A Node Embedding-Based Influential Spreaders Identification Approach



Abstract
:1. Introduction
2. Related Concepts
2.1. Social Influence Maximization (SIM) Problem
2.2. Node Embedding
3. Centrality Analysis
3.1. Centrality Measure
3.2. Point Coloring Theory
3.3. Susceptible-Infected-Recovered (SIR) Model
4. The Overall Approach
4.1. Proposed Node-Embedding Approach
| Algorithm 1. Centrality-weighted DeepWalk (G, m, d, γ, t, λ) |
| Input: |
| window size m |
| embedding size d |
| walks per vertex γ |
| walk length t |
| Number of iterations λ |
| Output: matrix of vertex representations Mn×h. |
| 1. ∈ //Vector of normalized node centrality values |
| 2. for to do |
| 3. //Shuffle the node set of |
| 4. for do |
| 5. /Generate node sequences |
| 6. //Train and gain node embeddings |
| 7. end for |
| 8. end for |
- Generate one hot node vectors for anchor node ’s context nodes(inputs), where is the window size.
- Calculate the embedded node vectors of context nodes
- where prime marks are used to distinguish the calculated embedded node vectors from the corresponding one hot node vectors.
- Average the embedded node vectors to obtain ;
- Calculate a score vector ;
- Turn the scores into probabilities ;
- Use gradient descent to optimize loss function , where is the real probability, which is actually the real one hot node vector of anchor node.
4.2. Key Node Selection
5. Experimental Analysis
5.1. Datasets
5.2. Comparing Algorithms
5.3. The Experimental Results
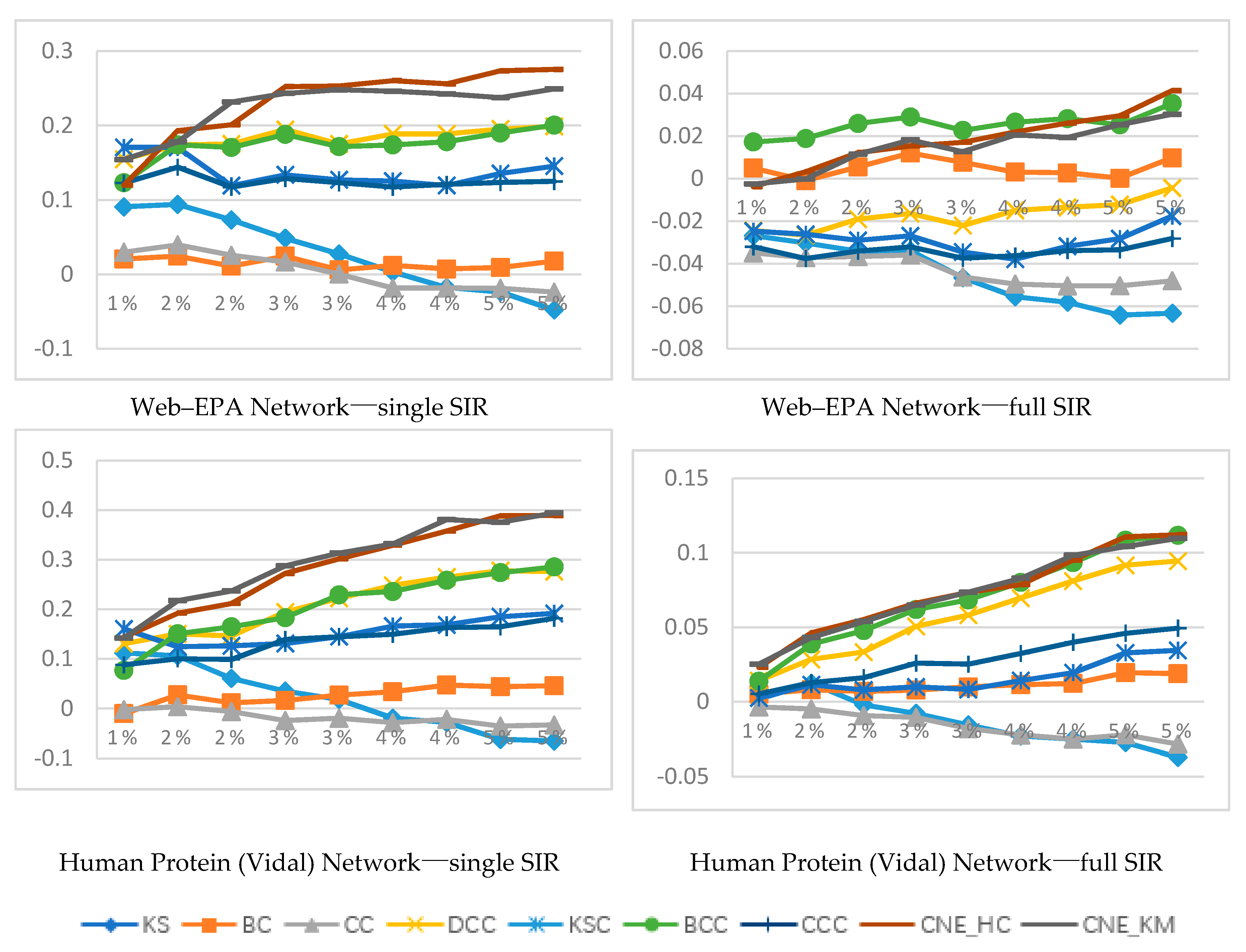
- (1)
- In the case of few key node groups (1%), when the infection rate is very small, i.e., as shown in the figure, the effects of CNE_HC and CNE_KM are not particularly ideal. With the increase of infection rate, the experimental results of CNE_HC and CNE_KM gradually improve and are better than other algorithms.
- (2)
- When the number of nodes in the key node group is 3% and 5%, the experimental results of CNE_HC and CNE_KM are better than other algorithms on the whole in terms of the impact on the whole network under the condition of different infection rates .
- (3)
- With the increase of infection rate , the difference in the impact of various key node group identification algorithms on the entire network will gradually decrease, and information such as disease information will be easily spread in the network. However, the experimental results of CNE_HC and CNE_KM still maintain good results and are superior to other methods.
