Optimal Sliced Latin Hypercube Designs with Slices of Arbitrary Run Sizes

Abstract
:1. Introduction
2. Construction of SLHDs with Slices of Arbitrary Run Sizes
- Step 1.
- Let for , and .
- Step 2.
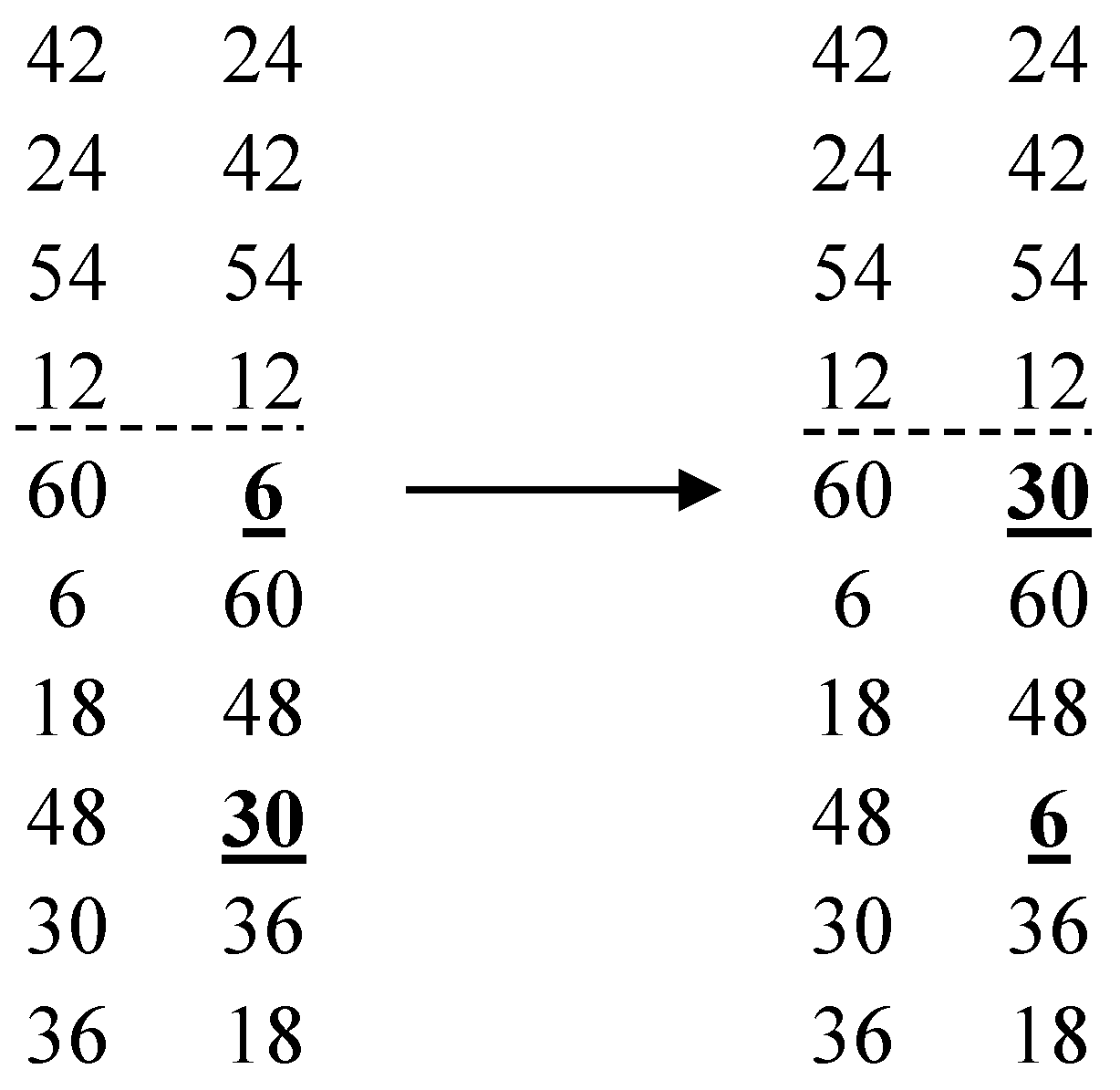
- For , let and calculateIf , for , let l denote the kth smallest integer of the set and add r to and let . Let and go to the next j.
