

Wasserstein Dissimilarity for Copula-Based Clustering of Time Series with Spatial Information

Abstract
:1. Introduction
- The Wasserstein distance allows for a meaningful comparison between distributions also without density. This property is not shared by the most common distances and divergences, such as the total variation distance, the Hellinger distance, or the Kullback–Leibler divergence (see, e.g., [36]).
- The Wasserstein metric seems to be more appropriate to measure distance between copulas since it does not lead to counter-intuitive clusters (see, e.g., [37]).
2. Background on Optimal Transport, Wasserstein Distance, and Copulas
3. The Methodology
- Determine the copula that describes the temporal dependence between the i-th and j-th time series.
- Determine the copula that interprets the spatial proximity between the attribute vectors and associated with the i-th and j-th time series.
- Merge and into one single copula that represents their weighted barycenter. This copula depends on the tuning parameter . Then, definei.e., the distance of from the comonotonicity copula M, which represents maximal concordance.
3.1. Extract the Temporal Dependence
- a parametric approach, i.e., one assumes that belongs to the same specific family of copulas, whose parameter can be fitted via, e.g, maximum likelihood techniques. See, e.g., [57].
3.2. Extract the Spatial Dependence
3.3. Create the Dissimilarity Measure
4. The Quasi-Gaussian Approach
- The copula from Section 3.1 is replaced with the G-copula with correlation matrix , where equals the estimation of the normal score correlation among the involved observations (as suggested in [38]).
- The copula from Section 3.2 is replaced with the G-copula with correlation matrix , where is the unique value that solveswhere is the normalized distance between and . Notice that is the (singular) correlation matrix showing maximal dependence (comonotonic case). For the existence and uniqueness of see Remark 2. In particular, we notice that since , the maximal spatial distance is interpreted by the vector of independent components.
- For a fixed , the copula from Section 3.3 is replaced with the G-copula having the correlation matrixwhere is the weighted barycenter of and given by (6) and D is the diagonal matrix associated with . In other words, we transform the covariance matrix of the weighted barycenter into a correlation matrix with the natural projection.
