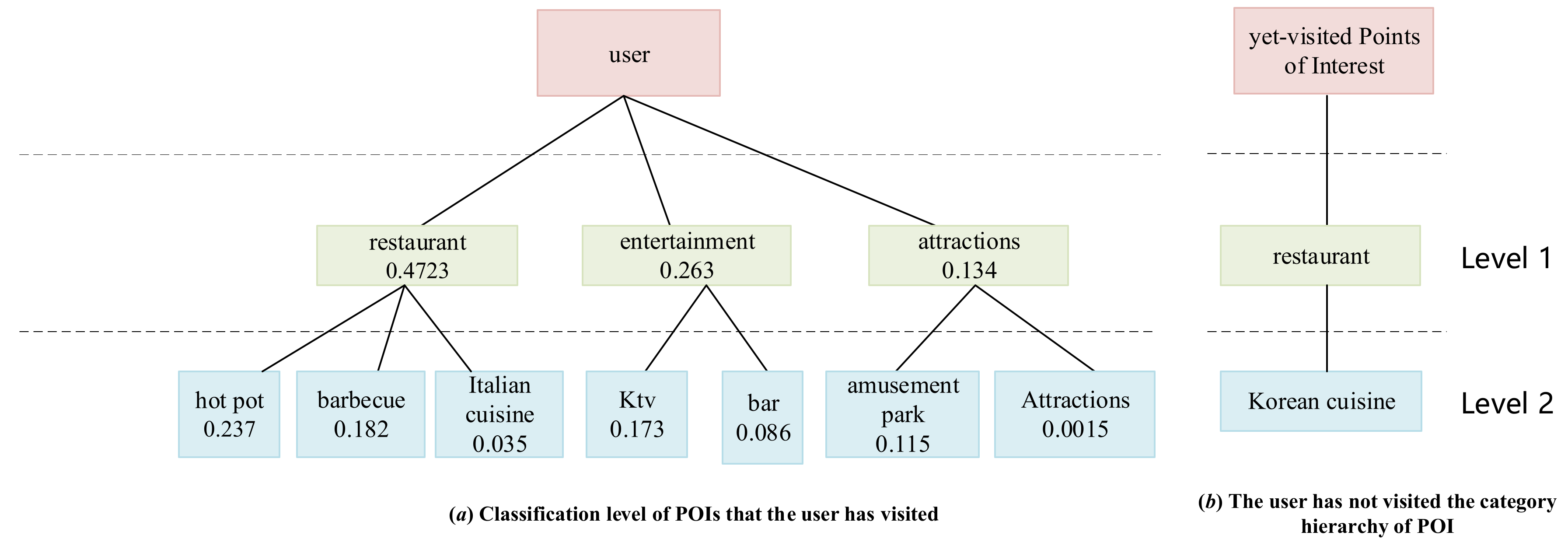
3.3. Recommendation of Sub-Model Based on POI Category
3.4. Generate POI Recommendation Results
4. Experiment and Result Analysis
4.1. Experimental Preparation
4.1.1. Description of the Data Set
4.1.2. Recommended Effect Evaluation Metrics
4.1.3. Comparison Method
4.2. Experimental Results and Analysis
4.2.1. Parameters Determination
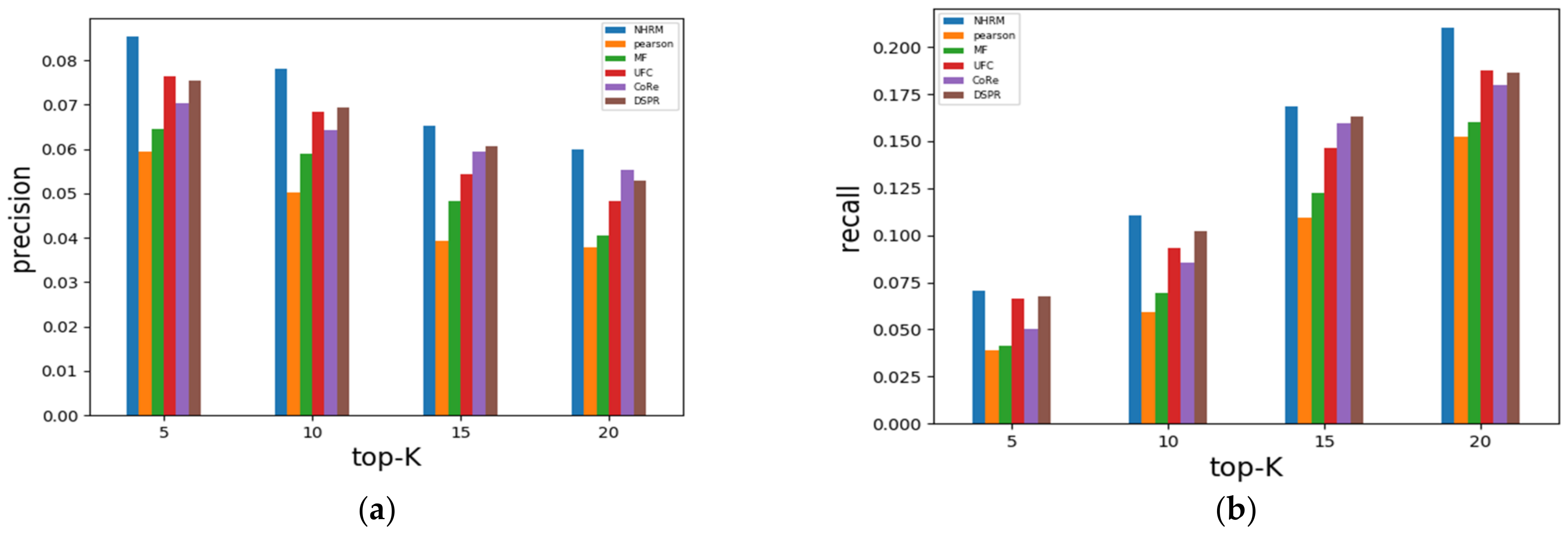
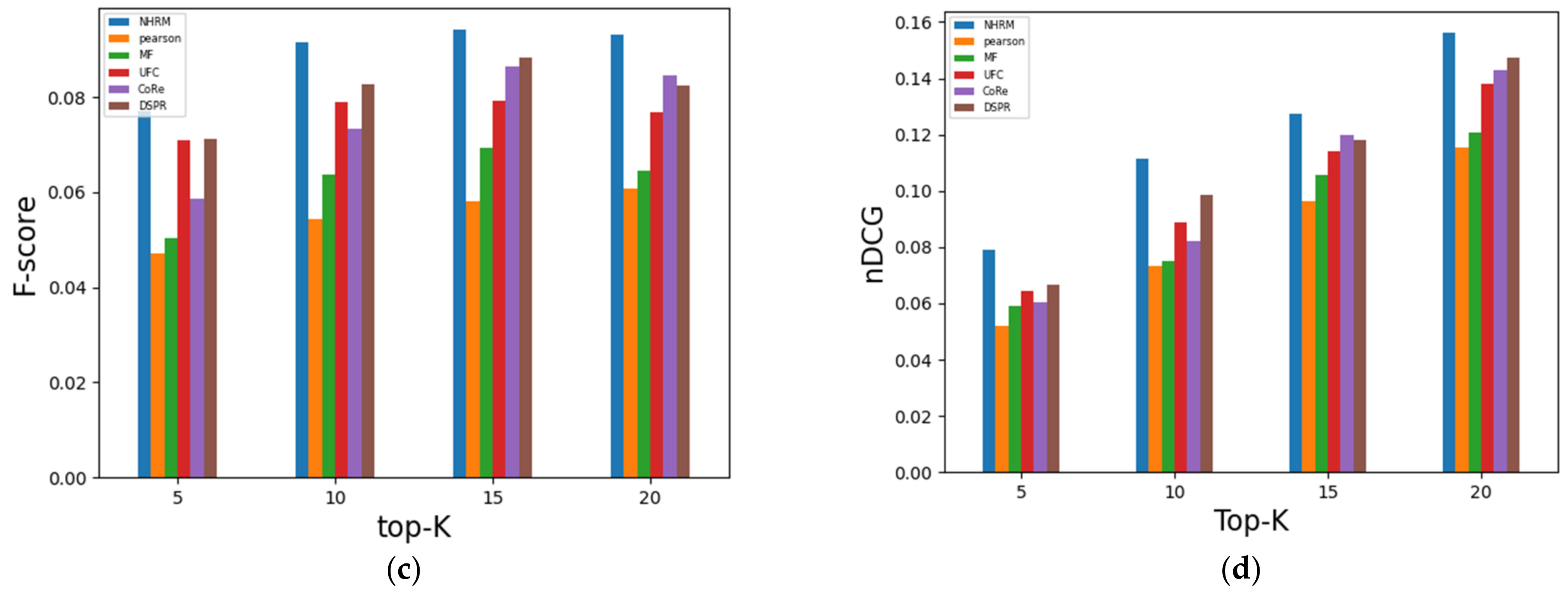
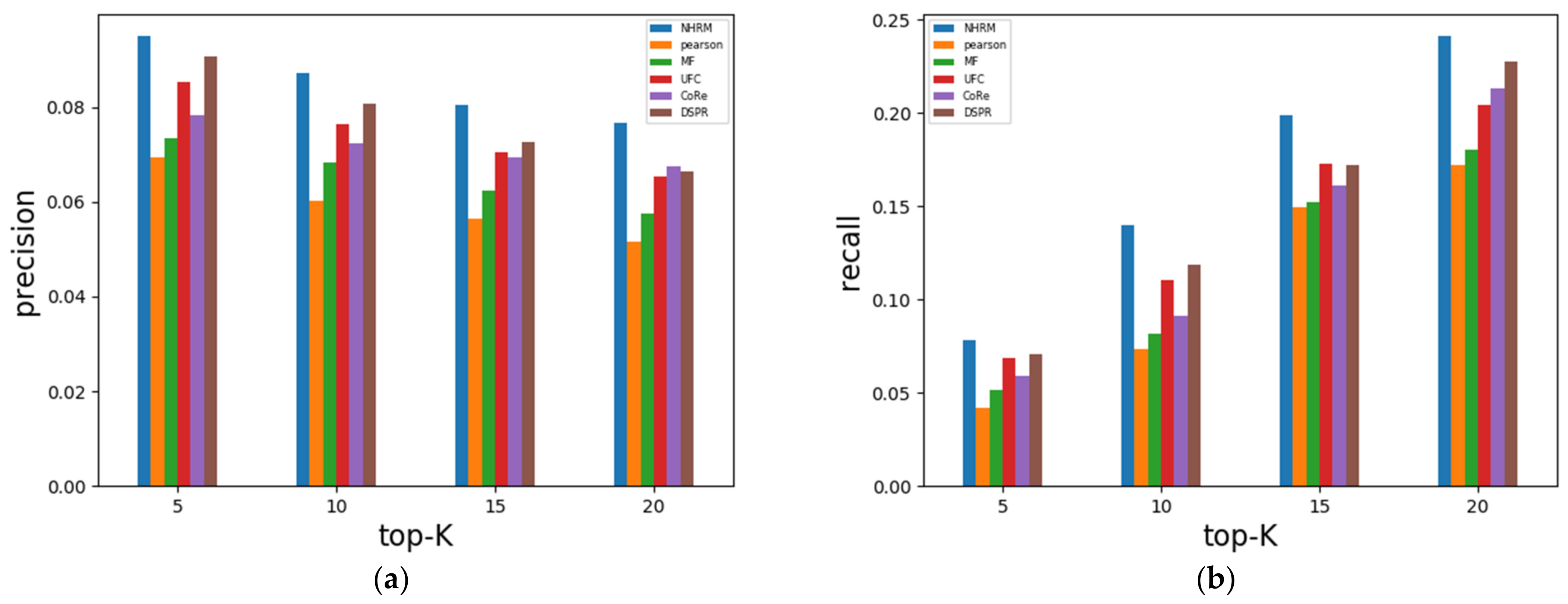
4.2.2. Results Analysis
4.2.3. Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhou, X.; Mascolo, C.; Zhao, Z. Topic-enhanced memory networks for personalized point-of-interest recommendation. In Proceedings of the ACM SIGKDD, Anchorage, AK, USA, 4–8 August 2019; pp. 3018–3028. [Google Scholar]
- Shi, M.; Shen, D.; Kou, Y.; Nie, T.; Yu, G. Attentional Memory Network with Correlation-based Embedding for time-aware POI recommendation. Knowl.-Based Syst. 2021, 214, 106747. [Google Scholar] [CrossRef]
- Werneck, H.; Santos, R.; Silva, N.; Pereira, A.C.M.; Mourão, F.; Rocha, L. Effective and diverse POI recommendations through complementary diversification models. Expert Syst. Appl. 2021, 175, 114775. [Google Scholar] [CrossRef]
- Ren, X.; Song, M.; Song, J. Point-of-Interest recommendation based on the user check-in behavior. Chin. J. Comput. 2017, 40, 28–51. [Google Scholar]
- Xiong, X.; Qiao, S.; Han, N.; Xiong, F.; Bu, Z.; Li, R.; Yue, K.; Yuan, G. Where to go: An effective point-of-interest recommendation framework for heterogeneous social networks. Neurocomputing 2020, 373, 56–69. [Google Scholar] [CrossRef]
- Huang, L.; Ma, Y.; Liu, Y. Point-of-interest recommendation in location-based social networks with personalized geo-social influence. China Commun. 2015, 12, 21–31. [Google Scholar] [CrossRef]
- Zhang, L.; Sun, Z.; Zhang, J.; Kloeden, H.; Klanner, F. Modeling hierarchical category transition for next POI recommendation with uncertain check-ins. Inf. Sci. 2020, 515, 169–190. [Google Scholar] [CrossRef]
