
A Comparative Evaluation of Self-Attention Mechanism with ConvLSTM Model for Global Aerosol Time Series Forecasting
 , , and
, , and
Abstract
:1. Introduction
2. Data and Methodology
2.1. Pre-Training Process
2.2. Literature Review and Related Work
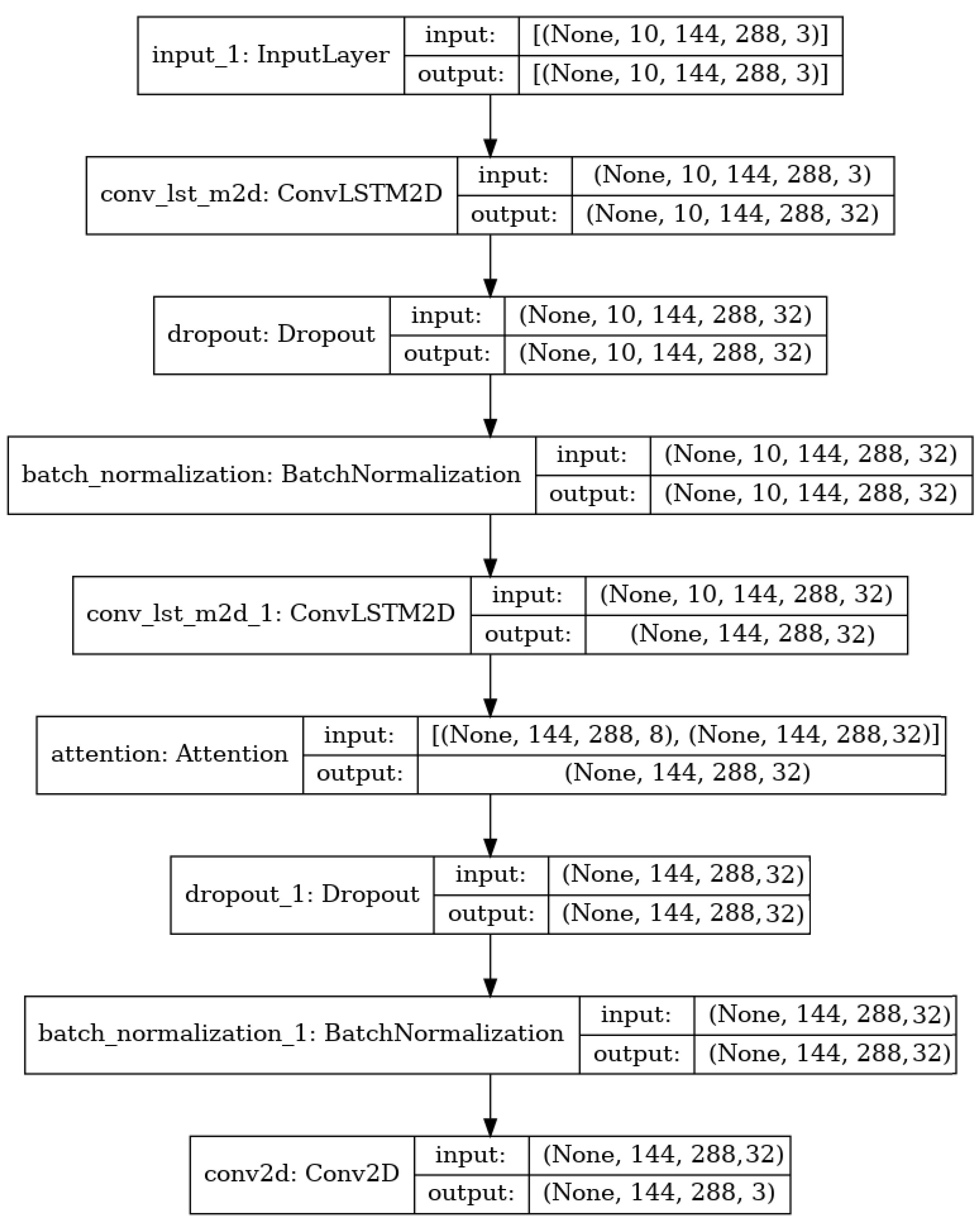
3. Deep Learning Model
