
Challenges and Countermeasures of Federated Learning Data Poisoning Attack Situation Prediction
Abstract
:1. Introduction
- From the perspective of technical principles, the types of data poisoning based on federated learning are summarized, and the advantages and disadvantages of various technologies are analyzed in detail.
- Regarding the prediction of federated learning data poisoning attack situations, challenges such as system architecture vulnerability, communication efficiency shortcomings, computing resource consumption, and prediction robustness are raised.
- Suggestions are put forward to build a federated learning data poisoning attack situation prediction system to help organizations discover and respond to data poisoning threats in a timely manner.
2. Related Work
2.1. Federated Learning
2.2. Federated Learning Attack Types
2.3. Data Poisoning Attack Methods
2.4. Federated Learning Privacy Protection Technology
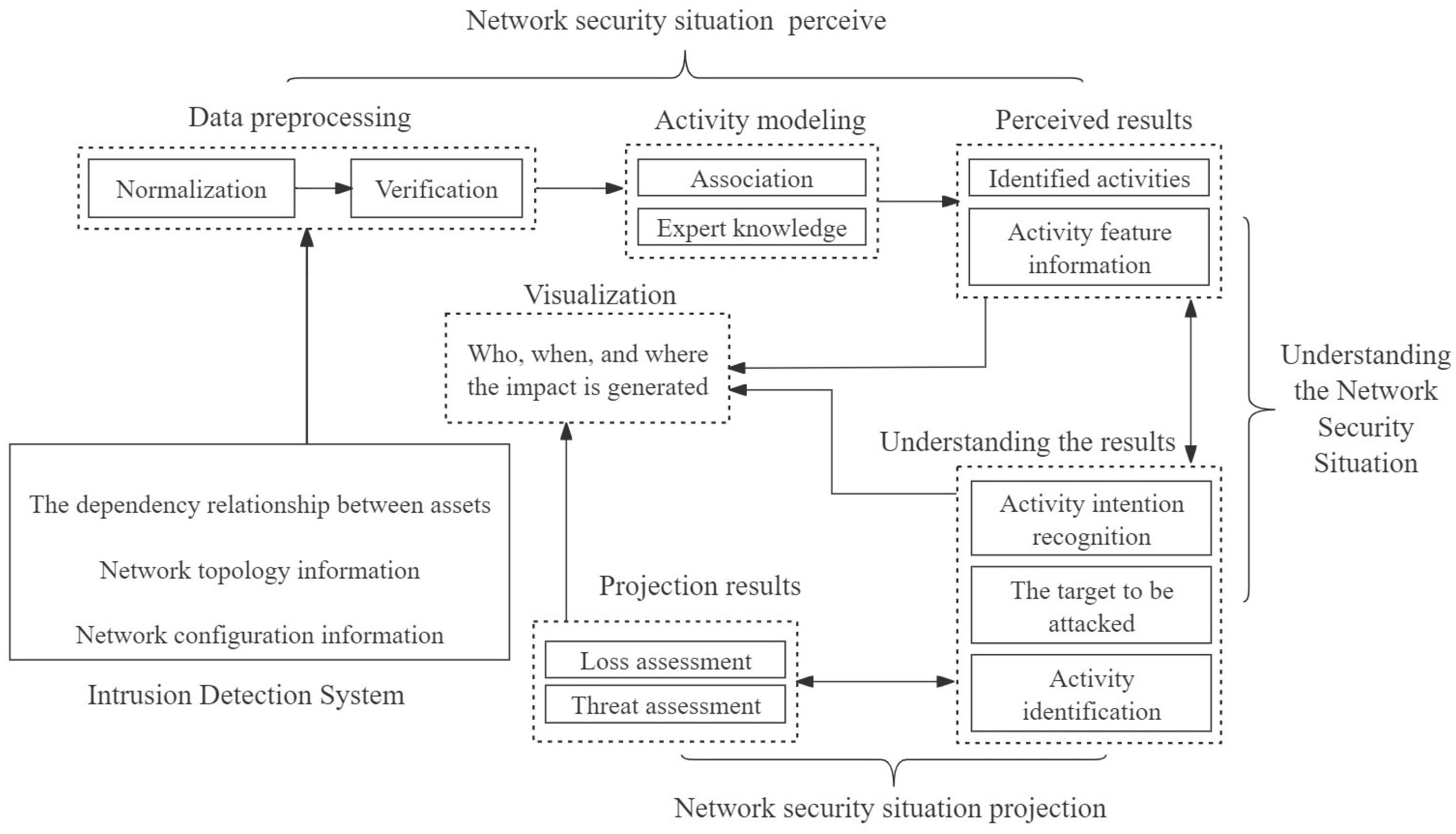
2.5. Data Security Situational Awareness
3. The Challenge of Predicting Data Poisoning Attack Situation
3.1. System Architecture Vulnerability Issues
- (1)
- The aggregation server is the nerve center of the federated learning model. It is responsible for initializing model parameters, aggregating model updates of participants and distributing the global model. If the server is compromised, the attacker can immediately disable the situation prediction ability and release malicious participants at will, thereby conducting data poisoning attacks and affecting the quality of the global model [49]. In addition, the aggregation server can utilize the maximum a posteriori principle (MAP) technology of the model inversion attack (MIA) to reconstruct participants’ training data, sensitive attributes or input data, potentially compromising their privacy [50]. Zhu et al. [51] introduced a label-only model reverse attack method, which uses labels to estimate the true confidence. The attack process is illustrated in Figure 7.
