1. Introduction
This paper investigates Evolutionary Algorithms (EAs) tuning from a multi-objective perspective. In particular, a set of experiments exemplify some of the relevant additional hints that a general multi-objective EA-tuning (Meta-EA) environment can provide, regarding the impact of EAs’ parameters on EAs’ performance, with respect to the single-objective EA-tuning environment of which it is a very simple extension.
Evolutionary Algorithms [
1] have been very successful in solving hard, multi-modal, multi-dimensional problems in many different tasks. Nevertheless, configuring EAs is not simple and implies critical decisions that are taken based, as summarized below, on a number of factors, such as: (i) the nature of the problem(s) under consideration, (ii) the problem’s constraints, such as the restrictions imposed by computation time requirements, (iii) an algorithm’s ability to generalize results over different problems, and (iv) the quality indices used to assess its performance.
Problem Features
When dealing with black-box real-world problems it is not always easy to identify the mathematical and computational properties of the corresponding fitness functions (such as modality, ruggedness, isotropy of the fitness landscape, see [
2]). Because of this, EAs are often applied acritically, using “standard” parameter settings which work reasonably on most problems but most often lead to sub-optimal solutions.
Generalization
An algorithm that effectively optimizes a certain function should optimize as effectively functions characterized by the same computational properties. An interesting study on this issue is the investigation of “algorithm footprints” [
3].
Some configurations of EAs, among which “standard” settings are usually comprised, can reach similar results on many problems, while others may exhibit performance characterized by a larger variability. While it is obviously important to find a good parameter set for a specific EA dealing with a specific problem, it is even more important to understand how much changing it can affect the performance of the EA.
Constraints and Quality Indices
Comparing algorithms (or different instances of the same algorithm) requires a precise definition of the conditions under which the comparison is made. As will be shown later in the plots Q10K and Q100K in Figure 7 (top left), convergence to a good solution can occur with very different modalities. Some parameter settings may lead to fast convergence to a sub-optimal solution, while others may need many more fitness evaluations to converge, but lead to better solutions. In several real-world applications it is often sufficient to reach a point which is “close enough” to the global optimum; in such cases, an EA that is consistently able to reach good sub-optimal results timely is to be preferred to slower, although more precise, algorithms. Instead, in problems with weaker time constraints, an EA that keeps refining the solution over time, even very slowly, is usually preferable.
The previous considerations indicate that comparing different algorithms is very difficult because, for the comparison to be fair, each algorithm should be used “at its best” for the given problem. In fact, there are many examples in the literature where the effort spent by the authors on tuning and optimizing the method they propose is much larger than the effort spent on tuning the ones to which it is compared. This may easily lead to biased interpretations of the results and to wrong conclusions.
The importance of methods (usually termed Meta-EAs) that tune EAs’ parameters to optimize their performance has been highlighted since 1978 [
4]. However, mainly due to the relevant computational effort they require, Meta-EAs and other parameter tuning techniques have become a mainstream research topic only recently.
We are aware that using as Meta-EA an algorithm whose behavior, as well, depends on its setup, would imply that the Meta-EA itself should undergo parameter tuning. There are obvious practical reasons related to the method’s computational burden for not doing so. As well, it can be argued that if the application of a Meta-EA can effectively lead to solutions that are closer to the global optimum for the problem at hand than those found by a standard setting of the algorithm that is being tuned, then, even supposing one uses several optimization meta-levels, the improvement margins for each higher-level Meta-EA become smaller and smaller with the level. This intuitively implies that the variability of the results depending on the higher-level Meta-EAs parameter settings also becomes smaller and smaller with the level. Therefore, even if, most probably, better settings of the Meta-EA could further improve the optimization performance, we consider that a “standard” setting of the Meta-EA is generally enough to achieve some relevant performance improvement with respect to a random setting.
In [
5], we proposed SEPaT (Simple Evolutionary Parameter Tuning), a single-objective Meta-EA in which GPU-based versions of Differential Evolution (DE, [
6]) and Particle Swarm Optimization (PSO, [
7]) were used to tune PSO on some benchmark functions, obtaining parameter sets that yielded results comparable with the state of the art and better than “standard” or manual settings.
Even if results were good, the approach was mainly practical, aimed at providing one set of good parameters, but no hints about their generality or about the reasons why they had been selected. One of the main limitations of the approach was related to its performing a single-objective optimization, which prevented it from considering other critical goals, such as generalization, besides the obvious one to optimize an EA’s performance on a given problem.