- Step 3.
- For , generate a vector by randomly permuting .
- Step 4.
- For , calculate , where . Combine to obtain an n-dimensional column vector , then let be constructed bywhere . Combine to obtain an n-dimensional column vector , and is one column of the design.
- Step 1.
- .
- Step 2.
- Calculate . For , then , since , we obtain . For , , , only an integer satisfies , and min, min. Hence, we add to , , and . For , , , only an integer satisfies , and min, min. Therefore, we add to , , and . After passing all j, we can get , , , and .
- Step 3.
- We get , , and by randomly permuting , , and .
- Step 4.
- We obtain , , and . Then, is constructed through , where , , and . Thus, we obtain an arbitrary column of the design.
3. Optimal SLHDs with Slices of Arbitrary Run Sizes
3.1. A Combined Space-Filling Measurement for FSLHDs
3.2. Exchange Procedures for FSLHDs
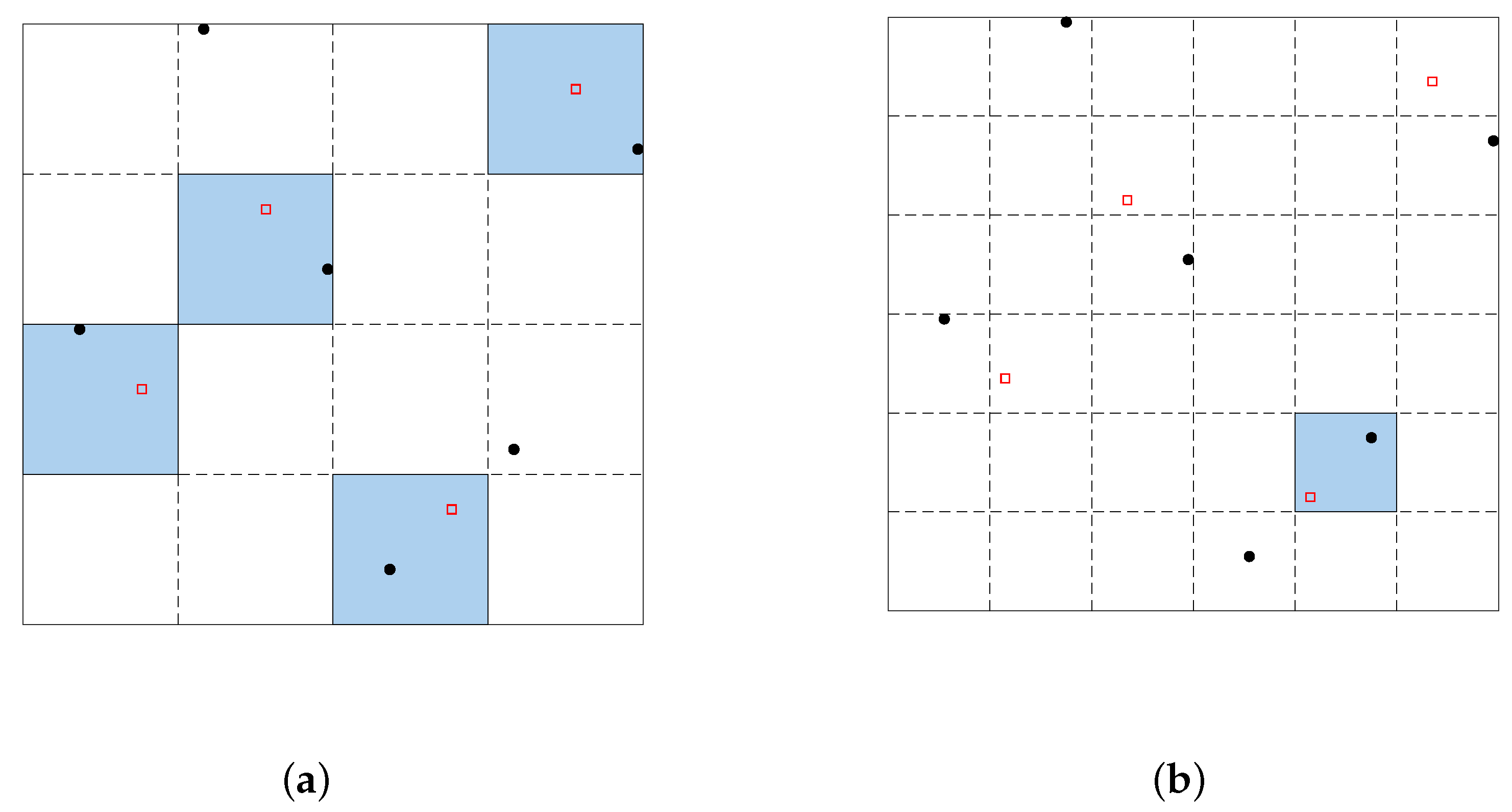
3.2.1. The Within-Slice Exchange Procedure
- Step 1.