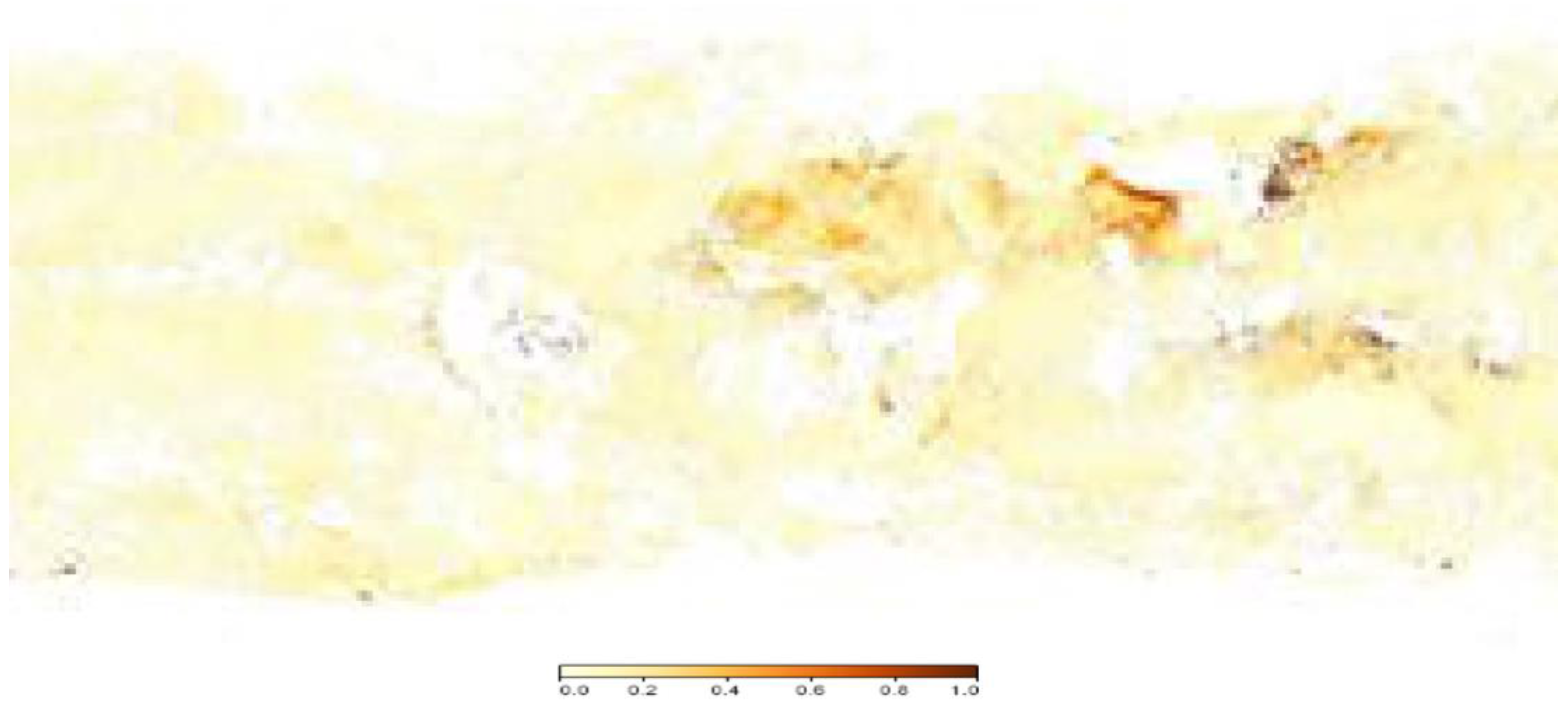
4. Results and Discussion
4.1. Evaluation Criteria
- The model is capable to generate image of global AOT if metrics for predicted image in comparation of an original image is equal or better than average difference of randomly selected images from the database.
