1. Introduction
The expression of feelings and moods in language is one of the foundations of social communication and interaction of personal and cultural values. Linguistic expressions activate feeling as an emergent cognitive interpretation of the components of the utterance: words and their syntactic organization. According to research in cognitive science [
1] and linguistics [
2], the process of affective evaluation of a symbolic code is an important component in emergent complex phenomena of creating a sense. Without recognizing, integrating and appraising an affective value in the linguistically articulated conceptual content, be it a rough grained positive vs. negative classification or a nuanced emotional categorization, there is no real comprehension of the text. For humans, the process of experiencing affective quality is evolutionary hardwired, sub-conscious trait that is activated by social interaction. However, humans also have difficulties objectively assessing the affective value of an utterance. On the other hand, for a sequence matching quantitative system, a computer, this is an even more difficult task.
Nonetheless, in recent years there has been a surge of natural language processing (NLP) techniques and resources that address affective and subjective phenomena in text analysis. Although reductive, the resources are becoming more extensive and versatile due to their quantitative nature. At the same time, graph theory, as a branch of discrete mathematics that studies the properties of graphs, has developed applications in fields as diverse as, for instance, computer science, engineering, physics, sociology, biology, and so on. Graph theory has also had a strong impact on computational linguistics, providing representations of grammar formalism and lexical analysis, among other things. In our linguistic study, graph theory has provided a particularly powerful and useful method for modeling lexical phenomena with which we are concerned with.
This paper demonstrates the application of graph theory to the field of NLP resources and the processing of lexical affective dimensions in sentiment analysis research, and proves that it has the potential to push the quantitative nature of the research further in the qualitative direction.
Sentiment analysis aims to evaluate generalised feeling that people get from cognitive processing of an utterance without focusing on a specific class of emotions. It relies on a simplified system of classifying and/or assigning a normalized range of values for a specific affective dimension. The assignment of a value that can describe the feeling expressed in a language utterance is at the core of the process of sentiment analysis. Sentiment can be evaluated for words, concepts, multi-word phrases, sentences, paragraphs, or entire texts. However, the basic component of sentiment analysis is a word or a lexeme. Lexemes are symbolic representations of conceptual references to a class of things, psychological states and sociocultural constructs, their relations, processes, and characteristics. Some lexemes represent a concept that has a predominantly culturally associated positive feeling, such as: joy, heart, flower, etc., while some lexemes represent concepts that are associated with negative feelings, such as sorrow, death, war, etc.
The basis for conducting a sentiment analysis is sentiment dictionaries, which contain information about the sentiment dimension expressed by words, phrases or concepts. These dictionaries are created by annotating the lexical entries based on the psychological evaluation of the words or by extending the already annotated dictionaries using various NLP techniques and resources. The two main shortcomings of the dictionary approach are (1) the lack of lexical entries and (2) problems in assigning sentiment values. The first problem could be easily solved with some labeling campaigns, but the second is a more difficult beast to struggle with, as it is burdened by the inherent subjectivity of evaluating the sentiment of a text, lexical ambiguity, and the domain and culturally specific word sense.
Nevertheless, NLP researchers have proposed general strategies for sentiment dictionary enrichment using a two-step procedure: (1) sentiment seed collection and (2) sentiment value propagation. In the first step, sentiment values of seed lexical structures are manually annotated or ascribed from existing dictionaries. The second step includes the propagation of sentiment values from the seeds to the remaining parts of the foundation graph, whether it is an existing word, phrase or concept graph [
3,
4,
5,
6,
7].
In this paper, we approach the above problems by using both NLP and graph theory to develop graph methods for distinguishing word senses [
8] and lexical sentiment potential enrichment. Our approach is based on the graph propagation algorithm, which uses a corpus-based syntactic dependency layer to compute a target sentiment value. Like other sentiment enrichment systems, we start from a sentiment dictionary and map the existing sentiment values to lexical nodes. Unlike standard bag-of-words abstraction, which lacks the sequential organization of a text, or neural network (skip-gram) sequence statistical analysis that does not distinguish the syntactic dependency categories, we use coordination syntactic dependency relation between lexemes in a corpus to construct a seed lexical graph and identify conceptual clusters.
This corpus-based graph method incorporates standard natural language processing techniques: tokenization, lemmatization, part-of-speech and syntactic dependency tagging, as well as the integration of an array of metadata about the lexical nodes from knowledge databases and sentiment dictionaries. The linguistic structures are transformed into a graph that can be used as a valuable resource for the detection of sense dynamics and the representation of lexical sentiment components.
The main contributions of this paper include:
Graph method for assigning labels to semantically related lexical sense clusters of a seed lexeme using a directed WordNet-based hypernym graph layer;
Graph algorithm for extending dictionary coverage by assigning sentiment values to the non-existent lexeme dictionary entries based on a corpus-specific coordination dependency graph layer;
Graph algorithm for reevaluating sentiment values from a dictionary based on a corpus-specific coordination dependency graph layer;
Graph metrics and representation of a sentiment distribution of a seed lexeme, called sentiment potential, based on a clustering of semantically related lexemes within a corpus-specific coordination dependency graph layer;
Methodology for dynamic, transparent and corpus-specific sentiment value analysis and model creation.
These contributions introduce solutions to the problems of creating sentiment dictionaries that feature word sense discrimination, do not suffer from sparsity and can represent culturally specific sentiment values.
The paper is organized as follows. In
Section 2, we present the method of assigning labels to subgraphs in the lexical dependency graph using the hypernym relation.
Section 3, introduces the main contribution of the paper, namely the sentiment potential of lexemes. The presented assignment of sentiment values to lexemes is evaluated in
Section 4, while the proposed methodology is discussed in
Section 5. We conclude with
Section 6, where we also propose avenues for future research.
2. Labeling Lexical Graphs
As already mentioned, one of the main problems in the field of language processing is related to lexical ambiguity and semantic change. The same word may have multiple senses, or acquire new meanings, sometimes even semantically unrelated. For example, the noun lexeme bass may refer to a musical instrument or a species of fish.
This ambiguity problem is obviously related to the assignment of the sentiment value for a specific word, since each sense may have a different sentiment value. For this reason we develop a method for lexical sentiment analysis with distinguishing lexical associations for a seed word. This allows us to assign labels and compute the sentiment value for each associated sense, i.e., to assert the dynamic sentiment potential of a lexeme.
2.1. ConGraCNet: Distinguishing Lexical Associations Using Syntactic Dependency Graph
The underlying graph-based computational method for the identifying lexical associations is implemented in the ConGraCNet application [
8], developed as part of the EmoCNet project [
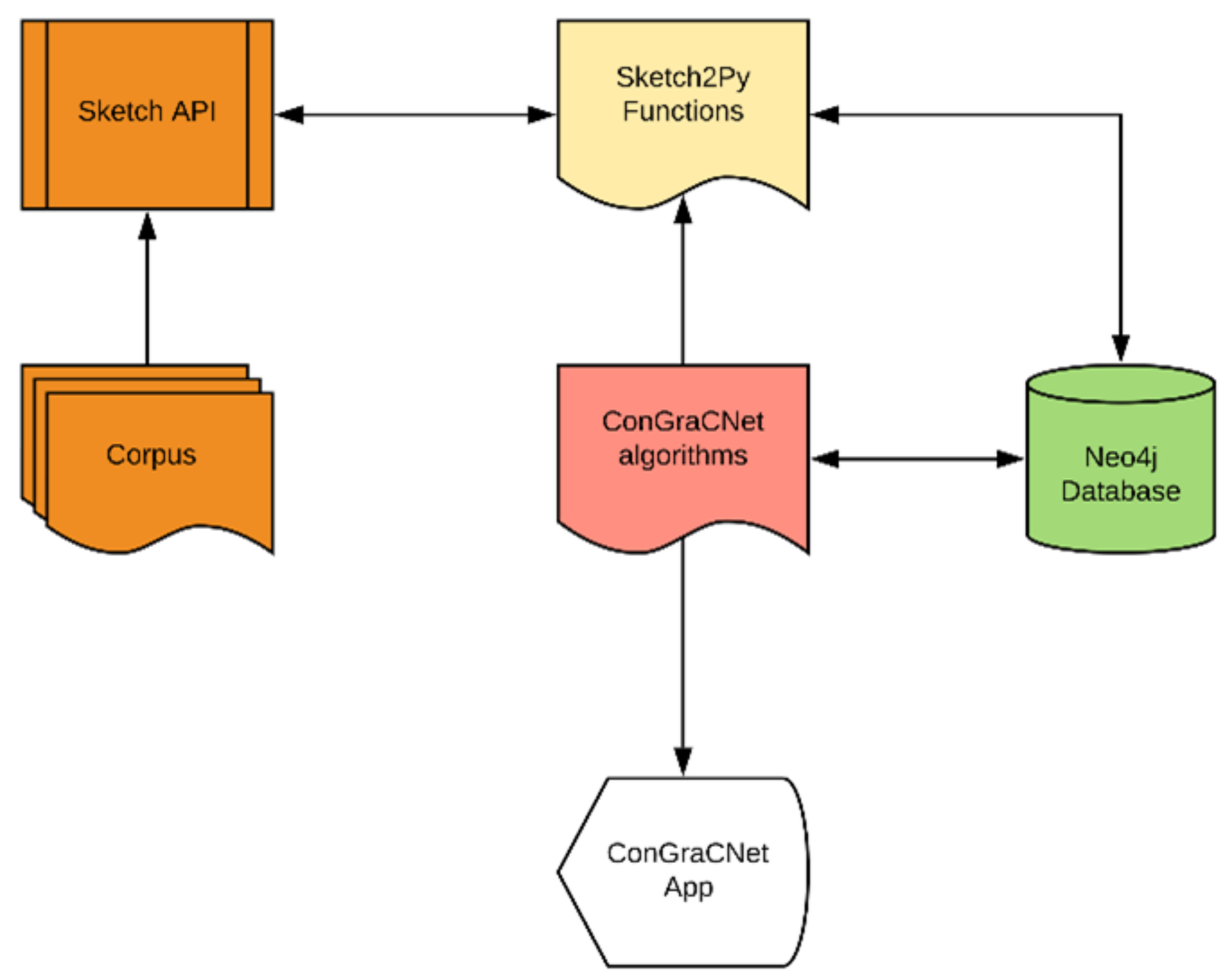
9], for tagged corpora creation, data retrieval from digital corpora, modeling, storage, algorithmic processing, sentiment analysis, and visualization of semantic-syntactic structures. The ConGraCNet application is designed to integrate data from a number of NLP pipelines, lexical dictionaries and sentiment dictionaries. In this study, we used as textual input the pipeline that collects syntactic dependency data from the morpho-syntactically tagged corpora Sketch Engine API [
10,
11]. Specifically, we use a large English Web ententen13_tt2_1 (ententen13) [
12] corpus containing 19 giga words, high frequency of lexical occurrence and various grammatical relation structures. The Sketch Engine API was used to extract a summary of various syntactic dependencies co-occurrence data for each lemma. The pipeline is shown in
Figure 1.