- Randomly select a column of .
- Step 2.
- Select any two different elements in ith slice of the column, where .
- Step 3.
- Exchange and in the same slice.
- Step 4.
- Generate .
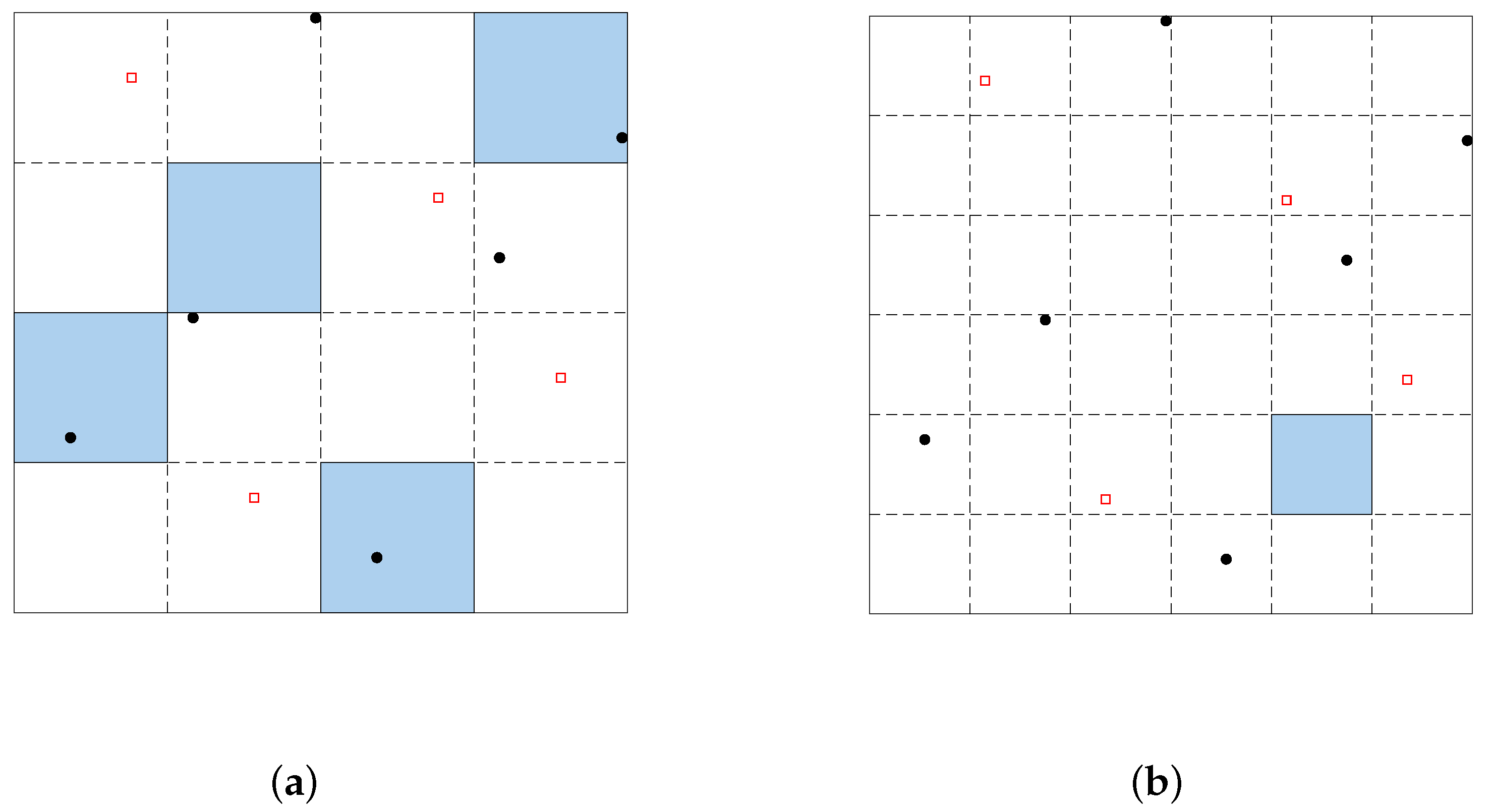
3.2.2. The Different-Slice Exchange and the Out-Slice Exchange Procedures
- Step 1.
