1. Introduction
Current trends in quantitative finance reveal that econophysics has become an economic analysis discipline characterized not by its multidisciplinary but by its transdisciplinary nature [
1], contributing to the formation of a common framework in the research of financial phenomena [
2]. Traditionally, the link has been strong between the stochastic analysis of hydrological phenomena and the study of time series, especially in the field of quantitative finance. The best-known example is likely represented by the Hurst exponent, a procedure inspired by the floods of the Nile River [
3], which is of unquestionable efficiency when estimating the long-term memory of time series. Hydrological phenomena are completely different to financial ones but, in general, they present certain common patterns of analysis. Thus, several works have transferred the applicability of the theory of copulas from the field of hydrology to finance [
4,
5,
6,
7]. Recently, Sadegh et al. [
8] developed a specific methodology based on the joint use of 26 multivariate copulas applied in hydrology (hereinafter, SRA), which, in our opinion, offers huge potential for the analysis of the price–volume relationship. Therefore, our aim was to introduce this methodological approach within quantitative finance, summarizing its fundamental aspects as a step prior to its practical implementation.
The analysis of the joint dependence between economic and financial variables has found important support in the Sklar’s theorem, through which it has been possible to specify, define, and contrast the latent or redundant dependence structures present in the bivariate and multivariate time series. Notably, Sklar’s theorem, the starting point from which this theory departs, has been subject to continuous extensions that have improved the analysis of the structures of dependence between random variables or, in other words, of their succinct relationships when these are schematized in their minimal mathematical expression.
The emergent interest in copulas, detailed by [
9], which increased in the field of finance after the paper by [
10], does not correspond in reality to the use of several of the numerous types of pre-existing copulas, but to the systematic implementation of certain copulas types, either in economics and quantitative finance or in any other field. According to the compendium of copulas by [
11], nonparametric and semiparametric models represent a minority that is largely surpassed by parametric models, amongst which almost 100 different types could be distinguished. Some of them have not been yet fully spread by the literature or, at least, they are not sufficiently well known, since most empirical studies opt for the application of a narrow number of copulas that could be classified as classic copulas.
Conversely, the analysis of the price–volume relationship (hereinafter, PVR) continues being a specific area of the financial literature that has not yet received a conclusive solution. In our opinion, the relationship between prices and trading volume can be derived by dissecting the dependence structure of both variables through the Sklar’s theorem, that is, through the implementation of copulas. To accomplish this task, we followed the suggestion of [
11] when implementing as many parametric copulas as possible to jointly analyze the same relationship, prices vs. trading or transaction volume, from different points of view (or dependence structures). Therefore, through this empirical work, we aimed to provide a new approach to the application of copulas in the context of PVR, implementing a large number of copulas that, to the best of our knowledge, have not been previously applied in the area of quantitative finance with the aim that these types of transdisciplinary approaches will transcend from the study of PVR to other areas of financial research in the future. This study was mainly based on [
8], whose 26 parametric copulas, estimated according to a Bayesian uncertainty framework, were replicated in the price–volume variables of the DJIA, FTSE100, NIKKEI225, and IBEX35 indices.
The SRA was implemented in accordance with two different guidelines focused on two respective scenarios: first, this procedure was applied per se to price–volume data of the DJIA index over the period 1928–2009. Second, one of the 26 copulas included in this methodology, the Tawn’s copula [
12], was used to jointly compare the dependence structures derived from the PVR in the FTSE100, NIKKEI225, and IBEX35 indices using the period 2000–2018 as the time horizon (also in per se values). This copula was expressly used as it can be considered one of the new-generation copulas whose knowledge is not yet broadly applied in the literature and whose contribution to the analysis of the PVR may be crucial given its exhaustiveness in the estimation of parameters.
The rest of this article is organized as follows: first,
Section 2 describes the current state of this research by outlining a literature review concerning the theory of copulas and the analysis of the PVR, detailing the works that expressly employed copulas in the determination of the relationship between prices and trading volume. In our opinion, with few exceptions such as [
13,
14], most of the works usually offer an excessively summarized and, in some cases, incomplete literature review of the PVR. For this reason, an extensive review of the literature was conducted by listing the four explanatory hypotheses that were mostly addressed in its study. Similarly, this section summarizes the plausible shortcomings derived from the utilization of copulas, pointing out a series of sociological weaknesses. In
Section 3, the different databases used as well as a brief review of the theoretical bases presented in the SRA are described: its Bayesian perspective, later developed in
Appendix A, and the Markov Chain Monte Carlo simulation used by this methodology. In
Section 4, the results obtained are contextualized, finishing this investigation with
Section 5, which is dedicated to the discussion of the results. The paper finishes with
Section 6, which reflect our conclusions, supplemented with a proposal for future lines of investigation, congruent with the methodological scheme implemented in this manuscript, emphasizing the practical usefulness of the PVR analysis, both for investors and practitioners, from the perspective of the scheme proposed by Karpoff [
13]. To ensure the maximum possible exhaustiveness,
Appendix B provides an introductory summary of the main basis of the theory of copulas.