The tagged syntactic dependencies between lexemes in a corpus are used to construct a multilayer network of lexemes. Each layer is constructed from lexemes collocated in a syntactic dependency that can be harnessed for its semantic potential and function [
13,
14]. For example,
object of the dependency yields a network of verbs and nouns representing processes that can be performed on entities, while
adjective modifier represents the attributes of entities, etc. The association network layer constructed from collocated lexemes in the
and/or syntactic dependency, also called
coordination construction, typically associates two ontologically related entities, attributes and/or processes with an underlying tendency to be assigned to a category. Therefore, the highest-ranked co-occurrences of the seed lexeme in the coordinated construction [lexeme1 and|or lexeme2] are used to create and analyze a graph of syntactically collocated lexemes that form a kind of conceptually associated class. ConGraCNet coordination-type network construction consists of the following steps:
- (1)
Constructing a weighted undirected first-order graph (seed-friend) from the constituent lexemes in the coordination syntactic-semantic construction;
- (2)
Constructing a weighted undirected second-order friend-of-a-friend (FoF) graph from the collocated lexemes in the coordination syntactic-semantic construction;
- (3)
Identifying prominent nodes in the graph using a centrality detection algorithm;
- (4)
Centrality-based pruning of the graph;
- (5)
Identifying subgraph communities of collocated lexemes using a community detection algorithm.
The whole procedure with a number of parameters for control over graph construction, pruning and cluster granularity is implemented in [
8].
The second-degree coordination-based (pruned) graph is a representation of the conceptually associated lexemes of a seed lexeme, while the community algorithm clustering represents strongly associated senses. All lexical graphs in the research were constructed using the
n = 15 best-ranked coordination collocations in the first and second degree, and clustering was performed using the Leiden algorithm [
15] and the mvp partition type.
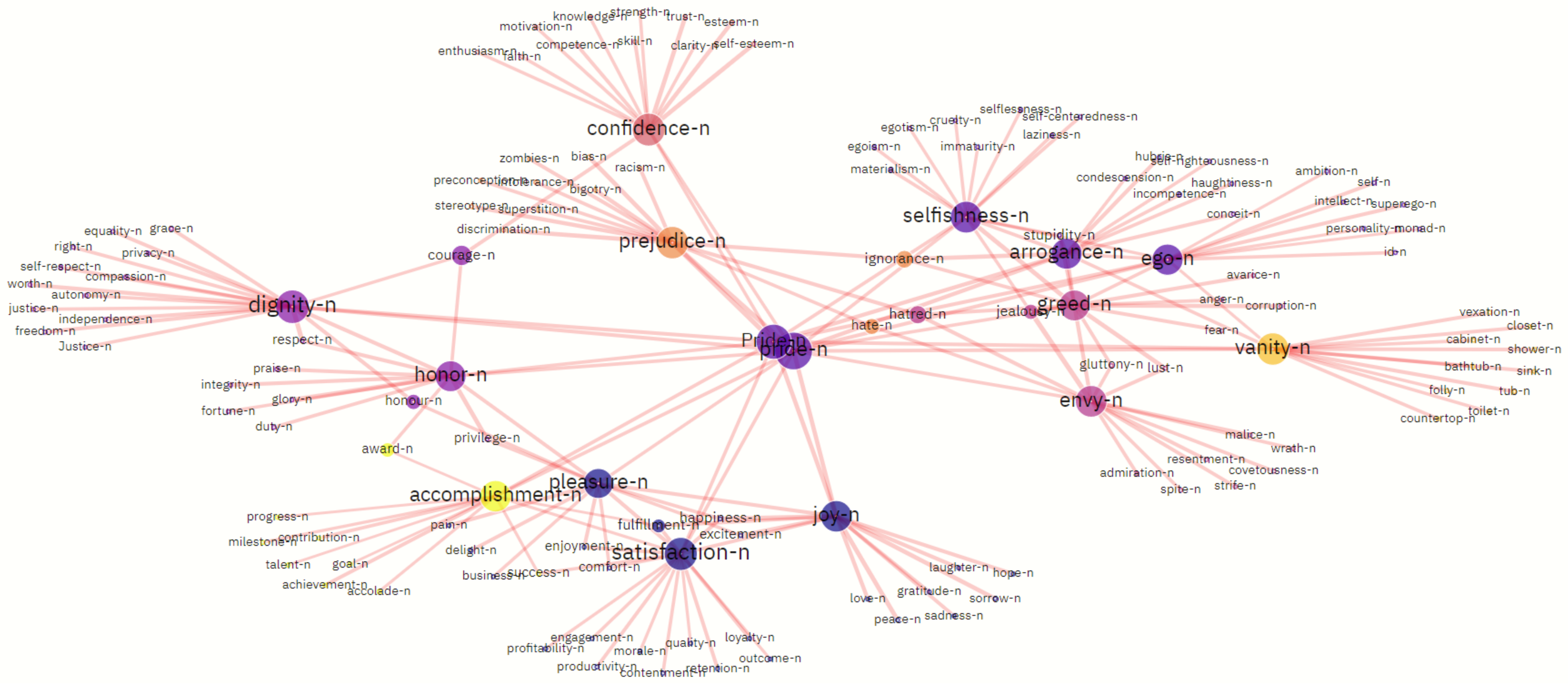
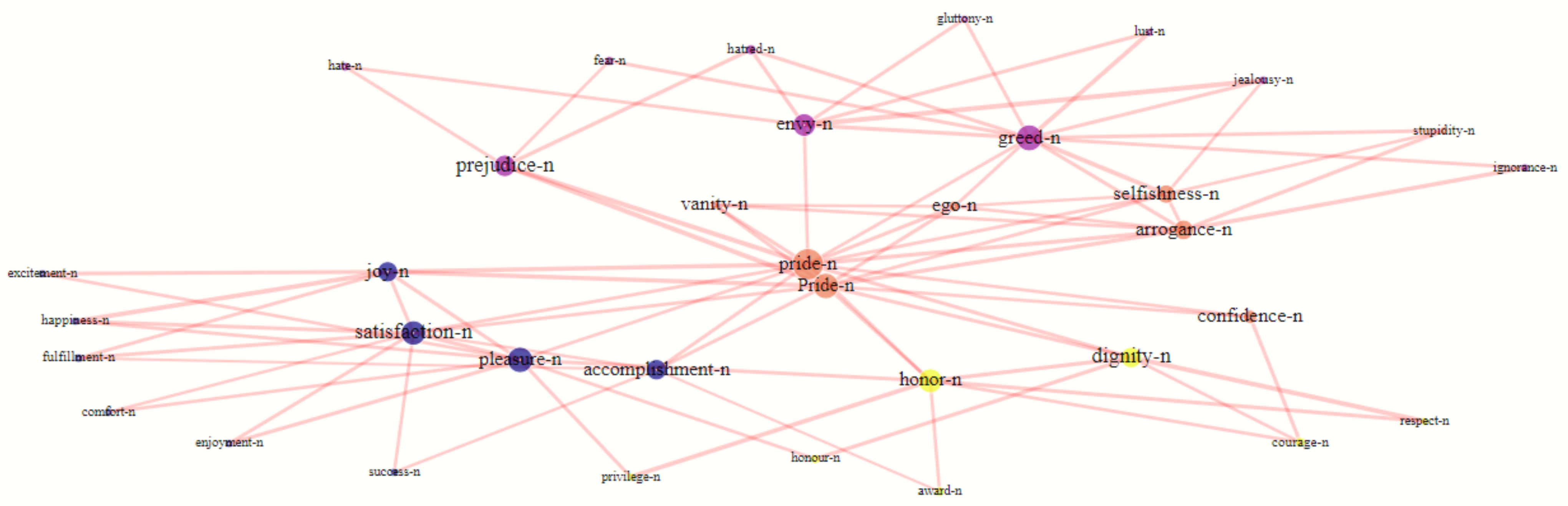
The clustered second degree coordination dependency lexical graph of the seed lexeme
pride with 143 nodes and 192 edges and 8 clusters is shown in
Figure 2. Its pruned version with 35 nodes and 84 edges in
Figure 3 is obtained by removing the nodes with
less than 2. The pruning method allows for a more concise way of representation as well as faster computation, although some marginal information is lost, the most important semantic associations are preserved. The clustered lexical communities are listed in
Table 1.