- (2)
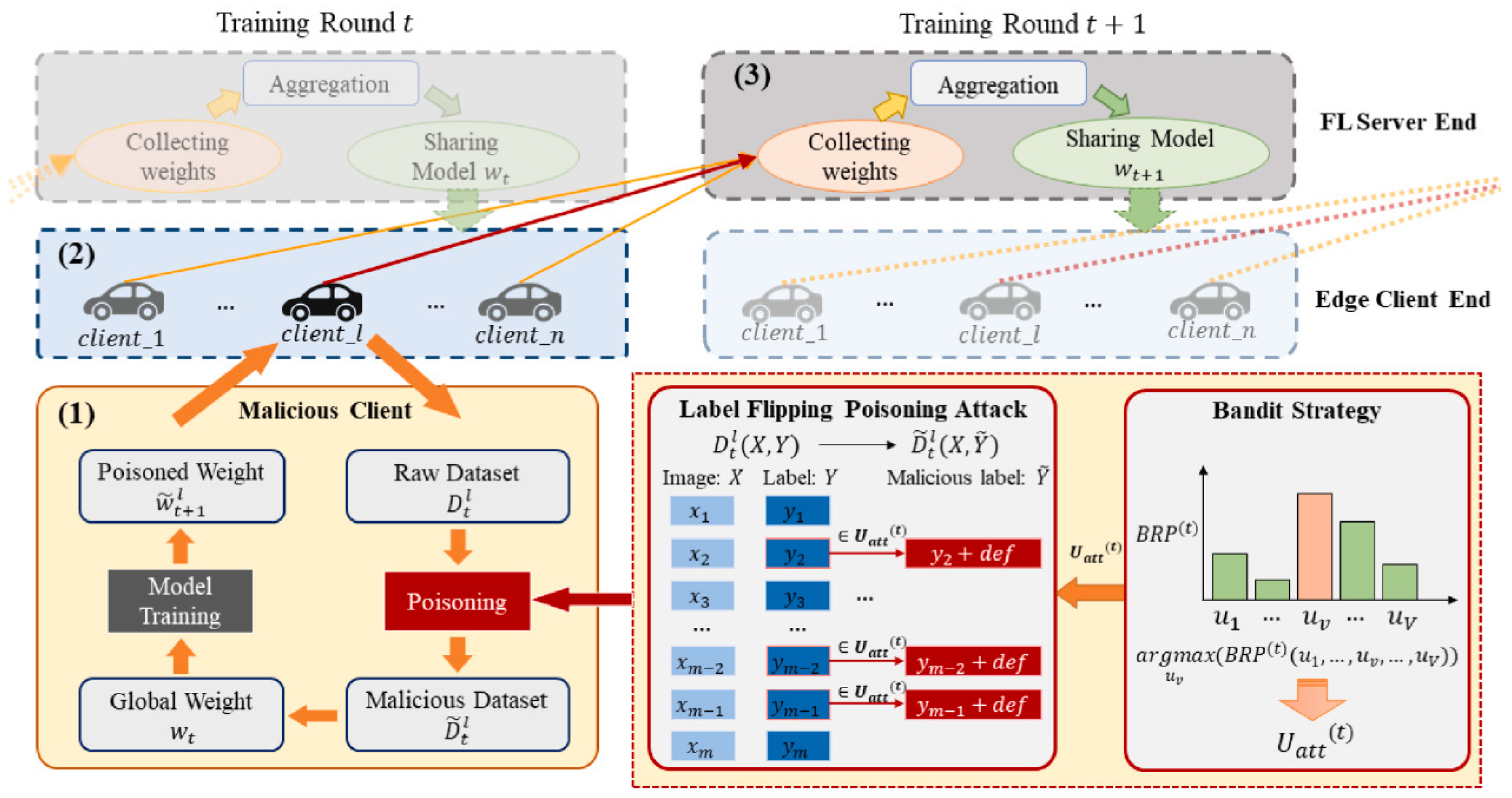
- Participants refer to the nerve endings of the federated learning model. Once a data poisoning attack occurs, they can destroy the aggregated global model by uploading updates to the model [11]. Currently, the participants in federated learning applications are mainly individual users. Compared with aggregation servers, individual users have weaker security protection measures, and the cost of attack is relatively low [52]. Attackers can easily join the federated learning training process by invading ordinary users or registering new users. They can attack the global model by forging local data or modifying model updates [25]. Wang et al. [46] proposed a data poisoning attack framework for the federated learning autonomous driving steering control (ATT-FLAV) based on the Bandit algorithm, which is used for dynamic data poisoning attacks against nonlinear regression models, as shown in Figure 8. In addition, attackers can also join forces with other malicious parties to launch attacks to enhance the attack effect. At the same time, individual users, as participants, also have vulnerabilities and unavailability when deploying data poisoning attack situational awareness probes. Therefore, participants can be said to be the most vulnerable link in a federated learning system [53].
3.2. Communication Efficiency Shortcomings
3.3. Computing Resource Consumption Problem
3.4. Situation Prediction Robustness Issues
- (1)
- Data heterogeneity and model heterogeneity: In federated learning scenarios, the data of the participants are usually heterogeneous, that is, they may come from different data sources, with different data structures, data types and data distributions. Wu et al. [58] summarized the challenges faced by federated learning into three aspects. First, there is heterogeneity in the storage, computing and communication capabilities of various participants. Secondly, the non-independent and identically distributed local data of each participant raises the problem of data heterogeneity. Data heterogeneity may reduce the accuracy and generalization ability of the model. Finally, the models required by each participant according to their application scenarios lead to the problem of model heterogeneity. Model heterogeneity refers to the differences in model structures, parameters, and hyperparameters used by different participants, which affects the performance and effect of the model. Both data heterogeneity and model heterogeneity may lead to the non-convergence of the global model [59], which may have an impact on the situation prediction effect and performance of federated learning data poisoning attacks.
- (2)
- Insufficient generalization ability. The current research on defense mechanisms against poisoning attacks in federated learning primarily focuses on the Byzantine robust aggregation algorithm [60], which is designed based on a central server to identify and eliminate potential poisoning participants. Other studies [61,62,63,64] utilize clustering algorithms or weight functions implemented by the server to mitigate or remove potential poisoning participants who deviate from the majority of participants’ updates. Another approach that is discussed in the literature [65] is the FoolsGold algorithm, which assumes that malicious updates have lower randomness compared to normal updates, providing defense against poisoning attacks where over half of the data from poisoned participants exceeds half. While these methods offer some protection against poisoning attacks, accurately assessing model updates submitted by participants is challenging due to the absence of real data sets on the server. As a result, these approaches may struggle to address poisoning attacks when the number of poisoned participants surpasses that of normal participants, ultimately leading to a reduced robustness in the situation prediction.
4. Countermeasures for Predicting Data Poisoning Attack Situation
4.1. Build a Trusted Federated Learning System
- (1)
- Optimize the federated learning model structure. To prevent data poisoning attacks, some researchers have taken inspiration from the security measures of centralized learning. They propose modifying the structure of the federated learning model to increase the model’s robustness and decrease the damage caused by contaminated data. In [67], a method of removing the aggregation server is proposed, and the corresponding tasks are handed over to the participating nodes; the blockchain replaces the removed aggregation server as a component of the model and information source. In a decentralized federated learning system, participants communicate with each other without the coordination of an aggregation server. Lu et al. [68] proposed a decentralized federated learning (DFL) method to defend against gradient reversal attacks, and demonstrated its security capabilities in a depth gradient leakage (DLG) environment, as shown in Figure 9. Li et al. [69] performs a cluster analysis on model parameters to distinguish good and bad models, and then detect potential malicious participants. Such a defense idea can be applied to detect malicious aggregation servers, and determine through a comparative analysis whether the global model update issued by the aggregation server after each iteration is under attack. Chang et al. [70] proposed a new federated learning framework called Cronus. This framework replaces model parameters with data labels, solving security risks caused by sharing parameters and enabling knowledge transfer.
