1. Introduction
Motivation. Mathematical epidemiology had started by proposing simple models for specific epidemics and computing explicitly certain important characteristics like the basic reproduction number and the final size; for example, the SIR model was introduced, among other concepts, in the celebrated “A contribution to the mathematical theory of epidemics” [
1]. The most fundamental, and actually the only general result of the field due to Diekmann, Heesterbeek, Van den Driesche and Watmough, expresses the disease-free equilibrium stability domain in terms of
, which is defined as the Perron–Frobenius eigenvalue of a certain
gradient decomposition (this is presented in detail in
Section 2.2). But, since the
decomposition is not unique, it seems to us that the question of what
is still deserves further discussion.
On the other hand, one may note that nowadays, mathematical epidemiologists typically either restrict themselves to low-dimensional models, resolved symbolically, even by hand, or consider very complicated models which are resolved only numerically, for particular values gleaned from the medical literature. Missing from here are moderately complex models, which may be solved partly symbolically for any values of the parameters, but in a way where the use of computer algebra systems (CAS) is either indispensable or greatly facilitating. Even in the case of papers belonging to this level—see, for example [
2], that the role of the CAS is deemphasized. Our paper is also an attempt to cast the CAS as one of the main heroes of our story.
Our main result. We provide below, for the first time, a universal recipe for choosing a natural gradient decomposition, which only requires specifying the disease compartments (a subset of those which are zero for the boundary point under consideration) (informally, these are not far conceptually from the so-called fast components of singular perturbation theory). This decomposition is useful both for determining and for computing the extinction probabilities of an associated stochastic model. We identify also examples in which the decomposition is not unique and in which choosing another decomposition with F of a lower rank may be beneficial for simplifying the formula.
First restriction (among others to follow). In this paper, we will restrict to mathematical epidemiology models for which there exist at least two possible special fixed states. The first, the disease-free equilibrium (DFE), corresponds to the elimination of all possible compartments involving sickness and will be assumed to be unique. Typically, this point is locally stable only for certain values of the parameters. Outside of this domain, it is typically replaced by another fixed point, which will be called “endemic“ if all its components are positive, and ”resident boundary point” otherwise.
Importantly, the stability of the DFE may be related to the historically famous
basic reproduction number and
net reproduction rate—see (
1). These pillar concepts in population dynamics, mathematical epidemiology, virology, ecology, etc., were already introduced by the father of mathematical demography Lotka—see [
3,
4]—and also the introduction of the book [
5], and in [
6], the authors described the stability of the solution of differential systems.
A bit of history of the net reproduction rate , and its evolution into the mathematical concept of basic reproduction number/stability threshold . Loosely speaking, in the case of only one infectious class, the net reproduction rate
describes the expected number of secondary cases which
one infected case would produce in a homogeneous, completely susceptible population during the lifetime of the infection. This description is especially relevant at the start of an epidemic, when the dynamics is well approximated by that of a branching process (a fact which goes back to Bartlett and Kendall—see for example [
7,
8]). The main characteristic of a branching process is the “fertility”, i.e., the expected number of descendants one individual produces in the next generation. As a consequence, in epidemiology, the branching result insuring extinction when the fertility is less than one translates into local stability results of the disease-free equilibrium involving
.
The reproduction number
intervened already, in a particular case, in the foundational paper “A contribution to the mathematical theory of epidemics” [
1], which showed that:
- 1.
The condition
implies local stability of the DFE. Here
is the net reproduction rate (number of secondary infections produced by one infectious individual), and
is the fraction of susceptibles at the DFE.
- 2.
The condition
implies instability of the DFE.
With more infectious classes, one deals, at the inception of an epidemic, with approximate multi-class branching processes, whose stability is determined via a “
next-generation matrix” (NGM)—see
Section 2.2.
The “Jacobian approach” for computing . For big size problems, this approach is doomed to fail symbolically, since it is equivalent to the Routh–Hurwitz conditions (RH), which rarely succeed symbolically beyond dimension 4 (also, RH is irrelevant numerically, since the eigenvalues themselves are just as easy to compute). Therefore, we studied below a variant, the “Jacobian factorization approach”, which focuses on an approximation, which we show to yield always upper or lower bounds of the NGM
, depending on whether
or not—see Theorem 1. Several questions around this bound are scattered below in
Section 6.3,
Section 8.1, and
Section 8.2.
Note, as mentioned in [
9], that an example where the Jacobian method does not yield
is offered in [
10] (Exe 5.43) and that of [
11] suggesting that when threshold parameters determined from the Jacobian do not have the biological interpretation of the dominant eigenvalue of the next-generation matrix, then they should not be called basic reproductive ratios nor denoted as
(we follow their suggestion and use the notation
in this case).
The dilemma of the several different methods for computing has been discussed in many papers, see for example [
9,
12]. But, this is a direct consequence of the non-uniqueness of the
decomposition.
Deterministic or stochastic models? Most of the mathematical epidemiology papers belong exclusively to one of these two paradigms. However, any deterministic model may also be viewed as a stochastic continuous time Markov field (CTMC) evolving on the integers. One interesting CTMC, which seems not to have been discussed before, is presented in
Section 2.4.
Contents. Our paper is structured as follows.
Section 2 recalls the definition of the DFE and provides our algorithmic definition of the (F, V) decomposition, in the form of a Mathematica script, as well as a discussion—see Remark 6—of why other decompositions might turn out useful. This section also provides a new Equation (
8) for computing extinction probabilities for associated continuous time Markov chain models in terms of the
decomposition, showing that the Jacobian factorization approach yields upper bounds and lower bounds for NGM
’s in
Appendix A.
We turn then to a series of examples, chosen to help investigate what may be the major open problem in the field nowadays, which, in our opinion, relates on one hand to
, and on the other hand, to the extinction probabilities—see below—and duration of minor epidemics [
13,
14,
15,
16,
17], which is not further touched on here.
Let us now briefly explain why so many examples were included in the paper.
Section 4 is dedicated to a host-only model, with a single susceptible class and an
F matrix of rank one, where the formula of
may be “guessed by inspection” of the flow chart. These kinds of examples have kept alive the hope of “interpretable
formulas”, as illustrated in other recent papers—see for example [
18,
19]. But in fact, as far as we know, no interpretable
formula has emerged outside the rank one case, which is already fully studied in [
20]. The papers [
18,
19] start by presenting simple rank one cases, then proposing algorithms for more complex cases based on the graph structure of the flow chart, which, in our opinion, are not sufficiently detailed or documented. While it may well be that tools like Petri nets, as proposed in the second paper, will one day succeed for resolving flow charts with certain structures, this does not seem to have happened yet. Also, for models with a next-generation matrix of high rank, the lack of simple formulas for
and of “simple biological interpretations” is naturally to be expected; simple formulas for the spectral radius can only be a consequence of a simple graph structure which has not been pinpointed yet.
Section 5.1 and
Section 7.1 offer two examples in which several
formulas were offered in the literature, but we are at a loss of how to choose among them. In the first case (a virus–tumor model), the recipe
is simpler than its competitor, but in the second case (a vector–host model), it is more complicated.
Section 6.2 shows that the boundary equilibria and the (invasion) reproduction numbers may be easily computed with our scripts; to illustrate this, we use a two-strain host-only model from [
21] (Ch.8), where our recipe NGM yields the same answer as that given by the Jacobian factorization.