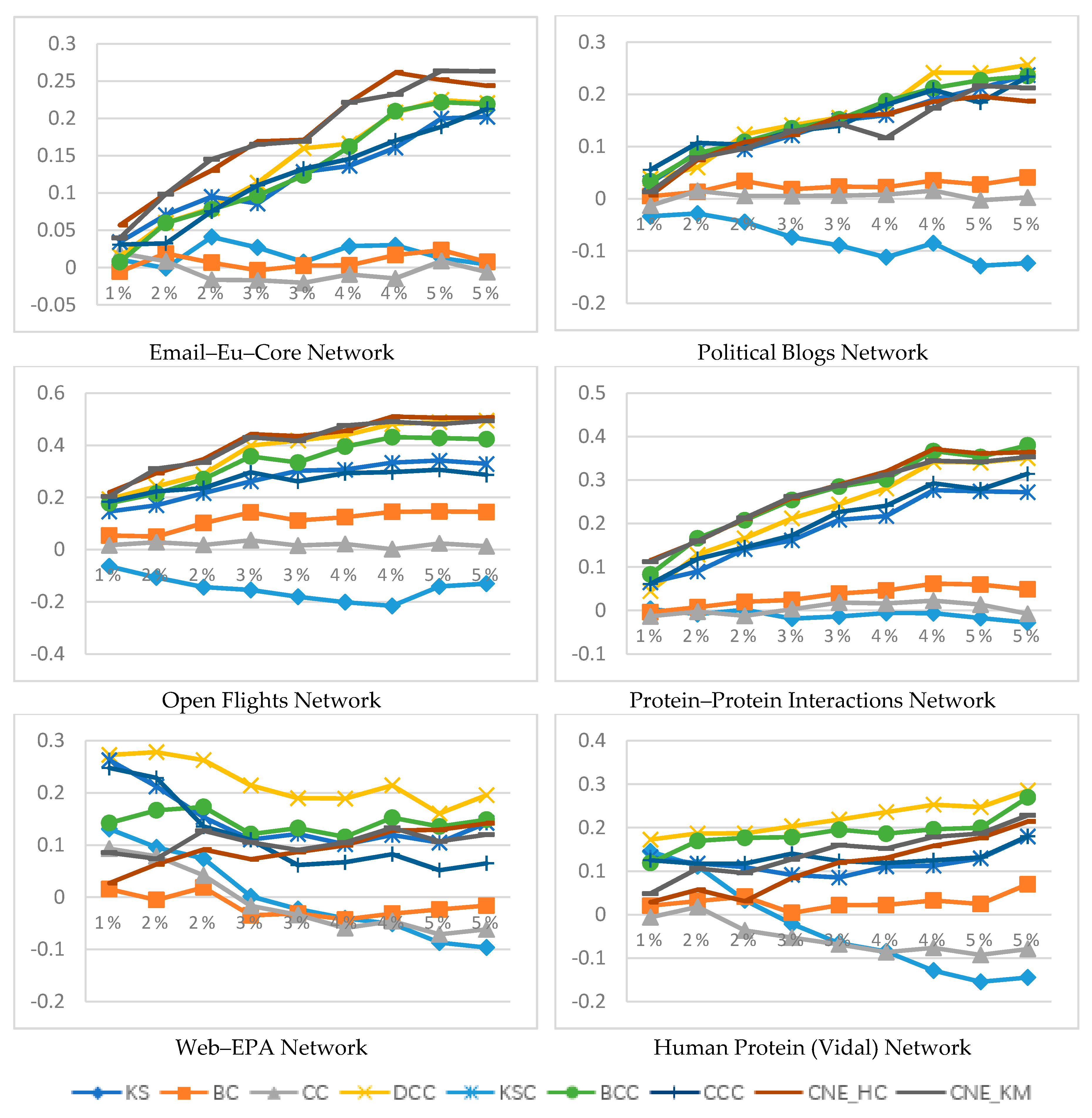
- (1)
- In Email, Openflights, PPI networks, regardless of the number of nodes in the key node group is 1%, 3% or 5%, and regardless of the infection rate, CNE_HC and CNE_KM perform well and are superior to other algorithms on the whole.
- (2)
- There are obviously different rules from the other four datasets in the Web-EPA and Vidal datasets. In Web-EPA and Vidal, when the infection rate is very small, i.e., , the experimental results of CNE_HC and CNE_KM are not ideal. With the increase of infection rate, the experimental results of CNE_HC and CNE_KM gradually improve, and catch up with and surpass other algorithms in the later stage.
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Tsugawa, S. Empirical Analysis of the Relation between Community Structure and Cascading Retweet Diffusion. In Proceedings of the International AAAI Conference on Web and Social Media, Munich, Germany, 11–14 June 2019; Volume 13, pp. 493–504. Available online: https://www.aaai.org/ojs/index.php/ICWSM/article/view/3247 (accessed on 11 August 2020).
