1. Introduction
In many studies, researchers have a binary multivariate data matrix and aim to reduce dimensions to investigate the structure of the data. For example, in the measurement of brand equity, a set of consumers evaluates the perceptions of quality, perceptions of value, or other brand attributes that can be represented in a binary matrix [
1]; in the evaluation of the impact of public policies, the answers used to identify whether the beneficiaries have some characteristics or to identify if some economic or social conditions have changed from a baseline are usually binary [
2,
3,
4]. Likewise, in biological research—and in particular in the analysis of genetic and epigenetic alterations—the amount of binary data has been increasing over time [
5]. In these cases, classical methods to reduce dimensionality, such as principal component analysis (PCA), are not appropriate.
This problem has received considerable attention in the literature; consequently, different extensions of PCA have been proposed. From a probabilistic perspective, Collins et al. [
6] provide a generalization of PCA to exponential family data using the generalized linear model framework. This approach suggests the possibility of having proper likelihood loss functions depending on the type of data.
Logistic PCA is the extension of the classic PCA method for binary data and was studied by Schein et al. [
7] using the Bernoulli likelihood, where an alternating least squares method is used to estimate the parameters. De Leeuw [
8] proposed the calculation of the maximum likelihood estimates of a PCA on the logit or probit scale, using a MM algorithm that iterates a sequence of weighted or unweighted singular value decompositions. Subsequently, Lee et al. [
9] introduced sparsity to the loading vectors defined on the logit transform of the success probabilities of the binary observations and estimated the parameters using an iterative weighted least squares algorithm, but the algorithm is computationally too demanding to be useful when the data dimension is high. To solve this problem, a different method was proposed by Lee and Huang [
10] using a combined algorithm with coordinate descent and MM to reduce the computational effort. More recently, Landgraf and Lee [
11] proposed a formulation that does not require matrix factorization, and they use an MM algorithm to estimate the parameters of the logistic PCA model. Song et al. [
12] proposed the fitting of a logistic PCA model using an MM algorithm across a non-convex singular value threshold to alleviate the overfitting issues. However, neither of these approaches provides a simultaneous representation of rows and columns to visualize the binary data set, similar to what is called a biplot for continuous data [
13].
The biplot methods allow the simultaneous representation of the individuals and variables of a data matrix [
14]. Biplots have proven to be very useful for analyzing multivariate continuous data [
15,
16,
17,
18,
19] and have also been implemented to visualize the results of other multivariate techniques such as multidimensional scaling, MANOVA, canonical analysis, correspondence analysis, generalized bilinear models, and the HJ-Biplot, among many others [
14,
20,
21,
22,
23,
24].
In cases where the variables of the data matrix are not continuous, a classical linear biplot representation is not suitable. Gabriel [
25] proposed the “bilinear regression” to fit a biplot for data with distributions from the exponential family, but the algorithm was not clearly established and was never used in practice. For multivariate binary data, Vicente-Villardon et al. [
26] proposed a biplot called Logistic Biplot (LB), which is a dimension reduction technique that generalizes PCA to cope with binary variables and has the advantage of simultaneously representing individuals and variables. In the LB, each individual is represented by a point and each variable as directed vectors, and the orthogonal projection of each point onto these vectors predicts the expected probability that the characteristic occurs. The method is related to logistic regression in the same way that classical biplot analysis is related to linear regression. In the same way, as linear biplots are related to PCA, LB is related to Latent Trait Analysis (LTA) or Item Response Theory (IRT).
The authors estimate the parameters of the LB model by a Newton–Raphson algorithm, but this presents some problems in the presence of separation or sparsity. In [
27], the method is extended using a combination of principal coordinates and standard logistic regression to approximate the LB model parameters in the genotype classification context and is called an external logistic biplot, but the procedure of estimation is quite inefficient for big data matrices. More recently, in [
28], the external logistic biplot method was extended for mixed data types, but the estimation algorithm still has problems with big data matrices or in the presence of sparsity. Therefore, there is a clear need to extend the previous algorithms for the LB model because they are not very efficient and none of them present a procedure for choosing the number of dimensions of the final solution of the model.