- (2)
- Improve the anomaly detection capabilities of participants. For data poisoning attacks, there are differences between poisonous samples and normal samples. The most intuitive situational awareness defense strategy is to detect and reject poisonous input samples. Liu et al. [71] used an anomaly detection algorithm to detect toxic samples and rejected their identification. Behavior-based defense ideas were proposed in the literature [15,62,72,73]. This idea identifies potential malicious participants by analyzing the behavioral characteristics of the models uploaded by participants, such as the similarity between local updates and global updates and the error rate after the aggregation of partial models. Udeshi et al. [74] proposed to build a trigger interceptor using the dominant colors in the input image and use it to detect and block the corresponding backdoor trigger. Kieu et al. [75] proposed a method for detecting anomalies in time series datasets based on recursive autoencoders that reduces the impact of overfitting on outliers. To further achieve robust and efficient anomaly detection in time series under unsupervised settings, a variational recurrent encoder model [76] can separate anomalies from normal data without relying on anomaly labels. Table 2 shows the federated learning data poisoning defense effect.
4.2. Strengthen Data Traffic Monitoring
- (1)
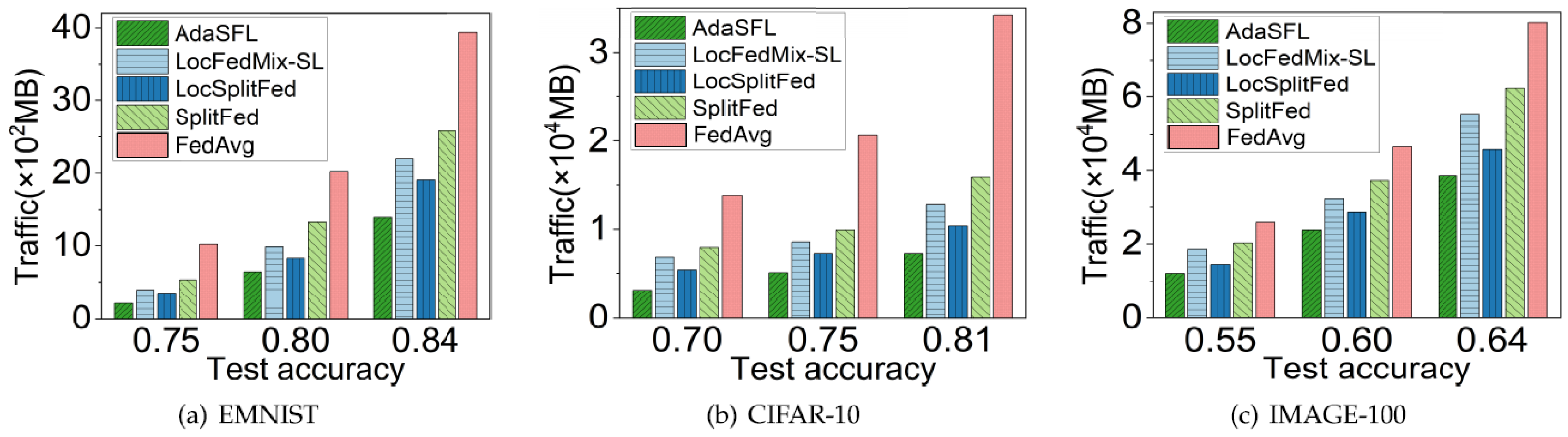
- Based on model compression methods, model compression [78] refers to the method of streamlining the model, which is carried out on the premise of ensuring the accuracy of the model. After model compression, the amount of network parameters and calculations are usually reduced. Model compression can decrease communication overhead and optimize federated learning at the cost of model performance [77]. Xu et al. [79] proposed a federated ternary quantization algorithm, which optimizes the learning model in the client through self-learning. This algorithm aims to solve the problem of updating a large number of redundant parameters in the federated learning process. The authors proved that the convergence of this algorithm is improved. Shah et al. [80] consider the compression techniques of the server model to address the downstream communication and compression techniques of the client model to solve upstream communication, both of which play a crucial role in the development and maintenance of sparsity across communication cycles and have proven to be effective. On the basis of model compression, Caldas S et al. [81] proposed a federated random deactivation (dropout) method to select a subset of the global model to update parameters. Compared to existing work, communication between server and client is reduced by 14× and client-to-server communication is reduced by 28× for EMNIST. Figure 10 shows that for CIFAR-10, server-to-client communication is saved 10 times and client-to-server communication is saved 21 times.
- (2)
- Methods for reducing model update frequency primarily enhance performance by increasing participant calculations and improving parallel computing capabilities. The FedAvg algorithm proposed by Mcmahan et al. [23] combines a local stochastic gradient descent with a server that performs model averaging. The client first iterates local updates multiple times and then sends the local iteration results to the server. This algorithm satisfies the independent and simultaneous data distribution. Good training results can be achieved under distribution assumptions. However, the FedAvg algorithm only has an obvious optimization effect when the data are independent and identically distributed, and its performance is poor when the data are not independently and identically distributed. The FedProx algorithm proposed by Li et al. [82] can dynamically update the number of local calculations required by different clients in each round. It does not require the participants to unify the number of calculations in each update. Therefore, this algorithm is more suitable for non-IID joints. Regarding modeling scenarios, Zhou et al. [83] started from the perspective of the algorithm framework, parallelized communication and training, and proposed the Overlap–FedAvg algorithm based on the set hierarchical computing strategy, data compensation mechanism and Nesterov Accelerated Gradient algorithm.
- (3)
- When dealing with a large number of clients, the federated learning algorithm’s communication with each client can result in low algorithm efficiency based on client selection methods [77]. The existing research addresses this problem by selecting a certain number of clients among many clients and training them as representatives to reduce the communication overhead and optimize the algorithm efficiency. Huang et al. [85] dynamically select clients in each round based on multi-armed bandits; Lai et al. [86] further implemented a federated learning client selection algorithm based on the exploration–exploitation strategy.