- The model is capable to find patterns in time domain if metrics for predicted image in comparation of an original image is equal or better than average difference of two adjacent images from the database.
4.2. Comparative Analysis
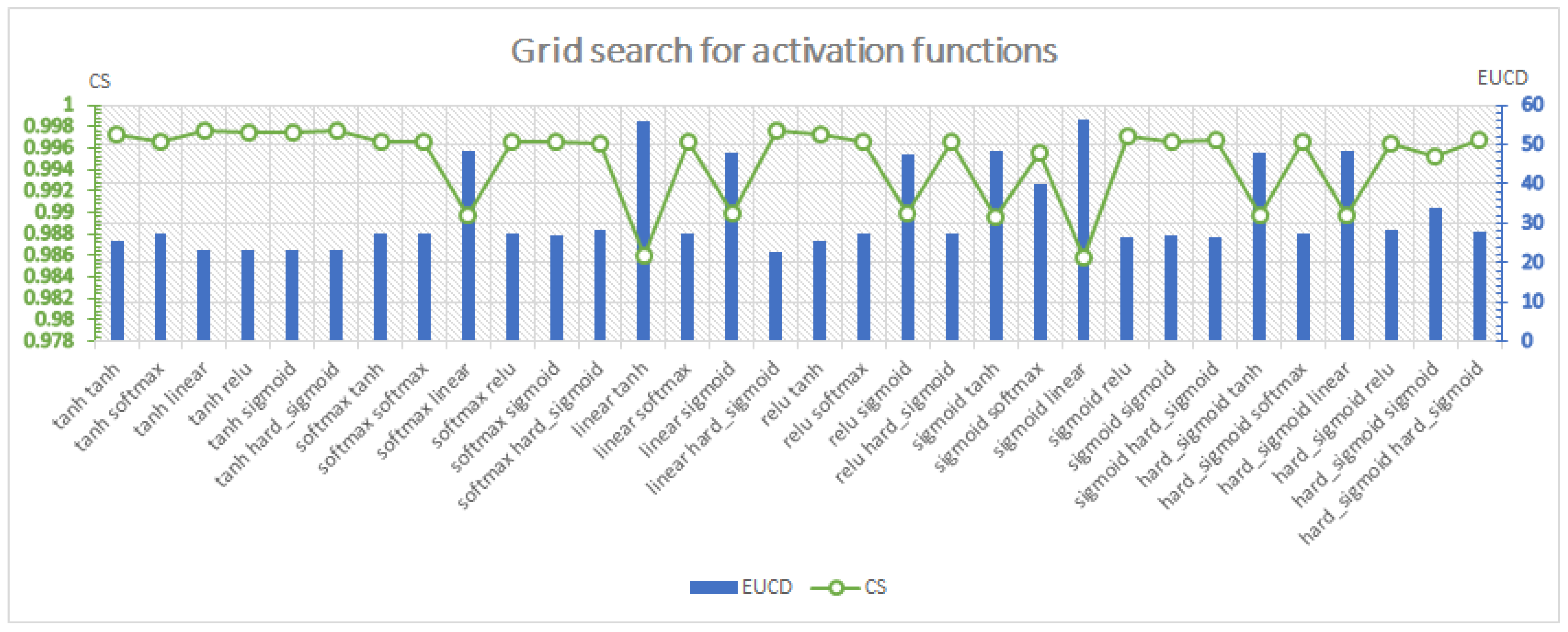
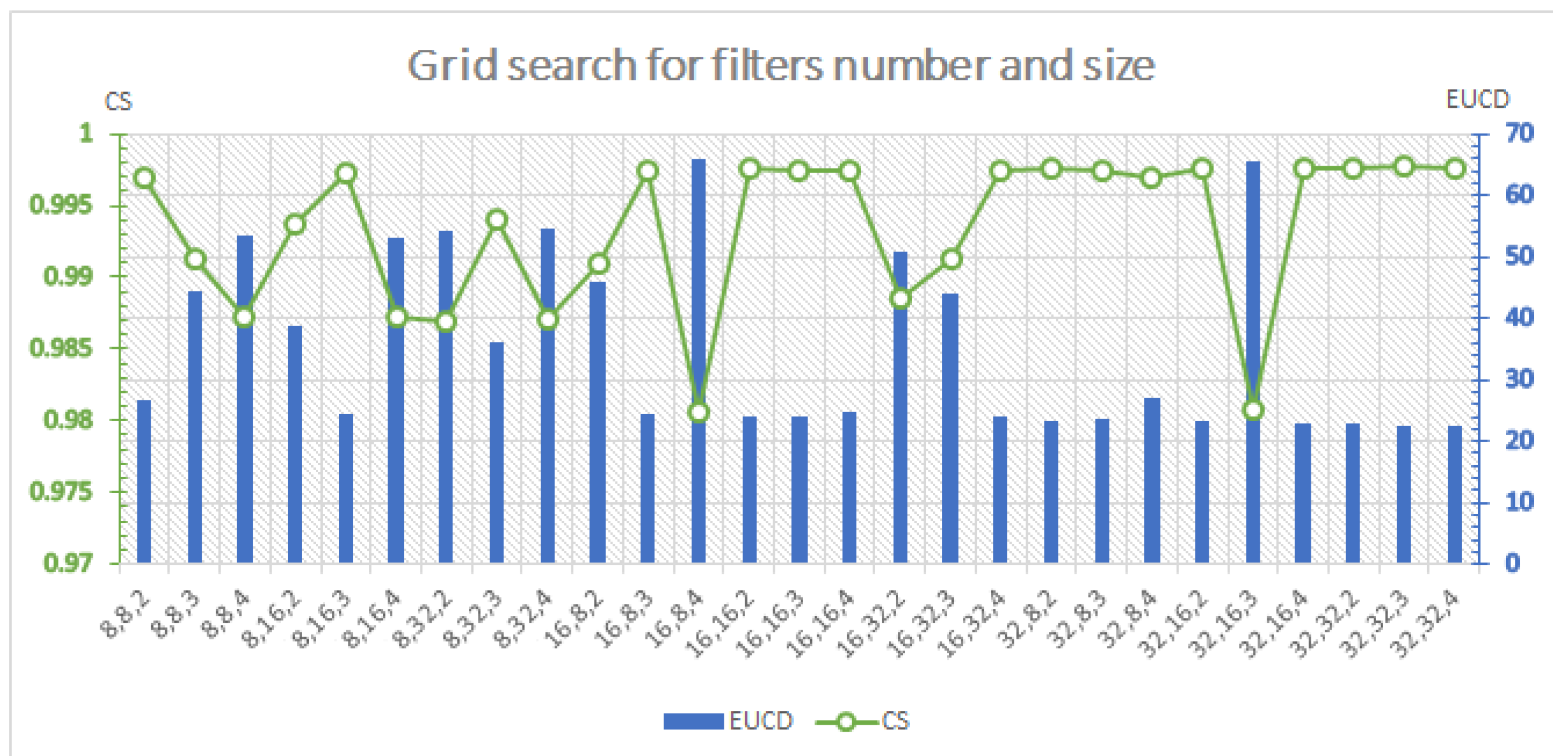
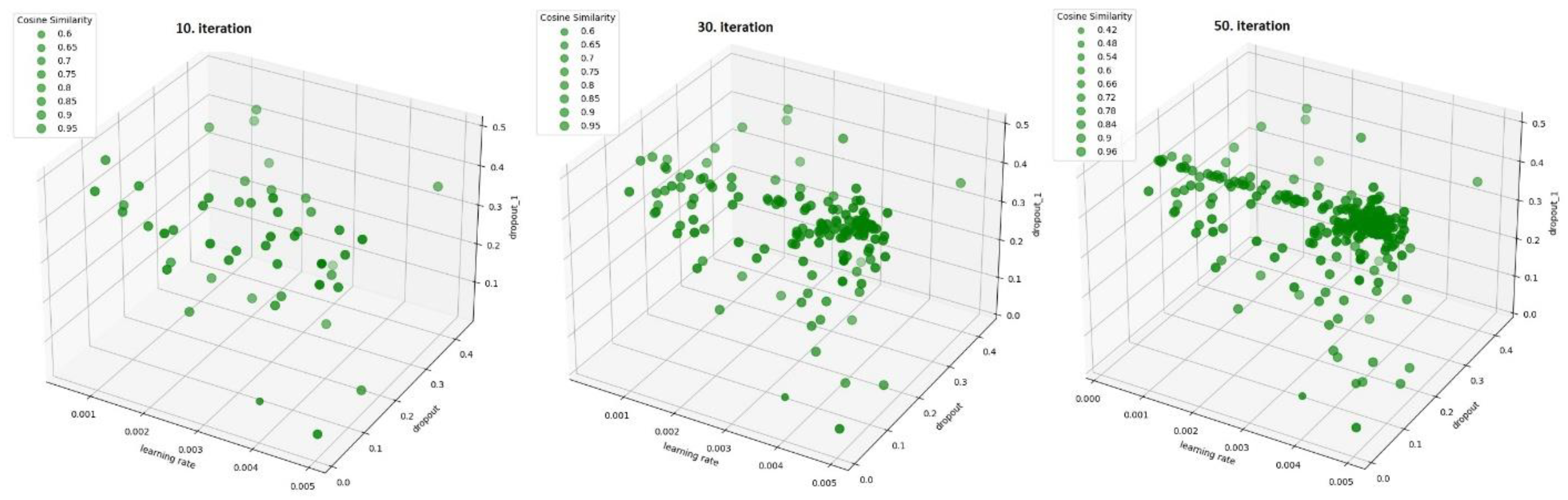
4.3. Hyperparameter Tuning
4.4. Ablation Study on Self-Attention Mechanism
4.5. Statistical Tests
5. Conclusions and Future Research
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Duncan, B.N.; Prados, A.I.; Lamsal, L.N.; Liu, Y.; Streets, D.G.; Gupta, P.; Hilsenrath, E.; Kahn, R.A.; Nielsen, J.E.; Beyersdorf, A.J.; et al. Satellite data of atmospheric pollution for U.S. air quality applications: Examples of applications, summary of data end-user resources, answers to FAQs, and common mistakes to avoid. Atmos. Environ. 2014, 94, 647–662. [Google Scholar] [CrossRef] [Green Version]
- Logan, T.; Dong, X.; Xi, B. Aerosol properties and their impacts on surface CCN at the ARM Southern Great Plains site during the 2011 Midlatitude Continental Convective Clouds Experiment. Adv. Atmos. Sci. 2018, 35, 224–233. [Google Scholar] [CrossRef]
- Nikezić, D.P.; Ramadani, U.R.; Radivojević, D.S.; Lazović, I.M.; Mirkov, N.S. Deep Learning Model for Global Spatio-Temporal Image Prediction. Mathematics 2022, 10, 3392. [Google Scholar] [CrossRef]
- Wangperawong, A. Attending to Mathematical Language with Transformers. arXiv 2019. [Google Scholar] [CrossRef]
- Vaswani, A.; Bengio, S.; Brevdo, E.; Chollet, F.; Gomez, A.N.; Gouws, S.; Uszkoreit, J. Tensor2Tensor for Neural Machine Translation, AMTA. In Proceedings of the 13th Conference of the Association for Machine Translation in the Americas, Association for Machine Translation in the Americas, Boston, MA, USA, 17–21 March 2018; Volume 1: Research Track, pp. 193–199. [Google Scholar]