In this paper, we go far beyond such results, investigating what additional hints a multi-objective approach can provide. To do so, we use a very general framework, which we called EMOPaT (Evolutionary Multi-Objective Parameter Tuning), that was described in [
8]. EMOPaT uses the well-known Multi-Objective Evolutionary Algorithm (MOEA) Non-dominated Sorting Genetic Algorithm (NSGA-II, [
9]) to automatically find good parameter sets for EAs.
The goal of this paper is not proposing EMOPaT as a reference environment. Instead, we use it, as virtually the simplest possible multi-objective derivation of SEPaT, to focus on some of the many additional hints that a multi-objective approach to EA tuning can provide with respect to a single-objective one. We are well conscious that more sophisticated and possibly better performing environments aimed at the same goal can be designed. SEPaT and EMOPaT have been developed with no intent to advance the state of the art of meta-optimization algorithms but as generic frameworks, with as few specific features as possible, aimed at studying EA meta-optimization. Consistently with this principle, within EMOPaT, we use NSGA-II as the multi-objective algorithm tuner, since it is possibly the most widely available, generally well-performing and easy to implement multi-objective stochastic optimization algorithm. Indeed, NSGA-II can be considered a natural extension of a single-objective genetic algorithm (GA) to multi-objective optimization. As well, we chose to test EMOPaT in tuning PSO and DE for no other reasons than the easy availability and good computational efficiency of these algorithms. EMOPaT is a general environment and can be used to tune virtually any other EA or metaheuristic.
EMOPaT is not only aimed at finding parameter sets that achieve good results considering the nature of the problems, the quality indices and, more in general, the conditions under which the EA is tuned. It allows one to extract information about the parameters’ semantics and the way they affect the algorithm by analyzing the Pareto fronts approximated by the solutions obtained by NSGA-II. A similar strategy has been presented by [
10] under the name of
innovization(innovation through optimization).
As well, we show that EMOPaT can evolve parameter sets that let an algorithm perform well not only on the problem(s) on which it has been tuned, but also on others.
Section 2 briefly introduces the three EAs used in our experiments,
Section 3 reviews the methods that inspired our work, and
Section 4 describes EMOPaT. In
Section 5 we first use EMOPaT to find good parameter sets for optimizing the same function under different conditions: doing so, we show that the analysis of EMOPaT’s results can clarify the role of EAs’ parameters and study EMOPaT’s generalization abilities; finally, EMOPaT is used to optimize seven benchmark functions and generalize its results to previously unseen functions.
Section 6 summarizes all results and suggests possible future extensions of this work.
Additionally, in a separate appendix, we demonstrate that EMOPaT can be considered an extension of SEPaT and has equivalent performance in solving single-objective problems, as well as assessing its correct behavior by considering some controlled situations, on which we show it to be able to perform tuning as expected.
3. Related Work
The importance of parameter tuning has been frequently addressed in the last years, not only in theoretical or review papers such as [
12] but also in papers with extensive experimental evidence which provide a critical assessment of such methods. In [
13], while recognizing the importance of finding a good set of parameters, the authors even suggest that using approaches to algorithm tuning that are computationally demanding may be almost useless, since a relatively limited random search in the algorithm parameter space can often offer good results.
Meta-optimization algorithms can be grouped into two main classes:
Along with Meta-EAs, several methods which do not strictly belong to that class but use similar paradigms have been proposed: one of the most successful is Relevance Estimation and Value Calibration (REVAC) by [
15], a method inspired by the Estimation of Distribution Algorithm (EDA, [
16]) that was able ([
17]) to find parameter sets that improved the performance of the winner of the competition on the CEC 2005 test-suite [
18]. In [
19], PSO tuned itself to optimize neural network training; Reference [
20] used a simple metaheuristic, called Local Unimodal Sampling, to tune DE and PSO, obtaining good performance while discovering unexpectedly good parameter settings. Reference [
21] proposed ParamILS, whose local search starts from a default parameter configuration which is then iteratively improved by modifying one parameter at a time. Reference [
22] used a Meta-EA as an optimization method in a massively parallel system to generate on-the-fly optimizers that directly solved the problem under consideration. In [
23], the authors propose a self-adaptive DE for feature selection.
Other approaches to parameter tuning include model-based methods like Sequential Parameter Optimization (SPO) proposed by [
24] and racing algorithms [
25,
26]: they generate a population of possible configurations based on a particular distribution; members of this population are then tested and possibly discarded as soon as a statistical test shows that there is at least another individual which outclasses them; these operations are repeated until a set of good configurations is obtained. A recent trend approaches parameter tuning as a two-level optimization problem [
27,
28].