4.3. Explore Collaborative Support to Ensure Computing Power
4.4. Improve the Robustness of Situational Awareness
- (1)
- Regarding personalized federation optimization, reference [84,90] proposed an effective method to alleviate the heterogeneity of data and models through a personalization at the device, data and model levels, and provide high-quality personalized models for each device, namely personalized federated learning. This method is widely used in personalized smart medical care [91], smart home services [92], location-aware recommendation services [93] and other scenarios, so personalized federated learning has attracted much attention.
- (2)
- Regarding the optimization of defense against poisoning attacks, the distributed training structure of federated learning is vulnerable to poisoning attacks. Existing methods mainly design security aggregation algorithms for the central server to defend against poisoning attacks, but they require the central server to be trustworthy and the number of poisoned participants to be lower than normal participants. Liu et al. [60] proposed a poisoning attack defense method based on federated learning participants. The main idea is to regard participants as independent executors of defense strategies under the framework of the FedAvg algorithm. During local training, the participant uses a difference calculation function (such as mean square error) to determine the difference loss weight between their local model and the global model parameters. This difference loss weight and function is then integrated into the training loss function. This allows for adaptive personalized training that uses the difference between the global model and the participant’s local model.The federated learning training accuracy of this algorithm is better than poisoning attack defense methods such as Kurm, multi-Kurm, and DnC, as shown in Figure 13. When the proportion of poisoned participants exceeds half, normal participants can still defend against poisoning attacks.
5. Future Research Directions
- (1)
- We can enhance the prediction capability of data poisoning attacks by utilizing generative artificial intelligence (Generative AI). Generative AI can generate synthetic training data, strengthen attack detection models, simulate data distribution and heterogeneous data, and evolve attack strategies. These capabilities have a potential application value and can help improve the ability of federated learning to predict data poisoning attacks. For example, using generative AI models such as GANs can generate large amounts of synthetic training data, including both normal data and malicious poisoning data. This helps train more robust federated learning models to better identify and defend against real-world poisoning attacks. Generative AI can also generate samples under different data distributions to simulate attack scenarios in heterogeneous environments. This helps federated learning models better adapt to data diversity and remain robust in the face of unknown attacks.
- (2)
- We can utilize large language models to enhance our capabilities in predicting data poisoning attacks. Large language models have demonstrated excellent performances in the field of natural language processing (such as Generative Pre-trained Transformer). In recent years, this type of model has also been used in research fields such as federated learning data poisoning attack pattern recognition, federated learning participant trust assessment and secure communication protocol design; it aims to improve its capabilities in data poisoning attack prediction and defense. For example, large language models can analyze and understand communication and update patterns in federated learning networks, training the model to identify the differences between normal and abnormal updates. Utilizing the powerful word processing capabilities of large language models, potential attack patterns can be discovered from model update logs submitted by participants, thereby identifying and preventing data poisoning attacks in advance.
- (3)
- Improve the prediction ability of data poisoning attacks through a graph neural network. Graph neural networks have obvious advantages in processing complex network structure data and have been widely used in many fields in recent years. GNN has demonstrated potential in enhancing federated learning data poisoning attack prediction capabilities. This can be achieved by identifying abnormal communication patterns, modeling participant networks, analyzing global/local structures, and more. Currently, the project team is conducting research on federated learning data poisoning attacks based on graph neural networks. Taking the graph neural network analysis federated learning architecture as an example, GNN can not only capture the local characteristics of each node, but also understands the global network structure by aggregating the neighbor information. This capability allows GNN to assess the security of the network as a whole, as well as reveal signs of data poisoning attacks in detail.
6. Conclusioins
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Voulodimos, A.; Doulamis, N.; Doulamis, A. Deep learning for computer vision: A brief review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef]
- Young, T.; Hazarika, D.; Poria, S. Recent trends in deep learning based natural language processing. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Anil, R.; Dai, A.M.; Firat, O.; Johnson, M.; Lepikhin, D.; Passos, A.; Shakeri, S.; Taropa, E.; Bailey, P.; Chen, Z.; et al. OpenAI. GPT-4 Technical Report. arXiv 2023, arXiv:2305.10403. [Google Scholar]
- Radford, A.; Wu, J.; Child, R. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Chen, M.X.; Zhang, J.B.; Li, T.R. A review of federated learning attack and defense research. Comput. Sci. 2020, 49, 310–323. [Google Scholar]
- Zhang, C.; Xie, Y.; Bai, H. A survey on federated learning. Knowledge-Based Syst. Comput. Sci. 2021, 216, 106775. [Google Scholar]
- Wang, B.; Dai, X.R.; Wang, W. Adversarial sample poisoning attack for federated learning. Chin. Sci. Inf. Sci. 2023, 53, 471–482. [Google Scholar]
- Baruch, M.; Baruch, G.; Goldberg, Y. A little is enough: Circumventing defenses for distributed learning. In Proceedings of the 33rd Int’l Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; ACM: Red Hook, NY, USA, 2019; p. 775. [Google Scholar]
- Fang, M.; Cao, X.; Jia, J.; Gong, N. Local model poisoning attacks to byzantine-robust federated learning. In Proceedings of the 2020 USENIX Security Symposium, Boston, MA, USA, 12–14 August 2020; USENIX Association: Berkeley, CA, USA, 2020; pp. 1605–1622. [Google Scholar]
- Shejwalkar, V.; Houmansadr, A. Manipulating the byzantine:optimizing model poisoning attacks and defenses for federated learning. In Proceedings of the 2021 NDSS, Virtual, 21–25 February 2021; ISOC: Rosten, VA, USA, 2021; pp. 21–24. [Google Scholar]
- Biggio, B.; Nelson, B.; Laskov, P. Poisoning attacks against support vector machines. In Proceedings of the 29th Int’l Conf. on Machine Learning, Edinburgh, UK, 26 June–1 July 2012; ACM: Edinburgh, UK, 2012; pp. 1467–1474. [Google Scholar]
- Zhang, J.L.; Chen, B.; Cheng, X.; Binh, H.; Yu, S. PoisonGAN: Generative poisoning attacks against federated learning in edge computing systems. IEEE Internet Things J. 2021, 8, 3310–3322. [Google Scholar] [CrossRef]
- Tolpegin, V.; Truex, S.; Gursoy, M.E.; Liu, L. Data poisoning attacks against federated learning systems. In Proceedings of the 25th European Symp. on Computer Security, Guildford, UK, 14–18 September 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 480–501. [Google Scholar]
- Chen, Q.; Chai, Z.; Wang, Z.l. Poisoning Attack Detection Scheme in Federated Learning Based on Generative Adversarial Networks. Available online: http://kns.cnki.net/kcms/detail/51.1307.TP.20230522.1041.004.html (accessed on 27 October 2023).