3. Materials and Methods
Our objective was to present a multi-perspective design of Larkin’s research [
98] that enables the analysis of the PVR from different standpoints, depending on the use of different datasets, time horizons, and analytical tools (copulas). The SRA was applied to two different scenarios to provide a generic and a specific image of this methodology. Instead of using a representative hydrological or meteorological index as an empirical basis (i.e., the standardized precipitation index (SPI) [
99]), per se values of four stock market indices commonly employed by the literature in the study of the PVR were selected: DJIA, FTSE100, NIKKEI225, and IBEX35.
In the first case, or generic scenario, all available copulas (26) were applied to a single index (DJIA). Later, in the specific scenario, a single copula was adjusted to three indices (FTSE100, NIKKEI225, and IBEX35). The copula chosen in the second case was the Tawn copula, a family of new-generation copulas derived from the Khoudraji’s device copula [
100]. In this way, we contribute to the analysis of the PVR with the inclusion of new copulas never or rarely implemented in this research, such as some of those included in the SRA approach. In relation to the construction of the generic scenario, we decided to use a wide database consisting of 20,219 stock trading sessions of the DJIA index, covering the period from 10 January 1928 to 4 August 2009, which were consecutively subdivided into quarterly periods until obtaining 490 observations representing the adjusted closing values of the DJIA at the end of each corresponding session and the final volume of the shares traded at each date.
This temporal accrual as well as the use of data per se allowed us to adapt the original datasets to the methodology proposed by [
8]. The analysis of the specific scenario corresponding to the FTSE100, NIKKEI225, and IBEX35 indices involved monthly data of per se price and volume collected during the period from 31 October 2000 to 30 November 2018, which included 218 monthly observations for each stock index. The most representative descriptive statistics of the generic scenario, shown in