Section 6.3 offers another two-strain host-only example, this time including also vaccination, in which our recipe NGM yields again the same answer as that given by the Jacobian factorization.
Section 7.2 offers an example from the textbook of [
21] in which the square relation stops holding.
Section 8.1 and
Section 8.2 offer yet more examples, this time in the two-strain vector–host context, in which our recipe NGM yields an
formula which is precisely the square root of that given by the Jacobian approach. Note that here, the first of the three elegant relations concerning the invasion numbers from
Section 6.3—see Remark 22—holds, but the other two seem to break down.
The last subsection provides, for the invasion numbers, a second example where another choice of may be more reasonable, on the grounds of leading to a simpler answer (but the admissibility requirement forces then extra assumptions on the parameters).
2. A Bird’s Eye View of Mathematical Epidemiology: The Disease-Free Equilibrium, the Next-Generation Matrix, and an Algorithmic Definition of a Stability Threshold Associated to the Basic Reproduction Number
2.1. The Disease-Free Equilibrium (DFE)
The DFE may be defined as a “maximal boundary state” and may be found by identifying a maximal sub-system of the ODE epidemic model which factors
where the prime denotes the derivative with respect to time, and
M is a matrix that may depend on
but also may not explode in the domain of interest, which we will take for the sake of simplicity to be
.
Remark 1. One fixed point of this system is . This motivates us to call the components disease or infectious states. The set of all its indices will be denoted by . Note that specifying ‘ induces a partition of both the coordinates and the equations of our original system into infection (eliminable) and “non-infection” (the others) components.
The eventual other fixed points may be found by solving together with the other non-infection equations under the condition .
In this paper, we will assume the uniqueness of the DFE, at least after excluding biologically irrelevant fixed points, like an unreachable origin.
We end this section with the very elementary script that implements this. Note that any ODE model “mod” (like SIR, etc…) is a pair mod = (dyn,X) consisting of a vector field “dyn” and a list of variables “X”, and that to find any boundary fixed point, it suffices to know the set of indices “inf” where it is 0, so that we solve the system “dyn==0” under the condition “X[[inf]]->0”. But, since sometimes only numeric solutions are possible, our DFE Mathematica script below also has an optional numerical condition parameter “cn”, which is taken by default as the empty set.
DFE[mod_,inf_,cn_:{}]:=Module[{dyn,X},
dyn=mod[[1]]/.cn;X=mod[[2]];
Solve[Thread[dyn==0]/.Thread[X[[inf]]->0],X]];
For the non-Mathematica users, only the Solve command is relevant, with the others being just Mathematica implementation details.
2.2. Gradient Decompositions, the Next-Generation Matrix, , and a Simple Recipe for Computing Them
From now on, the infection Equation (
2) will be rewritten as
Of course, such a decomposition is not unique, but we will also ask, following [
7,
22,
23], that
F, the gradient of
, is a matrix with non-negative elements, and
, the gradient of
, is a Markovian generating matrix (i.e., a matrix with non-negative off-diagonal elements and non-positive row sums). Conceptually,
F models input to the disease compartments from outside (”new infections”), and
models transfer between the disease compartments. Still, a priori, the decomposition (
3) is not unique.
Example 1. Let us illustrate this via an SIR example with superinfection parameter ξ, in which the classes S and R play symmetric roles inspired by the works of [24,25,26]When this reduces to the symmetric SIR model introduced for mathematical purposes by [25,26], in which births may also directly enter the R class, with parameter , and may also infect, with parameter . Furthermore, there are linear flows from to both and , where the former does not make epidemiologic sense. Here, the only infection equation, the second, is already written in a decomposed form , and .
Note that for the application of the next-generation matrix method, we must finally plug ; therefore, the second term in F, due to ”superinfection”, is irrelevant for this purpose.
Remark 2. The possible non-uniqueness of the decomposition brings us to a delicate point in mathematical epidemiology. Anticipating a bit, since is the Perron–Frobenius eigenvalue of strictly speaking, is not determined just by an ODE epidemical model, but also by the gradient decomposition. If we want an ODE epidemical model to uniquely determine an , we must include, in the definition of the ODE epidemical model, the gradient decomposition we also adopt.
Remark 3. For us, an ODE epidemic model is an ODE dynamical model in which a certain subset of equations, usually called “disease/infection” equations, referred from now on as a zeroable set, admits at least one admissible decomposition (
3),
with satisfying the conditions (A1–A5) of [23]. Remark 4. Note that (
3)
is the most common model used in population dynamics. This makes it natural to informally define ODE epidemic models as population dynamics models (
3),
with extra equations modeling interactions with the non-disease compartments, which admits at least one admissible decomposition. Remark 5. The definition of ODE epidemic models above is imprecise, since it does not list all the requirements we must put on an ODE model. Some reasonable restrictions are
- 1.
Essentially non-negative processes have a non-empty set of disease classes, so we deal with an epidemic (note, however, that we define disease classes in the sense of classes which satisfy (
2),
which excludes, for example, importation models). - 2.
Processes with a unique DFE, at least after excluding biologically irrelevant fixed points, like an unreachable origin.
- 3.
The local stability domain of the DFE is non-empty and not the full set.
- 4.
The dynamical system has polynomial coefficients to be able to take advantage of the remarkable symbolic computation tools available for this class.
We make these assumptions because they are satisfied by most mathematical models which have already been used for modeling real-life biological phenomena. However, these assumptions might not be enough and further ones might be necessary for obtaining the currently missing precise definition of “real life ODE mathematical epidemiology models”.
Remark 6. Admissible decompositions need not be unique. A priori, one may “move terms from F to V”, to lower its rank and simplify the formula for , and also “move off-diagonal terms from V to F”, which enlarges the domain of parameters which ensure that has positive terms. There is a tradeoff between these two possible moves, since the simplicity of comes at the cost of extra assumptions on the parameters. Our universal decomposition seems to strike a balance between the two directions.
Remark 7. It was emphasized from the outstart—see for example [12,27,28,29]—that an ODE mathematical epidemiology model might have several “admissible decompositions”, which might yield distinct next-generation matrices and distinct ’s. For any admissible decomposition, Diekmann, Heesterbeek, Van den Driesche, and Watmough established the following celebrated DFE stability theorem:
Proposition 1. For any admissible decomposition , letdenote the Perron–Frobenius eigenvalue of the next-generation matrix. Then, the DFE is unstable on and locally stable on [7,10,22,23]. For a recent historical overview of
, next-generation matrices, and their calculation in many examples, we refer the reader to the delightful paper [
30].
Unfortunately, the standard definition of a next-generation matrix (and hence of ) involves concepts like “new infections”, which were defined in the original papers based on epidemiological considerations and therefore require the intervention of a human expert. This had created the impression that this method cannot be encapsulated into a computer program. However, we offer and implement below a simple algorithmic definition, based only on the structure of the system and of the “infectious/disease equations”.