- Weng, L.; Menczer, F.; Ahn, Y.-Y. Virality prediction and community structure in social networks. Sci. Rep. 2013, 3, 2522. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Centola, D. The spread of behavior in an online social network experiment. Science 2010, 329, 1194–1197. [Google Scholar] [CrossRef] [PubMed]
- De Arruda, G.F.; Barbieri, A.L.; Rodriguez, P.M.; A Rodrigues, F.H.; Moreno, Y.; Costa, L.D.F. Role of centrality for the identification of influential spreaders in complex networks. Phys. Rev. E 2014, 90. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Richardson, M.; Domingos, P. Mining knowledge-sharing sites for viral marketing. In Proceedings of the 8th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Edmonton, AB, Canada, 23–26 July 2002; pp. 61–70. [Google Scholar]
- Probst, F.; Grosswiele, D.-K.L.; Pfleger, D.-K.R. Who will lead and who will follow: Identifying influential users in online social networks. Bus. Inf. Syst. Eng. 2013, 5, 179–193. [Google Scholar] [CrossRef]
- Lu, Z.; Zhang, W.; Wu, W.; Fu, B.; Du, D.Z. Approximation and Inapproximation for the Influence Maximization Problem in Social Networks under Deterministic Linear Threshold Model. In Proceedings of the 31st International Conference on Distributed Computing Systems Workshops, Minneapolis, MN, USA, 20–24 June 2011. [Google Scholar]
- Livstone, M.S.; Breitkreutz, B.J.; Stark, C.; Boucher, L.; Tyers, M. The biogrid interaction database. Nat. Preced. 2011. [Google Scholar] [CrossRef]
- Roy, M.; Pan, I. Lazy Forward Differential Evolution for Influence Maximization in Large Data Network. SN Comput. Sci. 2020, 1, 1–6. [Google Scholar] [CrossRef] [Green Version]
- Dospinescu, O.; Anastasiei, B.; Dospinescu, N. Key Factors Determining the Expected Benefit of Customers When Using Bank Cards: An Analysis on Millennials and Generation Z in Romania. Symmetry 2019, 11, 1449. [Google Scholar] [CrossRef] [Green Version]
- Liu, B.; Cong, G.; Zeng, Y.; Xu, D.; Chee, Y.M. Influence spreading path and its application to the time constrained social influence maximization problem and beyond. IEEE Trans. Knowl. Data Eng. 2014, 26, 1904–1917. [Google Scholar] [CrossRef] [Green Version]
- Hamilton, W.L.; Ying, R.; Leskovec, J.J. Representation learning on graphs: Methods and applications. arXiv 2017, arXiv:1709.05584. [Google Scholar]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. DeepWalk: Online Learning of Social Representations. In Proceedings of the 20th ACM SIGKDD Int. Conf. on Knowledge Discovery and Data Mining (NY, USA) (KDD ’14); ACM: New York, NY, USA, 2014; pp. 701–710. [Google Scholar]
- Tang, J.; Qu, M.; Wang, M.; Zhang, M.; Yan, J.; Mei, Q. LINE: Large-Scale Information Network Embedding. In Proceedings of the 24th Int. Conf. on World Wide Web, Florence, Italy, 18–22 May 2015; IW3C2. pp. 1067–1077. [Google Scholar]
- Grover, A.; Leskovec, J. node2vec: Scalable Feature Learning for Networks. arXiv 2016, arXiv:1607.00653. [Google Scholar]
- Cao, S.; Lu, W.; Xu, Q. Grarep: Learning graph representations with global structural information. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management-CIKM ’15, Melbourne, Australia, 19–23 October 2015. [Google Scholar] [CrossRef]
- Zhou, D.; He, J.; Yang, H.; Fan, W. SPARC: Self-Paced Network Representation for Few-Shot Rare Category Characterization. In Proceedings of the 24th ACM SIGKDD International Conference, London, UK, 19–23 August 2018. [Google Scholar]
- Feng, L.P.; Wang, H.B.; Feng, S.Q. Improved SIR model of computer virus propagation in the network. J. Comput. Appl. 2011, 31, 1891–1893. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Schmidt, C.W. Improving a tf-idf weighted document vector embedding. arXiv 2019, arXiv:1902.09875. [Google Scholar]
