1. Introduction
To capture the geometry of arbitrary objects as completely as possible, nowadays in engineering geodesy areal (area-wise, in contrast to point-wise) measurement methods are applied. Examples are terrestrial laser scanning or photogrammetric approaches based on the evaluation of image data. However, the resulting point cloud is almost never used as a final result since the creation of Computer-aided Design (CAD) models or deformation analyses require a curve or surface approximation by a continuous mathematical function. An overview of curve and surface approximations of three-dimensional (3D) point clouds, including polynomial curves, Bézier curves, B-Spline curves and NURBS curves, was presented by Bureick et al. [
1]. Ezhov et al. [
2] elaborated the basic methodology of spline approximation in two dimensions (2D) from a geodetic point of view using splines constructed from ordinary polynomials of the form
. In the resulting adjustment problem, the values
were introduced as observations subject to random errors and the values
as error-free values. This approach is relevant, for example, for the following applications:
Registration of a signal at certain time intervals, whereby the time measurement is much more precise than the measurement of the signal and can therefore be considered as error-free.
Acquisition of measurements at fixed sensor positions, e.g., measurement of vertical displacements with displacement transducers at fixed horizontal positions during a load test.
Regarding the values as error-free to generate a solution using a linear functional model. This can be justified when the interpretation of the error vectors (in contrast to deformation analysis) is not the primary aim, but point clouds are approximated to obtain results that primarily satisfy aesthetic requirements.
The fundamental concept and the statistical properties of geodetic measurements are explained e.g., by Mikhail [
3] (p. 3 ff.). In that textbook, on page 24, it is pointed out that in practical applications, normal distributions are encountered very often, since in geodesy random variables that represent measurements (respectively, their errors) are often nearly normally distributed. In this contribution we consider the case that both values
and
of spline functions of the form
are observations subject to random errors. An example for this case is the spline approximation in the field of deformation monitoring where the data were captured with a profile laser scanner.
If the dispersion matrix is a scalar multiple of the identity matrix, the observations
and
are equally weighted and uncorrelated and a parameter estimation using the method of least squares yields a result where the error vectors of each point are orthogonal to the computed spline approximation. This characteristic is of vital importance for the interpretation of the error vectors not only for the purpose of deformation analysis in engineering geodesy but in many other scientific fields. Hence, a vast literature has been created that discusses the general problem of “orthogonal distance fitting”. Elaborations of this topic are offered e.g., by Sourlier [
4], Turner [
5] and Ahn [
6].
In the contribution of Crambes [
7] the case of spline approximation with
and
as erroneous observations is regarded as errors-in-variables (EIV) model and a total least squares (TLS) solution is presented. A total least squares fitting of Bézier curves to ordered data with an extension to B-spline curves was proposed by Borges and Pastva [
8]. They developed an algorithm for applying the Gauss-Newton approach to this problem with a direct method for evaluating the Jacobian based on implicitly differentiating a pseudo-inverse. However, a dispersion matrix for the observations was not introduced.
Jazaeri et al. [
9] have presented a new algorithm for solving arbitrary weighted TLS problems within an EIV model having linear and quadratic constraints and singular dispersion matrices. They equivalently translate the weighted total least squares (WTLS) objective function under consideration of the constraints into the Lagrange target function of the constrained minima technique to derive an integrative solution. Fang [
10] presented a WTLS and constrained weighted total least squares (CWTLS) solution based on Newton iteration.
In this contribution, we follow the idea of Neitzel [
11] and present a total least squares spline approximation as a rigorous evaluation of an iteratively linearized Gauss-Helmert (GH) model taking into account additional constraints for the unknowns. This model has the advantage that it does not impose any restrictions on the form of the functional relationship between the quantities involved in the model. The functional model of 2D similarity transformation discussed by Neitzel [
11], e.g., yields a functional matrix that contains two columns that do not contain any random errors (“fixed” or “frozen” columns in the frame of TLS terminology) and two columns in which the same
- and
-values appear crosswise (one with reversed sign). In order to appropriately consider this structure of the functional matrix, special TLS algorithms must be applied, as presented by Mahboub [
12], Schaffrin et al. [
13] or Han et al. [
14], while this case can be solved in a standard way in the GH model. Furthermore, arbitrary and even singular dispersion matrices can be introduced into the GH model as shown by Schaffrin et al. [
15] and Neitzel and Schaffrin [
16]. Therefore, the iteratively linearized GH model can be regarded as a generalized approach for solving constrained weighted total least squares (CWTLS) problems.