Our proposal is to use a special F-V decomposition, with F constructed as the positive part of all the interactions in the disease equations which involve both disease compartments and input/susceptible ones. The latter are defined as the complement of the disease compartments, after the possible removal of output compartments, which may be specified as deterministic functions of the other compartments (i.e., may be computed, once the other compartments are known). Note now that the concept of the “positive part of the interactions” may be hard to pinpoint mathematically, but useful enough to have been implemented in CAS’s (Mathematica, Maple, Sage, etc.); this made us adopt the following definition:
Remark 8. For a given zeroable set, an admissible gradient decomposition (3) is one where F, the gradient of , does not contain, in its expanded form, syntactic minuses in its CAS representation, and also where V, the gradient of , is such that is a “sub-generating matrix” under the assumption of non-negativity of all the model parameters. The problem of whether the of the decomposition provided satisfies, under certain conditions, the stability theorem of Van den Driessche and Watmough is still open; therefore, it should be viewed for now just as a recipe that works well in simple cases.
After lots of experimenting, we have found only few cases—see for example
Section 8.2, where the recipe NGM has a serious competitor; it is for computing the invasion reproduction number for a two-strain vector–host model, with altered infectivity for co-infected vectors, and with ADE (antibody-dependent enhancement).
2.3. An Algorithmic Decomposition
We complement now the famous
“equations decomposition” and the next-generation matrix method of [
7,
22,
23] using a algorithmic
decomposition.
- 1.
The user supplies the model “mod” (a pair containing the RHS of the dynamical system and its variables) and the indices “inf” of the disease (or infectious) variables; the indices of the other compartments are denoted by “infc”.
- 2.
Subsequently, the Jacobian of the infectious equations M with respect to the corresponding variables is computed.
- 3.
Define the interaction terms as terms in M which contain variables , and which, if positive, must end up in F. Their complement, denoted by , will form part of V.
- 4.
As a first guess for F, is constructed as the complement of . It contains all the interaction terms (which involve both disease and susceptible compartments).
- 5.
F is obtained by retaining only the positive part of the matrix , i.e., the terms which do not contain syntactic minuses (we use the simplest algebraic representation of the equations and do not study the effect which algebraic manipulations introducing minuses might have). Finally, is increased to V, which is the complement of F.
- 6.
The script outputs .
NGM[mod_,inf_]:=Module[{dyn,X,infc,M,V,F,F1,V1,K},
dyn=mod[[1]];X=mod[[2]];
infc=Complement[Range[Length[X]],inf];
M=Grad[dyn[[inf]],X[[inf]]]
(*The jacobian of the infectious equations*);
V1=-M/.Thread[X[[infc]]->0]
(*V1 is a first guess for V, retains all gradient terms which
disappear when the non infectious components are null*);
F1=M+V1
(*F1 is a first guess for F, containing all other gradient terms*);
F=Replace[F1, _. _?Negative -> 0, {2}];
(*all terms in F1 containing minuses are set to 0*);
V=F-M;
K=(F . Inverse[V])/.Thread[X[[inf]]->0]//FullSimplify;
{M,V1,F1,F,V,K}]
Note that our NGM script requires a minimal input from the user, which is just the specification of the disease compartments; there is no need to specify “new infections”.
The results of this decomposition seem to yield correct results in all the examples from the literature we checked. We would like to add that for dynamical systems satisfying the four conditions in Remark 5, this decomposition yields “admissible gradient decompositions” in the sense that
will contain only non-negative terms, and that it is furthermore obtainable from an equations’ decomposition, which is admissible in the sense of [
23] and therefore yields the correct stability domain.
Remark 9. Note that the “Replace” command in the script uses the powerful Mathematica capability of applying a “rule” to parts of an “expression”, specified by “levelspec”, and that it was furnished to us by the user Michael E2 in
https://mathematica.stackexchange.com/questions/286500/
how-to-set-to-0-all-terms-in-a-matrix-which-contain-a-minus
/287406?noredirect=1#comment715559_287406
Finally, let us discuss an alternative possible implementation. We could just provide NGM with the right-hand side of the differential equations, compute the steady states, specify one of them, and then define the infected classes as the components with zeros.
However, this would be impractical, since for the majority of the models with explicit DFE, the other fixed points are either not explicit or require very long execution times. It is therefore much simpler to have the user help the AI by providing it with
, which leads immediately to the matrix
M. Essentially, we jump directly to the factorization (
2) of the infected equations, postponing the solving of the non-infection variables to later.
2.4. A Multi-Dimensional Birth-and-Death CTMC Process Associated to a Decomposition, Its Branching Process Approximation, and the Bacaer Equation for the Probability of Extinction
The works of Kendall and Bartlett suggest that ODE epidemic models may be associated to corresponding birth-and-death CTMC processes and then approximated further via branching process.
Citing [
31]: “It has been noted by Bartlett (1955), p. 129, that for an epidemic in a large population, the number of susceptibles may, at least in the early stages of an outbreak, be regarded as approximately constant at its initial value and that this approximation will continue to hold throughout the course of an epidemic, provided that the final epidemic size is small relative to the total susceptible population. Thus the general epidemic process may be approximated by a simple birth-and-death process”.
To make this more precise, a
decomposition (
3) determines a naturally associated multi-dimensional birth-and-death CTMC process by fixing the values of the non-disease variables, so that the matrices
depend only on
, and interpreting the transition rates between compartments as rates of BD transitions. If the CTMC has rates which are linear in the disease variables, one may associate it to a branching process and take advantage of the well-known equation for extinction probabilities. This procedure has been detailed in previous works like [
13,
14,
15,
16,
17] and used to approximate extinction and invasion probabilities, as well as the duration of minor epidemics. If the CTMC has rates which are super linear in the disease variables, a further approximation of ignoring the higher power terms in
is necessary. At the end, this results in assuming that the matrices
are constant (they do not depend on
).
Let us illustrate this philosophy on the famous SIR example. However, in line with our interest in this paper and also getting a bit ahead of ourselves, we will only look at a “disease process” of the infected, with the other components fixed. The state space of the process will thus be . We note this is similar in spirit with the “slow-fast/singular perturbation” technique of considering only variables whose lifetime is short and fixing the other variables whose lifetime is longer, which in fact is the idea behind the famous next-generation matrix approach.
Example 2. The “SIR” disease process (i.e., defined on the disease compartments) is . The natural SIR/linear CT birth-and-death disease stochastic process (DSP) is a Markov process with a generating operator on the set of functions defined byand corresponding to a semi-infinite generator matrix Remark 10. We recall, for the benefit of readers who have not been exposed to the (immense) literature on Markov processes, that the behavior of expectations of this class of stochastic processes always involves one deterministic operator A, the generator of the Markovian semigroup, which acts on a space of “appropriate functions” on the state space (
4)
and where “appropriate” may be skipped in simple cases like ours (
5).
