Lossless and Efficient Secret Image Sharing Based on Matrix Theory Modulo 256


Abstract
:1. Introduction
2. Preliminaries
2.1. Shamir’s Polynomial-Based SS
2.2. Matrix Method for Polynomial-Based SS
2.3. The Method to Solve Inverse Matrix
3. The Proposed Scheme
3.1. The Basic Idea
- Condition 1:
- Any k row vectors of the matrix K are linearly independent.
- Condition 2:
- The determinant of any submatrix is coprime with 256.
3.2. The Sharing Phase
| Algorithm 1 The sharing phase of the proposed scheme. |
| Input: The threshold parameters , or , and a grayscale secret image S with size of . Output: n shadows and matrix K. Step 1: Generate an matrix K randomly, and determine that the determinant of any submatrix is not zero and is coprime with 256. If not, repeat Step 1. Step 2: For every secret pixel s in each position , , repeat Step 3–4. Step 3: Generate a vector a, set , and generate randomly in [0,255]. Step 4: Compute f = Ka (mod 256), where . Step 5: Output n shadows and matrix K. |
3.3. The Recovery Phase
| Algorithm 2 The recovery phase of the proposed scheme. |
| Input: The k shadows which are randomly selected from n shadows and corresponding k vectors . Output:The original secret image S. Step 1: Construct a matrix K by k vectors . Step 2: Calculate the adjoint matrix and determinant of matrix K. Compute the inverse matrix according to Equation (7). Step 3: For each position , , repeat Step 4–5. Step 4: Get a by . Step 5: Set the pixel . Step 6: Output the secret image S. |
