1. Introduction
The Logarithmic Number System (LNS) provides comparable range and precision as the floating point (FLP) representation, however—for certain applications—it can surpass it in terms of complexity. The range of logarithmic numbers depends on the exponent’s integer part, and the precision is defined by its fraction part [
1]. Yet, LNS would outperform FLP only if the logarithmic addition and subtraction can be performed with at least the same speed and accuracy as FLP [
2].
The long history of LNS numbers dates back to the 1970′s when the “logarithmic arithmetic” for digital signal processing was introduced [
3]. To avoid negative logarithms, a complementary notation for LNS was introduced in [
4]. Architecture for the LNS-based processor was proposed in [
5]. Implementations of basic arithmetic operations on FPGA [
6] using FLP and LNS have shown that the multiplication and division operations are more effective if using LNS, as they require fewer area resources and have a significantly lower time latency. Otherwise, addition and subtraction are more suitable using FLP representation. A higher efficiency of some LNS operations was a motivation for using the LNS format for the realization of control algorithms for the autonomous electric vehicle developed within a running research project.
Nowadays, LNS representation is implemented in various applications, such as deep-learning networks [
7], Cartesian to polar coordinates converters [
8], or embedded model predictive control [
9].
In a very interesting paper [
10], it is proposed how numbers close to zero can be represented in the denormal LNS method (DLNS) using either fixed-point or LNS representations, guaranteeing constant absolute or constant relative precisions, respectively. Up to now, LNS have not been standardized.
Various methods have been developed to decrease the costs and complexity of LNS implementation, e.g., interpolation, co-transformation, multipartite tables, etc. [
11,
12,
13]. Typically, there are three main categories of LNS arithmetic techniques: lookup tables, piecewise polynomial approximation, and digit–serial methods [
14].
Generally, LNS addition and subtraction are carried out based on the evaluation of the transcendental functions as follows:
where
a,
b are logarithmic numbers.
Signal processing in embedded systems based on LNS has three stages: logarithmic conversions, simple operations, and antilogarithmic conversions. In the first processing stage, logarithmic conversions are applied to convert binary numbers into logarithmic ones. In the second stage, simple operations are used to perform corresponding calculations, such as addition and subtraction. In the last stage, logarithmic numbers are converted back to binary ones. There are many approaches to solving logarithmic conversion that can be classified into three categories: memory-based methods [
15,
16], mathematical approximations [
6], and shift-and-add-based methods [
11,
13,
17,
18,
19,
20]. Very fast conversions (e.g., shift-and-add) allow us to combine calculations in LNS and FLP systems and design hybrid LNS/FLP processors [
13,
21,
22]. In hybrid systems, the conversions are carried out several times during the calculation, not only the first and last phases.
Using memory-based methods, fast and more accurate conversions are achieved; however, memory size costs may increase significantly while the bit-width of the inputs increases. On the other hand, using polynomial approximations will reduce the area costs, while sacrificing the accuracy and speed. Approximation-based methods almost always use a multiplication operation, for example, an antilogarithmic converter [
6] uses 20 multipliers and achieves a latency of more than 70 ns. Compared with these two kinds of implementation, shift-and-add methods can be used to achieve better design tradeoffs between accuracy, memory costs, and speed. All the above-mentioned “shift-and-add” methods achieve a latency of less than 1 ns at the cost of a low accuracy (above 1% relative error [
20]) except for [
23], where the attained accuracy of the LNS/FLP conversions is 0.138%. Using the proposed looping-in-sectors method in combination with a very simple approximation based on bit manipulations, a radical increase in accuracy and an acceptably low latency can be achieved.
The logarithmic and antilogarithmic conversions are a gateway to LNS algorithms. Yet, the conversions are not freely available from FPGA producers [
24] and, thus, must be implemented by our own means. Furthermore, the above methods available in the literature do not meet our requirements in that the accuracy of modern industrial sensors is better than 0.1%, and sampling periods in embedded systems for motion control are less than 1 ms, which places high demands on conversion speed and application calculations. Therefore, our motivation was to develop a simple and efficient FLP/LNS conversion guaranteeing sufficient accuracy and speed, which will be a “golden mean” between the accurate but complex approximation methods and the very efficient and fast (up to 1ns) but inaccurate (relative error higher than 1%) shift-and-add methods.
Embedded systems are expanding into increasingly demanding applications, such as camera systems, lidars and 2D/3D image processing, neural networks, car control units, autonomous control systems that require more computing power, etc. A necessary reliability and functional safety are often based on redundancy of two/three channel technologies. Therefore, alternative calculations (one option is LNS) on independent HW and SW (hardware and software) solutions are needed; outputs of the independent channels are then compared according to the principles of fault tolerant systems (e.g., two out of three).
However, embedded control systems based on LNS arithmetic that operate in real-time necessitate an efficient conversion in every sampling period. Input data from sensors, counters, A/D converters, etc., are typically fixed-point (FXP) numbers, thus they have to be converted to LNS, and, the other way round, the LNS arithmetic results are to be converted back to the FXP format conventionally required by typical output devices (actuators). In this paper, the focus is on conversions between LNS and FLP, conversions from FXP to FLP and back are supposed to be resolved.