Table 1, reveal a fundamental aspect: the huge level of variability of variables “price” and “trading volume” when both are measured in per se terms (especially in the latter case).
In the same way, the values per se of the variables “price” and “trading volume” denote a relatively high degree of correlation in terms of the Pearson, Kendall, and Spearman correlation coefficients (0.7365, 0.8279, and 0.9559, respectively), which a priori could be considered significant measures of dependence. However, as underlined by Frey et al. [
101], a high degree of correlation does not necessarily imply real dependence between the involved variables.
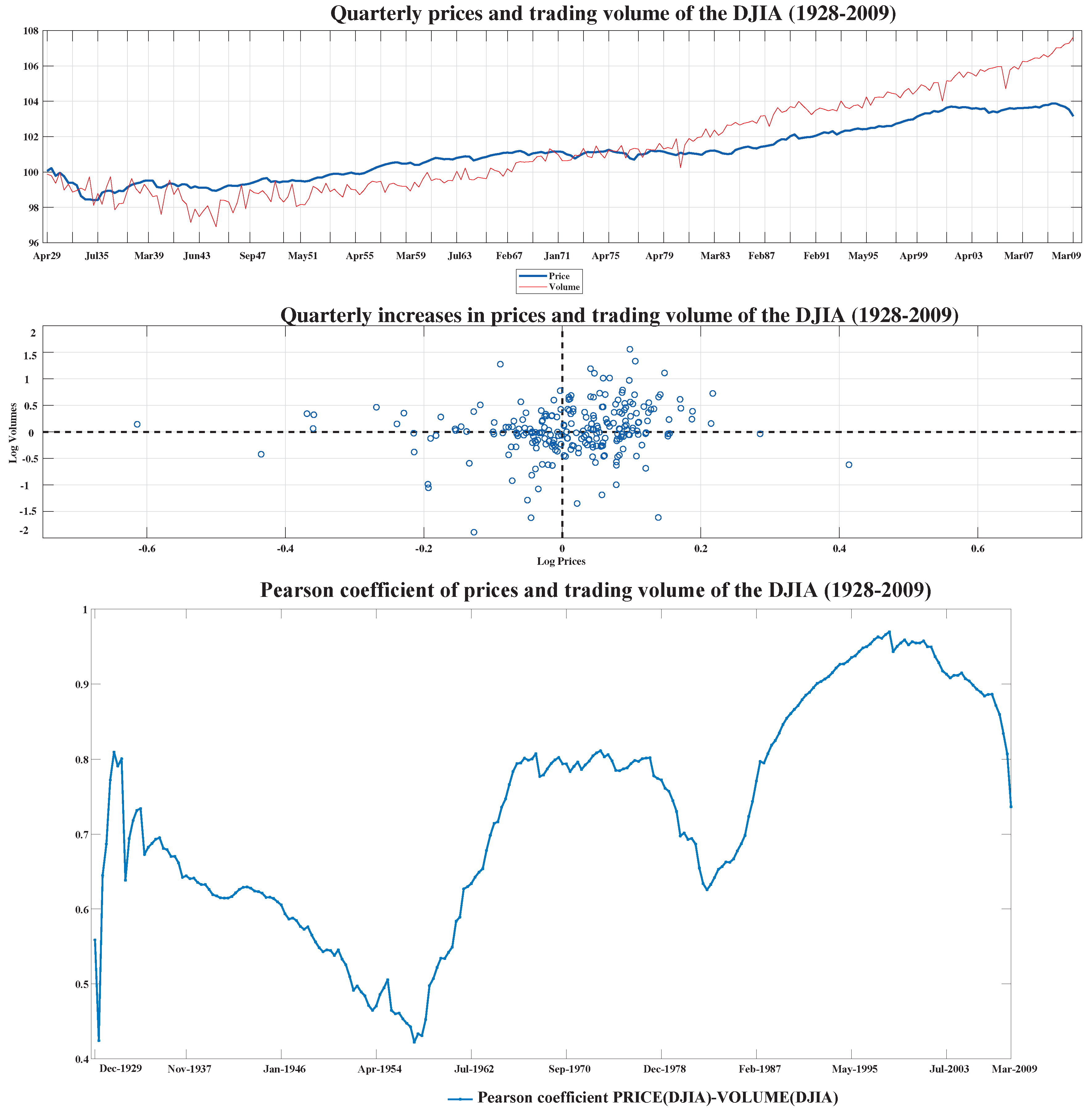
Figure 1 shows the huge level of dispersion and variability of both variables. The first two subfigures, elaborated according to Patton [
29], exhibit a normalized time series plot of price (DJIA)–volume (DJIA) as well as a scatter plot of log-increments, both series normalized in base 100, according to the equality
. The third subfigure represents the Pearson regression coefficient of per se prices and volumes of the DJIA over the analyzed time horizon, showing a quasicyclical relationship between prices and transactional volume within this index, which a priori do not appear to be connected with the evolution of the economic cycle. Several phases or trends can be distinguished: relative decline (1934–1957, 1979–1984, and 2000 onwards), stabilization (1967–1977), and increase (1929–1933, 1958–1966, and 1985–1999) in the relationship between the variables in terms of Pearson’s linear correlation coefficient (
).
Considering per se magnitudes,
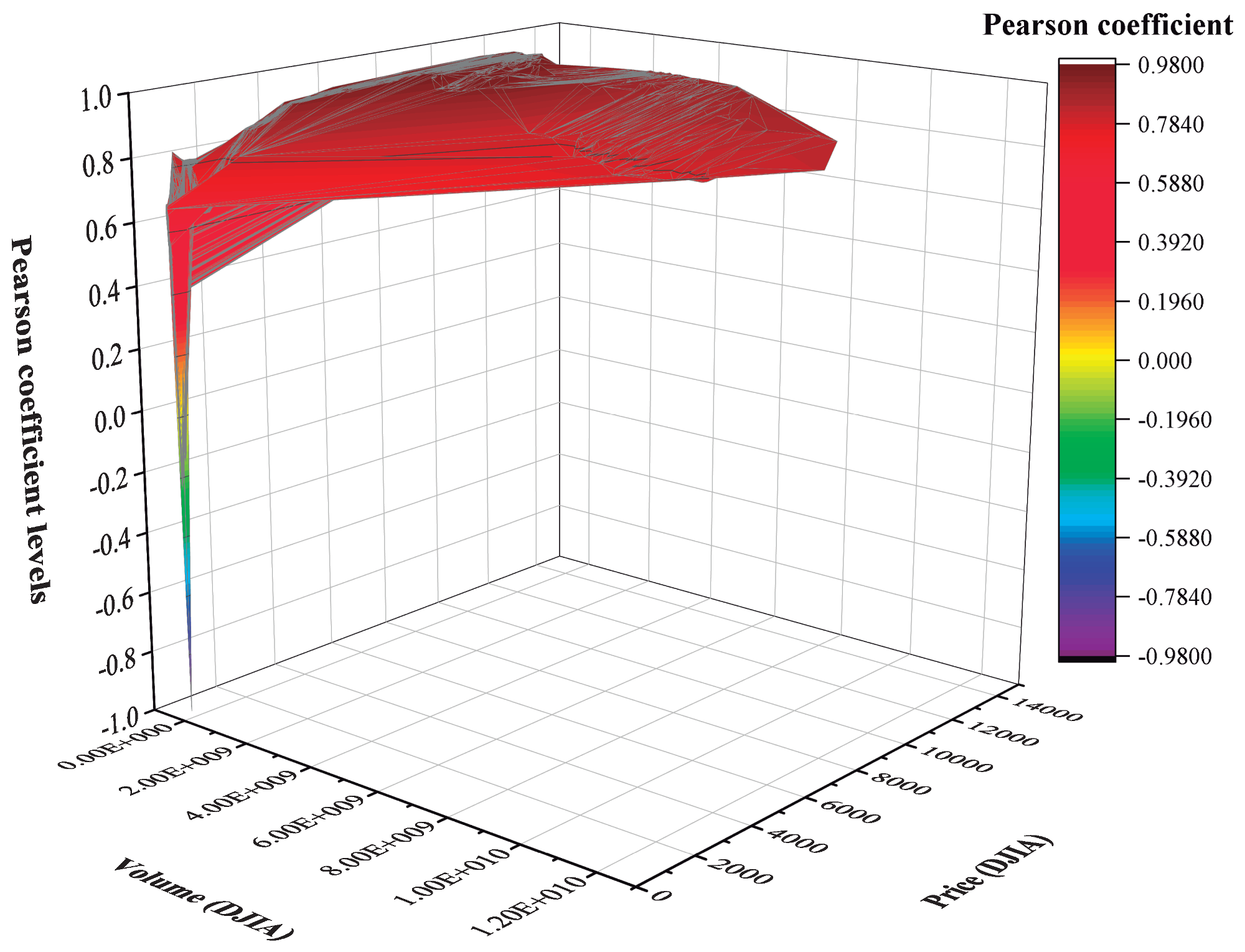
Figure 2 presents a three-dimensional scatter plot of the DJIA index that links variables
X (volume) and
Y (price) to the Pearson linear correlation coefficient (
Z =
). Simply, it can be observed that this chart mostly associates the highest correlation levels of
P and
V to high per se values of
P. Low trading volume per se usually fluctuates within a range from 5.00 × 10
to 15.00 × 10
, although sometimes a relatively high degree of correlation between price and low trading volume can be detected (close to 5.00 × 10
).