The essential thing to note here is that our Markov generator operator A is completely defined by the rates, just like its “mean-field” deterministic ODE. Thus, from the practical point of view of estimating rates, we have added nothing to the parameters of the ODE model (as would be the case with other stochastic processes involving Brownian motion, etc.). We have only modified the state space and the operator; however, this way, phenomena which are invisible in the continuous mean-field limit become relevant. Finally, for readers puzzled by the question of where the randomness hidden in the deterministic operator (4) is, we mention that this arrives via two Poisson processes describing the times when the process jumps up and down, respectively, and we refer to the literature for more details. This process converges to ∞ (i.e., is non-recurrent) or to a stationary distribution if is strictly bigger than 1
, or strictly smaller than 1
, respectively. The probability of “extinction/absorbtion into 0”
, when starting the process with j infected, are This result may be found for example in the textbook [32] (it is, up to technical difficulties caused by the non-compact state space, the simplest illustration of the fact that solutions of “Dirichlet problems” of the form where τ is the exit time from a domain S, must solve and on the boundary of S). The expected time to extinction when starting the process, with j infected and when may be found using the fact that solutions of “Poisson problems” of the form must solve Another interesting quantity is the expected time to extinction when in the case that extinction occurs. This “Dirichlet-Poisson problem” may be written aswhere , and g is the indicator of extinction occurring. Such expectations must solvewhere p is the solution of the Dirichlet problem with boundary value g. For SIR, we must solve, respectively, These two equations may be solved explicitly. The limits are quite challenging even with Mathematica, as shown in Appendix A.1. We are able to recover and generalize the results of [33] (see also ([16] eq(10))) when for the first problem, but not for the second one). The Bacaer equation. One missing aspect in the previous works, however, characterizes the extinction probabilities via one final equation, without going through the discretization procedure employed in [
13,
14,
15,
16,
17], solving each example individually. Interestingly, such an equation in terms of
decompositions was provided by Griffiths in [
31], except that this paper considers only BD’s with no transfers.
We review now the work of [
34] (who were motivated by analyzing the case of periodic steady solutions), but on the way also spelled out the simple Equation (
8) below. To each fixed value for the disease variables, one may associate to a
decomposition
a “multi-dimensional birth and death process” (BD), with birth rates given by
F, and with transfer and death rates given by
. (
are precisely the mean-field equation for the multi-dimensional birth-and-death process; this is precisely ([
31] eq(6)), under the extra condition that we assume that the immigration vector into the disease compartments is 0. In fact, the
matrix by itself generates an absorbing CTMC (and the
F matrix models’ rough inputs to be fed into this absorbing CTMC). This observation explains that an ODE mathematical epidemiology model has associated it to both a birth-and-death process, as well as a “death and transfer only” absorption CTMC—see Remark 24 for an example. Furthermore, if
are independent of
we are dealing with a branching process (approximation).
A useful fact to recall is that the probabilities of extinction of a multi-variate discrete time-branching process are of the form
where
,
J is the number of disease compartments, and
satisfies the “Bacaer equation”
where * denotes the coordinate-wise product, the dot product is denoted by ∘, and
. This equation is new, but it may be inferred from ([
31] eq(9)) and refs. ([
34] eq(11)) and ([
35] eq(5.3)) (after some changes in the variables).
For the SIR process for example, (
8) becomes
with the two roots
and
, recovering Whittle’s result (the two roots yield the correct result when
is strictly smaller than 1 and strictly bigger than 1, respectively).
We will check below that (
8) also recovers other explicit particular cases offered in the literature, like SEIR [
13], ([
14] (Section 4)), SIV [
36], etc.
2.5. The Jacobian Factorization Bound
Note first the following elementary fact:
Lemma 1. A sufficient (but not necessary) condition for a polynomial with real coefficients and a positive leading term to admit a positive root is that , where is the constant term of the polynomial.
For polynomials of degree 1, this condition is also necessary. This converse result may be strengthened to “Descartes type polynomials”.
Definition 1. We will say that a parametric polynomial with real coefficients, whose constant coefficient may change signs, but whose all other coefficients are “sign definite” and of the same sign (which w.l.o.g. could be supposed as +), is of Descartes type.
As an immediate consequence of Descartes’s rule of signs, it follows that
Lemma 2. A sufficient and necessary condition for a Descartes polynomial with a
positive leading term
to admit a positive root is that , where is the constant term of the polynomial.
Remark 11. Note the immense simplification with respect to the Routh–Hurwitz conditions, when we need to establish the existence of a positive root for a Descartes type polynomial.
We believe that “the mystery of the success of the Jacobian factorization approach” comes from the fact that “simple epidemic models” often feature Descartes type polynomials. However, this leaves us with many further questions, like when does this happen and what to do when it does not.
The Jacobian factorization approach consists in:
- 1.
Putting all the rational factors of the characteristic polynomial of the Jacobian in a form normalized to have positive leading term, assuming they are sign definite (if this is not the case, this approach does not work but may be generalized).
- 2.
Removing all linear factors with eigenvalues which are negative.
- 3.
For all remaining factors
for which
may hold for certain parameter values, rewrite this inequality into the form
where
are the positive and negative parts of the expanded form of
- 4.
Define the “Jacobian factorization
”
Theorem 1. (A) In the instability domain, is a lower bound for .
(B) In the stability domain, is an upper bound for .
Proof. (A) Fix any admissible
F and let
be its associated NGM
. Then
Thus
and the result follows.
(B) Similar proof.
Conjecture: We conjecture that if all the factors are Descartes polynomials, then for any admissible decomposition will denote the resulting object by .
Open question 1: Under what conditions do our NGM and our Jacobian coincide?
The implementation of the Jacobian factorization approach is provided in
Appendix A. □
2.6. The “Rational Univariate Representation” (RUR) and the Reduced Order Quasi-Stationary Approximation
Hundreds of mathematical epidemiology papers have already employed the idea of reducing the fixed point system to one scalar equation in one of the disease variables via rational substitutions for the other variables. We note that this is a particular case of the so-called “rational univariate representation” (RUR), but for Mathematica users, this is irrelevant, since RUR is not implemented currently and we had to write our own script, included below, in which the user chooses a variable in a system that they want to restrict to.
The current code for this reduction to one equation algorithm is
RUR[mod_, ind_, cn_ : {}] := Module[{dyn, X, par, eq, elim},
dyn = mod[[1]]; X = mod[[2]]; par = mod[[3]];
elim = Complement[Range[Length[X]],ind];
eq = Thread[dyn == 0];
ratsub = Solve[Drop[eq, ind], X[[elim]]][[1]];
pol =
Collect[GroebnerBasis[Numerator[Together[dyn /. cn]],
Join[par, X[[ind]]], X[[elim]]], X[[ind]]];
{ratsub, pol}
]
Remark 12. The command which does the essential work is ”GroebnerBasis”. When ”ind” is a set with just one component, this reduces the system to a polynomial in this variable. Alternatively, this could be achieved by plugging the results of ”ratsub” into the system.
The script above works directly for models with demographics but must be modified for “conservation systems”, where the fixed points are only determined by adding the total mass conservation equation to the fixed point equations.
This script may also be used for order reduction, both in the spirit of the ( quasi-steady-state assumption) QSSA method in biochemistry and of the recent epidemiology paper [
37]. We illustrate this for the simplest SIR example.
Example 3. For the SIR process with linear birth rates for the susceptible and the recovered, the system for the fractions is: The DFE is: .
