
Time-Consistency of an Imputation in a Cooperative Hybrid Differential Game



{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Problem Formulation
2.1. Differential Game
- The controls are assumed to be piecewise continuous functions on the interval that belong to the set of admissible control values , which are consequently convex compact subsets of . The optimal controls are further assumed to be open-loop, i.e., they are defined as functions of t.
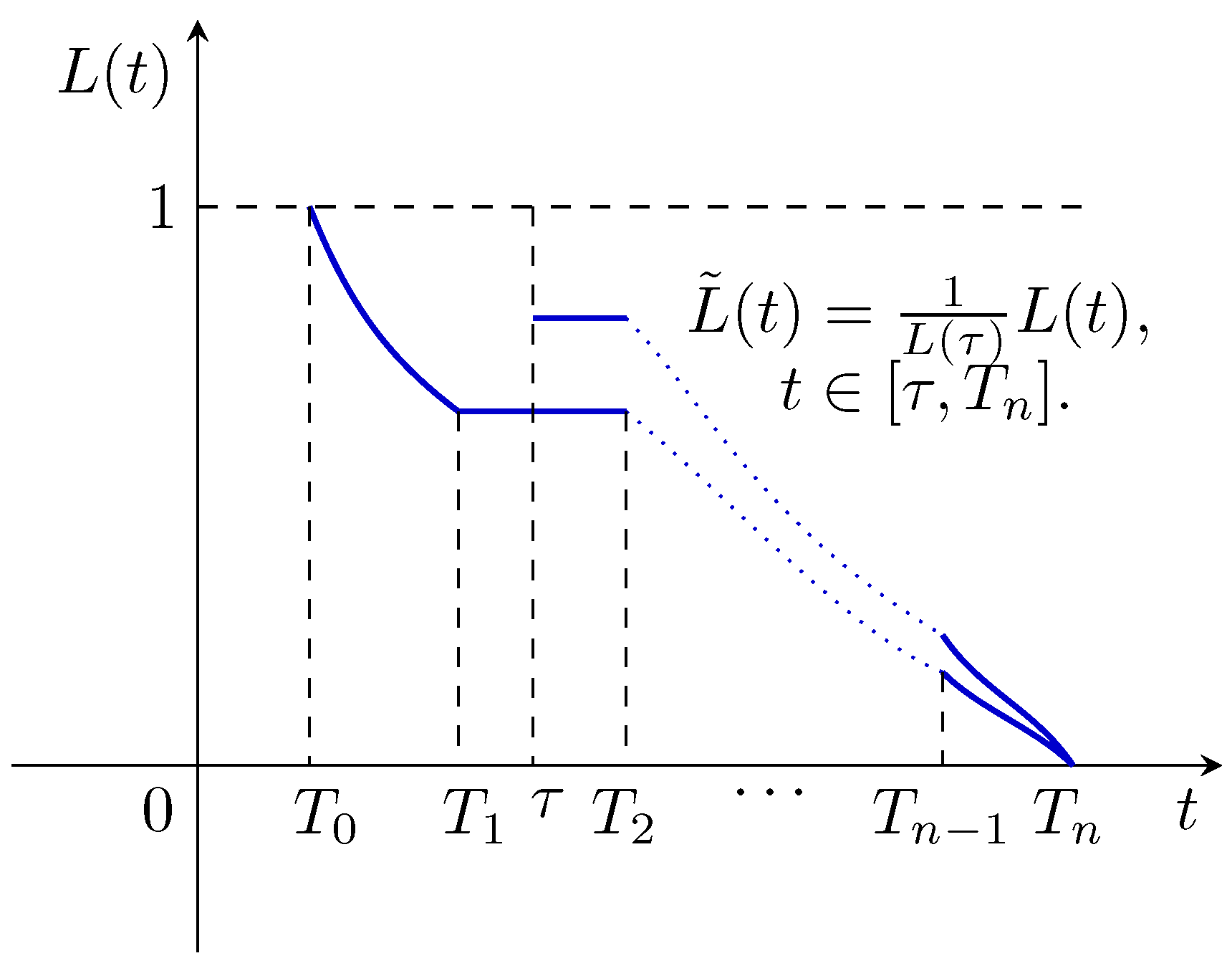
- and , i.e., the discounting function is equal to 1 at the initial time and 0 at the final time;
- , are non-increasing and continuously differentiable a.e. functions on ;
- The discounting functions on the neighboring intervals agree at the switching points:
- ; ;
- , are non-decreasing and continuously differentiable a.e. on .
2.2. Subgame
2.3. Cooperative Differential Game
3. Computation of IDP: A Numerical Example
3.1. Description of the Model
3.2. Optimal Solution
3.3. Optimal Solutions for Subgames
3.4. Computation of the Imputation Distribution Procedure (IDP)
- For all the vector , wherefor all , belongs to the same optimality principle in the subgame , i.e., is an imputation in ;
- For all the vector , wherefor all , belongs to the same optimality principle in the subgame , i.e., is an imputation in ;
- For all the vector wherefor all , belongs to the same optimality principle in the subgame , i.e., is an imputation in ;
- For all the vector wherefor all , belongs to the same optimality principle in the subgame , i.e., is an imputation in .