- Su, J.; Byeon, W.; Kossaifi, J.; Huang, F.; Kautz, J.; Anandkumar, A. Convolutional Tensor-Train LSTM for Spatio-Temporal Learning. In Proceedings of the Advances in Neural Information Processing Systems 33 (NeurIPS 2020), Virtual, 6–12 December 2020; Volume 33, pp. 13714–13726, ISBN 9781713829546. [Google Scholar]
- Zivkovic, M.; Jovanovic, L.; Ivanovic, M.; Bacanin, N.; Strumberger, I.; Joseph, P.M. XGBoost Hyperparameters Tuning by Fitness-Dependent Optimizer for Network Intrusion Detection. In Communication and Intelligent Systems; Sharma, H., Shrivastava, V., Kumari Bharti, K., Wang, L., Eds.; Lecture Notes in Networks and Systems; Springer: Singapore, 2022; Volume 461. [Google Scholar] [CrossRef]
- Lin, Z.; Li, M.; Zheng, Z.; Cheng, Y.; Yuan, C. Self-Attention ConvLSTM for Spatiotemporal Prediction. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI-20), New York, NY, USA, 7–12 February 2020. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30, ISBN 9781510860964. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Houlsby, N. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations (ICLR 2021), Vienna, Austria, 4–8 May 2021. [Google Scholar]
- Luong, M.-T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Lisbon, Portugal, 17–21 September 2021; pp. 1412–1421. [Google Scholar]
- Dzmitry, B.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2016, arXiv:1409.0473. [Google Scholar] [CrossRef]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in Vision: A Survey. ACM Comput. Surv. 2022, 54, 1–41. [Google Scholar] [CrossRef]