- Liu, X.; Yang, Y.; Xu, Y.; Yang, F.; Huang, Q.; Yang, H. Real-Time POI Recommendation via Modeling Long- and Short-Term User Preferences. Neurocomputing 2021, 467, 454–464. [Google Scholar] [CrossRef]
- Wang, W.; Chen, J.; Wang, J.; Chen, J.; Liu, J.; Gong, Z. Trust-Enhanced Collaborative Filtering for Personalized Point of Interests Recommendation. IEEE Trans. Ind. Inform. 2020, 16, 6124–6132. [Google Scholar] [CrossRef]
- Zeng, J.; Li, F.; He, X.; Wen, J. Fused Collaborative Filtering with User Preference, Geographical and Social Influence for Point of Interest Recommendation. Int. J. Web Serv. Res. 2019, 16, 40–52. [Google Scholar] [CrossRef]
- Jiao, X.; Xiao, Y.; Zheng, W.; Xu, L.; Wu, H. Exploring Spatial and Mobility Pattern’s Effects for Collaborative Point-of-Interest Recommendation. IEEE Access 2019, 7, 158917–158930. [Google Scholar] [CrossRef]
- Yao, L.; Sheng, Q.; Wang, X.; Zhang, W.; Qin, Y. Collaborative Location Recommendation by Integrating Multi-dimensional Contextual Information. ACM Trans. Internet Technol. 2018, 18, 1–24. [Google Scholar] [CrossRef] [Green Version]
- Cai, L.; Wen, W.; Wu, B.; Yang, X. A Coarse-to-Fine User Preferences Prediction Method for Point-of-interest Recommendation. Neurocomputing 2020, 422, 1–11. [Google Scholar] [CrossRef]
- Yu, D.; Wanyan, W.; Wang, D. Leveraging contextual influence and user preferences for point-of-interest recommendation. Multimed. Tools Appl. 2020, 8, 1487–1501. [Google Scholar] [CrossRef]
- Chen, Y.; Thaipisutikul, T.; Shih, T.K. A Learning-Based POI Recommendation with Spatiotemporal Context Awareness. IEEE Trans. Cybern. 2020, 99, 1–14. [Google Scholar] [CrossRef]
- Wang, H.; Li, P.; Liu, Y.; Shao, J. Towards Real-time Demand-aware Sequential POI Recommendation. Inf. Sci. 2021, 547, 482–497. [Google Scholar] [CrossRef]