4. Theoretical Analysis
4.1. Threshold Analysis
- To make the determinant odd, we need to add an odd number of product terms with odd products. Corresponding to: to make the determinant to be 1, we need to add an odd number of product terms whose product is 1.
- To make the product term odd, all the factors need to be odd. Corresponding to: to make the product term to be 1, we need all 1 in the factor.
- There is one even number in the factor, then the product is even. Corresponding to: there is one 0 in the factor, then the product is 0.
4.2. Security Analysis
4.3. Complexity Evaluation
4.4. Lossless Recovery Analysis
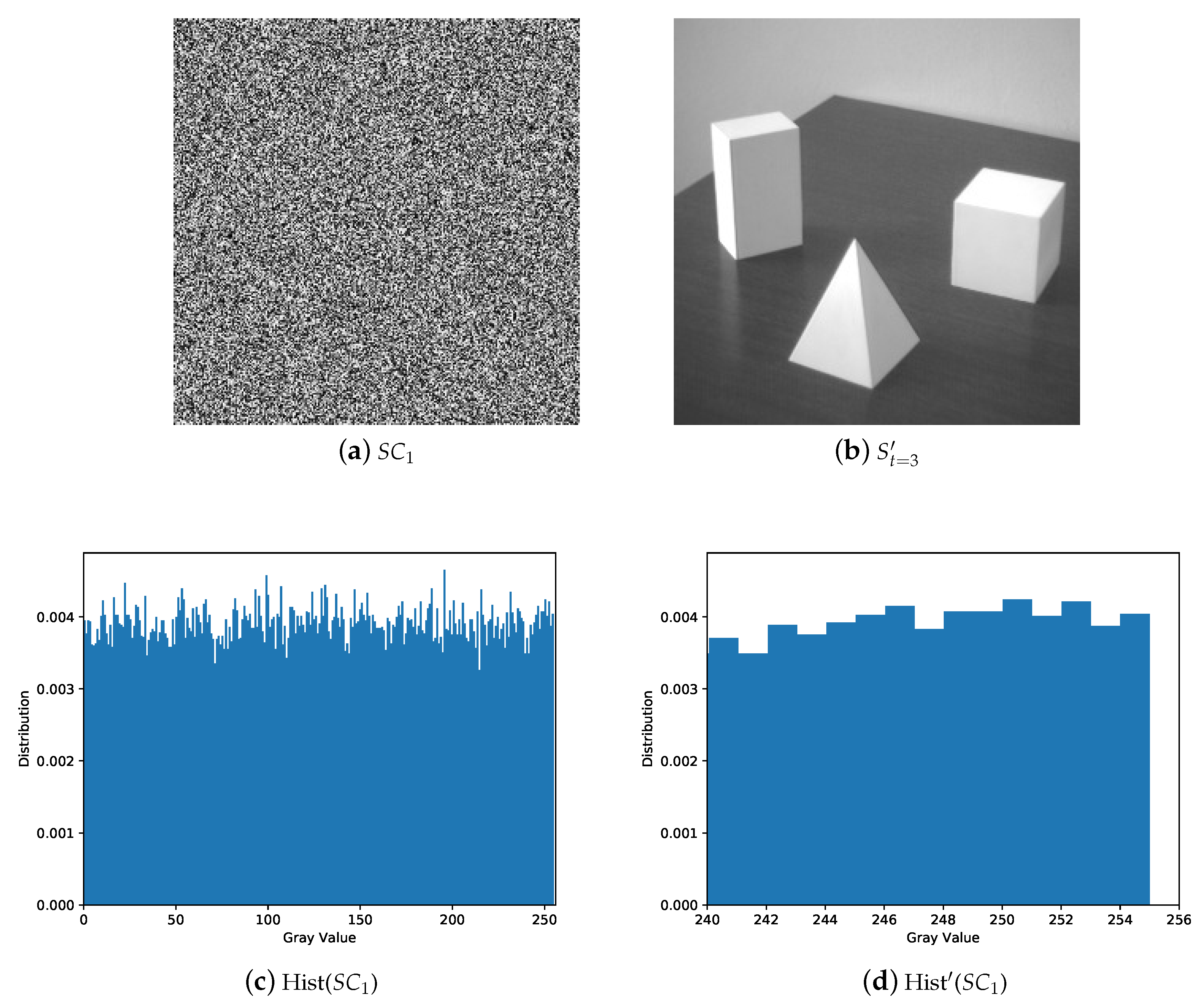
5. Experiments and Comparisons
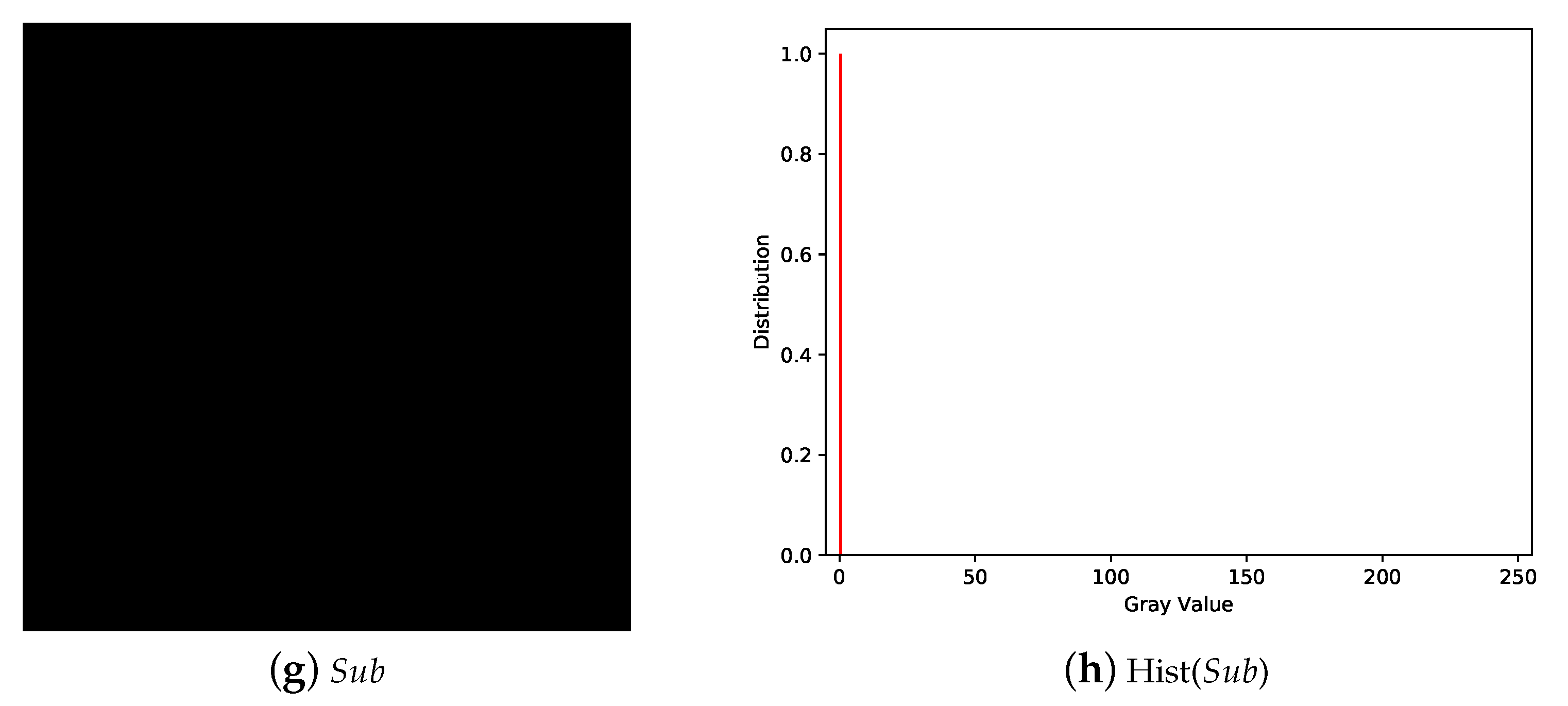
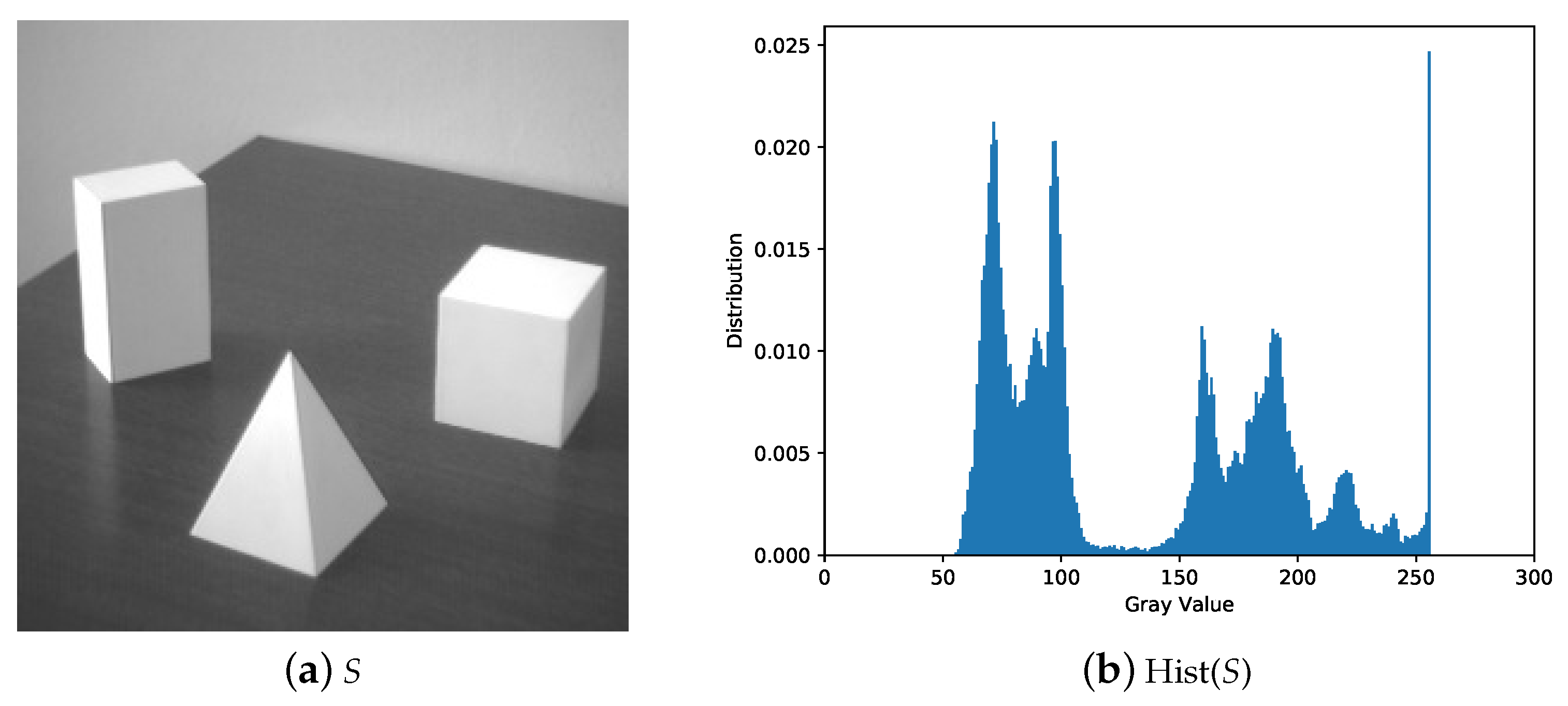
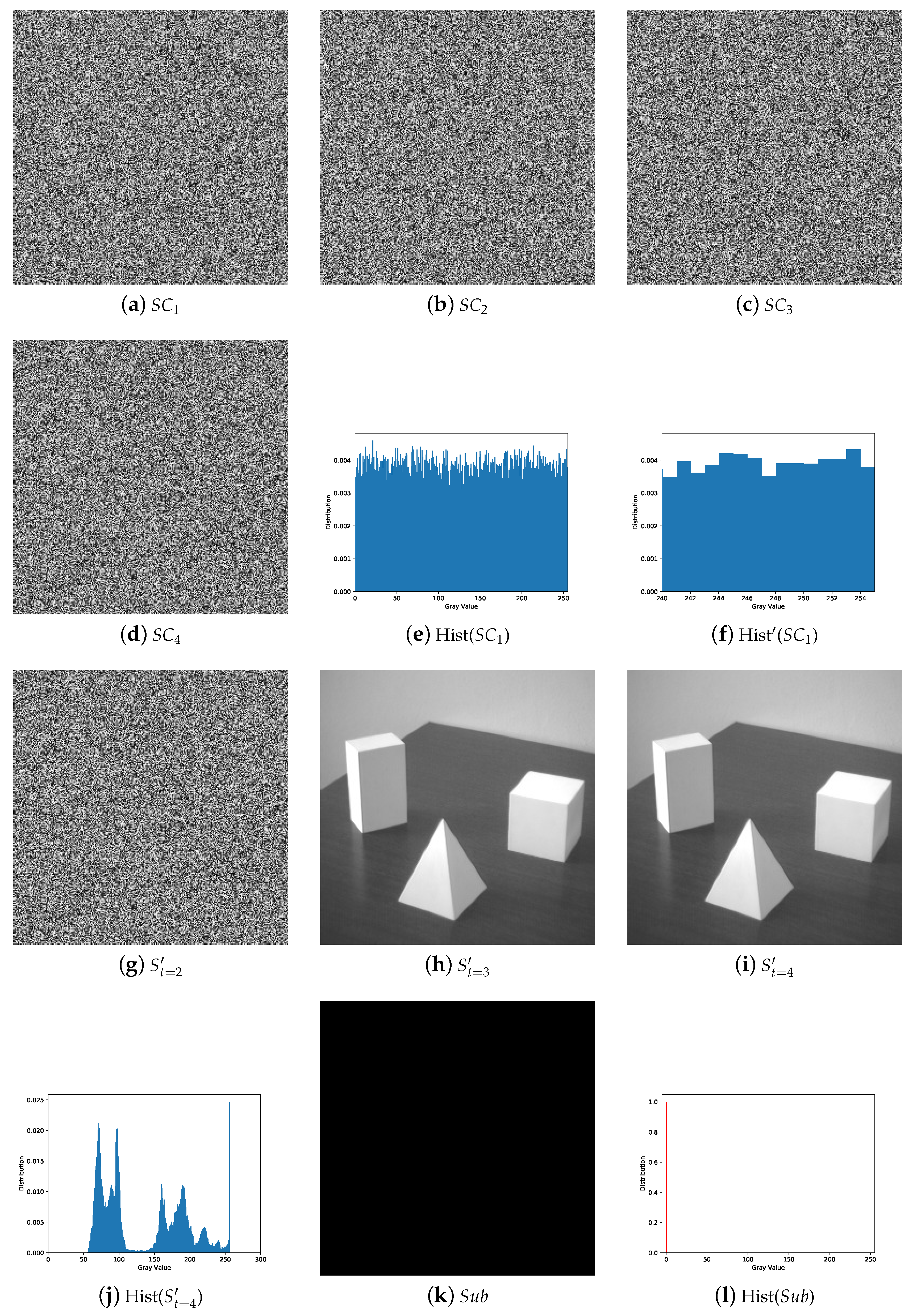
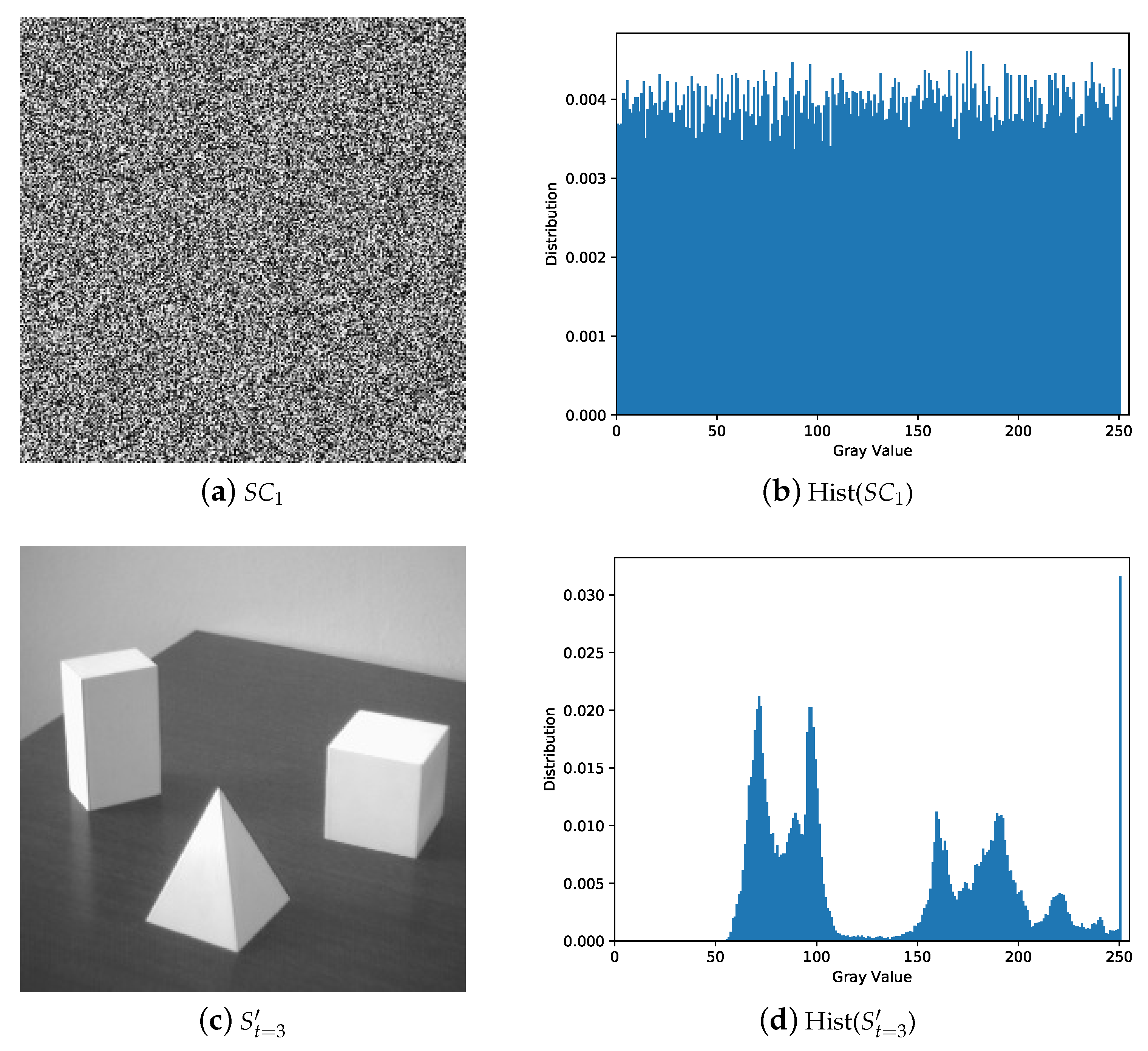
5.1. Image Illustration
5.2. Comparisons with Related Works
5.2.1. Illustration Comparison
5.2.2. Efficiency Comparison
5.3. Brief Summary
- The secret image can be reconstructed losslessly with k or more shadows and there is no leakage of secret information from the recovered image with less than k shadows.
- The shadows are noisy-like, thus every single shadow gives no clue about the secret. Pixel values of shadow are evenly distributed without security issues.