The Xilinx’s industry-leading tool suite natively supports different FLP precisions including half (FLP16), single (FLP32), and double (FLP64) precisions, as well as fixed-point data types. The added flexibility of custom precision is also available in MATLAB System Generator for DSP toolbox. The FLP to FXP conversion is dealt with in [
24], however the LNS data type is not yet officially supported and conversions from LNS to FLP and back are not available in FPGA libraries.
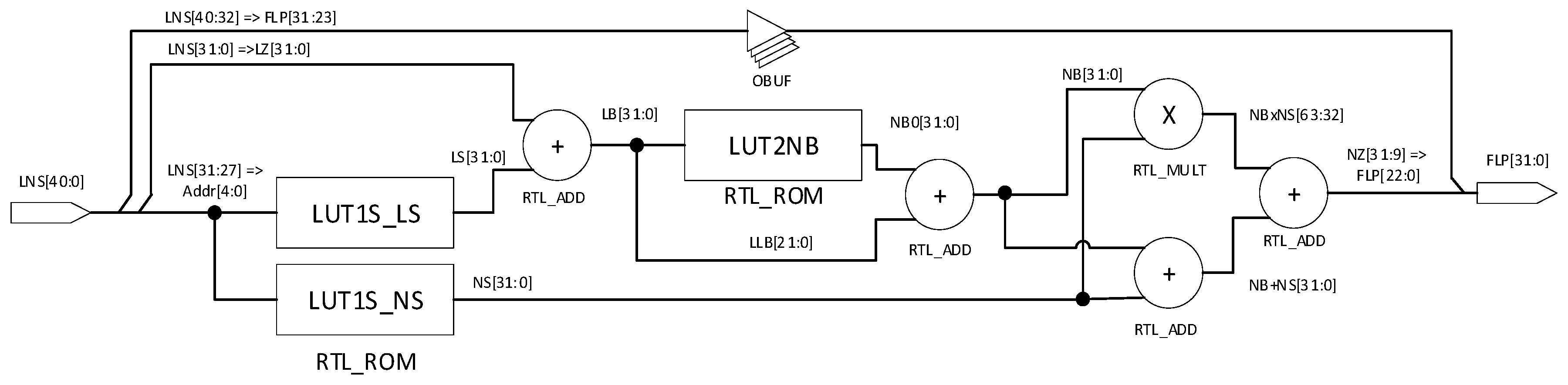
This paper presents an application of the proposed RISC conversions for logarithmic addition using the Reduced Instruction Set Computing (RISC) realizable just by means of simple operations without using multiplication, etc. Herein, RISC indicates a set of simple computer operations (add, minus, shift by 2, i.e., multiplication/division, logical operations, and bit manipulations). The proposed approach has the ambition to apply just the above-mentioned RISC operations fully excluding multiplication, division, and all other functions (log, square, …). Using the unified format of LNS and FLP, conversion between them can be realized only by dealing with the mantissa and the fraction. To reduce memory requirements for conversions, a novel method called “looping in sectors” was developed.
The paper presents a novel effective RISC-based method, which uses the so-called “looping-in-sectors” procedure and a simple interpolation in the conversion between FLP and LNS number representations. The novel algorithm of logarithmic addition based on the developed conversions performs differently from previously known approaches. The partial results on the development of RISC conversions and algorithms for LNS [
25] are completed by the conversion algorithm from LNS to FLP and its realization on FPGA.
The paper is organized as follows. In
Section 2, an overview of FLP and LNS number representations is provided.
Section 3 presents two developed algorithms of the RISC conversion between both systems. A simple interpolation method along with accuracy analysis are dealt with in
Section 4. Principle of the RISC-based LNS addition is explained in
Section 5. FPGA realization of the RISC conversion is demonstrated on a simple example in
Section 6. Discussion on obtained results, their potential, and future research concludes the paper.
2. Number Systems
Let us briefly revisit the FLP and LNS number representations. According to
Table 1, a floating point (FLP) number is expressed as follows:
where
m is a mantissa, and
N is an integer or a real number from the intervals 〈0,
M − 1〉 or ⟨0,
M〉, respectively.
M is the maximum of the mantissa (fractional part) with t bits.
Table 2 shows the principle of an LNS number representation; according to it:
The logarithmic fraction f can be expressed as follows:
where
F is an integer in the range 〈
〉 or a real number in the range
.
In terms of individual bits, the whole exponent
Ef consists of “integer bits” (
ix) and “fractional bits” (
fy), placed next to each other.
SE denotes the sign of the exponent.
For both numerical systems, the number of bits of the exponent E corresponds to the range of the numbers, and the number of the fractional part bits reflects the accuracy.
2.1. Two Possible Representations of LNS Numbers
The mantissa m is always a positive number (0 ≤ m < 1), but the logarithmic fraction depends on the sign of the exponent SE. Still, there is also another possibility to represent LNS fraction as always positive, similar to mantissas.
Let a number
X < 1,
E ≤ 0 and a fraction
f < 0.