The aim of this paper is to highlight the key aspects of the SRA as an optimal methodological approach for the analysis of the PVR from an empirical perspective that is completely different from the rest of the predominant lines of research. In summary, this methodology can be characterized by: (1) the use of a high number of bivariate copulas (26, see
Table 2), especially recommended to simultaneously represent different dependence structures and to conduct prospective inferences based on the chosen variables (not necessarily related to hydrology), such as the variables price and trading volume of a given financial asset or stock index. Notably, to the best of our knowledge, the large number of copulas jointly implemented in the SRA was employed for the first time in the investigation of the PVR. (2) This methodology is based on a unitary reference framework (Bayesian analysis, see
Appendix A) in which the hybrid evolution algorithm of the Monte Carlo Markov Chain simulation (MCMCS) was introduced, focusing on the numerical estimation of the subsequent distribution of copula parameters within a context of uncertainty that is relatively similar to the uncertainty observable in financial markets, especially when the different volatility ranges can be conveniently delimited.
As stated by Johannes and Polson [
114], the key aspect of the MCMCS is its ability to easily characterize the complete conditional distributions,
and
, instead of analyzing the higher-dimensional joint distribution
. The SRA belongs to the class of econometric methods usually applied to the sampling of high-dimensional complex distributions, which implement a hybrid-evolution MCMCS algorithm to infer posterior parameter regions within a Bayesian context. This algorithm is considered a hybrid since it includes a combination of Gibbs steps and Metropolis–Hastings steps [
114].
The hybrid-evolution MCMCS algorithm starts with an intelligent starting point selection, structured according to the use of adaptive metropolis (AM), differential evolution (DE), and snooker update.
Table 3 summarizes, in descending order, the working schema implemented in the algorithm developed by Sadegh et al. [
8]. For the sake of brevity, intermediate iterative conditions (i.e., end do, end if, etc.) have been omitted from the table.
