
A Theoretical Model for Global Optimization of Parallel Algorithms


Abstract
:1. Introduction
- A model of parallel algorithms is introduced, which abstracts the algorithmic structure from the executed functions. This model facilitates the analysis of global algorithmic properties while building on a flexible definition of local parallel structures.
- A new class of global transformation techniques is enabled by introducing necessary performance conditions called algorithmic efficiencies. Three main efficiencies are identified: synchronization, inter-processor dataflow, and intra-processor dataflow efficiency.
- The model’s applicability is demonstrated on three typical parallel algorithms showcasing the major transformation capabilities, and their performance improvements are investigated.
2. Related Work
2.1. Abstractions for Parallel Programming
2.2. Transformation Techniques
2.3. Architectural Mapping and Code Generation
3. A Theoretical Model of Parallel Algorithms
3.1. Performance Definition and Model Assumptions
- Local Optimality: Locally, the parallel hotspots have been identified, and the potential independence of their operations is expressed optimally in the algorithmic structure. This assumption can be assured by methods for identifying concurrency, such as introduced by Mattson et al. [5].
- Correct: All dependencies are well-defined, and the algorithm is free of data races, deadlocks, and similar correctness issues.
3.2. Algorithmic Representation
- A data item, in short data, is produced and consumed as the result of computations during the execution of an algorithm. Thereby, a data item is immutable and does not refer to a memory location.
- An operation is a set of instructions producing and consuming data, which resembles the task definition of typical parallel programming models. This set of instructions is interpreted atomically.
- A place is a source (does not consume data) or a sink (does not produce data), i.e., external inputs and outputs of the parallel algorithm.
- A data dependency between operations occurs when one operation consumes a data item another operation produces. The definition by A. J. Bernstein [46] corresponds to a flow dependency (or true dependency, read-after-write, RAW).
3.2.1. Local Structures: Serial and Parallel Patterns
- An operation depends on another operation , iff there is a non-empty directed path from to o. All other operations are independent (cf. happens-before relation [47]).
- Let be an operation and let be the depending operations of o, i.e., . The earliest-execution-time of o is defined as (all operands are available) with for any place p.
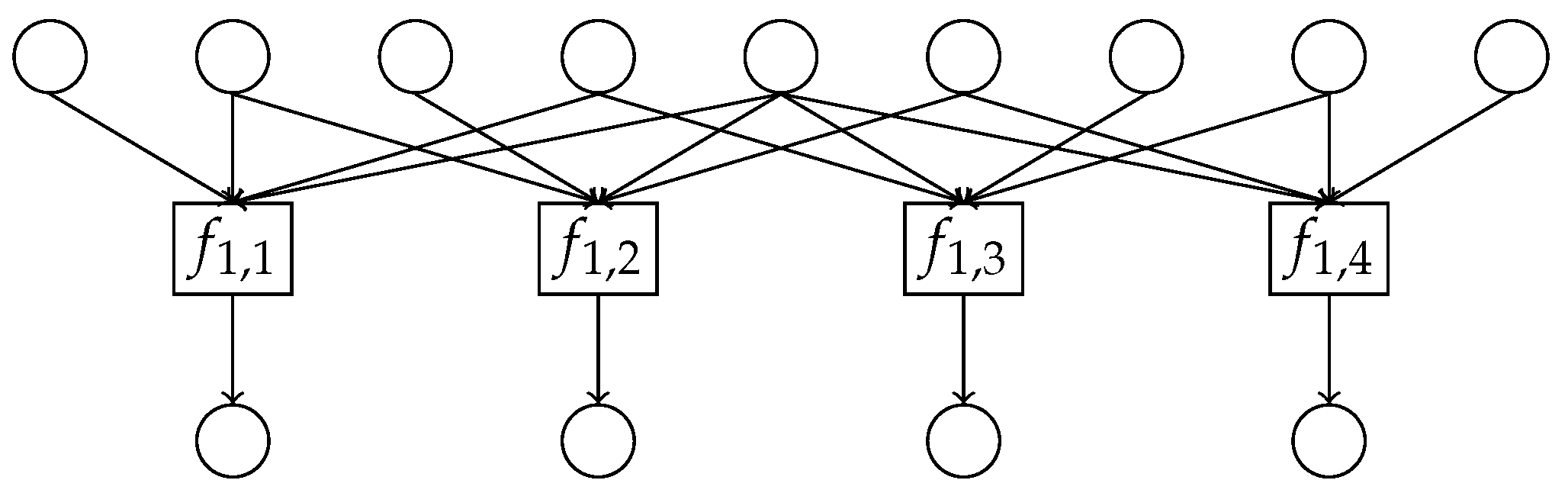
- Let denote the set of all pairwise independent operations with earliest-execution-time of n. The operations of are pairwise parallel and form a single logical step of the pattern.