FSE and
FAP are positive real numbers from 〈0, M〉.
where
FAP is a complement of
FSE to the range of the fraction
M, i.e.,
For numbers X > 1, FAP = FSE and the integer E is unchanged. FAP is an always-positive fraction.
The sign of FSE is the same as the sign SE. For the sake of completeness note that for X = 1 there are two possible ways (i.e., possible codes) to represent zero. In the FSE representation, E= ±0 and the fraction FSE = 0 (the same as for X = −1). In the FAP representation there is no such anomaly; the conversion between FAP and FSE proceeds (7) and (8).
2.2. Equivalence between FLP and LNS
The FLP (2) and LNS (4) representations are equivalent if integer parts of both representations are equal numbers of e-bits, and both the fraction and the mantissa are equal numbers of t-bits. It is also necessary to use an always positive fraction
FAP. The sign
S and the exponent
E are matching:
Let
NX denote the mantissa (FLP) and
LX = FAP is the always positive fraction (LNS). The subscript “x“ specifies that they represent (code) the equivalent number
X in diverse number systems. Using the following conversion between the mantissa and the fraction, equivalence of FLP and LNS can be attained:
where
and
LZ, NZ are positive integers from the interval 〈
〉 or positive real numbers within the interval 〈
〉. In the same range, sequences of integers for
L and
N are geometric and arithmetic, respectively. The integer form of
L and