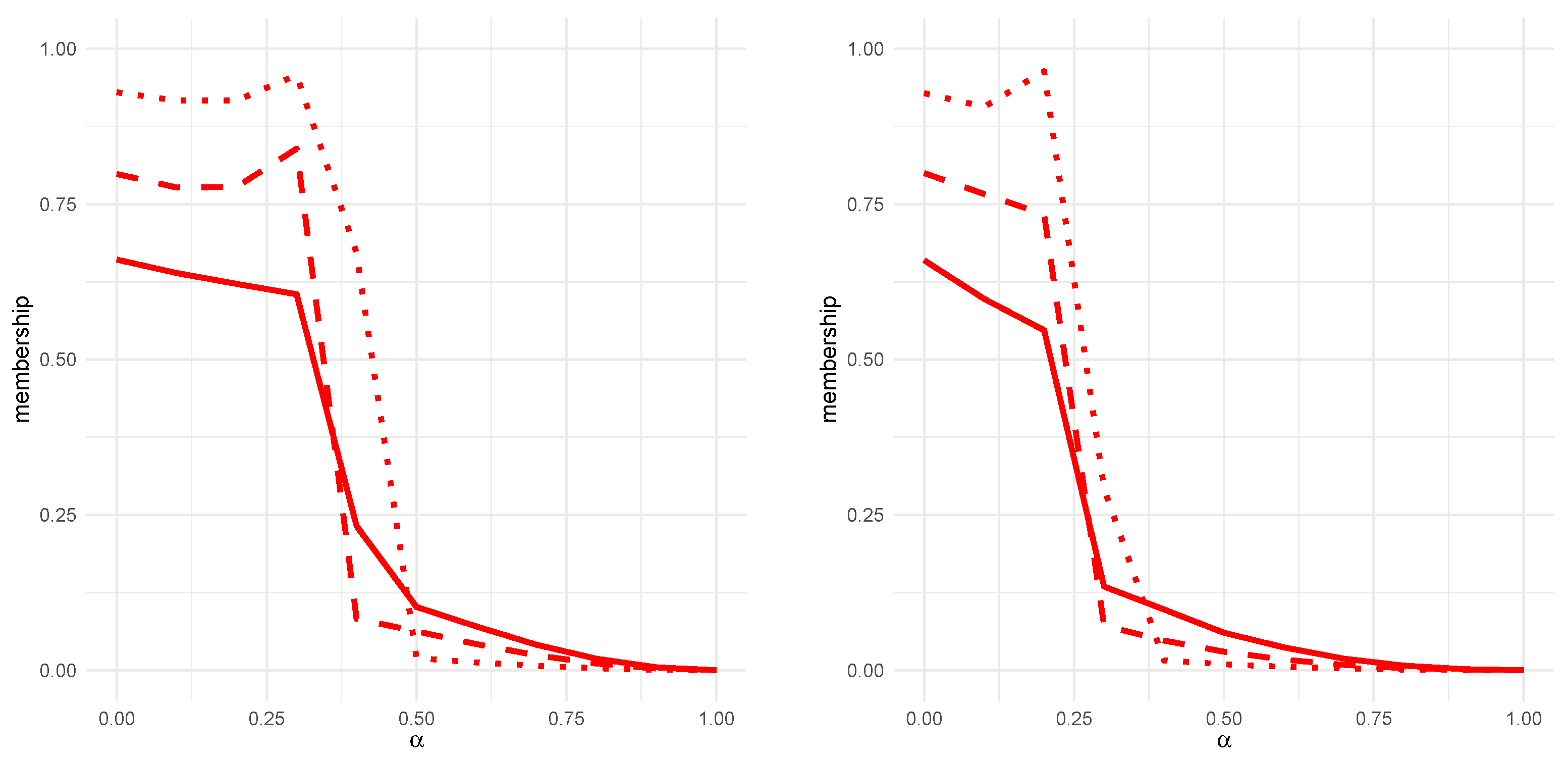
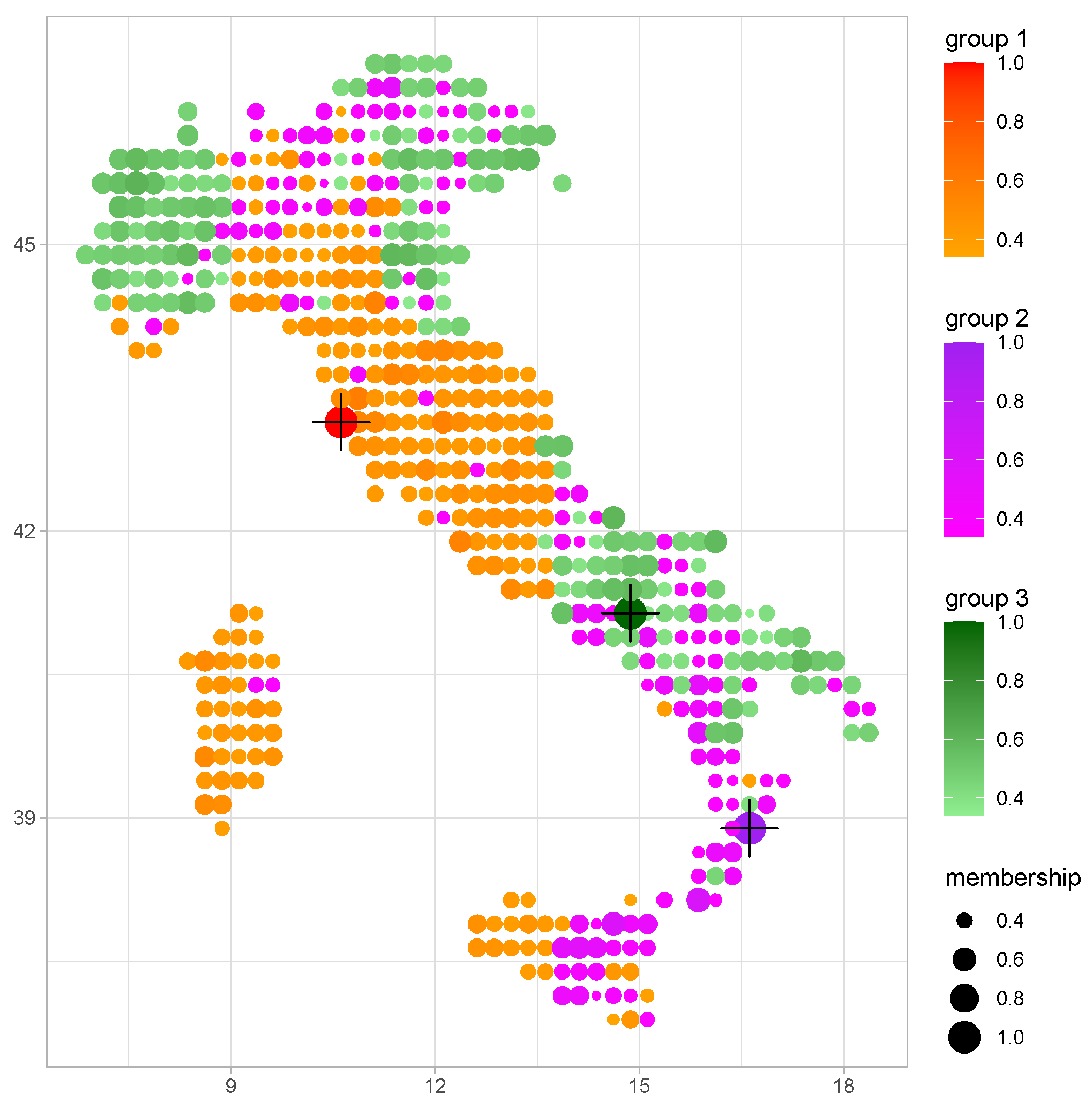
5. An Illustration with a Fuzzy-PAM Algorithm
6. An Empirical Application
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
- , ;
- , ;
- , where is the Pearson’s correlation between U and V.
References
- Hennig, C.; Meila, M.; Murtagh, F.; Rocci, R. Handbook of Cluster Analysis; Chapman and Hall/CRC Handbook of Modern Statistical Methods; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- Maharaj, E.A.; D’Urso, P.; Caiado, J. Time Series Clustering and Classification; Chapman Hall/CRC Computing and Data Analytics Series; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Caiado, J.; Maharaj, E.A.; D’Urso, P. Time-series clustering. In Handbook of Cluster Analysis; Hennig, C., Meila, M., Murtagh, F., Rocci, R., Eds.; CRC Press: Boca Raton, FL, USA, 2016; pp. 241–263. [Google Scholar]
- Di Lascio, F.; Durante, F.; Pappadà, R. Copula–based clustering methods. In Copulas and Dependence Models with Applications; Úbeda Flores, M., de Amo, E., Durante, F., Fernández Sánchez, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2017; pp. 49–67. [Google Scholar]
- Marti, G.; Nielsen, F.; Bińkowski, M.; Donnat, P. A Review of Two Decades of Correlations, Hierarchies, Networks and Clustering in Financial Markets. In Progress in Information Geometry: Theory and Applications; Nielsen, F., Ed.; Springer: Cham, Switzerland, 2021; pp. 245–274. [Google Scholar]
- De Luca, G.; Zuccolotto, P. A tail dependence-based dissimilarity measure for financial time series clustering. Adv. Data Anal. Classif. 2011, 5, 323–340. [Google Scholar] [CrossRef]
- De Luca, G.; Zuccolotto, P. Hierarchical time series clustering on tail dependence with linkage based on a multivariate copula approach. Internat. J. Approx. Reason. 2021, 139, 88–103. [Google Scholar] [CrossRef]
- Durante, F.; Pappadà, R.; Torelli, N. Clustering of time series via non–parametric tail dependence estimation. Statist. Pap. 2015, 56, 701–721. [Google Scholar] [CrossRef]
- Bonanomi, A.; Nai Ruscone, M.; Osmetti, S.A. Dissimilarity measure for ranking data via mixture of copulae. Stat. Anal. Data Min. Asa Data Sci. J. 2019, 12, 412–425. [Google Scholar] [CrossRef]
- De Keyser, S.; Gijbels, I. Hierarchical variable clustering via copula-based divergence measures between random vectors. Int. J. Approx. Reason. 2023, 21, 109090. [Google Scholar] [CrossRef]