3.2.2. Global Structure: Abstract Pattern Tree
3.2.3. Basic Notations
4. Algorithmic Efficiencies
4.1. Algorithmic Steps and Synchronization
4.2. Inter-Processor Dataflow
Cost Modeling
- Execution costs: The execution of operations is captured by the number of floating point operations (FLOPS) divided by the peak performance (clock frequency times FLOPS per cycle):
- Network costs: The network costs are defined as the slowest data transfer between two processors. A data transfer thereby bundles all bytes to be transferred from one processor to another to satisfy the data dependencies. The bandwidth is determined by the slowest interconnect between these two processors and a latency penalty is added:
4.3. Intra-Processor Dataflow
5. Evaluation
5.1. Experimental Setup
- Jacobi: The problem showcases the capabilities of the model for applying algorithmic changes. Two linear equation systems and are defined who share A and are of size 8192 × 8192. The equations are solved iteratively with the Jacobi algorithm and a fixed number of iterations for both systems.
- k-means: The problem showcases the automatic accelerator offloading capabilities of the model. The algorithm partitions data points into clusters. The mean Euclidean distances of the data points to their respective nearest cluster are minimized iteratively in 100 iterations.
- Monte Carlo Pi: The problem showcases the distributed computing capabilities of the model. It defines the approximation of via the Monte Carlo method. The area of a unit circle is accumulated by averaging over 96 independent estimations with random draws each.
5.2. Results
5.2.1. Jacobi Algorithm
- The two Jacobi applications are independent and could be fused into a single sequence of Jacobi iterations.
- In each iteration, the corresponding rows between both equation systems share the same data from matrix A.
5.2.2. k-Means Algorithm
5.2.3. Monte Carlo Pi
6. Discussion
6.1. Analysis of the Results
6.2. Performance Model
6.3. Optimizations
6.4. Integration into Compiler Frameworks
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Asanovic, K.; Bodik, R.; Demmel, J.; Keaveny, T.; Keutzer, K.; Kubiatowicz, J.; Morgan, N.; Patterson, D.; Sen, K.; Wawrzynek, J.; et al. A View of the Parallel Computing Landscape. Commun. ACM 2009, 52, 56–67. [Google Scholar] [CrossRef] [Green Version]
- Bacon, D.F.; Graham, S.L.; Sharp, O.J. Compiler Transformations for High-performance Computing. ACM Comput. Surv. 1994, 26, 345–420. [Google Scholar] [CrossRef] [Green Version]
- OpenMP API for Parallel Programming, Version 5.0. Available online: https://www.openmp.org/wp-content/uploads/OpenMP-API-Specification-5.0.pdf (accessed on 25 June 2021).
- MPI Forum. MPI: A Message-Passing Interface Standard, Version 3.1. Available online: https://www.mpi-forum.org/docs/mpi-3.1/mpi31-report.pdf (accessed on 25 June 2021).