N is used to address the look up table (LUT) memory, while their real form is needed to attain a required accuracy. By extending the number of bits of the lower fraction and mantissa to
t +
r bits, the accuracy can be improved. Using the following corrections, the mutual number conversions over the interval 〈
〉 can be defined as follows:
where
CNZ and
CLZ are correction functions for conversions in both directions:
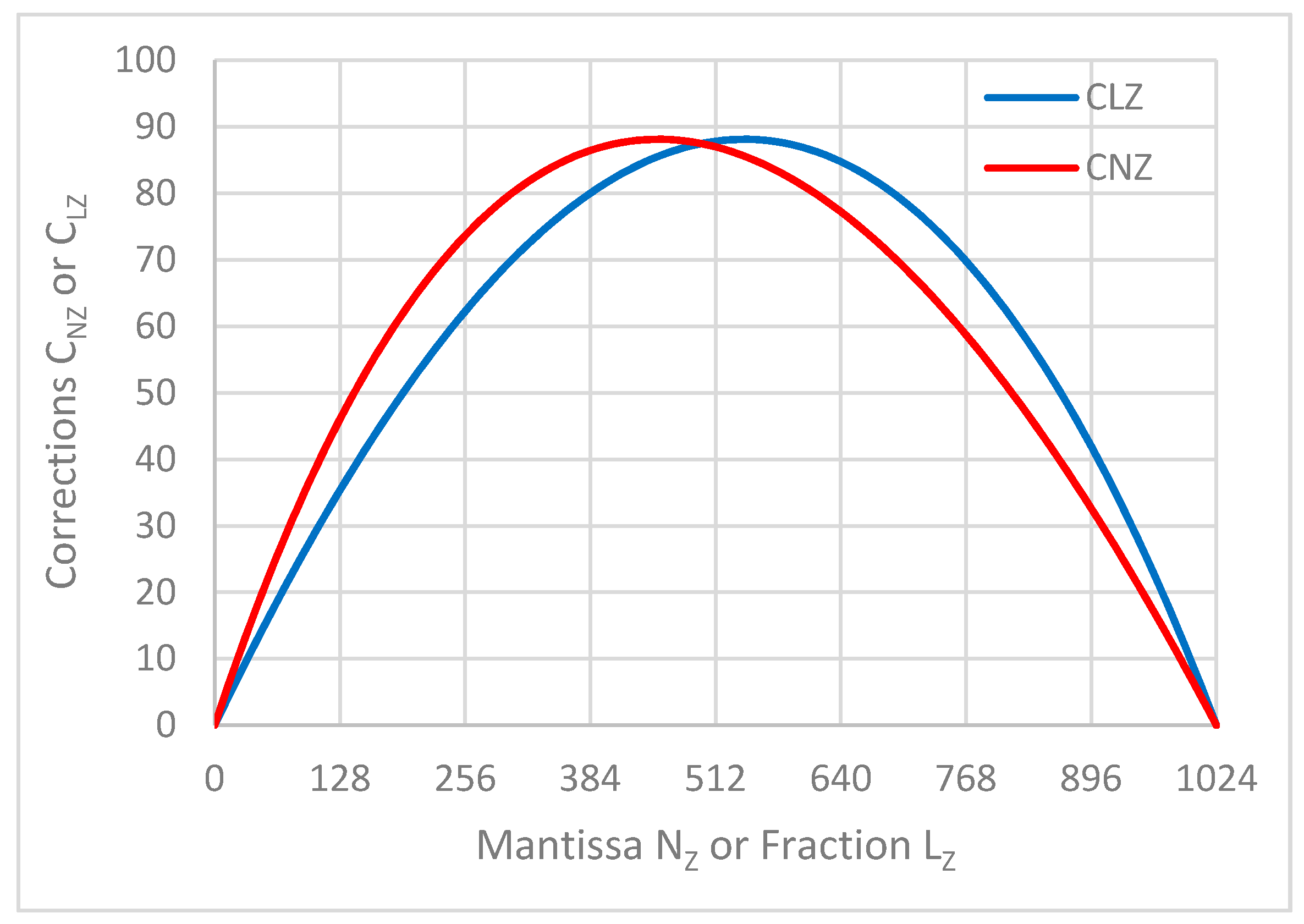
From the corresponding diagrams in
Figure 1 it is evident that both functions have the same maximum, however at various arguments:
4. Interpolation and Accuracy
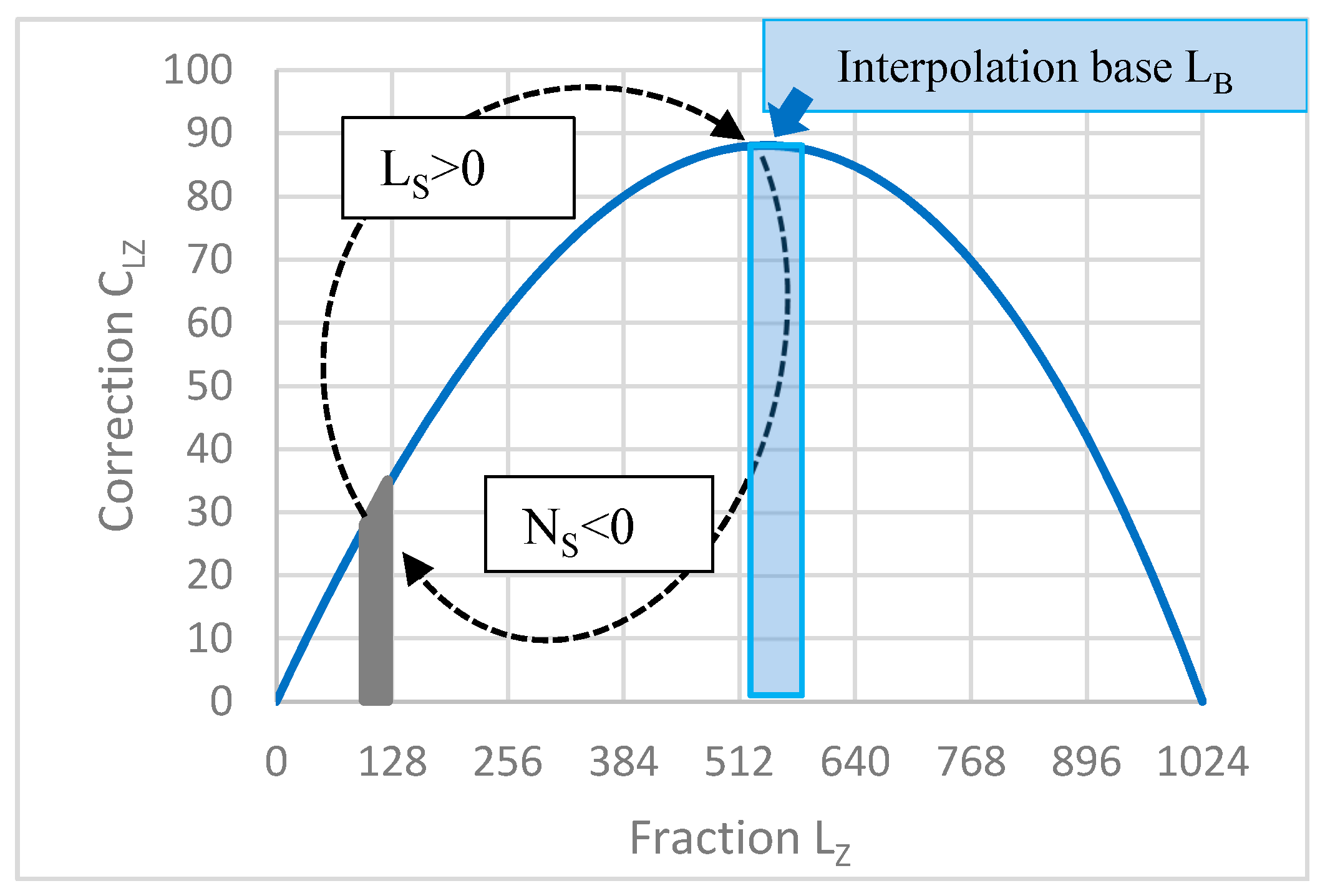
For both FLP and LNS, the accuracy is given by the number of bits of the mantissa and the fraction; it usually decreases due to approximation or interpolation. In the effective RISC conversion design, a simple interpolation is based on bit manipulation. The interpolation is demonstrated on the LNS to FLP conversion. The base generated according to (12) and (14) and the corresponding look-up table LUT2NB were chosen so that the base falls within the plateau in the close vicinity of the
CLZ function maximum (
Figure 2).
The plateau region was intentionally chosen as the interpolation base because differences between the “adjacent” logarithmic values of
LB and the arithmetic sequence values of
NB are approximately matching; this allows us to interpolate between two points in the table in a very simple way (
Figure 3).