- Disegna, M.; D’Urso, P.; Durante, F. Copula-based fuzzy clustering of spatial time series. Spat. Stat. 2017, 21, 209–225. [Google Scholar] [CrossRef]
- Kojadinovic, I. Agglomerative hierarchical clustering of continuous variables based on mutual information. Comput. Stat. Data Anal. 2004, 46, 269–294. [Google Scholar] [CrossRef]
- Zhang, B.; An, B. Clustering time series based on dependence structure. PLoS ONE 2018, 13, e0206753. [Google Scholar] [CrossRef]
- De Luca, G.; Zuccolotto, P. A double clustering algorithm for financial time series based on extreme events. Stat. Risk Model. 2017, 34, 1–12. [Google Scholar] [CrossRef]
- Durante, F.; Pappadà, R.; Torelli, N. Clustering of financial time series in risky scenarios. Adv. Data Anal. Classif. 2014, 8, 359–376. [Google Scholar] [CrossRef]
- Pappadà, R.; Durante, F.; Salvadori, G.; De Michele, C. Clustering of concurrent flood risks via Hazard Scenarios. Spat. Stat. 2018, 23, 124–142. [Google Scholar] [CrossRef]
- Saunders, K.R.; Stephenson, A.G.; Karoly, D.J. A regionalisation approach for rainfall based on extremal dependence. Extremes 2021, 24, 1386–1999. [Google Scholar] [CrossRef]
- Fouedjio, F. Clustering of multivariate geostatistical data. WIREs Comput Stat. 2020, 12, e1510. [Google Scholar] [CrossRef]
- Kopczewska, K. Spatial machine learning: New opportunities for regional science. Ann. Reg. Sci. 2022, 68, 713–755. [Google Scholar] [CrossRef]
- Asgharian, H.; Hess, W.; Liu, L. A spatial analysis of international stock market linkages. J. Bank. Financ. 2013, 37, 4738–4754. [Google Scholar] [CrossRef]
- Fernández-Avilés, G.; Montero, J.M.; Orlov, A.G. Spatial modeling of stock market comovements. Fin. Res. Lett. 2012, 9, 202–212. [Google Scholar] [CrossRef]
- Hüttner, A.; Scherer, M.; Gräler, B. Geostatistical modeling of dependent credit spreads: Estimation of large covariance matrices and imputation of missing data. J. Bank. Financ. 2020, 118, 105897. [Google Scholar] [CrossRef]
- Oliver, M.A.; Webster, R. A geostatistical basis for spatial weighting in multivariate classification. Math. Geol. 1989, 21, 15–35. [Google Scholar] [CrossRef]
- Coppi, R.; D’Urso, P.; Giordani, P. A fuzzy clustering model for multivariate spatial time series. J. Class. 2010, 27, 54–88. [Google Scholar] [CrossRef]
- Fouedjio, F. A hierarchical clustering method for multivariate geostatistical data. Spat. Stat. 2016, 18, 333–351. [Google Scholar] [CrossRef]