- The proposed scheme has obvious advantages in efficiency.
6. Conclusions
- To further exploit the secret image sharing scheme, we can consider various recommendation mechanisms that provide content to the end users [26].
- We can use the personalized content retrieval mechanisms [27], in order to exploit the content, i.e., images, that the users consume to further improve our secret image sharing scheme.
- Big data that are available in complex systems [28] can be exploited to improve our analysis and model.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Shamir, A. How to share a secret. Commun. ACM 1979, 22, 612–613. [Google Scholar] [CrossRef]
- Blakley, G.R. Safeguarding cryptographic keys. In Proceedings of the National Computer Conference, New York, NY, USA, 4–7 June 1979; IEEE Computer Society: New York, NY, USA, 1979; pp. 313–317. [Google Scholar]
- Ciegis, R.; Starikoviăźius, V.; Tumanova, N.; Ragulskis, M. Application of distributed parallel computing for dynamic visual cryptography. J. Supercomput. 2016, 72, 4204–4220. [Google Scholar] [CrossRef]
- Palevicius, P.; Ragulskis, M. Image communication scheme based on dynamic visual cryptography and computer generated holography. Opt. Commun. 2015, 335, 161–167. [Google Scholar] [CrossRef]
- Yan, X.; Lu, Y.; Liu, L.; Wan, S.; Ding, W.; Liu, H. Exploiting the Homomorphic Property of Visual Cryptography. Int. J. Digit. Crime Forensics 2017, 9, 45–56. [Google Scholar] [CrossRef] [Green Version]