The ConGraCNet methodology has shown perspective results, e.g., in the study of linguistic expressions of emotions and the conceptual analysis of cultural framing [
16,
17,
18,
19,
20,
21].
2.2. Labeling the Lexical Associations Using the Wordnet Hypernym Relation
Once the ConGraCNet algorithm yields the graph structure with subgraph communities for a seed lexeme, it is possible to assert labels for each subgraph community. For instance, the lexical community cat, dog, mouse could be labeled domestic animals, mammals, etc.
Labeling in this sense is a kind of generalization of community features using a more abstract concept. In other words, this labeling task aims to predict the most appropriate hypernym category for a subgraph of the lexical sense community.
The WordNet hypernym labeling method is based on constructing a hypernym graph from the constituents of the lexical subgraph using WordNet synset and hypernym relations in the following steps:
- (1)
Each lexical node in a subgraph community is mapped to a lemma with corresponding WordNet synset;
- (2)
Each synset is queried for a WordNet hypernym synset, creating:
(lexeme) → [has_a_synset] → (synset) → [has_a_hypernym] → (hypernym) relation;
- (3)
The resulting directed weighted (lexeme) → (hypernym) graph is analysed with a centrality measure;
- (4)
The most central nodes in the hypernym graph are selected to represent the label of the subgraph community.
The example of the WordNet hypernym labeling procedure for the community subgraphs of the seed word
pride-n computed on the large web ententen13 corpus is shown in
Table 1.
Each directed hypernym relation is uniformly weighted with a weight of 1. The ranking of synset candidates for the most appropriate hypernym label of a coordination-based lexical community is generated using the
and the
centrality measures. Intuitively, the
measure yields the most connected nodes in the graph. The nodes with the same
are further ranked by their
values, if necessary. The
values, on the other hand, indicate the nodes with higher association based on the directed nature of the hypernym relation, thus providing a fine-tuning ranking for nodes with similar
values. The calculations are performed using the Python iGraph library [
22]. Other centrality algorithms are also being developed aiming for a greater ranking granularity and enhanced mapping of the coordination-based source nodes importance on the hypernym target nodes.
One of the main advantages of the WordNet hypernym labeling graph algorithm is the symbolic categorical assignment of lexical nodes to a class within a structured taxonomy. This allows the semantic enrichment of the associated lexical communities obtained by the bottom-up unsupervised graph classification method into a set of synsets with well-defined and curated top-down knowledge relations.
The hypernym graph abstracts the categories of lexical communities with the knowledge from the WordNet dictionary relative to the data provided by a corpus. This yields a comparable corpus-based representation of lexical usage, with the same set of graph parameters.
Table 2, for example, shows the labeling of communities based on the europarl7_en English corpus of Euro Parliamentary discussions (europarl7).
In these examples, we can see that both corpora provide a set of lexical clusters that abstract pride in the sense of an affective and emotional state feeling.n.01, in particular as a feeling of self-esteem and personal worth pride.n.01, and satisfaction with achievements pride.n.02. However, pride-n in the web corpus ententen13 is associated with the unforgivable sin that entails a total loss of grace, while the European Parliamentary corpus abstracts community with the antonyms humility-n, arrogance-n as a distinguishing feature of one’s personal nature, and provides more socially oriented labels that highlight an extended social group with a distinct cultural and economic organization at a particular time and place.
Another advantage of using WordNet is the ability to find corresponding hypernym structures in many languages via the Open Multilingual WordNet library [
23]. For example, the results of a Croatian lexical concept
ponos computed on the hrWac corpus [
24] are given in
Table 3. For example. the same concept
pride in the Croatian corpus hrwac22 associates the
ponos with the state of being honored, the state of being free and prosperous, and a feeling of gratitude and appreciation.
In this way, the corpus-based graph structures highlight the usage-based and cultural differences in the semantic processing of the same lexical concept. These features provide a transparent and consistent approach for an intra- and cross-cultural analysis of the associative semantic lexical potential for a given seed word.
As a drawback of the method, it should be noted that the lexical sparseness of the WordNet hypernym relations hinders the full scope of the mapping. Nevertheless, the structure of the coordination layer subgraphs can be compensated to some extent by the association of more frequent noun lexemes, which provide a more conventional abstract categorical label for an associated sense of a source lexeme.
In the next section we demonstrate the use of sentiment analysis resources to map and assign sentiment value to the ConGraCNet lexical graph structures.
3. Assigning Sentiment Value in Lexical Graphs
Sentiment analysis aims to provide a simplified system for classifying of the expressed feeling as well as the assigning a normalized range of values for a specific affective dimension. Sentiment can be evaluated for words, concepts, multi-word phrases, sentences, paragraphs or whole texts. As mentioned earlier, one of the problems with lexical dictionaries is related to their sparseness and rather reductive nature.
The structure of the ConGraCNet lexical graph allows the assignment of sentiment values to a single lexical item or the computation of sentiment values for missing lexemes or whole lexical communities by propagating the values from an existing sentiment dictionary.
3.1. Sentiment Dictionaries
For assigning sentiment values to lexeme nodes and their corresponding subgraph communities we rely on the existing sentiment dictionaries. Sentiment values are mapped to a lexical node using sentiment dictionaries, which contain sentiment data for words and concepts. Different dictionaries provide one or more sentiment dimensions, such as polarity, positive score, negative score, etc. In this paper, we show the mapping results for three dictionaries: SenticNet, SentiWords and Senti WordNet.
One of the most extensive sentiment lexical dictionaries available is SenticNet6 [
6,
25]. Its commonsense knowledge base of 200 k lexical concepts is built by integrative top-down and bottom-up learning over an ensemble of symbolic and sub-symbolic AI tools. The upgrading of syntactic and logical features makes this approach very compatible with the ConGraCNet approach. On the other hand, due to the number of semantic dimensions, namely the ‘polarity_score’, ‘sensitivity’, ‘attitude’, ‘temper’, and ‘introspection’, expressed in numerical values ranging from −1 to 1, we are able to calculate various numeric values representing sentiment of CongraCNet lexical nodes and community subgraphs. Throughout this paper, we mainly use the SenticNet 6 sentiment dictionary for our running examples.
SenticNet 6 was integrated into the ConGraCNet app using the Python library SenticNet 6 API [
26] to retrieve sentiment dimensions and values. Of particular interest for non-English language corpora is the integration of the multilingual feature of the BabelNetSentic module, which provides sentiment values for 40+ languages [
27].
Senti WordNet [
28] is another standard sentiment dictionary integrated into the ConGraCNet application. It assigns sentiment values to WordNet synsets instead of words. Each Senti WordNet synset has a positivity and a negativity value normalized between 0 and 1. Since the combined scores never exceed 1, it is possible to calculate the neutral value by subtracting 1-(positive+negative score). This dictionary covers more than 150 k words, with inherited synset ID, part of speech tags and gloss from the WordNet dictionary, making it possible to extend the values to non-English WordNets. This dictionary maps a single lemma to more than one synset, with potentially different sentiment values. For example, the noun
fight has positive 0 and negative 0 values for the synset glossed as ‘a boxing or wrestling match’, but positive 0 and negative 0.125 values for synset ‘an aggressive willingness to compete’. This structure that usage relies on the word sense disambiguation. This top-down approach to word sense disambiguation and sentiment assignment of the word related senses in the Senti WordNet dictionary complements our bottom-up graph approach to computing the lexical potential of the associated lexical communities.