- Randomly select an element b in .
- Step 2.
- Generate a set .
- Step 3.
- If , go to Step 4; else, go to Step 5.
- Step 4.
- For k from 1 to , if belongs to , go to Step 5; else, go to Step 6.
- Step 5.
- Generate by exchanging b with . If still satisfies Theorem 1(ii), go to Step 7.
- Step 6.
- Generate by exchanging b with . If still satisfies Theorem 1(i), go to Step 7.
- Step 7.
- Add to .
3.3. A Sliced ESE Algorithm for Generating Optimal FSLHDs
| Algorithm 1: The SESE algorithm. |
 |
3.4. Efficient Two-Part Algorithm for Generating Space-Filling FSLHDs
- Step 1.
- Let , and set the index .
- Step 2.
- If , compute , go to Step 5.
- Step 3.
- If , randomly choose a repeating row of , and randomly choose another row in the same slice. We exchange two elements which correspond to a randomly selected column of the two rows. Generate an ; else, go to Step 5.
- Step 4.
- If , , go back to Step 2; else, go back to Step 3.
- Step 5.
- Under the condition of , generate an by the within-slice procedure in the ith slice of , then calculate .
- Step 6.
- If , then replace by ; else, go back to Step 3.
- Step 7.
- Repeat Step 4 and Step 5 until meeting the stopping criterion.
- Step 8.
- Update , if , go to Step 2; else, output = .
- Step 1.
- Let , and set the index .
- Step 2.
- In the ith slice of , generate an by the different-slice or the out-slice exchange procedures under the condition of .
- Step 3.
- If , replace by .
- Step 4.
- Repeat Step 2 and Step 3 until meeting the stopping criterion.
- Step 5.
- Update , if , go to Step 2; else, output = .
4. Simulation Results
4.1. Example 1
4.2. Example 2
- (i)
- The average time of the operation shows that the two-part algorithm has higher efficiency than the SESE algorithm.
- (ii)
- For FSLHD, since with , the values of the resulting FSLHD from Part-I algorithm are desirable when compared with those values from the two-part algorithm. However, the results of Part-I algorithm for FSLHD are not good enough. Therefore, if q is large and , we need not to run the Part-II algorithm.
- (iii)
- Based on the values of the resulting FSLHDs, we can see that the values are close to each other. It can be concluded that both the two-part algorithm and the SESE algorithm are stable and do not heavily rely on the initial design.
5. Discussion of the Methods for Evaluating the Combined Space-Filling Measurement
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- McKay, M.D.; Beckman, R.J.; Conover, W.J. A Comparison of Three Methods for Selecting Values of Input Variables in the Analysis of Output from a Computer Code. Technometrics 1979, 21, 381–402. [Google Scholar]
- Qian, P.Z.G. Sliced Latin Hypercube Designs. J. Am. Stat. Assoc. 2012, 107, 393–399. [Google Scholar] [CrossRef]
- He, X.; Qian, P.Z. A central limit theorem for nested or sliced Latin hypercube designs. Stat. Sin. 2016, 26, 1117–1128. [Google Scholar]
- Qian, P.Z.G.; Wu, H.; Wu, C.F.J. Gaussian Process Models for Computer Experiments with Qualitative and Quantitative Factors. Technometrics 2008, 50, 383–396. [Google Scholar] [CrossRef]
- Gang, H.; Santner, T.J.; Notz, W.I.; Bartel, D.L. Prediction for Computer Experiments Having Quantitative and Qualitative Input Variables. Technometrics 2009, 51, 278–288. [Google Scholar]