The aim of this publication is not to investigate which algorithm is more efficient, but rather to show that the TLS spline approximation can be solved in the well-known GH model, which can be traced back to Helmert [
17] (p. 285 ff.), and to offer the algorithm which can be used for solving practical geodetic problems.
2. A Review of the Errors-in-Variables (EIV) Model
Using the function of a cubic polynomial as an example, a brief overview of the errors-in-variables (EIV) model with regular dispersion matrix is presented in the following. In the case of the EIV model with a singular dispersion matrix, please refer to the contribution of Schaffrin et al. [
15]. Ezhov et al. [
2] elaborated a spline function constructed from ordinary cubic polynomials
with additional constraints to impose continuity, smoothness and continuous curvature. Under consideration of the values
as observations subject to random errors
, values
as fixed (error-free) values and
as unknowns, the observation equations
are obtained. For a description of the constraint equations please refer to Ezhov et al. [
2]. The resulting adjustment problem can be expressed as
where
is the observation vector containing the values ,
the normally distributed random error vector associated with containing the values with expected value and dispersion matrix ,
the functional matrix containing the coefficients of the linear functional model,
the vector of adjusted unknowns containing the parameters ,
the vector with given constant values,
the functional matrix containing the coefficients of the linear constraints for the unknowns, refer to Ezhov et al. [
2] for details, and
the theoretical reference standard deviation.
With
being a non-singular matrix the corresponding weight matrix can be computed from
Introducing the vector
of Lagrange multipliers, the constrained minima technique can be applied which yields the objective function
compare with the textbook by Mikhail [
3] (p. 215). The solution can be obtained from a Gauss-Markov (GM) model with constraints, as shown in detail by Ezhov et al. [
2].
If we now consider both the values
and the values
as observations, we have to introduce not only errors
associated with the values
but also errors
associated with observations
and we obtain the condition equations
For a description of the additional constraint equations please refer to Ezhov et al. [
2]. Starting from (3) these condition equations can be expressed in a general form as a so-called errors-in-variables (EIV) model (in which some of the columns of the functional matrix
contain observations and are thus subject to random errors
) with constraints
The normally distributed random error vector associated with
and
containing the vectors
and
with expected value
and dispersion matrix
reads
where
is the random error matrix associated with containing the values , and
the vectorized form of .
From the non-singular dispersion matrix
, the weight matrix
can be computed, which leads to the objective function
The solution for this EIV model can be determined (amongst others) using the TLS approach, more precisely in this case the constrained weighted total-least squares (CWTLS) approach. The notion “total least squares” (TLS) was introduced by Golub and van Loan [
18] and very elegant solution algorithms based on singular value decomposition (SVD) were developed; see, e.g., the contributions by Golub and van Loan [
18], van Huffel and Vandewalle [
19] (p. 29 ff.) or Markovsky and van Huffel [
20].
However, a solution with SVD is only possible if the functional model of the adjustment problem is pseudo-linear and if it has a certain structure, yielding a functional matrix that does not contain fixed (error-free) columns or columns in which the same variables occur multiple times (e.g., crosswise). The problem discussed in this article does not belong to this class. A systematic approach for direct solutions of specific non-linear adjustment problems such as fitting of a straight line in 2D and 3D, fitting of a plane in 3D and 2D similarity transformation with all coordinates introduced as observations subject to random errors was elaborated from a geodetic point of view by Malissiovas et al. [
21].
Jazaeri et al. [
9] have presented a new flexible algorithm for solving the weighted TLS problem within an EIV model having linear and quadratic constraints and singular dispersion matrices. Their iterative algorithm is based on an equivalent translation of the objective function (13) subject to (9) and (10) into a Lagrange target function. The case of quadratic constraints occurs, e.g., when the 2D or 3D coordinate transformation is formulated for the most general case (affine transformation) and the cases of similarity or rigid transformation are imposed with the help of constraint equations, which was shown by Fang [
10]. Singular dispersion matrices are always associated with coordinates computed from a free network adjustment, as explained by Neitzel and Schaffrin [
16].