Another sentiment analysis dictionary, SentiWords [
29,
30,
31] is a high coverage resource containing about 155 k English words associated with a sentiment score ranging between −1 and 1. The words in this resource are in the form lemma#PoS and are matched against WordNet lists (which contain adjectives, nouns, verbs and adverbs). The scores are learned from Senti WordNet and represent the computation of words’ prior polarities (i.e., the polarity for non-disambiguated words) using Senti WordNet.
3.2. Calculating Sentiment Value of a Lexical Graph
This section explains graph procedures that can be used to mitigate the problems associated with sparsity and subjectivity in sentiment analysis. In particular, it demonstrates how to propagate the sentiment value of a lexeme based on a sentiment dictionary and how to evaluate the sentiment value of a lexeme sense subgraph.
In some of the existing sentiment dictionaries, sentiment values are expressed in quantitative dimensions, such as ‘PosScore’ or ‘NegScore’ in the Senti WordNet dictionary or ‘polarity_value’, ‘attention_value’, and ‘sensitivity_value’ in the case of the SenticNet 6 dictionary. Our graph procedures refer to such numerical sentiment categories. For assigning and assessing the sentiment value of words of interest, and their associated lexical communities, we rely on ConGraCNet coordination dependency layer lexical graph with subgraph communities representing associated senses.
In the case of non-existing lexical dictionary entries, we can propagate the word sentiment value by computing the associated lexical graph sentiment value, this enriching the dictionary coverage. Moreover, the existing sentiment values for original dictionary entries can be reassessed using the same graph construction approach and calculating their sentiment value.
Given a lexical graph, we assign the sentiment value to a subgraph according to the dictionary valence values of the node lexemes and the corresponding graph structure. Node importance in the weighted undirected coordination dependency based ConGraCNet graph can be extracted using various node measures, such as
,
[
32] or
[
33]. For a chosen graph, a chosen sentiment dictionary and a sentiment category, we define the
Graph Sentiment Value (
) measure.
Given a graph structure G with the lexemes as nodes, their dependency relations as edges, and a chosen centrality measure of node importance, let denote the measure of a node x in the graph G. Then, given a sentiment dictionary D and a sentiment category C, we extract the numerical sentiment values of the nodes in G, , that appear in the dictionary D. Let denote the set of nodes for which is known.
The graph sentiment value of graph
G is defined for a nonempty set
as follows:
For an example of
values obtained from SenticNet 6 dictionary ‘polarity_value’ for a ConGraCNet subgraph see
Table 4. The
values shown were obtained using
,
and
. The subgraph node lexemes and the corresponding values of the various graph centrality measures are given along with SenticNet 6 ‘polarity_values’. Note that the lexemes with the highest values of the centrality measure have thegreatest impact on the
computed with respect to that centrality measure. For example, the lexeme
leader is the only node in the subgraph with a negative ‘polarity_value’, while the other values from the dictionary are positive or do not appear in the dictionary. Interestingly, many of the listed ‘polarity_values’ are very high. In terms of graph properties,
is the measure that has the highest relative differences between the values of the node measures among those listed. The highest
values in the subgraph correspond to the lexeme nodes
Member and
member. These values are more than 11 times greater than the nearest
value. At the same time, the majority of the nodes have the
value of 0. This is not the case for the other measures presented. Consequently, the
value obtained with
is strongly influenced by the negative polarity value of the lexeme
leader, and only slightly corrected by the positive values of the remaining nodes with nonzero
values. Therefore, the
value obtained with
is negative, while the
values calculated with other centrality measures are positive. The lexeme
leader does not have much impact on the propagation of
with respect to the measures
and
.
For another example see
Table 5. In this subgraph, the most influential node for the
value is the lexeme
lecturer which has a fairly neutral sentiment value. The rest of the available lexeme nodes
values are all positive. Since the sentiment values of the
and
are more evenly distributed, the obtained
and
values are significantly more positive due to the influence of the strongly positive lexeme nodes.
In general, the number of node lexemes in a graph that do not have a sentiment value in a dictionary varies. The more values.
As the above examples show, the choice of the centrality measure is of great importance for the computation of the graph . Since different measures reflect specific graph properties, the different obtained sentiment assessments of the lexical graph can be used according to a specific lexical analysis.
3.3. Calculating Sentiment Value of a Lexeme
It is typically the case that not all lexemes that appear in the ConGraCNet graph are labeled with sentiment values in a sentiment dictionary. Certainly, the more lexical nodes are found in the dictionary, the better the evaluation of the assigned sentiment values of the lexical graph. This leads to the idea of extending the coverage of the sentiment dictionary by sentiment value propagation.
In this dictionary enrichment task, the ConGraCNet coordination dependency graph layer identifies candidates without original sentiment values while providing a structure for sentiment value assignment.
Based on the sentiment values of the lexeme entries in the sentiment dictionary, called Original Dictionary Values (), we propagate the sentiment values to lexical nodes without thus extending the coverage of the dictionary. We call the resulting sentiment value for lexeme a the Assigned Dictionary Value () of lexeme a.
Given a sentiment dictionary D and its sentiment dimension C, the assigned dictionary value of the lexeme node a, which does not occur in D, is computed from the corpus-based coordination dependency lexical graph and the available sentiment values for its lexeme nodes. We extract the available valence values in category C from D for the nodes of , denoted by . Let be the set of nodes for which appears in D.
The assigned valence value of node
a in category
C of dictionary
D, denoted by
, is defined as follows for a nonempty set
:
where
is the
measure of the node
x in the
graph and
is the valency value of lexeme
x in category
C of
D.
Note that
, as defined in (
2), is actually
(FoFa) with
as the centrality measure. The chosen measure of
propagation is
because it quantifies the role of the node as a bridge along the shortest path between two other nodes. It provides a way to determine the impact of a node on the connectivity of the graph. Given the FoF graph structure, the high values of the
measure of the lexeme nodes in the ConGraCNet lexical graphs suggest that these node lexemes best represent the primary or dominant lexeme senses.
Some examples of lexemes and their computed
values are shown in
Table 6. The absolute differences between the obtained
values and the extracted
values are significant in some cases. For some more examples of obtained
values and the comparison with the
values see Figure 8 in
Section 4 where the subjective assessment is presented. For a discussion on the lexical implications of the question of differences between
and
values see
Section 5.
3.4. Sentiment Potential: Graph Propagation Algorithm for Lexeme Sentiment Value
ConGraCNet lexical graph represents an information structure that can be enriched with sentiment values. Orthogonally, this graph can provide a basis for enriching the sentiment representation which addresses the reductive nature of quantifying lexically expressed feeling. We present a graph propagation algorithm that leads to an enriched, more complex sentiment representation for word sentiment, called Sentiment Potential ().
For a chosen seed lexeme a, the propagation algorithm takes the following parameters: (1) a sentiment dictionary D and its numeric dictionary category C, (2) ConGraCNet graph parameters including the size of the computed FoF seed lexeme graph, the clustering algorithm, the centrality algorithm, and the choice of corpus.
For the chosen parameters, the propagation algorithm returns the by performing the following steps:
- (1)
Computing the ConGraCNet lexical graph for the seed lexeme a;
- (2)
Mapping the values for lexeme nodes for which the sentiment values appear in category C in the sentiment dictionary D;
- (3)
Computing the values for lexeme nodes for which the sentiment values in category C do not appear in D;
- (4)
Assigning labels for identified lexical subgraphs of ;
- (5)
Computing sentiment values for identified lexical subgraphs of representing the associated lexical senses of the seed lexeme a;
- (6)
Calculating the average for the lexeme a.
- (7)
Visual representation of .
For a chosen lexeme
a the ConGraCNet method provides the associated lexical graph
. The available sentiment values for the lexical nodes of
can be extracted from the chosen dictionary
D. For the remaining lexical nodes of the
graph,
values are assigned, as defined in
Section 3.3. These first steps of the
algorithm, (1)–(3), yield the enriched lexical graph of lexeme nodes, each with its associated sentiment value.
Furthermore, in step (1), the subgraph communities of the graph are identified by the ConGraCNet method. Then in step (4), for each subgraph
of
, the abstracted category labels are computed using the WordNet hypernym graph, as presented in
Section 2.
Next, in step (5), for each subgraph
of
, its sentiment value
is computed using the
centrality measure, as defined in
Section 3.2.