- Chen, J.; Li, X.; Cheung, W.K.; Li, K. Effective successive POI recommendation inferred with individual behavior and group preference. Neurocomputing 2016, 210, 174–184. [Google Scholar] [CrossRef]
- Zhu, L.; Xu, C.; Guan, J.; Zhang, H. SEM-PPA: A semantical pattern and preference-aware service mining method for personalized point of interest recommendation. J. Netw. Comput. Appl. 2017, 82, 35–46. [Google Scholar] [CrossRef]
- Liu, K.; Yin, L.; Lu, F.; Mou, N. Visualizing and exploring POI configurations of urban regions on POI-type semantic space. Cities 2020, 99, 102610. [Google Scholar] [CrossRef]
- Hao, P.; Cheang, W.H.; Chiang, J.H. Real-time event embedding for POI recommendation. Neurocomputing 2019, 349, 1–11. [Google Scholar] [CrossRef]
- Adomavicius, G.; Tuzhilin, A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749. [Google Scholar] [CrossRef]
- Xing, S.; Liu, F.; Zhao, X.; Li, T. Points-of-interest recommendation based on convolution matrix factorization. Appl. Intell. 2018, 48, 2458–2469. [Google Scholar] [CrossRef]
- Davtalab, M.; Alesheikh, A. A POI recommendation approach integrating social spatio-temporal information into probabilistic matrix factorization. Knowl. Inf. Syst. 2021, 63, 65–85. [Google Scholar] [CrossRef]
- Hu, L.; Xing, Y.; Gong, Y.; Zhao, K.; Wang, F. Nonnegative matrix tri-factorization with user similarity for clustering in point-of-interest. Neurocomputing 2019, 363, 58–65. [Google Scholar] [CrossRef]
- Xu, C. A big-data oriented recommendation method based on multi-objective optimization. Knowl.-Based Syst. 2019, 177, 11–21. [Google Scholar] [CrossRef]
- Si, Y.; Zhang, F.; Liu, W. CTF-ARA: An adaptive method for POI recommendation based on check-in and temporal features. Knowl.-Based Syst. 2017, 128, 59–70. [Google Scholar] [CrossRef]
- Xu, C. A novel recommendation method based on social network using matrix factorization technique. Inf. Process. Manag. 2018, 54, 463–474. [Google Scholar] [CrossRef]