- Wensel, J.; Ullah, H.; Munir, A. ViT-ReT: Vision and Recurrent Transformer Neural Networks for Human Activity Recognition in Videos. arXiv 2022, arXiv:2208.07929. [Google Scholar] [CrossRef]
- Kaiser, Ł.; Bengio, S. Can Active Memory Replace Attention? In Proceedings of the 30th International Conference on Neural Information Processing Systems (NIPS’16), Barcelona, Spain, 5–10 December 2016; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 3781–3789. [Google Scholar]
- Ge, H.; Li, S.; Cheng, R.; Chen, Z. Self-Attention ConvLSTM for Spatiotemporal Forecasting of Short-Term Online Car-Hailing Demand. Sustainability 2022, 14, 7371. [Google Scholar] [CrossRef]
- Bacanin, N.; Zivkovic, M.; Stoean, C.; Antonijevic, M.; Janicijevic, S.; Sarac, M.; Strumberger, I. Application of Natural Language Processing and Machine Learning Boosted with Swarm Intelligence for Spam Email Filtering. Mathematics 2022, 10, 4173. [Google Scholar] [CrossRef]
- Elements of Multivariate Statistics and Statistical Learning, Statistical Image Analysis, Department of Mathematics, Dartmouth College. Available online: https://math.dartmouth.edu/~m70s20/ImageAnalysis.pdf (accessed on 19 January 2023).
- D’Agostino, R.B. An omnibus test of normality for moderate and large sample size. Biometrika 1971, 58, 341–348. [Google Scholar] [CrossRef]
- Bacanin, N.; Stoean, R.; Zivkovic, M.; Petrovic, A.; Rashid, T.A.; Bezdan, T. Performance of a Novel Chaotic Firefly Algorithm with Enhanced Exploration for Tackling Global Optimization Problems: Application for Dropout Regularization. Mathematics 2021, 9, 2705. [Google Scholar] [CrossRef]
- Kruskal, W.H.; Wallis, W.W. Use of Ranks in One-Criterion Variance Analysis. J. Am. Stat. Assoc. 1952, 47, 583–621. [Google Scholar] [CrossRef]