The term errors-in-variables (EIV) model was introduced in the literature on mathematics and statistics. It is used for regression models where measurement errors are taken into account for both, the dependent variables and the independent variables. For geodesists, this terminology is rather confusing, because whenever we introduce errors, they are inherently associated with the term observations and not with variables. A remark of this kind was also given by Fuller [
22], who explained: “The term errors in variables is used in econometrics, while the terms observation error or measurement error are common in other areas of statistical application.” Thus, it is immediately evident that an EIV model is just another formulation of a well-known adjustment problem. Therefore, we can rearrange the EIV model (8) and obtain an implicit form of the functional relation
which is an example of a functional relationship that leads to the adjustment of (nonlinear) condition equations with unknowns that can already be found in the classical textbook of Helmert [
17] (p. 285 ff.).
Neitzel [
11] showed using the example of unweighted and weighted 2D similarity transformation that the TLS solution within an EIV model can be obtained from a rigorous solution of an iteratively linearized Gauss-Helmert model. After the definition of a spline constructed from ordinary cubic polynomials in
Section 3 and the definition of the problem in
Section 4, we will follow this idea and show in
Section 5 how to derive the constrained weighted total-least squares (CWTLS) of an EIV model from a rigorous solution of an iteratively linearized Gauss-Helmert model with additional constraints for the unknowns. A numerical example will be presented in
Section 6 followed by conclusions and outlook in
Section 7.
3. Definition of a Spline Constructed from Ordinary Cubic Polynomials
For the definition of a spline constructed from ordinary cubic polynomials the elaboration from Ezhov et al. [
2] is presented in what follows. Considering a 2D Cartesian coordinate system,
Figure 1 illustrates a spline interpolation where the given knots are interpolated by a piecewise continuous spline consisting of polynomials which meet at these knots. The coordinates of the knots are denoted by
; hence,
is the index (ordinal number) of the knot and
the number of segments. Character
stands for “knot” and is not an index; hence,
means “
-value of the knot
”. Then the spline is given by the function
with the following properties:
is a piecewise cubic polynomial with knots at , , …, ,
is a linear polynomial for and ,
has two continuous derivatives everywhere,
for .
According to Schumaker [
23] (p. 7)
(see
Figure 1) defined as above, is in a way the best interpolating function. This is one of the reasons why the cubic spline is generally accepted as the most relevant of all splines.
Starting from the above mentioned properties a spline function can be defined as
where the expression for a cubic polynomial in each segment
can be written as
The property that the spline has to meet exactly the data at the given knots yields the conditions
The property that
has two continuous derivatives everywhere yields the constraints
From Equation (16) and
Figure 1 we see that there are
polynomial functions
and
knots. The cubic function depends on four parameters, and consequently, the spline
on
unknowns. From (17), we obtain
and from (18) and (19) we get
condition equations. This results in
condition equations to be solved for
unknowns and hence the equation system is underdetermined. To overcome this problem, arbitrary additional conditions can be introduced. Usually the missing constraints are introduced at the first and the last knot. For more details refer to Ezhov et al. [
2].
The main application of spline interpolation is the construction of curves through a sparse sequence of data points, e.g., in the construction of aesthetically pleasing curves in CAD models. The aim is different when modern sensors such as laser scanners are used with an acquisition rate of up to 2 million points per second, providing a very dense sequence of data points. Due to the high point density and the fact that measurements are affected by random errors, it is no longer appropriate to apply spline interpolation, since observation errors and other abrupt changes in the data points would be modeled, resulting in a strongly oscillating spline.
To avoid this effect, the point sequence is divided into not so many intervals using predefined knots. Due to the high point density, this results in an overdetermined configuration and the parameters of piecewise cubic splines can be determined using least squares adjustment. Conditions for smoothness at the knots (where two polynomials meet) can be introduced as constraint equations into the formulation of the adjustment problem. The result is a spline that no longer follows all data points exactly, but as closely as possible, subject to a predefined target function. In the case of least squares adjustment, this means that the sum of the weighted squared residuals becomes minimal. This case, illustrated in
Figure 2, is called spline approximation.