4. Results
Despite the SRA employing a good number of new generation copulas, with some of them complex in mathematical terms (i.e., Plackett or Shih-Louis),
Table 4 shows that two copulas with a not very analytically complex, Li et al. [
102] and Frees and Valdez [
50] best fit the price–volume time series of the DJIA during the considered period (1928–2009), emphasizing that, in all cases, the specified selection criteria coincide except for three copulas: Galambos, BB1, and BB5.
Complementarily,
Table 5 provides estimations of the parameters of each copula (Par) by fixing a range of 95% of uncertainty in their estimation (Unc-Range) through the application of local optimization and MCMCS. The copulas with best performance (Rank) are defined in terms of the root mean square error (RMSE) and the Nash–Sutcliff Efficiency (NSE) criteria. At this point, the existing literature usually employs local optimization algorithms when estimating the parameters of copulas with the consequent risk of being trapped in local optima, thus often obtaining unbiased and nonsignificant results [
8]. Conversely, the hybrid-evolution MCMCS algorithm used in the SRA overcomes this initial limitation by determining an efficient estimator of the global optimum as well as an accurate approximation of uncertainties in the content of a Bayesian conceptual framework in the form of isolines, which is another of the improvements provided by this methodology to PVR analysis.
The analysis of the SRA applied to the NIKKEI225, FTSE100, and IBEX35 indices using the Tawn’s copula is summarized in
Table 6, similarly to
Table 5. The price–volume dependence structure of the per se NIKKEI225 index is optimal in accordance with the NSE criterion, as it is very close to unity (0.9914), indicating an almost perfect model fitting. The per se IBEX35 adjustment is relatively optimal (0.9737), being lower for the FTSE100 (0.8235). The range of uncertainty of the parameters defining the Tawn’s copula (
,
, and
,
Table 2) is considerably lower in the Nippon index than in the other two stock market indices.
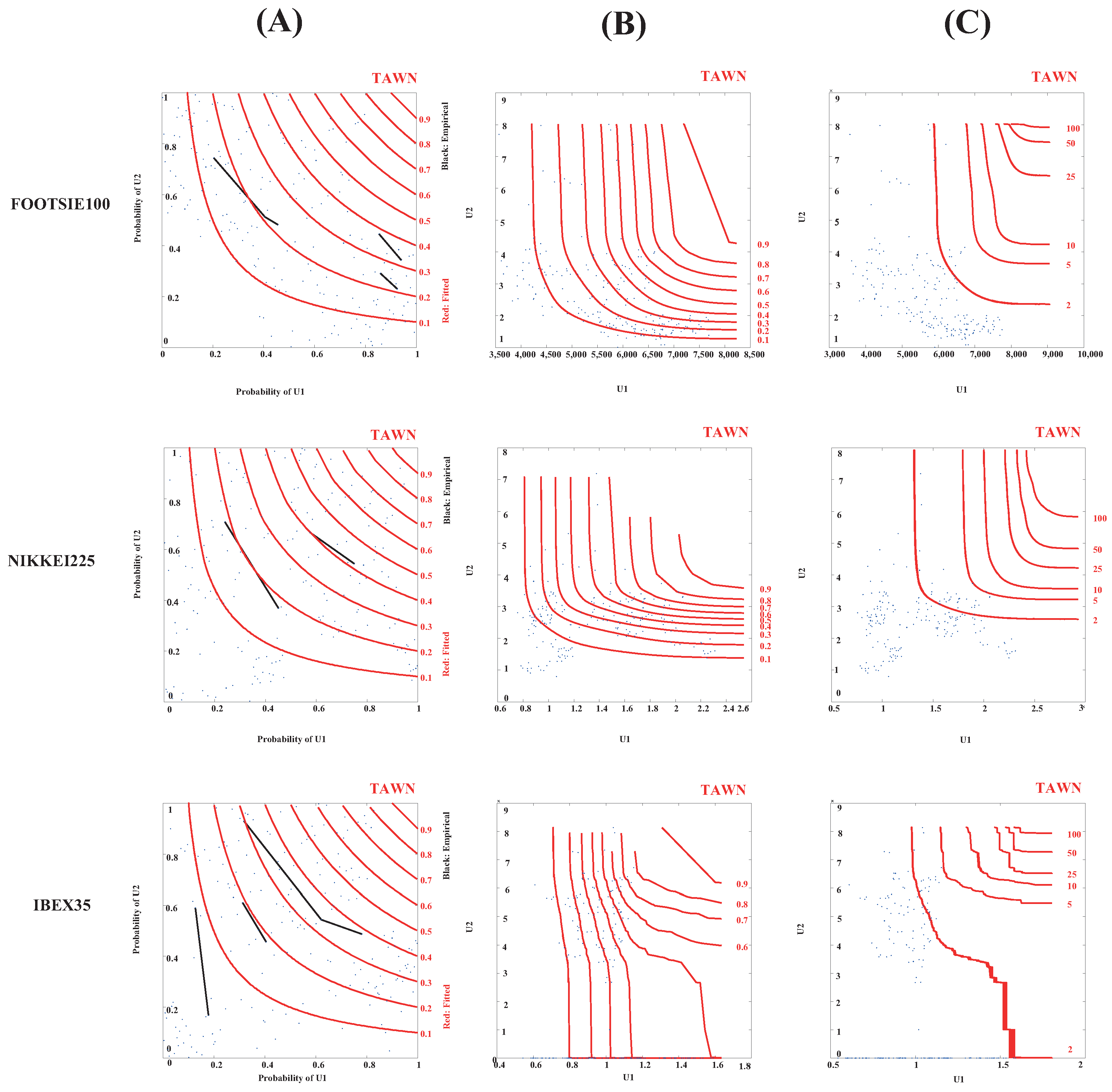
Figure 3 shows that each stock exchange index corresponds to a certain typology of its probability isolines. Rows 1 to 3 refer to the analyzed indices, whereas columns correspond to the following specifications: (A) fitted empirical copulas probabilities, (B) fitted empirical copulas, and (C) return period copulas, calculated according to [
115] by considering the joint return
as a measure of the dependence structure between the observed price peaks and trading volumes.