- Yan, X.; Lu, Y.; Liu, L.; Song, X. Reversible Image Secret Sharing. IEEE Trans. Inf. Forensics Secur. 2020, 15. [Google Scholar] [CrossRef]
- Naor, M.; Shamir, A. Visual cryptography. In Advances in Cryptology—EUROCRYPT’94 Lecture Notes in Computer Science, Workshop on the Theory and Application of Cryptographic Techniques, Perugia, Italy, 9–12 May 1994; Springer: Berlin/Heidelberg, Germany, 1995; pp. 1–12. [Google Scholar]
- Yang, C.N. New visual secret sharing schemes using probabilistic method. Pattern Recognit. Lett. 2004, 25, 481–494. [Google Scholar] [CrossRef]
- Yan, X.; Wang, S.; El-Latif, A.A.A.; Niu, X. Visual secret sharing based on random grids with abilities of AND and XOR lossless recovery. Multimed. Tools Appl. 2015, 74, 3231–3252. [Google Scholar] [CrossRef]
- Wang, G.; Liu, F.; Yan, W.Q. Basic Visual Cryptography Using Braille. Int. J. Digit. Crime Forensics 2016, 8, 85–93. [Google Scholar] [CrossRef] [Green Version]
- Thien, C.C.; Lin, J.C. Secret image sharing. Comput. Graph. 2002, 26, 765–770. [Google Scholar] [CrossRef]
- Bhadravati, S.; Khabbazian, M.; Atrey, P.K. On the Semantic Security of Secret Image Sharing Methods. In Proceedings of the 2013 IEEE Seventh International Conference on Semantic Computing, Irvine, CA, USA, 16–18 September 2013; pp. 302–305. [Google Scholar]