- Zhang, J.; Chow, C.; Li, Y. LORE: Exploiting sequential influence for location recommendations. In Proceedings of the 22nd ACM International Conference on Advances in Geographic Information Systems, SIGSPATIAL, Dallas, TX, USA, 4–7 November 2014; pp. 103–112. [Google Scholar]
- Ren, X.; Song, M.; Haihong, E.; Song, J. Context-aware probabilistic matrix factorization modeling for point-of-interest recommendation. Neurocomputing 2017, 241, 38–55. [Google Scholar] [CrossRef]
- Xu, Z.; Chen, L.; Chen, G. Topic based context-aware travel recommendation method exploiting geotagged photos. Neurocomputing 2015, 155, 99–107. [Google Scholar] [CrossRef]
- Kolahkaj, M.; Harounabadi, A.; Nikravanshalmani, A.; Chinipardaz, R. A hybrid context-aware approach for e-tourism package recommendation based on asymmetric similarity measurement and sequential pattern mining. Electron. Commer. Res. Appl. 2020, 42, 100978. [Google Scholar] [CrossRef]
- Gavalas, D.; Kenteris, M. A web-based pervasive recommendation system for mobile tourist guides. Pers. Ubiquitous Comput. 2011, 15, 759–770. [Google Scholar] [CrossRef]
- Xu, C.; Ding, A.S.; Zhao, K. A novel POI recommendation method based on trust relationship and spatial-temporal factors. Electron. Commer. Res. Appl. 2021, 48, 101060. [Google Scholar] [CrossRef]
- Chang, B.; Park, Y.; Kim, S.; Kang, J. DeepPIM: A Deep Neural Point-of-Interest Imputation Model. Inf. Sci. 2018, 465, 61–71. [Google Scholar] [CrossRef]
- Jiao, X.; Xiao, Y.; Zheng, W.; Wang, H.; Hsu, C. A novel next new point-of-interest recommendation system based on simulated user travel decision-making process. Future Gener. Comput. Syst. 2019, 100, 982–993. [Google Scholar] [CrossRef]
- Liu, T.; Liao, J.; Wu, Z.; Wang, Y.; Wang, J. Exploiting Geographical-Temporal Awareness Attention for Next Point-of-Interest Recommendation. Neurocomputing 2020, 400, 227–237. [Google Scholar] [CrossRef]
- Zhao, G.; Lou, P.; Qian, X.; Hou, X. Personalized location recommendation by fusing sentimental and spatial context. Knowl.-Based Syst. 2020, 196, 105849. [Google Scholar] [CrossRef]