- Yin, D.; Chen, Y.; Kannan, R. Byzantine-robust distributed learning:Towards optimal statistical rates. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; JMLR: San Diego, CA, USA, 2018; pp. 5650–5659. [Google Scholar]
- Steinhardt, J.; Koh, P.W.; Liang, P. Certified defenses for data poisoning attack. In Proceedings of the 31st International Conference on Neural Information Proceedings Systems, Long Beach, CA, USA, 4–9 December 2017; NIPS: La Jolla, CA, USA, 2017; pp. 3520–3532. [Google Scholar]
- Bhagoji, A.N.; Chakraborty, S.; Mittal, P. Analyzing federated learning through an adversarial lens. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; JMLR: San Diego, CA, USA, 2019; pp. 634–643. [Google Scholar]
- Feng, J.; Xu, H.; Mannor, S. Robust logistic regression and classification. In Proceedings of the 27th International Conference on Neural Information Proceeding Systems, Bangkok, Thailand, 18–22 November 2020; NIPS: La Jolla, CA, USA, 2014; pp. 253–261. [Google Scholar]
- Zhao, Y.; Chen, J.; Zhang, J. Detecting and mitigating poisoning attacks in federated learning using generative adversarial networks. Concurr. Comput. Pract. Exp. 2020, 34, e5906. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-abadie, J.; Mirza, M. Generative adversarial nets. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Jagielski, M.; Oprea, A.; Biggio, B. Manipulating machine learning: Poisoning attacks and countermeasures for regression learning. In Proceedings of the 39th IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 21–23 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 19–35. [Google Scholar]
- Li, T.; Sahu, A.K.; Talwalkar, A. Federated learning: Challenges, methods, and future directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A.Y. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; JMLR: Fort Lauderdale, FL, USA, 2017; pp. 1273–1282. [Google Scholar]
- Gu, Y.H.; Bai, Y.M. Research progress on security and privacy of federated learning models. J. Softw. 2023, 34, 2833–2864. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, T.J.; Tong, Y.X. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. 2019, 10, 12. [Google Scholar] [CrossRef]
- Chen, X.H.; Ren, Z.Q.; Zhang, H.Y. Overview of Security Threats and Defense Measures in Federated Learning. Available online: http://kns.cnki.net/kcms/detail/51.1307.TP.20230731.1744.024.html (accessed on 23 October 2023).
- Li, M.H.; Wan, W.; Lu, J.R. Shielding federated learning: Mitigating by zantine attacks with less constraints. In Proceedings of the 18th IEEE International Conference on Mobility, Sensing and Networking, Guangzhou, China, 14–16 December 2022; IEEE: Piscataway, NJ, USA, 2022; p. 178185. [Google Scholar]
- Sun, G.; Cong, Y.; Dong, J.; Wang, Q.; Lyu, L.; Liu, J. Data poisoning attacks on federated machine learning. IEEE Internet Things J. 2021, 9, 11365–11375. [Google Scholar] [CrossRef]
- Zhang, J.; Chen, J.; Wu, D.; Chen, B.; Yu, S. Poisoning attack in federated learning using generative adversarial nets. In Proceedings of the 2019 IEEE International Conference on Big Data Science and Engineering, Los Angeles, CA, USA, 9–12 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 374–380. [Google Scholar]
- Bagdasaryan, E.; Veit, A.; Hua, Y.; Estrin, D.; Shmatikov, V. How to backdoor federated learning. In Proceedings of the 2020 International Conference on Artificial Intelligence and Statistics, Virtual, 26–28 August 2020; PMLR: New York, NY, USA, 2020; pp. 2938–2948. [Google Scholar]
- Wang, H.J.; Liang, Y.N.; Li, L.; Li, R. Overview of privacy protection mechanisms in federated learning. Mod. Comput. 2022, 28, 1–12. [Google Scholar]
- Fung, C.; Yoo, C.J.M.; Beschastnikh, I. Mitigating Sybils in Federated Learning Poisoning. arXiv 2018, arXiv:1808.04866. [Google Scholar]
- Han, X.; Huang, X.; Claudia, E. Adversarial label flips attack on support vector machines. In ECAI 2012; IOS Press: Amsterdam, The Netherlands, 2012; pp. 870–875. [Google Scholar]
- Shi, L.; Chen, Z.; Shi, Y.C.; Zhao, G.; Wei, L.; Tao, Y.; Gao, Y. Data Poisoning Attacks on Federated Learning by Using Adversarial Samples. In Proceedings of the 2022 International Conference on Computer Engineering and Artificial Intelligence (ICCEAI), Shijiazhuang, China, 22–24 July 2022; pp. 158–162. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing Properties of Neural Networks. arXiv 2023, arXiv:1312.6199. [Google Scholar]
- Wang, H.Y.; Sreenivasan, K.; Rajput, S.; Vishwakarma, H.; Agarwal, S.; Sohn, J.Y.; Lee, K.; Papailiopoulos, D. Attack of the Tails: Yes, You Really Can Backdoor Federated Learning. arXiv 2023, arXiv:2007.05084. [Google Scholar]
- Sha, F.H.; Huang, W.R.; Na, J.B.M.; Suciu, O.; Studer, C.; Dumitras, T.; Goldstein, T. Poison Frogs! Targeted Clean-Label Poisoning Attacks on Neural Networks. arXiv 2018, arXiv:1804.00792. [Google Scholar]
- Dwork, C.; Mcsherry, F.; Nissim, K.; Smith, A. Calibrating noise to sensitivity in private data analysis. In Theory of Cryptography Conference; Springer: Berlin/Heidelberg, Germany, 2006; pp. 265–284. [Google Scholar]
- Rivest, R.L.; Adleman, L.; Dertouzos, M.L. On data banks and privacy homomorphisms. Found. Secur. Comput. 1978, 4, 169–180. [Google Scholar]
- Yao, A.C. Protocols for secure computations. In Proceedings of the 23rd Annual Symposium on Foundations Of Computer Science (SFCS 1982), Chicago, IL, USA, 3–5 November 1982; IEEE: Piscataway, NJ, USA, 1982; pp. 160–164. [Google Scholar]