- Deng, X.; Lin, C.D.; Liu, K.W.; Rowe, R.K. Additive Gaussian Process for Computer Models with Qualitative and Quantitative Factors. Technometrics 2017, 59, 283–292. [Google Scholar] [CrossRef]
- Hwang, Y.; He, X.; Qian, P.Z. Sliced orthogonal array-based Latin hypercube designs. Technometrics 2016, 58, 50–61. [Google Scholar] [CrossRef]
- Yin, Y.; Lin, D.K.; Liu, M.Q. Sliced Latin hypercube designs via orthogonal arrays. J. Stat. Plan. Inference 2014, 149, 162–171. [Google Scholar] [CrossRef]
- Xie, H.; Xiong, S.; Qian, P.Z.; Wu, C.J. General sliced Latin hypercube designs. Stat. Sin. 2014, 24, 1239–1256. [Google Scholar] [CrossRef]
- Yang, J.; Chen, H.; Lin, D.K.; Liu, M.Q. Construction of sliced maximin-orthogonal Latin hypercube designs. Stat. Sin. 2016, 26, 589–603. [Google Scholar] [CrossRef]
- Huang, H.; Lin, D.K.; Liu, M.Q.; Yang, J.F. Computer experiments with both qualitative and quantitative variables. Technometrics 2016, 58, 495–507. [Google Scholar] [CrossRef]
- Kennedy, M.C.; O’Hagan, A. Predicting the Output from a Complex Computer Code When Fast Approximations Are Available. Biometrika 2000, 87, 1–13. [Google Scholar] [CrossRef]
- Qian, Z.; Seepersad, C.C.; Joseph, V.R.; Allen, J.K.; Wu, C.F.J. Building surrogate models based on detailed and approximate simulations. J. Mech. Des. 2006, 128, 668. [Google Scholar] [CrossRef]
- Ba, S.; Myers, W.R.; Brenneman, W.A. Optimal Sliced Latin Hypercube Designs. Technometrics 2015, 57, 479–487. [Google Scholar] [CrossRef]
- Chen, H.; Huang, H.; Lin, D.K.; Liu, M.Q. Uniform sliced Latin hypercube designs. Appl. Stoch. Model. Bus. Ind. 2016, 32, 574–584. [Google Scholar] [CrossRef]
- Kong, X.; Ai, M.; Tsui, K.L. Flexible sliced designs for computer experiments. Ann. Inst. Stat. Math. 2018, 70, 631–646. [Google Scholar] [CrossRef]
- Xu, J.; He, X.; Duan, X.; Wang, Z. Sliced Latin Hypercube Designs for Computer Experiments with Unequal Batch Sizes. IEEE Access 2018, 6, 60396–60402. [Google Scholar] [CrossRef]
- Zhang, J.; Xu, J.; Wang, Z. A flexible construction for sliced Latin hypercube designs. J. Phys. Conf. Ser. 2019, 1168, 022005. [Google Scholar] [CrossRef]
- Xu, J.; He, X.; Duan, X.; Wang, Z. Sliced Latin hypercube designs with arbitrary run sizes. arXiv 2019, arXiv:1905.02721. [Google Scholar]
- Johnson, M.E.; Moore, L.M.; Ylvisaker, D. Minimax and maximin distance designs. J. Stat. Plan. Inference 1990, 26, 131–148. [Google Scholar] [CrossRef]
- Grosso, A.; Jamali, A.R.M.J.U.; Locatelli, M. Finding maximin latin hypercube designs by Iterated Local Search heuristics. Eur. J. Oper. Res. 2009, 197, 541–547. [Google Scholar] [CrossRef]
- Dam, E.R.; Husslage, B.; Hertog, D.D.; Melissen, H. Maximin Latin Hypercube Designs in Two Dimensions. Oper. Res. 2007, 55, 158–169. [Google Scholar] [Green Version]
- Dam, E.R.V.; Rennen, G.; Husslage, B.G.M. Bounds for Maximin Latin Hypercube Designs. Oper. Res. 2009, 57, 595–608. [Google Scholar] [Green Version]
- Jin, R.; Chen, W.; Sudjianto, A. An efficient algorithm for constructing optimal design of computer experiments. J. Stat. Plan. Inference 2016, 134, 268–287. [Google Scholar] [CrossRef]
- Morris, M.D.; Mitchell, T.J. Exploratory designs for computational experiments. J. Stat. Plan. Inference 1995, 43, 381–402. [Google Scholar] [CrossRef] [Green Version]