Approximating the mantissa
NB (denoted as the interpolation base
LB in
Figure 2) using the look-up table LUT2NB is demonstrated in
Figure 3:
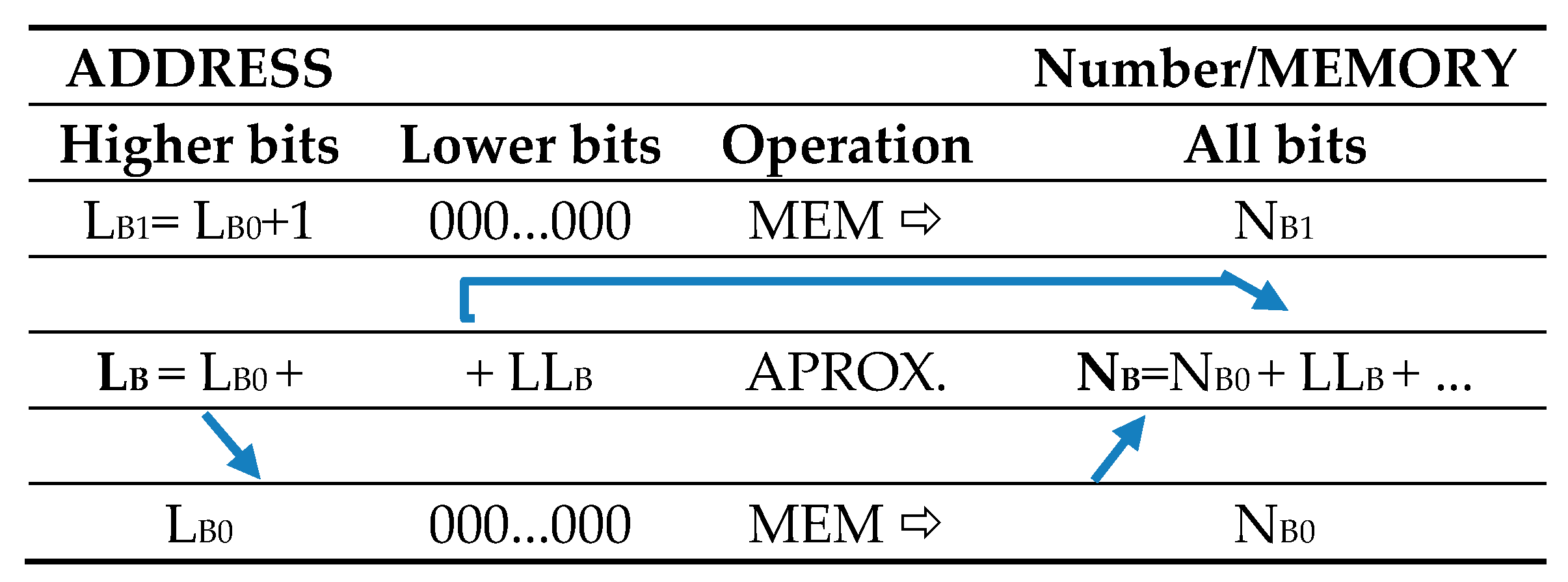
The fraction LB is rounded to the higher n bits (e.g., n = 10), thus obtaining the address LB0. Then, NB0 is read from the memory.
Lower bits of
LB are denoted as
LLB:
The simplest approximation is the “quasilinear” interpolation as follows:
According to this method, the error dN
B01 is calculated as a difference of adjacent memory locations in the considered memory LUT2NB:
In case of a 10-bit memory quantization in the range
the maximum positive error is
(
) at the right limit of the interval, and the maximum negative error is
(
) at the left limit, which corresponds to an accuracy of 16 bits (10 + 6). These errors of the variable
NB will then be influenced by a factor (1 +
NS/M) in the range 〈
〉, according to (18). The resulting error analysis is in
Section 6. The accuracy can be improved using a finer memory quantization in the plateau region. Note that the above accuracy levels are attained using RISC, i.e., multiplication is not used.
If a higher accuracy is needed, the following linear interpolation can be applied:
In the memory region LUT2NB with 40 cells where the approximation error occurs due to nonlinearity. Local extremes between adjacent memory cells (approximately in the middle of them) were examined. For a 10-bit memory quantization, the related accuracy is 23 bits (10 + 13). The proposed linear interpolation is a RISC extended by one multiplication operation.
Finally, it has to be noted that the FLP to LNS interpolation procedure is similar, only based on Equations (11) and (13). Details are described in [
25]. Accuracy assessment in terms of memory quantization is the same.
5. Application of RISC Conversions for Logarithmic Addition
The principle of the logarithmic addition based on the developed RISC conversions is briefly presented in this section. The aim is to show the possibility of applying the developed conversions for RISC-based LNS addition without additional memory requirements. Similar algorithms developed for data conversion at the input and output of the embedded system can be used for the LNS adder.