The first multi-objective Meta-EA was proposed in [
29] where NSGA-II was used to optimize speed and precision of four different algorithms. However, that work took into consideration only one parameter at a time, so the approach described therein cannot be considered a full parameter set optimization algorithm. A similar method has been proposed by [
30]. The authors describe a variation of a MOEA called Multi-Function Evolutionary Tuning Algorithm (M-FETA), in which the performance of a GA on two different functions represent the different goals that the MOEA must optimize; the final goal is to discriminate algorithms that perform well on a single function from those that do on more than one, respectively called “specialists” and “generalists”, following the terminology introduced by [
31].
In [
32], the authors propose an interesting technique, aimed at identifying the best parameter settings for different possible computational budgets (i.e., number of fitness evaluations) up to a maximum. This is obtained using a MOEA in which the fitness of an individual is a vector whose components are the fitness values obtained in every generation. In this way, it is possible to find a family of parameter sets which obtain the best results with different computational budgets.
A comprehensive review of Meta-EAs can be found in [
33].
More recently, MO-ParamILS has been proposed as a multi-objective extension of the state-of-the-art single-objective algorithm configuration framework ParamILS [
34]. This automatic algorithm produces good results on several challenging bi-objective algorithm configuration scenarios. In [
35], MO-ParamILS is used to automatically configure a multi-objective optimization algorithm in a multi-objective fashion.
4. EMOPaT, a General Framework for Multi-Objective Meta-Optimization
This section describes EMOPaT’s main structure and operation, introduced in [
5] as a straightforward multi-objective extension of the corresponding single-objective general framework SEPaT.
SEPaT and EMOPaT share the same very general scheme, presented in
Figure 2.
The block in the lower part of the image represents a traditional optimization problem in which an EA, referred to as Lower-Level EA (LL-EA) optimizes one or more objective functions. The Tuner EA operates within the search space of the parameters of the LL-EA. This means that the tuner evolves a population of possible parameter sets of LL-EA parameters. Each parameter set corresponds to an instance of LL-EA that is tested N times on LL-EA’s objective function(s) (from now on, we will consider “configuration” and “parameter set” as equivalent terms). The N results are synthesized into one or more “Quality Indices” that represent the objective function(s) of the tuner.
The difference between SEPaT and EMOPaT therefore stands in the different number of quality indices. In SEPaT, any single-objective EA can be used as Tuner EA, while EMOPaT requires a multi-objective EA. In the case described in this paper, we used NSGA-II.
It should be noticed that as evidenced in the figure, the tuning of the (usually, but not necessarily, single-objective) LL-EA may be aimed at finding the best “generalist” setting for optimizing any number of functions. For instance, in [
5] PSO and DE were used as tuners in SEPaT to optimize the behavior of PSO over 8 objective functions. In that case, an EA configuration was considered better than another if it obtained better results over the majority of the functions. The quality index, in this case, was therefore a score computed according to a tournament-like comparison among the individuals.
In [
5], the parameter set found by SEPaT was compared to the set found using
irace [
25,
36] and to “standard” parameters, with results similar to
irace and better than the “standard” settings.
On the one hand, using this approach, besides allowing one to synthesize the results as a single score, brings the advantage that the functions for which the LL-EAs are tuned do not need to assume values within comparable ranges, avoiding the need for normalization. On the other hand, being based on a comparison may sometimes limit the effectiveness of this approach. In fact, a configuration may win even if it cannot obtain good results on some of the functions, since it is required only to perform better than the others on the majority of them. Therefore, the resulting parameter sets, despite being good on average, may not be as good on all functions. This is one of the limitations that EMOPaT tries to overcome (see
Section 5.2).
The multiple objectives taken into consideration by EMOPaT may differ depending on the function under consideration, the quality index considered, or the constraints applied, such as the number of evaluations, time constraints or others. The output of the tuning process is not a single solution as in SEPaT, but an entire set of non-dominated EA configurations, i.e., ideally, a sampling of the Pareto front for the objectives under consideration (see Figure 6 for two examples of Pareto fronts, highlighted in yellow). This allows a developer to analyze the parameters’ selection strategy more in depth. We think that this approach can be particularly relevant, in light of the conclusions drawn in [
37]: according to the outcome of the experiments, even if the Meta-EAs they considered performed better than SPO and REVAC, the authors pointed out that they were unable to provide insights about EA parameters.