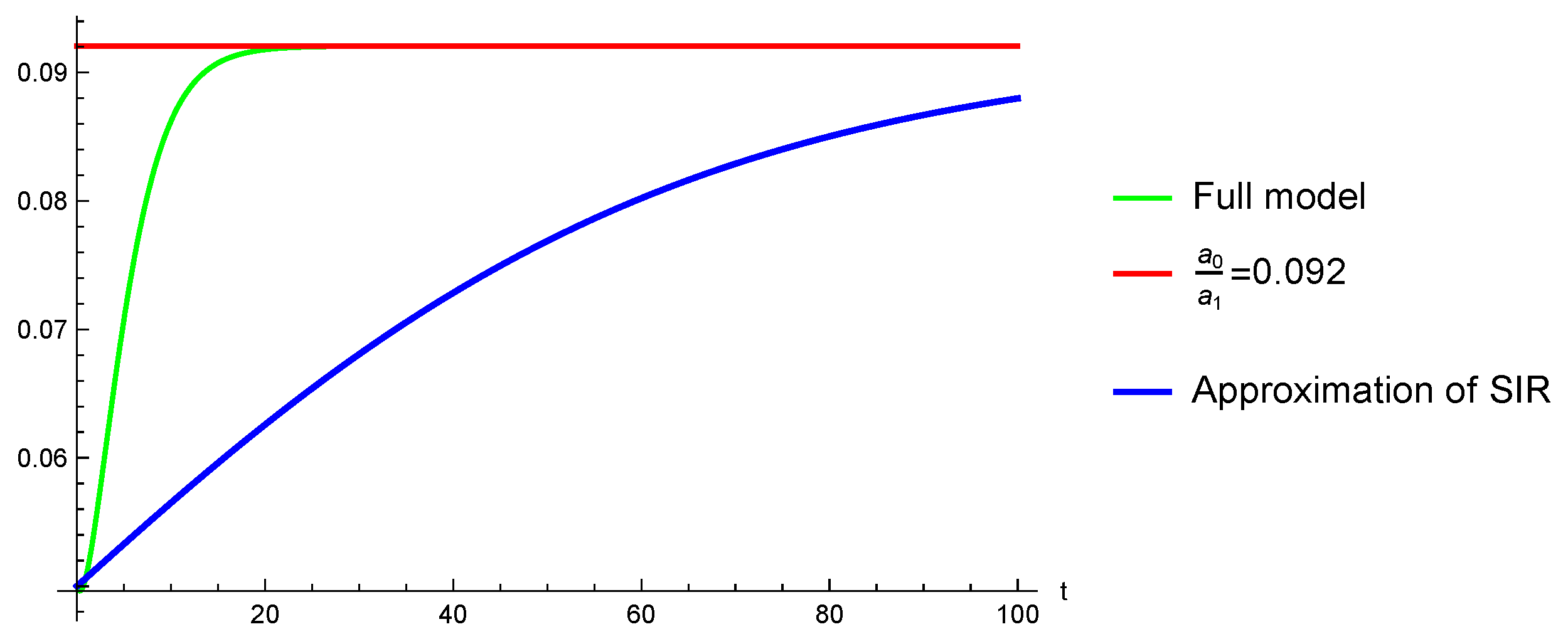
The rational substitution with respect to i obtained via RUR is:Note that this reduces to the DFE when . The reduced approximate model obtained via RUR is: This has an explicit (rather formidable) analytic solution, provided in the Mathematica file.
One may notice that for the chosen numerical illustration, the plots of i and its approximation converge towards the same value but differ sharply for the chosen numeric values as far as shape is concerned; see Figure 1. We mention finally the possibility to develop yet another possible algorithm for computing a “bifurcation ”, suggested by the example above, which is based on the known fact that this parameter is expected to produce bifurcations at .
The steps are:
- 1.
Factor out the variable in the scalar polynomial of the reduced model (always possible if this is a disease variable).
- 2.
Write the free coefficient of the divided polynomial as , where is rational (always possible due to the known bifurcation at ).
- 3.
Identify a factor which is linear in susceptible variables like , etc., and write it as a difference of positive and negative terms. Upon normalizing one of them to one, the other will be , or .
6. Multi-Strain Host-Only Models
Multi-strain diseases are diseases that consist of several strains, or serotypes. One interesting thing about multi-strain models is that, besides the DFE, we have new boundary points which are relevant epidemiologically, in which one subset of strains A is present (“resident”). We have then a natural coexistence of several “ thresholds”:
- 1.
is the bifurcation threshold at which the DFE stops being stable, when the only compartments present are those of A.
- 2.
is the bifurcation threshold at which the boundary point starts existing (in the presence of the compartments).
- 3.
is the bifurcation threshold at which the boundary point stops being stable, i.e., when the compartments invade the A compartments.
Note that for two strains already, we have at least two new thresholds, which, together with and the thresholds , of the individual strains, divide the line into six regions with different stability properties. Studying the relations between the various thresholds in the parameter space is quite a challenging topic. However, their calculation is a priori of the same level of difficulty as for the DFE.
6.1. The Two-Strain SIS Tuberculosis Model of ([22] (Section 4.4))
The model presented here is a limiting case of that presented in the next section, obtained when the transition rates
converge to
∞. It also generalizes the two-strain SIS tuberculosis model of ([
22] (Section 4.4)) by allowing for cross infections in both directions
where we put
in the first two equations to simplify their notation (the last equation may be removed, since
).
Noting that the first two equations’ factor yields the following three boundary steady states, where
:
where we put
The disease-free steady state exists for all parameter values, while the original strain-only steady state is physically relevant if and only if , and the emerging strain-only steady state is physically relevant if and only if .
There may also be a fourth non-negative coexistence equilibrium (COE), given by
Note that this depends only on
which shows that the case
considered in ([
22] (Section 4.4)) is not that restrictive (However, the appearance of
in the denominator suggests limiting the diffusion phenomena, which may be worth studying in their own right.) In this case, the COE point simplifies to:
which is positive if
and the following conditions hold
We give now some details of the NGM implementation for the three boundary points. Recall that the idea is to project the ODE at each boundary point on the 0 coordinates (or some subset), while fixing the other coordinates. We must therefore compute new pairs at each boundary point, since the respective zero coordinates are different.
- 1.
At the DFE, the zero coordinates are , and so .
Our script yields the expected result
- 2.
When
we recover the result ([
22] (18))
This implies that the stability holds if
and
are not too big, more precisely:
For a sanity check, we will derive the stability condition of the point
also by the direct Jacobian approach. The Jacobian at
is
In the case of [
22], the eigenvalues are
The second eigenvalue is negative if
, and the third eigenvalue is negative when
- 3.