- Li, P.; Yang, C.; Kong, Q. A novel two-in-one image secret sharing scheme based on perfect black visual cryptography. J. Real Time Image Process. 2018, 14, 41–50. [Google Scholar] [CrossRef]
- He, J.; Lan, W.; Tang, S. A secure image sharing scheme with high quality stego-images based on steganography. Multimed. Tools Appl. 2017, 76, 7677–7698. [Google Scholar] [CrossRef]
- Yang, C.N.; Ciou, C.B. Image secret sharing method with two-decoding-options: Lossless recovery and previewing capability. Image Vis. Comput. 2010, 28, 1600–1610. [Google Scholar] [CrossRef]
- Li, P.; Ma, P.J.; Su, X.H.; Yang, C.N. Improvements of a two-in-one image secret sharing scheme based on gray mixing model. J. Vis. Commun. Image Represent. 2012, 23, 441–453. [Google Scholar] [CrossRef]
- Li, P.; Yang, C.N.; Wu, C.C.; Kong, Q.; Ma, Y. Essential secret image sharing scheme with different importance of shadows. J. Vis. Commun. Image Represent. 2013, 24, 1106–1114. [Google Scholar] [CrossRef]
- Li, L.; El-Latif, A.A.A.; Yan, X.; Wang, S.; Niu, X. A Lossless Secret Image Sharing Scheme Based on Steganography. In Proceedings of the 2012 Second International Conference on Instrumentation, Measurement, Computer, Communication and Control, Harbin, China, 8–10 December 2012; pp. 1247–1250. [Google Scholar]