- Endsley, M.R. Toward a theory of situation awareness in dynamic system. Found. Secur. Comput. 1995, 37, 32–64. [Google Scholar] [CrossRef]
- Franke, U.; Brynielsson, J. Cyber situational awareness a systematic review of the literature. Comput. Secur. 2014, 46, 18–31. [Google Scholar] [CrossRef]
- Lenders, V.; Tanner, A.; Blarer, A. Gaining an edge in cyberspace with advanced situational awareness. Secur. Priv. IEEE 2015, 13, 65–74. [Google Scholar] [CrossRef]
- Bass, T. Intrusion Detection Systems and Data Fusion. Commun. ACM 2000, 43, 99–105. [Google Scholar] [CrossRef]
- Gong, J.; Zang, X.D.; Su, Q. A review of network security situational awareness. J. Softw. 2017, 28, 1010–1026. [Google Scholar]
- Wang, S.; Li, Q.; Cui, Z.; Hou, J.; Huang, C. Bandit-based data poisoning attack against federated learning for autonomous driving models. Expert Syst. Appl. 2023, 227, 120295. [Google Scholar] [CrossRef]
- Talpur, A.; Gurusamy, M. GFCL: A GRU-based Federated Continual Learning Framework against Data Poisoning Attacks in IoV. arXiv 2022, arXiv:2204.11010. [Google Scholar]
- Shahid, A.R.; Ahmed, I.; Shahriar, B.; Md, Z.H. Assessing Wearable Human Activity Recognition Systems Against Data Poisoning Attacks in Differentially-Private Federated Learning. In Proceedings of the 2023 IEEE International Conference on Smart Computing (SMARTCOMP), Nashville, TN, USA, 26–30 June 2023; pp. 355–360. [Google Scholar]
- Hong, L.T.; Aono, Y.; Hayashi, T.; Wang, L.H.; Moriai, S. Privacy-preserving deep learning via additively homomorphic encryption. IEEE Trans. Inf. Forensics Secur. 2018, 13, 1333–1345. [Google Scholar]
- Fredrikson, M.; Lantz, E.; Jha, S. Privacy in pharmacogenetics: An end-to-end case study of personalized warfarin dosing. In Proceedings of the USENIX Security Symposium, Philadelphia, PA, USA, 19–20 June 2014; USENIX Association: Berkeley, CA, USA, 2014; pp. 17–32. [Google Scholar]
- Zhu, T.Q.; Ye, D.Y.; Zhou, S. Label-only model inversion attacks: Attack with the least information. IEEE Trans. Inf. Forensics Secur. 2023, 18, 991–1005. [Google Scholar] [CrossRef]
- Guo, J.J.; Liu, J.Z.; Ma, Y.; Liu, Z.Q.; Xiong, Y.P.; Miao, K.; Li, J.X.; Ma, J.F. Federated learning backdoor attack defense method based on model watermark. J. Comput. Sci. 2024, 47, 622–676. [Google Scholar]
- Jere, M.S.; Farnan, T.; Koushanfar, F. A taxonomy of attacks on federated learning. IEEE Secur. Priv. 2021, 19, 20–28. [Google Scholar] [CrossRef]
- Zhou, C.X.; Sun, Y.; Wang, D.G. A review of federated learning research. J. Netw. Inf. Secur. 2021, 7, 77–92. [Google Scholar]
- Konecny, J.; Mcmahan, H.B.; Yu, F.X. Federated learning: Strategies for improving communication efficiency. arXiv 2016, arXiv:1610.05492. [Google Scholar]
- Wang, L.; Wang, W.; Bo, L.I. CMFL: Mitigating Communication Overhead for Federated Learning. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–9 July 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Paudice, A.; Muñoz-González, L.; Gyorgy, A. Detection of adversarial training examples in poisoning attacks through anomaly detection. arXiv 2018, arXiv:1802.03041. [Google Scholar]
- Wu, Q.; He, K.W.; Chen, X. Personalized federated learning for intelligent iot applications: A cloud-edge based framework. arXiv 2020, arXiv:2002.10671. [Google Scholar] [CrossRef]
- Long, Y.C. Research on Adversarial Attacks and Robustness of Vertical Federated Learning; Guangzhou University: Guangzhou, China, 2023. [Google Scholar]
- Liu, J.Q.; Zhang, Z.; Chen, Z.D. A poisoning attack defense method based on federated learning participants. Comput. Appl. Res. 2023, 7, 0340. [Google Scholar]
- Liu, B.; Zhang, F.J.; Wang, W.X. Byzantine Robust Federated Learning Algorithm Based on Matrix Mapping. Comput. Res. Dev. 2021, 58, 2416–2429. [Google Scholar]
- Blanchard, P.; El, M.E.M.; Guerraoui, R. Machine Learning with Adversaries: Byzantine Tolerant Gradient Descent. In Proceedings of the Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017; NIPS Foundation: San Diego, CA, USA, 2017; pp. 119–129. [Google Scholar]
- Lu, Y.; Fan, L. An Efficient and Robust Aggregation Algorithm for Learning Federated CNN. In Proceedings of the 2020 3rd International Conference on Signal Processing and Machine Learning, Beijing, China, 22–24 October 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1–7. [Google Scholar]
- Pillutla, K.; Kakade, S.M.; Harchaoui, Z. Robust Aggregation for Federated Learning. IEEE Trans. Signal Process. 2019, 70, 1142–1154. [Google Scholar] [CrossRef]
- Fung, C.; Yoon, C.J.M.; Beschastnikh, I. The Limitations of Federated Learning in Sybil Settings. In Proceedings of the International Symposium on Recent Advances in Intrusion Detection (RAID 2020), Virtual, 14–16 October 2020; USENIX Association: Berkeley, CA, USA, 2020; pp. 301–316. [Google Scholar]
- Chen, D.; Jiang, X.; Zhong, H.; Cui, J. Building Trusted Federated Learning: Key Technologies and Challenges. J. Sens. Actuator Netw. 2023, 12, 13. [Google Scholar] [CrossRef]
- Li, L.X.; Yuan, S.; Jin, Y. Overview of federated learning technology based on blockchain. Comput. Appl. Res. 2021, 38, 3222–3230. [Google Scholar]
- Lu, G.X.; Xiong, Z.B.; Li, R.N. Decentralized Federated Learning: A Defense Against Gradient Inversion Attack. In Proceedings of the International Wireless Internet Conference 2022, Virtual, 17 November 2022; pp. 301–316. [Google Scholar]