In the context of supervised learning, some optimization methods have been successfully implemented for logistic regression. For example, Komarek and Moore [
29] develops Truncated-Regularized Iteratively-Reweighted Least Squares (TR-IRLS) technique that implements a linear Conjugate Gradient (CG) to approximate the Newton direction. The algorithm is especially useful for large, sparse data sets because it is fast, accurate, robust to linear dependencies, and no data preprocessing is necessary. Furthermore, another of the advantages of the CG method is that it guarantees convergence in a maximum number of steps [
30]. On the other hand, when the imbalance is extreme, this problem is known as the rare events problem or the imbalanced data problem, which presents several problems and challenges to existing classification algorithms [
31]. Maalouf and Siddiqi [
32] developed a method of Rare Event Weighted Logistic Regression (RE-WLR) for the classification of imbalanced data on large-scale data.
In this paper, we propose the estimation of the parameters of the LB model in two different ways: one of these is to use CG methods, and the other way is to use a coordinate descendent MM algorithm. In addition, we incorporate a cross-validation procedure to estimate the generalization error and thus choose the number of dimensions in the LB model.
Taking into account the latent variables and model specification that defines a LB, a simulation process is carried out that allows for the evaluation of the performance of the algorithms and their ability to identify the correct number of dimensions to represent the multivariate binary data matrix adequately. Besides the proposed methods, the BiplotML package [
33] was written in R language [
34] to give practical support to the new algorithms.
The paper is organized into the following sections.
Section 2.1 presents the classical biplot for continuous data. Next,
Section 2.2 presents the formulation of the LB model.
Section 2.3 introduces the proposed adaptation of the CG algorithm and the coordinate descendent MM algorithm to fit the LB model.
Section 2.4 describes the model selection procedure (number of dimensions) and introduces our formulation via simulated data.
Section 3 presents the performance of the proposed models and an application using real data. Finally,
Section 4 presents a discussion of the main results.
3. Results
3.1. Monte Carlo Study
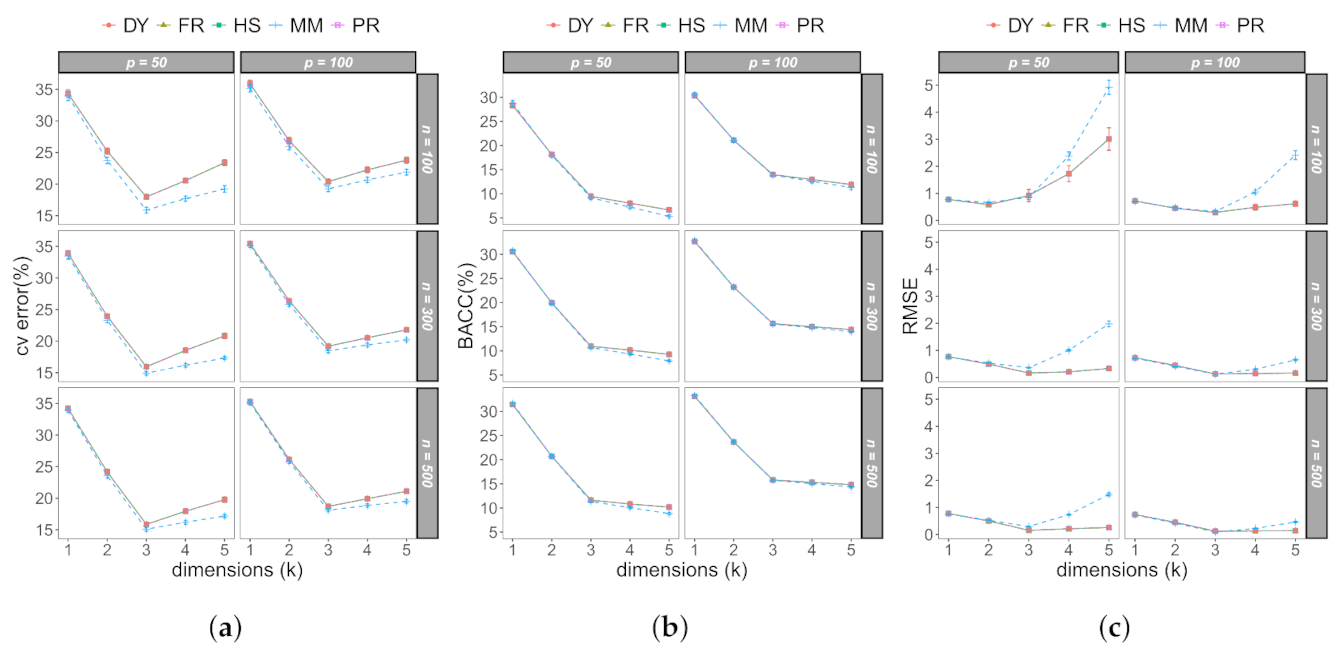