- Liu, L.; Lu, Y.; Yan, X.; Ding, W. A Novel Progressive Secret Image Sharing Method with Better Robustness. In Data Science: Third International Conference of Pioneering Computer Scientists, Engineers and Educators, ICPCSEE 2017, Changsha, China, 22–24 September 2017, Part II; Zou, B., Han, Q., Sun, G., Jing, W., Peng, X., Lu, Z., Eds.; Springer: Singapore, 2017; pp. 539–550. [Google Scholar] [CrossRef]
- Lin, S.J.; Lin, J.C. VCPSS: A two-in-one two-decoding-options image sharing method combining visual cryptography (VC) and polynomial-style sharing (PSS) approaches. Pattern Recognit. 2007, 40, 3652–3666. [Google Scholar] [CrossRef]
- Zhou, X.; Lu, Y.; Yan, X.; Wang, Y.; Liu, L. Lossless and efficient polynomial-based secret image sharing with reduced shadow size. Symmetry 2018, 10, 249. [Google Scholar] [CrossRef] [Green Version]
- Gong, Q.; Yan, X.; Wang, Y.; Liu, L. Polynomial-based Secret Image Sharing in the Galois Field of GF(28). In Proceedings of the 2019 Fifteenth China Information Hiding Workshop (CIHW2019), Xiamen, China, 19–20 October 2019. [Google Scholar]
- Ding, W.; Liu, K.; Yan, X.; Wang, H.; Liu, L.; Gong, Q. An image secret sharing method based on matrix theory. Symmetry 2018, 10, 530. [Google Scholar] [CrossRef] [Green Version]
- Xia, Z.; Yang, X.; Xiao, M.; He, D. Provably secure threshold paillier encryption based on hyperplane geometry. In Information Security and Privacy. ACISP 2016; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Guo, Z.; Qing, H. Inquiry into integer determinant parity. Math. Pract. Theory 2010, 21, 212–215. [Google Scholar]