- Spliethöver, M.; Klaff, J.; Heuer, H. Is It Worth the Attention? A Comparative Evaluation of Attention Layers for Argument Unit Segmentation. In Proceedings of the 6th Workshop on Argument Mining, Association for Computational Linguistics, Florence, Italy, 1 August 2019; pp. 74–82. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CS | RMSE | EUCD | |
|---|---|---|---|
| 1. criterion for evaluation | 0.9950 ±0.002 | 0.0931 ±0.018 | 32.8803 ±6.318 |
| 2. criterion for evaluation | 0.9975 ±0.001 | 0.0663 ±0.013 | 23.3766 ±4.493 |
| Ratio | Train | Validation | Test | ||||||
|---|---|---|---|---|---|---|---|---|---|
| CS | RMSE | EUCD | CS | RMSE | EUCD | CS | RMSE | EUCD | |
| 70:20:10 | 0.9982 | 0.0736 | 23.1746 | 0.9985 | 0.0664 | 23.1272 | 0.9975 | 0.0665 | 23.0200 |
| 70:10:20 | 0.9982 | 0.0727 | 23.2243 | 0.9985 | 0.0670 | 23.2473 | 0.9976 | 0.0660 | 22.9765 |
| 20:70:10 | 0.9982 | 0.0741 | 23.3053 | 0.9986 | 0.0679 | 23.5969 | 0.9975 | 0.0668 | 23.1850 |
| 20:10:70 | 0.9982 | 0.0682 | 23.4433 | 0.9984 | 0.0682 | 23.6810 | 0.9976 | 0.0656 | 22.8610 |
| 10:70:20 | 0.9981 | 0.0752 | 23.6591 | 0.9986 | 0.0683 | 23.7524 | 0.9974 | 0.0680 | 23.5864 |
| 10:20:70 | 0.9984 | 0.0711 | 23.1147 | 0.9986 | 0.0665 | 23.0807 | 0.9976 | 0.0667 | 23.0897 |
| Ratio | Train | Validation | Test | ||||||
|---|---|---|---|---|---|---|---|---|---|
| CS | RMSE | EUCD | CS | RMSE | EUCD | CS | RMSE | EUCD | |
| 70:20:10 | 0.9987 | 0.0624 | 21.7002 | 0.9987 | 0.0625 | 21.6925 | 0.9978 | 0.0624 | 21.5246 |
| 70:10:20 | 0.9988 | 0.0619 | 21.2434 | 0.9988 | 0.0614 | 21.2196 | 0.9979 | 0.0613 | 21.2229 |
| 20:70:10 | 0.9987 | 0.0621 | 21.308 | 0.9987 | 0.0633 | 21.8114 | 0.9979 | 0.0615 | 21.1876 |