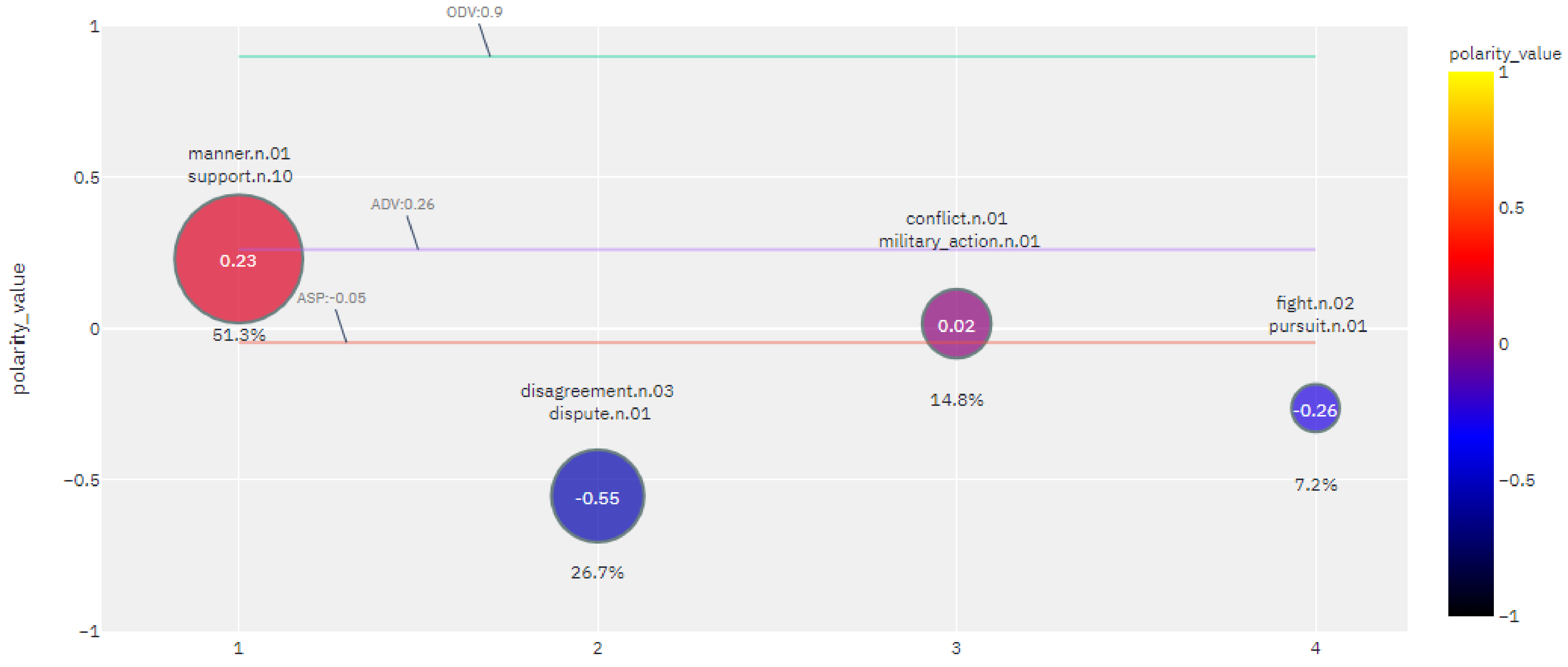
Table 7 shows an example of a lexical subgraph, along with the
values assigned to the node lexemes that do not appear in the dictionary. The obtained
value of the subgraph community of the example lexeme
fight is positive, since the lexical nodes with the highest rank are very positive, while the negative nodes have lower
values. The remaining subgraph communities of the lexeme
fight and the
values for all of the subgraphs are shown in
Table 8.
The obtained sentiment values of all subgraphs of the lexical graph provide a more detailed sentiment score for the lexeme a, where each of the values corresponds to one of the semantic domains related to the senses of the seed lexeme a. This spectre of sentiment values together with the corresponding subgraph communities and their labels, forms the sentiment potential of the seed word.
Finally, in step (6), the average representative sentiment value for the seed lexeme is computed. The
Average Sentiment Potential (
) represents the average sentiment value of the seed lexeme over its semantic communities identified by the ConGraCNet method. It is computed as the mean of the propagated sentiment values of the identified lexical subgraphs as follows:
where
m is the number of subgraph communities
identified in the seed lexeme graph
,
is the
value of the subgraph
, and
is the
of the node
x in
.
For example, the lexeme fight has −0.0452, which is an average sentiment value for this lexeme propagated using ententen13 corpus. Note that the corresponding value is a strongly positive value of 0.9. The assigned value is also positive, but significantly lower, due to the influence of the sentiment values of the associated nodes in the corpus-based lexical dependency graph layer.
As shown above, the propagation of the sentiment potential leads to a semantic description of the selected lexeme and an enriched representation of its sentiment value in the corpus-specific data.
As the results for the running example of the lexeme
fight, presented in
Table 8 show, the sentiment value of the word
fight is positive when associated with collocating lexemes such as
response, action, reaction, but negative when associated with collocating lexemes like
misunderstanding, quarrel, disagreement. However, in the collocation subgraph containing the lexemes
battle, conflict, war, victory, it is more neutral due to the mixed sentiment polarity of its community members.
The list of values obtained represents multifaceted sentiment values of the seed lexeme specifically associated with each associated semantic community. As shown above, a lexical concept can convey very different sentiments in its different senses.
3.4.1. Visual Representation of Sentiment Potential
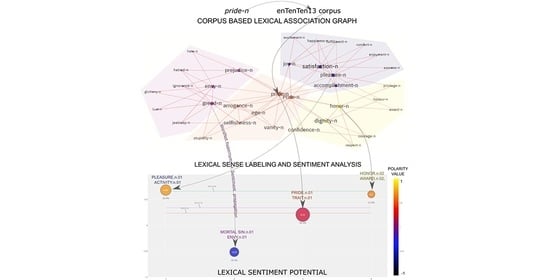
The lexical sentiment distribution contained in the sentiment potential is visualized using a graphical representation shown in
Figure 4.
Each lexical community is marked as a circle of the corresponding size, calculated using the relative proportion in the overall lexical dependency graph of the seed lexeme. The percentage and associated hypernym labels are attached to each community circle. The vertical placement of the community circles and the associated colors reflect the numerical sentiment value of the community, normalized in the range [−1, 1]. The lexical communities with negative are positioned lower and darker, with black color representing the −1 value, and vice versa, the positive communities are positioned higher and lighter, with yellow color representing the 1 value. The horizontal lines correspond to the original dictionary value , the assigned dictionary value and the assigned sentiment potential values obtained by dictionary mapping, computing the sentiment values of the associated lexemes, and the average sentiment value of their lexical clusters, respectively.
3.5. Analyzing Sentiment Dynamics
In general, the obtained of a lexeme a is associated with some chosen parameters. By changing a parameter, e.g., choosing a different sentiment dictionary or changing a corpus, the comparison of the different values can give an insight into the dynamic sentiment potential of the chosen lexeme relative to the specific corpora in synchronic and diachronic dimensions.