- Mattson, T.G.; Sanders, B.; Massingill, B. Patterns for Parallel Programming; Pearson Education: Amsterdam, The Netherlands, 2004. [Google Scholar]
- McCool, M.D.; Robison, A.D.; Reinders, J. Structured Parallel Programming—Patterns for Efficient Computation; Elsevier: Amsterdam, The Netherlands, 2012. [Google Scholar]
- RAJA Performance Portability Layer. Available online: https://github.com/LLNL/RAJA (accessed on 25 June 2021).
- Edwards, H.C.; Trott, C.R.; Sunderland, D. Kokkos: Enabling manycore performance portability through polymorphic memory access patterns. J. Parallel Distrib. Comput. 2014, 74, 3202–3216. [Google Scholar] [CrossRef] [Green Version]
- Ben-Nun, T.; de Fine Licht, J.; Ziogas, A.N.; Schneider, T.; Hoefler, T. Stateful dataflow multigraphs: A data-centric model for performance portability on heterogeneous architectures. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC19), Denver, CO, USA, 17–22 November 2019; pp. 1–14. [Google Scholar]
- Alexander, C. A Pattern Language: Towns, Buildings, Construction; Oxford University Press: Oxford, UK, 1977. [Google Scholar]
- Beck, K.; Cunningham, W. Using Pattern Languages for Object Oriented Programs. In Proceedings of the Conference on Object-Oriented Programming, Systems, Languages, and Applications (OOPSLA), Orlando, FL, USA, 4–8 October 1987. [Google Scholar]
- Gamma, E. Design Patterns: Elements of Reusable Object-Oriented Software; Addison-Wesley: Reading, MA, USA, 1995; Volume 99. [Google Scholar]
- Cole, M. Algorithmic Skeletons: Structured Management of Parallel Computation; MIT Press: Cambridge, MA, USA, 1991. [Google Scholar]
- Darlington, J.; Guo, Y.K.; To, H.W.; Yang, J. Parallel Skeletons for Structured Composition. In Proceedings of the Fifth ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, PPOPP ’95, Santa Barbara, CA, USA, 19–21 July 1995; ACM: New York, NY, USA, 1995; pp. 19–28. [Google Scholar]
- del Rio Astorga, D.; Dolz, M.F.; Fernández, J.; García, J.D. A generic parallel pattern interface for stream and data processing. Concurr. Comput. Pract. Exp. 2017, 29, e4175. [Google Scholar] [CrossRef] [Green Version]
- Aldinucci, M.; Danelutto, M.; Kilpatrick, P.; Torquati, M. Fastflow: High-level and efficient streaming on multi-core. In Programming Multi-Core and Many-Core Computing Systems, Parallel and Distributed Computing; John Wiley & Sons, Inc.: Haboken, NJ, USA, 2017; pp. 261–280. [Google Scholar]
- Gonzàlez-Vèlez, H.; Leyton, M. A survey of algorithmic skeleton frameworks: High-level structured parallel programming enablers. Softw. Pract. Exp. 2010, 40, 1135–1160. [Google Scholar] [CrossRef]
- The OpenACC Application Programming Interface. Available online: OpenACC-Standard.org (accessed on 25 June 2021).
- The Open Standard for Parallel Programming of Heterogeneous Systems. Available online: https://www.khronos.org/opencl/ (accessed on 25 June 2021).
- C++ Single-Source Heterogeneous Programming for OpenCL. Available online: https://www.khronos.org/sycl/ (accessed on 25 June 2021).
- Ragan-Kelley, J.; Adams, A.; Paris, S.; Levoy, M.; Amarasinghe, S.; Durand, F. Decoupling algorithms from schedules for easy optimization of image processing pipelines. ACM Trans. Graph. 2012, 31. [Google Scholar] [CrossRef]
- Bezanson, J.; Karpinski, S.; Shah, V.B.; Edelman, A. Julia: A fast dynamic language for technical computing. arXiv 2012, arXiv:1209.5145. [Google Scholar]
- MATLAB (Matrix Laboratory). Available online: https://www.mathworks.com (accessed on 25 June 2021).