Binary matrices were simulated with ; ; ; and , where the parameter D represents the proportion of ones in matrix . The different sparsity levels were simulated to check if the performance with the algorithms to find the low-dimensional structure was affected for this reason. The combinations of n, p, k, and D generated the different scenarios; in each scenario, R matrices were simulated independently, and the measures were calculated to evaluate the performance of the algorithms. Finally, the mean of the cross-validation error (cv error) was calculated, as well as the mean of the training error (BACC) and the mean of the relative mean squared error (RMSE) with their respective standard errors. We used a value of that generated standard errors less than in the estimation of the BACC and cv error.
Figure 1a presents the cross-validation error of the algorithms based on the conjugate gradient and the MM algorithm when the matrix
is balanced. From the cv error, we can see that all models began to overfit when
, so the five estimation methods identified the three underlying dimensions for all balanced scenarios that were simulated.
Figure 1b shows the Balanced Accuracy (BACC); it is highlighted that the slope decelerated when the three underlying dimensions were reached in the matrix, and thus an elbow criterion could be used as a signal of the number of dimensions to choose. Finally,
Figure 1c shows the estimation of the relative mean squared error (RMSE) for the matrix
; we see that the algorithms based on the conjugate gradient and the MM algorithm showed similar results when the number of dimensions was less than or equal to 3. Whereas, when the model had more than the three predefined dimensions in the simulation, the algorithms based on the conjugate gradient presented a lower RMSE than the MM algorithm, although, for a fixed value of
p, these gaps closed as
n increased.
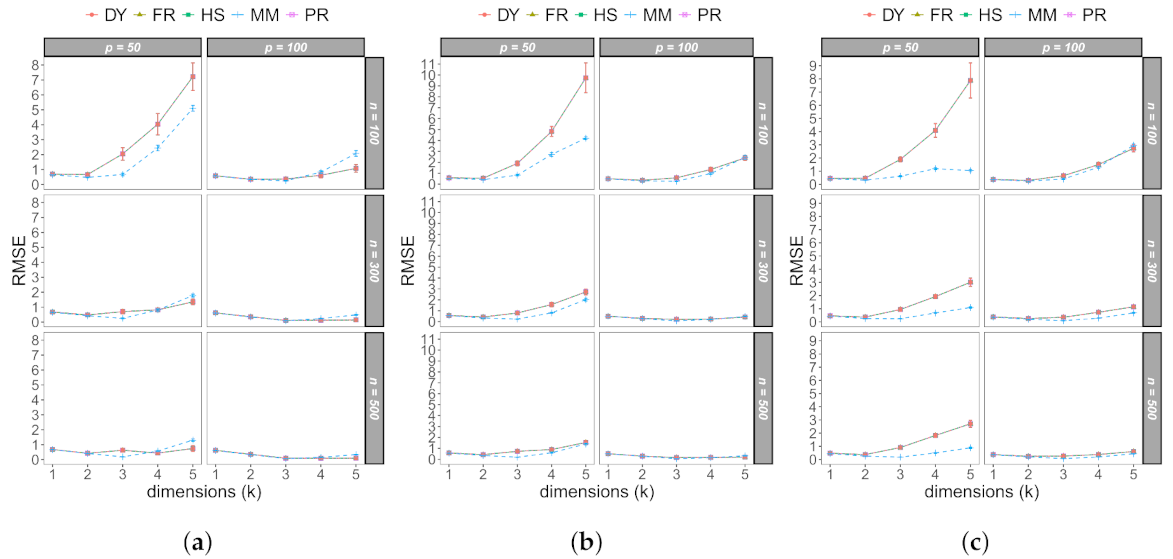
Figure 2a–c show the cross-validation errors when the data are imbalanced with
, and
, respectively. In all the scenarios studied, it is observed that the error was minimized when the number of underlying dimensions in the space of the variables was reached, so our method identified that a value of
in the LB model was appropriate to avoid overfitting. As this occurred with all imbalanced data sets, then we see that the level of dispersion does not affect the performance of the algorithms in terms of correctly finding the low-dimensional space.