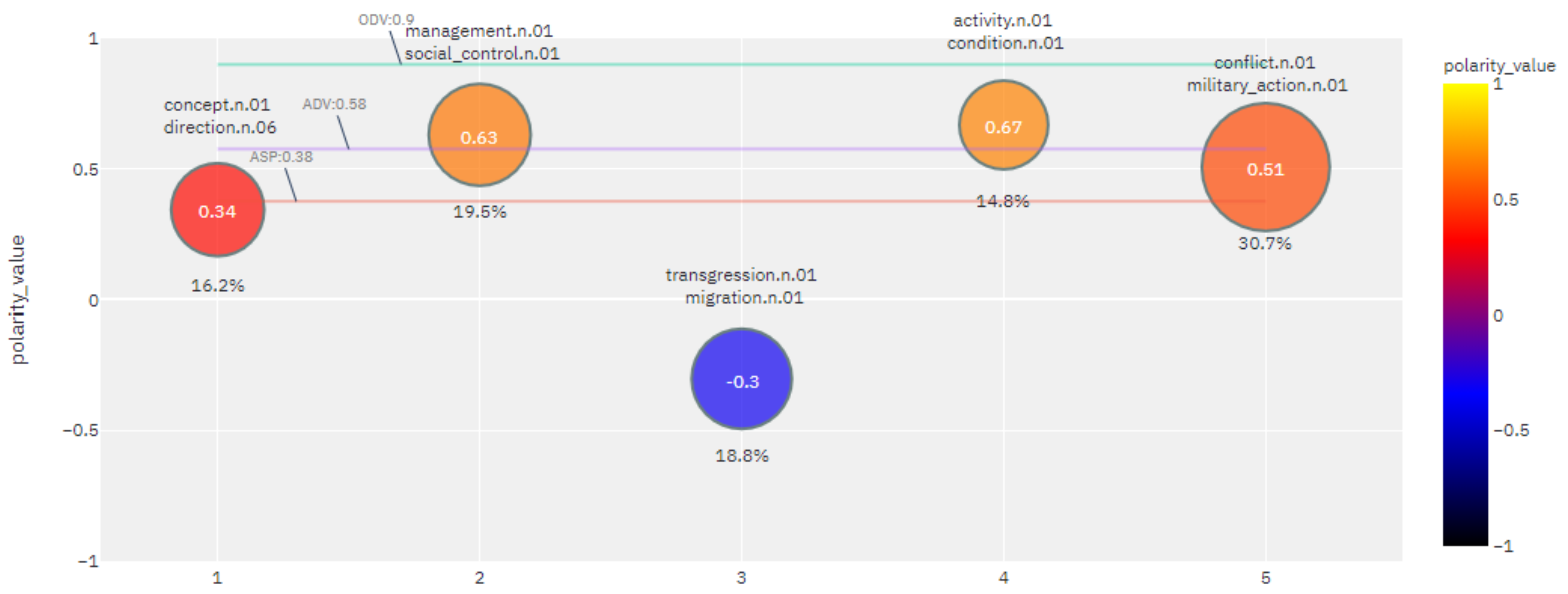
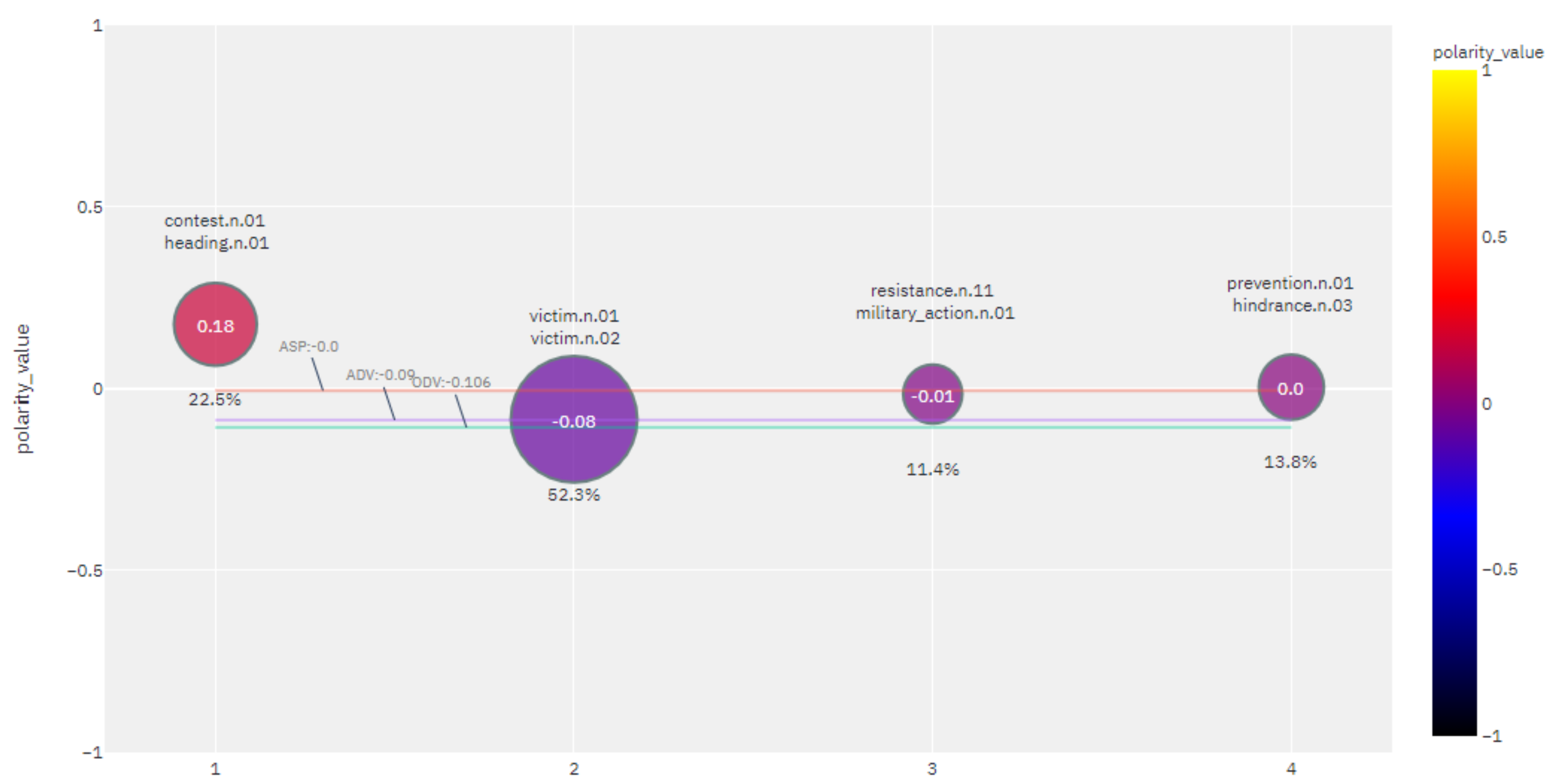
For example, the
values of the lexeme
fight obtained for some other SenticNet 6 dimensions and the SentiWords dictionary are shown in
Table 9, while the visualization of the
values of the lexeme
fight obtained using different corpora, English Plenary sessions of the EuroParliament (europarl_plenary) and hrwac22, are shown in
Figure 5 and
Figure 6.
The resulting value of the lexeme fight in the europarl_plenary corpus is significantly more positive than that obtained in the general ententen13 corpus. The obtained labels for lexical clusters in the europarl_plenary indicate a domain specific political conceptualization of fight as a concept with direction describing how something should be done or managed.
Moreover, with different language corpora, a cross-language comparison of sentiment representations for the same seed concept can be achieved. In this way, the proposed sentiment potential provides the method for multilingual and cross-cultural linguistic studies.
4. Evaluation
Representing word sentiment with numerical values, or even classifying sentiment as positive, neutral or negative is not a straightforward task. In fact, different sentiment values have been assigned to the same lexeme in different sentiment dictionaries. For example, the lexeme cream has the SentiWords polarity score of 0.4479, the SenticNet 6 sentiment polarity value of −0.95, and a neutral valence in the Senti WordNet sentiment dictionary.
The criteria by which these values were assigned are not always clear and are necessarily subjective. What should be less subjective is the relative difference in sentiment value between words with similar senses and between closely related words in a chosen sentiment dictionary. This is not always the case. For example, the Senti WordNet sentiment dictionary marks the lexeme researcher as positive, while research is neither positive nor negative.
In other sentiment dictionaries, their sentiment values differ as well. In SentiWords, researcher has the positive ‘polarity_score’ of 0. 1756 and the lexeme research has a neutral ‘polarity_score’ 0. In SenticNet 6 the ‘polarity_value’ of the lexeme researcher has a quite negative value of −0.83, while the lexeme research has the opposite ‘polarity_value’ of 0.883. For comparison, our methodology yields an value of 0.0621 for the lexeme researcher and value of 0.7587 for lexeme research.
Although it is difficult to imagine an objective evaluation of sentiment values, we attempted to measure the subjective evaluation of sentiment values from a dictionary in two separate surveys. Survey responses were anonymized. The surveys were conducted anonymously among elementary school and university students, both male and female.
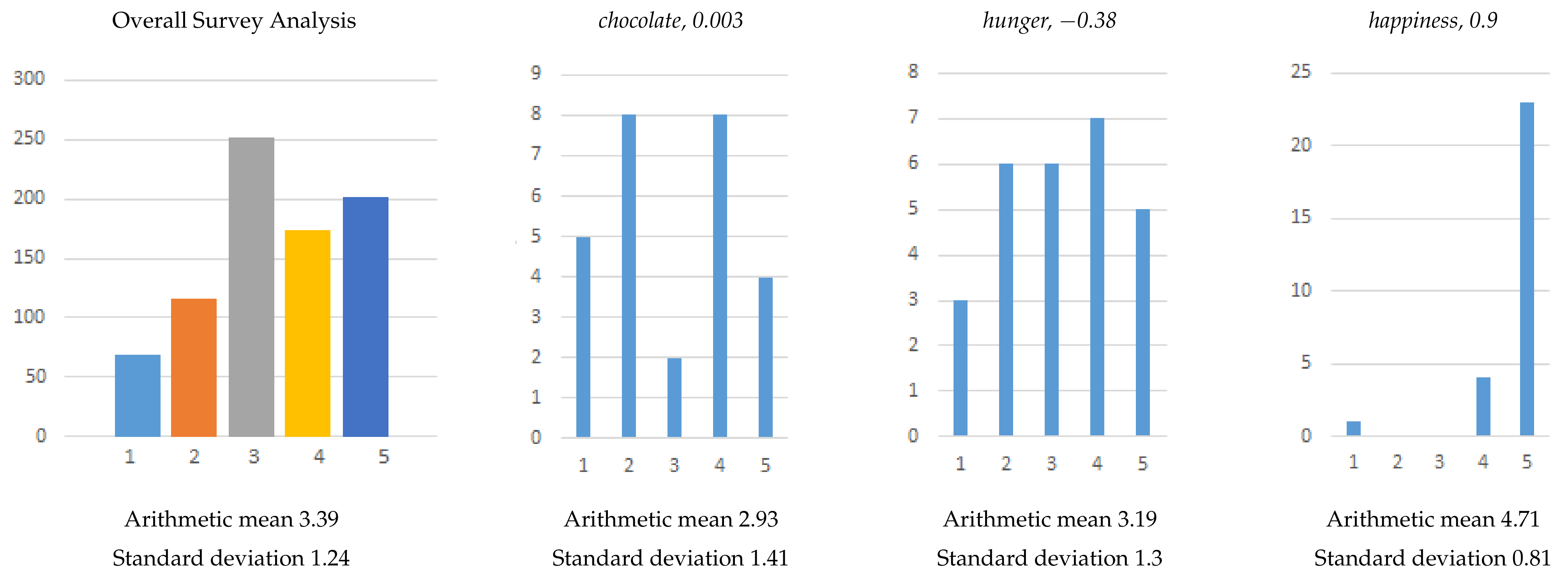
The first survey tested subjective ratings of sentiment polarity scores from the SenticNet 6 dictionary for approximately 30 selected noun lexemes. The selected lexemes had different sentiment values, ranging from strongly negative to neutral to strongly positive. A group of 27 subjects were first presented with word examples and their semantic values to familiarize themselves with the word sentiment. In the survey, the original sentiment dictionary value was presented for each lexeme, e.g., chocolate, 0.003. Subjects were asked to indicate their personal perception of the presented sentiment value on a scale of 1 to 5, where 1 marked strong disagreement and 5 strong agreement with the presented value.