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation ({OSDI} 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Dean, J.; Ghemawat, S. MapReduce: Simplified data processing on large clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Chen, C.; Chame, J.; Hall, M. CHiLL: A Framework for Composing High-Level Loop Transformations; Technical Report; University of Utah School of Computing: Salt Lake City, UT, USA, 2008. [Google Scholar]
- Blelloch, G.E. NESL: A Nested Data Parallel Language; Carnegie Mellon University: Pittsburgh, PA, USA, 1992. [Google Scholar]
- Chakravarty, M.M.; Keller, G.; Lechtchinsky, R.; Pfannenstiel, W. Nepal—Nested data parallelism in Haskell. In Proceedings of the European Conference on Parallel Processing, Manchester, UK, 28–31 August 2001; Springer: Berlin/Heidelberg, Germany, 2001; pp. 524–534. [Google Scholar]
- Blelloch, G.E.; Sabot, G.W. Compiling collection-oriented languages onto massively parallel computers. J. Parallel Distrib. Comput. 1990, 8, 119–134. [Google Scholar] [CrossRef]
- Chakravarty, M.M.; Keller, G. More types for nested data parallel programming. ACM Sigplan Not. 2000, 35, 94–105. [Google Scholar] [CrossRef]
- Spoonhower, D.; Blelloch, G.E.; Harper, R.; Gibbons, P.B. Space profiling for parallel functional programs. J. Funct. Program. 2010, 20, 417–461. [Google Scholar] [CrossRef]
- Steuwer, M.; Remmelg, T.; Dubach, C. Matrix multiplication beyond auto-tuning: Rewrite-based GPU code generation. In Proceedings of the International Conference on Compilers, Architectures and Synthesis for Embedded Systems, Pittsburgh, PA, USA, 1–7 October 2016; pp. 1–10. [Google Scholar]
- Steuwer, M.; Fensch, C.; Lindley, S.; Dubach, C. Generating performance portable code using rewrite rules: From high-level functional expressions to high-performance OpenCL code. ACM Sigplan Not. 2015, 50, 205–217. [Google Scholar] [CrossRef] [Green Version]
- Rasch, A.; Schulze, R.; Gorlatch, S. Generating Portable High-Performance Code via Multi-Dimensional Homomorphisms. In Proceedings of the 2019 28th International Conference on Parallel Architectures and Compilation Techniques (PACT), Seattle, WA, USA, 23–26 September 2019; pp. 354–369. [Google Scholar]
- Lenstra, J.; Shmoys, D.; Tardos, É. Approximation Algorithms for Scheduling Unrelated Paralle Machines. In Proceedings of the 28th Annual Symposium on Foundations of Computer Science (SFCS 1987), Los Angeles, CA, USA, 12–14 October 1987; Volume 46, pp. 217–224. [Google Scholar] [CrossRef] [Green Version]
- Beaumont, O.; Becker, B.A.; DeFlumere, A.; Eyraud-Dubois, L.; Lambert, T.; Lastovetsky, A. Recent Advances in Matrix Partitioning for Parallel Computing on Heterogeneous Platforms. IEEE Trans. Parallel Distrib. Syst. 2019, 30, 218–229. [Google Scholar] [CrossRef]
- Hovestadt, M.; Kao, O.; Keller, A.; Streit, A. Scheduling in HPC resource management systems: Queuing vs. planning. In Proceedings of the Workshop on Job Scheduling Strategies for Parallel Processing, Seattle, WA, USA, 24 June 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 1–20. [Google Scholar]