An analog result holds via symmetry at
, where
, and
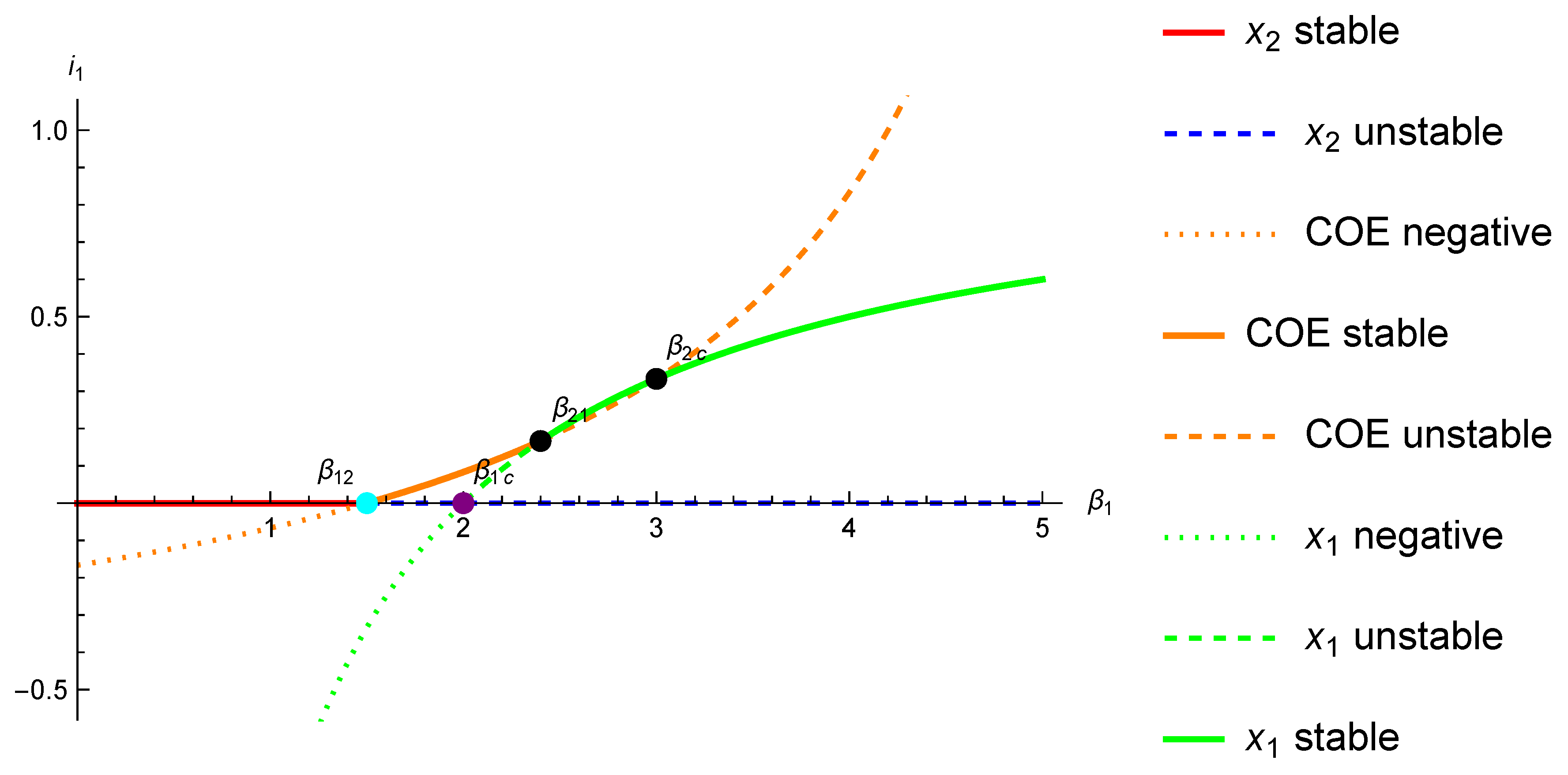
We illustrate now in
Figure 3 via an
bifurcation diagram that, as natural, when
is small enough, the
fixed point is stable enough to be replaced as an attractor, first by the COE, and finally by the
fixed point, when
increases.
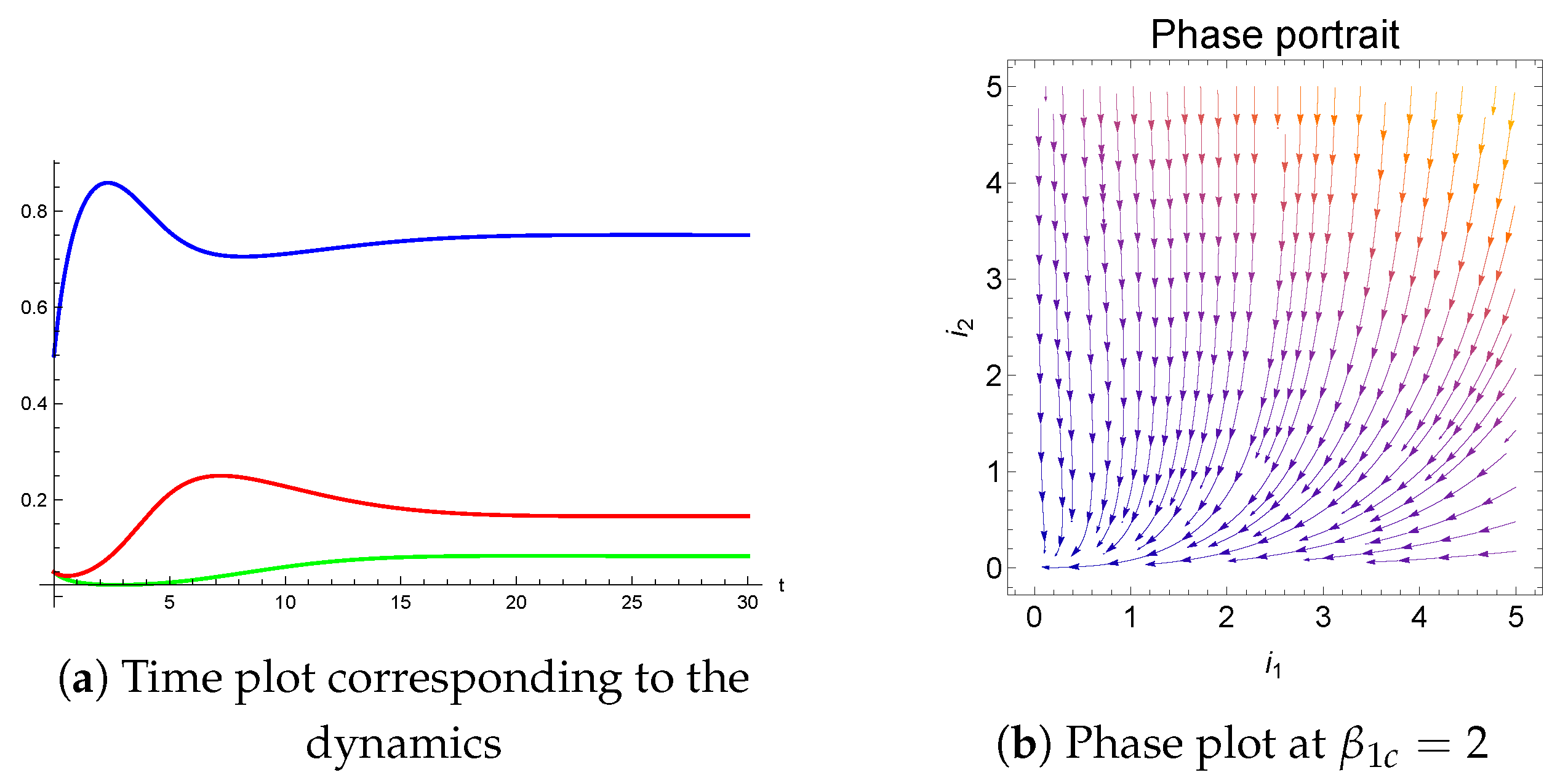
Figure 4 illustrate time and phase plots at the critical point
.