- Li, D.; Wang, W.E.; Wang, W.; Yao, Y.; Chau, M. Detection and mitigation of label-flipping attacks in federated learning systems with KPCA and K-means. In Proceedings of the 2021 International Conference on Dependable Systems and Their Applications (DSA), Yinchuan, China, 11–12 September 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 551–559. [Google Scholar]
- Chan, H.Y.; Shejwalkar, V.; Shokri, R.; Houmansadr, A. Cronus: Robust and heterogeneous collaborative learning with black-box knowledge transfer. arXiv 2019, arXiv:1912.11279. [Google Scholar]
- Liu, Y.; Xie, Y.; Srivastava, A. Neural Trojans. In Proceedings of the 2017 IEEE International Conference on Computer Design (ICCD), Boston, MA, USA, 5–8 November 2017; pp. 45–48. [Google Scholar]
- Muñoz-González, L.; Co, K.T.; Lupu, E.C. Byzantine-robust federated machine learning through adaptive model averaging. arXiv 2019, arXiv:1909.05125. [Google Scholar]
- Awan, S.; Luo, B.; Li, F. Contra: Defending against poisoning attacks in federated learning. In Proceedings of the 2021 European Symposium on Research in Computer Security, Virtual, 4–8 October 2021; Springer: Cham, Switzerland, 2021; pp. 455–475. [Google Scholar]
- Udeshi, S.; Peng, S.; Woo, G.; Loh, L.; Rawshan, L.; Chattopadhyay, S. Model agnostic defence against backdoor attack in machine learning. arXiv 2019, arXiv:1908.02203. [Google Scholar] [CrossRef]
- Kieu, T.; Yang, B.; Guo, C. Outlier detection for time series with recurrent autoencoder ensembles. In Proceedings of the International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 2725–2732. [Google Scholar]
- Kieu, T.; Yang, B.; Guo, C. Anomaly detection in time series with robust variational quasi-recurrent autoencoders. In Proceedings of the IEEE International Conference on Data Engineering, Kuala Lumpur, Malaysia, 9–12 May 2022; pp. 1342–1354. [Google Scholar]
- Yang, Q.; Tong, Y.X.; Wang, Y.S. A review of federated learning algorithms in swarm intelligence. Chin. J. Intell. Sci. Technol. 2022, 4, 29–44. [Google Scholar]
- Li, J.; Zhao, Y.; Xue, Z.; Cai, Z.; Li, Q. A review of deep neural network model compression. J. Eng. Sci. 2019, 41, 1229–1239. [Google Scholar]
- Xu, J.J.; Du, W.L.; Jin, Y.C.; He, W.; Cheng, R. Ternary compression for communication-efficient federated learning. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 1162–1176. [Google Scholar] [CrossRef] [PubMed]
- Shah, S.M.; Lau, V.K. Model Compression for Communication Efficient Federated Learning. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 5937–5951. [Google Scholar] [CrossRef] [PubMed]
- Caldas, S.; Konecny, J.; Mcmahan, H.B. Expanding the reach of federated learning by reducing client resource requirements. arXiv 2018, arXiv:1812.07210. [Google Scholar]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization for heterogeneous networks. arXiv 2021, arXiv:1812.06127. [Google Scholar]
- Zhou, Y.H.; Ye, Q.; Lv, J.C. Communication-efficient federated learning with compensated Overlap-FedAvg. IEEE Trans. Parallel Distrib. Syst. 2022, 33, 192–205. [Google Scholar] [CrossRef]
- Bellet, A.; Guerraoui, R.; Taziki, M.; Tommasi, M. Personalized and private peer-to-peer machine learning. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Playa Blanca, Spain, 9–11 April 2018; pp. 473–481. [Google Scholar]
- Huang, T.S.; Lin, W.W.; Wu, W.T.; He, L.; Li, K.; Zomaya, A.Y. An efficiency-boosting client selection scheme for federated learning with fairness guarantee. IEEE Trans. Parallel Distrib. Syst. 2021, 32, 1552–1564. [Google Scholar] [CrossRef]
- Lai, F.; Zhu, X.F.; Madhyastha, H.; Chowdhury, M. Oort: Informed participant selection for scalable federated learning. arXiv 2020, arXiv:2010.06081. [Google Scholar]
- Rajbhandari, S.; Rasley, J.; Ruwase, O.; He, Y. ZeRO: Memory optimizations Toward Training Trillion Parameter Models. In Proceedings of the SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, Atlanta, GA, USA, 9–19 November 2020; pp. 1–16. [Google Scholar]
- Chen, C.C.; Feng, X.H.; Zhou, J.; Yin, J.W.; Zheng, X.L. Federated Large Language Model: A Position Paper. arXiv 2023, arXiv:2307.08925. [Google Scholar]
- Liao, Y.; Xu, Y.; Xu, H.; Yao, Z.; Wang, L.; Qiao, C. Accelerating Federated Learning with Data and Model Parallelism in Edge Computing. IEEE/ACM Trans. Netw. 2024, 32, 904–918. [Google Scholar] [CrossRef]
- Vanhaesebrouck, P.; Bellet, A.; Tommasi, M. Decentralized collaborative learning of personalized models over networks. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Cadiz, Spain, 9–11 May 2016; pp. 509–517. [Google Scholar]
- Jin, T.; Pan, S.; Li, X.; Chen, S. Metadata and Image Features Co-Aware Personalized Federated Learning for Smart Healthcare. IEEE J. Biomed. Health Inform. 2023, 27, 4110–4119. [Google Scholar] [CrossRef]
- Rasti-Meymandi, A.; Sheikholeslami, S.M.; Abouei, J.; Plataniotis, K.N. Graph Federated Learning for CIoT Devices in Smart Home Applications. IEEE Internet Things J. 2023, 10, 7062–7079. [Google Scholar] [CrossRef]
- Ye, Z.; Zhang, X.; Chen, X.; Xiong, H.; Yu, D. Adaptive Clustering based Personalized Federated Learning Framework for Next POI Recommendation with Location Noise. IEEE Trans. Knowl. Data Eng. 2023, 10, 1–14. [Google Scholar] [CrossRef]
- Xie, C.; Koyejo, S.; Gupta, I. Asynchronous Federated Optimization. arXiv 2019, arXiv:1903.03934. [Google Scholar]
- Kulkarni, V.; Kulkarni, M.; Pant, A. Survey of personalization techniques for federated learning. arXiv 2020, arXiv:2003.08673. [Google Scholar]
- Mansour, Y.; Mohri, M.; Ro, J.; Suresh, A.T. Three approaches for personalization with applications to federated learning. arXiv 2020, arXiv:2002.10619. [Google Scholar]