Consider two real numbers
where
represented in LNS using integer exponents
EA, EB, and fractions
LA, LB, respectively:
The proposed operation of logarithmic addition will be demonstrated under the assumptions
and
. Applying the distributive law, we obtain:
Assume
and
, we obtain:
Denote
LAB, d and
EAS as follows:
Then from both assumptions results:
The RISC-based conversion of the fraction
LAB =
LA −
LB to the mantissa
NAB is carried out using (12). Then, 1
+ NAB /M has a mantissa format;
can be considered as a mantissa or a fraction, as needed. For
M, the corrections (13), (14) are zero, i.e., no conversion is required. Dividing
M by powers of 2
d, i.e., applying the shifting by
d, we obtain a result, which has the range and character of a mantissa; let us denote it
, then
where the two rightmost terms in the expression in parentheses have a
format and can be simply summed:
If is
(overflow), then
Applying the RISC conversion of
to
according to (11) we obtain:
which is a logarithmic sum of the original numbers A, B.
When implemented, the overflow
of the range 〈0,
M − 1〉 by the fraction L has to be treated. The integer exponent of the sum
ESUM can take two values: either
EAS or
EAS + 1 (under overflown).
The above-presented original procedure of LNS addition is based solely on RISC-type operations including two RISC conversions that determine the accuracy of the adder. The LNS adder can be implemented using the six standard additions or subtractions (28)–(30), (33), (34) and (36), by comparing four pairs of numbers, two shifting operations, and two RISC conversions. The developed approach is promising for applications in embedded control systems realized, e.g., on FPGA [