3.5. Numerical Illustration of the Computed IDP Numeric Example
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Petrosyan, L.; Murzov, N. Game-theoretic problems of mechanics. Litovsk. Math. Sb. 1966, 7, 423–433. [Google Scholar]
- Marin-Solano, J.; Shevkoplyas, E. Non-constant discounting and differential games with random time horizon. Automatica 2011, 47, 2626–2638. [Google Scholar] [CrossRef]
- Marin-Solano, J.; Patxot, C. Heterogeneous discounting in economic problems. Optim. Control Appl. Methods 2012, 33, 32–50. [Google Scholar] [CrossRef]
- de-Paz, A.; Marin-Solano, J.; Navas, J. A consumption investment problem with heterogeneous discounting. Math. Soc. Sci. 2013, 66, 221–232. [Google Scholar] [CrossRef]
- de-Paz, A.; Marin-Solano, J.; Navas, J.; Roch, O. Consumption, investment and life insurance strategies with heterogeneous discounting. Insur. Math. Econ. 2014, 54, 66–75. [Google Scholar] [CrossRef] [Green Version]
- de Frutos Cachorro, J.; Marin-Solano, J.; Navas, J. Competition between different groundwater uses under water scarcity. Water Resour. Econ. 2021, 33, 100173. [Google Scholar] [CrossRef]
- Riedinger, P.; Iung, C.; Kratz, F. An optimal control approach for hybrid systems. Eur. J. Control 2003, 9, 449–458. [Google Scholar] [CrossRef] [Green Version]
- Shaikh, M.S.; Caines, P.E. On the hybrid optimal control problem: Theory and algorithms. IEEE Trans. Autom. Control 2007, 52, 1587–1603. [Google Scholar] [CrossRef]
- Bonneuil, N.; Boucekkine, R. Optimal transition to renewable energy with threshold of irreversible pollution. Eur. J. Oper. Res. 2016, 248, 257–262. [Google Scholar] [CrossRef] [Green Version]
- Elliott, R.J.; Siu, T.K. A stochastic differential game for optimal investment of an insurer with regime switching. Quant. Financ. 2011, 11, 365–380. [Google Scholar] [CrossRef]
- Gromov, D.; Bondarev, A.; Gromova, E. On periodic solution to control problem with time-driven switching. Optim. Lett. 2021. in print. [Google Scholar] [CrossRef]
- Kuhn, M.; Wrzaczek, S. Rationally Risking Addiction: A Two-Stage Approach. In Dynamic Modeling and Econometrics in Economics and Finance; Dynamic Economic Problems with Regime Switches; Springer: Berlin/Heidelberg, Germany, 2021; pp. 85–110. [Google Scholar]
- Reddy, P.; Schumacher, J.; Engwerda, J. Optimal management with hybrid dynamics—The shallow lake problem. In Mathematical Control Theory I; Springer: Berlin/Heidelberg, Germany, 2015; pp. 111–136. [Google Scholar]
- Gromov, D.; Gromova, E. Differential games with random duration: A hybrid systems formulation. Contrib. Game Theory Manag. 2014, 7, 104–119. [Google Scholar]
- Gromov, D.; Gromova, E. On a Class of Hybrid Differential Games. Dyn. Games Appl. 2017, 7, 266–288. [Google Scholar] [CrossRef]
- Gromova, E.; Malakhova, A.; Palestini, A. Payoff Distribution in a Multi-Company Extraction Game with Uncertain Duration. Mathematics 2018, 6, 165. [Google Scholar] [CrossRef] [Green Version]
- Zaremba, A.; Gromova, E.; Tur, A. A Differential Game with Random Time Horizon and Discontinuous Distribution. Mathematics 2020, 8, 2185. [Google Scholar] [CrossRef]
- Lin, Q.; Ryan, L.; Kok, L.T. The control parameterization method for nonlinear optimal control: A survey. J. Ind. Manag. Optim. 2014, 10, 275–309. [Google Scholar] [CrossRef]
- Pontryagin, L.; Boltyanskii, V.; Gamkrelidze, R.; Mishchenko, E. The Mathematical Theory of Optimal Processes; Interscience: New York, NY, USA, 1962. [Google Scholar]
- Finkelstein, M. Failure Rate Modelling for Reliability and Risk; Springer: Berlin/Heidelberg, Germany, 2008; 290p. [Google Scholar]
- Petrosjan, L. Stability of solutions in differential many-player games. Vestn. Leningr. Univ. 1977, 4, 46–52. (In Russian) [Google Scholar]
- Petrosjan, L.A. The Shapley value for differential games. New Trends Dyn. Games Appl. 1995, 3, 409–417. [Google Scholar]
- Petrosyan, L.; Danilov, N. Cooperative Differential Games and Their Applications; Izd. Tomskogo Universiteta: Tomsk, Russia, 1982. [Google Scholar]
- Petrosyan, L.A.; Zaccour, G. Cooperative differential games with transferable payoffs. In Handbook of Dynamic Game Theory; Springer: Cham, Switzerland, 2018; pp. 595–632. [Google Scholar]
- Gromova, E. The Shapley value as a sustainable cooperative solution in differential games of three players. In Recent Advances in Game Theory and Applications; Birkhäuser: Cham, Switzerland, 2016; pp. 67–89. [Google Scholar]
- Dockner, E.J.; Jorgensen, S.; Van Long, N.; Sorger, G. Differential Games in Economics and Management Science; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gromova, E.; Zaremba, A.; Su, S. Time-Consistency of an Imputation in a Cooperative Hybrid Differential Game. Mathematics 2021, 9, 1830. https://doi.org/10.3390/math9151830
Gromova E, Zaremba A, Su S. Time-Consistency of an Imputation in a Cooperative Hybrid Differential Game. Mathematics. 2021; 9(15):1830. https://doi.org/10.3390/math9151830
Chicago/Turabian StyleGromova, Ekaterina, Anastasiia Zaremba, and Shimai Su. 2021. "Time-Consistency of an Imputation in a Cooperative Hybrid Differential Game" Mathematics 9, no. 15: 1830. https://doi.org/10.3390/math9151830