For formulating this approximation problem, cubic polynomials (16) are used for each interval of the spline. Furthermore, constraint equations for continuity (17), smoothness (18) and continuous curvature (19) are to be introduced at the knots. Both the values and the values are regarded as observations subject to random errors. An example for this case is the spline approximation in the field of deformation monitoring where the data were captured with a profile laser scanner.
In spline approximation, the parameters for an overdetermined configuration are determined by a least squares adjustment. In contrast to spline interpolation, a solution can be found by minimizing the sum of the weighted squared residuals without imposing any extra conditions to the first and last point of the spline. Only the already mentioned conditions for continuity, smoothness and continuous curvature have to be introduced at the “inner” knots as additional constraints. In the following section the resulting adjustment problem is defined.
4. Definition of the Problem
Let:
be pairs of observed values within an interval , where the sequence on the -axis is non-decreasing,
be the stochastic model and the corresponding weight matrix,
be a non-decreasing sequence of user-defined values for the knots on the
-axis which are regarded as error-free. As mentioned before, the first knot
and the last knot
, see
Figure 1, have no particular influence on the adjustment, they are just
and
. Therefore, when the positioning of the knots is discussed, we refer only to the knots
, see
Figure 2, on which some constraints are imposed. The positioning of the knots plays a key role in spline approximation problems. This problem is further discussed in
Section 5.4.
To determine:
, which represent a set of parameters for the cubic polynomials which has to be estimated for all intervals .
According to (16) the functional model for the cubic polynomials reads
with
as index for an interval
. Furthermore,
represents an index for all pairs of observed values within the interval
.
Since an overdetermined system of equations is considered, a spline approximation is performed without putting any extra conditions on the first and the last knots of the spline. The dataset is subdivided into intervals w.r.t. the
-axis by predefined knots. For each interval
there is a set of at least two pairs of values
inside of it. According to (17)–(19) the conditions
are imposed on the knots for constructing a spline. These knots
are also coordinates on the
-axis but their number and their values are freely specified, or can be determined by some knot placement strategy, see
Section 5.4.
After having defined all these quantities, a spline approximation can be performed from an overdetermined configuration using the Gauss-Helmert model with additional constraints for the unknowns.
5. TLS Solution Generated by Least Squares Adjustment within the Gauss-Helmert Model
In this section, the solution for the weighted total least-squares problem with constraints (CWTLS) (13) is based on “classical” procedures, specifically on an iterative evaluation of the nonlinear normal equations derived for nonlinear condition and constraint equations by least squares adjustment. A common approach does replace the original nonlinear condition and constraint equations by a sequence of linearized equations which obviously requires a correct linearization of the condition and constraint equations. This means that the linearization has to be done both at the approximate values for the unknowns, and at approximate values for the random errors. Such an iterative solution is regarded as “rigorous” evaluation of the iteratively linearized Gauss-Helmert model.
An extensive presentation of an evaluation of this kind was already given e.g., by Pope [
24]. Lenzmann and Lenzmann [
25] pick up this problem once more and present another rigorous solution for the iteratively linearized GH model. In doing so, they show very clearly which terms when neglected will produce merely approximate formulas. Unfortunately, these approximate formulas, which can yield an unusable solution, can be found in many popular textbooks on adjustment calculus. For more details please refer to Neitzel [
11]. The rigorous solution as presented in the following is based on Lenzmann and Lenzmann [
25].
5.1. Formulation of the Adjustment Problem
Based on the functional model (20) with observations
and
, the condition equations
can be formulated. Obviously, (24) is nonlinear. However, the application of least squares adjustment usually “lives” in the linear world. Since the Gauss-Newton method is used here for solving least squares problems, the condition equations have to be linearized. With appropriate approximate values
and
, the linearized condition equations can be written as
with
and the matrices of partial derivatives
These derivatives have to be evaluated at the approximate values
and
. Taking the partial derivatives for the function that defines the condition Equation (24) with respect to the unknowns
we can set up the matrices
for each polynomial piece of the spline. The functional matrix for the first interval reads
for the second interval, we obtain
This construction of
matrices continues until the last interval. Finally, the entire functional matrix has the following form
From (32) and (33), we can see the typical characteristic of an EIV model (9), where some (or sometimes all) columns of the functional matrix contain observations with their corresponding errors.