26]. More details on LNS addition and subtraction via RISC computing can be found in [
25].
7. Discussion
Conversions of numbers play an important role in the LNS arithmetic, especially in real-time systems. In this paper, equivalence between the FLP (semi-logarithmic) and LNS (fully logarithmic) systems was defined, and conversion between them was reduced to a conversion between the mantissa and fraction performed within the interval 〈1, 2〉. Derived correction functions enabled to specify an optimal interval for conversion within the plateau around their maxima where a mathematically simple and accurate interpolation can be performed. According to the developed procedure called looping in sectors (LiS), the converted number is to be moved to the plateau in the vicinity of the correction function peak and back after the interpolation accomplishment, hence reducing memory consumption. Note, that the LiS is performed without loss of accuracy, resulting in effective RISC conversions, which use only elementary computer operations. The developed conversions are then implemented in the designed LNS addition based on RISC operations and can thus be realized without a necessity to use multiplication, division, and other functions.
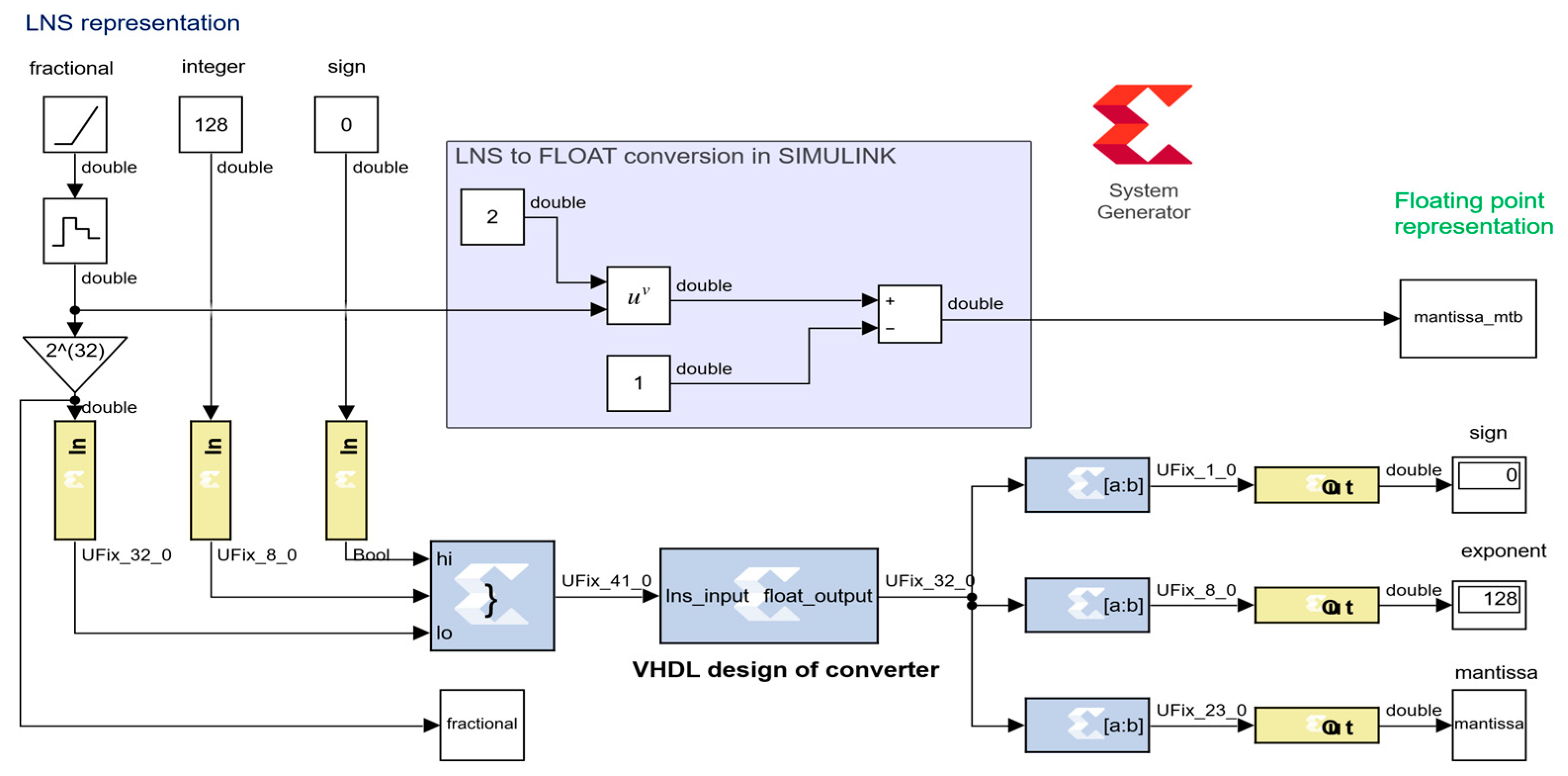
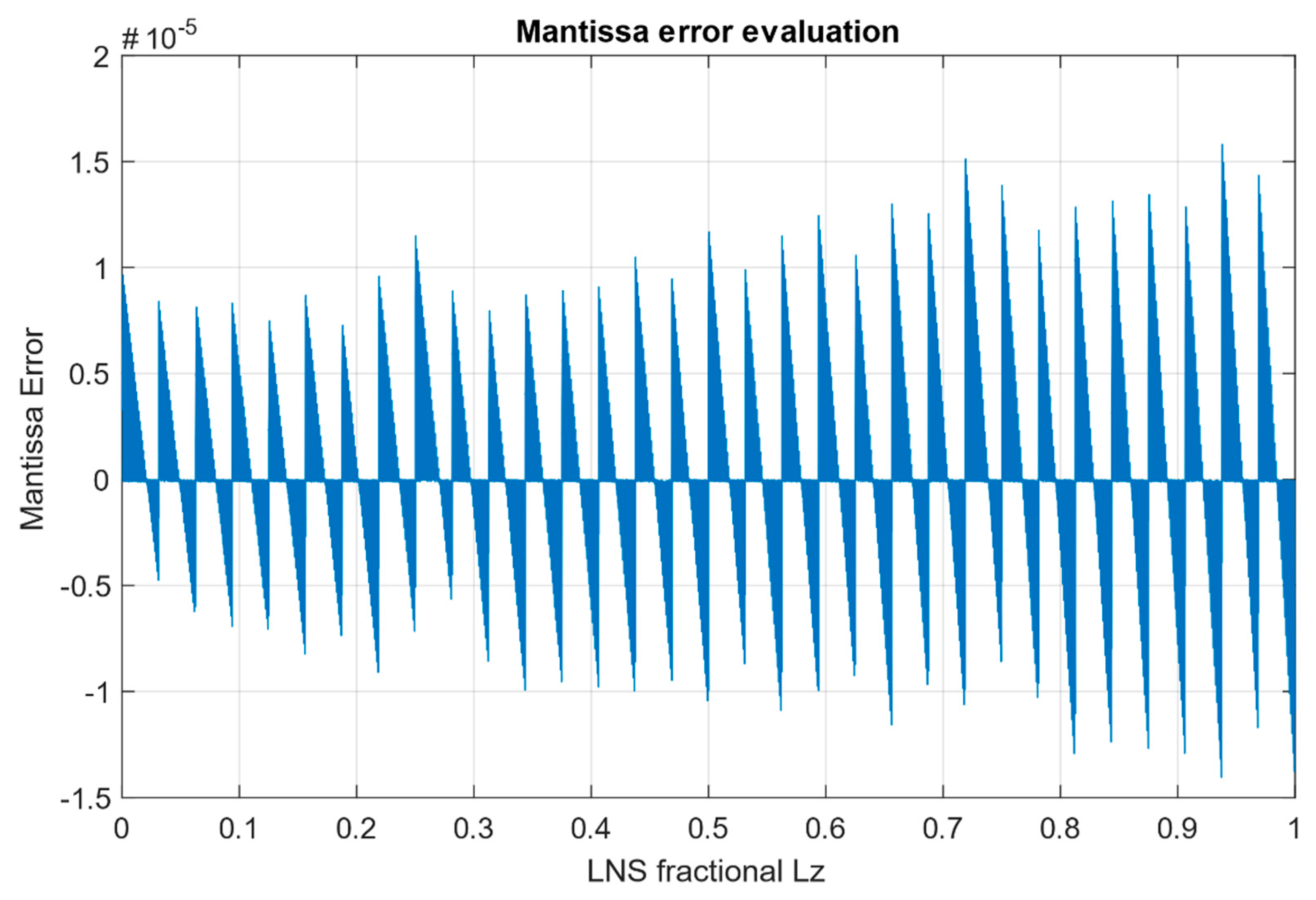
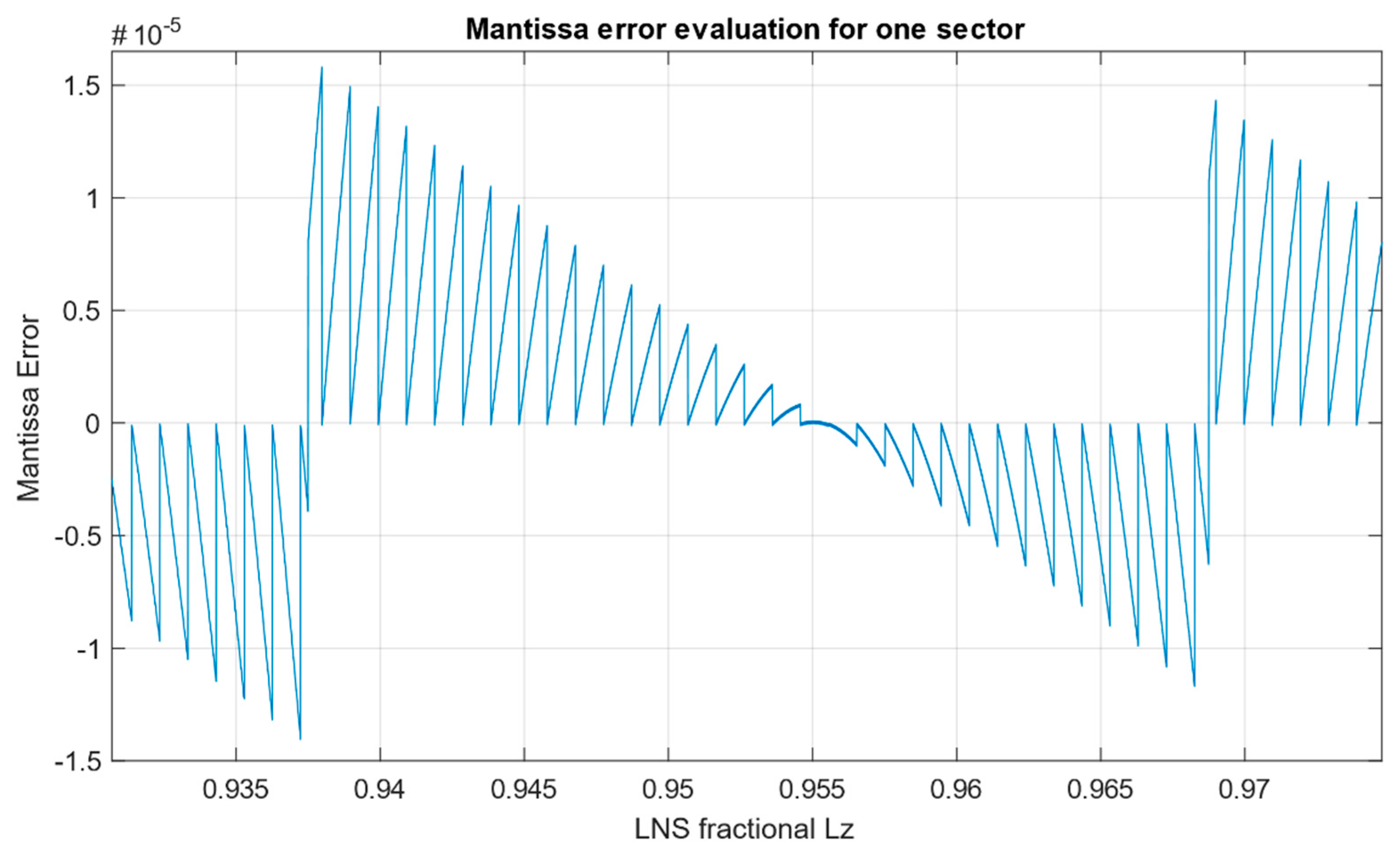
As a part of the development, conversion algorithms from LNS to FLP and vice versa [