- Stai, E.; Kafetzoglou, S.; Tsiropoulou, E.E.; Papavassiliou, S. A holistic approach for personalization, relevance feedback & recommendation in enriched multimedia content. Multimed. Tools Appl. 2018, 77, 283–326. [Google Scholar]
- Pouli, V.; Kafetzoglou, S.; Tsiropoulou, E.E.; Dimitriou, A.; Papavassiliou, S. Personalized multimedia content retrieval through relevance feedback techniques for enhanced user experience. In Proceedings of the 2015 13th International Conference on Telecommunications (ConTEL), Graz, Austria, 13–15 July 2015; pp. 1–8. [Google Scholar]
- Thai, M.; Wu, W.; Xiong, H. Big Data in Complex and Social Networks; CRC Press: New York, NY, USA, 2016; pp. 1–242. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Descriptions |
|---|---|
| threshold, | |
| the integer space of modulo 256 | |
| p | generally a prime number, we take 256 in this paper |
| K | a random matrix by a filter operation satisfying any k row vectors of the matrix K are linearly independent and the determinant of any submatrix is coprime with 256 |
| K | a submatrix of K |
| a | a vector in which is the secret pixel value and others are generated randomly in [0,255] |
| f | a vector obtained by Ka = f, whose elements are |
| a pixel in shadow image | |
| a shadow image corresponding to the i-th participant |
| Time | Time | ||
|---|---|---|---|