The isolines derived from the application of Tawn’s copula are ostensibly biased toward the upper left corner, which seems to indicate a low probability of occurrence of the price () synchronously linked to a high probability of occurrence of the trading volume () (both measured in magnitudes per se). Likewise, given the joint representation of the probability isolines and the empirical estimates of the joint probability distributions, the trends of the FOOTSIE100 and NIKKEI225 indices are fairly similar, although in the former index, high prices use to be related to trading volumes lower than those shown in the Japanese stock market. The P—V relationship in the IBEX35, although following a similar pattern, differs to some extent from the analysis of the other two indices, as low prices seem to be more related to high trading volumes quotas. This type of asymmetric and skewed dependence structure can be considered a common pattern of the three indices analyzed, equally extrapolated to the analysis of the fitted empirical copulas and return period copulas.
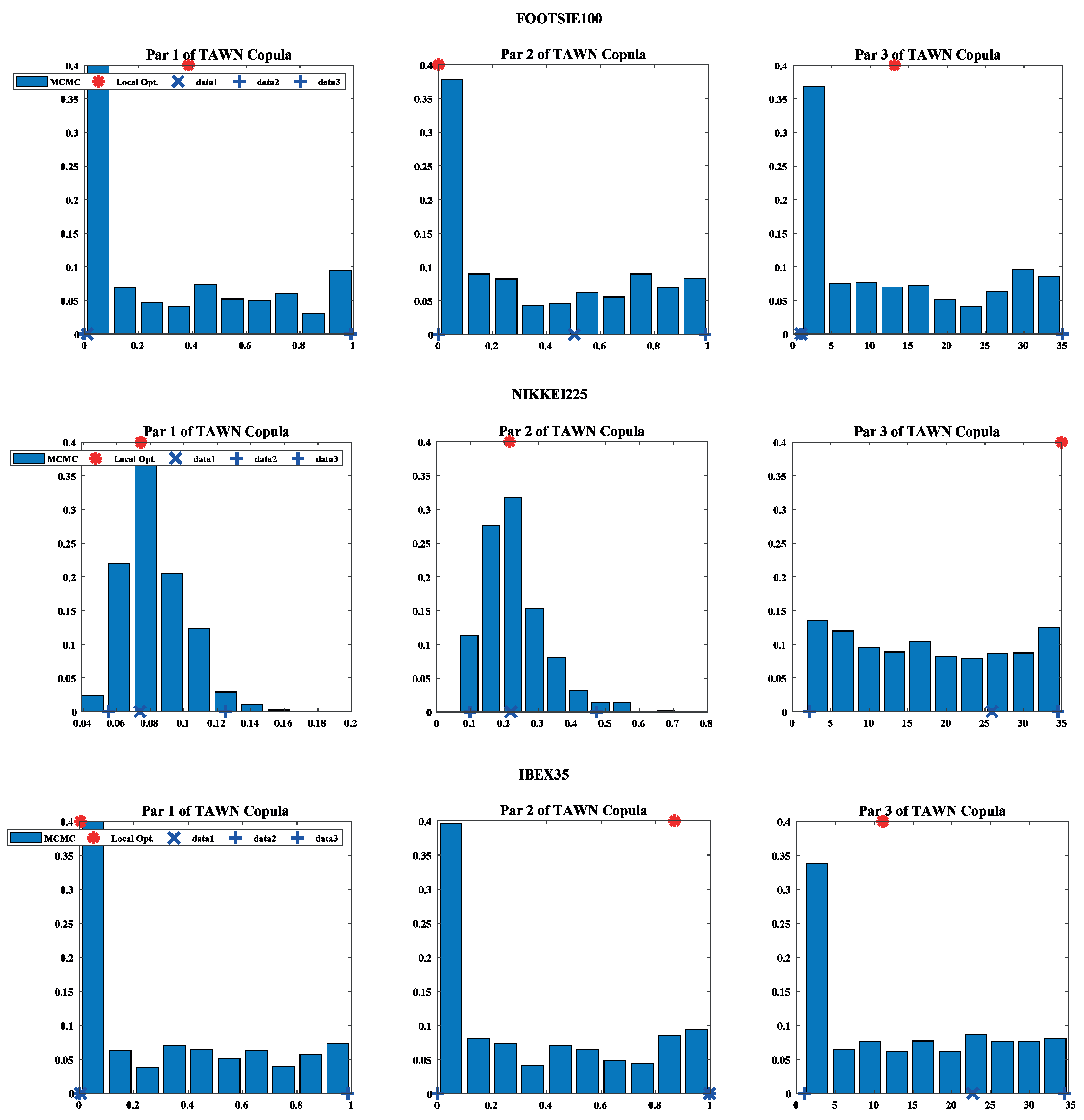
Figure 4 shows the degree of uncertainty associated with the three parameters defining the Tawn’s copula.
Figure 4 exhibits the specification of the copula parameters generated by the MCMCS through a Bayesian framework. Blue bins represent the MCMC-obtained parameters, blue crosses (bottom of each plot) denote the maximum likelihood estimation parameters, and red asterisks (top of each plot) indicate the copula parameter value obtained by local optimization.
In a context characterized by minimal uncertainty when specifying the parameters of the copula in each market, the parameters obtained by the local optimization algorithm should coincide with the mode of the distribution calculated through the MCMCS. However, this was only observed in the NIKKEI225 (parameters 1 and 2) and IBEX35 (parameter 1) and was not contrastable for any of the three parameters obtained from the Tawn’s copula to the FOOTSIE100 index. These results are consistent with the previously calculated uncertainty ranges and with the delimitation of the degree of goodness of the adjustment performed by the NSE criteria (
Table 6), according to which the NIKKEI225 index represented a quasiperfect fitting to this copula, followed by the IBEX35, and, to a lesser extent, the FOOTSIE100. This can be justified by the different range of variation of the parameters obtained for each index, where the FOOTSIE100 index is associated with a higher level of uncertainty compared with NIKKEI225 and IBEX35.