The results of the evaluation are shown in
Figure 7. In addition,
Figure 7 shows examples of lexeme ratings with divergent results. For example, when rating the lexeme
chocolate the vast majority of subjects had an opinion, either agreeing or disagreeing, whereas for the lexeme
hunger opinions were not as clear. For the lexeme
happiness the vast majority of subjects strongly agreed with the polarity value presented.
The obtained results clearly show that the evaluation and sentiment assessment is highly subjective. We suspect that the range of results would be similar for another sentiment dictionary. This volatile assessment is difficult to capture accurately due to the polysemous nature of the words.
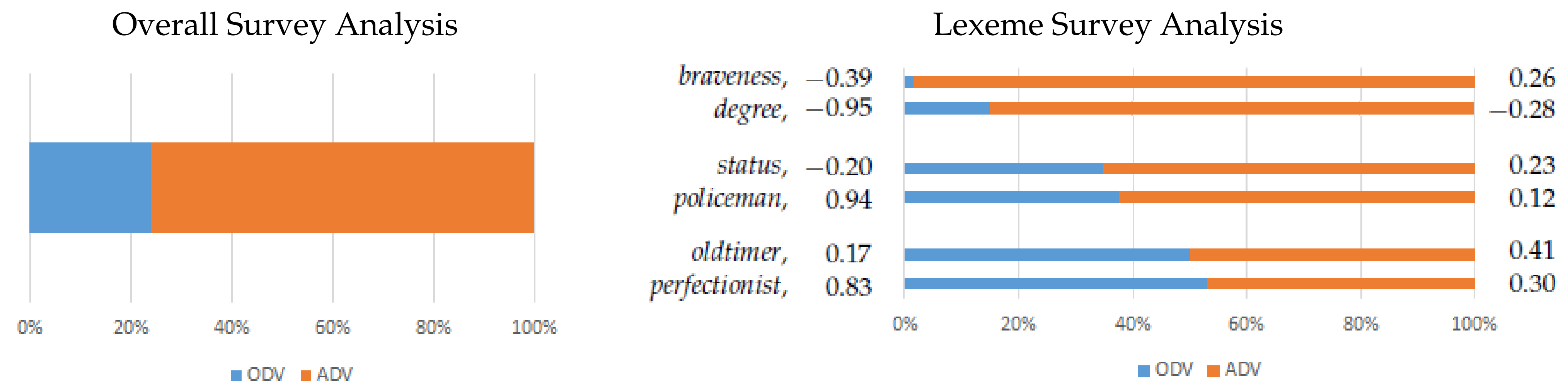
In addition, we surveyed a group of 66 subjects who evaluated the original SenticNet 6 against the assigned dictionary ‘polarity_value’ obtained by our methodology on sample of lexemes. The criterion for selecting the survey lexemes was the indication of a noticeable difference in sentiment value between the original (ODV) and the computed numerical value (ADV). The absolute difference between the corresponding ODV and ADV values ranged from 0.21 to 0.92, with an average of 0.65. In some cases, the polarity_values of the presented lexemes had opposite signs, i.e., some lexemes have a positive valence calculated by our methodology and a negative valence calculated by the SenticNet 6 dictionary, or vice versa. For each of the selected lexemes both ODV and ADV numerical values were presented for assessment. Subjects were asked to select which of the presented values was closest to their own perception. The numerical values were not labeled, and their order was mixed, so subjects were unable to identify the origin of the values.
The overall results on lexeme evaluations are shown in
Figure 8. Overall, for a set of 23 lexemes for which both ‘polarity_values’ were given and anonymized in the sense that the
and
labels were not visible, 76% of subjects chose the
over the
value.
Figure 8 on the right also shows the results on the ratings of the example lexemes, from a large majority for
values, to no clear majority to a majority for
values. The cases with the large majority of
preference may indicate an error in dictionary input, antonymy, or a lexeme with clear polysemous nature. The results may also be influenced by the lack of POS labeling in the SenticNet 6 sentiment dictionary. For a discussion, see
Section 5.
5. Discussion
As shown in the previous sections, sentiment analysis is a complex area of linguistic research. In addition to the psychological subjectivity inherent in emotional phenomena, it deals with the ambiguity and polysemous nature of the symbolic code, and with reductive attempts to assign the normalized token count to a dimension of the emotion invoked by an utterance. However, the cognitive structure of linguistic-syntactic dependencies revealed in a corpora gives us the opportunity to develop a more consistent and transparent domain-dependent enrichment of symbolic tokens with numerical sentiment values [
34].
Instead of considering a text as a bundle of words, or only superficially considering the structure of syntactic information, the ConGraCNet graph machine learning methodology uses a corpus-based syntactic dependency graph layer to learn the domain-specific cognitive structures that can be more consistently enriched with sentiment values. The coordination dependency lexical graph layer reveals the commonsense associative structure of a single lexical node, which enables more transparent and human-like assignment of a normalized sentiment value and representation of its polysemous sentiment potential within a domain of texts.
The polysemous nature of the lexeme in a corpus is identified using a clustering algorithm of a seed lexeme. The hypernym graph label assignment described in
Section 2 provides labels for each of these subgraph communities. The assigned labels emerge as the most central nodes in the hypernym graph obtained using WordNet hypernym and synset relations. Among the different implemented approaches to labeling data in ConGraCNet, we used a dictionary-based approach for assigning labels to a subgraph community using WordNet synsets hypernym relations. The other approaches could involve other knowledge databases, such as ConceptNet.io [
35], and DBpedia, or a combination with corpus-based
is_a syntactic dependency methods.
Particularly important for building sentiment analysis resources, this graph method can be used to check the consistency of the initial sentiment dictionary values to identify, reassess and possibly reassign some values with respect to the associated lexical clusters. In our research, we created a blueprint of the procedure on a small sample of SenticNet 6 dictionary values, which includes (1) reassignment of sentiment values for each node, (2) comparison of with , (3) ranking of nodes with largest difference, (4) assessment of sentiment values by human subjects. In our future work, we will incorporate this iterative process with the goal of generating representative and consistent sentiment dictionaries from a set of sparse sentiment dictionary entries, reassigning values in accordance with human evaluation, or evaluating a new sentiment dimension.
Of course, the structural dependency of the syntactic graph on a specific corpus should be taken into account. The larger the corpus, the more generalized, robust and rich the semantic relations represented in the associative layer will be. In general, the (re)assignment of sentiment dictionary is more representative if it is built on a larger corpus. However, if the sentiment values in a word dictionary are (re)evaluated reasonably consistently, the corpus can be considered as the dependent variable. The ConGraCNet procedure can then be used to reveal the cultural, domain specific, stylistic or idiomatic variations of sentiment potential, as is described in
Section 3.
Moreover, the sentiment potential representation
has the ability to enrich lexical semantics [
36] by adding a dynamic and polysemous dimensions of sentiment values that, to our knowledge, are not yet part of the existing semantic research. For instance, by using time-stamped data, one can measure not only diachronic semantic change at the level of lexical relations, but also the underlying salience of the sentiment potential that occurs as a result of this change. A somewhat vivid example of this diachronic change is the lexeme
corona, which has a rather positive sense potential
0.246, with
0.27 using a SentiNet 6 dictionary and the WordNet hypernym labels related to beer, aureole and landmarks. However, the recent COVID-19 crisis has imparted new layer to the sentiment potential of the lexeme
corona. Some recent corpora, like Timestamped web corpus of English 2014–2020 [
37], identify this different sentiment potential of the lexeme
corona with
0.08. When compared to the previous dominant trends, there appears to be a distinct lexical cluster labeled as
influenza and
contagious disease with graph sentiment value
−0.373 comprising 16 percent of the seed lexeme
corona-n graph structure of 50 best ranked collocates in the first degree and 5 in the second degree. This type of analysis opens up a whole new dimension in the semasiological change research.