- Chang, C.-Y.; Lee, S.-J.; Lai, C.-C. Weighted word2vec based on the distance of words. In Proceedings of the 2017 International Conference on Machine Learning and Cybernetics (ICMLC), Ningbo, China, 9–12 July 2017; Volume 2, pp. 563–568. [Google Scholar]
- Kitsak, M.; Gallos, L.K.; Havlin, S.; Liljeros, F.; Muchnik, L.; Stanley, H.E.; Makse, H. AIdentification of influential spreaders in complex networks. Nat. Phys. 2010, 6, 888–893. [Google Scholar] [CrossRef] [Green Version]
- Bollobás, B. Graph Theory and Combinatorics: Proceedings of the Cambridge Combinatorial Conference in Honour of Paul Erdös, Trinity College, Cambridge, 21–25 March 1983; Academic Press: Cambridge, MA, USA, 1984. [Google Scholar]
- Leskovec, J.; Kleinberg, J.; Faloutsos, C. Graph evolution: Densification and shrinking diameters. ACM Trans. Knowl. Discov. Data 2007, 1, 2-es. [Google Scholar] [CrossRef]
- Adamic, L.A.; Glance, N. The political blogosphere and the 2004 U.S. election: Divided they blog. In Proceedings of the 3rd International Workshop on Link Discovery, Chicago, IL, USA, 21–25 August 2005; ACM: New York, NY, USA; pp. 36–43. [Google Scholar]
- Opsahl, T.; Agneessens, F.; Skvoretz, J. Node centrality in weighted networks: Generalizing degree and shortest paths. Soc. Netw. 2010, 3, 245–251. [Google Scholar] [CrossRef]
- Rossi, R.A.; Ahmed, N.K. The Network Data Repository with Interactive Graph Analytics and Visualization. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; AAAI Press: Menlo Park, CA, USA, 2015. [Google Scholar]
- Rual, J.F.; Venkatesan, K.; Hao, T.; Hirozane-Kishikawa, T.; Dricot, A.; Li, N.; Berriz, G.F.; Gibbons, F.D.; Dreze, M.; Ayivi-Guedehoussou, N.; et al. Towards a proteome-scale map of the human protein-protein interaction network. Nature 2005, 437, 1173–1178. [Google Scholar] [CrossRef] [PubMed]
- Fortunato, S. Community detection in graphs. Phys. Rep. 2011, 486, 75–174. [Google Scholar] [CrossRef] [Green Version]
- Newman, M. Networks: An Introduction; Oxford University Press, Inc.: Oxford, UK, 2010. [Google Scholar]
- Feixiong, L.; Liang, M.A. Heuristic ant search algorithm for Graph coloring problem. Comput. Eng. 2007, 33, 191–192. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DataSets | Nodes | Edges | Community |
|---|---|---|---|
| Email Network | 986 | 16,064 | 42 |
| Political Blogs | 1222 | 16,714 | 2 |
| DataSets | CBOW | Degree_CBOW |
|---|---|---|
| Email network | 69.81% | 69.83% |
| Political blogs | 75.00% | 74.82% |
| DataSets | Nodes | Edges | <k> (Average Degree) |
|---|---|---|---|
| Email Network | 986 | 16,064 | 32.5842 |
| Political Blogs | 1222 | 16,714 | 27.3552 |
| OpenFlights | 2905 | 15,645 | 10.7711 |
| Protein–Protein Interactions (PPI) | 3852 | 37,841 | 19.6475 |
| Web-EPA | 4253 | 8897 | 4.1839 |
| Human Protein (Vidal) | 2783 | 6607 | 4.3169 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, D.; Du, P.; Fang, B.; Wang, D.; Huang, X. A Node Embedding-Based Influential Spreaders Identification Approach. Mathematics 2020, 8, 1554. https://doi.org/10.3390/math8091554
Chen D, Du P, Fang B, Wang D, Huang X. A Node Embedding-Based Influential Spreaders Identification Approach. Mathematics. 2020; 8(9):1554. https://doi.org/10.3390/math8091554
Chicago/Turabian StyleChen, Dongming, Panpan Du, Bo Fang, Dongqi Wang, and Xinyu Huang. 2020. "A Node Embedding-Based Influential Spreaders Identification Approach" Mathematics 8, no. 9: 1554. https://doi.org/10.3390/math8091554