The training error for imbalanced data sets with different levels of sparsity is shown in
Figure 3a–c. In all the studied scenarios, it is observed that the percentage of loss in the training error stabilized from the third dimension. In this way, the different algorithms allowed the low-dimensional space to be appropriately selected using the elbow method.
The RMSE of the estimation of the log-odds
for the different levels of sparsity is shown in
Figure 4a–c; we can see that the algorithms presented similar performances. In the scenarios of
and
, it is observed that the RMSE increased notably when the number of dimensions was greater than 3, so there were some important gaps between the two approaches, although these differences decreased as the value of
p or the value of
n increased.
On the other hand, the computational performance of the algorithms was measured on a computer with an Intel Core i7-3517U processor with 6 GB of RAM.
Table 1 shows the the running time in seconds with 100 replications for
and a stopping criterion of
. We see that the performances of the different algorithms were competitive, and they converged relatively quickly when the maximum of the absolute changes of the estimated parameters in two subsequent iterations was less than
. In general, it is observed that the CPU times of the CG algorithms were similar and presented a better performance than the MM algorithm when
and the sparsity level began to be high (
), or when
,
, and
. In the other cases, the MM algorithm performed better, especially when
n and
p increased, resulting in up to six times faster performance than CG algorithms in balanced scenarios when
and
.
3.2. Application
To apply the proposed methodology, we used data from the Genomic Determinants of Sensitivity in Cancer 1000 (GDSC1000) [
5]. The database contains 926 tumor cell lines with comprehensive measurements of point mutation, CNA, methylation, and gene expression. To illustrate the methods, the methylation data were used, and to facilitate the interpretation of the results, three types of cancer were included: breast invasive carcinoma (BRCA), lung adenocarcinoma (LUAD), and skin cutaneous melanoma (SKCM).
We performed preprocessing to sort the data sets and separate the methylation information into one data set. After preprocessing, the methylation dataset has 160 rows and 38 variables, each variable is a CpG island located in the gene promoter area. In this case, code 1 indicates a high level of methylation, and 0 indicates a low level; approximately of the binary data matrix are ones.
Figure 5 shows the cross-validation error and training error using the conjugate gradient algorithms and the coordinate descendent MM algorithm. If
, the model (
6) only considered the term
, meaning that
, where
is the proportion of ones in column
j and was used as a reference to observe the performance of the algorithms when more dimensions were included by incorporating the row and column markers,
.
The cross-validation error was minimized in three dimensions for the four formulas (FR, HS, PR, and DY) based on the CG algorithm, so was the appropriate value to avoid overfitting when using these methods of estimation. When using the MM algorithm, it was found that the LB model generated overfitting for , so using two dimensions in the LB model is suitable when using this estimation method.
An advantage of using a biplot approach is that it allows for a simultaneous representation of rows and columns, which are plotted with points and directed vectors, respectively.