Taking the partial derivatives of the function
from condition Equations (24) with respect to the errors
we can define the matrices
and
Finally, matrix
obtains the following form
Now, we have to take into account also the constraints (21)–(23). Since the knots
are error-free values, we obtain linear constraint equations
which enforce the spline to be continuous at the knots. The next set of constraint equations
enforces the spline to have a continuous first derivative at the knots. This implies that the spline will have smooth transition at the knots. The last set of constraint equations
enforces the spline to have a continuous second derivative at the knots, which implies that the curvature at the knots will be continuous. Rearranging Equations (40)–(42) yields for continuity the constraint equations
for smoothness it is
and for the curvature we obtain
The nonlinearity of the condition equations (24) affects the unknowns of the linear constraint equations. As a consequence, we have to consider the linear constraint equations in a “linearized” form
with
and
, where the matrices
contain the coefficients of the unknowns. Every row of these matrices refers only to two consecutive intervals, i.e.,:
Unknowns from the first row refer to the first two intervals, and .
Unknowns from the second row refer to the second and the third interval, and .
This continues until the last row where the unknowns refer to the last and its preceding interval, and .
Taking into account the sequence of the unknowns, matrix
that imposes continuity at the knots is
Matrix
contains the coefficients from the equations of constraints that preserve the smoothness of the spline at the knots and is expressed as
Matrix
contains the coefficients from the equations of constraints which enforce continuous curvature at the knots written as
Now, we expand (25) and introduce
and for the constraint Equations (46) we introduce
as vectors of misclosures. Finally, we can write the linearized condition equation and the constraint equations in the form
5.2. Least Squares Adjustment
Since from (52) and (53), four separate sets of equations are obtained, four vectors of Langrange multipliers
,
,
and
have to be introduced to apply the constrained minima technique. The quadratic form to be minimized is
To minimize the objective function we take the partial derivatives of (54) w.r.t. the errors
, the reduced unknowns
and the Lagrange multipliers
,
,
,
. Afterwards, every derivative is set equal to zero and we obtain
Solving (55) for
yields
with the dispersion matrix of the observations
. Since in almost all cases the dispersion matrix
is given directly, this inversion is usually not necessary. Inserting (61) into (57) yields
Finally, we can set up the system of matrix equations
This system of matrix equations can be written in matrix form as
Obviously, it is possible to further reduce this system by eliminating
but in the form (64), it offers the great advantage to consider also a singular dispersion matrix
for the observations. The structure of the coefficient matrix in (64) coincides with the one that Jazaeri et al. [
9] use for their weighted TLS solution with constraints when
is singular. The rank condition that has to be fulfilled to obtain a unique solution was explained by Neitzel and Schaffrin [
16].
The solution
and the Lagrange multipliers can be derived from (64) using matrix inversion. However, in most of the applications, other methods such as Cholesky decomposition are used, because the inversion of a matrix is highly prone to rounding errors and is computationally inefficient. The error vector
can be obtained from (61). The solution
,
, after stripping it of its random character, is to be substituted as a new approximation as long as necessary until a break-off condition is met. For the choice of break-off conditions, we refer, e.g., to Lenzmann and Lenzmann [
25]. Note that often the update in (50) is erroneous, in which case convergence may occur, but not to the correct nonlinear least squares solution.
After the solution is obtained we can compute the total sum of squared residuals (TSSR) by
In case of a singular dispersion matrix, the weight matrix
does not exist and we introduce (61) for the residuals to obtain the TSSR from
Finally, we can compute the estimated reference standard deviation
where
is the redundancy of the adjustment problem. Based on the value
, we can get an idea about the quality of the adjustment by applying a statistical test.
5.3. Initial Values for the Unknowns
In the case under consideration, appropriate starting values for the unknowns can be obtained from the solution of the linear adjustment problem with
as observations and
as fixed values, presented by Ezhov et al. [
2] and as initial values of the errors we can choose
Experience with several numerical examples has shown that it is also possible to introduce
as initial values for the unknowns.