Parameter Representation
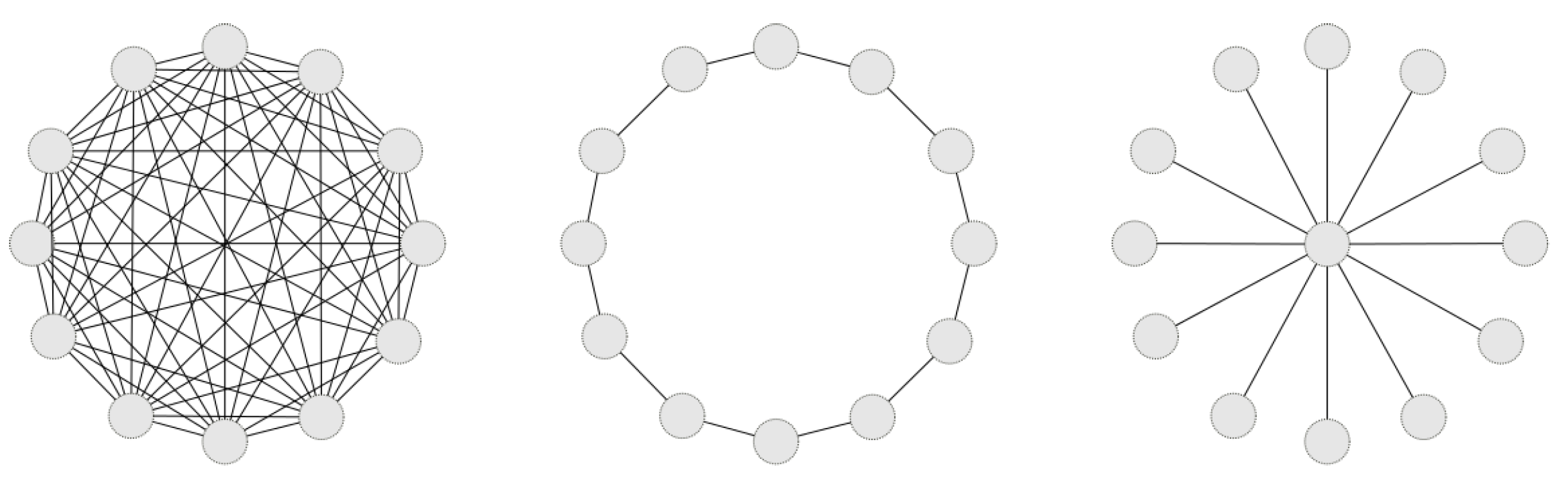
Since the tuner algorithms we consider are real-valued optimization methods, we need a proper representation of the nominal parameters of the LL-EA, i.e., the parameters that encode choices among a limited set of options. We opted for representing each nominal parameter as a real-valued vector with as many elements (genes) as the options available: the actual choice is the one that corresponds to the gene with the largest value. For instance, if the parameter to optimize is PSO topology, we can choose between
ring,
star and
global topology. Each individual in the tuner represents this setting as a three-dimensional vector whose largest element determines the topology used in the LL-EA configuration. These particular genes are mutated and crossed-over following NSGA-II rules just like any other.
Figure 3 shows how DE and PSO configurations are encoded.
5. Experimental Evaluation
In this section, we discuss the results of some experiments in which we optimize different performance criteria that can assess the effectiveness of an EA in solving a given optimization task. We take into consideration “classical” criteria pairs, such as solution quality vs. convergence speed, as well as experiments in which the different criteria are represented by different constraints on the available resources (e.g., different fitness evaluation budgets).
To do so, we use DE and PSO as LL-EAs and NSGA-II as EMOPaT’s Tuner-EA.
Table 1 shows the ranges within which we let PSO and DE parameters change in our tests. During the execution of the Tuner-EA, all values are actually normalized in the range
; a linear scale transformation is then performed whenever a LL-EA is instantiated.
The computation load of the meta-optimization process is heavily dependent on the cost of a single optimization process. If we term
t the average time needed for a single run of the LL-EA (which corresponds, for the Tuner-EA, to one fitness evaluation), then the upper bound for the time
T needed for the whole process is:
since we can consider the computation time requested by the tuner’s search operators to be negligible with respect to a fitness evaluation. This process can be highly parallelized, since all
N repetitions, as well as all evaluations of a population can be run in parallel if enough resources are available. In our tests, we used an 8-core 64-bit Intel(R) CoreTM i7 CPU running at 3.40 GHz; we chose not to parallelize the optimization process but we preferred to parallelize independent runs of the tuners.
EMOPaT has been tested on some functions from the CEC 2013 benchmark [
38], with the only difference that the function minima were set to 0.