Figure 6 shows the biplot obtained for the methylation data using the Fletcher–Reeves conjugate gradient algorithm; the vectors of the variables are represented by arrows (segments) that start at the point that predicts
and end at the point that predicts
. Therefore, short vectors indicate a rapid increase in probability and the orthogonal projection of the row markers on the vector approximates the probability of finding high levels of methylation in the cell line.
The position of the segment, which corresponds to the point that predicts a probability of 0.5, can start any side around the origin. For example, in
Figure 6, the variable DUSP22 points to the origin, when doing the orthogonal projection of the points in the direction of the vector, most of them will be projected after the reference point where the segment starts; this means that almost all cell lines of the three groups have high fitted probabilities of having high levels of methylation in that variable.
The cell lines are separated into three clearly identified clusters. In the BRCA type of cancer, variables such as NAPRT1, THY1, or ADCY4 are directed towards the positive part of dimension 1 and therefore have a greater probability of presenting high levels of methylation. The LUAD cell lines are located in the negative part of dimension 2, so these have a high propensity to present high levels of methylation in variables such as HIST1H2BH, ZNF382, and XKR6. Finally, the cell lines for the SKCM cancer type are located in the negative part of dimension 1 and have a greater probability of presenting high levels of methylation in variables such as LOC100130522, CHRFAM7A, or DHRS4L2.
Table 2 shows the rate of correct classifications for each variable using the measures of sensitivity and specificity; these measures allowed us to determine if the model exhibited a good classification for the two types of data in each variable. Sensitivity measured the true positives rate, specificity measured the true negatives rate, and the global measure corresponded to the total rate of correct classifications for each variable.
In general, the model with three dimensions and using the CG algorithm with the FR formula generated high values for sensitivity; only the GSTT1 gene presented a relatively low sensitivity, with 72% true positives. Regarding specificity, the LOC391322 gene obtained the lowest true negatives rate, with 80.9%. Thus, the results of the model are satisfactory.
4. Conclusions and Discussion
The Logistic Biplot (LB) model is a dimensionality reduction technique that generalizes the PCA to deal with binary variables and has the advantage of simultaneously representing individuals and variables (biplot).
In this paper, we propose and develop a methodology to estimate the parameters of the LB model using nonlinear conjugate gradient algorithms or the descending coordinate MM algorithm. For the selection of the LB model, we have incorporated a cross-validation procedure that allows the choice of the number of dimensions of the model in order to counteract overfitting.
As a complement to the proposed methods and to give practical support, a package has been written in the R language called
BiplotML package [
33], which is available from CRAN; this is a valuable tool that enables the application of the proposed algorithms to data analysis in every scientific field. Our contribution is important because we provide alternatives to solve some problems encountered in the LB model in the presence of sparsity or a big data matrix [
23,
26,
27,
28]. Additionally, a procedure is presented that allows the choice of the number of dimensions, which until now had not been investigated for an LB model.
The proposed algorithms are iterative and have the property that the loss function decreases with each iteration. To study the properties of the proposed algorithms to fit a LB model, low rank data sets with and different levels of sparsity were generated for rows and columns. The accuracy of the algorithms was measured using the training error, generalization error (cv-error), and mean square error (RMSE) of the log-odds. According to the Monte Carlo study, we established that the cross-validation criterion is successful in the estimation of the hyperparameter of the number of dimensions. This allows the model to be specified and thus avoid overfitting; in this way, we obtain the best performance of the proposed algorithms in terms of recovering the underlying low rank structure.
The comparison of the running times showed that the algorithms converge quickly. The CG algorithm is more efficient when the matrices are sparse and not very large, while the performance of the MM algorithm is better when the number of rows and columns tends to increase; thus, it is preferable for large matrices.
Finally, we used real data on gene expression methylation to show our approach. The LB model allowed us to carry out a simultaneous projection between rows and columns, where a grouping of three classes was observed, formed by the cell lines of the three types of cancer analyzed. Furthermore, the vectors that represented the variables allowed us to identify those cell lines that were more likely to achieve high levels of methylation in the different genes.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}