- D’Urso, P.; Vitale, V. A robust hierarchical clustering for georeferenced data. Spat. Stat. 2020, 35, 100407. [Google Scholar] [CrossRef]
- Di Lascio, F.; Menapace, A.; Pappadà, R. A spatially-weighted AMH copula-based dissimilarity measure for clustering variables: An application to urban thermal efficiency. Environmetrics 2023, e2828. [Google Scholar] [CrossRef]
- Zuccolotto, P.; De Luca, G.; Metulini, R.; Carpita, M. Modeling and clustering of traffic flows time series in a flood prone area. In Proceedings of the Statistics and Data Science Conference; Cerchiello, P., Agosto, A., Osmetti, S., Spelta, A., Eds.; EGEA: Pavia, Italy, 2023; pp. 113–118. [Google Scholar]
- Benevento, A.; Durante, F. Correlation-based hierarchical clustering of time series with spatial constraints. Spat. Stat. 2024, 59, 100797. [Google Scholar] [CrossRef]
- Romary, T.; Ors, F.; Rivoirard, J.; Deraisme, J. Unsupervised classification of multivariate geostatistical data: Two algorithms. Comput. Geosci. 2015, 85, 96–103. [Google Scholar] [CrossRef]
- Benevento, A.; Durante, F.; Pappadà, R. An approach to cluster time series extremes with spatial constraints. In Proceedings of the Book of the Short Papers SIS 2023; Chelli, F., Ciommi, M., Ingrassia, S., Mariani, F., Recchioni, M., Eds.; Pearson: London, UK, 2023; pp. 679–684. [Google Scholar]
- Villani, C. Optimal Transport Old and New; Grundlehren der mathematischen Wissenschaften; Springer: Berlin, Germany, 2009; Volume 338. [Google Scholar]
- Santambrogio, F. Optimal transport for applied mathematicians. Birkäuser 2015, 55, 94. [Google Scholar]
- McCann, R.J. A convexity principle for interacting gases. Adv. Math. 1997, 128, 153–179. [Google Scholar] [CrossRef]
- Agueh, M.; Carlier, G. Barycenters in the Wasserstein space. SIAM J. Math. Anal. 2011, 43, 904–924. [Google Scholar] [CrossRef]
- Catalano, M.; Lijoi, A.; Prünster, I. Measuring dependence in the Wasserstein distance for Bayesian nonparametric models. Ann. Stat. 2021, 49, 2916–2947. [Google Scholar] [CrossRef]
- Marti, G.; Andler, S.; Nielsen, F.; Donnat, P. Optimal transport vs. Fisher-Rao distance between copulas for clustering multivariate time series. In Proceedings of the 2016 IEEE statistical signal processing workshop (SSP), Palma de Mallorca, Spain, 26–29 June 2016; pp. 1–5. [Google Scholar]
- Mordant, G.; Segers, J. Measuring dependence between random vectors via optimal transport. J. Multivar. Anal. 2022, 189, 104912. [Google Scholar] [CrossRef]