5.1. Multi-Objective Single-Function Optimization Under Different Constraints
A multi-objective experiment can optimize different functions, the same function under different conditions, etc. Thus, optimizing a single function under different constraints can be seen as a particular case of multi-objective optimization. In this section, we report the results of tests on single-function optimization under different fitness evaluations budgets. Similar experiments can be performed evaluating the function under different conditions (e.g., different problem dimensions) or according to different quality indices as we did in [
8] where we considered two objectives (fitness and fitness evaluations budget) for a single function. With respect to that work, the main additional contribution of this section is showing how EMOPaT can be used to generalize the behavior of an EA in optimizing a function when working under different conditions. We consider the following set of quality indices:
{QXi} ≜ best results after {Xi} fitness evaluations, averaged over N runs.
We performed four different tests considering, in each of them, one of the four functions shown in
Table 2. Our objectives were the best-fitness values reached after 1000,
and
function evaluations, namely
Q1K,
Q10K,
Q100K. Each test was run 10 times. Doing so, we expected we would favor the emergence of patterns related with the impact of a parameter when looking for “fast-converging” or “slow-converging” configurations.
Table 2 summarizes the experimental setup for these experiments.
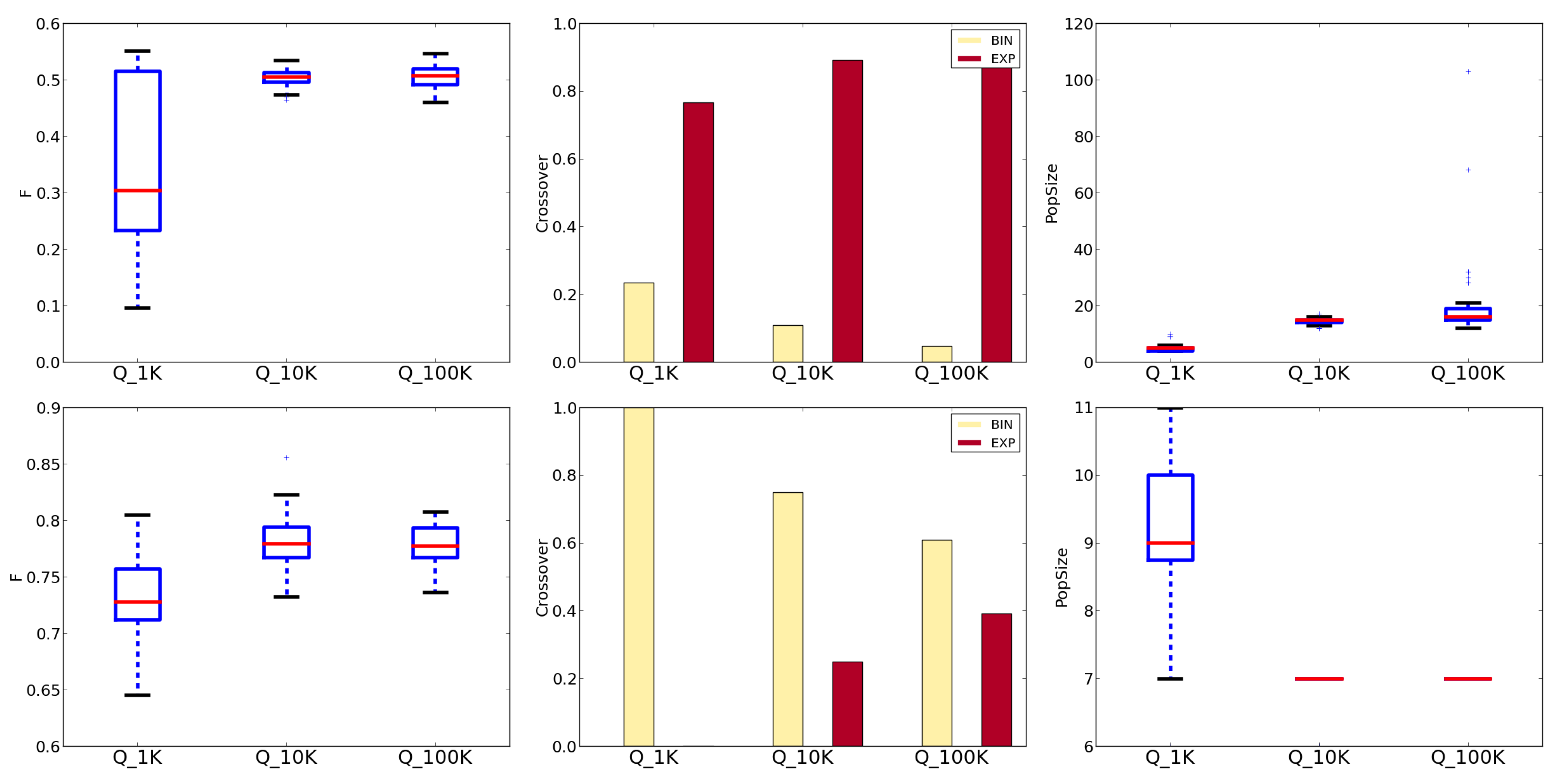
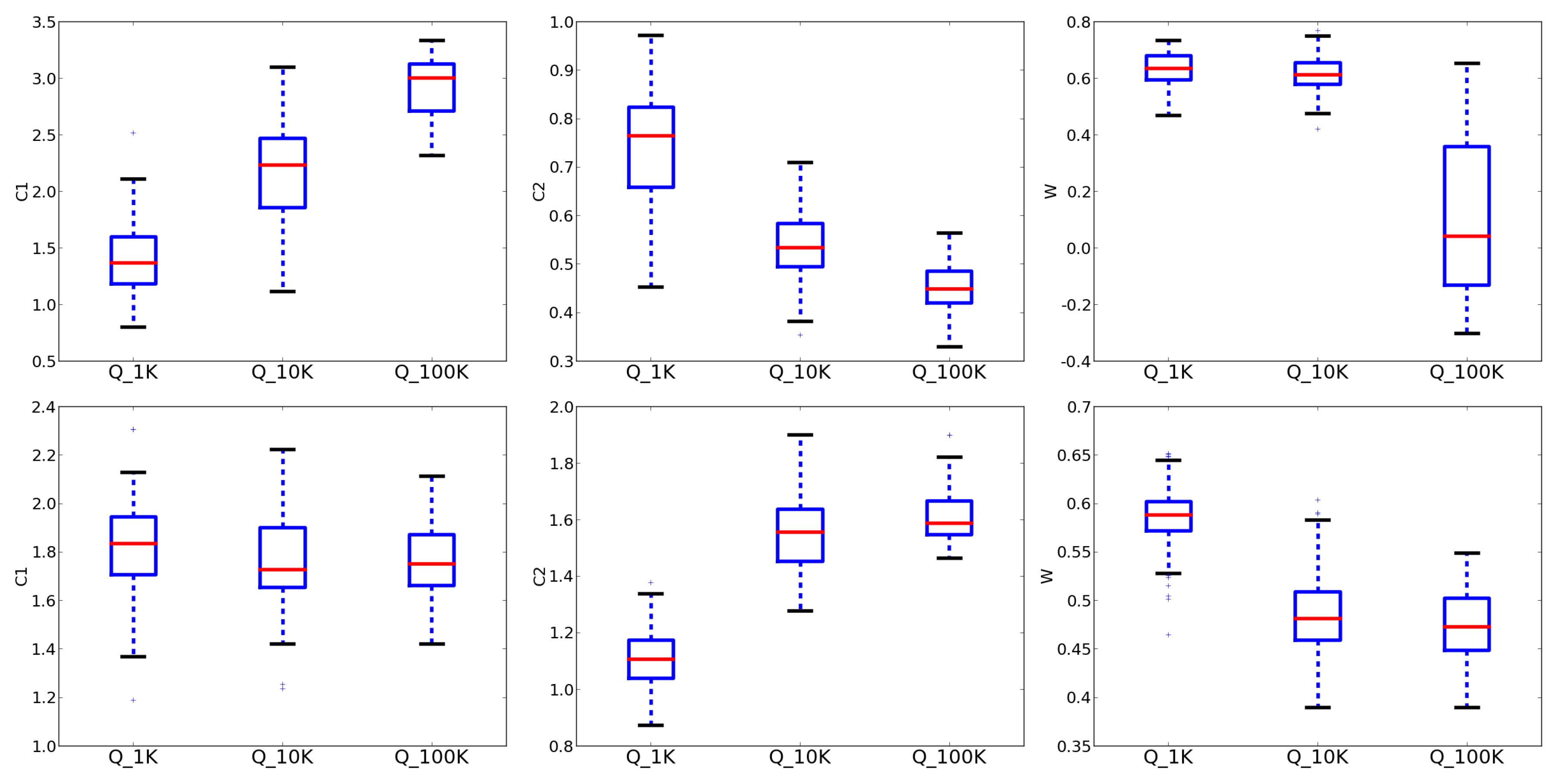
Firstly, we analyze the LL-EA parameter sets evolved under the different criteria. To do so, we merge the populations of the ten independent runs and, from this pool, we select, for each objective, the top
of the best solutions. For most parameters there is a clear trend as their values monotonically grow or decrease as the fitness evaluations budget increases (see
Table 3). This result suggests that, in these cases, it may not be necessary to keep track of all possible computational budgets as in [
32], but that the optimal parameters for intermediate objectives may be inferred by interpolating the ones found for the objectives actually taken into consideration; consequently, a developer can use this information to tune its algorithm according to his own budget constraints. Nevertheless, while this can be true for a function, such trends are rarely consistent through different functions, preventing one from drawing more general conclusions.