5.4. Knot Placement Strategies
As described by Ezhov et al. [
2], the basic problem of knot placement in spline approximation comprises two fundamental challenges:
According to these specifications, the knots are rearranged in the course of an iterative process until the quality criteria are met. Since the distribution of the knots plays a crucial role in spline approximation, various knot placement strategies have been proposed in the literature; see, e.g., the approaches developed by Cox et al. [
26], Schwetlick and Schütze [
27] and Park [
28]. An overview of knot placement strategies is offered by Bureick et al. [
1,
29]. Current research focuses on choosing the optimal number of B-spline control points using the Akaike Information Criterion (AIC) and the Bayesian Information Criterion (BIC); see the contribution by Harmening and Neuner [
30].
In this article, the main focus is on generating the TLS solution for spline approximation. Hence, for simplicity, a uniformly distributed knot sequence is chosen, proposed by De Boor [
31], also called “equidistant arrangement”; see the contribution by Yanagihara and Ohtaki [
32]. The term uniformly distributed knot sequence describes that all knots have equal spacing within the dataset
in which the spline is fitted.
6. Numerical Example
In the following numerical example, we consider the spline approximation for the case that both the values and are observations subject to random errors. Two inherently different approaches for this case are presented:
Using the synthetic data set in
Table 1, which can be regarded as a cutout from a profile laser scan, we want to investigate the error vectors that are obtained from the TLS and the LS approach.
Naturally, both approaches will yield different results, because they consider two different least squares adjustment problems. Therefore, it is not a question of which approach yields “better” results than the other. It is simply to show which approach might be more suitable for the application in engineering geodesy. In all computations, the observations
and
are considered equally weighted and uncorrelated (although the methodology proposed in this article can handle the most general correlated case, as well), and the knots are uniformly distributed, as described in
Section 5.4.
However, for the LS approach based on spline functions in parametric form, there is a slight difference. The knots are chosen from the span of the vector of parameters instead of the span of the vector of observations as for the TLS approach. Since in the LS case two separate functional models and are considered, two separate least squares adjustments are performed. The chosen knots are identical for both of them.
Computations were performed for three different cases:
Case 1: Total least squares (TLS) adjustment of a spline function,
Case 2.a: Least squares (LS) adjustment of a spline curve with equally spaced location parameters ,
Case 2.b: Least squares (LS) adjustment of a spline curve with location parameters proportional to the chord length.
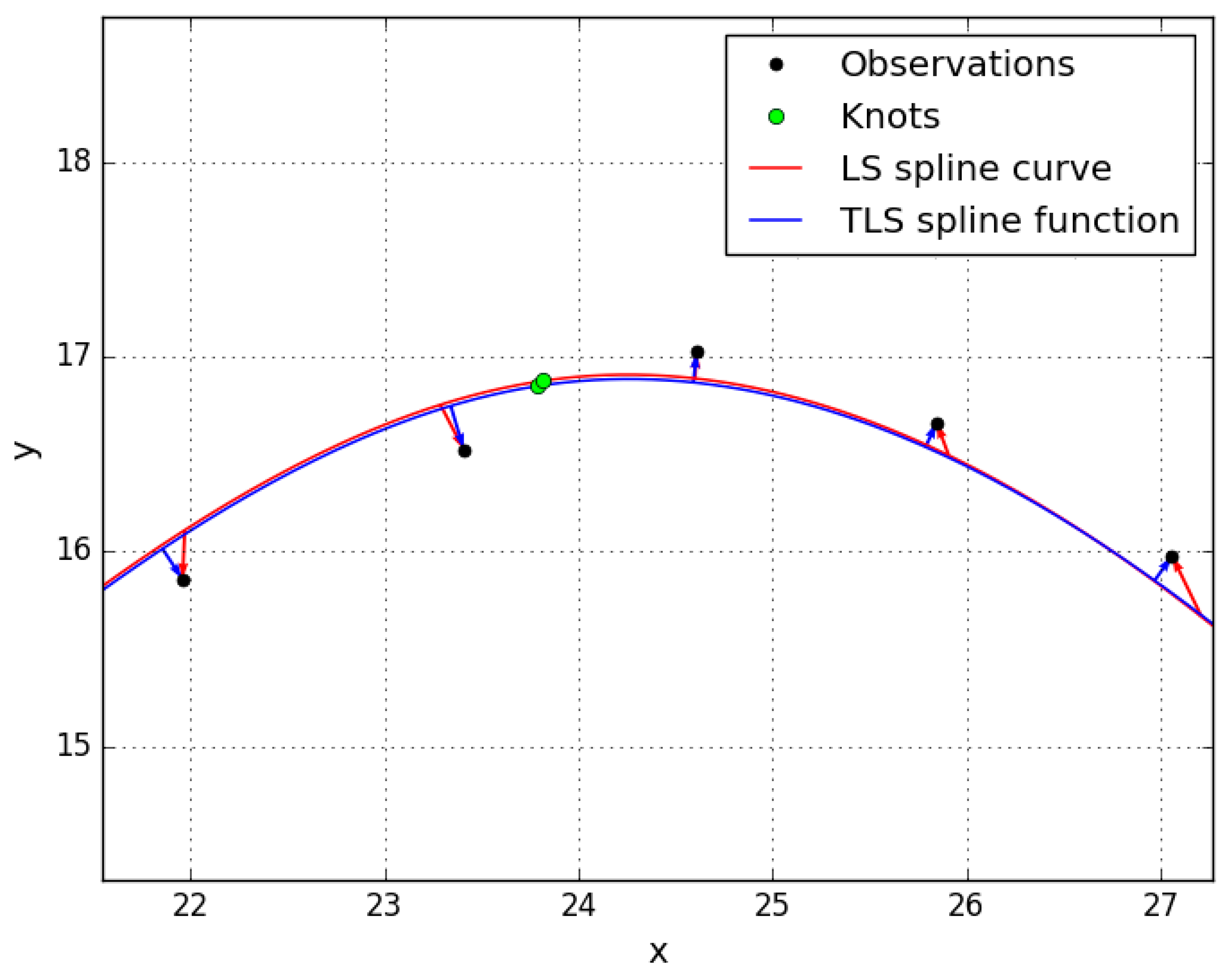