- Rong, G.; Li, J.; Li, X.; Song, C.; Zhou, Y. A Personalized Point-of-Interest Recommendation Model via Fusion of Geo-social Information. Neurocomputing 2018, 273, 159–170. [Google Scholar]
- Mosteller, F.; Turkey, J. Data Analysis, Including Statistics. In The Handbook of Social Psychology; Gardner, L., Eliot, A., Eds.; Springer & Addison-Wesley: Reading, MA, USA, 1968; pp. 109–112. [Google Scholar]
- Zhang, J.; Chow, C. CoRe: Exploiting the personalized influence of two-dimensional geographic coordinates for location recommendations. Inf. Sci. 2015, 293, 163–181. [Google Scholar] [CrossRef]
- Zhou, J.; Liu, B.; Chen, Y.; Lin, F. UFC: A Unified POI Recommendation Framework. Arab. J. Sci. Eng. 2019, 44, 9321–9332. [Google Scholar] [CrossRef]
- Xiang, K.; Xu, C.; Wang, J. Understanding the Relationship Between Tourists’ Consumption Behavior and Their Consumption Substitution Willingness Under Unusual Environment. Psychol. Res. Behav. Manag. 2021, 14, 483–500. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Xu, C.; Liu, W. Understanding the adoption of mobile social payment? From the cognitive behavioral perspective. Int. J. Mob. Commun. 2022, in press. [Google Scholar] [CrossRef]
- Tang, Z.; Hu, H.; Xu, C.; Zhao, K. Exploring an Efficient Remote Biomedical Signal Monitoring Framework for Personal Health in the COVID−19 Pandemic. Int. J. Environ. Res. Public Health 2021, 18, 9037. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Emotional Vocabulary | Emotion Degree | Emotion Polarity | Emotion Score | After Adding Negative Words | Final Score |
|---|---|---|---|---|---|
| Abundant | 3 | 1 | 3 | not abundant | 3 × −0.5 = −1.5 |
| Incomparable happiness | 5 | 1 | 5 | not happy | 5 × −1 = −5 |
| Dirty and messy | 4 | 2 | −4 | not messy | −4 × −1 = 4 |
| Satisfied | 4 | 1 | 4 | not satisfied | 4 × −1 = −4 |
| Angry | 3 | 2 | −3 | not angry | 3 × 0.5 = 1.5 |
| User | POI | Time | Categories | Coordinate | Times |