Let us analyze in more details the results on the Rastrigin and the Sphere functions (similar conclusions can be drawn for the other functions).
Figure 4 and
Figure 5 show the boxplots of some parameters for the top
DE and PSO configurations on these two functions. When parameters are nominal, a bar chart plots the selection frequencies for each option. For the Sphere function, the boxplots of
Q10K and
Q100K are very similar, pointing out that for this function, 10,000 evaluations are usually sufficient to reach convergence.
To evaluate the hypothesis that intermediate budgets can be inferred from the results obtained on the objectives that have actually been optimized, one can generate new solutions in two ways:
infer them as the mean of two top solutions found for two different objectives between which the new objective lies. This approach presents some limitations: (i) the parameter must have a clear trend, (ii) some policy for nominal parameters must be defined if the two reference configurations have different settings, (iii) there is no guarantee that all intermediate values of a parameter correspond to valid configurations of the algorithm;
select them from the Pareto front by plotting the set of all the individuals obtained at the end of ten independent runs on the two objectives of interest, estimate the Pareto front based on those solutions and randomly pick one configuration that lies on it, in an intermediate position between the extremes (see an example related with the Rastrigin function in
Figure 6).
Table 4 shows the parameters of the best solutions found for the Rastrigin and Sphere functions for the three objectives and of four intermediate solutions generated by the two methods. The ones indicated by
A lie between
Q1K and
Q10K and the ones indicated by
B between
Q10K and
Q100K. It can be noticed that the values of the parameter sets generated using the Pareto Front differ from both the ones inferred as a weighted mean of neighboring ones and the top solutions. In some cases (as with DE on Sphere) these solutions use a mutation type that is never considered by the top solutions. For the nominal parameters of the inferred solutions, we chose to consider both options when the two top solutions disagreed, distinguishing the two solutions by an index (e.g.,
and
).
Figure 7 shows the performance of the configurations considered in
Table 4, averaged over 100 independent runs, for DE and PSO. The solid lines represent the Top Solutions; as expected, after 1000 evaluations (see the plots on the right)
Q1K is the best-performing configuration, while
Q100K is slower in the beginning but is the best at the end of the evolution. In most cases, the inferred solutions have a performance that lies between the performance of the two top solutions used as starting points. The results obtained on the Rastrigin function (first row of
Figure 7) are particularly clear: in the first 1000 evaluations,
Q1K performs best, then it is surpassed by Inferred A, followed by
Q10K, Pareto B, and finally
Q100K; this example seems to confirm our general hypothesis. A relevant exception is
in DE Sphere (
Figure 7, last row) that performs worse than all others: since its only difference with
is the crossover type, this suggests that it is not possible to infer nominal parameters reliably unless one is clearly prevalent.
Finally, to compare EMOPaT with a state-of-the-art tuner, we implemented the Flexible-Budget method (FBM) proposed by [
32]. For a fair comparison, we implemented their method using the same NSGA-II parameters used by EMOPaT, including the budget of LL-EA evaluations. The secondary criterion used to compare equally ranked individuals (see [
32] for more details) is the Area Under the Curve. Ten independent runs of FBM were run, after which we selected the solutions that among all runs, had obtained the best-performing configurations after 1 K, 10 K, 100 K evaluations (similar to our setting) and
K and 55 K evaluations (for a comparison with our inferred parameter sets). Then, we performed 100 runs for each configuration and compared the results to the ones reported in
Table 4 (for intermediate values we used the ones called “From Pareto”) allowing the same computational budget.
Table 5 shows the parameters found by FBM and
Table 6 the comparison between the performance of the two methods. Except for PSO on the Sphere function, for which the results provided by EMOPaT are always better (Wilcoxon signed-rank test,
), the two tuning methods always obtain equivalent results with budgets of 1 K, 10 K and 100 K evaluations. With the two intermediate budgets, FBM is better three times, EMOPaT is better twice and once they are equivalent; therefore no significant difference between the two methods can be observed.