- Peyré, G.; Marti, M. Computational Optimal Transport: With Applications to Data Science. Found. Trends® Mach. Learn. 2019, 11, 355–607. [Google Scholar] [CrossRef]
- Panaretos, V.M.; Zemel, Y. Statistical aspects of Wasserstein distances. Annu. Rev. Stat. Appl. 2019, 6, 405–431. [Google Scholar] [CrossRef]
- Cuturi, M.; Doucet, A. Fast computation of Wasserstein barycenters. In Proceedings of the 31st International Conference on Machine Learning; Xing, E., Jebara, T., Eds.; Proceedings of Machine Learning Research: Bejing, China, 2014; Volume 32, pp. 685–693. [Google Scholar]
- Puccetti, G.; Rüschendorf, L.; Vanduffel, S. On the computation of Wasserstein barycenters. J. Multivar. Anal. 2020, 176, 16. [Google Scholar] [CrossRef]
- Takatsu, A. Wasserstein geometry of Gaussian measures. Osaka J. Math. 2011, 48, 1005–1026. [Google Scholar]
- Givens, C.; Shortt, R.M. A class of Wasserstein metrics for probability distributions. Mich. Math. J. 1984, 31, 231–240. [Google Scholar] [CrossRef]
- Dowson, D.C.; Landau, B.V. The Fréchet distance between multivariate normal distributions. J. Multivar. Anal. 1982, 12, 450–455. [Google Scholar] [CrossRef]
- Knott, M.; Smith, C.S. On the optimal mapping of distributions. J. Optim. Theory Appl. 1984, 43, 39–49. [Google Scholar] [CrossRef]
- Olkin, I.; Pukelsheim, F. The distance between two random vectors wigh given dispersion matrices. Linear Algebra Appl. 1982, 48, 257–263. [Google Scholar] [CrossRef]
- Durante, F.; Sempi, C. Principles of Copula Theory; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- Nielsen, F.; Marti, G.; Ray, S.; Pyne, S. Clustering patterns connecting COVID-19 dynamics and human mobility using optimal transport. Sankhyā Ser. B 2021, 83, 167–184. [Google Scholar] [CrossRef]
- Wiesel, J. Measuring association with Wasserstein distances. Bernoulli 2022, 28, 2816–2832. [Google Scholar] [CrossRef]
- Fuchs, S.; Di Lascio, F.M.L.; Durante, F. Dissimilarity functions for rank-invariant hierarchical clustering of continuous variables. Comput. Statist. Data Anal. 2021, 159, 107201. [Google Scholar] [CrossRef]
- Marti, G.; Andler, S.; Nielsen, F.; Donnat, P. Exploring and measuring non-linear correlations: Copulas, Lightspeed Transportation and Clustering. In Proceedings of the NIPS 2016 Time Series Workshop; PMLR: Beijing, China, 2017; pp. 59–69. [Google Scholar]
- Chen, X.; Fan, Y. Estimation and model selection of semiparametric copula-based multivariate dynamic models under copula misspecification. J. Econom. 2006, 135, 125–154. [Google Scholar] [CrossRef]