- Broquedis, F.; Clet-Ortega, J.; Moreaud, S.; Furmento, N.; Goglin, B.; Mercier, G.; Thibault, S.; Namyst, R. hwloc: A generic framework for managing hardware affinities in HPC applications. In Proceedings of the 2010 18th Euromicro Conference on Parallel, Distributed and Network-Based Processing, Pisa, Italy, 17–19 February 2010; pp. 180–186. [Google Scholar]
- Newburn, C.J.; So, B.; Liu, Z.; McCool, M.; Ghuloum, A.; Du Toit, S.; Wang, Z.G.; Du, Z.H.; Chen, Y.; Wu, G.; et al. Intel’s Array Building Blocks: A retargetable, dynamic compiler and embedded language. In Proceedings of the International Symposium on Code Generation and Optimization (CGO 2011), Chamonix, France, 2–6 April 2011; pp. 224–235. [Google Scholar]
- Catanzaro, B.; Garland, M.; Keutzer, K. Copperhead: Compiling an embedded data parallel language. In Proceedings of the 16th ACM Symposium on Principles and Practice of Parallel Programming, San Antonio, TX, USA, 12–16 February 2011; pp. 47–56. [Google Scholar]
- Bondhugula, U.; Hartono, A.; Ramanujam, J.; Sadayappan, P. A practical automatic polyhedral parallelizer and locality optimizer. In Proceedings of the 29th ACM SIGPLAN Conference on Programming Language Design and Implementation, Tucson, AZ, USA, 7–13 June 2008; pp. 101–113. [Google Scholar]
- Ansel, J.; Chan, C.; Wong, Y.L.; Olszewski, M.; Zhao, Q.; Edelman, A.; Amarasinghe, S. PetaBricks: A language and compiler for algorithmic choice. ACM Sigplan Not. 2009, 44, 38–49. [Google Scholar] [CrossRef]
- Verdoolaege, S.; Carlos Juega, J.; Cohen, A.; Ignacio Gomez, J.; Tenllado, C.; Catthoor, F. Polyhedral parallel code generation for CUDA. ACM Trans. Archit. Code Optim. 2013, 9. [Google Scholar] [CrossRef] [Green Version]
- Vasilache, N.; Zinenko, O.; Theodoridis, T.; Goyal, P.; DeVito, Z.; Moses, W.S.; Verdoolaege, S.; Adams, A.; Cohen, A. Tensor comprehensions: Framework-agnostic high-performance machine learning abstractions. arXiv 2018, arXiv:1802.04730. [Google Scholar]
- Vasilache, N.; Zinenko, O.; Theodoridis, T.; Goyal, P.; Devito, Z.; Moses, W.S.; Verdoolaege, S.; Adams, A.; Cohen, A. The next 700 accelerated layers: From mathematical expressions of network computation graphs to accelerated GPU kernels, automatically. ACM Trans. Archit. Code Optim. 2019, 16, 1–26. [Google Scholar] [CrossRef] [Green Version]
- Bernstein, A.J. Analysis of Programs for Parallel Processing. IEEE Trans. Electron. Comput. 1966, 757–763. [Google Scholar] [CrossRef] [Green Version]
- Lamport, L. Time, Clocks, and the Ordering of Events in a Distributed System. Commun. ACM 1978, 21, 558–565. [Google Scholar] [CrossRef]
- Miller, J.; Trümper, L.; Terboven, C.; Müller, M.S. Poster: Efficiency of Algorithmic Structures. In Proceedings of the IEEE/ACM International Conference on High Performance Computing, Networking, Storage and Analysis (SC19), Denver, CO, USA, 17–22 November 2019. [Google Scholar]
- Hennessy, J.L.; Patterson, D.A. Computer Architecture, Fifth Edition: A Quantitative Approach, 5th ed.; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2011. [Google Scholar]
- Williams, S.; Waterman, A.; Patterson, D. Roofline: An Insightful Visual Performance Model for Multicore Architectures. Commun. ACM 2009, 52, 65–76. [Google Scholar] [CrossRef]