6.2. The Minimal Disease Set of the Multi-Strain Host-Only Dengue Model with Antibody-Dependent Enhancement (ADE) [48]
The ADE (antibody-dependent enhancement) effect, believed to occur for dengue and Zika, means that infection with a single serotype is asymptomatic, but infection with a second serotype may lead to serious illness accompanied by greater infectivity. It was first studied mathematically by [
49,
50], who showed that for sufficiently small ADE, the numbers of infectives of each serotype synchronize, with outbreaks occurring in phase, but when the ADE increases past a threshold, the system becomes chaotic, and infectives of each serotype desynchronize (however, certain groupings of the primary and secondary infectives remain synchronized even in the chaotic regime). Subsequently, Ref. [
51] examined the effects of single-strain vaccine campaigns on the dynamics of an epidemic multi-strain dengue model. We cite now the eloquent dengue description given by these authors:
“What makes modeling the dengue virus so interesting is that it has developed a sophisticated spreading process. Dengue is known to exhibit as many as four coexisting serotypes (strains) in a region. Once a person is infected and recovered from one serotype, they confer life-long immunity from that serotype. However, the antibodies that the body develops for the first serotype will not counteract a second infection by a different serotype. In fact, due to the nature of the disease, the antibodies developed from the first infection form complexes with the second serotype so that the virus can enter more cells, increasing viral production. The increased transmission rate in subsequent infections is known as antibody-dependent enhancement (ADE). ADE is an alarming evolutionary development in multistrain viruses with respect to vaccines. An optimal vaccination would need to cover all strains of the disease at once, or the vaccinations could increase transmission of the strains not covered. This is particularly dangerous for people who have dengue because the infections are more severe in individuals who already have dengue antibodies”.
A multi-strain model which adds further compartments allowing for temporary cross-immunity has been developed in the works of Aguiar, Stollenwerk, and Kooi [
48,
52,
53,
54,
55].
In this section, we consider a ten-compartmentasymmetric version of the model of [
48], whose variables, denoted by capital letters, represent
- 1.
S as individuals susceptible to both strains;
- 2.
, for , as individuals infected with strain i and with temporary cross-immunity to strain ;
- 3.
as individuals who have recovered from strain i, but are not yet susceptible to the other strain j;
- 4.
as individuals who have recovered from strain i, and have become susceptible to the other strain j;
- 5.
as individuals previously infected with strain i and are now immune to it, but became reinfected with strain ;
- 6.
R, omitted in (
31) since they do not feed back to the other components, as the recovered individuals immune to all the strains.
After denoting by small letters the corresponding proportions, we arrive at:
In addition to the DFE where and all the other compartments are 0, this system also has two other boundary points. With , these are:
- 1.
one with
, given by
- 2.
and one with
, given by
Thus, are the bifurcation values at which these two boundary points appear.
The maximal disease set contains
. The DFE may be determined already using the disease set
, which has the advantage of possessing a simple characteristic polynomial with two factors
, which yields:
Also, our scripts find that
Finally, applying the NGM script to
yields the elegant relation
Remark 18. Note the notations , suggesting that we want to view these as polynomials in the variables of the model, rather than as values evaluated at one of the fixed points.
We end this section by drawing the attention to the object which allowed for computing the key polynomials .
Definition 2. (A) A minimal disease set is a minimal set which still allows the computation of the DFE, after being set to 0.
(B) The model factors are the factors which may admit positive roots in the characteristic polynomial of the Jacobian with all variables in set to 0.
Remark 19. Assume w.l.o.g. . Two situations may arise:and in each of them, 1
may lie in any of the partition intervals. This gives raise to six disjoint cases: All these cases have been investigated in detail; for a more general model, see [56], which reviewed in the next section. Thus, it turns out that the results are fully determined by the model factors. Before proceeding, let us give a name to the very interesting structure we have started to investigate.
Definition 3. A Descartes multi-strain model of order M is an epidemic model for which the characteristic polynomial of the Jacobian factors are completely over the rationals as a product of terms, where precisely M of which are “Descartes polynomials”. For such models, the Jacobian factorization threshold is defined as One may check that
Lemma 3. For Descartes multi-strain models of order K, the local stability set is a subset of Remark 20. The example of this section is a Descartes two-strain model (since the characteristic polynomial has only linear factors, precisely two of which have constant coefficients which may change signs).
6.3. Effects of Single-Strain Vaccination on the Dynamics of a Multi-Strain Host-Only Dengue Model with ADE
In this section, we will show that the mysterious Formula (
34) continues to hold under the considerably more complicated two-strains model of [
56], with vaccination applied to one strain only. The model studied in [
56] is depicted in
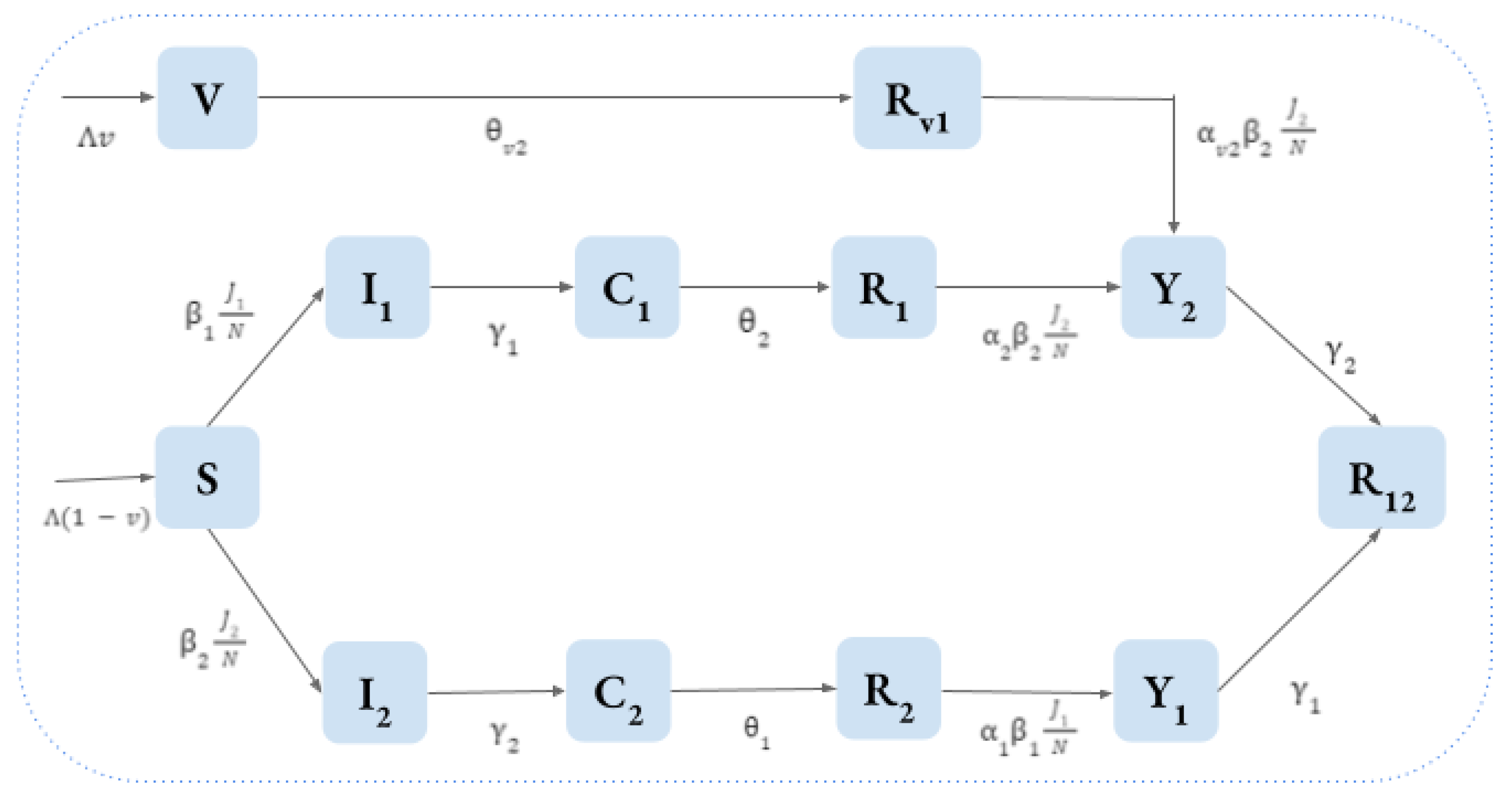
Figure 5.