5. Discussion
The application of the SRA provides an alternative and innovative approach to PVR based on the simultaneous application of 26 copulas, which facilitated the analysis of their dependence structures and implicit morphology according with their probability isolines. Many of these copulas are dissimilar in form, although quite similar in performance. This also allowed us to model the relationship between prices and trading volumes from different points of view, quantifying the uncertainty underlying to the specification of the parameters defining each copula. The PVR, usually characterized by a markedly asymmetric relationship [
13], is reinforced by the application of the SRA, since several of the copulas used in this methodology (e.g., Galambos, Bernstein, Tawn, etheory of copulas.) are especially effective in the study of phenomena with underlaying asymmetric skewed dependence structures.
From an empirical point of view, the joint implementation of the 26 copulas in the DJIA (generic scenario) confirmed that Joe’s copula is able to more efficiently model the dependence structures of this index. Framing our findings with the existing literature, the use of Tawn’s copula in the FOOTSIE100, NIKKEI225, and IBEX35 indices (specific scenario) confirms Ying [
68]’s findings in their seminal analysis of the S&P 500 index. Similarly, our results confirm the analysis of the NIKKEI225 completed by Bremer and Kato [
116], according to which an asymmetric relationship could be observed (negative correlation between past prices and current trading volume). This relationship was explained in the FOOTSIE100 by Huang and Masulis [
117] based on the existence of a minority of informed-trading investors who simply sought immediate liquidity. The asymmetric PVR detected in the IBEX35 aligns with that already reported in the literature (see, for example, [
118]). Its differentiated nature with respect to the other two indices is probably due to, according to [
119] in the Spanish financial markets (Mercado Continuo), a strong linear causal relationship from returns to trading volume. Specifically, periods with high returns are usually followed by periods with particularly high trading volume. Such guidelines are comparable to those detected in other works [
95,
97], which explicitly used copulas in the study of PVR in the Asian financial markets, repeatedly verifying the existence of an inverse relationship between prices and volumes traded, in both cases foreseeably increased by the effects of the 1997 Asian financial crisis.