Another interesting lexical semantics feature is the presence of antonymous lexemes and lexical communities within a seed lexeme graph, as illustrated in the seed graph of the lexeme
pride. Pride is associated with pleasure, but also with mortal sin. It arouses positive sentiments labeled as
pleasure, such as
joy, happiness, but also negative ones, such as
greed, envy, jealousy, labeled as
mortal sin. This phenomenon is part of embodied cognitive structures that have a long history of research [
38,
39], but sentiment potential and lexical clustering representation can add new data to a somewhat rigid one-dimensional conceptual view of antonymy phenomena. One of our future research tasks will be to further investigate the sentiment-enriched graph representation to find domain specific lexemes and lexical structures with antonymous features.
From the data processing perspective, the method requires that the corpus be tagged with grammatical and syntactic features in order to construct a coordination network. This process requires the extensive use of NLP morpho-syntactic tagging and a database to store and extract the occurrence of lexical nodes and the co-occurrence of the nodes. However, resulting coordination layer can then be used to identify conceptual associations between nouns as entities, adjectives as attributes of entities, verbs as processes and adverbs as attributes of processes. Other parts of speech are necessarily dependent on these grammatical categories and therefore have no inherent prototypical sentiment. For instance, it would be odd to assign a definite sentiment value to a particle a, the, logical connectors and, or, or a pronoun you, etc., since they acquire their sentiment values in syntactic-semantic constructions.
After constructing a syntactic dependency network embedding, the ConGraCNet approach to lexical sentiment analysis is actually language agnostic. Equipped with a relevant sentiment dictionary with enough entries to boot-start graph propagation procedure, the method can be applied to a lexical coordination graph of any language.
On this topic, it is important to mention the morpho-syntactic format of the sentiment dictionaries. The two out of three sentiment dictionaries used here, SentiWords and SentiWordNet have the Part of Speech (POS) tags. POS grammatical metadata gives a more accurate mapping of the
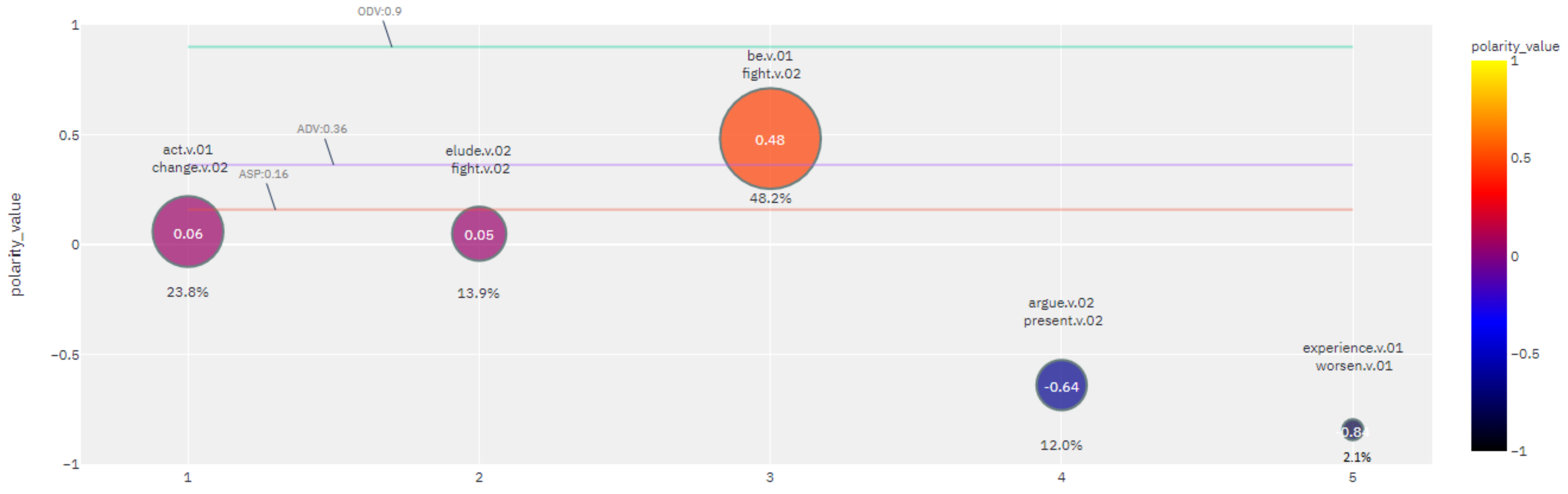
to a lexical node. SenticNet, due to the nature of symbolic data extraction, does not provide the POS tags, which can result in a somewhat overlapping mapping of the same sentiment value to an orthographically identical lexeme but grammatically completely different category, as in the case of the lexeme
fight, which symbolically can be both noun
fight-n and verb
fight-v. In addition to the different semantic subgraphs and corresponding labels, the average sentiment potential value of these lexemes is also different, namely,
and
, see
Figure 4 and
Figure 9. In this case, the calculation of
can used to asses the adequacy and consistency of
.
The computation of the values depends on the choice of the sentiment dictionary, while the assignment of the new values and re-computation of the old ones additionally depends on the choice of the parameters of the graph-based ConGraCNet methodology, such as the size of the computed seed graph, the clustering and centrality algorithms, and the choice of the corpus.
This syntactic dependency lexical approach can be useful for a number of downstream applications dealing with sentiment analysis of larger linguistic structures, such as constructions, phrases, sentences, texts. The
values assigned to the lexemes and their
values together with their abstracted labels can be used as components for contextual sentiment text summary or dynamic compositional sentiment analysis [
40].
6. Conclusions and Future Work
The paper addresses the problems of data integration, processing and enrichment in the context of the graph method used for labeling lexical clusters of a seed lexeme and identifying its sentiment potential using the syntactic dependency layer of a morpho-syntactically tagged corpus, implemented in the ConGraCNet application. According to the processing procedure, after the construction of the coordination graph layer for a seed word and its lexical clusters, we first implement the cluster labeling algorithm. This provides the conceptual abstraction for semantically related lexical communities of a seed lexeme. Labels for each community are propagated by constructing a WordNet hypernym graph from the clustered lexemes in a coordination graph layer and selected based on a set of centrality measures. The candidate labels abstract the central theme of a particular cluster and provide a way to distinguish it from other clusters in an efficient manner.
Although the results of WordNet labeling are promising, in our future work we plan to integrate other knowledge databases with similar semantic relations, such as Conceptnet is_a, and compare the results with corpus-based word is_a category and category is_a word syntactic dependencies.
The main contribution of the paper is related to the description of the graph algorithms that can be used to calculate new lexical sentiment values and extend the range of sentiment dictionaries that currently suffer from sparseness and lack of culture-specific sentiment values; to re-evaluate existing sentiment values from a sentiment dictionary based on a corpus-specific coordination dependency graph layer; to introduce polysemous sentiment graph metrics and distribution of a seed lexeme, called sentiment potential, with description of the sentiment potential algorithm, a graph procedure for mapping, identification and reassignment of the sentiment values from a number of sentiment dictionaries.
Starting from SenticNet, SentiWords, SentiWordsNet dictionary based sentiment dimensions and values, associated to lexemes in a coordination graph layer, we have demonstrated the efficiency of the graph algorithm for assigning the sentiment values to the lexical sense communities, to missing lexemes or for reassignment of the sentiment values based on a specific corpus. This methodology for dynamic, transparent and corpus-specific sentiment value analysis and model creation allows us to create sentiment lexical dictionaries for various languages and specific corpora.
We performed an evaluation of the reliability of the sentiment values on a sample of 30 lexemes, as well as the subjective evaluation of the original dictionary values vs. graph assigned values on a set of lexemes with slightly larger difference via questionnaire on 66 subjects. The distribution of evaluation have shown relative agreement with the original values. Subjective ratings of the appropriateness of the were relatively high with 76% of subjects choosing the value over the value. These promising results motivate us to further experiment further with the corpus-based graph algorithm to extend the dictionary coverage by assigning a sentiment value to non-existing lexeme dictionary deal with. In our future work we will implement the algorithms to develop dense lexical sentiment dictionaries and sentiment potential models calculated from various large corpora of major languages that could be used in standard procedures for sentiment analysis. The other line of applications will address sentiment dictionary consistency analysis.
Our future work will also extend the syntactically based analysis to a other syntactic dependency layers to create sentiment potential for various multi-word expressions.
In general, the proposed approach has the potential to be used as a complementary method to other NLP contemporary resources for the enrichment of various semantic tasks including word disambiguation, domain relatedness, sense structure, synonymy, antonymy and metaphoricity, as well as establish a cross-and intra-cultural discourse variations of prototypical conceptualization patterns and knowledge representations.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}