| 20:10:70 | 0.9987 | 0.0637 | 22.2504 | 0.9986 | 0.0652 | 22.5577 | 0.9979 | 0.0624 | 21.6773 |
| 10:70:20 | 0.9987 | 0.0623 | 21.5556 | 0.9988 | 0.0623 | 21.5717 | 0.9978 | 0.0633 | 21.7486 |
| 10:20:70 | 0.9987 | 0.063 | 22.045 | 0.9987 | 0.0636 | 22.0764 | 0.9977 | 0.0645 | 22.2383 |
| CS | RMSE | EUCD | ||||
|---|---|---|---|---|---|---|
| AVG | DIFF [%] | AVG | DIFF [%] | AVG | DIFF [%] | |
| Train | 0.99872 ±4 × 10−3% | 5 × 10−2 ±1 × 10−2 | 6.25 × 10−2 ±1.07% | −13.86 ±3.63 | 21.68 ±1.85% | −7.01 ±2.04 |
| Validation | 0.99872 ±7.5 × 10−3% | 1.8 × 10−2 ±1.1 × 10−2 | 6.3 × 10−2 ±2.08% | −6.43 ±2.44 | 21.82 ±2.10% | −6.80 ±2.45 |
| Test | 0.99783 ±8.2 × 10−3% | 3 × 10−2 ±1.2 × 10−2 | 6.3 × 10−2 ±1.9% | −6.06 ±2.27 | 21.60 1.80% | −6.57 ±2.10 |
| Ratio | Train | Validation | Test | ||||||
|---|---|---|---|---|---|---|---|---|---|
| CS | RMSE | EUCD | CS | RMSE | EUCD | CS | RMSE | EUCD | |
| 70:20:10 | 0.9987 | 0.0634 | 21.4830 | 0.9988 | 0.0619 | 21.4671 | 0.9979 | 0.0617 | 21.2680 |
| 70:10:20 | 0.9987 | 0.0627 | 21.2872 | 0.9988 | 0.0617 | 21.3075 | 0.9979 | 0.0610 | 21.1572 |
| 20:70:10 | 0.9988 | 0.0618 | 21.1337 | 0.9988 | 0.0625 | 21.5810 | 0.9979 | 0.0611 | 21.0578 |
| 20:10:70 | 0.9987 | 0.0624 | 21.3761 | 0.9987 | 0.0629 | 21.7307 | 0.9980 | 0.0597 | 20.7411 |
| 10:70:20 | 0.9987 | 0.0626 | 21.2960 | 0.9988 | 0.0617 | 21.3259 | 0.9979 | 0.0622 | 21.3959 |
| 10:20:70 | 0.9987 | 0.0622 | 21.2285 | 0.9988 | 0.0613 | 21.2381 | 0.9979 | 0.0622 | 21.3617 |
| CS | RMSE | EUCD | ||||
|---|---|---|---|---|---|---|
| AVG | DIFF [%] | AVG | DIFF [%] | AVG | DIFF [%] | |
| Train | 0.99872 ±4.1 × 10−3% | 0 ±5.8 × 10−3 | 6.25 × 10−2 ±0.86% | −7.99 × 10−2 ±1.37 | 21.30 ±0.56% | −1.77 ±1.93 |