- Stengel, H.; Treibig, J.; Hager, G.; Wellein, G. Quantifying Performance Bottlenecks of Stencil Computations Using the Execution-Cache-Memory Model. In Proceedings of the 29th ACM on International Conference on Supercomputing, ICS ’15, Frankfurt, Germany, 12–16 June 2015; ACM: New York, NY, USA, 2015; pp. 207–216. [Google Scholar]
- Balaprakash, P.; Dongarra, J.; Gamblin, T.; Hall, M.; Hollingsworth, J.K.; Norris, B.; Vuduc, R. Autotuning in High-Performance Computing Applications. Proc. IEEE 2018, 106, 2068–2083. [Google Scholar] [CrossRef]
- Frigo, M.; Johnson, S.G. FFTW: An adaptive software architecture for the FFT. In Proceedings of the 1998 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP’98 (Cat. No. 98CH36181), Seattle, WA, USA, 15 May 1998; Volume 3, pp. 1381–1384. [Google Scholar]
- Whaley, R.C.; Dongarra, J.J. Automatically tuned linear algebra software. In Proceedings of the SC’98: Proceedings of the 1998 ACM/IEEE Conference on Supercomputing, Orlando, FL, USA, 7–13 November 1998; p. 38. [Google Scholar]
- Dever, M.; Hamilton, G. AutoPar: Automatic Parallelization of Functional Programs. In Proceedings of the 2014 Fourth International Valentin Turchin Workshop on Metacomputation, META, Pereslavl-Zalessky, Russia, 29 June–3 July 2014; Volume 2014, p. 1125. [Google Scholar]
- Bondhugula, U.; Baskaran, M.; Krishnamoorthy, S.; Ramanujam, J.; Rountev, A.; Sadayappan, P. Automatic transformations for communication-minimized parallelization and locality optimization in the polyhedral model. In Proceedings of the International Conference on Compiler Construction, Budapest, Hungary, 29 March–6 April 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 132–146. [Google Scholar]
- Li, Z.; Atre, R.; Ul-Huda, Z.; Jannesari, A.; Wolf, F. DiscoPoP: A profiling tool to identify parallelization opportunities. In Tools for High Performance Computing 2014; Springer: Berlin/Heidelberg, Germany, 2015; pp. 37–54. [Google Scholar]
- Lattner, C.; Adve, V. LLVM: A Compilation Framework for Lifelong Program Analysis & Transformation. In Proceedings of the International Symposium on Code Generation and Optimization: Feedback-Directed and Runtime Optimization, CGO ’04, San Jose, CA, USA, 20–24 March 2004; IEEE Computer Society: Washington, DC, USA, 24 March 2004; p. 75. [Google Scholar]
- Schäling, B. The Boost C++ Libraries; Boris Schäling, 2011. [Google Scholar]



{kind=link}
{kind=link}
| Algorithm | Cost [s] | Runtime [s] | Transformations | ||
|---|---|---|---|---|---|
| Base | Opt. | Base | Opt. | ||
| Jacobi | Fusion, re-ordering, pipelining | ||||
| k-means | GPU offloading | ||||
| Monte Carlo Pi | Distributed computing | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Miller, J.; Trümper, L.; Terboven, C.; Müller, M.S. A Theoretical Model for Global Optimization of Parallel Algorithms. Mathematics 2021, 9, 1685. https://doi.org/10.3390/math9141685
Miller J, Trümper L, Terboven C, Müller MS. A Theoretical Model for Global Optimization of Parallel Algorithms. Mathematics. 2021; 9(14):1685. https://doi.org/10.3390/math9141685
Chicago/Turabian StyleMiller, Julian, Lukas Trümper, Christian Terboven, and Matthias S. Müller. 2021. "A Theoretical Model for Global Optimization of Parallel Algorithms" Mathematics 9, no. 14: 1685. https://doi.org/10.3390/math9141685