| (2, 2) | 0.000499 | (2, 3) | 0.000998 |
| (3, 3) | 0.000497 | (3, 4) | 0.001501 |
| (4, 4) | 0.000501 | (4, 5) | 0.004497 |
| (5, 5) | 0.000499 | (5, 6) | 0.009499 |
| (6, 6) | 0.000499 | (6, 7) | 0.031500 |
| mod 257 | mod | mod 256 (Ours) | |
|---|---|---|---|
| (2, 2) | 1.040 | 1.116 | 0.906 |
| (2, 3) | 1.387 | 1.513 | 0.992 |
| (3, 3) | 1.522 | 1.752 | 1.131 |
| (3, 4) | 1.871 | 2.144 | 1.211 |
| mod 257 | mod | mod 256 (Ours) | |
|---|---|---|---|
| (2, 2) | 1.146 | 0.934 | 0.785 |
| (2, 3) | 1.139 | 0.923 | 0.789 |
| (3, 3) | 1.743 | 1.562 | 0.891 |
| (3, 4) | 1.746 | 1.561 | 0.878 |
| mod 257 | mod | mod 256 (Ours) | |
|---|---|---|---|
| (2, 2) | 2.187 | 2.050 | 1.691 |
| (2, 3) | 2.526 | 2.436 | 1.781 |
| (3, 3) | 3.266 | 3.314 | 2.022 |
| (3, 4) | 3.617 | 3.705 | 2.089 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, L.; Liu, L.; Xia, Z.; Yan, X.; Lu, Y. Lossless and Efficient Secret Image Sharing Based on Matrix Theory Modulo 256. Mathematics 2020, 8, 1018. https://doi.org/10.3390/math8061018
Yu L, Liu L, Xia Z, Yan X, Lu Y. Lossless and Efficient Secret Image Sharing Based on Matrix Theory Modulo 256. Mathematics. 2020; 8(6):1018. https://doi.org/10.3390/math8061018
Chicago/Turabian StyleYu, Long, Lintao Liu, Zhe Xia, Xuehu Yan, and Yuliang Lu. 2020. "Lossless and Efficient Secret Image Sharing Based on Matrix Theory Modulo 256" Mathematics 8, no. 6: 1018. https://doi.org/10.3390/math8061018