|---|---|---|---|---|---|
| 0 | 138 | 1185638400.0 | 3 21 2 | (40.405245, −80.018538) | 4 |
| 393 | 123 | 1226592000.0 | 110 2 | (40.4657148,79.9535041) | 4 |
| 393 | 102 | 1312732800.0 | 2 3 | (40.4484631,79.98940859) | 8 |
| 401 | 13,379 | 1310227200.0 | 6 11 2 | (40.489141799,79.8930872) | 4 |
| 491 | 10,330 | 1341244800.0 | 502 22 138 2 | (40.459956,79.924269999) | 2 |
| 632 | 6388 | 1291305600.0 | 87 31 103 | (36.0473627825,115.1710557) | 3 |
| 816 | 4111 | 1283443200.0 | 12 13 4 15 326 2 | (36.1130255,115.1634847001) | 5 |
| … | … | … | … | … | … |
| User | POI | Time | Categories | Coordinate | Comment | Star |
|---|---|---|---|---|---|---|
| 91 | 76 | 2016/4/18 22:48 | fast food | (116.372,40.107) | Will come to eat again. Not bad! I will come to eat again. | 5 |
| 6 | 389 | 2016/3/18 18:55 | hot pot | (121.582,30.924) | Taste good. I often come here. The boss is nice and hospitable. The taste is not bad. Not far from my home. Take-away is offered. Great! | 5 |
| 142 | 90 | 2016/1/31 21:38 | fast food | (116.451,39.924) | Little noodles. The soup is extremely salty. I’m so disappointed. | 1 |
| 302 | 273 | 2016/5/23 15:54 | vegetarian diet | (116.357,40.085) | It’s really not easy to make vegetarian dishes delicious. Keep refueling. | 4 |
| … | … | … | … | … | … | … |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, C.; Liu, D.; Mei, X. Exploring an Efficient POI Recommendation Model Based on User Characteristics and Spatial-Temporal Factors. Mathematics 2021, 9, 2673. https://doi.org/10.3390/math9212673
Xu C, Liu D, Mei X. Exploring an Efficient POI Recommendation Model Based on User Characteristics and Spatial-Temporal Factors. Mathematics. 2021; 9(21):2673. https://doi.org/10.3390/math9212673
Chicago/Turabian StyleXu, Chonghuan, Dongsheng Liu, and Xinyao Mei. 2021. "Exploring an Efficient POI Recommendation Model Based on User Characteristics and Spatial-Temporal Factors" Mathematics 9, no. 21: 2673. https://doi.org/10.3390/math9212673