The results for Case 1 and Case 2.a are depicted in
Figure 3, a magnification of the area marked by a rectangle is shown in
Figure 4. The numerical values for the observation errors are listed in
Table 2. With
,
, introduced as equally weighted and uncorrelated observations, the TLS solution yields error vectors that are orthogonal to the graph of the adjusted spline. In contrast, it is clearly visible in
Figure 4 that the LS solution yields error vectors with “irregular” behavior, in the sense that they are far away from being orthogonal to the curve. Since the LS and the TLS solution refer to two different adjustment problems, the resulting adjusted graphs of the spline differ from each other. In this numerical example, the difference between the two adjusted graphs is rather small. The total sum of squared residuals (TSSR) for the TLS and for the LS solution are listed in
Table 3.
Figure 5 compares the result for Case 1 with the result for Case 2.b. In the magnification of the area marked by a rectangle shown in
Figure 6 it is again clearly visible that the directions of the error vectors obtained from the LS solution are “irregular” and not orthogonal to the graph of the spline curve. Furthermore, if the length and direction of the error vectors for Case 2.a and Case 2.b are compared, a considerable influence of the chosen numerical values for the location parameter
can be observed. In this numerical example the resulting adjusted graphs of the spline deviate considerably from each other. The corresponding TSSR values are listed in
Table 3.
It can be concluded that both approaches have their advantages and disadvantages. Their application depends on the type of the phenomenon that is subject to the approximation. The parametric spline curve (LS solution) can be useful for geometrical approximation of arbitrary shapes where the interpretation of the errors is not the main focus since they vary with the choice of the values of the location parameter . The error vectors obtained from the TLS approach can be utilized for deformation monitoring purposes, since they are orthogonal to the graph of the spline function in the case of equally weighted and uncorrelated observations.
It should be noted that the coordinates
and
captured with, e.g., a profile laser scanner are not original observations. They are based on the same angle and distance measurements and are, therefore, differently weighted and correlated. Since the precision of the distance measurement is influenced by a variety of factors, simplified assumptions about the stochastic model have often been used in the past. The intensity-based approach developed by Wujanz et al. [
34] allows now to set up an appropriate stochastic model for 3D laser scanners. Based on this, Heinz et al. [
35] have developed a stochastic model for a profile laser scanner. If a general stochastic model is used, the error vectors will no longer be strictly orthogonal to the adjusted spline, but it will be possible to apply statistical tests for outlier detection and deformation analysis.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}