- Schneider, J.; Vlachos, M. Mass personalization of deep learning. arXiv 2019, arXiv:1909.02803. [Google Scholar]
- Smith, V.; Chiang, C.K.; Sanjabi, M.; Talwalkar, A.S. Federated multi-task learning. Adv. Neural Inf. Process. Syst. 2017, 30, 4424–4434. [Google Scholar]
- Li, D.; Wang, J. Fedmd: Heterogenous federated learning via model distillation. arXiv 2019, arXiv:1910.03581. [Google Scholar]
- Jiang, Y.; Konecny, J.; Rush, K.; Kannan, S. Improving federated learning personalization via model agnostic meta learning. arXiv 2019, arXiv:1909.12488. [Google Scholar]
- Arivazhagan, M.G.; Aggarwal, V.; Singh, A.K.; Choudhary, S. Federated learning with personalization layers. arXiv 2019, arXiv:1912.00818. [Google Scholar]
- Hanzely, F.; Richtarik, P. Federated learning of a mixture of global and local models. arXiv 2020, arXiv:2002.05516. [Google Scholar]
- Chen, X.B.; Ren, Z.Q. PFKD: A personalized federated learning framework that comprehensively considers data heterogeneity and model heterogeneity. J. Nanjing Univ. Inf. Sci. Technol. (Natural Sci. Ed.) 2023, 32, 1–10. [Google Scholar]
- Shen, T.; Zhang, J.; Jia, X.K.; Zhang, F.; Lv, Z.; Kuang, K.; Wu, C.; Wu, F. Federated mutual learning: A collaborative machine learning method for heterogeneous data, models and goals (English). Front. Inf. Technol. Electron. Eng. 2023, 24, 1390–1403. [Google Scholar] [CrossRef]
- Dinh, C.T.; Tran, N.H.; Nguyen, T.D. Personalized federated learning with moreau envelopes. arXiv 2020, arXiv:2006.08848. [Google Scholar]
- Yuan, B.; Qiu, W. Personalized Federated Learning System Based on Permissioned Blockchain. In Proceedings of the 2021 International Conference on Intelligent Computing, Automation and Systems (ICICAS), Chongqing, China, 29–31 December 2021; pp. 95–100. [Google Scholar]
- Ibitoye, O.; Shafiq, M.O.; Matrawy, A. DiPSeN: Differentially Private Self–Normalizing Neural Networks For Adversarial Robustness in Federated Learning. arXiv 2021, arXiv:2101.03218. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. arXiv 2015, arXiv:1412.6572. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Literature | Attack Type | Attack Methodology | Attack Evaluation Index | DataSet | Training Settings/ (Number–Items) | Result% |
|---|---|---|---|---|---|---|
| [28] | Untargeted poisoning | Utilizing the projected stochastic gradient ascent algorithm to maximize the experience loss of the target node | Model error rate | EndAD | 6:*:no-iid | Base: 6.88 ± 0.52 Result: 28.588 ± 3.74 |
| [11] | Untargeted poisoning | Predict changes in the SVM decision function caused by malicious input and use this ability to construct malicious data | Model error rate | MNIST | *:*:* | Base: 2–5 Result: 15–20 |
| [13] | Targeted poisoning | Aim for successful poisoning in the final rounds and choose the right tag to flip | Maximum recall loss | CIFAR-10 | 50:*:iid | Base: 0 Result: 2:1.42; 20:25.4 |
| [29] | Targeted poisoning | Utilize GAN technology to generate data and implement label flipping | Poisoning task accuracy rate | MNIST | 10:*:no-iid | Base: 0 Result: 20:60±; 40:80±; 60:85± |
| Literature | Attack Type | Defensive Thinking | Defense Mode | Defensive Indicators | Defense Result |
|---|---|---|---|---|---|
| [62] | Untargeted poisoning | Behavior based | Aggregating models using robust distributed gradient descent algorithms | Model error rate | Base: 10± Attack: 60± After: 10± |
| [15] | Targeted poisoning | Behavior based | Aggregating models using robust distributed gradient descent algorithms | Model accuracy | Base: 94.3± Attack: 77.3± After: 90.7± |
| [69] | Targeted poisoning | Based on clustering | Use clustering algorithms to identify malicious models | Model accuracy | Base: 78± Attack: 76±; 74.5± After: 78±; 77.5± |
| [72] | Targeted poisoning | Behavior based | Determine the malicious model based on the cosine similarity between the local model and global model | Model error rate | Base: 2.80 ± 0.12 Attack: unknown After: 2.99 ± 0.12±, 2.96 ± 0.15; 3.04 ± 0.14 |
| [73] | Targeted poisoning | Behavior based | Determine the malicious model based on the cosine similarity between the local model and global model and combined with the reputation mechanism | Model accuracy | Base: unknown Attack: unknown After: 83.11; 81.23 |
| Model | Dataset | Parameters | FedAvg | Overlap–FedAvg |
|---|---|---|---|---|
| MLP | Mnist | 199,210 | 31.2 | 28.85 (↓7.53%) |
| MnistNet | Fmnist | 1,199,882 | 32.96 | 28.31 (↓14.11%) |
| MnistNet | Emnist | 1,199,882 | 47.19 | 42.15 (↓10.68%) |
| CNNCifar | Cifar10 | 878,538 | 48.07 | 45.33 (↓5.70%) |
| VGG | Cifar10 | 2,440,394 | 64.4 | 49.33 (↓23.40%) |
| ResNet | Cifar10 | 11,169,162 | 156.88 | 115.31 (↓26.50%) |
| ResNet | Cifar100 | 11,169,162 | 156.02 | 115.3 (↓26.10%) |
| Transformer | Wikitext-2 | 13,828,478 | 133.19 | 87.9 (↓34.0%) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, J.; Jin, J.; Wu, C. Challenges and Countermeasures of Federated Learning Data Poisoning Attack Situation Prediction. Mathematics 2024, 12, 901. https://doi.org/10.3390/math12060901
Wu J, Jin J, Wu C. Challenges and Countermeasures of Federated Learning Data Poisoning Attack Situation Prediction. Mathematics. 2024; 12(6):901. https://doi.org/10.3390/math12060901
Chicago/Turabian StyleWu, Jianping, Jiahe Jin, and Chunming Wu. 2024. "Challenges and Countermeasures of Federated Learning Data Poisoning Attack Situation Prediction" Mathematics 12, no. 6: 901. https://doi.org/10.3390/math12060901