The results obtained by EMOPaT are also consistent with previous experimental and theoretical findings, such as the ones reported in [
39], which proved that premature convergence can be avoided if:
Of the fourteen DE instances in
Table 4, Sphere
Q1K is the only one that does not respect this condition; this may be an explanation for the fact that this DE version is fast, but generally unable to reach convergence optimizing such a simple unimodal function.
5.2. Multi-Function Optimization
In this section, we show how EMOPaT behaves when the goal is to obtain configurations that perform well on functions that are not included in the “training set”. Following the terminology introduced by [
31], we expect to find “generalist” and “specialist” versions of the EAs taken into consideration.
Table 7 gives more details about this experiment.
We used EMOPaT to optimize all the seven functions together (repeating the test 10 times) and then we merged all results into a single collection of configurations. From this collection, we selected the best-performing configuration for each of the seven objective functions.
The next step was to select the “generalist” solutions. We consider a “generalist” solution to be a parameter set that does not perform badly on any of the objectives taken into consideration, i.e., it is never in the worst percent of the population, when ordered by any objective. Obviously, the higher , the lower the number of generalists. We decided to set the value of such that seven generalists would be selected, to match the specialists’ number.
Table 8 shows the generalists’ and specialists’ parameters obtained by merging the results of ten independent runs of EMOPaT. An interesting outcome worth highlighting is that, similar to the previous experiment, some of the generalists are not obtained by simply “interpolating” other results but they contain some traits that are not featured by any specialist. For instance, DE
has a smaller population than any specialist, PSO
’s inertia value is higher than that of all specialists.
A more standard way to infer a “generalist” configuration is to take the one with the best overall results. To do so, we consider the results of all the solutions found by EMOPaT and normalize them so that each fitness has average = 0 and standard deviation = 1; then, we select the configuration that minimizes the sum of the normalized fitnesses. In
Table 8, these configurations are reported as “average”.
We also performed 10 meta-optimizations using SEPaT and
irace, with the same budget allowed for EMOPaT. The parameters of SEPaT are the ones presented in
Table A1, while for
irace we used the parameters suggested by the authors. For each optimization method, the ten solutions obtained were compared using the tournament method described in
Section 4 to find the best configuration, which is also reported in
Table 8.
To test the parameter sets obtained, we selected seven functions from the CEC 2013 benchmark that were not used during training (namely Elliptic, Rotated Discus, Rotated Weierstrass, Griewank, Rotated Katsuura, CF5 and CF7).
Table 9 shows, for each function, which configuration(s) obtained the best results. To determine the best function, we performed the Wilcoxon signed-rank test (
) on all configurations pairwise. A configuration is considered to be the best if no other configuration performs significantly better on that function. The table shows that, in some cases, generalists were actually able to obtain better results on previously unseen functions than specialists.
Since the definition of “generalist EA” implies the ability not to perform badly on any function, we also analyzed the same data from another viewpoint. Each cell
in
Table 10 shows the number of test functions for which the optimizer which row
i refers to performs statistically worse than the one referred to by column
j (Wilcoxon signed-rank test,
). The last column reports the sum of each line and can be considered an indicator of the generalization ability of the optimizer with respect to the others over the test functions.
It can be observed that some of the generalists performed very well. The best optimizers for DE were the configurations obtained by SEPaT along with two generalists,
and
. The first two configurations are very similar to each other (same mutation and crossover,
and
), as shown by the presence of statistically significant differences between them only on one function out of seven. No specialist features a similar parameter set. Regarding PSO, two of the specialists (
and
) obtained very good results, as well as three of the generalists (
,
, and
). It is important to notice that most generalists evolved by EMOPaT outperform the solutions found by the other single-objective tuners used as reference, as well as the one obtained by computing a normalized average of all solutions evolved by EMOPaT (“average” in
Table 8). This last configuration (which is the same as
for PSO) was the best optimizer for three functions and the worst one (not reported) for two (Elliptic, Katsuura). This suggests that this is not the correct way of finding a configuration able to perform well on different functions.
In conclusion, we can say that EMOPaT, in a single optimization process, is able to find, at the same time, algorithm configurations that work well on a single function of interest and others that are able to generalize over different unseen functions, while single-objective tuners need separate processes with a consequent increase of the time spent to perform this operation.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