- Ye, K.Q.; Li, W.; Sudjianto, A. Algorithmic construction of optimal symmetric Latin hypercube designs. J. Stat. Plan. Inference 2000, 90, 145–159. [Google Scholar] [CrossRef]
- Viana, F.A.C.; Venter, G.; Balabanov, V. An algorithm for fast optimal Latin hypercube design of experiments. Int. J. Numer. Methods Eng. 2010, 82, 135–156. [Google Scholar] [CrossRef]
- Hickernell, F. A generalized discrepancy and quadrature error bound. Math. Comput. 1998, 67, 299–322. [Google Scholar] [CrossRef] [Green Version]
- Fang, K.T.; Ma, C.X.; Winker, P. Centered L2Discrepancy of Random Sampling and Latin Hypercube Design, and Construction of Uniform Designs. Math. Comput. 2002, 71, 275–296. [Google Scholar] [CrossRef]
- Chen, R.B.; Hsieh, D.N.; Ying, H.; Wang, W. Optimizing Latin hypercube designs by particle swarm. Stat. Comput. 2013, 23, 663–676. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95—International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; pp. 1942–1948. [Google Scholar]
- Liefvendahl, M.; Stocki, R. A study on algorithms for optimization of Latin hypercubes. J. Stat. Plan. Inference 2006, 136, 3231–3247. [Google Scholar] [CrossRef] [Green Version]
- Bates, S.; Sienz, J.; Toropov, V. Formulation of the optimal Latin hypercube design of experiments using a permutation genetic algorithm. In Proceedings of the 45th AIAA/ASME/ASCE/AHS/ASC Structures, Structural Dynamics & Materials Conference, Palm Springs, CA, USA, 19–22 April 2004; pp. 1–7. [Google Scholar]
- Chen, D.; Xiong, S. Flexible Nested Latin Hypercube Designs for Computer Experiments. J. Qual. Technol. A Q. J. Methods Appl. Relat. Top. 2017, 49, 337–353. [Google Scholar] [CrossRef]
- Yang, J.F.; Lin, C.D.; Qian, P.Z.; Lin, D.K. Construction of sliced orthogonal Latin hypercube designs. Stat. Sin. 2013, 23, 7–1130. [Google Scholar] [CrossRef]
- Huang, H.; Yang, J.F.; Liu, M.Q. Construction of sliced (nearly) orthogonal Latin hypercube designs. J. Complex. 2014, 30, 355–365. [Google Scholar] [CrossRef]
- Cao, R.Y.; Liu, M.Q. Construction of second-order orthogonal sliced Latin hypercube designs. J. Complex. 2015, 31, 762–772. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Design | Min | Mean | Max | Standard Deviation | Average Time |
|---|---|---|---|---|---|---|
| SESE | FSLHD | 7.8943 | 8.2941 | 8.7239 | 0.0199 | 94 s |
| Part-I | FSLHD | 9.0673 | 10.4267 | 14.2223 | 0.5904 | 3 s |
| Part-I + Part-II | FSLHD | 8.3720 | 9.1520 | 11.4659 | 0.1421 | 5 s |
| SESE | FSLHD | 1.8803 | 2.0923 | 2.5968 | 0.0082 | 249 s |
| Part-I | FSLHD | 1.9747 | 2.2325 | 2.7115 | 0.0124 | 13 s |
| Part-I + Part-II | FSLHD | 1.8945 | 2.0347 | 2.2390 | 0.0030 | 18 s |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Xu, J.; Jia, K.; Yin, Y.; Wang, Z. Optimal Sliced Latin Hypercube Designs with Slices of Arbitrary Run Sizes. Mathematics 2019, 7, 854. https://doi.org/10.3390/math7090854
Zhang J, Xu J, Jia K, Yin Y, Wang Z. Optimal Sliced Latin Hypercube Designs with Slices of Arbitrary Run Sizes. Mathematics. 2019; 7(9):854. https://doi.org/10.3390/math7090854
Chicago/Turabian StyleZhang, Jing, Jin Xu, Kai Jia, Yimin Yin, and Zhengming Wang. 2019. "Optimal Sliced Latin Hypercube Designs with Slices of Arbitrary Run Sizes" Mathematics 7, no. 9: 854. https://doi.org/10.3390/math7090854