One of the improvements associated with the application of the SAR approach to the PVR is facilitating the analysis of both variables from a large number of copulas by defining the relationship based on ranges of uncertainty applying the RMSE and NSE criteria (see
Table 5 and
Table 6), independent of the degree or sign of the linear correlation exhibited by the Pearson correlation coefficient (
), which, to the best of our knowledge, is an entirely new application in the field of quantitative finance of future utility for researchers and investors.
6. Conclusions
The main contribution of this research is the analysis of the existing relationship between prices and trading volume from multiple copulas, which allowed us to comparatively abstract the underlying dependency structures of both variables to establish possible analogies or differences. One of the most important limitations related to the empirical application of copulas is solved, which is employing a limited number of standard copulas when, in reality, there are multiple copulas not yet well extended in the literature [
11]. Through the empirical methodology introduced in this article, the versatility of copulas increases when they are simultaneously combined with the polyvalence of the Bayesian analysis and with the hybrid-evolution MCMCS algorithm proposed by Sadegh et al. [
8]. We are the first to implement the SRA, not just in PVR analysis, but in the ambit of quantitative finance. More specifically, for practical purposes, PVR analysis is decisive for both academics and practitioners, since, following the scheme constructed by Karpoff [
13], it has the following implications: (1) it generates additional information regarding the structure of financial markets; (2) from an empirical point of view, it is fundamental in the generation of case studies that jointly use prices and trading volume, facilitating the implementation of analyses and inferences; (3) it is a crucial element in the study of the empirical distribution of speculative prices; and (4) its research would be particularly indicated in the futures markets where, a priori, the variability of prices used to affect the trading volume.
Additionally, we tried to answer and reconcile three questions linked to the theory of copulas: which copula is the “right one” [
120], which copula should be used [
20], and why copulas have been successful in many practical applications [
44]? Versatility is the key term that best defines a copula; therefore, the most appropriate copula for analyzing a particular issue is the one that best summarizes its implicit dependence structures. Hence, copulas have been so successful in different fields of study.
A first conclusion to be drawn from this work is that the potential of the theory of copulas could be significantly reduced if certain copulas-type are systematically used in the analysis of bivariate time series. Precisely, this was the factor that caused a certain reluctance toward the use of copulas when the Gaussian copula [
10] was employed massively in almost any scientific field, without considering either the intrinsic nature of the phenomena analyzed or that the use of a large number of copulas can substantially improve the knowledge of the different relations of dependence observable in a given dataset [
50]. Thus, the SRA is not simply limited to the task of choosing and fitting the copula [
121], but following the transdisciplinary perspective of econophysics, it supposes a new framework in the analysis of the PVR, extrapolated from the field of hydrology, which is directly applicable to many other areas such as quantitative finance.
Since Karpoff [
13], the PVR has been practically subsumed to the generalization of the significance of Pearson’s linear correlation coefficient of the price and trading volume variables. However, an alternative is provided in this methodology since the classical optimization methods applied to copulas often get trapped in local minima. The SRA is able to conveniently overcome this limitation by accurately describing the dependence structure of variables
P and
V and, importantly, by allowing the analysis of uncertainties given a determined time horizon (or length of record, see [
8]). Another contribution of this work that may be important for future lines of research is the incorporation in the methodology of copula probability isolines in the analysis of PVR, which approximates this research to the multifractal models of Mandelbrot [
22].
In our opinion, other future lines of research related to this work include, for example, the analysis of the role played by floating capital (outstanding shares vs. restricted shares) in the context of PVR, an aspect which has been often overlooked in the literature, or the rigorous enunciation and detailed compilation of those empirical stylized facts defining the price–volume time series, as well as the definitive consolidation of the works that have analyzed PVR from the perspective of the market microstructure of Garman [
122]. This research could be gradually applied to the area of behavioral finance following the path of works such as Gomes [
123], in which the analysis of PVR is directly connected to the prospective theory of Kahneman and Tversky [
124].

 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}