- Patton, A. A review of copula models for economic time series. J. Multivar. Anal. 2012, 110, 4–18. [Google Scholar] [CrossRef]
- Rémillard, B. Goodness-of-Fit Tests for Copulas of Multivariate Time Series. Econometrics 2017, 5, 13. [Google Scholar] [CrossRef]
- Nasri, B.R.; Rémillard, B.N. Copula-based dynamic models for multivariate time series. J. Multivar. Anal. 2019, 172, 107–121. [Google Scholar] [CrossRef]
- Hofert, M.; Kojadinovic, I.; Mächler, M.; Yan, J. Elements of Copula Modeling with R; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Genest, C.; Nešlehová, J.G.; Rémillard, B. Asymptotic behavior of the empirical multilinear copula process under broad conditions. J. Multivar. Anal. 2017, 159, 82–110. [Google Scholar] [CrossRef]
- Pfeifer, D.; Mändle, A.; Ragulina, O.; Girschig, C. New copulas based on general partitions-of-unity. III: The continuous case. Depend. Model. 2019, 7, 181–201. [Google Scholar] [CrossRef]
- Segers, J.; Sibuya, M.; Tsukahara, H. The empirical beta copula. J. Multivar. Anal. 2017, 155, 35–51. [Google Scholar] [CrossRef]
- Kaufman, L.; Rousseeuw, P.J. Finding Groups in Data: An Introduction to Cluster Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- Bador, M.; Naveau, P.; Gilleland, E.; Castellà, M.; Arivelo, T. Spatial clustering of summer temperature maxima from the CNRM-CM5 climate model ensembles & E-OBS over Europe. Weather Clim. Extrem. 2015, 9, 17–24. [Google Scholar]
- Campello, R.J.; Hruschka, E.R. A fuzzy extension of the silhouette width criterion for cluster analysis. Fuzzy Sets Syst. 2006, 157, 2858–2875. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 0.176 | 0.208 | 0.194 | 0.163 | 0.120 | 0.154 | 0.118 | 0.105 | 0.102 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Benevento, A.; Durante, F. Wasserstein Dissimilarity for Copula-Based Clustering of Time Series with Spatial Information. Mathematics 2024, 12, 67. https://doi.org/10.3390/math12010067
Benevento A, Durante F. Wasserstein Dissimilarity for Copula-Based Clustering of Time Series with Spatial Information. Mathematics. 2024; 12(1):67. https://doi.org/10.3390/math12010067
Chicago/Turabian StyleBenevento, Alessia, and Fabrizio Durante. 2024. "Wasserstein Dissimilarity for Copula-Based Clustering of Time Series with Spatial Information" Mathematics 12, no. 1: 67. https://doi.org/10.3390/math12010067