| Validation | 0.99878 ±4.0 × 10−3% | 6.7 × 10−3 ±8.5 × 10−3 | 6.2 × 10−2 ±0.95% | −1.67 ±2.28 | 21.44 ±0.87% | −1.74 ±2.27 |
| Test | 0.99792 ±4.0 × 10−3% | 8.4 × 10−3 ±9.1 × 10−3 | 6.1 × 10−2 ±1.54% | −2.00 ±2.45 | 21.16 ±1.15% | −2.02 ±2.13 |
| Object of Testing | Sort of Testing | Data | Statistic | p Value |
|---|---|---|---|---|
| Image | Normaltest | original | 312.74 | 0.0156 |
| ConvLSTM-SA | 323.48 | 0.0033 | ||
| ConvLSTM | 187.11 | 0.0230 | ||
| Kruskal–Wallis H test | Original/ConvLSTM-SA | 161.85 | 0.0823 | |
| Original/ConvLSTM | 119.56 | 0.0992 | ||
| ConvLSTM-SA/ConvLSTM | 151.82 | 0.0444 | ||
| Pixel in time domain | Normaltest | original | 137.12 | 0.0377 |
| ConvLSTM-SA | 55.34 | 0.0198 | ||
| ConvLSTM | 63.16 | 0.0537 | ||
| Kruskal–Wallis H test | Original/ConvLSTM-SA | 52.04 | 0.0927 | |
| Original/ConvLSTM | 29.80 | 0.2373 | ||
| ConvLSTM-SA/ConvLSTM | 54.76 | 0.0848 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Radivojević, D.S.; Lazović, I.M.; Mirkov, N.S.; Ramadani, U.R.; Nikezić, D.P. A Comparative Evaluation of Self-Attention Mechanism with ConvLSTM Model for Global Aerosol Time Series Forecasting. Mathematics 2023, 11, 1744. https://doi.org/10.3390/math11071744
Radivojević DS, Lazović IM, Mirkov NS, Ramadani UR, Nikezić DP. A Comparative Evaluation of Self-Attention Mechanism with ConvLSTM Model for Global Aerosol Time Series Forecasting. Mathematics. 2023; 11(7):1744. https://doi.org/10.3390/math11071744
Chicago/Turabian StyleRadivojević, Dušan S., Ivan M. Lazović, Nikola S. Mirkov, Uzahir R. Ramadani, and Dušan P. Nikezić. 2023. "A Comparative Evaluation of Self-Attention Mechanism with ConvLSTM Model for Global Aerosol Time Series Forecasting" Mathematics 11, no. 7: 1744. https://doi.org/10.3390/math11071744