25] were implemented on FPGA, and their accuracy was verified by simulation. The presented methodology based on the new correction functions, the looping-in-sectors method, and the optimal choice of a base for an efficient interpolation can further be optimized for different types of applications in embedded systems. For different applications, different attributes are prioritized: in measurement and signal processing from sensors it is accuracy, in complex control algorithms it is speed, in automotive and autonomous systems reliability and credibility of the information obtained are the most essential ones.
The modern very fast “shift-and-add” methods (latencies about 1 ns) prevail only in selected complex algorithms that tolerate low accuracy (only 1%) but are inappropriate in other applications. The proposed LiS method is suitable for control applications in combination with input and output signal processing, as well as one of alternative methods for redundant signal processing and fault-detection due to a deterministically determined high accuracy. The proposed LiS method belongs to faster methods (with a latency of 22 ns) and can be used in real-time control applications even in time-critical applications with a sampling period up to 1 ms.
The future research will be directed on the functional safety of embedded system applications, usually implemented through redundancy and dual-channel technology today. In this sense, we understand LNS not only as an alternative to FLP but also as an SW/HW independent dual method of calculation to eliminate errors and increase the plausibility of results in full compliance with a new paradigm [
34]: “It is much more important to know whether information is reliable or not than the accuracy of the information itself.”











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}