This model involves twelve compartments, two of which capture the vaccination against strain 1.
- 1.
are individuals susceptible to both strains;
- 2.
, for are individuals infected with strain i, with temporary cross-immunity to strain ;
- 3.
(
in the original model of [
52]) are individuals recovered from strain
i, and hence, are permanently immune to it, with temporary cross-immunity to strain
;
- 4.
(
in the original model of [
52]) are unvaccinated individuals who have recovered from strain
i, but have now become susceptible to the other strain
j;
- 5.
(
in the original model of [
52]) are individuals previously infected with strain
i and are immune to it, but have become reinfected with strain
;
- 6.
are individuals immune to all the strains;
- 7.
Finally, there are individuals V who are vaccinated against strain 1 and are still susceptible to strain 2, and individuals who have been vaccinated against strain 1 and have subsequently become infected by strain 2.
Denote by
the total population, put
, and assume that the two forces of infection acting on
S are:
and that the forces of infection acting on
are:
where
denote the decreases or increases in the susceptibility to secondary infections (
implying an ADE effect).
The following equations, with appropriate initial conditions, represent the disease dynamics model:
Table 1 summarizes the parameters and compartments of the model.
This system does not have negative cross effects; therefore, it leaves the non-negative quadrant invariant [
57]. It follows from the equations that
Therefore,
Assuming
implies that
, for
. Using this, we may assume w.l.o.g. that
, working with the proportions, is to be denoted by the corresponding lowercase letters.
The only non-zero compartments in the DFE, to be denoted by
, are easily found to be
in fact, the last value holds at any fixed point. As known from [
56], there are also two endemic points on the boundary, whose rather complicated formulas will be given later.
Remark 21. From a modeling point of view, this system has crucial parameters like (note that means perfect vaccination, and , which means that infection by the second strain is equally likely for vaccinated people).
Due to conservation, the system evolves in a compact domain, and so we may eliminate one compartment, for example, V, from the analysis. Finally, the last compartment does not send input to the others and therefore may also be disregarded in the analysis.
6.3.1. The Jacobian Is the Max of Two Polynomials, Obtained Using a Minimal Disease Set
We may tackle this example via the Jacobian factorization approach, choosing the
minimal disease set , just like in the previous section. Again, the characteristic polynomial of the Jacobian with the variables in
are set to 0 factors completely as a product of the linear terms
only two of which (the seventh and eighth factors) may yield positive eigenvalues. Both are of the Descartes type, and instability may occur if
At the DFE,
and this yields
This expression reveals a pattern similar to (
16), with the difference that the existence of two strains are reflected in the max and that the second strain is alimented by two classes of susceptibles, one of which is the people vaccinated against the first strain.
In addition to the disease-free equilibrium, there might exist two more equilibriums on the boundary: the endemic equilibrium where there are only infections by strain 1, , and the endemic equilibrium where there are only infections by strain 2, ; this will be reviewed in the next section.
6.3.2. The Endemic Boundary Equilibrium Exist If
At the equilibrium
, the values of
and
are zero. The coordinates are easily found using the “Solve” command. Those of
are the same as at the DFE, and the others are:
where
(the endemic equilibrium
exists if and only if
).
At the equilibrium , the values of and are zero, and that of V is the same as at the DFE.
The solutions of the
system involve all complicated square roots. In such a case, it is more convenient to replace the “Solve” command by our RUR algorithm, which requires the user to input a variable to reduce 2. The normal choice is
(which transitions to positive at the bifurcation value), but here we will use
s, to check the results of [
56], who find, using as a reduction scalar
that
and that
x is the solution of the quadratic equation
The equilibrium
exists if
, where
If
, the fractions in the expression of
b must be smaller than one or equal to one, and it is not possible for both to be one. Therefore,
. We also have
. Since that
, Equation (
42) does not have roots with positive real parts. This implies that there is no endemic equilibrium like
. Thus, in this case,
. Since the coefficient
a is positive, Equation (
42) has two real roots and only one of them is positive. To resume, if
, there is a unique endemic equilibrium where there are infections only by strain 2.
6.3.3. The Recipe next-generation matrix and the Jacobian Factorization One Coincide
This section shows that the polynomials in this example may also be obtained via the next-generation matrix approach as eigenvalues of the K matrix via a judicious choice of infectious classes.
One may choose, as the infectious subset, the nine compartments that are 0 in the limit, but a luckier choice here is the smaller subset
, which precisely has, as eigenvalues, the expressions
in (
33).
The decomposition matrices are
where
are:
The explicit non-zero eigenvalues of the next-generation matrix
are
confirming the result of the Jacobian method.
Let us note finally that (
37), as well as the result of this section, imply the relation
where
denote the bifurcation parameters at which the boundary points
start to exist.
Remark 22. Interestingly, is the max of two quantities which satisfy that are precisely the domains where endemic points containing exactly one of the strains appear—see (
44).
This formula, natural in cases where the next-generation matrix has a block structure, seems to be a general feature of multi-strain models, even when the block structure is not apparent. In the case of this section, there seems to be a more specific structure: the Jacobian factorization approach allows for introducing two “Descartes type” (see Definition 1) factors of the characteristic polynomial, which are that
- 1.
The existence conditions formay be expressed as—
see (
40), (
42),
and (
46).
- 2.
The invasion reproduction numbers may be obtained simply by substituting the coordinates of the dominance boundary equilibria into the corresponding factor. More precisely, the invasion number of the fixed point for strain i is given by .
Open question 2: Does the relation hold for all Descartes multi-strain models of order K? (recall Definition 3 and Lemma 3).
6.3.4. The Invasion Reproduction Number of Is Given by
The invasion reproduction numbers (see for example [
58]) may, just as the basic reproduction number, be calculated using the next-generation matrix.
Our script yields quickly that
Open question 3: Do the formulas connecting (
44) and (
45) to the Jacobian factorization
hold for some general class of epidemic models?
(C) For “two strain epidemic models”, what conditions must be satisfied to ensure the inequalities ?
To resolve these questions, it might be useful to study the three and four strain generalizations of this problem and to investigate “non-simple” multi-strain models (in which the characteristic polynomial contains non-Descartes type polynomials).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}